Unlocking Latent Value: Taxonomy-Guided Recovery of High-Performing Data from Low-Tier Web Corpora
Pith reviewed 2026-06-27 21:50 UTC · model grok-4.3
The pith
Taxonomy-guided filtering recovers high-performing data from low-tier web corpora, allowing subsets from lower tiers to outperform unfiltered top-tier data on reasoning and coding.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
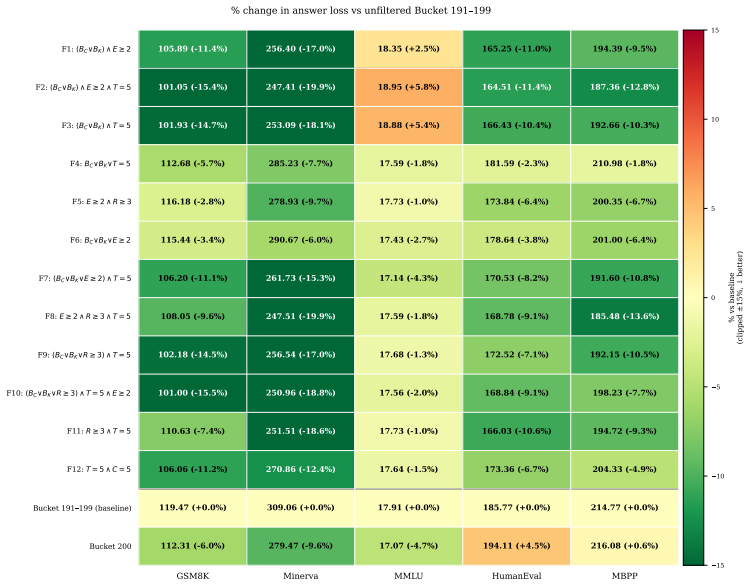
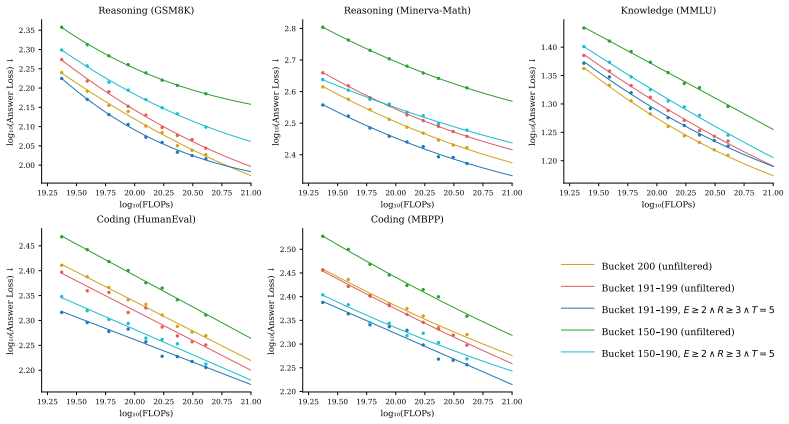
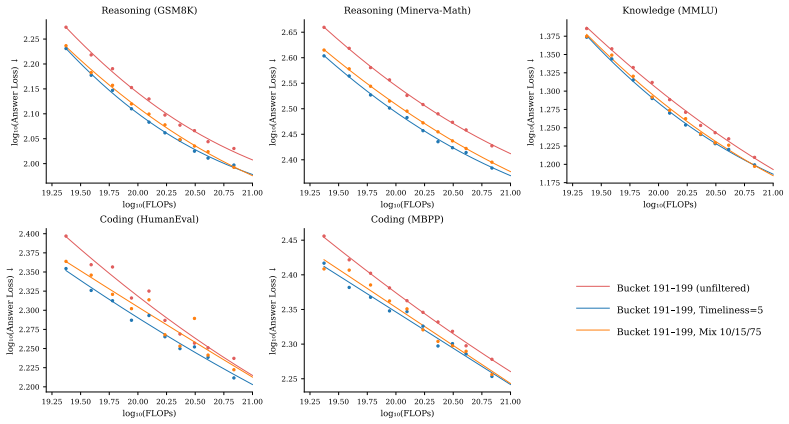
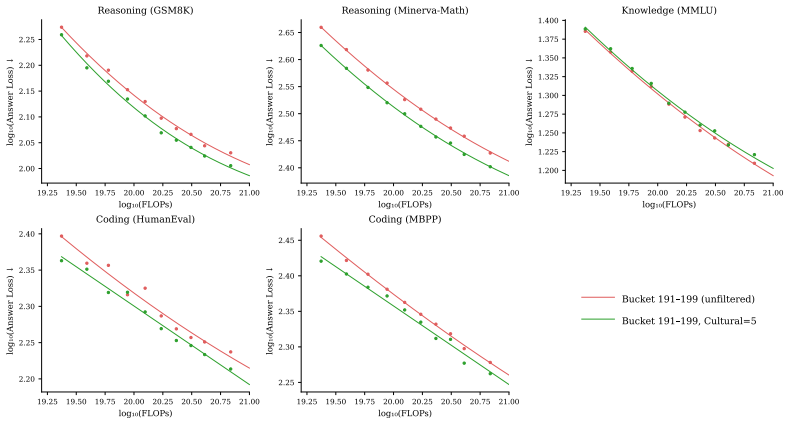
The central claim is that taxonomy-driven multi-dimensional filtering unlocks latent value in low-tier web data. New dimensions of timeliness and cultural specificity are added to an existing taxonomy; documents are annotated at scale with a distilled lightweight model and an MLP on embeddings. A two-pass framework first finds strong single-dimension signals then evaluates compound filters, identifying configurations that, when applied to mid-tier data, yield 12.1% gains on reasoning and 9.5% on coding over the unfiltered baseline while exceeding top-tier data by 6.7% on reasoning and 13.7% on coding. Data from two tiers below the production threshold improves by 22.3% on reasoning and 19.5%
What carries the argument
The taxonomy-driven two-pass filter selection framework that constructs and evaluates conjunctive and disjunctive compound filters from the strongest dimension signals identified at small scale.
If this is right
- Low-tier web data contains recoverable high-value subsets for reasoning and coding that exceed current top-tier performance after filtering.
- Composite single-score curation systematically underweights certain semantic dimensions that multi-dimensional taxonomy captures.
- The two-pass selection method reduces the cost of exploring filter combinations enough to make corpus-wide application practical.
- Deprioritized data sources can be re-evaluated with the same taxonomy to surface additional training material without new crawling.
Where Pith is reading between the lines
- Similar taxonomy filtering could be applied to other data modalities or domains where single-score curation is used.
- The gains suggest that production data pipelines may be over-discarding material that would benefit from dimension-specific selection rather than global thresholds.
- If the taxonomy dimensions prove stable across model scales, the approach could be used to audit and improve existing pretraining corpora retroactively.
Load-bearing premise
Annotations produced by the large model are treated as reliable ground truth when training the smaller labelers for the new taxonomy dimensions.
What would settle it
Re-annotating the same documents with human raters or an independent large model and then re-running the filter selection and downstream training; if the performance gains disappear, the claim is falsified.
Figures


read the original abstract
Dominant web data curation pipelines for pretraining collapse document quality into a single composite score, systematically missing high-value content along dimensions the scorer underweights. We present a taxonomy-driven framework that recovers this value by filtering along semantically meaningful dimensions that composite scores fail to capture. First, building on the ESSENTIAL-WEB taxonomy, we introduce two novel dimensions: timeliness and cultural specificity, both of which show low pairwise NMI with existing ones. We annotate 14M documents using Qwen2.5 32B and distill into a lightweight 0.5B model. To enable rapid corpus-wide annotation, we additionally train a 73M multi-task MLP on E5 embeddings, achieving 50x inference throughput. Second, to navigate the combinatorial explosion of filter configurations, we introduce a compute-efficient two-pass framework: Pass 1 identifies the strongest dimension signals at small scale; Pass 2 constructs and evaluates conjunctive and disjunctive compound filters from the top performers - identifying high-performing configurations at a fraction of full scaling-law cost. Applying the selected filters to deprioritized web data, taxonomy-filtered subsets outperform their unfiltered baselines and even surpass the highest-quality tier. On mid-tier data, our best filter improves over its unfiltered baseline by 12.1% on reasoning, 9.5% on coding, and 2.0% on knowledge benchmarks, exceeding unfiltered top-tier data by 6.7% on reasoning and 13.7% on coding. Furthermore, filtered data from two tiers below the typical production threshold improves by 22.3% on reasoning and 19.5% on coding over its unfiltered baseline, surpassing top-tier data on coding benchmarks. These results establish that vast latent value remains locked in deprioritized web data, and that multi-dimensional taxonomy filtering is a principled, compute-efficient key to unlocking it.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that a taxonomy-driven multi-dimensional filtering approach, introducing timeliness and cultural specificity dimensions annotated by Qwen2.5-32B and distilled to 0.5B/73M models, combined with a two-pass compound filter selection process, can recover high-value subsets from low-tier web data. These subsets outperform unfiltered baselines by 12.1-22.3% on reasoning and 9.5-19.5% on coding, and even surpass unfiltered top-tier data on several benchmarks.
Significance. If the central claims hold after addressing validation and selection issues, the work would show that substantial latent value remains in deprioritized web corpora and that taxonomy-guided filtering offers a compute-efficient way to unlock it, with direct implications for scaling laws and data curation efficiency in pretraining.
major comments (3)
- [Abstract and annotation description] Annotation pipeline (14M documents labeled by Qwen2.5-32B for timeliness and cultural specificity): no human validation, inter-model agreement, or error analysis is reported for these novel dimensions, which are treated as ground truth when training the 0.5B distiller and 73M MLP; this directly undermines the reliability of all downstream filter performance claims.
- [Two-pass framework description] Two-pass filter selection framework: Pass 1 identifies strong signals and Pass 2 evaluates conjunctive/disjunctive compounds at small scale, but both passes measure performance on the same reasoning/coding/knowledge benchmark families later used to report the 22.3%/19.5% gains, creating a selection bias that the two-pass design only partially mitigates.
- [Results and claims on benchmark improvements] Experimental results (mid-tier and two-tier-below claims): no error bars, ablation studies on filter thresholds or model distillation accuracy, or full protocol details are provided, making it impossible to assess whether the reported outperformance over top-tier data is robust.
minor comments (1)
- [Abstract] The abstract states 'low pairwise NMI with existing ones' for the new dimensions but does not quantify the NMI values or reference the exact existing taxonomy dimensions used for comparison.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback, which highlights important aspects of validation, experimental design, and robustness. We address each major comment below, indicating planned revisions where appropriate to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract and annotation description] Annotation pipeline (14M documents labeled by Qwen2.5-32B for timeliness and cultural specificity): no human validation, inter-model agreement, or error analysis is reported for these novel dimensions, which are treated as ground truth when training the 0.5B distiller and 73M MLP; this directly undermines the reliability of all downstream filter performance claims.
Authors: We agree that reporting human validation, inter-model agreement, and error analysis for the novel timeliness and cultural specificity dimensions would improve confidence in the annotations. These dimensions were derived from the ESSENTIAL-WEB taxonomy with low NMI to existing ones, and Qwen2.5-32B annotations served as the basis for distillation due to scale. In revision, we will add inter-model agreement results (comparing Qwen2.5-32B to a second model on a held-out subset) and a small-scale human evaluation study (e.g., 500 documents) with agreement metrics. Full human validation on 14M documents is not feasible, but the added analysis will directly address reliability concerns for the downstream claims. revision: yes
-
Referee: [Two-pass framework description] Two-pass filter selection framework: Pass 1 identifies strong signals and Pass 2 evaluates conjunctive/disjunctive compounds at small scale, but both passes measure performance on the same reasoning/coding/knowledge benchmark families later used to report the 22.3%/19.5% gains, creating a selection bias that the two-pass design only partially mitigates.
Authors: The two-pass framework was developed to manage the combinatorial cost of filter configurations by first identifying strong single-dimension signals at small scale (Pass 1) and then testing compounds (Pass 2), before full-corpus application. We acknowledge that reusing the same benchmark families for selection introduces a risk of optimistic bias in the reported gains. The small-scale design partially mitigates compute-driven overfitting but does not eliminate benchmark-specific selection effects. In the revision, we will explicitly discuss this limitation in the methods and results sections, including its potential impact, and note that final performance is measured on the full held-out corpus application. revision: partial
-
Referee: [Results and claims on benchmark improvements] Experimental results (mid-tier and two-tier-below claims): no error bars, ablation studies on filter thresholds or model distillation accuracy, or full protocol details are provided, making it impossible to assess whether the reported outperformance over top-tier data is robust.
Authors: We agree that the current presentation lacks error bars, ablations, and sufficient protocol details, which limits assessment of robustness for the outperformance claims (e.g., 12.1-22.3% gains). In the revised manuscript, we will add error bars to all benchmark tables (from multiple random seeds or subsamples), include ablation studies varying filter thresholds and reporting distillation accuracy metrics for the 0.5B and 73M models, and expand the experimental setup section with complete protocol details including data splits, training hyperparameters, and evaluation procedures to support reproducibility and robustness evaluation. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper's central claims rest on empirical results from applying taxonomy-based filters (new timeliness and cultural specificity dimensions annotated via Qwen2.5-32B, distilled to smaller models, then selected via two-pass combinatorial search) to web data and measuring downstream benchmark gains. No step reduces by construction to its own inputs: filter selection uses benchmark performance but does not equate the reported improvements to the selection process itself; the taxonomy extension is additive rather than self-referential; no equations or derivations collapse to tautologies; and no load-bearing self-citation chain is invoked to justify uniqueness or force the outcome. The derivation chain remains self-contained against external benchmarks and model outputs.
Axiom & Free-Parameter Ledger
free parameters (1)
- filter thresholds and conjunction/disjunction choices
axioms (1)
- domain assumption Qwen2.5 32B annotations constitute reliable ground truth for timeliness and cultural specificity
Reference graph
Works this paper leans on
-
[1]
Essential AI. Essential-web: A twelve-dimensional taxonomy for curating high-quality web data at scale.arXiv preprint arXiv:2506.14111, 2025
-
[2]
Program Synthesis with Large Language Models
Jacob Austin, Augustus Odena, Maxwell Nye, Maarten Bosma, Henryk Michalewski, David Dohan, Ellen Jiang, Carrie Cai, Michael Terry, Quoc Le, and Charles Sutton. Program synthesis with large language models.arXiv preprint arXiv:2108.07732, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[3]
Pythia: A suite for analyzing large language models across training and scaling
Stella Biderman, Hailey Schoelkopf, Quentin Gregory Anthony, Herbie Bradley, Kyle O’Brien, Eric Hallahan, Mohammad Aflah Khan, Shivanshu Purohit, USVSN Sai Prashanth, Edward Raff, et al. Pythia: A suite for analyzing large language models across training and scaling. In International conference on machine learning, pages 2397–2430. PMLR, 2023
2023
-
[4]
Evaluating Large Language Models Trained on Code
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, et al. Evaluating large language models trained on code.arXiv preprint arXiv:2107.03374, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[5]
Training Verifiers to Solve Math Word Problems
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. Training verifiers to solve math word problems.arXiv preprint arXiv:2110.14168, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[6]
Measuring massive multitask language understanding.Proceedings of the International Conference on Learning Representations, 2021
Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. Measuring massive multitask language understanding.Proceedings of the International Conference on Learning Representations, 2021
2021
-
[7]
Training compute-optimal large language models.Advances in Neural Information Processing Systems, 35, 2022
Jordan Hoffmann, Sebastian Borgeaud, Arthur Mensch, Elena Buchatskaya, Trevor Cai, Eliza Rutherford, Diego de Las Casas, Lisa Anne Hendricks, Johannes Welbl, Aidan Clark, et al. Training compute-optimal large language models.Advances in Neural Information Processing Systems, 35, 2022
2022
-
[8]
Mind the gap: assessing temporal generalization in neural language models
Angeliki Lazaridou, Adhiguna Kuncoro, Elena Gribovskaya, Devang Agrawal, Adam Liška, Tayfun Terzi, Mai Gimenez, Cyprien de Masson d’Autume, Tomas Kocisky, Sebastian Ruder, Dani Yogatama, Kris Cao, Susannah Young, and Phil Blunsom. Mind the gap: assessing temporal generalization in neural language models. InProceedings of the 35th International Conference ...
2021
-
[9]
Solving quantitative reasoning problems with language models.Advances in Neural Information Processing Systems, 35, 2022
Aitor Lewkowycz, Anders Andreassen, David Dohan, Ethan Dyer, Henryk Michalewski, Vinay Ramasesh, Ambrose Slone, Cem Anil, Imanol Schlag, Theo Gutman-Solo, et al. Solving quantitative reasoning problems with language models.Advances in Neural Information Processing Systems, 35, 2022
2022
-
[10]
DataComp-LM: In search of the next generation of training sets for language models.Advances in Neural Information Processing Systems, 37, 2024
Jeffrey Li, Alex Fang, Georgios Smyrnis, Maor Ivgi, Matt Jordan, Samir Yitzhak Gadre, Hritik Bansal, Etash Guha, Sedrick Keh, Luke Arber, et al. DataComp-LM: In search of the next generation of training sets for language models.Advances in Neural Information Processing Systems, 37, 2024
2024
-
[11]
The FineWeb Datasets: Decanting the Web for the Finest Text Data at Scale
Anton Lozhkov, Loubna Ben Allal, Leandro von Werra, and Thomas Wolf. Fineweb-edu: Filtering for high-quality educational web content.arXiv preprint arXiv:2406.17557, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[12]
Aboutme: Using self-descriptions in webpages to document the effects of english pretraining data filters
Li Lucy, Suchin Gururangan, Luca Soldaini, Emma Strubell, David Bamman, Lauren Klein, and Jesse Dodge. Aboutme: Using self-descriptions in webpages to document the effects of english pretraining data filters. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 7393–7420, 2024
2024
-
[13]
Jupinder Parmar, Rajarshi Puri, Niklas Muennighoff, Joseph Jennings, and Oleksii Kuchaiev. NemotronCC: Creating high-quality synthetic data for common crawl.arXiv preprint arXiv:2412.02595, 2024
-
[14]
FineWeb: Decanting the web for the finest text data at scale.Advances in Neural Information Processing Systems, 37, 2024
Guilherme Penedo, Hynek Kydlíˇcek, Anton Lozhkov, Margaret Mitchell, Thomas Wolf, and Lewis Tunstall. FineWeb: Decanting the web for the finest text data at scale.Advances in Neural Information Processing Systems, 37, 2024
2024
-
[15]
Multilingual E5 Text Embeddings: A Technical Report
Liang Wang, Nan Yang, Xiaolong Huang, Linjun Yang, Rangan Majumder, and Furu Wei. Multilingual E5 text embeddings: A technical report.arXiv preprint arXiv:2402.05672, 2024. 11 Appendix A Taxonomy Dimensions Table 1 shows the essential web taxonomy dimensions and Table 2 shows the scale definitions for the two novel taxonomy dimensions introduced in this w...
work page internal anchor Pith review Pith/arXiv arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.