Robust-U1: Can MLLMs Self-Recover Corrupted Visual Content for Robust Understanding?
Pith reviewed 2026-06-27 20:04 UTC · model grok-4.3
The pith
MLLMs can self-recover corrupted visual content to achieve robust understanding.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
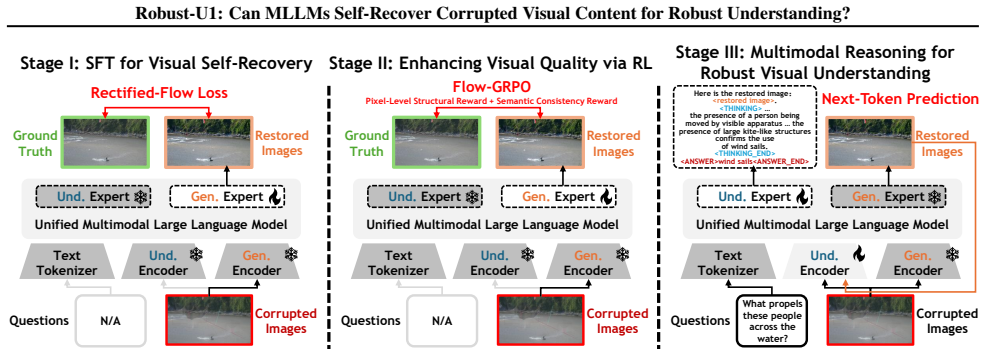
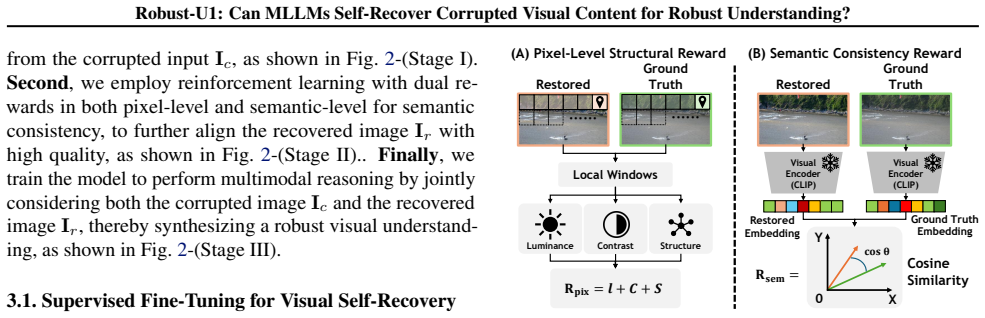
Robust-U1 equips MLLMs with explicit visual self-recovery through supervised fine-tuning for initial reconstruction, reinforcement learning with dual rewards of SSIM and CLIP similarity for high visual quality, and multimodal reasoning that jointly considers the corrupted input and the recovered image; experiments confirm that high-quality visual recovery directly enhances reasoning performance.
What carries the argument
Robust-U1 framework with supervised fine-tuning for reconstruction, dual-reward reinforcement learning using SSIM and CLIP, and multimodal reasoning over both corrupted and recovered images.
If this is right
- State-of-the-art robustness on the real-world corruption benchmark.
- Superior performance under adversarial corruptions on general VQA benchmarks.
- High-quality visual recovery directly enhances reasoning performance.
- Self-recovery functions as a critical mechanism for robust visual understanding.
Where Pith is reading between the lines
- If the recovery step generalizes beyond the tested corruptions, models could handle novel degradations without additional fine-tuning.
- Joint use of corrupted and recovered images may let models learn to identify and compensate for specific damage patterns.
- The approach could extend to other input modalities such as video frames or audio signals that suffer analogous degradations.
Load-bearing premise
The dual-reward reinforcement learning stage produces image recoveries that genuinely improve downstream reasoning rather than merely optimizing the chosen SSIM and CLIP metrics.
What would settle it
An ablation showing that models given only the original corrupted images achieve the same or higher accuracy on the corruption and VQA benchmarks as models given the recovered images.
Figures


read the original abstract
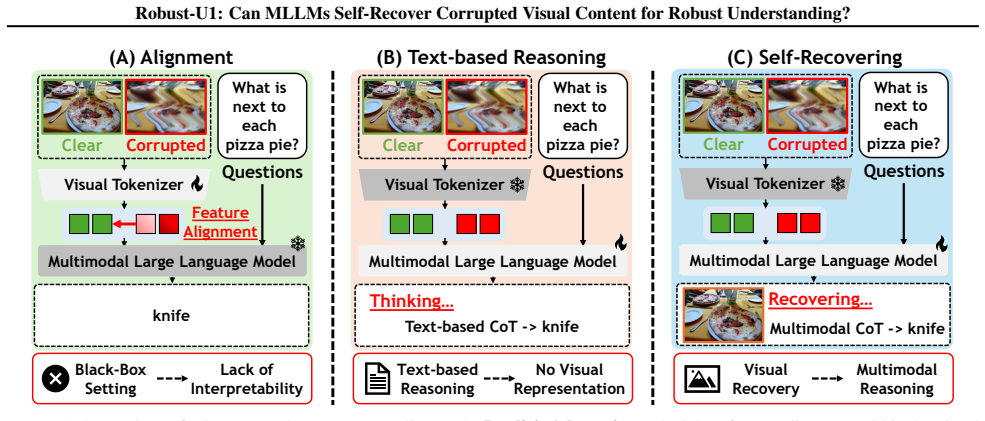
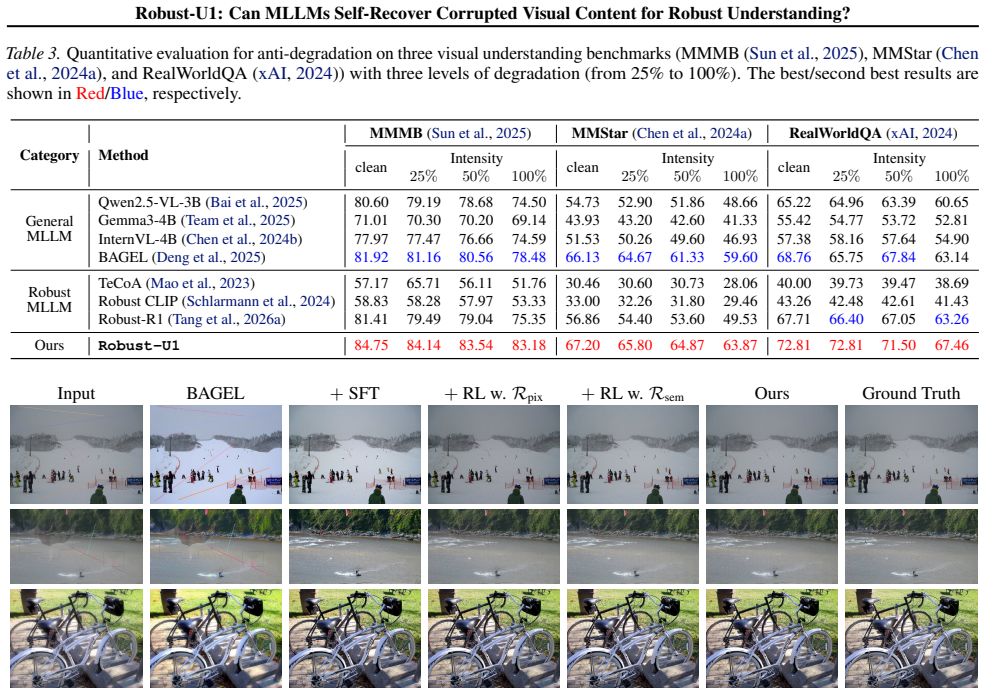
Multimodal Large Language Models (MLLMs) have demonstrated remarkable success in visual understanding, yet their performance degrades significantly under real-world visual corruptions. While existing robustness enhancement approaches exist, they are limited: black-box feature alignment lacks interpretability, and white-box text-based reasoning cannot restore lost pixel-level details. This work investigates a fundamental research question: Can MLLMs recover corrupted visual content by themselves? To address this, we propose Robust-U1, a novel framework that equips MLLMs with explicit visual self-recovery capability for robust understanding. The approach comprises three core stages: supervised fine-tuning for initial reconstruction, reinforcement learning with dual rewards (pixel-level SSIM and semantic-level CLIP similarity) for aligning high visual quality, and multimodal reasoning that jointly considers both the corrupted input and the recovered image. Extensive experiments demonstrate that Robust-U1 achieves state-of-the-art robustness on the real-world corruption benchmark and maintains superior performance under adversarial corruptions on general VQA benchmarks. Analysis confirms that high-quality visual recovery directly enhances reasoning performance, establishing self-recovery as a critical mechanism for robust visual understanding. The source code is available at https://github.com/jqtangust/Robust-U1.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Robust-U1, a three-stage framework equipping MLLMs with self-recovery capability for corrupted images: supervised fine-tuning for initial reconstruction, reinforcement learning using dual rewards (pixel-level SSIM and semantic-level CLIP similarity), and multimodal reasoning that jointly processes the corrupted input and recovered image. It claims this yields state-of-the-art robustness on real-world corruption benchmarks and superior performance under adversarial corruptions on VQA tasks, with analysis showing that high-quality visual recovery directly enhances reasoning.
Significance. If validated, the result would establish an interpretable pixel- and semantic-level self-recovery mechanism as a critical component for MLLM robustness, going beyond black-box feature alignment or text-only reasoning; the public source code link supports reproducibility.
major comments (2)
- [Abstract / multimodal reasoning stage] The multimodal reasoning stage jointly feeds both corrupted and recovered images, yet no ablation is described (e.g., substituting RL output with original corruption, a constant image, or SFT-only output) to isolate whether reported reasoning gains are causally driven by the RL-recovered content rather than the joint prompt format or prior stages; this directly affects the central claim that recovery enhances reasoning.
- [Reinforcement learning stage] No quantitative details are given on the relative weighting between SSIM and CLIP rewards in the RL stage, nor on ablation controls or error bars for the SOTA results; this leaves the internal validity of the experimental outcomes unverifiable from the reported high-level outcomes.
minor comments (1)
- The abstract states that source code is available; ensure the repository includes exact hyperparameter values for the dual-reward weighting and the full set of benchmark numbers with error bars.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and positive evaluation of the work's potential significance. We address each major comment below with plans for targeted revisions to improve clarity and experimental rigor.
read point-by-point responses
-
Referee: [Abstract / multimodal reasoning stage] The multimodal reasoning stage jointly feeds both corrupted and recovered images, yet no ablation is described (e.g., substituting RL output with original corruption, a constant image, or SFT-only output) to isolate whether reported reasoning gains are causally driven by the RL-recovered content rather than the joint prompt format or prior stages; this directly affects the central claim that recovery enhances reasoning.
Authors: We agree that the absence of these ablations limits the strength of the causal claim. In the revised version we will add a dedicated ablation subsection reporting performance when the RL-recovered image is replaced by (i) the original corrupted input, (ii) a constant image, and (iii) the SFT-stage output only, while keeping the joint-prompt format fixed. These results will directly quantify the incremental benefit attributable to the RL-recovered content. revision: yes
-
Referee: [Reinforcement learning stage] No quantitative details are given on the relative weighting between SSIM and CLIP rewards in the RL stage, nor on ablation controls or error bars for the SOTA results; this leaves the internal validity of the experimental outcomes unverifiable from the reported high-level outcomes.
Authors: We will insert the exact weighting coefficient (λ) used to combine the SSIM and CLIP terms in the composite reward, together with an ablation table that isolates each reward component. For the main SOTA tables we will also report standard deviations computed over three independent training seeds. These additions will be placed in the experimental section and appendix. revision: yes
Circularity Check
No circularity; empirical method with external benchmarks
full rationale
The paper presents an empirical three-stage framework (SFT for reconstruction, RL with SSIM+CLIP dual rewards, joint multimodal reasoning on corrupted+recovered inputs) whose claims rest on experimental results against standard external benchmarks and metrics. No derivation chain, equations, or self-referential definitions reduce any result to inputs by construction. No self-citation load-bearing steps, uniqueness theorems, or ansatzes appear; the central claim that recovery enhances reasoning is presented as an experimental observation rather than a forced consequence of fitted parameters or prior author work. The work is self-contained against independent evaluation.
Axiom & Free-Parameter Ledger
free parameters (1)
- relative weighting of SSIM and CLIP rewards
Reference graph
Works this paper leans on
-
[1]
Are we on the right way for evaluating large vision-language models? InNeurIPS, 2024a
Chen, L., Li, J., Dong, X., Zhang, P., Zang, Y ., Chen, Z., Duan, H., Wang, J., Qiao, Y ., Lin, D., et al. Are we on the right way for evaluating large vision-language models? InNeurIPS, 2024a. Chen, Z., Wu, J., Wang, W., Su, W., Chen, G., Xing, S., Zhong, M., Zhang, Q., Zhu, X., Lu, L., et al. Internvl: Scaling up vision foundation models and aligning fo...
-
[2]
Emerg- ing properties in unified multimodal pretraining.arXiv preprint arXiv:2505.14683,
Deng, C., Zhu, D., Li, K., Gou, C., Li, F., Wang, Z., Zhong, S., Yu, W., Nie, X., Song, Z., Shi, G., and Fan, H. Emerg- ing properties in unified multimodal pretraining.arXiv preprint arXiv:2505.14683,
-
[3]
Hu, C., Chen, X., Jia, Z., Shi, W., Zhang, F., Guo, J., and Wei, Y . A semantic decoupling-based two-stage rainy-day attack for revealing weather robustness de- ficiencies in vision-language models.arXiv preprint arXiv:2601.13238,
-
[4]
Liu, J., Jia, Z., Li, J., Li, B., Jin, X., Zeng, W., and Lu, Y . When mllms meet compression distortion: A coding paradigm tailored to mllms.arXiv preprint arXiv:2509.24258, 2025a. Liu, J., Liu, G., Liang, J., Li, Y ., Liu, J., Wang, X., Wan, P., Zhang, D., and Ouyang, W. Flow-grpo: Training flow matching models via online rl.arXiv preprint arXiv:2505.054...
-
[5]
Qwen3 technical report.arXiv preprint arXiv:2505.09388,
Qwen Team. Qwen3 technical report.arXiv preprint arXiv:2505.09388,
-
[6]
Zheng, Z., Yang, M., Hong, J., Zhao, C., Xu, G., Yang, L., Shen, C., and Yu, X. Deepeyes: Incentivizing" thinking with images" via reinforcement learning.arXiv preprint arXiv:2505.14362,
-
[7]
11 Robust-U1: Can MLLMs Self-Recover Corrupted Visual Content for Robust Understanding? Summary of Appendix This appendix is organized into eight sections, ordered from implementation details to broader discussion: • Appendix A – Implementation Details.Per-stage training cost (GPU type, time, memory, trainable parameters) and evaluation protocols on R-Ben...
2025
-
[8]
(750k pairs)Generation onlyStage II (RL) 8 ∼20 h 160 41 GBRobust-R1 (Tang et al., 2026a) training splitGeneration onlyStage III (Reasoning)8 ∼8 h 64 43 GBRobust-R1 (Tang et al., 2026a) reasoning dataUnderstanding+Generation A.2. Evaluation Protocol on R-Bench To rigorously assess the performance of our model on R-Bench (Li et al., 2024), we implement dive...
2024
-
[9]
The aggregate performance is represented by the mean score: Score= 1 N NX i=1 si,(12) where si denotes the scoring result assigned by GPT-3.5-turbo for the i-th sample
as a proxy evaluator to quantify the semantic alignment between model-generated responses and reference answers. The aggregate performance is represented by the mean score: Score= 1 N NX i=1 si,(12) where si denotes the scoring result assigned by GPT-3.5-turbo for the i-th sample. The evaluation framework focuses on three critical dimensions: • Completene...
2025
-
[10]
restoration → understanding
is utilized to parse the model’s output and identify the intended choice label (e.g., A, B, C, D), which is then compared against the ground-truth label to determine the final accuracy. B. Extended Quantitative Comparisons This section reports two extended comparisons that situate Robust-U1 against alternative pipelines: (i) using state-of-the- art extern...
2025
-
[11]
0.7398 for Robust-U1
As reported in Table 8, all external-restoration variants underperform Robust-U1 by a large margin in overall score, with the best baseline (all-in-one (Tian et al., 2025)) reaching only 0.5511 vs. 0.7398 for Robust-U1. Two factors explain this gap. First, specialized modules (deblurring, denoising, dehazing) require knowing the degradation type and tend ...
2025
-
[12]
Rec. Mem
0.6765 0.6584 0.5671 0.4466 0.3782 0.3371 0.6938 0.5914 0.4845 0.5371 Robust-U1(Ours) 0.7353 0.7329 0.6768 0.7067 0.7164 0.6934 0.8272 0.8059 0.7640 0.7398 B.2. Inference Cost and the Detect-then-Recover Variant We extend the computation-cost analysis in Section 4.3 to inference. We compare three deployment modes on R-Bench using Qwen2.5-VL-7B-class hardw...
2024
-
[13]
as the frozen encoder. To verify that our conclusions are not tied to this specific encoder, we replace TinyCLIP with three alternatives of different scales and architectures: CLIP-B/16 (Radford et al., 2021), SigLIP-B/16 (Zhai et al., 2023), and a heavily distilled, weaker CLIP (Radford et al.,
2021
-
[14]
Table 18.Sensitivity ofRobust-U1’s scores on R-Bench to the choice of LLM-based evaluator
and GPT-4o (Hurst et al., 2024). Table 18.Sensitivity ofRobust-U1’s scores on R-Bench to the choice of LLM-based evaluator. Evaluator MCQ VQA CAP Overall low mid high low mid high low mid high GPT-3.5-turbo (default) 0.7353 0.7329 0.6768 0.7067 0.7164 0.6934 0.8272 0.8069 0.7640 0.7398 Qwen3-Max (Qwen Team,
2024
-
[15]
Limitations and Future Work H.1
5.6% 2.1% 10.1% 4.2%Robust-U1(Ours) 92.3% 85.7% H. Limitations and Future Work H.1. Limitations While Robust-U1 demonstrates promising results in enhancing the robustness of Multimodal Large Language Models through visual self-recovery, our work has several limitations that warrant discussion and motivate the future directions discussed in Section H.2. Re...
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.