Continual Quadruped Robots Coordination via Semantic Skill Discovery
Pith reviewed 2026-06-27 19:36 UTC · model grok-4.3
The pith
Conquer lets multi-quadruped teams learn new coordination tasks sequentially by retrieving and updating skills organized by semantic similarity.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
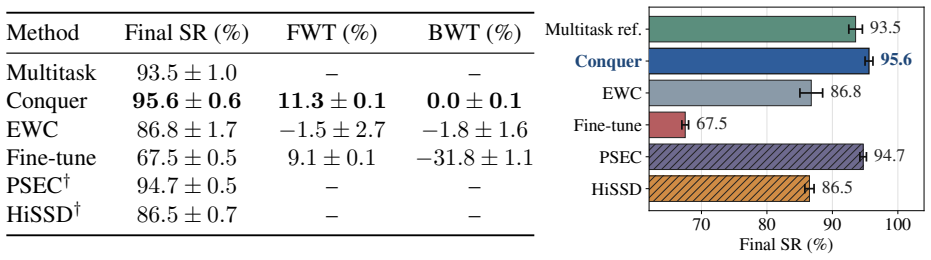
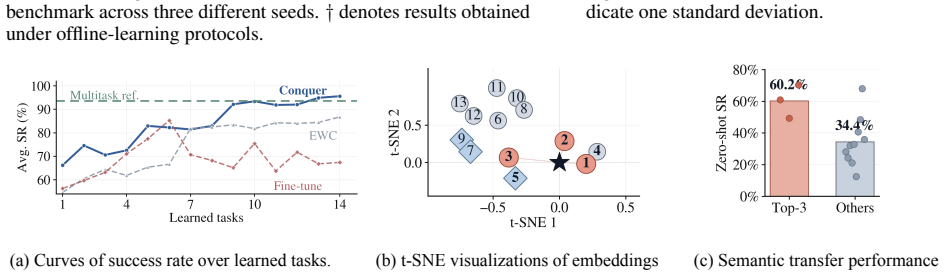
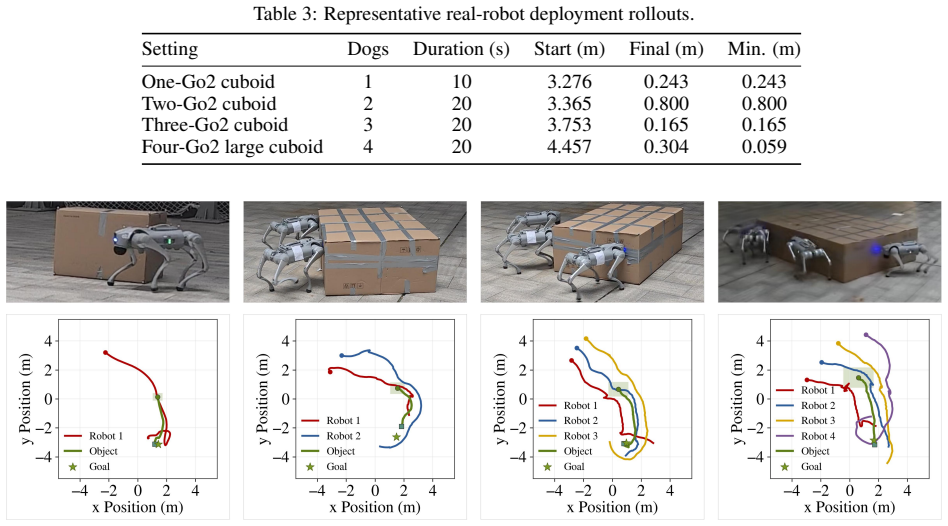
Conquer formulates continual multi-quadruped coordination as a retrieve-adapt-update process. It builds task-level semantic descriptors from pre-execution information to retrieve relevant skills for adaptation, then extracts trajectory-level semantic descriptors after execution and organizes them by semantic distance to update the library. This enables continual skill accumulation and cross-task transfer. The approach uses a Self-Allies-Goal backbone that explicitly models each robot's own state, teammate context, and task goal to handle variable team sizes. Simulation experiments reach a final average success rate of 95.6 percent with strong forward transfer and negligible catastrophic forg
What carries the argument
The retrieve-adapt-update cycle driven by task-level and trajectory-level semantic descriptors that measure semantic distance to organize skills, supported by the team-structured Self-Allies-Goal backbone for variable-cardinality robot teams.
If this is right
- Robot teams can acquire coordination skills for sequentially arriving tasks while reusing earlier ones.
- Coordination works across teams whose size changes between tasks without starting from scratch.
- Semantic distance organization produces measurable cross-task knowledge transfer.
- The same library supports both simulated training and physical deployment on real quadruped platforms.
Where Pith is reading between the lines
- The same retrieve-adapt-update structure could be tested on coordination tasks involving mixed robot types rather than only quadrupeds.
- Semantic organization might allow libraries to grow larger before retrieval costs become prohibitive.
- Pairing the skill descriptors with online adaptation methods could further reduce the number of real-world trials needed for new tasks.
Load-bearing premise
Semantic descriptors taken from pre-execution information and trajectories can reliably measure distances between skills to allow accurate retrieval and organization without overlap or loss of distinct capabilities.
What would settle it
A sequence of new tasks in which the average success rate falls well below 95 percent or performance on previously mastered tasks degrades noticeably would show that the semantic organization fails to support transfer or prevent forgetting.
Figures



read the original abstract
Multi-quadruped coordination has attracted increasing attention due to its enhanced payload capacity, broader contact coverage, and improved adaptability to challenging tasks. Existing methods for multi-quadruped manipulation typically focus on predefined or closed task families, often relying on multi-agent reinforcement learning (MARL) to train task-specific coordination policies. However, such methods struggle in open-ended continual learning settings, where tasks arrive sequentially and robots are expected to acquire new coordination skills while reusing previously learned ones without catastrophic forgetting. To address this challenge, we propose Conquer, a semantic skill-library framework that formulates continual multi-quadruped coordination as a retrieve-adapt-update process. First, to accommodate varying team sizes across tasks, we design a team-structured Self-Allies-Goal (SAG) backbone that supports variable-cardinality robot teams by explicitly modeling each robot's own state, teammate context, and task goal. For each incoming task, Conquer constructs a task-level semantic descriptor from pre-execution information and retrieves a relevant skill from the library for adaptation. After successful execution, Conquer updates the skill library by extracting trajectory-level semantic descriptors and organizing them according to semantic distance, thereby enabling continual skill accumulation and cross-task knowledge transfer. Simulation experiments show that Conquer achieves a final average success rate of 95.6%, demonstrating strong forward transfer and negligible catastrophic forgetting. Real-world rollouts on Unitree Go2 teams further validate the deployment feasibility of Conquer for practical multi-quadruped coordination. Simulation and real-robot demonstration videos are available at: https://conquer-project.pages.dev/.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Conquer, a semantic skill-library framework for continual multi-quadruped coordination formulated as a retrieve-adapt-update process. It designs a team-structured Self-Allies-Goal (SAG) backbone to handle variable robot team cardinalities, constructs task-level semantic descriptors from pre-execution information for retrieval, and updates the library using trajectory-level semantic descriptors organized by semantic distance. Simulation experiments report a final average success rate of 95.6% with strong forward transfer and negligible catastrophic forgetting; real-world validation on Unitree Go2 teams is also presented.
Significance. If the central claims hold, the work addresses an important open problem in continual multi-agent robotics by enabling skill accumulation across sequential tasks without forgetting. The SAG backbone's explicit modeling of self-state, teammate context, and goal for variable cardinality is a concrete technical contribution that could transfer to other multi-robot settings.
major comments (2)
- [Method and Experiments] The central claim of negligible catastrophic forgetting and strong forward transfer (abstract and experiments) rests on the assumption that task-level and trajectory-level semantic descriptors reliably compute semantic distance to retrieve and organize skills without overlap or erasure. No independent verification of descriptor quality (e.g., nearest-neighbor accuracy on held-out skill pairs or embedding separability metrics) is provided, leaving the load-bearing mechanism untested.
- [Experiments] The reported 95.6% final success rate and transfer/forgetting results lack comparison to baselines (e.g., standard MARL continual learning methods or non-semantic skill libraries), ablations isolating the contribution of the semantic distance organization, and analysis across different task sequences or team sizes, making it impossible to evaluate whether the observed performance is due to the proposed retrieve-adapt-update loop.
minor comments (2)
- [Abstract] The abstract states high success rates but supplies no experimental details on the number of tasks, task sequence, team cardinalities tested, or error bars; this should be added for clarity.
- [Method] Notation for the SAG backbone components (self, allies, goal) and how semantic distance is formally computed should be defined with equations in the method section for reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which identifies key areas where additional evidence would strengthen the claims regarding semantic descriptors and experimental validation. We address each major comment below and commit to revisions that directly incorporate the suggested analyses.
read point-by-point responses
-
Referee: [Method and Experiments] The central claim of negligible catastrophic forgetting and strong forward transfer (abstract and experiments) rests on the assumption that task-level and trajectory-level semantic descriptors reliably compute semantic distance to retrieve and organize skills without overlap or erasure. No independent verification of descriptor quality (e.g., nearest-neighbor accuracy on held-out skill pairs or embedding separability metrics) is provided, leaving the load-bearing mechanism untested.
Authors: We agree that the manuscript does not provide an independent verification of descriptor quality (e.g., nearest-neighbor accuracy or embedding separability). The reported success rates and transfer metrics offer indirect support, but this leaves the core mechanism insufficiently tested in isolation. In the revised manuscript we will add a dedicated analysis of the task-level and trajectory-level descriptors, including embedding separability metrics and nearest-neighbor evaluation on held-out pairs, to directly substantiate their reliability for semantic-distance computation. revision: yes
-
Referee: [Experiments] The reported 95.6% final success rate and transfer/forgetting results lack comparison to baselines (e.g., standard MARL continual learning methods or non-semantic skill libraries), ablations isolating the contribution of the semantic distance organization, and analysis across different task sequences or team sizes, making it impossible to evaluate whether the observed performance is due to the proposed retrieve-adapt-update loop.
Authors: We acknowledge that the current experiments do not include the requested baselines, ablations, or cross-condition analyses, which limits attribution of the 95.6% success rate and transfer/forgetting results specifically to the retrieve-adapt-update loop. To address this, the revised version will expand the experimental section with comparisons against standard MARL continual-learning baselines and non-semantic skill-library variants, ablations that isolate the semantic-distance organization, and additional results across varied task sequences and team cardinalities. revision: yes
Circularity Check
No circularity: framework description contains no derivations or self-referential reductions
full rationale
The paper presents Conquer as a retrieve-adapt-update process that uses task-level semantic descriptors from pre-execution information, trajectory-level descriptors after execution, and a SAG backbone for variable team cardinality. No equations, parameter fits, or mathematical derivations appear in the abstract or description. The 95.6% success rate is stated as an experimental outcome rather than a prediction derived from the method itself. No self-citations, uniqueness theorems, or ansatzes are invoked in a load-bearing manner. The central claims rest on the empirical performance of the described process rather than reducing to inputs by construction, making the derivation chain self-contained.
Axiom & Free-Parameter Ledger
invented entities (2)
-
Semantic skill library
no independent evidence
-
SAG backbone
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Open-environment machine learning.National Science Review, 9(8):nwac123, 2022
Zhi-Hua Zhou. Open-environment machine learning.National Science Review, 9(8):nwac123, 2022
2022
-
[2]
Lei Yuan, Ziqian Zhang, Lihe Li, Cong Guan, and Yang Yu. A survey of progress on cooperative multi-agent reinforcement learning in open environment.arXiv preprint arXiv:2312.01058, 2023
arXiv 2023
-
[3]
M., Dundesh S
Ashish Majithia, Darshita Shah, Jatin Dave, Ajay Kumar, Sarita Rathee, Namrata Dogra, Vishwanatha H. M., Dundesh S. Chiniwar, and Shivashankarayya Hiremath. Design, motions, capabilities, and applications of quadruped robots: a comprehensive review.Frontiers in Mechanical Engineering, 10, 2024
2024
-
[4]
Elio Tuci, Muhanad H. M. Alkilabi, and Otar Akanyeti. Cooperative object transport in multi-robot systems: A review of the state-of-the-art.Frontiers in Robotics and AI, 5, 2018
2018
-
[5]
Multi-robot formation control and object transport in dy- namic environments via constrained optimization.International Journal of Robotics Research, 36(9):1000–1021, 2017
Javier Alonso-Mora, Stuart Baker, and Daniela Rus. Multi-robot formation control and object transport in dy- namic environments via constrained optimization.International Journal of Robotics Research, 36(9):1000–1021, 2017
2017
-
[6]
Reinforcement learning for collaborative quadrupedal manipula- tion of a payload over challenging terrain
Yandong Ji, Bike Zhang, and Koushil Sreenath. Reinforcement learning for collaborative quadrupedal manipula- tion of a payload over challenging terrain. InInternational Conference on Automation Science and Engineering (CASE), pages 899–904, 2021
2021
-
[7]
Learning multi-agent loco- manipulation for long-horizon quadrupedal pushing
Yuming Feng, Chuye Hong, Yaru Niu, Shiqi Liu, Yuxiang Yang, and Ding Zhao. Learning multi-agent loco- manipulation for long-horizon quadrupedal pushing. InInternational Conference on Robotics and Automation (ICRA), pages 14441–14448, 2025
2025
-
[8]
Hussein Ali Jaafar, Cheng-Hao Kao, and Sajad Saeedi. Mr. cap: Multi-robot joint control and planning for object transport.IEEE Control Systems Letters, 8:139–144, 2024
2024
-
[9]
A survey of continual rein- forcement learning.arXiv preprint arXiv:2506.21872, 2025
Chaofan Pan, Xin Yang, Yanhua Li, Wei Wei, Tianrui Li, Bo An, and Jiye Liang. A survey of continual rein- forcement learning.arXiv preprint arXiv:2506.21872, 2025
Pith/arXiv arXiv 2025
-
[10]
A comprehensive survey of continual learning: Theory, method and application.IEEE Transactions on Pattern Analysis and Machine Intelligence, 46(8):5362–5383, 2024
Liyuan Wang, Xingxing Zhang, Hang Su, and Jun Zhu. A comprehensive survey of continual learning: Theory, method and application.IEEE Transactions on Pattern Analysis and Machine Intelligence, 46(8):5362–5383, 2024
2024
-
[11]
Towards continual reinforcement learning: A review and perspectives.Journal of Artificial Intelligence Research, 75:1401–1476, 2022
Khimya Khetarpal, Matthew Riemer, Irina Rish, and Doina Precup. Towards continual reinforcement learning: A review and perspectives.Journal of Artificial Intelligence Research, 75:1401–1476, 2022
2022
-
[12]
Same state, different task: Continual reinforcement learning without interference
Samuel Kessler, Jack Parker-Holder, Philip Ball, Stefan Zohren, and Stephen J Roberts. Same state, different task: Continual reinforcement learning without interference. InProceedings of the AAAI Conference on Artificial Intelligence, pages 7143–7151, 2022
2022
-
[13]
Disentangling transfer in continual reinforcement learning
Maciej Wolczyk, Michał Zaj ˛ ac, Razvan Pascanu, Łukasz Kuci´nski, and Piotr Miło´s. Disentangling transfer in continual reinforcement learning. InAdvances in Neural Information Processing Systems, volume 35, pages 6304–6317, 2022
2022
-
[14]
Experience replay for continual learning
David Rolnick, Arun Ahuja, Jonathan Schwarz, Timothy P Lillicrap, and Greg Wayne. Experience replay for continual learning. InAdvances in Neural Information Processing Systems, pages 350–360, 2019
2019
-
[15]
Feng Chen, Fuguang Han, Cong Guan, Lei Yuan, Zhilong Zhang, Yang Yu, and Zongzhang Zhang. Stable continual reinforcement learning via diffusion-based trajectory replay.arXiv preprint arXiv:2411.10809, 2024
arXiv 2024
-
[16]
Con- tinual diffuser (cod): Mastering continual offline rl with experience rehearsal.IEEE Transactions on Neural Networks and Learning Systems, 2025
Jifeng Hu, Li Shen, Sili Huang, Zhejian Yang, Hechang Chen, Lichao Sun, Yi Chang, and Dacheng Tao. Con- tinual diffuser (cod): Mastering continual offline rl with experience rehearsal.IEEE Transactions on Neural Networks and Learning Systems, 2025
2025
-
[17]
Learning and retrieval from prior data for skill- based imitation learning
Soroush Nasiriany, Tian Gao, Ajay Mandlekar, and Yuke Zhu. Learning and retrieval from prior data for skill- based imitation learning. InConference on Robot Learning, pages 2181–2204, 2023
2023
-
[18]
Lotus: Continual imitation learning for robot manipula- tion through unsupervised skill discovery
Weikang Wan, Yifeng Zhu, Rutav Shah, and Yuke Zhu. Lotus: Continual imitation learning for robot manipula- tion through unsupervised skill discovery. In2024 IEEE International Conference on Robotics and Automation (ICRA), pages 537–544, 2024
2024
-
[19]
Srsa: Skill retrieval and adaptation for robotic assembly tasks
Yijie Guo, Bingjie Tang, Iretiayo Akinola, Dieter Fox, Abhishek Gupta, and Yashraj Narang. Srsa: Skill retrieval and adaptation for robotic assembly tasks. InInternational Conference on Learning Representations, 2025
2025
-
[20]
Cliport: What and where pathways for robotic manipulation
Mohit Shridhar, Lucas Manuelli, and Dieter Fox. Cliport: What and where pathways for robotic manipulation. InConference on Robot Learning, pages 894–906, 2022
2022
-
[21]
Do as i can, not as i say: Grounding language in robotic affordances
Anthony Brohan, Yevgen Chebotar, Chelsea Finn, Karol Hausman, Alexander Herzog, Daniel Ho, Julian Ibarz, Alex Irpan, Eric Jang, Ryan Julian, et al. Do as i can, not as i say: Grounding language in robotic affordances. InConference on Robot Learning, pages 287–318, 2023
2023
-
[22]
Language guided skill discovery
Seungeun Rho, Laura Smith, Tianyu Li, Sergey Levine, Xue Bin Peng, and Sehoon Ha. Language guided skill discovery. InInternational Conference on Learning Representations, volume 2025, pages 87731–87752, 2025
2025
-
[23]
The surprising effectiveness of ppo in cooperative multi-agent games.Advances in Neural Information Processing Systems, 35: 24611–24624, 2022
Chao Yu, Akash Velu, Eugene Vinitsky, Jiaxuan Gao, Yu Wang, Alexandre Bayen, and Yi Wu. The surprising effectiveness of ppo in cooperative multi-agent games.Advances in Neural Information Processing Systems, 35: 24611–24624, 2022
2022
-
[24]
Action semantics network: Considering the effects of actions in multiagent systems
Weixun Wang, Tianpei Yang, Yong Liu, Jianye Hao, Xiaotian Hao, Yujing Hu, Yingfeng Chen, Changjie Fan, and Yang Gao. Action semantics network: Considering the effects of actions in multiagent systems. InInternational Conference on Learning Representations, 2020
2020
-
[25]
Updet: Universal multi-agent rl via policy decoupling with transformers
Siyi Hu, Fengda Zhu, Xiaojun Chang, and Xiaodan Liang. Updet: Universal multi-agent rl via policy decoupling with transformers. InInternational Conference on Learning Representations, 2021
2021
-
[26]
Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen
Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. Lora: Low-rank adaptation of large language models. InInternational Conference on Learning Represen- tations, 2022
2022
-
[27]
Carlson, Ji Yuan Feng, Animesh Garg, Renato Gasoto, Lionel Gulich, Yijie Guo, M
Mayank Mittal, Pascal Roth, James Tigue, Antoine Richard, Octi Zhang, Peter Du, Antonio Serrano-Muñoz, Xinjie Yao, René Zurbrügg, Nikita Rudin, Lukasz Wawrzyniak, Milad Rakhsha, Alain Denzler, Eric Heiden, Ales Borovicka, Ossama Ahmed, Iretiayo Akinola, Abrar Anwar, Mark T. Carlson, Ji Yuan Feng, Animesh Garg, Renato Gasoto, Lionel Gulich, Yijie Guo, M. G...
Pith/arXiv arXiv 2025
-
[28]
Multi-agent embodied ai: Advances and future directions.Science China Information Sciences, 69(5):151202, 2026
Zhaohan Feng, Ruiqi Xue, Lei Yuan, Yang Yu, Ning Ding, Meiqin Liu, Bingzhao Gao, Jian Sun, Xinhu Zheng, and Gang Wang. Multi-agent embodied ai: Advances and future directions.Science China Information Sciences, 69(5):151202, 2026
2026
-
[29]
Peter Sunehag, Guy Lever, Audrunas Gruslys, Wojciech Marian Czarnecki, Vinicius Zambaldi, Max Jaderberg, Marc Lanctot, Nicolas Sonnerat, Joel Z Leibo, Karl Tuyls, et al. Value-decomposition networks for cooperative multi-agent learning.arXiv preprint arXiv:1706.05296, 2017
Pith/arXiv arXiv 2017
-
[30]
Monotonic value function factorisation for deep multi-agent reinforcement learning.Journal of Machine Learning Research, 21(178):1–51, 2020
Tabish Rashid, Mikayel Samvelyan, Christian Schroeder De Witt, Gregory Farquhar, Jakob Foerster, and Shimon Whiteson. Monotonic value function factorisation for deep multi-agent reinforcement learning.Journal of Machine Learning Research, 21(178):1–51, 2020
2020
-
[31]
Multi-agent actor-critic for mixed cooperative-competitive environments
Ryan Lowe, Yi Wu, Aviv Tamar, Jean Harb, Pieter Abbeel, and Igor Mordatch. Multi-agent actor-critic for mixed cooperative-competitive environments. InAdvances in Neural Information Processing Systems, pages 6382–6393, 2017
2017
-
[32]
Counterfactual multi-agent policy gradients
Jakob Foerster, Gregory Farquhar, Triantafyllos Afouras, Nantas Nardelli, and Shimon Whiteson. Counterfactual multi-agent policy gradients. InProceedings of the AAAI conference on artificial intelligence, volume 32, 2018
2018
-
[33]
Mitigating plasticity loss in continual reinforcement learning by reducing churn
Hongyao Tang, Johan Obando-Ceron, Pablo Samuel Castro, Aaron Courville, and Glen Berseth. Mitigating plasticity loss in continual reinforcement learning by reducing churn. InInternational Conference on Machine Learning, pages 58883–58904, 2025
2025
-
[34]
Loss of plasticity in continual deep reinforcement learning
Zaheer Abbas, Rosie Zhao, Joseph Modayil, Adam White, and Marlos C Machado. Loss of plasticity in continual deep reinforcement learning. InConference on Lifelong Learning Agents, pages 620–636, 2023
2023
-
[35]
Overcoming catastrophic forgetting in neural networks.Proceedings of the national academy of sciences, 114(13):3521–3526, 2017
James Kirkpatrick, Razvan Pascanu, Neil Rabinowitz, Joel Veness, Guillaume Desjardins, Andrei A Rusu, Kieran Milan, John Quan, Tiago Ramalho, Agnieszka Grabska-Barwinska, et al. Overcoming catastrophic forgetting in neural networks.Proceedings of the national academy of sciences, 114(13):3521–3526, 2017
2017
-
[36]
Memory aware synapses: Learning what (not) to forget
Rahaf Aljundi, Francesca Babiloni, Mohamed Elhoseiny, Marcus Rohrbach, and Tinne Tuytelaars. Memory aware synapses: Learning what (not) to forget. InProceedings of the European Conference on Computer Vision, pages 139–154, 2018
2018
-
[37]
Gradient episodic memory for continual learning
David Lopez-Paz and Marc’Aurelio Ranzato. Gradient episodic memory for continual learning. InAdvances in Neural Information Processing Systems, pages 6470–6479, 2017
2017
-
[38]
Continual learning with scaled gradient projection
Gobinda Saha and Kaushik Roy. Continual learning with scaled gradient projection. InProceedings of the AAAI conference on artificial intelligence, volume 37, pages 9677–9685, 2023
2023
-
[39]
Continual world: A robotic benchmark for continual reinforcement learning
Maciej Wołczyk, Michał Zaj ˛ ac, Razvan Pascanu, Łukasz Kuci´nski, and Piotr Miło´s. Continual world: A robotic benchmark for continual reinforcement learning. InAdvances in Neural Information Processing Systems, pages 28496–28510, 2021
2021
-
[40]
Multiagent continual coordination via progressive task contextualization.IEEE Transactions on Neural Networks and Learning Systems, 36(4): 6326–6340, 2024
Lei Yuan, Lihe Li, Ziqian Zhang, Fuxiang Zhang, Cong Guan, and Yang Yu. Multiagent continual coordination via progressive task contextualization.IEEE Transactions on Neural Networks and Learning Systems, 36(4): 6326–6340, 2024
2024
-
[41]
Learn- ing to coordinate with anyone
Lei Yuan, Lihe Li, Ziqian Zhang, Feng Chen, Tianyi Zhang, Cong Guan, Yang Yu, and Zhi-Hua Zhou. Learn- ing to coordinate with anyone. InProceedings of the Fifth International Conference on Distributed Artificial Intelligence, pages 1–9, 2023
2023
-
[42]
Learning options in reinforcement learning
Martin Stolle and Doina Precup. Learning options in reinforcement learning. InInternational Symposium on abstraction, reformulation, and approximation, pages 212–223, 2002
2002
-
[43]
Diversity is all you need: Learning skills without a reward function
Benjamin Eysenbach, Abhishek Gupta, Julian Ibarz, and Sergey Levine. Diversity is all you need: Learning skills without a reward function. InInternational Conference on Learning Representations, 2018
2018
-
[44]
Dynamics-aware unsupervised discovery of skills
Archit Sharma, Shixiang Gu, Sergey Levine, Vikash Kumar, and Karol Hausman. Dynamics-aware unsupervised discovery of skills. InInternational Conference on Learning Representations, 2020
2020
-
[45]
Discovering gener- alizable multi-agent coordination skills from multi-task offline data
Fuxiang Zhang, Chengxing Jia, Yi-Chen Li, Lei Yuan, Yang Yu, and Zongzhang Zhang. Discovering gener- alizable multi-agent coordination skills from multi-task offline data. InInternational Conference on Learning Representations, 2023
2023
-
[46]
Learning generalizable skills from offline multi-task data for multi-agent cooperation
Sicong Liu, Yang Shu, Chenjuan Guo, and Bin Yang. Learning generalizable skills from offline multi-task data for multi-agent cooperation. InInternational Conference on Learning Representations, 2025
2025
-
[47]
Life- long language-conditioned robotic manipulation learning
Xudong Wang, Zebin Han, Zhiyu Liu, Gan Li, Jiahua Dong, Baichen Liu, Lianqing Liu, and Zhi Han. Life- long language-conditioned robotic manipulation learning. InProceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 18629–18637, 2026
2026
-
[48]
Skill expansion and composition in parameter space
Tenglong Liu, Jianxiong Li, Yinan Zheng, Haoyi Niu, Yixing Lan, Xin Xu, and Xianyuan Zhan. Skill expansion and composition in parameter space. InInternational Conference on Learning Representations, volume 2025, pages 85192–85228, 2025
2025
-
[49]
Springer, 2016
Frans A Oliehoek, Christopher Amato, et al.A concise introduction to decentralized POMDPs, volume 1. Springer, 2016
2016
-
[50]
Jordan, and Pieter Abbeel
John Schulman, Philipp Moritz, Sergey Levine, Michael I. Jordan, and Pieter Abbeel. High-dimensional contin- uous control using generalized advantage estimation. InInternational Conference on Learning Representations, 2016
2016
-
[51]
Deep decentralized multi-task multi-agent reinforcement learning under partial observability
Shayegan Omidshafiei, Jason Pazis, Christopher Amato, Jonathan P How, and John Vian. Deep decentralized multi-task multi-agent reinforcement learning under partial observability. InInternational Conference on Ma- chine Learning, pages 2681–2690, 2017
2017
-
[52]
Jiawei Wang, Jian Zhao, Zhengtao Cao, Ruili Feng, Rongjun Qin, and Yang Yu. Multi-task multi-agent shared layers are universal cognition of multi-agent coordination.arXiv preprint arXiv:2312.15674, 2023
arXiv 2023
-
[53]
Mtrl-cg: Multi-task reinforcement learning method with spectral clustering-based task grouping.Proceedings of the AAAI Conference on Artificial Intelligence, 40: 36723–36731, 2026
Wenjia Meng, Teng Zhang, Haoliang Sun, and Yilong Yin. Mtrl-cg: Multi-task reinforcement learning method with spectral clustering-based task grouping.Proceedings of the AAAI Conference on Artificial Intelligence, 40: 36723–36731, 2026. Algorithm 1Conquer retrieve-adapt-update procedure Require:Task streamY={M 1, . . . ,MT }; frozen SAG backboneθ; VLM-to-e...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.