Programmable Silicon Retina on Pixel Processor Array
Pith reviewed 2026-06-27 18:51 UTC · model grok-4.3
The pith
A multi-stage silicon retina model on pixel processor hardware yields events that improve saliency prediction while cutting the event rate nearly in half.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
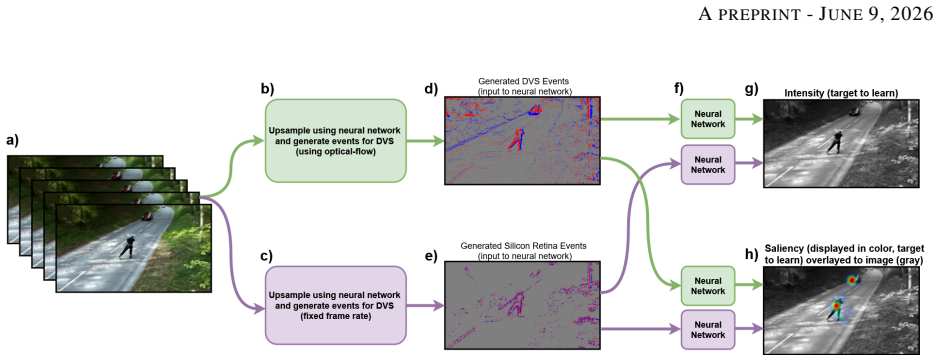
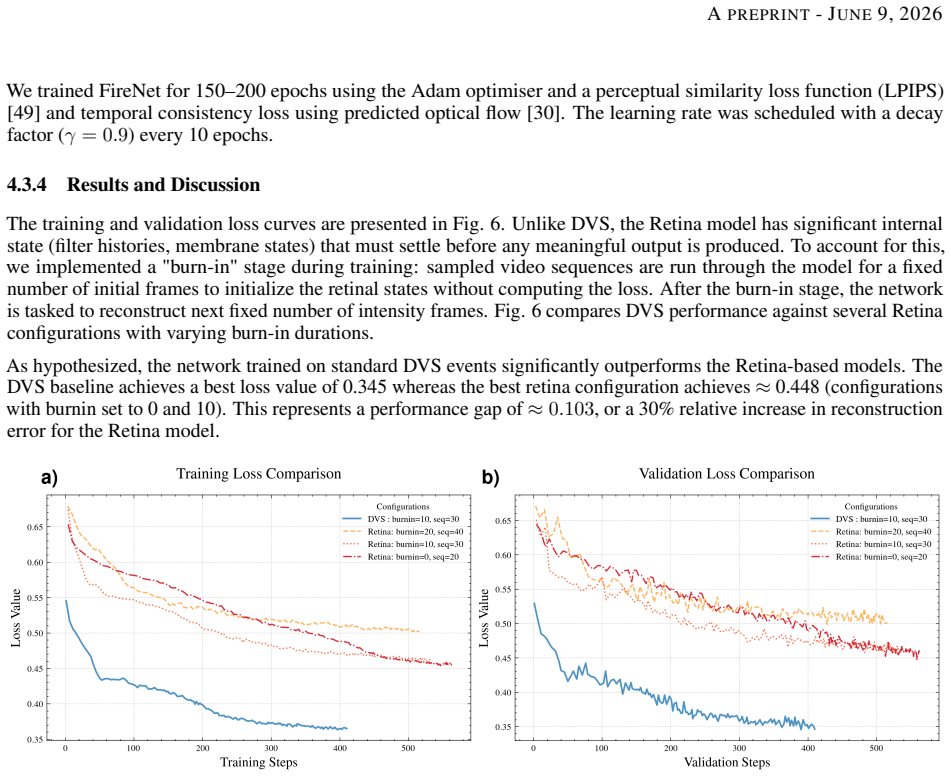
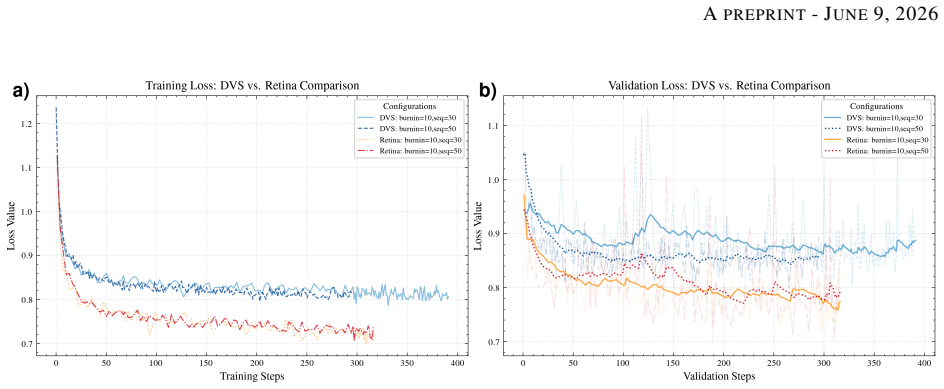
The silicon retina model, which performs temporal contrast detection followed by spatial filtering and gain control, is realized on the SCAMP-5 pixel processor array; when its output events are supplied to an adapted FireNet-style network for video saliency prediction, the model produces a 13 percent reduction in prediction loss and an approximately 47 percent reduction in event rate compared with standard DVS event streams, although the same events perform worse than DVS events at absolute intensity frame reconstruction.
What carries the argument
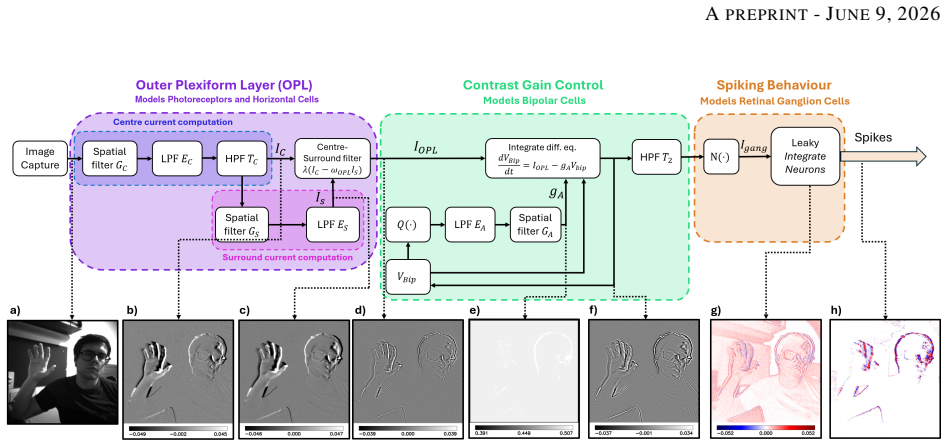
Multi-stage silicon retina model that adds spatial filtering and gain control to temporal contrast detection on the SCAMP-5 pixel processor array.
If this is right
- The model supplies a more compact event representation suited to bandwidth-limited saliency prediction on edge hardware.
- The same processing stages can be executed in real time on existing pixel processor array chips.
- A GPU simulation of the model allows rapid exploration of parameter choices before hardware deployment.
- Bio-inspired distillation stages can reduce the data volume that must reach a downstream neural network.
Where Pith is reading between the lines
- The same stages might be evaluated on other tasks such as optical flow or object detection to check whether the efficiency pattern generalizes.
- Programmable pixel arrays could host task-specific retina variants tuned for different downstream networks.
- The observed event-rate reduction could be measured directly for power or latency impact in a full hardware pipeline.
Load-bearing premise
That the measured gains with this particular lightweight network and these video datasets reflect benefits that would appear for other networks or tasks.
What would settle it
Testing the identical silicon retina event streams with a different saliency-prediction network architecture and observing no reduction in loss or no drop in event rate would falsify the efficiency claim.
Figures






read the original abstract
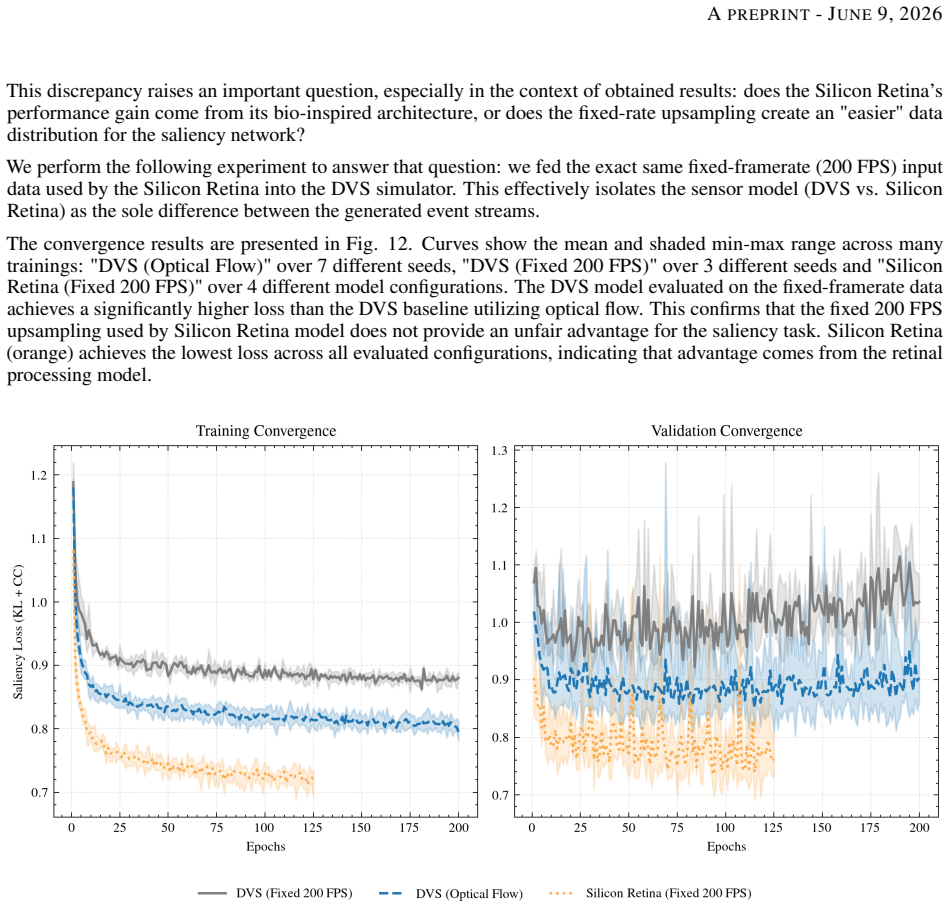
Standard dynamic vision sensors approximate retinal processing by detecting temporal contrast changes, offering high speed and high dynamic range. In this work, we explore whether incorporating additional biologically inspired processing stages - specifically spatial filtering and gain control - can offer advantages for certain downstream tasks such as saliency prediction. We present the first implementation of a multi-stage Silicon Retina model on the SCAMP-5 Pixel Processor Array, along with a GPU-based simulation framework. We evaluate the performance of our model on Video Intensity Reconstruction and Video Saliency Prediction. While the bio-inspired model is less effective at reconstructing absolute intensity frames, it achieves a 13\% reduction in saliency prediction loss in comparison to standard DVS event representation, while reducing the event rate by approximately 47\%. These experiments are obtained using a lightweight $\approx 100$k-parameter FireNet-style network, adapted from event-based reconstruction to saliency prediction. These results suggest that the silicon retina's "information distillation" mechanism can achieve a more efficient representation for downstream neural networks, particularly in bandwidth-constrained edge applications.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to present the first hardware implementation of a multi-stage Silicon Retina model (incorporating temporal contrast detection, spatial filtering, and gain control) on the SCAMP-5 Pixel Processor Array, together with a matching GPU simulation. On video intensity reconstruction the model underperforms standard DVS; on saliency prediction with a single adapted ~100 k-parameter FireNet-style network it reports a 13 % reduction in loss and a 47 % reduction in event rate relative to standard DVS, which the authors interpret as evidence of an “information distillation” benefit for bandwidth-constrained edge applications.
Significance. A working PPA implementation of additional biologically inspired stages is a concrete engineering contribution. If the reported saliency gains prove robust, the work supplies a concrete example of hardware-level preprocessing that can lower event rate while improving a downstream task. The narrow evaluation scope, however, prevents any strong claim of generality across tasks or architectures.
major comments (2)
- [Abstract and Experiments section] Abstract and Experiments section: the central claim that the silicon retina supplies a general “information distillation” benefit for downstream neural networks rests entirely on results from one ~100 k-parameter FireNet-style network adapted from reconstruction to saliency prediction; no other architectures, tasks (detection, flow, classification), or datasets are evaluated, so the extrapolation is unsupported.
- [Abstract] Abstract: quantitative results (13 % loss reduction, 47 % event-rate reduction) are stated without error bars, statistical tests, dataset identifiers, or a reproducible experimental protocol, preventing assessment of whether the observed differences are reliable or architecture-specific.
minor comments (2)
- The description of how the FireNet-style network was adapted from reconstruction to saliency prediction is brief; a short architectural diagram or layer table would improve clarity.
- Dataset names, resolutions, and preprocessing steps for both the reconstruction and saliency experiments are not stated in the provided text.
Simulated Author's Rebuttal
We thank the referee for the constructive comments highlighting the scope of evaluation and reporting details. Our work focuses on a concrete hardware implementation and specific results for saliency prediction; we clarify that no broad generality is claimed and address the points below.
read point-by-point responses
-
Referee: [Abstract and Experiments section] Abstract and Experiments section: the central claim that the silicon retina supplies a general “information distillation” benefit for downstream neural networks rests entirely on results from one ~100 k-parameter FireNet-style network adapted from reconstruction to saliency prediction; no other architectures, tasks (detection, flow, classification), or datasets are evaluated, so the extrapolation is unsupported.
Authors: The manuscript does not assert a general benefit across architectures or tasks; the abstract states that the results 'suggest' an efficient representation 'particularly in bandwidth-constrained edge applications' based on the presented saliency experiment. We agree the scope is narrow and will revise the abstract and discussion to explicitly note the limitation to this network and task, avoiding any implication of broader applicability. revision: partial
-
Referee: [Abstract] Abstract: quantitative results (13 % loss reduction, 47 % event-rate reduction) are stated without error bars, statistical tests, dataset identifiers, or a reproducible experimental protocol, preventing assessment of whether the observed differences are reliable or architecture-specific.
Authors: The full paper specifies the datasets and protocol used for the saliency experiments. We will revise the abstract and experiments section to include dataset identifiers, add error bars and any applicable statistical details, and expand the protocol description for reproducibility. revision: yes
Circularity Check
No circularity; empirical measurements only
full rationale
The paper reports measured performance numbers (13% saliency loss reduction, 47% event rate reduction) obtained by running a fixed lightweight FireNet-style network on outputs from the implemented silicon retina hardware and simulation. No equations, derivations, fitted parameters, or predictions appear in the provided text. The central claims rest on direct experimental comparison rather than any self-referential construction or self-citation chain that reduces to the inputs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Event-Based Vision Meets Deep Learning on Steering Prediction for Self-Driving Cars
Ana I. Maqueda et al. “Event-Based Vision Meets Deep Learning on Steering Prediction for Self-Driving Cars”. In:2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Salt Lake City, UT: IEEE, June 2018, pp. 5419–5427. DOI: 10.1109/CVPR.2018.00568.URL: https://ieeexp...
-
[2]
Fast Image Reconstruction with an Event Camera
Cedric Scheerlinck et al. “Fast Image Reconstruction with an Event Camera”. In:2020 IEEE Winter Conference on Applications of Computer Vision (WACV). 2020 IEEE Winter Conference on Applications of Computer Vision (WACV). Snowmass Village, CO, USA: IEEE, Mar. 2020, pp. 156–163.DOI: 10.1109/WACV45572.2020. 9093366.URL:https://ieeexplore.ieee.org/document/90...
-
[3]
Drone Detection with Event Cameras
Gabriele Magrini et al. “Drone Detection with Event Cameras”. In: ().URL: https://arxiv.org/abs/2508. 04564
-
[4]
Event-Based Vision: A Survey ,
Guillermo Gallego et al. “Event-based Vision: A Survey”. In:IEEE Transactions on Pattern Analysis and Machine Intelligence44.1 (Jan. 1, 2022), pp. 154–180.DOI: 10.1109/TPAMI.2020.3008413. arXiv: 1904.08405[cs]. URL:http://arxiv.org/abs/1904.08405(visited on 12/06/2025)
-
[5]
Retinomorphic Event-Based Vision Sensors: Bioinspired Cameras With Spiking Output
Christoph Posch et al. “Retinomorphic Event-Based Vision Sensors: Bioinspired Cameras With Spiking Output”. In:Proceedings of the IEEE102.10 (Oct. 2014), pp. 1470–1484.DOI: 10.1109/JPROC.2014.2346153.URL: https://ieeexplore.ieee.org/document/6887319/(visited on 12/06/2025)
-
[6]
Prince Philip et al.Neuromorphic Retina: An FPGA-based Emulator. Jan. 15, 2025.DOI: 10.48550/arXiv. 2501 . 08943. arXiv: 2501 . 08943[eess].URL: http : / / arxiv . org / abs / 2501 . 08943(visited on 12/06/2025)
work page internal anchor Pith review doi:10.48550/arxiv 2025
-
[7]
Bharatesh Chakravarthi et al.Recent Event Camera Innovations: A Survey. Aug. 27, 2024.DOI: 10.48550/ arXiv.2408.13627 . arXiv: 2408.13627[cs] .URL: http://arxiv.org/abs/2408.13627 (visited on 12/06/2025)
arXiv 2024
-
[8]
Nicholas Owen Ralph et al. “Astrometric calibration and source characterisation of the latest generation neu- romorphic event-based cameras for space imaging”. In:Astrodynamics7.4 (Dec. 1, 2023), pp. 415–443.DOI: 10.1007/s42064- 023- 0168- 2 .URL: https://doi.org/10.1007/s42064- 023- 0168- 2 (visited on 12/06/2025)
-
[9]
Sami Arja et al.Noise Filtering Benchmark for Neuromorphic Satellites Observations. Nov. 18, 2024.DOI: 10.48550/arXiv.2411.11233 . arXiv: 2411.11233[cs].URL: http://arxiv.org/abs/2411.11233 (visited on 12/09/2025). 22 APREPRINT- JUNE9, 2026
-
[10]
Robust Event-Based Object Tracking Combining Correlation Filter and CNN Representation
Hongmin Li and Luping Shi. “Robust Event-Based Object Tracking Combining Correlation Filter and CNN Representation”. In:Frontiers in Neurorobotics13 (Oct. 10, 2019).DOI: 10 . 3389 / fnbot . 2019 . 00082. URL: https://www.frontiersin.org/journals/neurorobotics/articles/10.3389/fnbot.2019. 00082/full(visited on 12/06/2025)
-
[11]
Simultaneous Optical Flow and Intensity Estima- tion from an Event Camera
Patrick Bardow, Andrew J. Davison, and Stefan Leutenegger. “Simultaneous Optical Flow and Intensity Estima- tion from an Event Camera”. In:2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Las Vegas, NV, USA: IEEE, June 2016, pp. 884–892.DOI: 10.1109/CVPR.2016.10...
-
[12]
High Speed and High Dynamic Range Video with an Event Camera
Henri Rebecq et al.High Speed and High Dynamic Range Video with an Event Camera. June 15, 2019.DOI: 10.48550/arXiv.1906.07165 . arXiv: 1906.07165[cs].URL: http://arxiv.org/abs/1906.07165 (visited on 12/06/2025)
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1906.07165 2019
-
[13]
Amélie Gruel and Jean Martinet.Bio-inspired visual attention for silicon retinas based on spiking neural networks applied to pattern classification. Issue: arXiv:2105.14753. May 31, 2021.DOI: 10.48550/arXiv.2105.14753. arXiv:2105.14753[cs].URL:http://arxiv.org/abs/2105.14753(visited on 12/06/2025)
-
[14]
Sirine Arfa et al.Efficient Deployment of Spiking Neural Networks on SpiNNaker2 for DVS Gesture Recognition Using Neuromorphic Intermediate Representation. Issue: arXiv:2504.06748. Apr. 9, 2025.DOI: 10.48550/ arXiv.2504.06748 . arXiv: 2504.06748[cs] .URL: http://arxiv.org/abs/2504.06748 (visited on 12/08/2025)
arXiv 2025
-
[15]
Simon Schaefer, Daniel Gehrig, and Davide Scaramuzza.AEGNN: Asynchronous Event-based Graph Neural Networks. Issue: arXiv:2203.17149. Nov. 1, 2022.DOI: 10 . 48550 / arXiv . 2203 . 17149. arXiv: 2203 . 17149[cs].URL:http://arxiv.org/abs/2203.17149(visited on 12/06/2025)
arXiv 2022
-
[16]
EvGNN: An Event-driven Graph Neural Network Ac- celerator for Edge Vision
Yufeng Yang, Adrian Kneip, and Charlotte Frenkel. “EvGNN: An Event-driven Graph Neural Network Ac- celerator for Edge Vision”. In:IEEE Transactions on Circuits and Systems for Artificial Intelligence2.1 (Mar. 2025), pp. 37–50.DOI: 10 . 1109 / TCASAI . 2024 . 3520905. arXiv: 2404 . 19489[cs].URL: http : //arxiv.org/abs/2404.19489(visited on 12/06/2025)
arXiv 2025
-
[17]
Continuous-time Intensity Estimation Using Event Cameras
Cedric Scheerlinck, Nick Barnes, and Robert Mahony.Continuous-time Intensity Estimation Using Event Cam- eras. Issue: arXiv:1811.00386. Nov. 1, 2018.DOI: 10.48550/arXiv.1811.00386. arXiv: 1811.00386[cs]. URL:http://arxiv.org/abs/1811.00386(visited on 12/06/2025)
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1811.00386 2018
-
[18]
PROPHESEE.URL: https://www.prophesee.ai/event-based-sensors/ (visited on 02/09/2026)
Metavision® Sensors. PROPHESEE.URL: https://www.prophesee.ai/event-based-sensors/ (visited on 02/09/2026). [19]Buy – iniVation.URL:https://inivation.com/buy/(visited on 02/09/2026)
2026
-
[19]
Thomas Finateu et al. “5.10 A 1280×720 Back-Illuminated Stacked Temporal Contrast Event-Based Vision Sensor with 4.86µm Pixels, 1.066GEPS Readout, Programmable Event-Rate Controller and Compressive Data- Formatting Pipeline”. In:2020 IEEE International Solid-State Circuits Conference - (ISSCC). 2020, pp. 112–114. DOI:10.1109/ISSCC19947.2020.9063149
-
[20]
Misha A. Mahowald and Carver Mead. “The Silicon Retina”. In:Scientific American264.5 (1991), pp. 76–83. URL:http://www.jstor.org/stable/24936904(visited on 06/04/2026)
arXiv 1991
-
[21]
Virtual Retina: A biological retina model and simulator, with contrast gain control
Adrien Wohrer and Pierre Kornprobst. “Virtual Retina: A biological retina model and simulator, with contrast gain control”. In:Journal of Computational Neuroscience26.2 (Apr. 1, 2009), pp. 219–249.DOI: 10.1007/s10827- 008-0108-4.URL:https://doi.org/10.1007/s10827-008-0108-4(visited on 12/06/2025)
-
[22]
G.D. Field and E.J. Chichilnisky. “Information Processing in the Primate Retina: Circuitry and Coding”. In: Annual Review of Neuroscience30.1 (July 1, 2007), pp. 1–30.DOI: 10.1146/annurev.neuro.30.051606. 094252.URL: https://www.annualreviews.org/doi/10.1146/annurev.neuro.30.051606.094252 (visited on 12/06/2025)
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1146/annurev.neuro.30.051606 2007
-
[23]
Sensor-level computer vision with pixel processor arrays for agile robots
Piotr Dudek et al. “Sensor-level computer vision with pixel processor arrays for agile robots”. In:Science Robotics7.67 (June 29, 2022), eabl7755.DOI: 10 . 1126 / scirobotics . abl7755.URL: https : / / www . science.org/doi/10.1126/scirobotics.abl7755(visited on 12/06/2025)
-
[24]
A 100,000 fps vision sensor with embedded 535GOPS/W 256×256 SIMD processor array
Stephen J. Carey et al. “A 100,000 fps vision sensor with embedded 535GOPS/W 256×256 SIMD processor array”. In:2013 Symposium on VLSI Circuits. 2013 Symposium on VLSI Circuits. June 2013, pp. C182–C183. URL:https://ieeexplore.ieee.org/document/6578654(visited on 12/06/2025)
arXiv 2013
-
[25]
Descriptor-In-Pixel : Point-Feature Tracking For Pixel Processor Arrays
Laurie Bose, Jianing Chen, and Piotr Dudek. “Descriptor-In-Pixel : Point-Feature Tracking For Pixel Processor Arrays”. In:Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). June 2025, pp. 5392–5400. 23 APREPRINT- JUNE9, 2026
2025
-
[26]
Pixel Processor Arrays For Low Latency Gaze Estimation
Laurie Bose et al. “Pixel Processor Arrays For Low Latency Gaze Estimation”. In:2022 IEEE Conference on Virtual Reality and 3D User Interfaces Abstracts and Workshops (VRW). 2022 IEEE Conference on Virtual Reality and 3D User Interfaces Abstracts and Workshops (VRW). Christchurch, New Zealand: IEEE, Mar. 2022, pp. 970– 971.DOI: 10.1109/VRW55335.2022.00336...
-
[27]
Haley M. So et al.PixelRNN: In-pixel Recurrent Neural Networks for End-to-end-optimized Perception with Neural Sensors. Apr. 11, 2023.DOI: 10.48550/arXiv.2304.05440 . arXiv: 2304.05440[cs].URL: http: //arxiv.org/abs/2304.05440(visited on 12/06/2025)
-
[28]
Pixel interlacing to trade off the resolution of a cellular processor array against more registers
Julien N. P. Martel et al. “Pixel interlacing to trade off the resolution of a cellular processor array against more registers”. In:2015 European Conference on Circuit Theory and Design (ECCTD). 2015, pp. 1–4.DOI: 10.1109/ECCTD.2015.7300011
-
[29]
Daniel Gehrig et al.Video to Events: Recycling Video Datasets for Event Cameras. Apr. 1, 2020.DOI: 10. 48550/arXiv.1912.03095. arXiv: 1912.03095[cs].URL: http://arxiv.org/abs/1912.03095 (visited on 12/06/2025)
arXiv 2020
-
[30]
Fast and Slow Contrast Adaptation in Retinal Circuitry
Stephen A. Baccus and Markus Meister. “Fast and Slow Contrast Adaptation in Retinal Circuitry”. In:Neuron 36.5 (Dec. 2002), pp. 909–919.DOI: 10.1016/S0896- 6273(02)01050- 4 .URL: https://linkinghub. elsevier.com/retrieve/pii/S0896627302010504(visited on 12/06/2025)
-
[31]
Tianruo Guo et al. “Understanding the Retina: A Review of Computational Models of the Retina from the Single Cell to the Network Level”. In:Critical Reviews in Biomedical Engineering42.5 (2014), pp. 419–436. DOI: 10.1615/CritRevBiomedEng.2014011732 .URL: http://www.dl.begellhouse.com/journals/ 4b27cbfc562e21b8,64a3e6f7290a8a6e,64cd0e236c1f5579.html(visite...
-
[32]
Tau-Cell-Based Analog Silicon Retina With Spatio-Temporal Filtering and Contrast Gain Control
Prince Philip et al. “Tau-Cell-Based Analog Silicon Retina With Spatio-Temporal Filtering and Contrast Gain Control”. In:IEEE Transactions on Biomedical Circuits and Systems18.2 (2024), pp. 423–437.DOI: 10.1109/ TBCAS.2023.3332117
arXiv 2024
-
[33]
The effect of contrast on the transfer properties of cat retinal ganglion cells
R M Shapley and J D Victor. “The effect of contrast on the transfer properties of cat retinal ganglion cells.” In: The Journal of Physiology285 (Dec. 1978), pp. 275–298.DOI: 10.1113/jphysiol.1978.sp012571 .URL: https://pmc.ncbi.nlm.nih.gov/articles/PMC1281756/(visited on 12/09/2025)
-
[34]
Feature Extraction using a Portable Vision System
Jianing Chen, Stephen J Carey, and Piotr Dudek. “Feature Extraction using a Portable Vision System”. In: ()
-
[35]
Real-Time Depth From Focus on a Programmable Focal Plane Processor
Julien N. P. Martel et al. “Real-Time Depth From Focus on a Programmable Focal Plane Processor”. In:IEEE Transactions on Circuits and Systems I: Regular Papers65.3 (Mar. 2018), pp. 925–934.DOI: 10.1109/TCSI. 2017.2753878.URL:https://ieeexplore.ieee.org/document/8071011/(visited on 12/06/2025)
-
[36]
A 128× 128 120 dB 15 µs Latency Asynchronous Temporal Contrast Vision Sensor
Patrick Lichtsteiner, Christoph Posch, and Tobi Delbruck. “A 128× 128 120 dB 15 µs Latency Asynchronous Temporal Contrast Vision Sensor”. In:IEEE Journal of Solid-State Circuits43.2 (2008), pp. 566–576.DOI: 10.1109/JSSC.2007.914337
-
[37]
A Spatial Contrast Retina With On-Chip Calibration for Neuromorphic Spike-Based AER Vision Systems
Jess Costas-Santos et al. “A Spatial Contrast Retina With On-Chip Calibration for Neuromorphic Spike-Based AER Vision Systems”. In:IEEE Transactions on Circuits and Systems I: Regular Papers54.7 (July 2007), pp. 1444–1458.DOI: 10.1109/TCSI.2007.900179 .URL: https://ieeexplore.ieee.org/document/ 4268401(visited on 12/14/2025)
-
[38]
Christoph Posch et al. “Live demonstration: Asynchronous time-based image sensor (ATIS) camera with full- custom AE processor”. In:Proceedings of 2010 IEEE International Symposium on Circuits and Systems. 2010 IEEE International Symposium on Circuits and Systems. May 2010, pp. 1392–1392.DOI: 10.1109/ISCAS. 2010.5537265.URL:https://ieeexplore.ieee.org/docu...
-
[39]
Juan Antonio Leñero-Bardallo, Teresa Serrano-Gotarredona, and Bernabé Linares-Barranco. “A Five-Decade Dynamic-Range Ambient-Light-Independent Calibrated Signed-Spatial-Contrast AER Retina With 0.1-ms Latency and Optional Time-to-First-Spike Mode”. In:IEEE Transactions on Circuits and Systems I: Regular Papers57.10 (Oct. 2010), pp. 2632–2643.DOI: 10.1109/...
-
[40]
Live demonstration: The “DA VIS
C. Brandli et al. “Live demonstration: The “DA VIS” Dynamic and Active-Pixel Vision Sensor”. In:2014 IEEE International Symposium on Circuits and Systems (ISCAS). 2014 IEEE International Symposium on Circuits and Systems (ISCAS). June 2014, pp. 440–440.DOI: 10.1109/ISCAS.2014.6865163.URL: https: //ieeexplore.ieee.org/document/6865163/(visited on 12/14/2025)
-
[41]
Yuki Hayashida et al. “Retinal Circuit Emulator With Spatiotemporal Spike Outputs at Millisecond Resolution in Response to Visual Events”. In:IEEE transactions on biomedical circuits and systems11.3 (June 2017), pp. 597–611.DOI:10.1109/TBCAS.2017.2662659. 24 APREPRINT- JUNE9, 2026
-
[42]
Efficient Meshflow and Optical Flow Estimation from Event Cameras
Xinglong Luo et al. “Efficient Meshflow and Optical Flow Estimation from Event Cameras”. In:2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Seattle, WA, USA: IEEE, June 16, 2024, pp. 19198–19207.DOI: 10 . 1109 / CVPR52733 . 2024 . 01816.URL: https : / /...
2024
-
[43]
Sachin Shah et al.CodedEvents: Optimal Point-Spread-Function Engineering for 3D-Tracking with Event Cameras. Issue: arXiv:2406.09409. June 13, 2024.DOI: 10 . 48550 / arXiv . 2406 . 09409. arXiv: 2406 . 09409[cs].URL:http://arxiv.org/abs/2406.09409(visited on 12/06/2025)
arXiv 2024
-
[44]
v2e: From Video Frames to Realistic DVS Events
Yuhuang Hu, Shih-Chii Liu, and Tobi Delbruck. “v2e: From Video Frames to Realistic DVS Events”. In: ()
-
[45]
Revisiting Video Saliency Prediction in the Deep Learning Era
Wenguan Wang et al. “Revisiting Video Saliency Prediction in the Deep Learning Era”. In:IEEE Transactions on Pattern Analysis and Machine Intelligence43.1 (Jan. 2021), pp. 220–237.DOI: 10.1109/TPAMI.2019.2924417. URL:https://ieeexplore.ieee.org/document/8744328(visited on 01/05/2026)
-
[46]
Christian Reinbacher, Gottfried Graber, and Thomas Pock.Real-Time Intensity-Image Reconstruction for Event Cameras Using Manifold Regularisation. Aug. 4, 2016.DOI: 10.48550/arXiv.1607.06283 . arXiv: 1607.06283[cs].URL:http://arxiv.org/abs/1607.06283(visited on 12/06/2025)
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1607.06283 2016
-
[47]
Events-To-Video: Bringing Modern Computer Vision to Event Cameras
Henri Rebecq et al. “Events-To-Video: Bringing Modern Computer Vision to Event Cameras”. In:2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Long Beach, CA, USA: IEEE, June 2019, pp. 3852–3861. DOI: 10.1109/CVPR.2019.00398.URL: https://ieeexplore.ieee.or...
-
[48]
Richard Zhang et al.The Unreasonable Effectiveness of Deep Features as a Perceptual Metric. Apr. 10, 2018.DOI: 10.48550/arXiv.1801.03924 . arXiv: 1801.03924[cs].URL: http://arxiv.org/abs/1801.03924 (visited on 12/06/2025). 25
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1801.03924 2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.