SceneConductor: 3D Scene Generation from a Single Image with Multi-Agent Orchestration
Pith reviewed 2026-06-27 19:06 UTC · model grok-4.3
The pith
A multi-agent orchestration framework decomposes single-image 3D scene generation into initialization, environment construction, and planner-driven refinement stages to achieve higher geometric accuracy and consistency.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
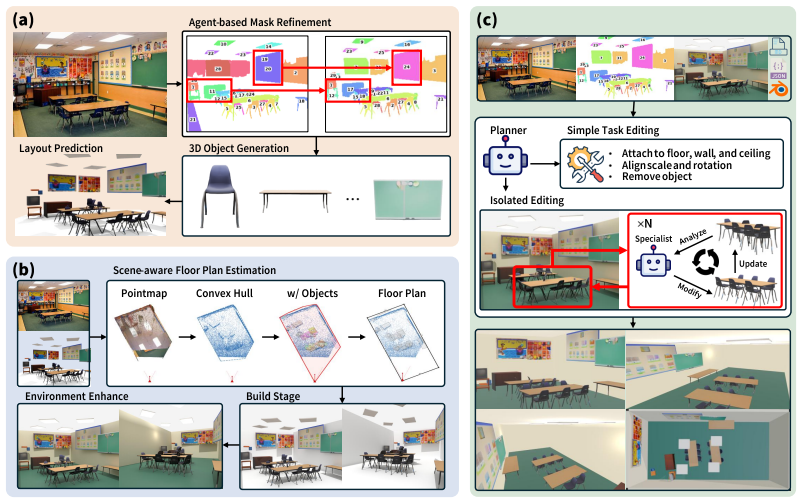
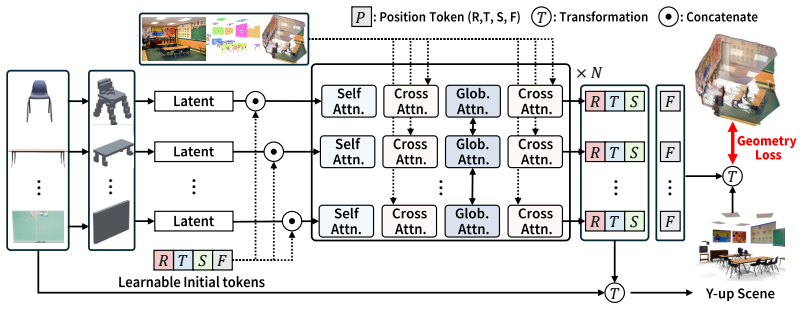
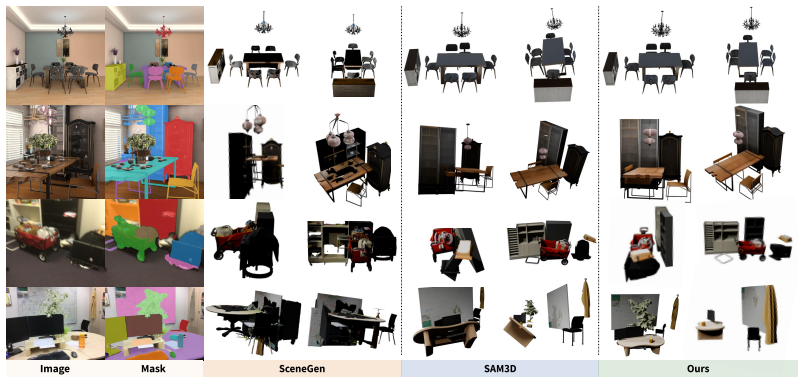
The paper claims that its multi-agent orchestration framework, consisting of scene initialization from image-derived object masks and a geometry-aware layout predictor, environment construction that builds supporting surfaces and illumination from point-map geometry, and a refinement stage in which a planner agent identifies inconsistencies and dispatches specialist agents for localized revisions that are reintegrated globally, produces scenes with superior geometric accuracy, spatial consistency, and perceptual realism on benchmarks while training the layout predictor from segmentation-level data rather than full scene annotations.
What carries the argument
The multi-agent orchestration framework that separates initialization, environment construction, and refinement, with a planner agent identifying inconsistencies and specialist agents performing localized revisions reintegrated into the global scene, plus the geometry-aware layout predictor supervised by sparse geometric priors from point maps.
If this is right
- The layout predictor generalizes to diverse real-world scenes when trained only on segmentation-level data and sparse geometric priors.
- The staged pipeline reduces reliance on extensive scene-level annotations during training.
- Benchmark results show consistent gains in geometric accuracy, spatial consistency, and perceptual realism over prior holistic methods.
- Localized revisions by specialist agents can be reintegrated into the global scene without breaking overall coherence.
Where Pith is reading between the lines
- The staged orchestration could be extended to video input by adding a temporal-consistency specialist agent that enforces frame-to-frame stability.
- Lower supervision requirements might allow the same decomposition to support casual photo-to-3D workflows in consumer applications such as interior design visualization.
- The planner-plus-specialist pattern suggests that other complex generative tasks could benefit from explicit inconsistency detection before local fixes rather than end-to-end generation.
Load-bearing premise
The planner agent can reliably detect structural and visual inconsistencies while specialist agents can revise them locally and reintegrate the changes without creating new errors.
What would settle it
A controlled test on scenes containing subtle geometric mismatches where the planner misses at least half the inconsistencies and the final outputs show no measurable gain or a drop in accuracy metrics compared with prior single-pipeline baselines.
Figures


read the original abstract
Generating complete 3D scenes from a single image requires inferring globally consistent geometry, object relationships, and environmental context from inherently ambiguous visual evidence. Despite recent progress in joint layout-and-mesh generation, existing methods often rely on holistic or weakly decomposed pipelines that entangle many factors at once and demand extensive scene-level supervision, limiting their generalization to complex real-world environments. We propose a multi-agent orchestration framework that decomposes single-image 3D scene generation into three structured stages: scene initialization, environment construction, and multi-agent refinement. The initialization stage extracts image-derived object masks, builds object-level 3D representations, and predicts an initial spatial layout to form a coarse 3D scene. The environment-construction stage then leverages this initialization together with point-map geometry to build an environmental scaffold of supporting surfaces, room boundaries, materials, and illumination. Finally, in the refinement stage, a planner agent identifies structural and visual inconsistencies, applies simple corrections directly, and dispatches specialist agents for complex localized revisions that are reintegrated into the global scene. To provide reliable structural initialization while reducing reliance on scene-level annotations, we further introduce a geometry-aware layout predictor supervised by sparse geometric priors derived from point maps. Unlike fully supervised layout generators, the predictor can be trained from segmentation-level data and generalizes robustly to diverse real-world scenes. Extensive experiments on benchmark datasets show that our method consistently outperforms prior approaches in geometric accuracy, spatial consistency, and perceptual realism.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes SceneConductor, a multi-agent orchestration framework for 3D scene generation from a single image. It decomposes the task into scene initialization (extracting object masks, building 3D representations, and predicting layout via a geometry-aware predictor supervised by sparse point-map priors), environment construction (building scaffolds for surfaces, boundaries, materials, and illumination), and multi-agent refinement (planner identifies inconsistencies and dispatches specialist agents for localized revisions). The central claim is that this approach reduces reliance on scene-level supervision, generalizes robustly, and consistently outperforms prior methods in geometric accuracy, spatial consistency, and perceptual realism on benchmark datasets.
Significance. If the empirical claims hold, the work could advance single-image 3D scene generation by offering a modular alternative to holistic pipelines, with the geometry-aware layout predictor providing a concrete mechanism for training from segmentation-level data rather than full annotations. The multi-agent refinement stage addresses a recognized challenge in maintaining global consistency. These elements, if validated, would be a positive contribution to the field.
major comments (2)
- [Abstract] Abstract: The central empirical claim that the method 'consistently outperforms prior approaches in geometric accuracy, spatial consistency, and perceptual realism' is presented without any metrics, baselines, dataset names, error bars, or ablation results. This assertion is load-bearing for the paper's contribution but cannot be evaluated from the provided text.
- [Abstract] Abstract, refinement stage description: The assumption that the planner agent reliably identifies structural/visual inconsistencies and that specialist agents perform revisions that reintegrate without introducing new errors is stated at a high level with no discussion of validation, failure cases, or integration mechanism. This assumption underpins the claimed robustness of the multi-agent pipeline.
minor comments (1)
- [Abstract] The phrase 'point-map geometry' is used without a brief definition or citation; adding one would improve clarity for readers unfamiliar with the term.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. We address each major comment below. Both points highlight opportunities to strengthen the abstract, and we will revise it accordingly while preserving its concise nature.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central empirical claim that the method 'consistently outperforms prior approaches in geometric accuracy, spatial consistency, and perceptual realism' is presented without any metrics, baselines, dataset names, error bars, or ablation results. This assertion is load-bearing for the paper's contribution but cannot be evaluated from the provided text.
Authors: We agree that the abstract would benefit from greater specificity to allow readers to immediately assess the claims. The full manuscript contains quantitative results, baselines, datasets, and ablations in the Experiments section, but the abstract itself does not reference them. In the revision we will update the abstract to name the primary benchmark datasets, report key metric improvements (with error bars where applicable), and briefly note the main baselines, while keeping the text within length limits. This change will make the contribution more transparent. revision: yes
-
Referee: [Abstract] Abstract, refinement stage description: The assumption that the planner agent reliably identifies structural/visual inconsistencies and that specialist agents perform revisions that reintegrate without introducing new errors is stated at a high level with no discussion of validation, failure cases, or integration mechanism. This assumption underpins the claimed robustness of the multi-agent pipeline.
Authors: The abstract presents the multi-agent refinement at a summary level, as is conventional. The full manuscript elaborates the planner's inconsistency detection, agent dispatching, and reintegration procedure in the dedicated refinement section, supported by qualitative examples. However, the abstract does not mention validation or failure modes. We will revise the abstract to include a concise clause on empirical validation via consistency metrics and will add a short discussion of failure cases and integration safeguards to the main text or supplementary material to address this concern directly. revision: yes
Circularity Check
No significant circularity detected
full rationale
The provided abstract and description outline a multi-agent pipeline (initialization, environment construction, refinement) and a geometry-aware layout predictor trained on sparse geometric priors from point maps. No equations, derivations, or first-principles results appear that reduce by construction to fitted parameters, self-definitions, or self-citation chains. The predictor is explicitly distinguished from fully supervised alternatives via its training data source, with no evidence of renaming known results or smuggling ansatzes. Empirical claims of outperformance rest on benchmark experiments rather than internal reductions. This is a standard methodological contribution without load-bearing circular steps.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Multi-agent refinement can identify inconsistencies and produce reintegrated corrections that improve global consistency.
- domain assumption The geometry-aware layout predictor generalizes robustly to diverse real-world scenes when trained on segmentation-level data.
Reference graph
Works this paper leans on
-
[1]
Occupancy networks: Learning 3d reconstruction in function space
Lars Mescheder, Michael Oechsle, Michael Niemeyer, Sebastian Nowozin, and Andreas Geiger. Occupancy networks: Learning 3d reconstruction in function space. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 4460–4470, 2019
2019
-
[2]
Pix2vox: Context- aware 3d reconstruction from single and multi-view images
Haozhe Xie, Hongxun Yao, Xiaoshuai Sun, Shangchen Zhou, and Shengping Zhang. Pix2vox: Context- aware 3d reconstruction from single and multi-view images. InProceedings of the IEEE/CVF international conference on computer vision, pages 2690–2698, 2019
2019
-
[3]
Alex Nichol, Heewoo Jun, Prafulla Dhariwal, Pamela Mishkin, and Mark Chen. Point-e: A system for generating 3d point clouds from complex prompts.arXiv preprint arXiv:2212.08751, 2022
Pith/arXiv arXiv 2022
-
[4]
Lion: Latent point diffusion models for 3d shape generation.Advances in Neural Information Processing Systems, 35:10021–10039, 2022
Arash Vahdat, Francis Williams, Zan Gojcic, Or Litany, Sanja Fidler, Karsten Kreis, et al. Lion: Latent point diffusion models for 3d shape generation.Advances in Neural Information Processing Systems, 35:10021–10039, 2022
2022
-
[5]
Get3d: A generative model of high quality 3d textured shapes learned from images
Jun Gao, Tianchang Shen, Zian Wang, Wenzheng Chen, Kangxue Yin, Daiqing Li, Or Litany, Zan Gojcic, and Sanja Fidler. Get3d: A generative model of high quality 3d textured shapes learned from images. Advances In Neural Information Processing Systems, 35:31841–31854, 2022
2022
-
[6]
Shap-e: Generating conditional 3d implicit functions.arXiv preprint arXiv:2305.02463, 2023
Heewoo Jun and Alex Nichol. Shap-e: Generating conditional 3d implicit functions.arXiv preprint arXiv:2305.02463, 2023
Pith/arXiv arXiv 2023
-
[7]
Midi: Multi-instance diffusion for single image to 3d scene generation
Zehuan Huang, Yuan-Chen Guo, Xingqiao An, Yunhan Yang, Yangguang Li, Zi-Xin Zou, Ding Liang, Xihui Liu, Yan-Pei Cao, and Lu Sheng. Midi: Multi-instance diffusion for single image to 3d scene generation. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 23646–23657, 2025
2025
-
[8]
Yuchen Lin, Chenguo Lin, Panwang Pan, Honglei Yan, Yiqiang Feng, Yadong Mu, and Katerina Fragki- adaki. Partcrafter: Structured 3d mesh generation via compositional latent diffusion transformers.arXiv preprint arXiv:2506.05573, 2025
arXiv 2025
-
[9]
Yanxu Meng, Haoning Wu, Ya Zhang, and Weidi Xie. Scenegen: Single-image 3d scene generation in one feedforward pass.arXiv preprint arXiv:2508.15769, 2025
arXiv 2025
-
[10]
Ling Wang, Hao-Xiang Guo, Xinzhou Wang, Fuchun Sun, Kai Sun, Pengkun Liu, Hang Xiao, Zhong Wang, Guangyuan Fu, Eric Li, et al. Scenetransporter: Optimal transport-guided compositional latent diffusion for single-image structured 3d scene generation.arXiv preprint arXiv:2602.22785, 2026
arXiv 2026
-
[11]
Sam 3d: 3dfy anything in images, 2025
SAM 3D Team, Xingyu Chen, Fu-Jen Chu, Pierre Gleize, Kevin J Liang, Alexander Sax, Hao Tang, Weiyao Wang, Michelle Guo, Thibaut Hardin, Xiang Li, Aohan Lin, Jiawei Liu, Ziqi Ma, Anushka Sagar, Bowen Song, Xiaodong Wang, Jianing Yang, Bowen Zhang, Piotr Dollár, Georgia Gkioxari, Matt Feiszli, and Jitendra Malik. Sam 3d: 3dfy anything in images, 2025
2025
-
[12]
Ze-Xin Yin, Liu Liu, Xinjie Wang, Wei Sui, Zhizhong Su, Jian Yang, and Jin Xie. 3d-fixer: Coarse-to-fine in-place completion for 3d scenes from a single image.arXiv preprint arXiv:2604.04406, 2026
Pith/arXiv arXiv 2026
-
[13]
Shaper: Robust conditional 3d shape generation from casual captures, 2026
Yawar Siddiqui, Duncan Frost, Samir Aroudj, Armen Avetisyan, Henry Howard-Jenkins, Daniel DeTone, Pierre Moulon, Qirui Wu, Zhengqin Li, Julian Straub, Richard Newcombe, and Jakob Engel. Shaper: Robust conditional 3d shape generation from casual captures, 2026
2026
-
[14]
3d-future: 3d furniture shape with texture.International Journal of Computer Vision, 129:3313–3337, 2021
Huan Fu, Rongfei Jia, Lin Gao, Mingming Gong, Binqiang Zhao, Steve Maybank, and Dacheng Tao. 3d-future: 3d furniture shape with texture.International Journal of Computer Vision, 129:3313–3337, 2021
2021
-
[15]
3d-front: 3d furnished rooms with layouts and semantics
Huan Fu, Bowen Cai, Lin Gao, Ling-Xiao Zhang, Jiaming Wang, Cao Li, Qixun Zeng, Chengyue Sun, Rongfei Jia, Binqiang Zhao, et al. 3d-front: 3d furnished rooms with layouts and semantics. InProceedings of the International Conference on Computer Vision, 2021
2021
-
[16]
Seongrae Noh, SeungWon Seo, Gyeong-Moon Park, and HyeongYeop Kang. Edit-as-act: Goal-regressive planning for open-vocabulary 3d indoor scene editing.arXiv preprint arXiv:2603.17583, 2026
arXiv 2026
-
[17]
Sceneweaver: All-in-one 3d scene synthesis with an extensible and self-reflective agent, 2025
Yandan Yang, Baoxiong Jia, Shujie Zhang, and Siyuan Huang. Sceneweaver: All-in-one 3d scene synthesis with an extensible and self-reflective agent, 2025
2025
-
[18]
3d-generalist: Self-improving vision-language-action models for crafting 3d worlds, 2025
Fan-Yun Sun, Shengguang Wu, Christian Jacobsen, Thomas Yim, Haoming Zou, Alex Zook, Shangru Li, Yu-Hsin Chou, Ethem Can, Xunlei Wu, Clemens Eppner, Valts Blukis, Jonathan Tremblay, Jiajun Wu, Stan Birchfield, and Nick Haber. 3d-generalist: Self-improving vision-language-action models for crafting 3d worlds, 2025. 10
2025
-
[19]
Shaofeng Yin, Jiaxin Ge, Zora Zhiruo Wang, Chenyang Wang, Xiuyu Li, Michael J Black, Trevor Darrell, Angjoo Kanazawa, and Haiwen Feng. Vision-as-inverse-graphics agent via interleaved multimodal reasoning.arXiv preprint arXiv:2601.11109, 2026
Pith/arXiv arXiv 2026
-
[20]
Structure-from-motion revisited
Johannes L Schonberger and Jan-Michael Frahm. Structure-from-motion revisited. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2016
2016
-
[21]
Vggsfm: Visual geometry grounded deep structure from motion
Jianyuan Wang, Nikita Karaev, Christian Rupprecht, and David Novotny. Vggsfm: Visual geometry grounded deep structure from motion. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2024
2024
-
[22]
Dust3r: Geometric 3d vision made easy
Shuzhe Wang, Vincent Leroy, Yohann Cabon, Boris Chidlovskii, and Jerome Revaud. Dust3r: Geometric 3d vision made easy. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2024
2024
-
[23]
Grounding image matching in 3d with mast3r
Vincent Leroy, Yohann Cabon, and Jérôme Revaud. Grounding image matching in 3d with mast3r. In Proceedings of the European Conference on Computer Vision, 2024
2024
-
[24]
Vggt: Visual geometry grounded transformer
Jianyuan Wang, Minghao Chen, Nikita Karaev, Andrea Vedaldi, Christian Rupprecht, and David Novotny. Vggt: Visual geometry grounded transformer. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2025
2025
-
[25]
Easi3r: Estimating disentangled motion from dust3r without training
Xingyu Chen, Yue Chen, Yuliang Xiu, Andreas Geiger, and Anpei Chen. Easi3r: Estimating disentangled motion from dust3r without training. InProceedings of the International Conference on Computer Vision, 2025
2025
-
[26]
Aether: Geometric-aware unified world modeling
Aether Team, Haoyi Zhu, Yifan Wang, Jianjun Zhou, Wenzheng Chang, Yang Zhou, Zizun Li, Junyi Chen, Chunhua Shen, Jiangmiao Pang, et al. Aether: Geometric-aware unified world modeling. InProceedings of the International Conference on Computer Vision, 2025
2025
-
[27]
Moge: Unlocking accurate monocular geometry estimation for open-domain images with optimal training supervision
Ruicheng Wang, Sicheng Xu, Cassie Dai, Jianfeng Xiang, Yu Deng, Xin Tong, and Jiaolong Yang. Moge: Unlocking accurate monocular geometry estimation for open-domain images with optimal training supervision. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 5261–5271, 2025
2025
-
[28]
Lrm: Large reconstruction model for single image to 3d
Yicong Hong, Kai Zhang, Jiuxiang Gu, Sai Bi, Yang Zhou, Difan Liu, Feng Liu, Kalyan Sunkavalli, Trung Bui, and Hao Tan. Lrm: Large reconstruction model for single image to 3d. InProceedings of the International Conference on Learning Representations, 2024
2024
-
[29]
Jiale Xu, Weihao Cheng, Yiming Gao, Xintao Wang, Shenghua Gao, and Ying Shan. Instantmesh: Efficient 3d mesh generation from a single image with sparse-view large reconstruction models.arXiv preprint arXiv:2404.07191, 2024
Pith/arXiv arXiv 2024
-
[30]
One-2-3-45++: Fast single image to 3d objects with consistent multi-view generation and 3d diffusion
Minghua Liu, Ruoxi Shi, Linghao Chen, Zhuoyang Zhang, Chao Xu, Xinyue Wei, Hansheng Chen, Chong Zeng, Jiayuan Gu, and Hao Su. One-2-3-45++: Fast single image to 3d objects with consistent multi-view generation and 3d diffusion. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10072–10083, 2024
2024
-
[31]
Fantasia3d: Disentangling geometry and appearance for high-quality text-to-3d content creation
Rui Chen, Yongwei Chen, Ningxin Jiao, and Kui Jia. Fantasia3d: Disentangling geometry and appearance for high-quality text-to-3d content creation. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 22246–22256, 2023
2023
-
[32]
Ln3diff: Scalable latent neural fields diffusion for speedy 3d generation
Yushi Lan, Fangzhou Hong, Shuai Yang, Shangchen Zhou, Xuyi Meng, Bo Dai, Xingang Pan, and Chen Change Loy. Ln3diff: Scalable latent neural fields diffusion for speedy 3d generation. InEuropean Conference on Computer Vision, pages 112–130. Springer, 2024
2024
-
[33]
Gaussiananything: Interactive point cloud latent diffusion for 3d generation
Yushi Lan, Shangchen Zhou, Zhaoyang Lyu, Fangzhou Hong, Shuai Yang, Bo Dai, Xingang Pan, and Chen Change Loy. Gaussiananything: Interactive point cloud latent diffusion for 3d generation. In International Conference on Learning Representations, 2025
2025
-
[34]
Structured 3d latents for scalable and versatile 3d generation.arXiv preprint arXiv:2412.01506, 2024
Jianfeng Xiang, Zelong Lv, Sicheng Xu, Yu Deng, Ruicheng Wang, Bowen Zhang, Dong Chen, Xin Tong, and Jiaolong Yang. Structured 3d latents for scalable and versatile 3d generation.arXiv preprint arXiv:2412.01506, 2024
Pith/arXiv arXiv 2024
-
[35]
3dtopia-xl: High-quality 3d pbr asset generation via primitive diffusion
Zhaoxi Chen, Jiaxiang Tang, Yuhao Dong, Ziang Cao, Fangzhou Hong, Yushi Lan, Tengfei Wang, Haozhe Xie, Tong Wu, Shunsuke Saito, Liang Pan, Dahua Lin, and Ziwei Liu. 3dtopia-xl: High-quality 3d pbr asset generation via primitive diffusion. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2025. 11
2025
-
[36]
Structured 3d latents for scalable and versatile 3d generation
Jianfeng Xiang, Zelong Lv, Sicheng Xu, Yu Deng, Ruicheng Wang, Bowen Zhang, Dong Chen, Xin Tong, and Jiaolong Yang. Structured 3d latents for scalable and versatile 3d generation. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2025
2025
-
[37]
Yangguang Li, Zi-Xin Zou, Zexiang Liu, Dehu Wang, Yuan Liang, Zhipeng Yu, Xingchao Liu, Yuan-Chen Guo, Ding Liang, Wanli Ouyang, et al. Triposg: High-fidelity 3d shape synthesis using large-scale rectified flow models.arXiv preprint arXiv:2502.06608, 2025
Pith/arXiv arXiv 2025
-
[38]
Sar3d: Autoregressive 3d object generation and understanding via multi-scale 3d vqvae
Yongwei Chen, Yushi Lan, Shangchen Zhou, Tengfei Wang, and Xingang Pan. Sar3d: Autoregressive 3d object generation and understanding via multi-scale 3d vqvae. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2025
2025
-
[39]
Xianghui Yang, Huiwen Shi, Bowen Zhang, Fan Yang, Jiacheng Wang, Hongxu Zhao, Xinhai Liu, Xinzhou Wang, Qingxiang Lin, Jiaao Yu, et al. Hunyuan3d 1.0: A unified framework for text-to-3d and image-to-3d generation.arXiv preprint arXiv:2411.02293, 2024
arXiv 2024
-
[40]
Objaverse: A universe of annotated 3d objects
Matt Deitke, Dustin Schwenk, Jordi Salvador, Luca Weihs, Oscar Michel, Eli VanderBilt, Ludwig Schmidt, Kiana Ehsani, Aniruddha Kembhavi, and Ali Farhadi. Objaverse: A universe of annotated 3d objects. arXiv preprint arXiv:2212.08051, 2022
arXiv 2022
-
[41]
Objaverse-xl: A universe of 10m+ 3d objects.arXiv preprint arXiv:2307.05663, 2023
Matt Deitke, Ruoshi Liu, Matthew Wallingford, Huong Ngo, Oscar Michel, Aditya Kusupati, Alan Fan, Christian Laforte, Vikram V oleti, Samir Yitzhak Gadre, Eli VanderBilt, Aniruddha Kembhavi, Carl V ondrick, Georgia Gkioxari, Kiana Ehsani, Ludwig Schmidt, and Ali Farhadi. Objaverse-xl: A universe of 10m+ 3d objects.arXiv preprint arXiv:2307.05663, 2023
Pith/arXiv arXiv 2023
-
[42]
Ultra3d: Efficient and high-fidelity 3d generation with part attention, 2025
Yiwen Chen, Zhihao Li, Yikai Wang, Hu Zhang, Qin Li, Chi Zhang, and Guosheng Lin. Ultra3d: Efficient and high-fidelity 3d generation with part attention, 2025
2025
-
[43]
Fullpart: Generating each 3d part at full resolution
Lihe Ding, Shaocong Dong, Yaokun Li, Chenjian Gao, Xiao Chen, Rui Han, Yihao Kuang, Hong Zhang, Bo Huang, Zhanpeng Huang, Zibin Wang, Dan Xu, and Tianfan Xue. Fullpart: Generating each 3d part at full resolution. InThe F ourteenth International Conference on Learning Representations, 2026
2026
-
[44]
X-part: high fidelity and structure coherent shape decomposition, 2025
Xinhao Yan, Jiachen Xu, Yang Li, Changfeng Ma, Yunhan Yang, Chunshi Wang, Zibo Zhao, Zeqiang Lai, Yunfei Zhao, Zhuo Chen, and Chunchao Guo. X-part: high fidelity and structure coherent shape decomposition, 2025
2025
-
[45]
Jiaxiang Tang, Ruijie Lu, Zhaoshuo Li, Zekun Hao, Xuan Li, Fangyin Wei, Shuran Song, Gang Zeng, Ming-Yu Liu, and Tsung-Yi Lin. Efficient part-level 3d object generation via dual volume packing.arXiv preprint arXiv:2506.09980, 2025
arXiv 2025
-
[46]
Tobias Sautter, Jan-Niklas Dihlmann, and Hendrik Lensch. 3d-re-gen: 3d reconstruction of indoor scenes with a generative framework.arXiv preprint arXiv:2512.17459, 2025
arXiv 2025
-
[47]
Yukai Shi, Weiyu Li, Zihao Wang, Hongyang Li, Xingyu Chen, Ping Tan, and Lei Zhang. Scenemaker: Open-set 3d scene generation with decoupled de-occlusion and pose estimation model.arXiv preprint arXiv:2512.10957, 2025
arXiv 2025
-
[48]
Buol: A bottom-up framework with occupancy-aware lifting for panoptic 3d scene reconstruction from a single image
Tao Chu, Pan Zhang, Qiong Liu, and Jiaqi Wang. Buol: A bottom-up framework with occupancy-aware lifting for panoptic 3d scene reconstruction from a single image. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 4937–4946, 2023
2023
-
[49]
Metascenes: Towards automated replica creation for real-world 3d scans
Huangyue Yu, Baoxiong Jia, Yixin Chen, Yandan Yang, Puhao Li, Rongpeng Su, Jiaxin Li, Qing Li, Wei Liang, Zhu Song-Chun, Tengyu Liu, and Siyuan Huang. Metascenes: Towards automated replica creation for real-world 3d scans. InProceedings of the Computer Vision and Pattern Recognition Conference, 2025
2025
-
[50]
Cast: Component-aligned 3d scene reconstruction from an rgb image
Kaixin Yao, Longwen Zhang, Xinhao Yan, Yan Zeng, Qixuan Zhang, Wei Yang, Lan Xu, Jiayuan Gu, and Jingyi Yu. Cast: Component-aligned 3d scene reconstruction from an rgb image. InACM SIGGRAPH Conference, 2025
2025
-
[51]
Wenqi Dong, Bangbang Yang, Zesong Yang, Yuan Li, Tao Hu, Hujun Bao, Yuewen Ma, and Zhaopeng Cui. Hiscene: creating hierarchical 3d scenes with isometric view generation.arXiv preprint arXiv:2504.13072, 2025
arXiv 2025
-
[52]
Xiang Tang, Ruotong Li, and Xiaopeng Fan. Towards geometric and textural consistency 3d scene genera- tion via single image-guided model generation and layout optimization.arXiv preprint arXiv:2507.14841, 2025. 12
arXiv 2025
-
[53]
Commonscenes: Generating commonsense 3d indoor scenes with scene graph diffusion
Guangyao Zhai, Evin Pınar Örnek, Shun-Cheng Wu, Yan Di, Federico Tombari, Nassir Navab, and Benjamin Busam. Commonscenes: Generating commonsense 3d indoor scenes with scene graph diffusion. InConference on Neural Information Processing Systems, 2023
2023
-
[54]
Artiscene: Language-driven artistic 3d scene generation through image intermediary
Zeqi Gu, Yin Cui, Zhaoshuo Li, Fangyin Wei, Yunhao Ge, Jinwei Gu, Ming-Yu Liu, Abe Davis, and Yifan Ding. Artiscene: Language-driven artistic 3d scene generation through image intermediary. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2025
2025
-
[55]
Lu Ling, Chen-Hsuan Lin, Tsung-Yi Lin, Yifan Ding, Yu Zeng, Yichen Sheng, Yunhao Ge, Ming-Yu Liu, Aniket Bera, and Zhaoshuo Li. Scenethesis: A language and vision agentic framework for 3d scene generation.arXiv preprint arXiv:2505.02836, 2025
arXiv 2025
-
[56]
Layoutgpt: Compositional visual planning and generation with large language models
Weixi Feng, Wanrong Zhu, Tsu-jui Fu, Varun Jampani, Arjun Akula, Xuehai He, Sugato Basu, Xin Eric Wang, and William Yang Wang. Layoutgpt: Compositional visual planning and generation with large language models. InConference on Neural Information Processing Systems, 2023
2023
-
[57]
Holodeck: Language guided generation of 3d embodied ai environments
Yue Yang, Fan-Yun Sun, Luca Weihs, Eli VanderBilt, Alvaro Herrasti, Winson Han, Jiajun Wu, Nick Haber, Ranjay Krishna, Lingjie Liu, et al. Holodeck: Language guided generation of 3d embodied ai environments. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2024
2024
-
[58]
Agentic 3d scene generation with spatially contextualized vlms.arXiv preprint arXiv:2505.20129, 2025
Xinhang Liu, Yu-Wing Tai, and Chi-Keung Tang. Agentic 3d scene generation with spatially contextualized vlms.arXiv preprint arXiv:2505.20129, 2025
arXiv 2025
-
[59]
Hunyuanworld 1.0: Generating immersive, explorable, and interactive 3d worlds from words or pixels.arXiv preprint, 2025
Team HunyuanWorld. Hunyuanworld 1.0: Generating immersive, explorable, and interactive 3d worlds from words or pixels.arXiv preprint, 2025
2025
-
[60]
Blenderalchemy: Editing 3d graphics with vision- language models
Ian Huang, Guandao Yang, and Leonidas Guibas. Blenderalchemy: Editing 3d graphics with vision- language models. InEuropean Conference on Computer Vision, pages 297–314. Springer, 2024
2024
-
[61]
Grounded sam: Assembling open-world models for diverse visual tasks, 2024
Tianhe Ren, Shilong Liu, Ailing Zeng, Jing Lin, Kunchang Li, He Cao, Jiayu Chen, Xinyu Huang, Yukang Chen, Feng Yan, Zhaoyang Zeng, Hao Zhang, Feng Li, Jie Yang, Hongyang Li, Qing Jiang, and Lei Zhang. Grounded sam: Assembling open-world models for diverse visual tasks, 2024
2024
-
[62]
Scannet: Richly-annotated 3d reconstructions of indoor scenes
Angela Dai, Angel X Chang, Manolis Savva, Maciej Halber, Thomas Funkhouser, and Matthias Nießner. Scannet: Richly-annotated 3d reconstructions of indoor scenes. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2017
2017
-
[63]
Microsoft coco: Common objects in context
Tsung-Yi Lin, Michael Maire, Serge Belongie, et al. Microsoft coco: Common objects in context. In European Conference on Computer Vision (ECCV), 2014
2014
-
[64]
Claude [large language model], 2025
Anthropic. Claude [large language model], 2025
2025
-
[65]
Codex [large language model], 2026
OpenAI. Codex [large language model], 2026
2026
-
[66]
Qwen3.5: Towards native multimodal agents, February 2026
Qwen Team. Qwen3.5: Towards native multimodal agents, February 2026
2026
-
[67]
Recognizing indoor scenes
Ariadna Quattoni and Antonio Torralba. Recognizing indoor scenes. In2009 IEEE conference on computer vision and pattern recognition, pages 413–420. IEEE, 2009
2009
-
[68]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. InProceedings of the International Conference on Machine Learning, 2021. 13
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.