FiberTune: Preserving Action-Fiber Visual Residuals in Vision-Language-Action Fine-Tuning
Pith reviewed 2026-06-27 18:40 UTC · model grok-4.3
The pith
Action-supervised fine-tuning of vision-language-action policies allows visual structure to collapse along action fibers, but FiberTune prevents this by filtering action-predictive directions and aligning the remaining residuals to a frozen
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
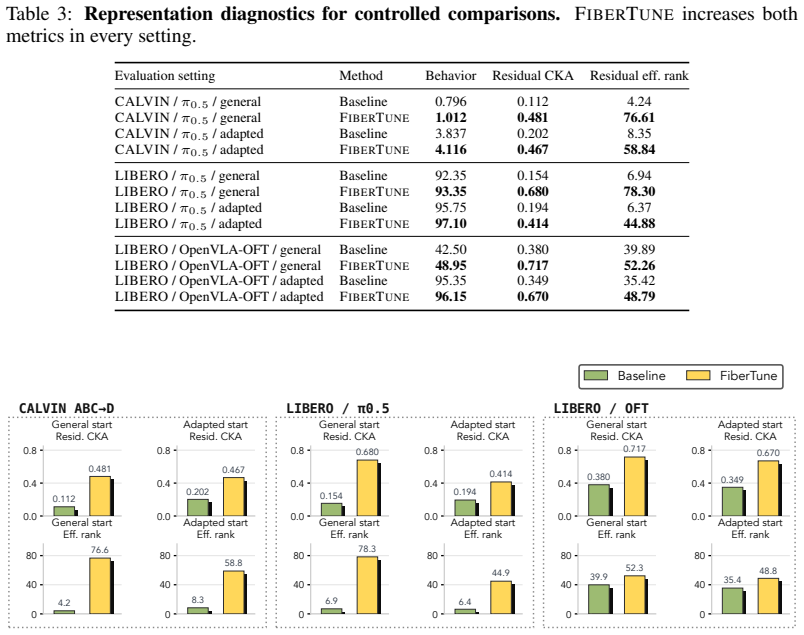
Action-supervised fine-tuning of vision-language-action policies fits demonstrations effectively but constrains only the directions that change predicted actions, leaving visual structure consistent across action-equivalent states free to collapse. This is formalized as residual visual collapse along local action fibers. FiberTune uses an online action probe to estimate action-predictive feature directions, filters them from intermediate visual-token representations, and aligns the resulting probe-filtered residuals to a frozen visual teacher while regularizing their effective rank, preserving teacher-structured visual residuals without adding inference-time overhead.
What carries the argument
The probe-filtered residual alignment objective, which removes estimated action-predictive directions from visual tokens before aligning the residuals to a frozen teacher and regularizing rank.
If this is right
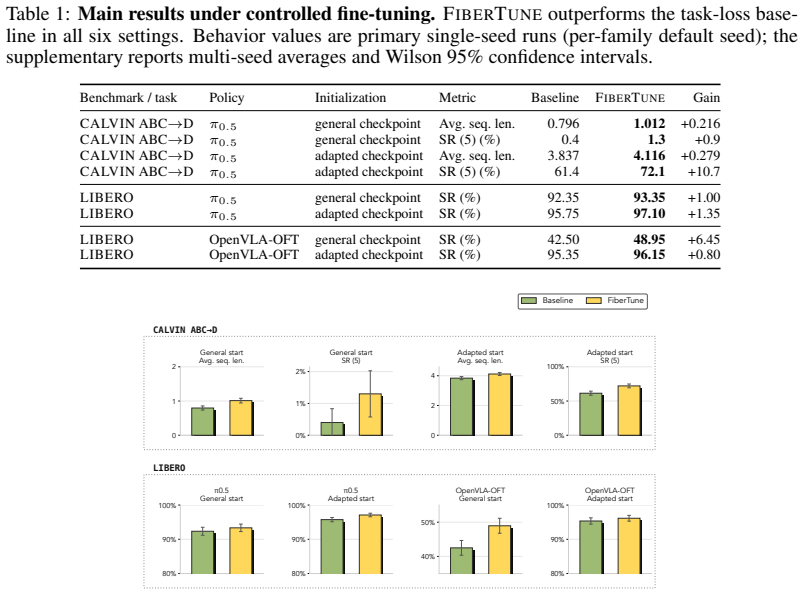
- Performance improves over task-loss-only fine-tuning in every one of six controlled simulation settings spanning two benchmarks and two architectures.
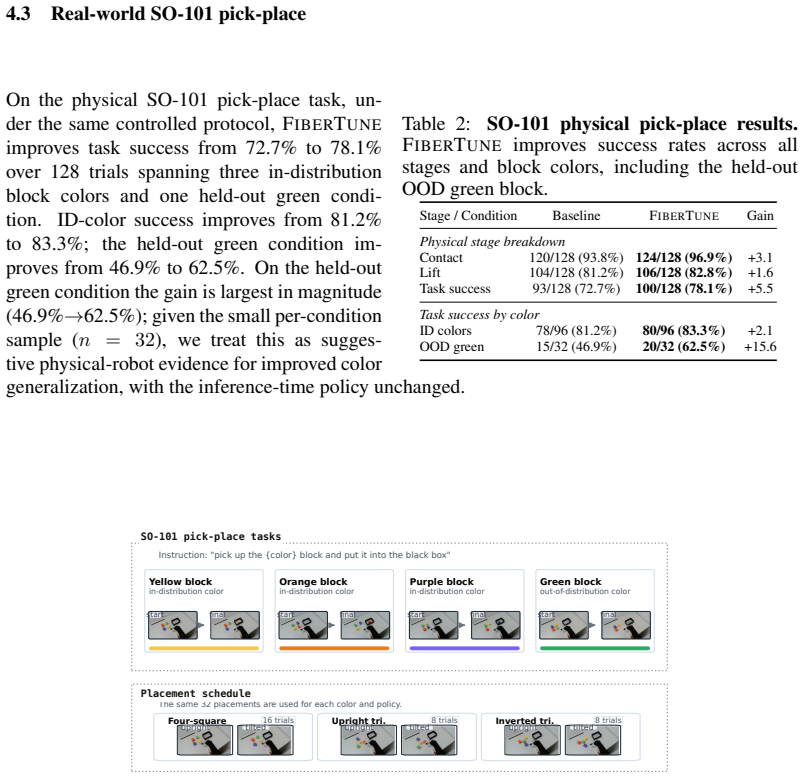
- Physical robot task success on SO-101 pick-place rises from 72.7% to 78.1%.
- Gains coincide with increased probe-filtered residual teacher alignment and effective rank.
- The method applies to pi_0.5 and OpenVLA-OFT without inference overhead.
- Long-horizon success rate SR(5) on CALVIN ABC-to-D increases by 10.7 percentage points.
Where Pith is reading between the lines
- The same filtering-plus-alignment pattern could be tested in other multimodal fine-tuning settings where supervision on outputs risks collapsing input representations that are invariant to those outputs.
- A static rather than online probe might simplify implementation while retaining similar benefits if the action-predictive directions are stable across training.
- The rank regularization term may combine with existing techniques such as weight decay or dropout to further stabilize visual features during adaptation.
- Applying the method to additional robot platforms would test whether the action-fiber structure is consistent across embodiments.
Load-bearing premise
An online action probe can reliably estimate action-predictive feature directions so that filtering them and aligning the residuals actually prevents harmful collapse without losing task-relevant information.
What would settle it
An ablation that applies the full FiberTune objective but disables the residual alignment loss and finds that performance gains over task-loss-only fine-tuning disappear would indicate the preservation mechanism is not responsible for the reported improvements.
Figures

read the original abstract
Action-supervised fine-tuning of vision-language-action (VLA) policies fits demonstrations effectively but constrains only the directions that change predicted actions, leaving visual structure consistent across action-equivalent states free to collapse. We formalize this as residual visual collapse along local action fibers and propose FiberTune, a training-time objective that preserves teacher-structured visual residuals without adding inference-time overhead. FiberTune uses an online action probe to estimate action-predictive feature directions, filters them from intermediate visual-token representations, and aligns the resulting probe-filtered residuals to a frozen visual teacher while regularizing their effective rank. Under identical training conditions, FiberTune improves over task-loss-only fine-tuning in every one of six controlled simulation settings spanning two benchmarks and two architectures (pi_0.5 and OpenVLA-OFT), as well as on physical SO-101 pick-place; representative gains include +10.7 percentage points SR(5) on long-horizon CALVIN ABC-to-D and physical SO-101 task success rising from 72.7% to 78.1%. Residual diagnostics show that these gains coincide with increased probe-filtered residual teacher alignment and effective rank, consistent with the action-fiber motivation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that standard action-supervised fine-tuning of VLA policies constrains only action-changing directions and allows visual structure to collapse along local action fibers. It proposes FiberTune, a training-time objective that deploys an online action probe to estimate and filter action-predictive directions from intermediate visual tokens, aligns the resulting residuals to a frozen visual teacher, and regularizes their effective rank. Under identical training conditions the method yields consistent gains over task-loss-only baselines across six simulation settings (two benchmarks, two architectures) plus a physical SO-101 pick-place task, with representative improvements of +10.7 pp SR(5) on CALVIN ABC-to-D and 72.7 % to 78.1 % success on the physical task; these gains correlate with higher probe-filtered residual alignment and rank.
Significance. If the central claim holds, FiberTune offers a practical, inference-free way to mitigate an under-appreciated form of visual collapse in VLA fine-tuning. The multi-benchmark, multi-architecture, and physical-robot validation is a clear strength, as is the explicit link between the proposed objective and the observed residual diagnostics. The work directly addresses a concrete failure mode that arises under standard imitation objectives.
major comments (2)
- Abstract: the reported performance gains (e.g., +10.7 pp SR(5) on CALVIN ABC-to-D and the physical SO-101 lift from 72.7 % to 78.1 %) are presented without error bars, number of runs, statistical significance tests, or explicit data-split details. This information is load-bearing for the claim of consistent improvement across all six controlled settings.
- Method description of the online action probe: the architecture, loss function, and update schedule of the probe are not specified. Because the central claim rests on the probe correctly isolating only action-predictive directions so that residual alignment preserves task-relevant structure, the absence of these details leaves open the possibility that the probe itself (rather than the alignment step) is responsible for the observed difference, exactly as flagged by the stress-test concern.
minor comments (1)
- Abstract: the phrase 'representative gains' would be clearer if accompanied by a short table or explicit list of all six simulation results rather than a single example.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on result presentation and methodological transparency. We respond point-by-point to the major comments below.
read point-by-point responses
-
Referee: Abstract: the reported performance gains (e.g., +10.7 pp SR(5) on CALVIN ABC-to-D and the physical SO-101 lift from 72.7 % to 78.1 %) are presented without error bars, number of runs, statistical significance tests, or explicit data-split details. This information is load-bearing for the claim of consistent improvement across all six controlled settings.
Authors: We agree that these details are necessary to support the consistency claim. In the revised manuscript we will report the number of runs (typically three random seeds), include error bars or standard deviations on the key metrics, note any statistical significance tests performed, and make data-split details explicit in the experimental section; a concise reference to run count will be added to the abstract where space permits. revision: yes
-
Referee: Method description of the online action probe: the architecture, loss function, and update schedule of the probe are not specified. Because the central claim rests on the probe correctly isolating only action-predictive directions so that residual alignment preserves task-relevant structure, the absence of these details leaves open the possibility that the probe itself (rather than the alignment step) is responsible for the observed difference, exactly as flagged by the stress-test concern.
Authors: We acknowledge that the current manuscript does not provide sufficient specification of the online action probe. We will expand the method section in the revision to fully describe the probe architecture, its loss function, and update schedule, and we will add analysis or controlled experiments to address the stress-test concern and clarify the distinct contribution of the alignment step. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper presents FiberTune as an independent additive objective (online probe to filter action-predictive directions, residual alignment to frozen teacher, rank regularization) on top of standard task-loss fine-tuning. Reported gains are empirical results from controlled experiments across benchmarks and architectures, not quantities obtained by fitting parameters to the same performance metrics or by renaming fitted inputs as predictions. No self-definitional equations, load-bearing self-citations, or uniqueness theorems imported from prior author work appear in the provided text. The alignment/rank diagnostics are post-hoc observations, not part of a closed derivation that reduces to the inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
M. Ahn, A. Brohan, N. Brown, Y . Chebotar, O. Cortes, B. David, C. Finn, C. Fu, K. Gopalakr- ishnan, K. Hausman, et al. Do as i can, not as i say: Grounding language in robotic affordances. arXiv preprint arXiv:2204.01691, 2022
Pith/arXiv arXiv 2022
-
[2]
E. Jang, A. Irpan, M. Khansari, D. Kappler, F. Ebert, C. Lynch, S. Levine, and C. Finn. Bc-z: Zero-shot task generalization with robotic imitation learning. InConference on Robot Learn- ing, pages 991–1002. PMLR, 2022
2022
-
[3]
Jiang, A
Y . Jiang, A. Gupta, Z. Zhang, G. Wang, Y . Dou, Y . Chen, L. Fei-Fei, A. Anandkumar, Y . Zhu, and L. Fan. VIMA: Robot manipulation with multimodal prompts. InInternational Conference on Machine Learning, pages 14975–15022, 2023
2023
-
[4]
Driess, F
D. Driess, F. Xia, M. S. M. Sajjadi, C. Lynch, A. Chowdhery, B. Ichter, A. Wahid, J. Tompson, Q. Vuong, T. Yu, et al. Palm-e: An embodied multimodal language model. InInternational Conference on Machine Learning, pages 8469–8488, 2023
2023
-
[5]
RT-1: Robotics transformer for real-world control at scale,
A. Brohan, N. Brown, J. Carbajal, Y . Chebotar, J. Dabis, C. Finn, K. Gopalakrishnan, K. Haus- man, A. Herzog, J. Hsu, et al. Rt-1: Robotics transformer for real-world control at scale. In Robotics: Science and Systems, 2023. doi:10.15607/rss.2023.xix.025
-
[6]
Brohan, N
A. Brohan, N. Brown, J. Carbajal, Y . Chebotar, X. Chen, K. Choromanski, T. Ding, D. Driess, A. Dubey, C. Finn, et al. RT-2: Vision-language-action models transfer web knowledge to robotic control. InProceedings of the Conference on Robot Learning, 2023
2023
-
[7]
X. Li, M. Liu, H. Zhang, C. Yu, J. Xu, H. Wu, C. Cheang, Y . Jing, W. Zhang, H. Liu, et al. Vision-language foundation models as effective robot imitators. InInternational Conference on Learning Representations, 2024
2024
-
[8]
M. J. Kim, K. Pertsch, S. Karamcheti, T. Xiao, A. Balakrishna, S. Nair, R. Rafailov, E. Foster, G. Lam, P. Sanketi, Q. Vuong, T. Kollar, B. Burchfiel, R. Tedrake, D. Sadigh, S. Levine, P. Liang, and C. Finn. Openvla: An open-source vision-language-action model. InProceedings of the Conference on Robot Learning, 2024
2024
-
[9]
M. J. Kim, C. Finn, and P. Liang. Fine-tuning vision-language-action models: Optimizing speed and success.arXiv preprint arXiv:2502.19645, 2025
Pith/arXiv arXiv 2025
-
[10]
Ghosh, H
Octo Model Team, D. Ghosh, H. Walke, K. Pertsch, K. Black, O. Mees, S. Dasari, J. Hejna, C. Xu, T. Kreiman, Y . L. Tan, L. Y . Chen, P. Sanketi, Q. Vuong, T. Xiao, D. Sadigh, C. Finn, and S. Levine. Octo: An open-source generalist robot policy. InRobotics: Science and Systems, 2024
2024
-
[11]
Q. Li, Y . Liang, Z. Wang, L. Luo, X. Chen, M. Liao, F. Wei, Y . Deng, S. Xu, Y . Zhang, et al. CogACT: A foundational vision-language-action model for synergizing cognition and action in robotic manipulation.arXiv preprint arXiv:2411.19650, 2024
Pith/arXiv arXiv 2024
-
[12]
K. Black, N. Brown, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusai, L. Groom, K. Haus- man, B. Ichter, S. Jakubczak, T. Jones, L. Ke, S. Levine, A. Li-Bell, M. Mothukuri, S. Nair, K. Pertsch, L. X. Shi, J. Tanner, Q. Vuong, A. Walling, H. Wang, and U. Zhilinsky.π 0: A vision-language-action flow model for general robot control.arXiv preprint arXiv:2410....
Pith/arXiv arXiv 2024
-
[13]
Physical Intelligence, K. Black, N. Brown, J. Darpinian, K. Dhabalia, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusai, M. Y . Galliker, D. Ghosh, L. Groom, K. Hausman, B. Ichter, S. Jakubczak, T. Jones, L. Ke, D. LeBlanc, S. Levine, A. Li-Bell, M. Mothukuri, S. Nair, K. Pertsch, A. Z. Ren, L. X. Shi, L. Smith, J. T. Springenberg, K. Stachowicz, J. Tanner...
Pith/arXiv arXiv 2025
-
[14]
N. Kachaev, M. Kolosov, D. Zelezetsky, A. K. Kovalev, and A. I. Panov. Don’t blind your vla: Aligning visual representations for ood generalization.arXiv preprint arXiv:2510.25616, 2025
arXiv 2025
-
[15]
Zhang, X.-H
Z. Zhang, X.-H. Chen, Y . Wang, Y . Sun, W. Luo, H. Ren, H. Lin, and Y . Yu. On the represen- tation degradation in vision-language-action models.OpenReview, 2025
2025
- [16]
-
[17]
Y . Chen, S. Tian, S. Liu, Y . Zhou, H. Li, and D. Zhao. Conrft: A reinforced fine-tuning method for vla models via consistency policy.arXiv preprint arXiv:2502.05450, 2025
arXiv 2025
- [18]
-
[19]
Y . Fan, P. Ding, S. Bai, X. Tong, Y . Zhu, H. Lu, F. Dai, W. Zhao, Y . Liu, S. Huang, Z. Fan, B. Chen, and D. Wang. Long-vla: Unleashing long-horizon capability of vision language action model for robot manipulation.arXiv preprint arXiv:2508.19958, 2025
arXiv 2025
-
[20]
T. Z. Zhao, V . Kumar, S. Levine, and C. Finn. Learning fine-grained bimanual manipulation with low-cost hardware. InRobotics: Science and Systems, 2023. doi:10.15607/rss.2023.xix. 016
-
[21]
C. Chi, S. Feng, Y . Du, Z. Xu, E. Cousineau, B. Burchfiel, and S. Song. Diffusion policy: Visuomotor policy learning via action diffusion. InRobotics: Science and Systems, 2023
2023
-
[22]
K. Pertsch, K. Stachowicz, B. Ichter, D. Driess, S. Nair, Q. Vuong, O. Mees, C. Finn, and S. Levine. FAST: Efficient action tokenization for vision-language-action models.arXiv preprint arXiv:2501.09747, 2025
Pith/arXiv arXiv 2025
-
[23]
F. Li, W. Song, H. Zhao, J. Wang, P. Ding, D. Wang, L. Zeng, and H. Li. Spatial forcing: Implicit spatial representation alignment for vision-language-action model.arXiv preprint arXiv:2510.12276, 2025
arXiv 2025
-
[24]
T. Kim, J. Lee, M. Koo, D. Kim, K. Lee, C. Kim, Y . Seo, and J. Shin. Contrastive representation regularization for vision-language-action models.arXiv preprint arXiv:2510.01711, 2025
Pith/arXiv arXiv 2025
-
[25]
Tishby, F
N. Tishby, F. C. Pereira, and W. Bialek. The information bottleneck method. InProceedings of the 37th Annual Allerton Conference on Communication, Control, and Computing, 1999
1999
-
[26]
S. Bai, W. Zhou, P. Ding, W. Zhao, D. Wang, and B. Chen. Rethinking latent redundancy in behavior cloning: An information bottleneck approach for robot manipulation.arXiv preprint arXiv:2502.02853, 2025
arXiv 2025
-
[27]
S. Lian, B. Yu, X. Lin, L. T. Yang, Z. Shen, C. Wu, Y . Miao, C. Huang, and K. Chen. Langforce: Bayesian decomposition of vision language action models via latent action queries.arXiv preprint arXiv:2601.15197, 2026
Pith/arXiv arXiv 2026
-
[28]
Garrido, R
Q. Garrido, R. Balestriero, L. Najman, and Y . LeCun. Rankme: Assessing the downstream performance of pretrained self-supervised representations by their rank. InInternational Con- ference on Machine Learning, pages 10929–10974, 2023
2023
-
[29]
Bardes, J
A. Bardes, J. Ponce, and Y . LeCun. Vicreg: Variance-invariance-covariance regularization for self-supervised learning. InInternational Conference on Learning Representations, 2022
2022
-
[30]
Zbontar, L
J. Zbontar, L. Jing, I. Misra, Y . LeCun, and S. Deny. Barlow twins: Self-supervised learning via redundancy reduction. InInternational Conference on Machine Learning, 2021. 11
2021
-
[31]
Kornblith, M
S. Kornblith, M. Norouzi, H. Lee, and G. Hinton. Similarity of neural network representations revisited. InInternational Conference on Machine Learning, 2019
2019
-
[32]
O. Mees, L. Hermann, E. Rosete-Beas, and W. Burgard. Calvin: A benchmark for language- conditioned policy learning for long-horizon robot manipulation tasks.IEEE Robotics and Automation Letters, 7(3):7327–7334, 2022
2022
-
[33]
B. Liu, Y . Zhu, C. Gao, Y . Feng, Q. Liu, Y . Zhu, and P. Stone. Libero: Benchmarking knowl- edge transfer for lifelong robot learning. InAdvances in Neural Information Processing Sys- tems, 2023
2023
-
[34]
R. Cadene, S. Alibert, F. Capuano, M. Aractingi, A. Zouitine, P. Kooijmans, J. Choghari, M. Russi, C. Pascal, S. Palma, D. Aubakirova, M. Shukor, J. Moss, A. Soare, Q. Lhoest, Q. Gallou´edec, and T. Wolf. Lerobot: An open-source library for end-to-end robot learning. InThe Fourteenth International Conference on Learning Representations, 2026. URLhttps: //...
arXiv 2026
-
[35]
C. Yu, Y . Wang, Z. Guo, H. Lin, S. Xu, H. Zang, Q. Zhang, Y . Wu, C. Zhu, J. Hu, et al. Rlinf: Flexible and efficient large-scale reinforcement learning via macro-to-micro flow transforma- tion.arXiv preprint arXiv:2509.15965, 2025
arXiv 2025
-
[36]
H. Zang, M. Wei, S. Xu, Y . Wu, Z. Guo, Y . Wang, H. Lin, P. Wang, L. Shi, Y . Xie, Z. Xu, et al. Rlinf-vla: A unified and efficient framework for reinforcement learning of vision-language- action models.arXiv preprint arXiv:2510.06710, 2025
arXiv 2025
-
[37]
T. M. Cover and J. A. Thomas.Elements of Information Theory. Wiley-Interscience, 2 edition, 2006
2006
-
[38]
K. V . Mardia and P. E. Jupp.Directional Statistics. Wiley Series in Probability and Statistics. John Wiley & Sons, 1999. doi:10.1002/9780470316979
-
[39]
Heinrich, M
G. Heinrich, M. Ranzinger, H. Yin, Y . Lu, J. Kautz, A. Tao, B. Catanzaro, and P. Molchanov. RADIOv2.5: Improved baselines for agglomerative vision foundation models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 22487– 22497, 2025
2025
-
[40]
J. Bjorck, F. Casta ˜neda, N. Cherniadev, X. Da, R. Ding, L. Fan, Y . Fang, D. Fox, F. Hu, S. Huang, et al. GR00T N1: An open foundation model for generalist humanoid robots.arXiv preprint arXiv:2503.14734, 2025. 12 A Technical details A.1 From ideal orthogonal residuals to probe-filtered residuals For a sample(v, ℓ, a), FIBERTUNEoperates on an intermedia...
Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.