A multi-agent system for spine MRI report generation from multi-sequence imaging
Pith reviewed 2026-06-27 17:32 UTC · model grok-4.3
The pith
SpineAgent generates spine MRI reports by pre-training T1 and T2 encoders and learning a synthesizer to embed other sequences into unified patient-level representations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
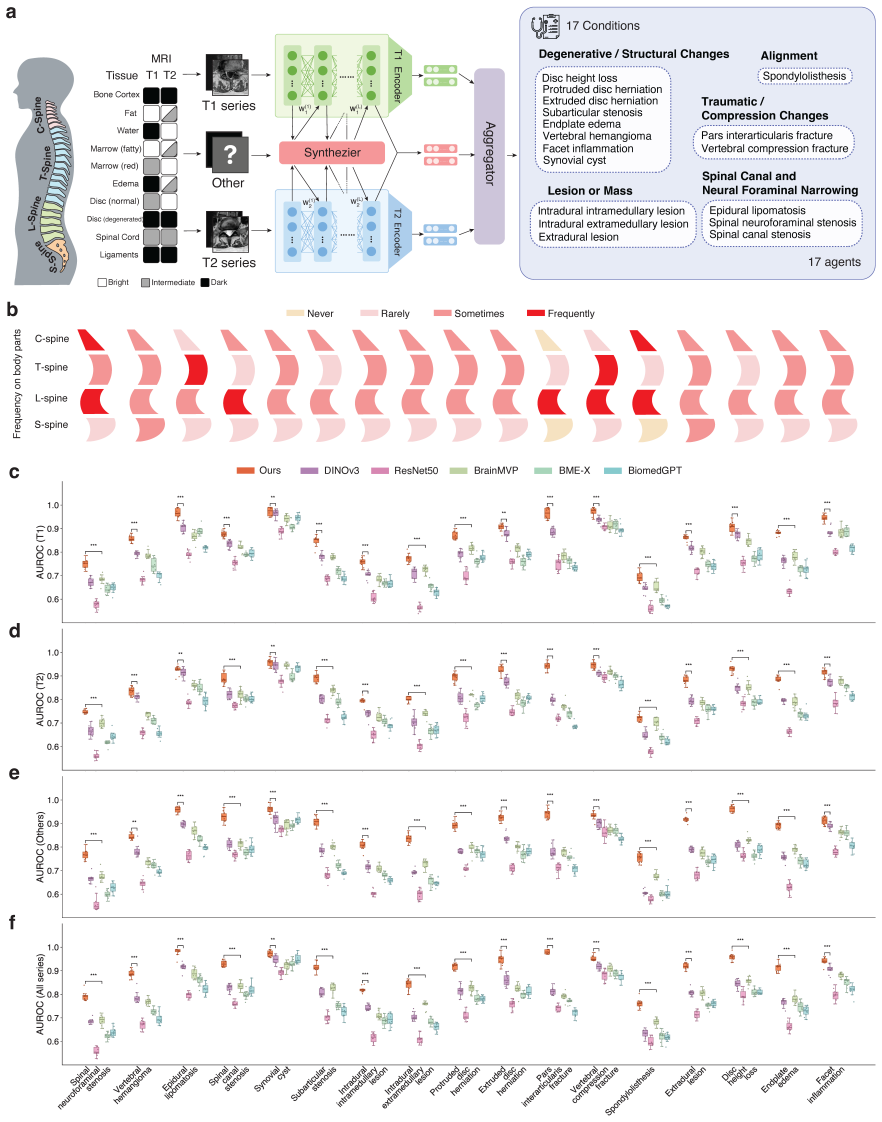
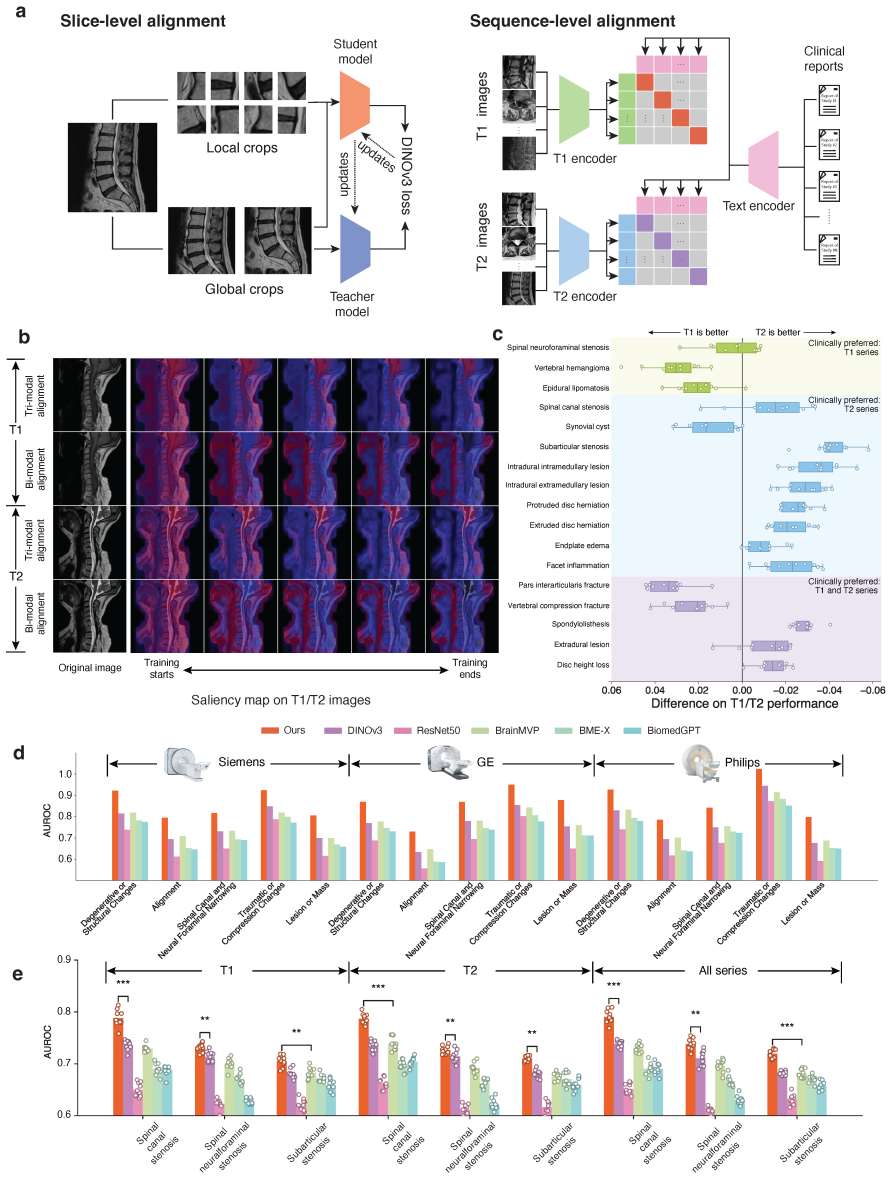
SpineAgent achieves state-of-the-art performance in spine MRI report generation and demonstrates strong generalizability under cross-manufacturer and cross-cohort evaluation by building a multi-sequence foundation model that pre-trains DINOv3-based encoders separately on T1- and T2-weighted sequences and introduces a continual training strategy that learns a synthesizer to embed images of other sequences, producing patient-level embeddings that integrate various signals across MRI sequences.
What carries the argument
The synthesizer learned through continual training, which embeds images of other sequences using the T1 and T2 encoders to produce patient-level embeddings that integrate signals across sequences.
If this is right
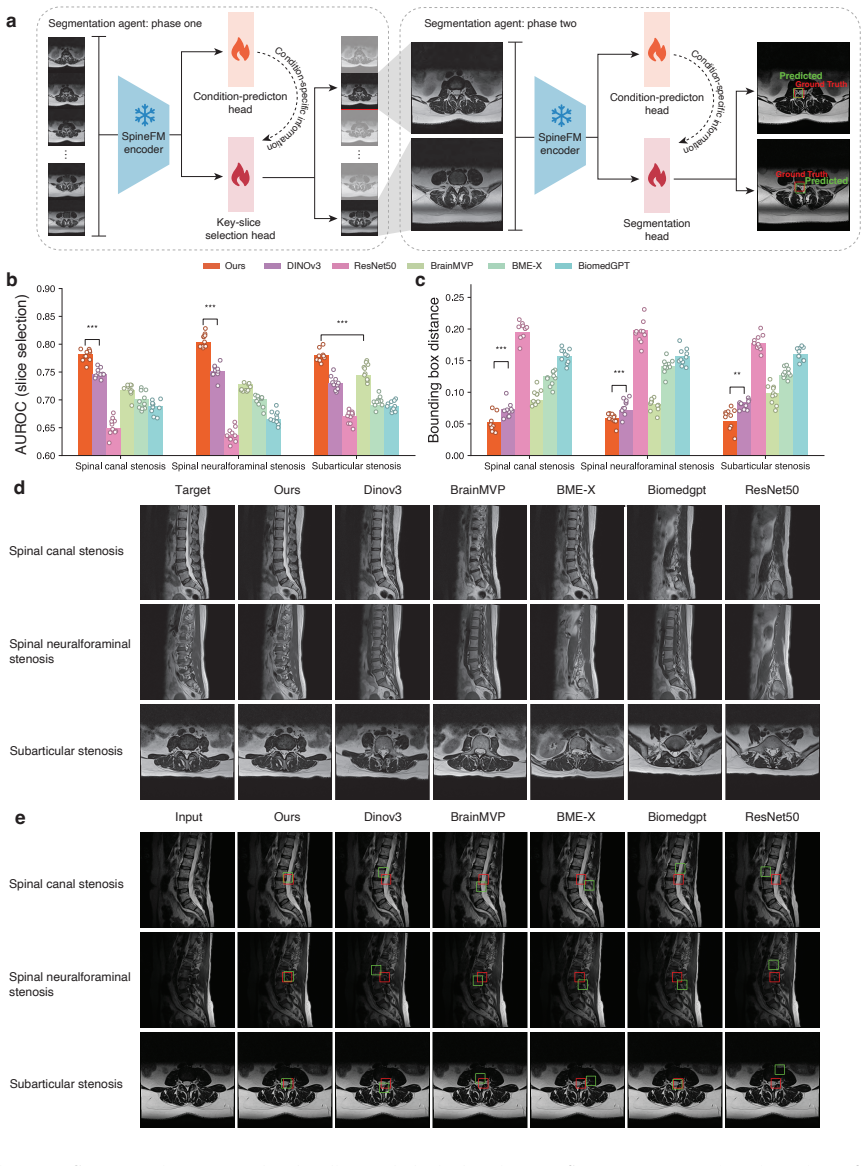
- The framework enables pathology localization through identification of findings-relevant slices and segmentation of pathological regions.
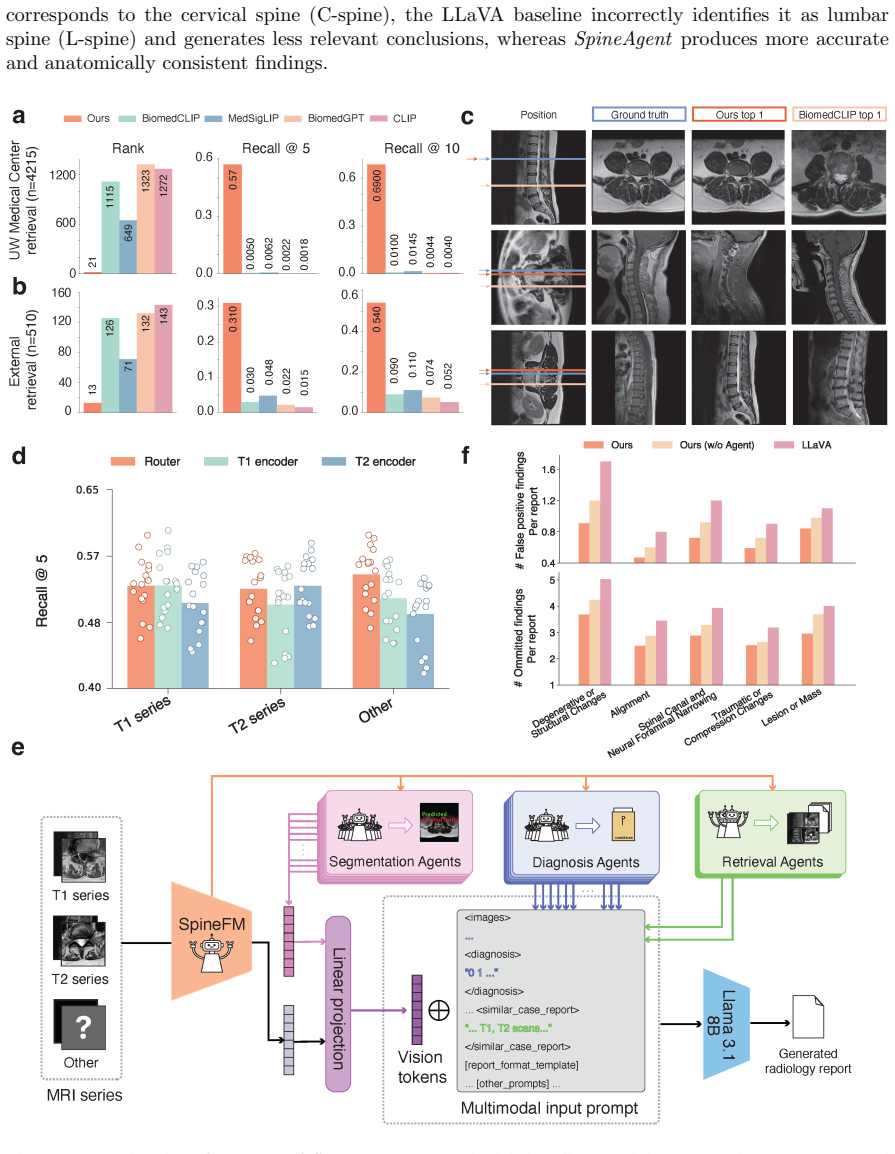
- It supports multimodal image-report retrieval in addition to report generation.
- Outputs from 37 specialized agents can be incorporated as structured tokens into an end-to-end trained Medical Report Agent.
- The approach shows strong generalizability under cross-manufacturer and cross-cohort evaluation according to both automated metrics and five-radiologist expert review.
Where Pith is reading between the lines
- If the patient-level embeddings successfully preserve sequence-specific information, the same pre-training and synthesis pattern could be tested on other multi-sequence imaging domains such as brain or abdominal MRI.
- The modular agent structure suggests that individual diagnostic subtasks could be updated independently without retraining the full report generator.
- Scalable deployment would require verifying that the large training set of 453,683 series does not introduce biases from specific scanner protocols.
Load-bearing premise
The continual training strategy learns a synthesizer that embeds images of other sequences using the T1 and T2 encoders to produce patient-level embeddings that integrate various signals across MRI sequences while preserving sequence-specific diagnostic information.
What would settle it
Performance on automated metrics or radiologist ratings falling below baselines in cross-manufacturer tests, or the synthesizer failing to produce embeddings that allow accurate pathology localization, would indicate the integration approach does not hold.
Figures


read the original abstract
Spinal pathology is a leading cause of pain and disability worldwide. Spine MRI is central to clinical evaluation, yet its interpretation remains complex and time-consuming, requiring integration of information across multiple imaging sequences and anatomical regions. Despite recent advances in automated MRI analysis, effectively combining multi-sequence data while preserving sequence-specific diagnostic information remains an open challenge. Here we present SpineAgent, a multi-agent framework for spine MRI report generation built upon a multi-sequence foundation model trained on routine clinical data from 32,047 patients and 453,683 MRI series, comprising a total of 13,441,191 MRI slices. To accommodate diverse modalities of sequences, we first pre-train two DINOv3-based encoders separately on T1- and T2-weighted sequences. We then introduce a continual training strategy that learns a synthesizer to embed images of other sequences using the T1 and T2 encoders, producing patient-level embedding that integrates various signals across MRI sequences. Using these embeddings, SpineAgent achieves state-of-the-art performance, and demonstrates strong generalizability under cross-manufacturer and cross-cohort evaluation. Beyond classification, SpineAgent enables pathology localization by identifying findings-relevant slices and segmenting pathological regions. It also supports multimodal image-report retrieval, providing a solid foundation for scalable and explainable MRI report generation. We further integrate these validated capabilities of SpineAgent into 37 specialized agents. Finally, we incorporate their outputs as structured tokens within a Medical Report Agent trained end-to-end for report generation. Through both automated metrics and expert evaluation by five radiologists, SpineAgent achieves leading performance in spine MRI report generation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents SpineAgent, a multi-agent framework for spine MRI report generation. It pre-trains separate DINOv3 encoders on T1- and T2-weighted sequences from an internal dataset of 32,047 patients and 453,683 series, then applies a continual training strategy with a synthesizer to embed other sequences into patient-level representations. These embeddings feed 37 specialized agents whose outputs are tokenized for an end-to-end Medical Report Agent. The paper claims state-of-the-art report generation performance, pathology localization, multimodal retrieval, and strong generalizability under cross-manufacturer and cross-cohort evaluation, supported by automated metrics and review by five radiologists.
Significance. If substantiated, the scale of the internal dataset and the multi-agent architecture with localization and retrieval capabilities would constitute a meaningful step toward scalable, explainable multi-sequence MRI analysis. The approach of synthesizing embeddings across sequences addresses a recognized clinical need. However, the absence of external validation and quantitative details limits the strength of the generalizability and SOTA assertions.
major comments (3)
- [Abstract (pre-training and embedding section)] Abstract (pre-training and embedding section): The continual training strategy that learns a synthesizer to embed non-T1/T2 sequences via the T1 and T2 encoders is presented without any loss function, synthesizer architecture, training hyperparameters, or ablation results demonstrating retention of sequence-specific diagnostic cues (e.g., STIR or contrast-enhanced contrast mechanisms). This assumption is load-bearing for the claim that patient-level embeddings integrate multi-sequence signals without loss of information; if it fails, downstream multi-agent report generation cannot be shown to outperform single-sequence baselines.
- [Abstract (performance and evaluation claims)] Abstract (performance and evaluation claims): The assertions of 'state-of-the-art performance' and 'strong generalizability under cross-manufacturer and cross-cohort evaluation' are made without reporting any quantitative metrics, baselines, error bars, dataset splits, exclusion criteria, or statistical tests. All results derive from a single internal clinical dataset (32,047 patients), so the SOTA and generalizability claims reduce to in-distribution performance and cannot be independently verified from the provided text.
- [Methods (multi-agent integration)] Methods (multi-agent integration): The description of how outputs from the 37 specialized agents are converted to structured tokens and incorporated into the end-to-end trained Medical Report Agent lacks architectural details, training objectives, or ablation studies isolating the contribution of the multi-agent component versus the foundation embeddings.
minor comments (2)
- The manuscript would benefit from explicit notation distinguishing the T1/T2 encoders from the synthesizer and from clearer definitions of 'patient-level embedding' versus per-series embeddings.
- Figure captions and table legends should include the exact automated metrics (e.g., BLEU, ROUGE, or clinical accuracy scores) and the number of cases per cross-manufacturer cohort.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback. We address each major comment point by point below, indicating revisions where appropriate while noting limitations that cannot be addressed in the current work.
read point-by-point responses
-
Referee: [Abstract (pre-training and embedding section)] Abstract (pre-training and embedding section): The continual training strategy that learns a synthesizer to embed non-T1/T2 sequences via the T1 and T2 encoders is presented without any loss function, synthesizer architecture, training hyperparameters, or ablation results demonstrating retention of sequence-specific diagnostic cues (e.g., STIR or contrast-enhanced contrast mechanisms). This assumption is load-bearing for the claim that patient-level embeddings integrate multi-sequence signals without loss of information; if it fails, downstream multi-agent report generation cannot be shown to outperform single-sequence baselines.
Authors: We agree that the abstract omits these implementation details. The full Methods section describes the synthesizer and continual training approach. In the revision we will add the loss function, synthesizer architecture, training hyperparameters, and ablation studies on retention of sequence-specific diagnostic information to the main text or supplementary material. revision: yes
-
Referee: [Abstract (performance and evaluation claims)] Abstract (performance and evaluation claims): The assertions of 'state-of-the-art performance' and 'strong generalizability under cross-manufacturer and cross-cohort evaluation' are made without reporting any quantitative metrics, baselines, error bars, dataset splits, exclusion criteria, or statistical tests. All results derive from a single internal clinical dataset (32,047 patients), so the SOTA and generalizability claims reduce to in-distribution performance and cannot be independently verified from the provided text.
Authors: The abstract summarizes the claims at a high level; the Results section contains the supporting quantitative metrics, baselines, error bars, splits, exclusion criteria, and statistical tests. The cross-manufacturer and cross-cohort evaluations use held-out subsets stratified by scanner vendor and cohort within the single internal dataset. We will revise the abstract to include key quantitative results and explicitly state the internal nature of the splits. External validation on independent datasets is not available in the current study. revision: partial
-
Referee: [Methods (multi-agent integration)] Methods (multi-agent integration): The description of how outputs from the 37 specialized agents are converted to structured tokens and incorporated into the end-to-end trained Medical Report Agent lacks architectural details, training objectives, or ablation studies isolating the contribution of the multi-agent component versus the foundation embeddings.
Authors: We agree the abstract description is high-level. The Methods section provides further information on tokenization and integration. In the revision we will expand this section with additional architectural details, training objectives, and ablation studies that isolate the multi-agent contribution relative to the foundation embeddings alone. revision: yes
- External validation on completely independent external datasets (the current evaluations, including cross-manufacturer and cross-cohort, are performed within the single internal dataset of 32,047 patients).
Circularity Check
No significant circularity in the derivation chain
full rationale
The paper presents a standard ML pipeline: separate pre-training of DINOv3 encoders on T1/T2 sequences, followed by a continual training step to learn a synthesizer for other sequences, then multi-agent report generation using the resulting embeddings. All performance claims (SOTA, generalizability under cross-manufacturer/cross-cohort splits) are evaluated on held-out portions of the authors' single internal dataset of 32,047 patients. No equations, definitions, or steps reduce a claimed output to its inputs by construction; no load-bearing self-citations appear; no fitted parameters are relabeled as independent predictions. The derivation remains self-contained as a description of model training and internal evaluation.
Axiom & Free-Parameter Ledger
free parameters (3)
- DINOv3 encoder parameters
- synthesizer parameters
- agent and report generator parameters
axioms (2)
- domain assumption DINOv3 self-supervised pre-training produces useful representations for clinical MRI sequences
- domain assumption Multi-agent decomposition can faithfully integrate outputs from specialized pathology, localization, and retrieval agents into coherent reports
invented entities (1)
-
SpineAgent multi-agent framework
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Vos, T.et al.Global burden of 369 diseases and injuries in 204 countries and territories, 1990– 2019: a systematic analysis for the global burden of disease study 2019.The lancet396, 1204–1222 (2020)
1990
-
[2]
Hartvigsen, J.et al.What low back pain is and why we need to pay attention.The Lancet391, 2356–2367 (2018)
2018
-
[3]
The global epidemic of low back pain.The Lancet Rheuma- tology5, e305 (2023)
The Lancet Rheumatology. The global epidemic of low back pain.The Lancet Rheuma- tology5, e305 (2023). URLhttps://www.thelancet.com/journals/lanrhe/article/ PIIS2665-9913(23)00133-9/fulltext. 19
2023
-
[4]
Lu, Y.et al.Global, regional, and national burden of spinal cord injury from 1990 to 2021 and projections for 2050: A systematic analysis for the global burden of disease 2021 study.Ageing Research Reviews103, 102598 (2025)
1990
-
[5]
F¨ orsth, P.et al.A randomized, controlled trial of fusion surgery for lumbar spinal stenosis.New England Journal of Medicine374, 1413–1423 (2016)
2016
-
[6]
& Bauman, C
Milligan, J., Ryan, K., Fehlings, M. & Bauman, C. Degenerative cervical myelopathy: diagnosis and management in primary care.Canadian Family Physician65, 619–624 (2019)
2019
-
[7]
N., Zimmerman, Z
Katz, J. N., Zimmerman, Z. E., Mass, H. & Makhni, M. C. Diagnosis and management of lumbar spinal stenosis: a review.Jama327, 1688–1699 (2022)
2022
-
[8]
H., Bradley, W
Hashemi, R. H., Bradley, W. G. & Lisanti, C. J.MRI: the basics(Lippincott Williams & Wilkins, 2010)
2010
-
[9]
H., Ramaiya, N
Afshari Mirak, S., Tirumani, S. H., Ramaiya, N. & Mohamed, I. The growing nationwide radi- ologist shortage: current opportunities and ongoing challenges for international medical graduate radiologists.Radiology314, e232625 (2025)
2025
-
[10]
Wu, J.et al.Vision-language foundation model for 3d medical imaging.npj Artificial Intelligence 1, 17 (2025)
2025
-
[11]
Bluethgen, C.et al.A vision–language foundation model for the generation of realistic chest x-ray images.Nature Biomedical Engineering9, 494–506 (2025)
2025
-
[12]
Xu, H.et al.A whole-slide foundation model for digital pathology from real-world data.Nature 630, 181–188 (2024)
2024
-
[13]
In International conference on machine learning, 8748–8763 (PmLR, 2021)
Radford, A.et al.Learning Transferable Visual Models From Natural Language Supervision. In International conference on machine learning, 8748–8763 (PmLR, 2021)
2021
-
[14]
& Beyer, L
Zhai, X., Mustafa, B., Kolesnikov, A. & Beyer, L. Sigmoid loss for language image pre-training. In Proceedings of the IEEE/CVF international conference on computer vision, 11975–11986 (2023)
2023
-
[15]
Monshi, M. M. A., Poon, J. & Chung, V. Deep learning in generating radiology reports: A survey. Artificial Intelligence in Medicine106, 101878 (2020)
2020
-
[16]
Goldberg-Stein, S.et al.Acr radpeer committee white paper with 2016 updates: revised scoring system, new classifications, self-review, and subspecialized reports.Journal of the American College of Radiology14, 1080–1086 (2017)
2016
-
[17]
Sim´ eoni, O.et al.DINOv3.arXiv preprint arXiv:2508.10104(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[18]
& Sun, J
He, K., Zhang, X., Ren, S. & Sun, J. Deep residual learning for image recognition. InProceedings of the IEEE conference on computer vision and pattern recognition, 770–778 (2016)
2016
-
[19]
Rui, S.et al.BrainMVP: Multi-modal Vision Pre-training for Brain Image Analysis using Multi- parametric MRI.arXiv e-printsarXiv–2410 (2024)
2024
-
[20]
& Wang, L
Sun, Y., Wang, L., Li, G., Lin, W. & Wang, L. A foundation model for enhancing magnetic reso- nance images and downstream segmentation, registration and diagnostic tasks.Nature Biomedical Engineering9, 521–538 (2025)
2025
-
[21]
Nature Medicine1–13 (2024)
Zhang, K.et al.A generalist vision–language foundation model for diverse biomedical tasks. Nature Medicine1–13 (2024)
2024
- [22]
-
[23]
Richards, T. J.et al.The rsna lumbar degenerative imaging spine classification (lumbardisc) dataset.arXiv preprint arXiv:2506.09162(2025). 20
-
[24]
R.et al.Performance of the winning algorithms of the rsna 2022 cervical spine fracture detection challenge.Radiology: Artificial Intelligence6, e230256 (2024)
Lee, G. R.et al.Performance of the winning algorithms of the rsna 2022 cervical spine fracture detection challenge.Radiology: Artificial Intelligence6, e230256 (2024)
2022
-
[25]
Rsna launches lumbar spine degenerative classification ai challenge.AXIS Imaging News(2024)
Stephens, K. Rsna launches lumbar spine degenerative classification ai challenge.AXIS Imaging News(2024)
2024
-
[26]
& Lee, Y
Liu, H., Li, C., Wu, Q. & Lee, Y. J. Visual Instruction Tuning.Advances in neural information processing systems36, 34892–34916 (2023)
2023
-
[27]
Ziegler, E.et al.Open health imaging foundation viewer: an extensible open-source framework for building web-based imaging applications to support cancer research.JCO clinical cancer informatics4, 336–345 (2020)
2020
-
[28]
Brand˜ ao, S.et al.Comparing t1-weighted and t2-weighted three-point dixon technique with conventional t1-weighted fat-saturation and short-tau inversion recovery (stir) techniques for the study of the lumbar spine in a short-bore mri machine.Clinical radiology68, e617–e623 (2013)
2013
-
[29]
S.et al.From language to action: a review of large language models as autonomous agents and tool users.Artificial Intelligence Review(2026)
Chowa, S. S.et al.From language to action: a review of large language models as autonomous agents and tool users.Artificial Intelligence Review(2026)
2026
-
[30]
InThe Thirteenth International Conference on Learning Representations(2025)
Shang, Y.et al.Agentsquare: Automatic llm agent search in modular design space. InThe Thirteenth International Conference on Learning Representations(2025)
2025
-
[31]
& Shazeer, N
Fedus, W., Zoph, B. & Shazeer, N. Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity.Journal of Machine Learning Research23, 1–39 (2022)
2022
-
[32]
& Riemer, M
Rosenbaum, C., Klinger, T. & Riemer, M. Routing networks: Adaptive selection of non-linear functions for multi-task learning. InInternational Conference on Learning Representations(2018)
2018
-
[33]
InInternational Conference on Learning Representations(2021)
Dosovitskiy, A.et al.An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. InInternational Conference on Learning Representations(2021)
2021
-
[34]
& Bojanowski, P
Darcet, T., Oquab, M., Mairal, J. & Bojanowski, P. Vision transformers need registers. InThe Twelfth International Conference on Learning Representations(2023)
2023
-
[35]
In Proceedings of the 28th international conference on computational linguistics, 669–679 (2020)
Chakraborty, S.et al.Biomedbert: A pre-trained biomedical language model for qa and ir. In Proceedings of the 28th international conference on computational linguistics, 669–679 (2020)
2020
-
[36]
Grattafiori, A.et al.The llama 3 herd of models.arXiv preprint arXiv:2407.21783(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[37]
J.et al.Lora: Low-rank adaptation of large language models.ICLR1, 3 (2022)
Hu, E. J.et al.Lora: Low-rank adaptation of large language models.ICLR1, 3 (2022)
2022
-
[38]
I.et al.Phi-4 technical report.CoRR(2024)
Abdin, M. I.et al.Phi-4 technical report.CoRR(2024)
2024
-
[39]
InInternational conference on machine learning, 1691–1703 (PMLR, 2020)
Chen, M.et al.Generative pretraining from pixels. InInternational conference on machine learning, 1691–1703 (PMLR, 2020)
2020
-
[40]
& Gallifant, J
McDermott, M., Zhang, H., Hansen, L., Angelotti, G. & Gallifant, J. A closer look at auroc and auprc under class imbalance.Advances in Neural Information Processing Systems37, 44102– 44163 (2024)
2024
-
[41]
Oquab, M.et al.DINOv2: Learning Robust Visual Features without Supervision.Transactions on Machine Learning Research Journal1–31 (2024)
2024
-
[42]
Zhang, S.et al.BiomedCLIP: a multimodal biomedical foundation model pretrained from fifteen million scientific image-text pairs.arXiv preprint arXiv:2303.00915(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[43]
Sellergren, A.et al.MedGemma Technical Report.arXiv preprint arXiv:2507.05201(2025). 21 Supplementary Information Supplementary Prompts System Prompt system_prompt = """<|begin of text|><|start header id|system|end header id|>. You are Spine-Agent, a radiology assistant focused strictly on Spine MRI. Scope and inputs: - Only discuss Spine MRI and directly...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[44]
"" Report Generation Prompt agent_report_generation_prompt =
Report Generation - Produce a structured radiology report with professional tone. - Summarize key actionable findings in the Impression. Style and safety: - Keep responses clear, concise, and focused on the provided Spine MRI. - Do not fabricate unseen sequences, planes, or prior comparisons. - Add an appropriate medical caution when relevant.""" Report G...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.