Understanding Quantization-Aware Training: Gradients at Quantized Weights Bias to the Low-Loss Basin
Pith reviewed 2026-06-27 17:32 UTC · model grok-4.3
The pith
Straight-through estimator in QAT evaluates gradients at quantized weights, creating an inward bias that steers iterates back into the low-loss basin where local PTQ can exit.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
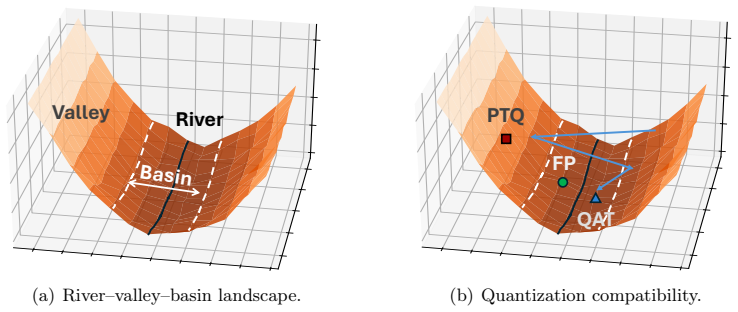
We model full-precision training as following a low-loss river inside a wider valley: a normal neighborhood of the river forms a nearly flat basin, while leaving this basin incurs a sharp loss increase. When the quantization grid is comparable to the basin width, local PTQ objectives, including rounding and Hessian-based second-order reconstruction, can select a high-loss deployed quantized point outside the basin even when nearby low-loss quantized points exist. In this regime, straight-through-estimator-based QAT has a useful bias: it evaluates gradients at the deployed quantized weights while updating latent full-precision weights, causing the gradient to sense the valley wall and acquire
What carries the argument
The local landscape model of a low-loss river inside a valley with a flat basin, together with the straight-through estimator that evaluates gradients at deployed quantized weights.
If this is right
- PTQ can geometrically fail by selecting high-loss quantized points outside the basin even when low-loss ones exist nearby.
- STE-based QAT acquires an inward gradient component from the valley wall that steers quantized iterates back inside the basin.
- Finite-time recovery to the basin is provable under the stated local quantizer-compatibility assumptions.
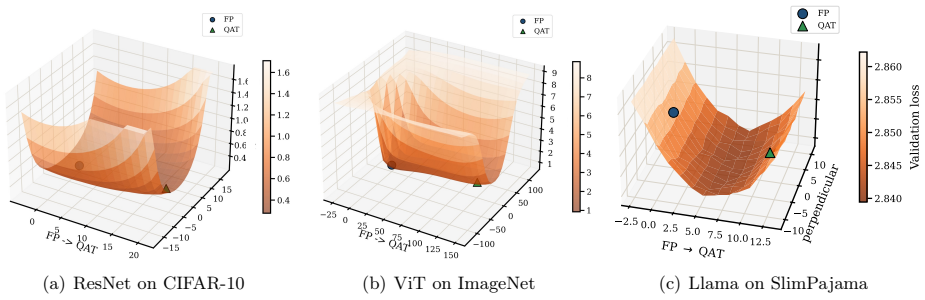
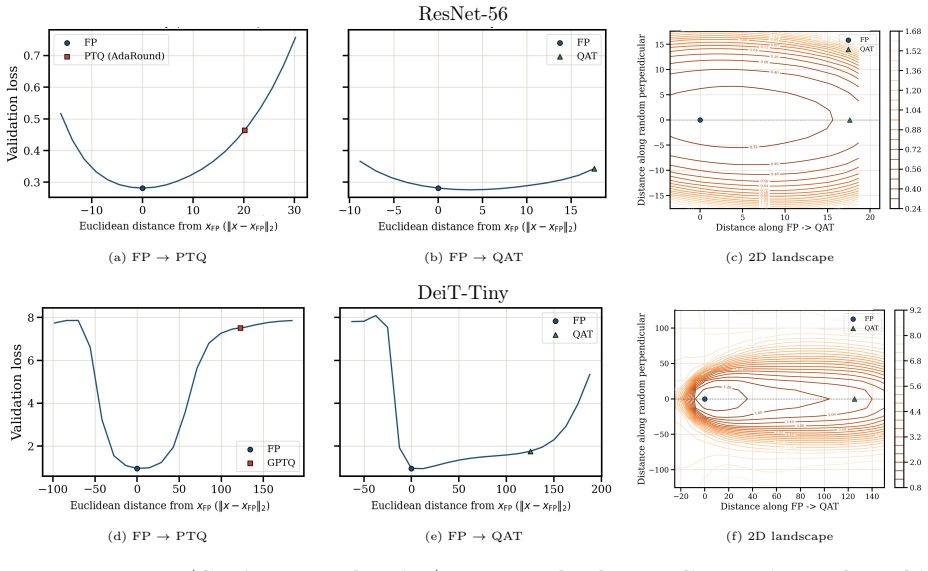
- The same geometric mechanism appears across vision and language models under multiple quantization schemes.
Where Pith is reading between the lines
- The basin model suggests testing whether explicit penalties on basin exit during QAT further improve low-bit accuracy.
- The framework could be extended to multi-basin landscapes to predict when QAT recovery breaks down.
- It raises the question of whether other gradient estimators or quantization schedules inherit similar inward bias properties.
Load-bearing premise
Full-precision training follows a low-loss river inside a wider valley whose normal neighborhood forms a nearly flat basin, and the quantizer satisfies the local compatibility assumptions needed for the finite-time recovery proof.
What would settle it
A controlled low-dimensional loss surface where the quantization step equals basin width, the full-precision optimum lies inside the basin, PTQ rounds to a point outside the basin, and QAT with STE either fails to recover or the measured gradient at the outside point has no inward component.
Figures

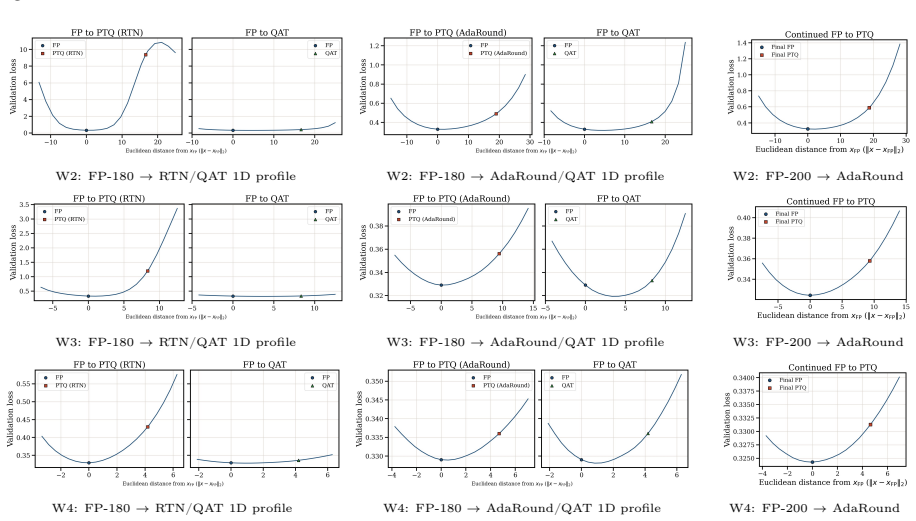
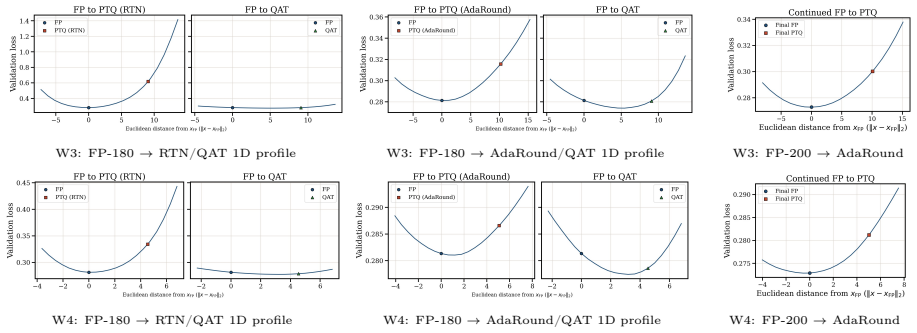
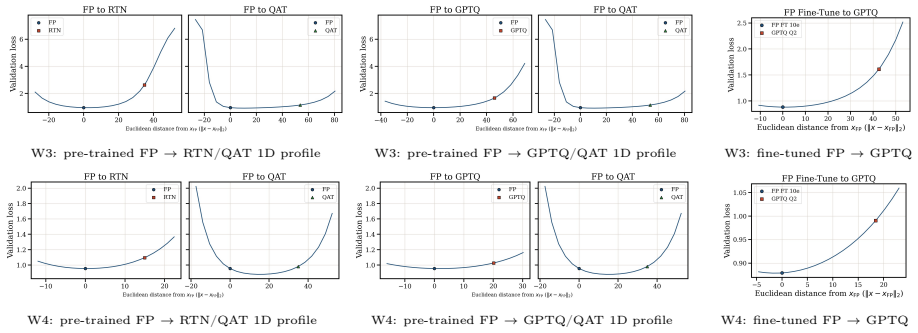
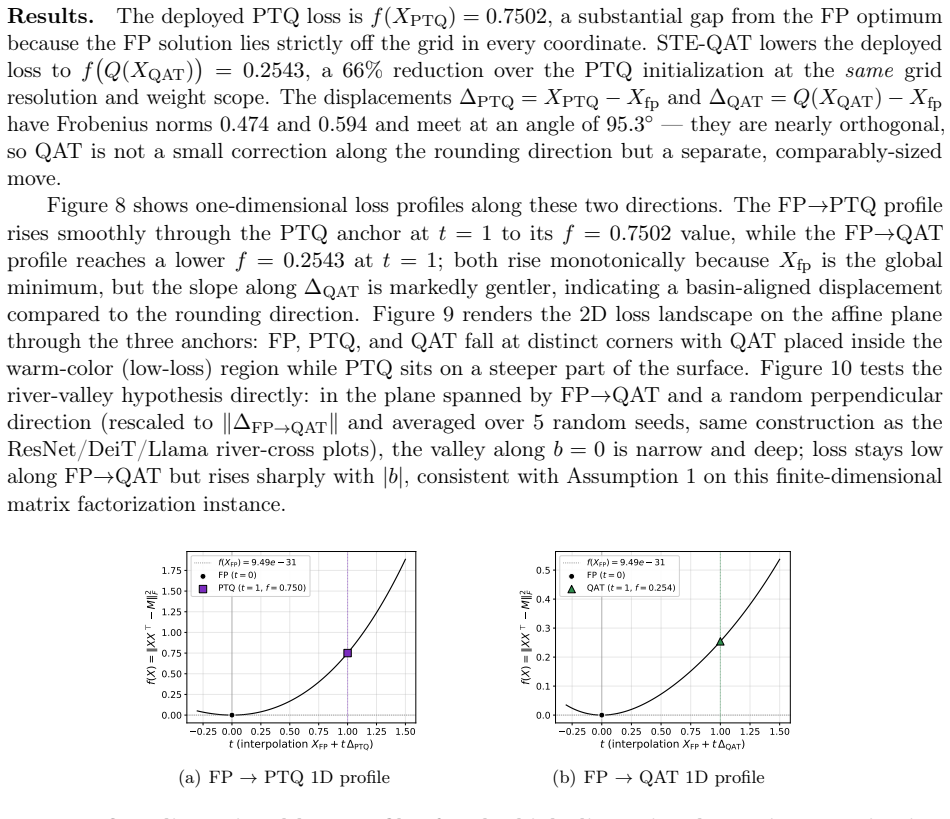
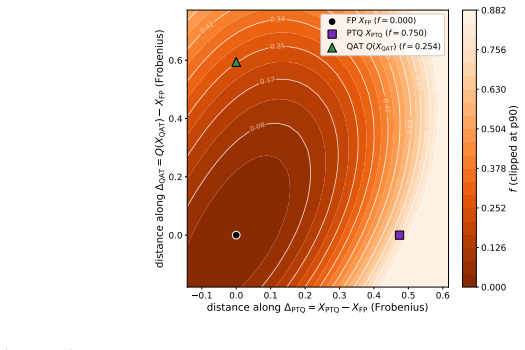
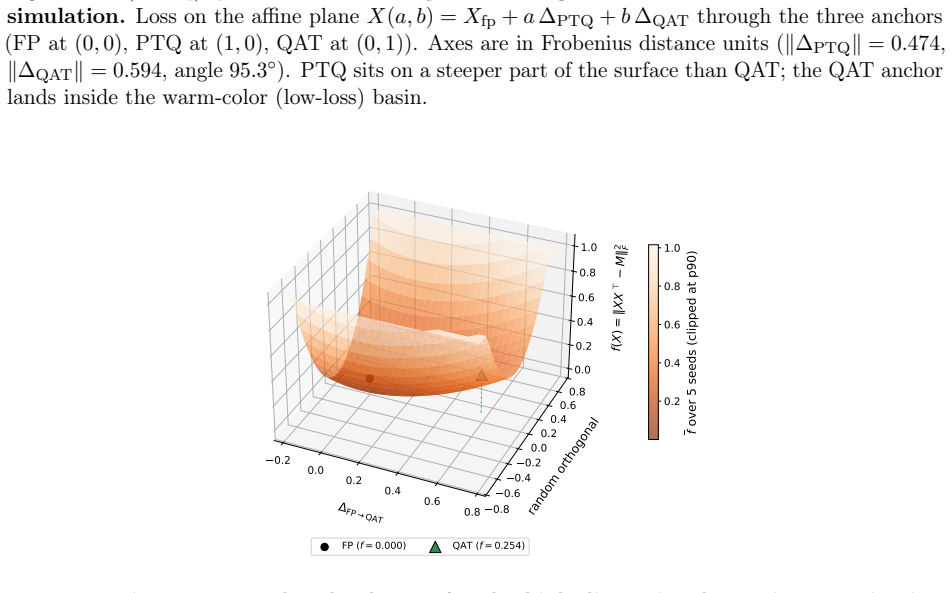
read the original abstract
Post-training quantization (PTQ) converts a trained full-precision model into low-bit weights without task-level retraining, while quantization-aware training (QAT) incorporates quantization into the training loop. Although PTQ is efficient and often accurate at moderate bitwidths, it can fail sharply at aggressive bitwidths; QAT is more expensive but can often recover the lost accuracy. We propose a unified geometric framework that explains both PTQ failure and QAT recovery. We model full-precision training as following a low-loss \emph{river} inside a wider \emph{valley}: a normal neighborhood of the river forms a nearly flat \emph{basin}, while leaving this basin incurs a sharp loss increase. When the quantization grid is comparable to the basin width, local PTQ objectives, including rounding and Hessian-based second-order reconstruction, can select a high-loss deployed quantized point outside the basin even when nearby low-loss quantized points exist. In this regime, straight-through-estimator-based QAT has a useful bias: it evaluates gradients at the deployed quantized weights while updating latent full-precision weights, causing the gradient to sense the valley wall and acquire an inward component that steers subsequent quantized iterates back into the basin. We formalize this mechanism through a local landscape model, construct a geometric PTQ failure mode, and prove finite-time QAT recovery under local quantizer-compatibility assumptions. Experiments across vision and language models under multiple neural-network quantization schemes corroborate the predicted basin-crossing failure of PTQ and the corresponding recovery mechanism of QAT.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a unified geometric framework explaining PTQ failure and QAT recovery. Full-precision training is modeled as following a low-loss river inside a wider valley whose normal neighborhood forms a nearly flat basin. When the quantization grid scale is comparable to basin width, local PTQ objectives (rounding, Hessian-based reconstruction) can select high-loss deployed points outside the basin even when low-loss quantized points exist nearby. STE-based QAT evaluates gradients at the deployed quantized weights, imparting an inward bias that steers iterates back into the basin. The paper constructs the geometric PTQ failure mode, proves finite-time QAT recovery under local quantizer-compatibility assumptions, and presents corroborating experiments on vision and language models under multiple quantization schemes.
Significance. If the geometric mechanism and recovery proof hold, the work supplies a principled explanation for the empirical superiority of QAT over PTQ at aggressive bit-widths and could guide algorithm design. The formal finite-time recovery result and the breadth of experimental corroboration across models and schemes are explicit strengths.
major comments (2)
- [Abstract and local landscape model section] Abstract and local landscape model section: the PTQ failure construction and the QAT inward-bias mechanism are derived only after positing the specific river-valley-basin geometry together with the local quantizer-compatibility assumptions; these modeling choices are load-bearing for the central claim yet receive no independent empirical verification (e.g., no landscape visualizations or basin-width measurements) that would confirm the geometry holds for the networks and quantizers studied.
- [Finite-time recovery theorem] Finite-time recovery theorem: the proof invokes additional local quantizer-compatibility assumptions whose restrictiveness is not quantified; without showing that these assumptions are satisfied by the uniform and other quantizers used in the experiments, the theorem does not yet establish that the claimed steering mechanism operates in the reported settings.
minor comments (2)
- [Experiments section] Experiments section: while the accuracy-gap results are consistent with the predicted basin-crossing behavior, adding controls that directly probe the posited geometry (e.g., loss-surface slices around quantized points) would tighten the link between theory and observation.
- [Notation] Notation: ensure that the distinction between latent full-precision weights, deployed quantized weights, and the STE gradient is denoted uniformly across all equations and algorithm boxes.
Simulated Author's Rebuttal
We thank the referee for the constructive review and for recognizing the potential significance of the geometric framework and finite-time recovery result. We address the two major comments point by point below, proposing targeted revisions to strengthen the presentation of modeling assumptions and their relation to the experiments.
read point-by-point responses
-
Referee: [Abstract and local landscape model section] Abstract and local landscape model section: the PTQ failure construction and the QAT inward-bias mechanism are derived only after positing the specific river-valley-basin geometry together with the local quantizer-compatibility assumptions; these modeling choices are load-bearing for the central claim yet receive no independent empirical verification (e.g., no landscape visualizations or basin-width measurements) that would confirm the geometry holds for the networks and quantizers studied.
Authors: We agree that the river-valley-basin geometry is a modeling choice introduced to explain the observed PTQ failure mode and QAT recovery. The manuscript provides indirect support through experiments showing that PTQ exhibits the predicted basin-crossing failures and QAT recovers under the same conditions across vision and language models with multiple quantization schemes. Direct landscape visualizations or basin-width measurements are not included, as they are computationally prohibitive at the scale of the studied networks. In revision we will add a dedicated paragraph in the local landscape model section that explicitly discusses the alignment between the posited geometry and the experimental outcomes, while acknowledging the lack of direct geometric measurements as a limitation. revision: partial
-
Referee: [Finite-time recovery theorem] Finite-time recovery theorem: the proof invokes additional local quantizer-compatibility assumptions whose restrictiveness is not quantified; without showing that these assumptions are satisfied by the uniform and other quantizers used in the experiments, the theorem does not yet establish that the claimed steering mechanism operates in the reported settings.
Authors: The local quantizer-compatibility assumptions are stated explicitly in the theorem (Section 4). We will revise the manuscript to add a new subsection that quantifies the restrictiveness of these assumptions (e.g., by bounding the deviation from uniformity near basin boundaries) and verifies that they hold for the uniform quantizer and the other schemes employed in the experiments under the local approximation. This verification will be performed analytically for the uniform case and numerically for the reported bit-widths. revision: yes
Circularity Check
No significant circularity: model and proof are explicit modeling choices with stated assumptions, not reductions by construction.
full rationale
The paper introduces its local landscape model (river/valley/basin geometry) and quantizer-compatibility assumptions directly in the text as a proposed framework, then derives the PTQ failure construction and QAT recovery theorem from them. No equations or claims reduce to their inputs by definition, no parameters are fitted then relabeled as predictions, and no self-citations are invoked as load-bearing uniqueness results. The derivation chain is self-contained as a hypothesis plus conditional proof plus experiments; this matches the default non-circular case.
Axiom & Free-Parameter Ledger
axioms (1)
- ad hoc to paper local quantizer-compatibility assumptions
invented entities (1)
-
low-loss river inside a wider valley with nearly flat basin
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Proxquant: Quantized neural networks via proximal operators
Yu Bai, Yu-Xiang Wang, and Edo Liberty. Proxquant: Quantized neural networks via proximal operators. InInternational Conference on Learning Representations, 2018
2018
-
[2]
Post training 4-bit quantization of convolu- tional networks for rapid-deployment
Ron Banner, Yury Nahshan, and Daniel Soudry. Post training 4-bit quantization of convolu- tional networks for rapid-deployment. InAdvances in Neural Information Processing Systems, volume 32, 2019
2019
-
[3]
Pascal Bégout, Jérôme Bolte, Thomas Mariotti, and Francisco Silva. Gradient extremals, talwegs, valleys, and directional alignment for generic gradient descent.arXiv preprint arXiv:2604.11213, 2026
Pith/arXiv arXiv 2026
-
[4]
Yoshua Bengio, Nicholas Léonard, and Aaron Courville. Estimating or propagating gradients through stochastic neurons for conditional computation.arXiv preprint arXiv:1308.3432, 2013
Pith/arXiv arXiv 2013
-
[5]
Training dynamics impact post- training quantization robustness
Albert Catalan-Tatjer, Niccolò Ajroldi, and Jonas Geiping. Training dynamics impact post- training quantization robustness. InInternational Conference on Learning Representations, 2026. 12
2026
-
[6]
Unveiling the basin-like loss landscape in large language models
Huanran Chen, Yinpeng Dong, Zeming Wei, Yao Huang, Yichi Zhang, Hang Su, and Jun Zhu. Unveiling the basin-like loss landscape in large language models. InInternational Conference on Learning Representations, 2026
2026
-
[7]
BinaryConnect: Training deep neural networks with binary weights during propagations
Matthieu Courbariaux, Yoshua Bengio, and Jean-Pierre David. BinaryConnect: Training deep neural networks with binary weights during propagations. InAdvances in Neural Information Processing Systems, volume 28, pages 3123–3131, 2015
2015
-
[8]
Gradient descent with adaptive stepsize converges (nearly) linearly under fourth-order growth.Mathematical Programming, pages 1–66, 2025
Damek Davis, Dmitriy Drusvyatskiy, and Liwei Jiang. Gradient descent with adaptive stepsize converges (nearly) linearly under fourth-order growth.Mathematical Programming, pages 1–66, 2025
2025
-
[9]
Demystify- ing and generalizing binaryconnect
Tim Dockhorn, Yaoliang Yu, Eyyüb Sari, Mahdi Zolnouri, and Vahid Partovi Nia. Demystify- ing and generalizing binaryconnect. InAdvances in Neural Information Processing Systems, volume 34, pages 13202–13216, 2021
2021
-
[10]
Compute- Optimal Quantization-Aware Training
Aleksandr Dremov, David Grangier, Angelos Katharopoulos, and Awni Hannun. Compute- Optimal Quantization-Aware Training. InInternational Conference on Learning Representations, 2026
2026
-
[11]
GPTQ: Accurate post- training quantization for generative pre-trained transformers
Elias Frantar, Saleh Ashkboos, Torsten Hoefler, and Dan Alistarh. GPTQ: Accurate post- training quantization for generative pre-trained transformers. InInternational Conference on Learning Representations, 2023
2023
-
[12]
Song Han, Huizi Mao, and William J. Dally. Deep compression: Compressing deep neural networks with pruning, trained quantization and huffman coding. InInternational Conference on Learning Representations, 2016
2016
-
[13]
Deep residual learning for image recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. InProceedings of the IEEE conference on Computer Vision and Pattern Recognition, pages 770–778, 2016
2016
-
[14]
Quantization and training of neural networks for efficient integer-arithmetic-only inference
Benoit Jacob, Skirmantas Kligys, Bo Chen, Menglong Zhu, Matthew Tang, Andrew Howard, Hartwig Adam, and Dmitry Kalenichenko. Quantization and training of neural networks for efficient integer-arithmetic-only inference. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 2704–2713, 2018
2018
-
[15]
Halyun Jeong, Jack Xin, and Penghang Yin. Beyond discreteness: Finite-sample analysis of straight-through estimator for quantization.arXiv preprint arXiv:2505.18113, 2025
Pith/arXiv arXiv 2025
-
[16]
PARQ: Piecewise-affine regularized quantization
Lisa Jin, Jianhao Ma, Zechun Liu, Andrey Gromov, Aaron Defazio, and Lin Xiao. PARQ: Piecewise-affine regularized quantization. InProceedings of the 42nd International Conference on Machine Learning, volume 267, pages 28044–28062. PMLR, 2025
2025
-
[17]
Raghuraman Krishnamoorthi. Quantizing deep convolutional networks for efficient inference: A whitepaper.arXiv preprint arXiv:1806.08342, 2018
Pith/arXiv arXiv 2018
-
[18]
Training quantized nets: A deeper understanding
Hao Li, Soham De, Zheng Xu, Christoph Studer, Hanan Samet, and Tom Goldstein. Training quantized nets: A deeper understanding. InAdvances in Neural Information Processing Systems, volume 30, 2017. 13
2017
-
[19]
ParetoQ: Improving scaling laws in extremely low-bit LLM quantization
Zechun Liu, Changsheng Zhao, Hanxian Huang, Sijia Chen, Jing Zhang, Jiawei Zhao, Scott Roy, Lisa Jin, Yunyang Xiong, Yangyang Shi, et al. ParetoQ: Improving scaling laws in extremely low-bit LLM quantization. InAdvances in Neural Information Processing Systems, 2025
2025
-
[20]
Chao Ma, Daniel Kunin, Lei Wu, and Lexing Ying. Beyond the quadratic approximation: The multiscale structure of neural network loss landscapes.arXiv preprint arXiv:2204.11326, 2022
arXiv 2022
-
[21]
Up or down? adaptive rounding for post-training quantization
Markus Nagel, Rana Ali Amjad, Mart Van Baalen, Christos Louizos, and Tijmen Blankevoort. Up or down? adaptive rounding for post-training quantization. InInternational Conference on Machine Learning, pages 7197–7206, 2020
2020
-
[22]
Loss aware post-training quantization.Machine Learning, 110(11):3245–3262, 2021
Yury Nahshan, Brian Chmiel, Chaim Baskin, Evgenii Zheltonozhskii, Ron Banner, Alex M Bronstein, and Avi Mendelson. Loss aware post-training quantization.Machine Learning, 110(11):3245–3262, 2021
2021
-
[23]
Efficient processing of deep neural networks: A tutorial and survey.Proceedings of the IEEE, 105(12):2295–2329, 2017
Vivienne Sze, Yu-Hsin Chen, Tien-Ju Yang, and Joel S Emer. Efficient processing of deep neural networks: A tutorial and survey.Proceedings of the IEEE, 105(12):2295–2329, 2017
2017
-
[24]
Training data-efficient image transformers & distillation through attention
Hugo Touvron, Matthieu Cord, Matthijs Douze, Francisco Massa, Alexandre Sablayrolles, and Hervé Jégou. Training data-efficient image transformers & distillation through attention. In International Conference on Machine Learning, pages 10347–10357. PMLR, 2021
2021
-
[25]
Understanding warmup-stable-decay learning rates: A river valley loss landscape view
Kaiyue Wen, Zhiyuan Li, Jason S Wang, David Leo Wright Hall, Percy Liang, and Tengyu Ma. Understanding warmup-stable-decay learning rates: A river valley loss landscape view. In International Conference on Learning Representations, 2025
2025
-
[26]
APHQ- ViT: Post-training quantization with average perturbation Hessian based reconstruction for vision transformers
Zhuguanyu Wu, Jiayi Zhang, Jiaxin Chen, Jinyang Guo, Di Huang, and Yunhong Wang. APHQ- ViT: Post-training quantization with average perturbation Hessian based reconstruction for vision transformers. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 9686–9695, 2025
2025
-
[27]
Understanding straight-through estimator in training activation quantized neural nets.International Conference on Learning Representations, 2019
P Yin, J Lyu, S Zhang, S Osher, YY Qi, and J Xin. Understanding straight-through estimator in training activation quantized neural nets.International Conference on Learning Representations, 2019
2019
-
[28]
PTQ4ViT: Post-training quantization for vision transformers with twin uniform quantization
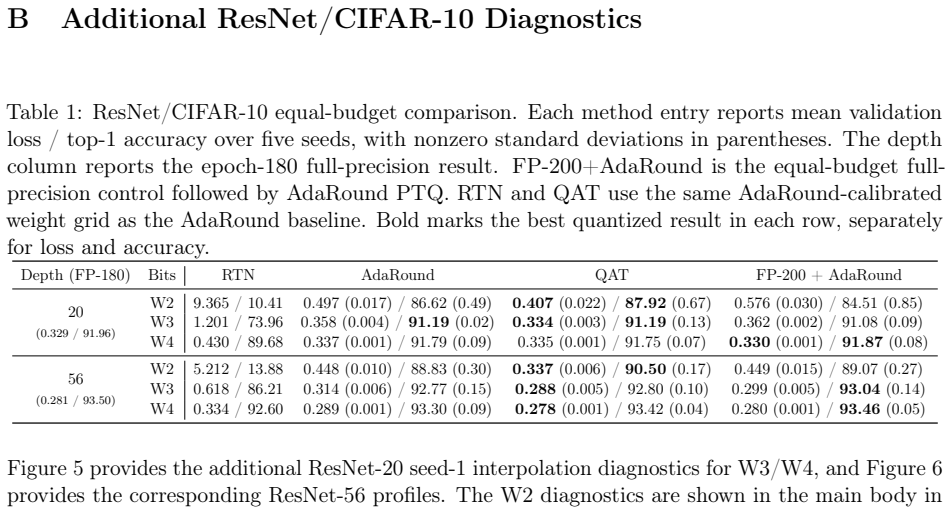
Zhihang Yuan, Chenhao Xue, Yiqi Chen, Qiang Wu, and Guangyu Sun. PTQ4ViT: Post-training quantization for vision transformers with twin uniform quantization. InEuropean Conference on Computer Vision, pages 191–207. Springer, 2022. 14 A Experimental Details ResNet/CIFAR-10.Each full-precision ResNet is trained for 200 epochs with SGD, momentum 0.9, batch si...
2022
-
[29]
We next control the error caused by replacingCP with the frozen metricC0
Applying the moving-metric estimate with threshold2R/ √ 5gives ⟨∇Zf(P, Z), ZC P ⟩ D0(Z) ≥ 16 25 c∗. We next control the error caused by replacingCP with the frozen metricC0. OnU, ∥∇Zf(P, Z)∥ F ≤4∥Z∥ F ∥P∥ 2 op + 4∥Z∥3 F ≤4R U(M 2 +R 2 U)≜G. SinceD 0(Z)≥ √λf ∥Z∥F, we have ⟨∇Zf(P, Z), Z(C 0 −C P )⟩ D0(Z) ≤ ∥∇Zf(P, Z)∥ F ∥Z∥F ∥C0 −C P ∥op D0(Z) ≤ GλsδH√λf . ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.