Hierarchical Policies from Verbal and Egocentric Human Signals for Natural Human-Robot Interaction
Pith reviewed 2026-06-27 13:29 UTC · model grok-4.3
The pith
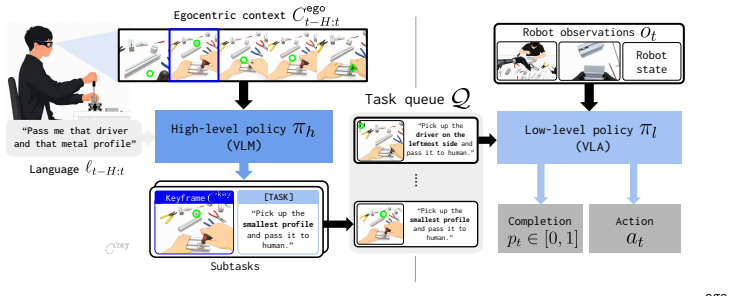
EDITH uses smart glasses streams of gaze and first-person video with language to let a high-level policy infer intent and output grounded subtasks for a low-level robot executor.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
EDITH captures the human's nonverbal signals through continuous streams of first-person view and gaze from smart glasses, and uses them alongside language instructions as inputs to the robot policy. The high-level policy infers the human's intent and produces a sequence of subtasks, where each subtask is represented as a fine-grained instruction paired with a keyframe that grounds the intent in the scene. A low-level policy then executes these subtasks, enabling the robot to act on brief nonverbal signals and reducing user effort compared to language instructions alone.
What carries the argument
Hierarchical policy in which the high-level component infers intent from egocentric video and gaze streams and emits instruction-keyframe pairs that a low-level executor then follows.
If this is right
- Robots can act on intent expressed briefly through nonverbal signals without waiting for full language instructions.
- User effort to convey intent drops significantly in interactive tasks compared with language-only interfaces.
- Noisy real-time egocentric streams can be turned into usable subtasks with scene-grounded keyframes.
- The same high-level policy can handle mixed verbal and nonverbal input streams without separate modules for each.
Where Pith is reading between the lines
- The keyframe grounding step could be tested as a way to improve policy robustness when language alone is ambiguous.
- Extending the streams to include additional wearable signals might further reduce reliance on explicit commands.
- The hierarchical split suggests a path for combining learned high-level intent models with existing low-level controllers.
- In multi-person settings the same mechanism might disambiguate which person's signals the robot should follow.
Load-bearing premise
The high-level policy can reliably extract accurate intent and valid keyframes from noisy, continuous egocentric video and gaze streams in real time without additional human correction.
What would settle it
In repeated real-robot trials, humans express intent only through brief gaze or gestures; if the robot repeatedly selects wrong keyframes or executes incorrect subtasks, the claim is falsified.
Figures




















read the original abstract
For natural human-robot interaction, a robot must understand human intent expressed not only through language but also through nonverbal signals such as gestures and gaze. However, current robot policies rely on language instructions as the sole interface for conveying intent, leaving nonverbal signals unused and placing the full burden of communication. In this work, we present EDITH, a robot framework that captures the human's nonverbal signals through continuous streams of first-person view and gaze from smart glasses, and uses them alongside language instructions as inputs to the robot policy. Our hardware system streams the human's first-person view, gaze, and speech to the robot in real time, transcribing the speech into language instructions. To handle these rich but noisy signals, we design a hierarchical policy in which a high-level policy infers the human's intent and produces a sequence of subtasks, where each subtask is represented as a fine-grained instruction paired with a keyframe that grounds the intent in the scene (e.g., the frame where the human points at the target object). A low-level policy then executes these subtasks. In our experiments on human-robot interactive tasks, EDITH enables the robot to act on the human's nonverbal signals even when intent is expressed only briefly, and significantly reduces user effort to convey intent compared to using language instructions alone. Visit our project page for source code and real-robot demo videos.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
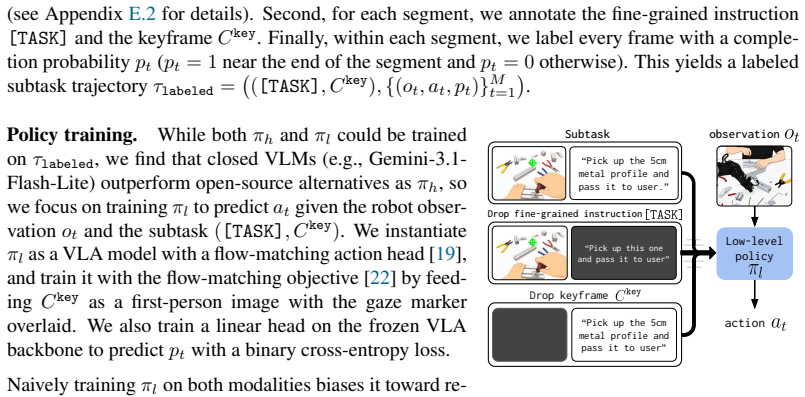
Summary. The paper presents EDITH, a hierarchical robot policy framework that streams first-person video, gaze, and transcribed speech from smart glasses to a high-level policy which infers intent and outputs subtasks (each a fine-grained instruction paired with a scene-grounded keyframe), which a low-level policy then executes. The central empirical claim is that this enables the robot to act on brief nonverbal signals and significantly reduces user effort relative to language-only instructions.
Significance. If the high-level policy's mapping from noisy egocentric streams to accurate subtasks and keyframes holds with the claimed robustness, the work would represent a practical advance in multimodal HRI by lowering the communication burden on users and enabling more natural interaction in collaborative tasks.
major comments (2)
- [Abstract] Abstract: the claim that EDITH 'significantly reduces user effort' and 'enables the robot to act on the human's nonverbal signals even when intent is expressed only briefly' is load-bearing for the contribution, yet the manuscript supplies no architecture details, training procedure, noise-handling mechanisms, or quantitative metrics (intent accuracy, keyframe IoU, or effort reduction with error bars) for the high-level policy on real egocentric data.
- [Method] The description of the high-level policy (which must map continuous, noisy first-person video + gaze streams to correct subtasks and keyframes in real time without human correction) provides no concrete implementation, loss functions, or robustness analysis, leaving the central assumption about signal reliability unverified and the performance claims unsupported.
minor comments (1)
- The mention of source code and demo videos on the project page is a positive step toward reproducibility; ensure the camera-ready version includes explicit links and a brief description of the low-level policy execution.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. We agree that additional details on the high-level policy are needed to support the claims and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that EDITH 'significantly reduces user effort' and 'enables the robot to act on the human's nonverbal signals even when intent is expressed only briefly' is load-bearing for the contribution, yet the manuscript supplies no architecture details, training procedure, noise-handling mechanisms, or quantitative metrics (intent accuracy, keyframe IoU, or effort reduction with error bars) for the high-level policy on real egocentric data.
Authors: We agree that the abstract claims require explicit supporting evidence from the high-level policy. The current manuscript presents the overall system and qualitative results from interactive tasks but does not include the requested quantitative metrics or implementation specifics for the high-level component. We will revise by adding these details, including architecture, training procedure, noise-handling, and metrics such as intent accuracy and effort reduction with error bars. revision: yes
-
Referee: [Method] The description of the high-level policy (which must map continuous, noisy first-person video + gaze streams to correct subtasks and keyframes in real time without human correction) provides no concrete implementation, loss functions, or robustness analysis, leaving the central assumption about signal reliability unverified and the performance claims unsupported.
Authors: We acknowledge that the method section describes the high-level policy at a conceptual level without concrete implementation details. We will expand this section in the revision to include the specific architecture, loss functions, training procedure, and robustness analysis for handling noisy egocentric streams. revision: yes
Circularity Check
No circularity: empirical system description with no derivations or self-referential reductions
full rationale
The paper presents EDITH as an empirical robotics framework that streams egocentric video/gaze/speech and uses a hierarchical policy (high-level intent inference to subtasks with keyframes, low-level execution). No equations, parameter fittings, or mathematical derivations appear in the provided text. Claims about reduced user effort and action on brief nonverbal signals are positioned as experimental outcomes, not as outputs forced by self-definition, fitted inputs renamed as predictions, or load-bearing self-citations. The derivation chain is self-contained as a descriptive system architecture without the circular patterns enumerated.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
O. Mees, L. Hermann, E. Rosete-Beas, and W. Burgard. Calvin: A benchmark for language- conditioned policy learning for long-horizon robot manipulation tasks.IEEE Robotics and Automation Letters, 7(3):7327–7334, 2022
2022
-
[2]
C. Lynch and P. Sermanet. Language conditioned imitation learning over unstructured data. arXiv preprint arXiv:2005.07648, 2020
arXiv 2005
-
[3]
Stepputtis, J
S. Stepputtis, J. Campbell, M. Phielipp, S. Lee, C. Baral, and H. Ben Amor. Language- conditioned imitation learning for robot manipulation tasks. InAdvances in Neural Information Processing Systems, 2020
2020
-
[4]
Radford, J
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clark, et al. Learning transferable visual models from natural language supervi- sion. InInternational Conference on Machine Learning, 2021
2021
-
[5]
M. Tschannen, A. Gritsenko, X. Wang, M. F. Naeem, I. Alabdulmohsin, N. Parthasarathy, T. Evans, L. Beyer, Y . Xia, B. Mustafa, et al. Siglip 2: Multilingual vision-language en- coders with improved semantic understanding, localization, and dense features.arXiv preprint arXiv:2502.14786, 2025
Pith/arXiv arXiv 2025
-
[6]
H. Liu, C. Li, Q. Wu, and Y . J. Lee. Visual instruction tuning. InAdvances in Neural Informa- tion Processing Systems, 2023
2023
-
[7]
L. Beyer, A. Steiner, A. S. Pinto, A. Kolesnikov, X. Wang, D. Salz, M. Neumann, I. Alabdul- mohsin, M. Tschannen, E. Bugliarello, et al. Paligemma: A versatile 3b vlm for transfer.arXiv preprint arXiv:2407.07726, 2024
Pith/arXiv arXiv 2024
-
[8]
A. Ali, J. Bai, M. Bala, Y . Balaji, A. Blakeman, T. Cai, J. Cao, T. Cao, E. Cha, Y .-W. Chao, et al. World simulation with video foundation models for physical ai.arXiv preprint arXiv:2511.00062, 2025
Pith/arXiv arXiv 2025
-
[9]
T. Wan, A. Wang, B. Ai, B. Wen, C. Mao, C.-W. Xie, D. Chen, F. Yu, H. Zhao, J. Yang, et al. Wan: Open and advanced large-scale video generative models.arXiv preprint arXiv:2503.20314, 2025
Pith/arXiv arXiv 2025
-
[10]
E. Jang, A. Irpan, M. Khansari, D. Kappler, F. Ebert, C. Lynch, S. Levine, and C. Finn. Bc-z: Zero-shot task generalization with robotic imitation learning. InConference on Robot Learn- ing, 2022
2022
-
[11]
Shridhar, L
M. Shridhar, L. Manuelli, and D. Fox. Cliport: What and where pathways for robotic manipu- lation. InConference on Robot Learning, 2022
2022
-
[12]
O. M. Team, D. Ghosh, H. Walke, K. Pertsch, K. Black, O. Mees, S. Dasari, J. Hejna, T. Kreiman, C. Xu, et al. Octo: An open-source generalist robot policy.arXiv preprint arXiv:2405.12213, 2024
Pith/arXiv arXiv 2024
-
[13]
Barreiros, A
J. Barreiros, A. Beaulieu, A. Bhat, R. Cory, E. Cousineau, H. Dai, C.-H. Fang, K. Hashimoto, M. Z. Irshad, M. Itkina, et al. A careful examination of large behavior models for multitask dexterous manipulation.Science Robotics, 11(113):eaea6201, 2026
2026
-
[14]
P. Intelligence, B. Ai, A. Amin, R. Aniceto, A. Balakrishna, G. Balke, K. Black, G. Bokin- sky, S. Cao, T. Charbonnier, et al.π 0.7: a steerable generalist robotic foundation model with emergent capabilities.arXiv preprint arXiv:2604.15483, 2026
Pith/arXiv arXiv 2026
-
[15]
S. Ye, Y . Ge, K. Zheng, S. Gao, S. Yu, G. Kurian, S. Indupuru, Y . L. Tan, C. Zhu, J. Xiang, et al. World action models are zero-shot policies.arXiv preprint arXiv:2602.15922, 2026. 10
Pith/arXiv arXiv 2026
-
[16]
Holler and S
J. Holler and S. C. Levinson. Multimodal language processing in human communication. Trends in cognitive sciences, 23(8):639–652, 2019
2019
-
[17]
Matuszek, L
C. Matuszek, L. Bo, L. Zettlemoyer, and D. Fox. Learning from unscripted deictic gesture and language for human-robot interactions. InAAAI Conference on Artificial Intelligence, 2014
2014
-
[18]
J. Engel, K. Somasundaram, M. Goesele, A. Sun, A. Gamino, A. Turner, A. Talattof, A. Yuan, B. Souti, B. Meredith, et al. Project aria: A new tool for egocentric multi-modal ai research. arXiv preprint arXiv:2308.13561, 2023
Pith/arXiv arXiv 2023
-
[19]
Physical Intelligence, K. Black, N. Brown, J. Darpinian, K. Dhabalia, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusai, et al.π 0.5: A vision-language-action model with open-world generalization.arXiv preprint arXiv:2504.16054, 2025
Pith/arXiv arXiv 2025
-
[20]
DeepMind
G. DeepMind. Gemini 3.1 flash-lite model card, 2026
2026
-
[21]
Kahneman.Thinking, fast and slow
D. Kahneman.Thinking, fast and slow. macmillan, 2011
2011
-
[22]
K. Black, N. Brown, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusai, L. Groom, K. Hausman, B. Ichter, et al.π 0: A vision-language-action flow model for general robot control.arXiv preprint arXiv:2410.24164, 2024
Pith/arXiv arXiv 2024
-
[23]
L. X. Shi, B. Ichter, M. R. Equi, L. Ke, K. Pertsch, Q. Vuong, J. Tanner, A. Walling, H. Wang, N. Fusai, et al. Hi robot: Open-ended instruction following with hierarchical vision-language- action models. InInternational Conference on Machine Learning, 2025
2025
-
[24]
M. Ahn, A. Brohan, N. Brown, Y . Chebotar, O. Cortes, B. David, C. Finn, C. Fu, K. Gopalakr- ishnan, K. Hausman, et al. Do as i can, not as i say: Grounding language in robotic affordances. InConference on Robot Learning, 2022
2022
-
[25]
Y . Li, Y . Deng, J. Zhang, J. Jang, M. Memmel, R. Yu, C. R. Garrett, F. Ramos, D. Fox, A. Li, A. Gupta, and A. Goyal. Hamster: Hierarchical action models for open-world robot manipulation. InInternational Conference on Learning Representations, 2025
2025
-
[26]
Black, M
K. Black, M. Nakamoto, P. Atreya, H. R. Walke, C. Finn, A. Kumar, and S. Levine. Zero- shot robotic manipulation with pre-trained image-editing diffusion models. InInternational Conference on Learning Representations, 2024
2024
-
[27]
J. Choi, J. Lee, J. Kim, C. Kim, T. Min, W. B. Knox, M. K. Lee, and K. Lee. State your intention to steer your attention: An ai assistant for intentional digital living. InCHI Conference on Human Factors in Computing Systems, 2026
2026
-
[28]
Radford, J
A. Radford, J. W. Kim, T. Xu, G. Brockman, C. McLeavey, and I. Sutskever. Robust speech recognition via large-scale weak supervision. InInternational Conference on Machine Learn- ing, 2023
2023
-
[29]
S. G. Hart and L. E. Staveland. Development of nasa-tlx (task load index): Results of empirical and theoretical research.Advances in psychology, 52:139–183, 1988
1988
-
[30]
Wilcoxon
F. Wilcoxon. Individual comparisons by ranking methods.Biometrics Bulletin, 1(6):80, 1945
1945
-
[31]
Tellex, N
S. Tellex, N. Gopalan, H. Kress-Gazit, and C. Matuszek. Robots that use language.Annual Review of Control, Robotics, and Autonomous Systems, 3(1):25–55, 2020
2020
-
[32]
Mavridis
N. Mavridis. A review of verbal and non-verbal human–robot interactive communication. Robotics and Autonomous Systems, 63:22–35, 2015
2015
-
[33]
W. Hunt, S. D. Ramchurn, and M. D. Soorati. A survey of language-based communication in robotics.arXiv preprint arXiv:2406.04086, 2024. 11
arXiv 2024
-
[34]
R. Liu and X. Zhang. Systems of natural-language-facilitated human-robot cooperation: A review.arXiv preprint arXiv:1701.08269, 2017
Pith/arXiv arXiv 2017
-
[35]
Bugmann, E
G. Bugmann, E. Klein, S. Lauria, T. Kyriacou, et al. Corpus-based robotics: A route instruction example. InIntelligent Autonomous Systems, 2004
2004
-
[36]
Deits, S
R. Deits, S. Tellex, P. Thaker, D. Simeonov, T. Kollar, and N. Roy. Clarifying commands with information-theoretic human-robot dialog.Journal of Human-Robot Interaction, 2(2):58–79, 2013
2013
-
[37]
Thomason, S
J. Thomason, S. Zhang, R. J. Mooney, and P. Stone. Learning to interpret natural language commands through human-robot dialog. InInternational Joint Conference on Artificial Intel- ligence, 2015
2015
-
[38]
Thomason, A
J. Thomason, A. Padmakumar, J. Sinapov, N. Walker, Y . Jiang, H. Yedidsion, J. Hart, P. Stone, and R. Mooney. Jointly improving parsing and perception for natural language commands through human-robot dialog.Journal of Artificial Intelligence Research, 67:327–374, 2020
2020
-
[39]
Liang, W
J. Liang, W. Huang, F. Xia, P. Xu, K. Hausman, B. Ichter, P. Florence, and A. Zeng. Code as policies: Language model programs for embodied control. InIEEE International conference on robotics and automation, 2023
2023
-
[40]
I. Singh, V . Blukis, A. Mousavian, A. Goyal, D. Xu, J. Tremblay, D. Fox, J. Thomason, and A. Garg. Progprompt: Generating situated robot task plans using large language models.arXiv preprint arXiv:2209.11302, 2022
Pith/arXiv arXiv 2022
-
[41]
A. Brohan, N. Brown, J. Carbajal, Y . Chebotar, J. Dabis, C. Finn, K. Gopalakrishnan, K. Haus- man, A. Herzog, J. Hsu, et al. Rt-1: Robotics transformer for real-world control at scale.arXiv preprint arXiv:2212.06817, 2022
Pith/arXiv arXiv 2022
-
[42]
M. J. Kim, K. Pertsch, S. Karamcheti, T. Xiao, A. Balakrishna, S. Nair, R. Rafailov, E. Foster, G. Lam, P. Sanketi, et al. Openvla: An open-source vision-language-action model.arXiv preprint arXiv:2406.09246, 2024
Pith/arXiv arXiv 2024
-
[43]
Zitkovich, T
B. Zitkovich, T. Yu, S. Xu, P. Xu, T. Xiao, F. Xia, J. Wu, P. Wohlhart, S. Welker, A. Wahid, et al. Rt-2: Vision-language-action models transfer web knowledge to robotic control. In Conference on Robot Learning, 2023
2023
-
[44]
J. Bjorck, F. Casta ˜neda, N. Cherniadev, X. Da, R. Ding, L. Fan, Y . Fang, D. Fox, F. Hu, S. Huang, et al. Gr00t n1: An open foundation model for generalist humanoid robots.arXiv preprint arXiv:2503.14734, 2025
Pith/arXiv arXiv 2025
-
[45]
L.-H. Lin, Y . Cui, Y . Hao, F. Xia, and D. Sadigh. Gesture-informed robot assistance via foundation model. InConference on Robot Learning, 2023
2023
-
[46]
Admoni and S
H. Admoni and S. S. Srinivasa. Predicting user intent through eye gaze for shared autonomy. InAAAI Fall Symposium Series, 2016
2016
-
[47]
H. Su, W. Qi, J. Chen, C. Yang, J. Sandoval, and M. A. Laribi. Recent advancements in multimodal human–robot interaction.Frontiers in Neurorobotics, 17:1084000, 2023
2023
-
[48]
Y . Lai, S. Yuan, B. Zhang, B. Kiefer, P. Li, T. Deng, and A. Zell. Fam-hri: Foundation-model assisted multi-modal human-robot interaction combining gaze and speech.arXiv preprint arXiv:2503.16492, 2025
Pith/arXiv arXiv 2025
-
[49]
Give me a straw- berry muffin, a cherry muffin, and an Oreo muffin
T. Y . H. Tay, X. Yan, J. Ouyang, D. Wu, W. Jiang, J. Kao, and Y . Cui. Intent at a glance: Gaze-guided robotic manipulation via foundation models.arXiv preprint arXiv:2601.05336, 2026. 12 Appendix A Additional Analysis Comparison toπ lang l provided with a fully-specified language instruction.We additionally evaluateπ lang l with the fully-specified lang...
arXiv 2026
-
[50]
Give me the muffin with grape topping, the muffin with cherry topping, and the muffin with 2 strawberries topping
-
[51]
Give me the muffin with cherry topping, the muffin with 2 strawberries topping, and the muffin with oreo and strawberry topping. 21
-
[52]
Give me the muffin with 2 strawberries topping, the muffin with oreo and strawberry topping, and the muffin with pineapple topping
-
[53]
Give me the muffin with oreo and strawberry topping, the muffin with pineapple topping, and the muffin with tangerine and strawberry topping
-
[54]
Give me the muffin with pineapple topping, the muffin with tangerine and strawberry top- ping, and the muffin with grape topping
-
[55]
Give me the muffin with tangerine and strawberry topping, the muffin with grape topping, and the muffin with cherry topping
-
[56]
Give me the muffin with grape topping, the muffin with 2 strawberries topping, and the muffin with pineapple topping
-
[57]
Give me the muffin with cherry topping, the muffin with oreo and strawberry topping, and the muffin with tangerine and strawberry topping
-
[58]
Give me the muffin with 2 strawberries topping, the muffin with pineapple topping, and the muffin with grape topping
-
[59]
Give me the muffin with oreo and strawberry topping, the muffin with tangerine and straw- berry topping, and the muffin with cherry topping
-
[60]
Give me the muffin with pineapple topping, the muffin with grape topping, and the muffin with 2 strawberries topping
-
[61]
Give me the muffin with tangerine and strawberry topping, the muffin with cherry topping, and the muffin with oreo and strawberry topping
-
[62]
Give me the muffin with grape topping, the muffin with oreo and strawberry topping, and the muffin with tangerine and strawberry topping
-
[63]
Give me the muffin with cherry topping, the muffin with pineapple topping, and the muffin with grape topping
-
[64]
Give me the muffin with 2 strawberries topping, the muffin with tangerine and strawberry topping, and the muffin with cherry topping
-
[65]
Give me the muffin with oreo and strawberry topping, the muffin with grape topping, and the muffin with 2 strawberries topping
-
[66]
Give me the muffin with pineapple topping, the muffin with cherry topping, and the muffin with oreo and strawberry topping
-
[67]
Give me the muffin with tangerine and strawberry topping, the muffin with 2 strawberries topping, and the muffin with pineapple topping
-
[68]
Give me the muffin with grape topping, the muffin with pineapple topping, and the muffin with cherry topping
-
[69]
Give me the muffin with cherry topping, the muffin with tangerine and strawberry topping, and the muffin with 2 strawberries topping
-
[70]
Give me the muffin with 2 strawberries topping, the muffin with grape topping, and the muffin with oreo and strawberry topping
-
[71]
Give me the muffin with oreo and strawberry topping, the muffin with cherry topping, and the muffin with pineapple topping
-
[72]
Give me the muffin with pineapple topping, the muffin with 2 strawberries topping, and the muffin with tangerine and strawberry topping
-
[73]
Put this tumbler and this tumbler into this basket
Give me the muffin with tangerine and strawberry topping, the muffin with oreo and straw- berry topping, and the muffin with grape topping. C.2 Tumbler-Sorting Scenario.Five different tumblers and two baskets are arranged on the table. The human directs the robot to place 2 tumblers into specific basket through a verbal instruction (“Put this tumbler and ...
-
[74]
Pick up the Pink Tumbler at the front left and put it in the left basket, and pick up the pink tumbler at front center and put it in the right basket
-
[75]
Pick up the Pink Tumbler at the front left and put it in the left basket, and pick up the green tumbler at front right and put it in the right basket
-
[76]
Pick up the Pink Tumbler at the front left and put it in the right basket, and pick up the Pink Tumbler at the back left and put it in the right basket
-
[77]
Pick up the Pink Tumbler at the front left and put it in the right basket, and pick up the green tumbler at back right and put it in the right basket
-
[78]
Pick up the pink tumbler at front center and put it in the left basket, and pick up the Pink Tumbler at the front left and put it in the left basket
-
[79]
Pick up the pink tumbler at front center and put it in the right basket, and pick up the green tumbler at front right and put it in the left basket
-
[80]
Pick up the pink tumbler at front center and put it in the left basket, and pick up the Pink Tumbler at the back left and put it in the left basket. 23
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.