Modeling Complex Behaviors: Multi-Personality Composition and Dynamic Switching in Vision-Language Models
Pith reviewed 2026-06-27 13:02 UTC · model grok-4.3
The pith
Prompt-based personality induction in vision-language models improves image captioning but impairs performance on reasoning tasks like VQA.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Model behavior is co-modulated by both previous and current personality constraints, as evidenced by balancing and residual effects observed during multi-trait composition and dynamic switching; personality induction improves image captioning performance but can impair performance on tasks requiring precise reasoning such as visual question answering.
What carries the argument
Explicit personality conditioning via prompts, which induces, composes, and switches personality traits to produce measurable changes in model output on captioning and VQA tasks.
If this is right
- Personality induction selectively boosts descriptive performance on image captioning.
- The same induction impairs accuracy on visual question answering that requires precise reasoning.
- Multi-trait composition produces balancing effects between competing personality constraints.
- Dynamic switching leaves residual influence from the prior personality on subsequent outputs.
- Existing prompt-based induction methods show limited transferability from text-only to multimodal settings.
Where Pith is reading between the lines
- Stable personality control in interactive applications may require methods beyond simple prompting.
- Residual effects could complicate long-running conversations where users expect consistent traits.
- The observed task-specific trade-offs suggest designers must choose induction targets based on primary use case.
- Limited multimodal transfer points to the value of testing induction techniques directly on image-text data rather than assuming text results generalize.
Load-bearing premise
Prompt-based personality induction produces measurable, stable personality-like behavior in MLLMs that can be isolated from other prompt or model effects without confounding factors in the chosen tasks.
What would settle it
Running the same captioning and VQA evaluations with personality prompts versus matched neutral prompts and finding no consistent performance differences or balancing/residual patterns would falsify the claim of distinct co-modulated effects.
Figures

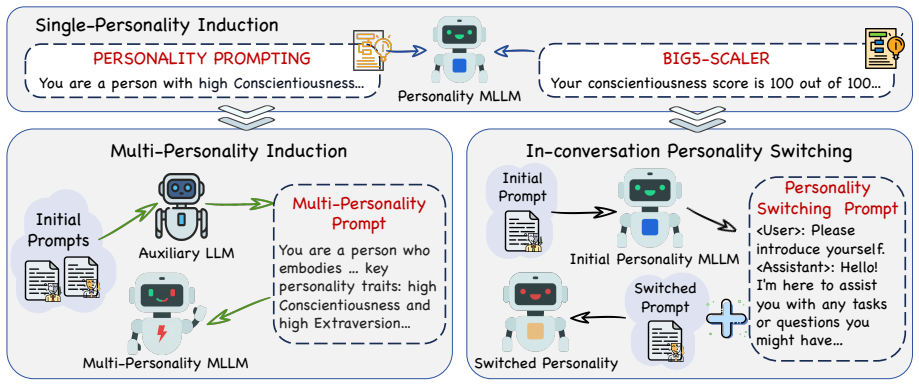
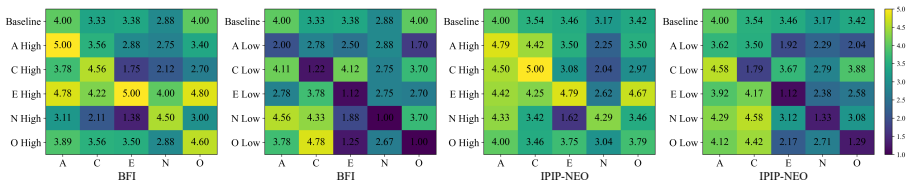
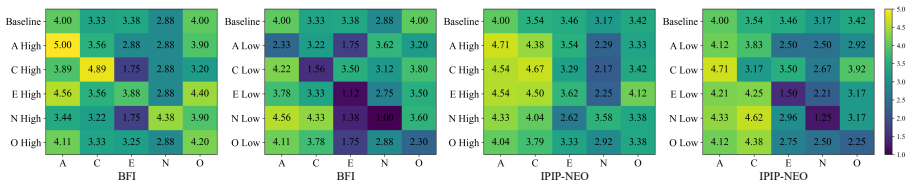
read the original abstract
With the widespread deployment of Multimodal Large Language Models (MLLMs) in social interaction, understanding and controlling their behavior under complex personality conditions is essential. This paper introduces explicit personality conditioning and establishes a systematic evaluation framework encompassing single-personality induction, multi-personality induction, and personality switching. Experiments show that personality induction improves image captioning performance but can impair performance on tasks requiring precise reasoning, such as visual question answering (VQA). Balancing and residual effects are observed during multi-trait composition and dynamic switching, indicating that model behavior is co-modulated by both previous and current personality constraints. Existing prompt-based personality induction methods show limited transferability to multimodal settings. Our work reveals the dynamic and complex nature of personality modeling in MLLMs and underscores the need for robust, tailored methods for personality induction and evaluation. The code will be released when the paper is accepted.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces explicit personality conditioning for Multimodal Large Language Models (MLLMs) along with a systematic evaluation framework covering single-personality induction, multi-personality composition, and dynamic personality switching. Experiments are reported to show that personality induction improves image captioning performance while impairing precise reasoning tasks such as VQA; balancing and residual effects are observed in multi-trait and switching scenarios, indicating co-modulation by prior and current personality constraints. Existing prompt-based methods exhibit limited transferability to multimodal settings, and the work calls for more robust induction and evaluation techniques. Code release is promised upon acceptance.
Significance. If the directional effects and balancing/residual phenomena are shown to be robust under controlled conditions with appropriate statistical support, the work would usefully illustrate the complexity of behavioral modulation in MLLMs and the shortcomings of current prompt-based approaches. This could help guide research on controllable multimodal systems for social applications. The commitment to release code supports reproducibility.
major comments (2)
- [Abstract] Abstract: The central claims of performance improvement on captioning, impairment on VQA, and the existence of balancing/residual effects are presented as directional observations without any reported sample sizes, number of trials, statistical tests, baselines, or error bars. This absence is load-bearing because the evaluation framework and all subsequent claims rest on these unspecified experiments.
- [Evaluation framework] Evaluation framework and experimental sections: The premise that prompt-based personality induction produces isolatable, stable personality-like behavior (distinct from general prompt or model effects) is not supported by described controls, ablations, or validation metrics. This directly affects interpretation of the multi-personality composition and switching results.
minor comments (1)
- The statement that code will be released upon acceptance is welcome; consider adding a footnote or repository link in the final version for immediate access.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback. We address each major comment below and indicate planned revisions to the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claims of performance improvement on captioning, impairment on VQA, and the existence of balancing/residual effects are presented as directional observations without any reported sample sizes, number of trials, statistical tests, baselines, or error bars. This absence is load-bearing because the evaluation framework and all subsequent claims rest on these unspecified experiments.
Authors: We agree that the abstract and supporting experimental descriptions would benefit from explicit statistical reporting. In the revised manuscript we will update the abstract to reference sample sizes, number of trials, baselines, error bars, and the statistical tests performed in the main text, and we will expand the evaluation framework section to include these details for all reported effects. revision: yes
-
Referee: [Evaluation framework] Evaluation framework and experimental sections: The premise that prompt-based personality induction produces isolatable, stable personality-like behavior (distinct from general prompt or model effects) is not supported by described controls, ablations, or validation metrics. This directly affects interpretation of the multi-personality composition and switching results.
Authors: We acknowledge that the current description relies primarily on downstream task differences to infer personality effects. We will add explicit controls and ablations (including neutral-prompt baselines and consistency checks across prompt variants) plus validation metrics in the revised experimental sections to better isolate personality-specific modulation from general prompt or model effects. revision: yes
Circularity Check
No significant circularity
full rationale
The paper is strictly empirical: it describes an evaluation framework for personality induction, multi-personality composition, and switching in MLLMs, then reports observed performance shifts on captioning and VQA tasks along with balancing/residual effects. No derivation chain, equations, fitted parameters, or first-principles predictions appear; all central claims are direct statements of experimental outcomes rather than reductions to inputs or self-citations. The work is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Prompt-based conditioning can isolate and control personality-like behavior in MLLMs independently of other prompt effects.
Reference graph
Works this paper leans on
-
[1]
2016 , eprint=
VQA: Visual Question Answering , author=. 2016 , eprint=
2016
-
[2]
2019 , eprint=
ViLBERT: Pretraining Task-Agnostic Visiolinguistic Representations for Vision-and-Language Tasks , author=. 2019 , eprint=
2019
-
[3]
2023 , eprint=
Building Emotional Support Chatbots in the Era of LLMs , author=. 2023 , eprint=
2023
-
[4]
SSRN Electronic Journal , year =
ChatGPT User Experience: Implications for Education , author =. SSRN Electronic Journal , year =
-
[5]
2020 , eprint=
DialoGPT: Large-Scale Generative Pre-training for Conversational Response Generation , author=. 2020 , eprint=
2020
-
[6]
2023 , eprint=
Sparks of Artificial General Intelligence: Early experiments with GPT-4 , author=. 2023 , eprint=
2023
-
[8]
2015 , eprint=
Exploring Models and Data for Image Question Answering , author=. 2015 , eprint=
2015
-
[9]
2016 , eprint=
Stacked Attention Networks for Image Question Answering , author=. 2016 , eprint=
2016
-
[10]
2018 , eprint=
Bottom-Up and Top-Down Attention for Image Captioning and Visual Question Answering , author=. 2018 , eprint=
2018
-
[11]
2021 , eprint=
Learning Transferable Visual Models From Natural Language Supervision , author=. 2021 , eprint=
2021
-
[12]
2021 , eprint=
Scaling Up Visual and Vision-Language Representation Learning With Noisy Text Supervision , author=. 2021 , eprint=
2021
-
[13]
2021 , eprint=
Masked Autoencoders Are Scalable Vision Learners , author=. 2021 , eprint=
2021
-
[14]
2022 , eprint=
BEiT v2: Masked Image Modeling with Vector-Quantized Visual Tokenizers , author=. 2022 , eprint=
2022
-
[15]
2022 , eprint=
BEiT: BERT Pre-Training of Image Transformers , author=. 2022 , eprint=
2022
-
[16]
2023 , eprint=
Visual Instruction Tuning , author=. 2023 , eprint=
2023
-
[17]
2023 , eprint=
Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond , author=. 2023 , eprint=
2023
-
[18]
2024 , eprint=
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution , author=. 2024 , eprint=
2024
-
[19]
2024 , eprint=
DeepSeek-VL2: Mixture-of-Experts Vision-Language Models for Advanced Multimodal Understanding , author=. 2024 , eprint=
2024
-
[20]
2025 , eprint=
Qwen3 Technical Report , author=. 2025 , eprint=
2025
-
[21]
2021 , eprint=
ClipCap: CLIP Prefix for Image Captioning , author=. 2021 , eprint=
2021
-
[22]
2022 , eprint=
ZeroCap: Zero-Shot Image-to-Text Generation for Visual-Semantic Arithmetic , author=. 2022 , eprint=
2022
-
[23]
2025 , eprint=
SC-Captioner: Improving Image Captioning with Self-Correction by Reinforcement Learning , author=. 2025 , eprint=
2025
-
[24]
2024 , eprint=
MMBench: Is Your Multi-modal Model an All-around Player? , author=. 2024 , eprint=
2024
-
[25]
2025 , eprint=
MME: A Comprehensive Evaluation Benchmark for Multimodal Large Language Models , author=. 2025 , eprint=
2025
-
[26]
2025 , eprint=
Qwen2.5-Omni Technical Report , author=. 2025 , eprint=
2025
-
[27]
The Big Five Inventory---Versions 4a and 54 , author =
-
[28]
1998 , publisher =
MBTI Manual: A Guide to the Development and Use of the Myers-Briggs Type Indicator , author =. 1998 , publisher =
1998
-
[29]
2024 , eprint=
Self-assessment, Exhibition, and Recognition: a Review of Personality in Large Language Models , author=. 2024 , eprint=
2024
-
[30]
2025 , eprint=
Persona-Assigned Large Language Models Exhibit Human-Like Motivated Reasoning , author=. 2025 , eprint=
2025
-
[31]
2024 , eprint=
HallusionBench: An Advanced Diagnostic Suite for Entangled Language Hallucination and Visual Illusion in Large Vision-Language Models , author=. 2024 , eprint=
2024
-
[32]
2025 , eprint=
Qwen2.5-VL Technical Report , author=. 2025 , eprint=
2025
-
[33]
2024 , eprint=
MathVista: Evaluating Mathematical Reasoning of Foundation Models in Visual Contexts , author=. 2024 , eprint=
2024
-
[34]
2024 , eprint=
Are We on the Right Way for Evaluating Large Vision-Language Models? , author=. 2024 , eprint=
2024
-
[35]
2023 , eprint=
SEED-Bench: Benchmarking Multimodal LLMs with Generative Comprehension , author=. 2023 , eprint=
2023
-
[36]
2024 , eprint=
MMMU: A Massive Multi-discipline Multimodal Understanding and Reasoning Benchmark for Expert AGI , author=. 2024 , eprint=
2024
-
[37]
On the Humanity of Conversational
Jen-tse Huang and Wenxuan Wang and Eric John Li and Man Ho LAM and Shujie Ren and Youliang Yuan and Wenxiang Jiao and Zhaopeng Tu and Michael Lyu , booktitle=. On the Humanity of Conversational. 2024 , url=
2024
-
[38]
2025 , eprint=
BIG5-CHAT: Shaping LLM Personalities Through Training on Human-Grounded Data , author=. 2025 , eprint=
2025
-
[39]
2024 , eprint=
The Better Angels of Machine Personality: How Personality Relates to LLM Safety , author=. 2024 , eprint=
2024
-
[40]
2025 , eprint=
Psychometric Personality Shaping Modulates Capabilities and Safety in Language Models , author=. 2025 , eprint=
2025
-
[41]
2025 , eprint=
Personality Alignment of Large Language Models , author=. 2025 , eprint=
2025
-
[42]
2023 , eprint=
Evaluating and Inducing Personality in Pre-trained Language Models , author=. 2023 , eprint=
2023
-
[43]
2025 , eprint=
Scaling Personality Control in LLMs with Big Five Scaler Prompts , author=. 2025 , eprint=
2025
-
[44]
2024 , eprint=
Editing Personality for Large Language Models , author=. 2024 , eprint=
2024
-
[45]
2024 , eprint=
Neuron-based Personality Trait Induction in Large Language Models , author=. 2024 , eprint=
2024
-
[46]
2025 , eprint=
Personality Vector: Modulating Personality of Large Language Models by Model Merging , author=. 2025 , eprint=
2025
-
[47]
Aho and Jeffrey D
Alfred V. Aho and Jeffrey D. Ullman , title =. 1972
1972
-
[48]
Publications Manual , year = "1983", publisher =
1983
-
[49]
Ashok K. Chandra and Dexter C. Kozen and Larry J. Stockmeyer , year = "1981", title =. doi:10.1145/322234.322243
-
[50]
Scalable training of
Andrew, Galen and Gao, Jianfeng , booktitle=. Scalable training of
-
[51]
Dan Gusfield , title =. 1997
1997
-
[52]
Tetreault , title =
Mohammad Sadegh Rasooli and Joel R. Tetreault , title =. Computing Research Repository , volume =. 2015 , url =
2015
-
[53]
A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =
Ando, Rie Kubota and Zhang, Tong , Issn =. A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =. Journal of Machine Learning Research , Month = dec, Numpages =
-
[54]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Cross-modal Identity Mapping: Minimizing Information Loss in Modality Conversion via Reinforcement Learning , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[57]
arXiv preprint arXiv:2602.22556 , year=
Stable adaptive thinking via advantage shaping and length-aware gradient regulation , author=. arXiv preprint arXiv:2602.22556 , year=
-
[58]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
Visual contextual attack: Jailbreaking mllms with image-driven context injection , author=. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
2025
-
[59]
Lawrence Zitnick, Dhruv Batra, and Devi Parikh
Aishwarya Agrawal, Jiasen Lu, Stanislaw Antol, Margaret Mitchell, C. Lawrence Zitnick, Dhruv Batra, and Devi Parikh. 2016. https://arxiv.org/abs/1505.00468 Vqa: Visual question answering . Preprint, arXiv:1505.00468
Pith/arXiv arXiv 2016
-
[60]
Peter Anderson, Xiaodong He, Chris Buehler, Damien Teney, Mark Johnson, Stephen Gould, and Lei Zhang. 2018. https://arxiv.org/abs/1707.07998 Bottom-up and top-down attention for image captioning and visual question answering . Preprint, arXiv:1707.07998
Pith/arXiv arXiv 2018
-
[61]
Jinze Bai, Shuai Bai, Shusheng Yang, Shijie Wang, Sinan Tan, Peng Wang, Junyang Lin, Chang Zhou, and Jingren Zhou. 2023. https://arxiv.org/abs/2308.12966 Qwen-vl: A versatile vision-language model for understanding, localization, text reading, and beyond . Preprint, arXiv:2308.12966
Pith/arXiv arXiv 2023
-
[62]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, Humen Zhong, Yuanzhi Zhu, Mingkun Yang, Zhaohai Li, Jianqiang Wan, Pengfei Wang, Wei Ding, Zheren Fu, Yiheng Xu, and 8 others. 2025. https://arxiv.org/abs/2502.13923 Qwen2.5-vl technical report . Preprint, arXiv:2502.13923
Pith/arXiv arXiv 2025
-
[63]
Hangbo Bao, Li Dong, Songhao Piao, and Furu Wei. 2022. https://arxiv.org/abs/2106.08254 Beit: Bert pre-training of image transformers . Preprint, arXiv:2106.08254
Pith/arXiv arXiv 2022
-
[64]
Sébastien Bubeck, Varun Chandrasekaran, Ronen Eldan, Johannes Gehrke, Eric Horvitz, Ece Kamar, Peter Lee, Yin Tat Lee, Yuanzhi Li, Scott Lundberg, Harsha Nori, Hamid Palangi, Marco Tulio Ribeiro, and Yi Zhang. 2023. https://arxiv.org/abs/2303.12712 Sparks of artificial general intelligence: Early experiments with gpt-4 . Preprint, arXiv:2303.12712
Pith/arXiv arXiv 2023
-
[65]
Lin Chen, Jinsong Li, Xiaoyi Dong, Pan Zhang, Yuhang Zang, Zehui Chen, Haodong Duan, Jiaqi Wang, Yu Qiao, Dahua Lin, and Feng Zhao. 2024. https://arxiv.org/abs/2403.20330 Are we on the right way for evaluating large vision-language models? Preprint, arXiv:2403.20330
Pith/arXiv arXiv 2024
-
[66]
Nuo Chen, Yan Wang, Haiyun Jiang, Deng Cai, Yuhan Li, Ziyang Chen, Longyue Wang, and Jia Li. 2023. https://doi.org/10.18653/v1/2023.findings-emnlp.570 Large language models meet harry potter: A dataset for aligning dialogue agents with characters . In Findings of the Association for Computational Linguistics: EMNLP 2023, pages 8506--8520, Singapore. Assoc...
-
[67]
Gunhee Cho and Yun-Gyung Cheong. 2025. https://arxiv.org/abs/2508.06149 Scaling personality control in llms with big five scaler prompts . Preprint, arXiv:2508.06149
arXiv 2025
-
[68]
Saloni Dash, Amélie Reymond, Emma S. Spiro, and Aylin Caliskan. 2025. https://arxiv.org/abs/2506.20020 Persona-assigned large language models exhibit human-like motivated reasoning . Preprint, arXiv:2506.20020
Pith/arXiv arXiv 2025
-
[69]
Jia Deng, Tianyi Tang, Yanbin Yin, Wenhao Yang, Wayne Xin Zhao, and Ji-Rong Wen. 2024. https://arxiv.org/abs/2410.12327 Neuron-based personality trait induction in large language models . Preprint, arXiv:2410.12327
Pith/arXiv arXiv 2024
-
[70]
Stephen Fitz, Peter Romero, Steven Basart, Sipeng Chen, and Jose Hernandez-Orallo. 2025. https://arxiv.org/abs/2509.16332 Psychometric personality shaping modulates capabilities and safety in language models . Preprint, arXiv:2509.16332
arXiv 2025
-
[71]
Chaoyou Fu, Peixian Chen, Yunhang Shen, Yulei Qin, Mengdan Zhang, Xu Lin, Jinrui Yang, Xiawu Zheng, Ke Li, Xing Sun, Yunsheng Wu, Rongrong Ji, Caifeng Shan, and Ran He. 2025. https://arxiv.org/abs/2306.13394 Mme: A comprehensive evaluation benchmark for multimodal large language models . Preprint, arXiv:2306.13394
Pith/arXiv arXiv 2025
-
[72]
Tianrui Guan, Fuxiao Liu, Xiyang Wu, Ruiqi Xian, Zongxia Li, Xiaoyu Liu, Xijun Wang, Lichang Chen, Furong Huang, Yaser Yacoob, Dinesh Manocha, and Tianyi Zhou. 2024. https://arxiv.org/abs/2310.14566 Hallusionbench: An advanced diagnostic suite for entangled language hallucination and visual illusion in large vision-language models . Preprint, arXiv:2310.14566
Pith/arXiv arXiv 2024
-
[73]
Kaiming He, Xinlei Chen, Saining Xie, Yanghao Li, Piotr Dollár, and Ross Girshick. 2021. https://arxiv.org/abs/2111.06377 Masked autoencoders are scalable vision learners . Preprint, arXiv:2111.06377
Pith/arXiv arXiv 2021
-
[74]
Le, Yunhsuan Sung, Zhen Li, and Tom Duerig
Chao Jia, Yinfei Yang, Ye Xia, Yi-Ting Chen, Zarana Parekh, Hieu Pham, Quoc V. Le, Yunhsuan Sung, Zhen Li, and Tom Duerig. 2021. https://arxiv.org/abs/2102.05918 Scaling up visual and vision-language representation learning with noisy text supervision . Preprint, arXiv:2102.05918
arXiv 2021
-
[75]
Haonan Jia, Shichao Dong, Xin Dong, Zenghui Sun, Jin Wang, Jinsong Lan, Xiaoyong Zhu, Bo Zheng, and Kaifu Zhang. 2026. Cross-modal identity mapping: Minimizing information loss in modality conversion via reinforcement learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 766--777
2026
-
[76]
Guangyuan Jiang, Manjie Xu, Song-Chun Zhu, Wenjuan Han, Chi Zhang, and Yixin Zhu. 2023. https://arxiv.org/abs/2206.07550 Evaluating and inducing personality in pre-trained language models . Preprint, arXiv:2206.07550
arXiv 2023
-
[77]
John, Eileen M
Oliver P. John, Eileen M. Donahue, and Robert L. Kentle. 1991. The big five inventory---versions 4a and 54. Technical report, University of California, Berkeley, Institute of Personality and Social Research
1991
-
[78]
Bohao Li, Rui Wang, Guangzhi Wang, Yuying Ge, Yixiao Ge, and Ying Shan. 2023. https://arxiv.org/abs/2307.16125 Seed-bench: Benchmarking multimodal llms with generative comprehension . Preprint, arXiv:2307.16125
Pith/arXiv arXiv 2023
-
[79]
Wenkai Li, Jiarui Liu, Andy Liu, Xuhui Zhou, Mona Diab, and Maarten Sap. 2025. https://arxiv.org/abs/2410.16491 Big5-chat: Shaping llm personalities through training on human-grounded data . Preprint, arXiv:2410.16491
arXiv 2025
-
[80]
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. 2023. https://arxiv.org/abs/2304.08485 Visual instruction tuning . Preprint, arXiv:2304.08485
Pith/arXiv arXiv 2023
-
[81]
Yuan Liu, Haodong Duan, Yuanhan Zhang, Bo Li, Songyang Zhang, Wangbo Zhao, Yike Yuan, Jiaqi Wang, Conghui He, Ziwei Liu, Kai Chen, and Dahua Lin. 2024. https://arxiv.org/abs/2307.06281 Mmbench: Is your multi-modal model an all-around player? Preprint, arXiv:2307.06281
Pith/arXiv arXiv 2024
-
[82]
Jiasen Lu, Dhruv Batra, Devi Parikh, and Stefan Lee. 2019. https://arxiv.org/abs/1908.02265 Vilbert: Pretraining task-agnostic visiolinguistic representations for vision-and-language tasks . Preprint, arXiv:1908.02265
arXiv 2019
-
[83]
Pan Lu, Hritik Bansal, Tony Xia, Jiacheng Liu, Chunyuan Li, Hannaneh Hajishirzi, Hao Cheng, Kai-Wei Chang, Michel Galley, and Jianfeng Gao. 2024. https://arxiv.org/abs/2310.02255 Mathvista: Evaluating mathematical reasoning of foundation models in visual contexts . Preprint, arXiv:2310.02255
Pith/arXiv arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.