Cross-Modal Benchmarking for Robotic Perception in Natural Environments
Pith reviewed 2026-06-27 10:57 UTC · model grok-4.3
The pith
Vision foundation models exhibit weaknesses in place recognition and metric depth estimation for field robotics in natural environments.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
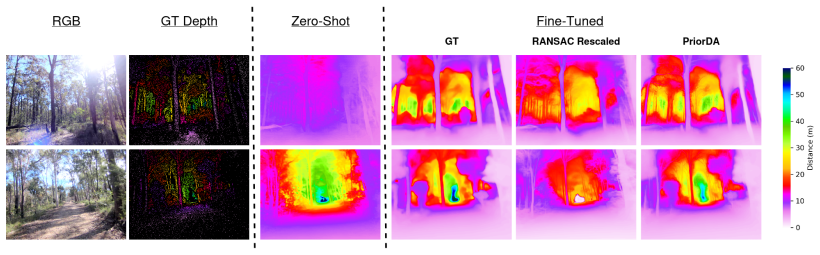
Current models show limitations in perception for field robotics tasks, as revealed by evaluation on the WildCross benchmark for place recognition and metric depth estimation in large-scale natural environments. The benchmark supplies over 476K sequential RGB frames with semi-dense depth and surface normal annotations aligned to accurate 6DoF poses and synchronized dense lidar submaps.
What carries the argument
The WildCross benchmark, a cross-modal dataset for evaluating place recognition and metric depth estimation using RGB frames aligned with depth, normals, 6DoF poses, and lidar submaps.
If this is right
- Vision models trained primarily on urban scenes will underperform on place recognition in natural environments.
- Metric depth estimation accuracy declines in large-scale natural scenes compared to structured settings.
- Cross-modal alignment with lidar data provides a direct way to quantify vision model errors in the wild.
- Expanded depth estimation experiments highlight specific failure modes not visible in place recognition alone.
Where Pith is reading between the lines
- Foundation model developers could improve robustness by incorporating natural environment data during pretraining.
- Field robotics systems may need domain-specific adaptation layers or multi-modal fusion beyond pure vision.
- The benchmark design allows tracking whether future models close the observed performance gap over time.
Load-bearing premise
The semi-dense depth, surface normal annotations, 6DoF poses, and synchronized lidar submaps in WildCross are sufficiently accurate and representative to reliably expose model limitations.
What would settle it
Re-running the model evaluations on WildCross after correcting for annotation errors or adding equivalent data from a different natural site yields no performance gaps relative to urban benchmarks.
Figures

read the original abstract
Natural environments present a complex challenge to robotics perception systems. Current models, particularly vision foundation models, are largely trained on structured, urban environments leading to weaknesses in their perception for field robotics tasks. We showcase the limitations of current models using our recently released WildCross benchmark, a new cross-modal benchmark for place recognition and metric depth estimation in large-scale natural environments. WildCross comprises over 476K sequential RGB frames with semi-dense depth and surface normal annotations, each aligned with accurate 6DoF pose and synchronized dense lidar submaps. In this work, we provide an expanded analysis of the benchmark results from the recent WildCross benchmark, with particular emphasis on expanded metric depth estimation experiments. Access to the code repository and dataset for this work can be found at https://csiro-robotics.github.io/WildCross.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that current vision foundation models exhibit weaknesses in perception for field robotics tasks in natural environments. This is demonstrated via an expanded analysis of the WildCross benchmark for place recognition and metric depth estimation, which comprises over 476K sequential RGB frames with semi-dense depth and surface normal annotations aligned to accurate 6DoF poses and synchronized dense lidar submaps.
Significance. If the ground-truth annotations are shown to be reliable, the work would be significant for exposing the domain gap between urban-trained models and unstructured natural environments, providing a large-scale cross-modal benchmark that could guide future robust perception research. The public release of the dataset and code is a clear strength supporting reproducibility.
major comments (2)
- [Abstract] Abstract: The central claim that the benchmark exposes model limitations rests on the annotations (semi-dense depth, surface normals, 6DoF poses, lidar submaps) being sufficiently accurate. However, the manuscript provides no quantitative validation such as absolute error histograms, consistency checks with independent lidar returns, or inter-annotator agreement in unstructured vegetation or terrain. This is load-bearing, as annotation noise could explain reported performance gaps rather than model weaknesses.
- [Abstract] Dataset description (Abstract): The text asserts 'accurate 6DoF pose' and 'synchronized dense lidar submaps' without reporting error bounds or cross-checks, directly undermining the weakest assumption that these labels reliably expose model limitations in natural environments.
minor comments (1)
- [Abstract] Abstract: The phrasing 'our recently released WildCross benchmark' and 'expanded analysis of the benchmark results from the recent WildCross benchmark' is redundant; clarify the relationship between this manuscript and the original benchmark release.
Simulated Author's Rebuttal
We thank the referee for highlighting the importance of validating the ground-truth annotations in the WildCross benchmark. We address each major comment below and will revise the manuscript to include additional validation details where possible.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that the benchmark exposes model limitations rests on the annotations (semi-dense depth, surface normals, 6DoF poses, lidar submaps) being sufficiently accurate. However, the manuscript provides no quantitative validation such as absolute error histograms, consistency checks with independent lidar returns, or inter-annotator agreement in unstructured vegetation or terrain. This is load-bearing, as annotation noise could explain reported performance gaps rather than model weaknesses.
Authors: We acknowledge this point. The manuscript describes the use of high-precision RTK-GPS for 6DoF poses and lidar for depth annotations, but does not provide explicit quantitative error analysis in the provided sections. To address this concern, we will add quantitative validation including error histograms and consistency checks in the revised manuscript. revision: yes
-
Referee: [Abstract] Dataset description (Abstract): The text asserts 'accurate 6DoF pose' and 'synchronized dense lidar submaps' without reporting error bounds or cross-checks, directly undermining the weakest assumption that these labels reliably expose model limitations in natural environments.
Authors: The term 'accurate' is based on the sensor specifications (RTK positioning typically achieving centimeter-level accuracy). However, we agree that reporting explicit error bounds would strengthen the paper. We will include sensor accuracy specifications and any available cross-validation results in the revised version of the manuscript. revision: yes
Circularity Check
No circularity: empirical benchmark release and model evaluation
full rationale
The paper releases the WildCross dataset (476K RGB frames with annotations) and reports direct empirical evaluations of existing vision foundation models on place recognition and metric depth estimation. No derivation chain, equations, fitted parameters, or predictions are described; the central claim is simply that models exhibit weaknesses when tested on this new benchmark. No self-citation load-bearing, self-definitional steps, or renaming of results occurs. The work is self-contained as a dataset contribution plus standard benchmarking, with no reduction of any claimed result to its own inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Advances in Agri- culture Robotics: A State-of-the-Art Review and Challenges Ahead ,
L. F. Oliveira, A. P. Moreira, and M. F. Silva, “Advances in Agri- culture Robotics: A State-of-the-Art Review and Challenges Ahead ,” Robotics, vol. 10, no. 2, p. 52, 2021
2021
-
[2]
Vision meets Robotics: The KITTI Dataset,
A. Geiger, P. Lenz, C. Stiller, and R. Urtasun, “Vision meets Robotics: The KITTI Dataset,”Int. J. Robot. Res., vol. 32, no. 11, pp. 1231– 1237, 2013
2013
-
[3]
1 Year, 1000km: The Oxford RobotCar Dataset,
W. Maddern, G. Pascoe, C. Linegar, and P. Newman, “1 Year, 1000km: The Oxford RobotCar Dataset,”Int. J. Robot. Res., vol. 36, no. 1, pp. 3–15, 2017
2017
-
[4]
Indoor Segmen- tation and Support Inference from RGBD Images,
N. Silberman, D. Hoiem, P. Kohli, and R. Fergus, “Indoor Segmen- tation and Support Inference from RGBD Images,” inEur . Conf. Comput. Vis., 2012, pp. 746–760
2012
-
[5]
VGGT: Visual Geometry Grounded Transformer,
J. Wang, M. Chen, N. Karaev, A. Vedaldi, C. Rupprecht, and D. Novotny, “VGGT: Visual Geometry Grounded Transformer,” in IEEE Conf. Comput. Vis. Pattern Recog., 2025, pp. 5294–5306
2025
-
[6]
Lip- loc: Lidar image pretraining for cross-modal localization,
S. Shubodh, M. Omama, H. Zaidi, U. S. Parihar, and M. Krishna, “Lip- loc: Lidar image pretraining for cross-modal localization,” inIEEE Conf. Comput. Vis. Pattern Recog. Worksh., 2024, pp. 948–957. Accepted to the IEEE ICRA Workshop on Open Challenges for Rigorous Robot Perception 2026
2024
-
[7]
Wild- Cross: A Cross-Modal Large Scale Benchmark for Place Recognition and Metric Depth Estimation in Natural Environments,
J. Knights, J. Reid, M. Cox, K. Roy, D. Hall, and P. Moghadam, “Wild- Cross: A Cross-Modal Large Scale Benchmark for Place Recognition and Metric Depth Estimation in Natural Environments,” inIEEE Int. Conf. Robot. Autom., 2026
2026
-
[8]
Wild-Places: A Large-Scale Dataset for Lidar Place Recognition in Unstructured Natural Environments,
J. Knights, K. Vidanapathirana, M. Ramezani, S. Sridharan, C. Fookes, and P. Moghadam, “Wild-Places: A Large-Scale Dataset for Lidar Place Recognition in Unstructured Natural Environments,” inIEEE Int. Conf. Robot. Autom., 2023, pp. 11 322–11 328
2023
-
[9]
Depth Anything V2,
L. Yang, B. Kang, Z. Huang, Z. Zhao, X. Xu, J. Feng, and H. Zhao, “Depth Anything V2,”Adv. Neural Inform. Process. Syst., vol. 37, pp. 21 875–21 911, 2024
2024
-
[10]
WildScenes: A benchmark for 2D and 3D semantic segmentation in large-scale natural environments,
K. Vidanapathirana, J. Knights, S. Hausler, M. Cox, M. Ramezani, J. Jooste, E. Griffiths, S. Mohamed, S. Sridharan, C. Fookes, and P. Moghadam, “WildScenes: A benchmark for 2D and 3D semantic segmentation in large-scale natural environments,”Int. J. Robot. Res., vol. 44, no. 4, pp. 532–549, 2025
2025
-
[11]
Wildcat: Online continuous- time 3d lidar-inertial slam,
M. Ramezani, K. Khosoussi, G. Catt, P. Moghadam, J. Williams, P. Borges, F. Pauling, and N. Kottege, “Wildcat: Online continuous- time 3d lidar-inertial slam,”arXiv preprint arXiv:2205.12595, 2022
arXiv 2022
-
[12]
NetVLAD: CNN architecture for weakly supervised place recogni- tion,
R. Arandjelovic, P. Gronat, A. Torii, T. Pajdla, and J. Sivic, “NetVLAD: CNN architecture for weakly supervised place recogni- tion,” inIEEE Conf. Comput. Vis. Pattern Recog., 2016, pp. 5297– 5307
2016
-
[13]
MixVPR: Feature Mixing for Visual Place Recognition,
A. Ali-Bey, B. Chaib-Draa, and P. Giguere, “MixVPR: Feature Mixing for Visual Place Recognition,” inIEEE Conf. Comput. Vis. Pattern Recog., 2023, pp. 2998–3007
2023
-
[14]
Optimal transport aggregation for visual place recognition,
S. Izquierdo and J. Civera, “Optimal transport aggregation for visual place recognition,” inIEEE Conf. Comput. Vis. Pattern Recog., 2024
2024
-
[15]
BoQ: A Place is Worth a Bag of Learnable Queries,
A. Ali-Bey, B. Chaib-draa, and P. Giguere, “BoQ: A Place is Worth a Bag of Learnable Queries,” inIEEE Conf. Comput. Vis. Pattern Recog., 2024, pp. 17 794–17 803
2024
-
[16]
Rethinking Visual Geo- localization for Large-Scale Applications,
G. Berton, C. Masone, and B. Caputo, “Rethinking Visual Geo- localization for Large-Scale Applications,” inIEEE Conf. Comput. Vis. Pattern Recog., 2022, pp. 4878–4888
2022
-
[17]
Deep residual learning for image recognition,
K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” inIEEE Conf. Comput. Vis. Pattern Recog., 2016, pp. 770–778
2016
-
[18]
DINOv2: Learning Robust Visual Features without Supervision,
M. Oquab, T. Darcet, T. Moutakanni, H. V o, M. Szafraniec, V . Khali- dov, P. Fernandez, D. Haziza, F. Massa, A. El-Nouby,et al., “DINOv2: Learning Robust Visual Features without Supervision,”arXiv preprint arXiv:2304.07193, 2023
Pith/arXiv arXiv 2023
-
[19]
O. Sim ´eoni, H. V . V o, M. Seitzer, F. Baldassarre, M. Oquab, C. Jose, V . Khalidov, M. Szafraniec, S. Yi, M. Ramamonjisoa,et al., “DI- NOv3,”arXiv preprint arXiv:2508.10104, 2025
Pith/arXiv arXiv 2025
-
[20]
Virtual Worlds as Proxy for Multi-Object Tracking Analysis,
A. Gaidon, Q. Wang, Y . Cabon, and E. Vig, “Virtual Worlds as Proxy for Multi-Object Tracking Analysis,” inIEEE Conf. Comput. Vis. Pattern Recog., 2016, pp. 4340–4349
2016
-
[21]
Depth anything 3: Recovering the visual space from any views,
H. Lin, S. Chen, J. Liew, D. Y . Chen, Z. Li, G. Shi, J. Feng, and B. Kang, “Depth anything 3: Recovering the visual space from any views,”arXiv preprint arXiv:2511.10647, 2025
Pith/arXiv arXiv 2025
-
[22]
Depth anything with any prior,
Z. Wang, S. Chen, L. Yang, J. Wang, Z. Zhang, H. Zhao, and Z. Zhao, “Depth anything with any prior,”arXiv preprint arXiv:2505.10565, 2025
arXiv 2025
-
[23]
Visual Place Recogni- tion with Repetitive Structures,
A. Torii, J. Sivic, T. Pajdla, and M. Okutomi, “Visual Place Recogni- tion with Repetitive Structures,” inIEEE Conf. Comput. Vis. Pattern Recog., 2013, pp. 883–890
2013
-
[24]
Mapillary Street-Level Sequences: A Dataset for Lifelong Place Recognition,
F. Warburg, S. Hauberg, M. Lopez-Antequera, P. Gargallo, Y . Kuang, and J. Civera, “Mapillary Street-Level Sequences: A Dataset for Lifelong Place Recognition,” inIEEE Conf. Comput. Vis. Pattern Recog., 2020, pp. 2626–2635. Accepted to the IEEE ICRA Workshop on Open Challenges for Rigorous Robot Perception 2026
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.