OpenMedReason: Scientific Reasoning Supervision for Medical Vision-Language Models
Pith reviewed 2026-06-27 09:52 UTC · model grok-4.3
The pith
A corpus of 450K medical image-question pairs with human-authored reasoning traces from biomedical articles lifts vision-language model accuracy by 20 percent.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
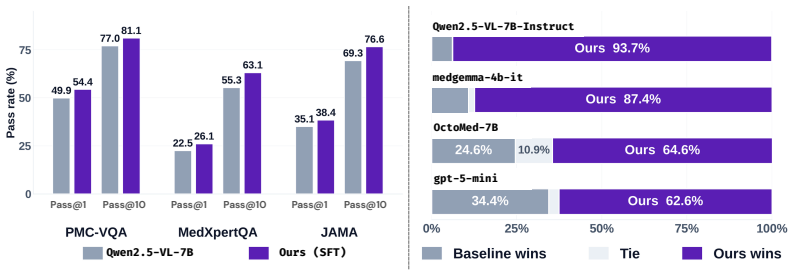
OpenMedReason supplies high-fidelity supervision for medical vision-language models by deriving reasoning traces primarily from curated human-authored biomedical scientific articles rather than synthetic chains of thought, resulting in models that improve 20 percent in VQA accuracy, advance jointly on perception, knowledge, and rationale, and produce traces preferred 86.1 percent of the time.
What carries the argument
OpenMedReason, a multimodal medical reasoning corpus of approximately 450K image-question-answer instances whose reasoning traces are derived from curated biomedical human-authored scientific articles.
If this is right
- Both supervised fine-tuning and reinforcement-based alignment produce measurable gains when trained on the corpus.
- Improvements appear jointly across perception, medical knowledge, and rationale rather than being confined to one axis.
- Reasoning traces generated after training are preferred over base-model traces in 86.1 percent of pairwise human comparisons.
- Final performance reaches within 4.2 percent of the strongest medical LVLMs of comparable scale.
Where Pith is reading between the lines
- A parallel corpus built from human-authored articles in another technical domain could be expected to produce similar joint gains for domain-specific vision-language models.
- The three-axis benchmark could be applied to diagnose whether future models continue to lag on particular modalities such as charts or microscopic images.
- Repeating the training experiments on models substantially larger or smaller than those tested would reveal whether the reported accuracy lift depends on model scale.
Load-bearing premise
Reasoning traces extracted from human-authored biomedical scientific articles supply higher-fidelity supervision than synthetic chains of thought for training medical vision-language models.
What would settle it
Train one model on OpenMedReason and an identical model on an equal volume of synthetic reasoning traces, then compare both on held-out VQA accuracy and on human preference for their generated reasoning traces.
Figures






read the original abstract
High-stakes clinical use of large vision-language models (LVLMs) requires reasoning that is grounded in visual evidence and clinical knowledge, not just correct final answers. We introduce OpenMedReason, a large-scale, open multimodal medical reasoning corpus comprising approximately 450K image-question-answer instances whose reasoning traces are primarily derived from curated biomedical, human-authored scientific articles. OpenMedReason provides high-fidelity supervision beyond synthetic chains of thought, covering diverse medical domain vision modalities such as radiological scans, microscopic images, visible light photographs, charts, and others. We complement it with OpenMedReason-Bench, a held-out benchmark that allows fine-grained evaluation of LVLMs along three complementary axes of capability, including perception, medical knowledge, and rationale, enabling diagnostic evaluation beyond final-answer accuracy. OpenMedReason is a rich training resource that exhibits its effectiveness in both supervised fine-tuning (SFT) and reinforcement-based alignment. Training with OpenMedReason yields a 20% average improvement in VQA accuracy over the base model and achieves performance within 4.2% of the strongest comparable-scale medical LVLMs. Fine-grained performance analysis confirms that the gains are not concentrated in any single axis: OpenMedReason improves perception, medical knowledge, and rationale jointly, and its reasoning traces are preferred over those of the base model in 86.1% of pairwise comparisons. We release the code and dataset at huggingface.co/datasets/neginb/OpenMedReason.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces OpenMedReason, an open multimodal medical reasoning corpus of ~450K image-question-answer instances whose reasoning traces are primarily derived from curated biomedical, human-authored scientific articles. It also releases OpenMedReason-Bench for fine-grained evaluation along perception, medical knowledge, and rationale axes. The authors report that SFT and reinforcement alignment on this data produce a 20% average VQA accuracy gain over the base model, performance within 4.2% of strong comparable-scale medical LVLMs, joint gains across the three axes, and 86.1% human preference for the generated reasoning traces over the base model.
Significance. An openly released, large-scale medical reasoning dataset with human-authored article grounding could be a useful resource for training LVLMs if the claimed fidelity advantage is substantiated. The public release of both dataset and code is a clear positive.
major comments (2)
- [Abstract] Abstract (paragraph 2): The claim that the traces supply 'high-fidelity supervision beyond synthetic chains of thought' because they are 'primarily derived from curated biomedical, human-authored scientific articles' is load-bearing for the central contribution, yet the abstract (and thus the manuscript's headline claim) provides no description of the derivation pipeline—manual extraction, LLM summarization, human editing, or automated alignment to images. Without this, the qualitative distinction from synthetic CoT cannot be evaluated.
- [Abstract] Abstract: No curation criteria for the source articles, no inter-annotator agreement statistics for reasoning quality, and no statistical significance tests or confidence intervals are reported for the 20% VQA improvement or the 86.1% preference rate. These omissions prevent assessment of whether the quantitative gains are reliable or attributable to the claimed fidelity rather than scale or domain coverage alone.
minor comments (1)
- [Abstract] Abstract: The phrase 'diverse medical domain vision modalities such as radiological scans, microscopic images, visible light photographs, charts, and others' would benefit from a quantitative breakdown of modality distribution.
Simulated Author's Rebuttal
We thank the referee for the detailed feedback on the abstract and evaluation reporting. We address each major comment below and will revise the manuscript accordingly where the points can be addressed without misrepresenting the work.
read point-by-point responses
-
Referee: [Abstract] Abstract (paragraph 2): The claim that the traces supply 'high-fidelity supervision beyond synthetic chains of thought' because they are 'primarily derived from curated biomedical, human-authored scientific articles' is load-bearing for the central contribution, yet the abstract (and thus the manuscript's headline claim) provides no description of the derivation pipeline—manual extraction, LLM summarization, human editing, or automated alignment to images. Without this, the qualitative distinction from synthetic CoT cannot be evaluated.
Authors: We agree the abstract should include a concise description of the derivation pipeline to support the central claim. The full manuscript (Section 3) details that reasoning traces are obtained via automated parsing of scientific articles followed by human curation and image alignment. We will add a one-sentence summary of this process to the abstract in revision. revision: yes
-
Referee: [Abstract] Abstract: No curation criteria for the source articles, no inter-annotator agreement statistics for reasoning quality, and no statistical significance tests or confidence intervals are reported for the 20% VQA improvement or the 86.1% preference rate. These omissions prevent assessment of whether the quantitative gains are reliable or attributable to the claimed fidelity rather than scale or domain coverage alone.
Authors: Curation criteria for source articles are provided in Section 3.1. Inter-annotator agreement statistics are not reported because the traces are extracted from pre-existing human-authored articles rather than newly created multi-annotator labels. We will add statistical significance tests and confidence intervals for the VQA gains and preference rates in the revised results section. revision: partial
- Inter-annotator agreement statistics for reasoning quality, as the dataset is constructed by deriving traces from existing scientific articles without new multi-annotator labeling.
Circularity Check
No circularity; dataset presented as external resource with empirical evaluation
full rationale
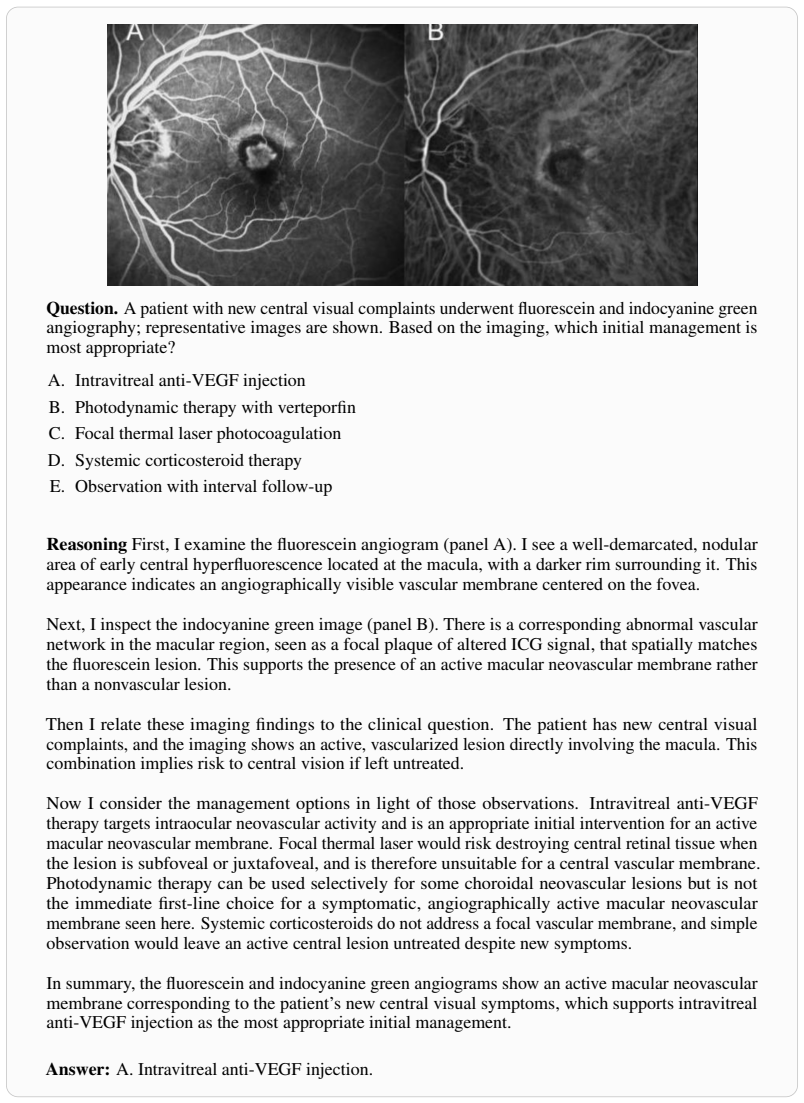
The paper introduces OpenMedReason as a corpus of ~450K instances whose reasoning traces are stated to be derived from curated human-authored biomedical articles, with no equations, fitted parameters, predictions, or self-citations invoked to justify any derivation. Performance gains (20% VQA lift, 86.1% preference) are reported as empirical outcomes on a held-out benchmark after SFT or alignment, without any reduction to model outputs or self-referential inputs. The central claim rests on the external sourcing of traces rather than any internal loop, making the work self-contained as a data contribution.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Reasoning traces extracted from curated biomedical, human-authored scientific articles supply high-fidelity supervision beyond synthetic chains of thought.
Reference graph
Works this paper leans on
-
[1]
Llava-med: Training a large language-and-vision assistant for biomedicine in one day.Advances in Neural Information Processing Systems, 36:28541–28564, 2023
Chunyuan Li, Cliff Wong, Sheng Zhang, Naoto Usuyama, Haotian Liu, Jianwei Yang, Tristan Nau- mann, Hoifung Poon, and Jianfeng Gao. Llava-med: Training a large language-and-vision assistant for biomedicine in one day.Advances in Neural Information Processing Systems, 36:28541–28564, 2023
2023
-
[2]
Andrew Sellergren, Sahar Kazemzadeh, Tiam Jaroensri, Atilla Kiraly, Madeleine Traverse, Timo Kohlberger, Shawn Xu, Fayaz Jamil, Cían Hughes, Charles Lau, et al. Medgemma technical report. arXiv preprint arXiv:2507.05201, 2025
Pith/arXiv arXiv 2025
-
[3]
Weiwen Xu, Hou Pong Chan, Long Li, Mahani Aljunied, Ruifeng Yuan, Jianyu Wang, Chenghao Xiao, Guizhen Chen, Chaoqun Liu, Zhaodonghui Li, et al. Lingshu: A generalist foundation model for unified multimodal medical understanding and reasoning.arXiv preprint arXiv:2506.07044, 2025
Pith/arXiv arXiv 2025
-
[4]
Towards generalist biomedical ai.Nejm Ai, 1(3):AIoa2300138, 2024
Tao Tu, Shekoofeh Azizi, Danny Driess, Mike Schaekermann, Mohamed Amin, Pi-Chuan Chang, Andrew Carroll, Charles Lau, Ryutaro Tanno, Ira Ktena, et al. Towards generalist biomedical ai.Nejm Ai, 1(3):AIoa2300138, 2024
2024
-
[5]
Advancing medical representation learning through high-quality data
Negin Baghbanzadeh, Adibvafa Fallahpour, Yasaman Parhizkar, Franklin Ogidi, Shuvendu Roy, Sajad Ashkezari, Vahid Reza Khazaie, Michael Colacci, Ali Etemad, Arash Afkanpour, et al. Advancing medical representation learning through high-quality data
-
[6]
The illusion of readiness in health ai.arXiv preprint arXiv:2509.18234, 2025
Yu Gu, Jingjing Fu, Xiaodong Liu, Jeya Maria Jose Valanarasu, Noel CF Codella, Reuben Tan, Qianchu Liu, Ying Jin, Sheng Zhang, Jinyu Wang, et al. The illusion of readiness in health ai.arXiv preprint arXiv:2509.18234, 2025
arXiv 2025
-
[7]
Hidden flaws behind expert-level accuracy of multimodal gpt-4 vision in medicine.NPJ Digital Medicine, 7(1):190, 2024
Qiao Jin, Fangyuan Chen, Yiliang Zhou, Ziyang Xu, Justin M Cheung, Robert Chen, Ronald M Summers, Justin F Rousseau, Peiyun Ni, Marc J Landsman, et al. Hidden flaws behind expert-level accuracy of multimodal gpt-4 vision in medicine.NPJ Digital Medicine, 7(1):190, 2024
2024
-
[8]
Qoq-med: Building multimodal clinical foundation models with domain-aware grpo training
Wei Dai, Peilin Chen, Chanakya Ekbote, and Paul Pu Liang. Qoq-med: Building multimodal clinical foundation models with domain-aware grpo training. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems
-
[9]
Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.Nature, 2025
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.Nature, 2025
2025
-
[10]
When does rl help medical vlms? disentangling vision, sft, and rl gains, 2026
Ahmadreza Jeddi, Kimia Shaban, Negin Baghbanzadeh, Natasha Sharan, Abhishek Moturu, Elham Dolatabadi, and Babak Taati. When does rl help medical vlms? disentangling vision, sft, and rl gains, 2026
2026
-
[11]
Timothy Ossowski, Sheng Zhang, Qianchu Liu, Guanghui Qin, Reuben Tan, Tristan Naumann, Junjie Hu, and Hoifung Poon. Octomed: Data recipes for state-of-the-art multimodal medical reasoning.arXiv preprint arXiv:2511.23269, 2025
arXiv 2025
-
[12]
Xiaoke Huang, Juncheng Wu, Hui Liu, Xianfeng Tang, and Yuyin Zhou. Medvlthinker: Simple baselines for multimodal medical reasoning.Neural Information Processing Systems (NeurIPS 2025) Workshop: The Second Workshop on GenAI for Health: Potential, Trust, and Policy Compliance, 2024
2025
-
[13]
A dataset of clinically generated visual questions and answers about radiology images.Scientific data, 5(1):180251, 2018
Jason J Lau, Soumya Gayen, Asma Ben Abacha, and Dina Demner-Fushman. A dataset of clinically generated visual questions and answers about radiology images.Scientific data, 5(1):180251, 2018
2018
-
[14]
Slake: A semantically-labeled knowledge-enhanced dataset for medical visual question answering
Bo Liu, Li-Ming Zhan, Li Xu, Lin Ma, Yan Yang, and Xiao-Ming Wu. Slake: A semantically-labeled knowledge-enhanced dataset for medical visual question answering. In2021 IEEE 18th international symposium on biomedical imaging (ISBI), pages 1650–1654. IEEE, 2021
2021
-
[15]
Towards visual question answering on pathology images
Xuehai He, Zhuo Cai, Wenlan Wei, Yichen Zhang, Luntian Mou, Eric Xing, and Pengtao Xie. Towards visual question answering on pathology images. In Chengqing Zong, Fei Xia, Wenjie Li, and Roberto Navigli, editors,Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Lan...
2021
-
[16]
Development of a large-scale medical visual question-answering dataset.Communications Medicine, 4(1):277, 2024
Xiaoman Zhang, Chaoyi Wu, Ziheng Zhao, Weixiong Lin, Ya Zhang, Yanfeng Wang, and Weidi Xie. Development of a large-scale medical visual question-answering dataset.Communications Medicine, 4(1):277, 2024. 10
2024
-
[17]
Omnimedvqa: A new large-scale comprehensive evaluation benchmark for medical lvlm
Yutao Hu, Tianbin Li, Quanfeng Lu, Wenqi Shao, Junjun He, Yu Qiao, and Ping Luo. Omnimedvqa: A new large-scale comprehensive evaluation benchmark for medical lvlm. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 22170–22183, 2024
2024
-
[18]
Medxpertqa: Benchmarking expert-level medical reasoning and understanding
Yuxin Zuo, Shang Qu, Yifei Li, Zhang-Ren Chen, Xuekai Zhu, Ermo Hua, Kaiyan Zhang, Ning Ding, and Bowen Zhou. Medxpertqa: Benchmarking expert-level medical reasoning and understanding. In International Conference on Machine Learning, pages 80961–80990. PMLR, 2025
2025
-
[19]
JAMA Challenge
American Medical Association. JAMA Challenge. https://jamanetwork.com/, 2024. Accessed: Jan. 1, 2024
2024
-
[20]
Negin Baghbanzadeh, Mohammed Saidul Islam, Sajad Ashkezari, Elham Dolatabadi, and Arash Afkanpour. Open-pmc-18m: A high-fidelity large scale medical dataset for multimodal representation learning.arXiv preprint arXiv:2506.02738, 2025
arXiv 2025
-
[21]
Juntao Jiang, Jiangning Zhang, Yali Bi, Jinsheng Bai, Weixuan Liu, Weiwei Jin, Zhucun Xue, Yong Liu, Xiaobin Hu, and Shuicheng Yan. M3cotbench: Benchmark chain-of-thought of mllms in medical image understanding.arXiv preprint arXiv:2601.08758, 2026
arXiv 2026
-
[22]
Med-r1: Reinforcement learning for generalizable medical reasoning in vision-language models.IEEE Transactions on Medical Imaging, 2026
Yuxiang Lai, Jike Zhong, Ming Li, Shitian Zhao, Yuheng Li, Konstantinos Psounis, and Xiaofeng Yang. Med-r1: Reinforcement learning for generalizable medical reasoning in vision-language models.IEEE Transactions on Medical Imaging, 2026
2026
-
[23]
Maddison, and Bo Wang
Adibvafa Fallahpour, Andrew Magnuson, Purav Gupta, Shihao Ma, Jack Naimer, Arnav Shah, Haonan Duan, Omar Ibrahim, Hani Goodarzi, Chris J. Maddison, and Bo Wang. Bioreason: Incentivizing multimodal biological reasoning within a dna-llm model, 2025
2025
-
[24]
Stiles, Filip Nem ˇcko, Alexander A
Adibvafa Fallahpour, Arman Seyed-Ahmadi, Parsa Idehpour, Omar Ibrahim, Purav Gupta, Jack Naimer, Kevin Zhu, Arnav Shah, Shihao Ma, Abhinav Adduri, Talu Güloglu, Nuo Liu, Haotian Cui, Arihant Jain, Max de Castro, Amirfaham Fallahpour, Antonio Cembellin-Prieto, John S. Stiles, Filip Nem ˇcko, Alexander A. Nevue, Hyungseok C. Moon, Lucas Sosnick, Olivia Mark...
2026
-
[25]
Towards injecting medical visual knowledge into multimodal llms at scale
Junying Chen, Chi Gui, Ruyi Ouyang, Anningzhe Gao, Shunian Chen, Guiming Hardy Chen, Xidong Wang, Zhenyang Cai, Ke Ji, Xiang Wan, et al. Towards injecting medical visual knowledge into multimodal llms at scale. InProceedings of the 2024 conference on empirical methods in natural language processing, pages 7346–7370, 2024
2024
-
[26]
Climb: Data foundations for large scale multimodal clinical foundation models
Wei Dai, Peilin Chen, Malinda Lu, Daniel A Li, Haowen Wei, Hejie Cui, and Paul Pu Liang. Climb: Data foundations for large scale multimodal clinical foundation models. InInternational Conference on Machine Learning, pages 11904–11953. PMLR, 2025
2025
-
[27]
Medtrinity-25m: A large-scale multimodal dataset with multigranular annotations for medicine
Yunfei Xie, Ce Zhou, Lang Gao, Juncheng Wu, Xianhang Li, Hong-Yu Zhou, Sheng Liu, Lei Xing, James Zou, Cihang Xie, et al. Medtrinity-25m: A large-scale multimodal dataset with multigranular annotations for medicine. InThe Thirteenth International Conference on Learning Representations
-
[28]
Gmai-mmbench: A comprehensive multimodal evaluation benchmark towards general medical ai.Advances in Neural Information Processing Systems, 37:94327–94427, 2024
Pengcheng Chen, Jin Ye, Guoan Wang, Yanjun Li, Zhongying Deng, Wei Li, Tianbin Li, Haodong Duan, Ziyan Huang, Yanzhou Su, et al. Gmai-mmbench: A comprehensive multimodal evaluation benchmark towards general medical ai.Advances in Neural Information Processing Systems, 37:94327–94427, 2024
2024
-
[29]
Medprobclip: Probabilistic adaptation of vision-language foundation model for reliable radiograph-report retrieval
Ahmad Elallaf, Yu Zhang, Yuktha Masupalli, Jeong Yang, Young Lee, Zechun Cao, and Gongbo Liang. Medprobclip: Probabilistic adaptation of vision-language foundation model for reliable radiograph-report retrieval. InProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, pages 1–10, 2026
2026
-
[30]
Cares: A comprehensive benchmark of trustworthiness in medical vision language models.Advances in Neural Information Processing Systems, 37:140334–140365, 2024
Peng Xia, Ze Chen, Juanxi Tian, Yangrui Gong, Ruibo Hou, Yue Xu, Zhenbang Wu, Zhiyuan Fan, Yiyang Zhou, Kangyu Zhu, et al. Cares: A comprehensive benchmark of trustworthiness in medical vision language models.Advances in Neural Information Processing Systems, 37:140334–140365, 2024
2024
-
[31]
Overview
United States Medical Licensing Examination. Overview. https://www.usmle.org/ bulletin-information/overview, 2024. Accessed: Jan. 1, 2024
2024
-
[32]
Meidan Ding, Jipeng Zhang, Wenxuan Wang, Haiqin Zhong, Xiaoling Luo, Wenting Chen, and Linlin Shen. Mmedexpert-r1: Strengthening multimodal medical reasoning via domain-specific adaptation and clinical guideline reinforcement.arXiv preprint arXiv:2601.10949, 2026. 11
arXiv 2026
-
[33]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300, 2024
Pith/arXiv arXiv 2024
-
[34]
VinDr-CXR: An open dataset of chest X-rays with radiologist annotations.PhysioNet, June 2021
Ha Quy Nguyen, Hieu Huy Pham, le tuan linh, Minh Dao, and lam khanh. VinDr-CXR: An open dataset of chest X-rays with radiologist annotations.PhysioNet, June 2021. Version 1.0.0
2021
-
[35]
The ham10000 dataset, a large collection of multi-source dermatoscopic images of common pigmented skin lesions.Scientific Data, 5:180161, 2018
Philipp Tschandl, Cliff Rosendahl, and Harald Kittler. The ham10000 dataset, a large collection of multi-source dermatoscopic images of common pigmented skin lesions.Scientific Data, 5:180161, 2018
2018
-
[36]
VinDr-Mammo: A large-scale benchmark dataset for computer-aided detection and diagnosis in full-field digital mammography.PhysioNet, March
Hieu Huy Pham, Hieu Nguyen Trung, and Ha Quy Nguyen. VinDr-Mammo: A large-scale benchmark dataset for computer-aided detection and diagnosis in full-field digital mammography.PhysioNet, March
-
[37]
Brain tumor classification (mri).https://www.kaggle.com/dsv/1183165, 2020
Sartaj Bhuvaji, Ankita Kadam, Prajakta Bhumkar, Sameer Dedge, and Swati Kanchan. Brain tumor classification (mri).https://www.kaggle.com/dsv/1183165, 2020. Dataset
arXiv 2020
-
[38]
Smedsrud, Steven A
Hanna Borgli, Vajira Thambawita, Pia H. Smedsrud, Steven A. Hicks, Debesh Jha, Sigrun L. Eskeland, Kristin R. Randel, Konstantin Pogorelov, Mathias Lux, Duc T. D. Nguyen, Dag Johansen, Carsten Griwodz, Håkon K. Stensland, Enrique Garcia-Ceja, Peter T. Schmidt, Hugo L. Hammer, Michael A. Riegler, Pål Halvorsen, and Thomas de Lange. Hyperkvasir, a comprehen...
2020
-
[39]
Diabetic retinopathy detection
Kaggle and EyePACS. Diabetic retinopathy detection. Kaggle Competition, 2015. Dataset
2015
-
[40]
Aptos 2019 blindness detection
Asia Pacific Tele-Ophthalmology Society. Aptos 2019 blindness detection. Kaggle Competition, 2019. Dataset
2019
-
[41]
Dataset of breast ultrasound images.Data in Brief, 28:104863, 2020
Walid Al-Dhabyani, Mohammed Gomaa, Hussien Khaled, and Aly Fahmy. Dataset of breast ultrasound images.Data in Brief, 28:104863, 2020. 12 A Data Curation Details A.1 Multi-Level Quality Filtering A.1.1 Visual Quality The visual-usability filter described in Section 3.1 applies four pixel-level checks; an image is rejected if it fails any of them. Represent...
2020
-
[42]
The text has acceptable English quality
-
[43]
The content is human/clinical and relevant to patient-level medical interpretation
-
[44]
The content is not primarily non-human, veterinary, animal-model, bench-only, or non- medical
-
[45]
The text is informative enough for downstream medical-image QA
-
[46]
If an image is provided, it is usable for visual medical QA
-
[47]
decision
The text contains reasoning signals that support a complex image-grounded QA pair. Reasoning signals include: •Causal:explains the cause or effect of a visual feature. •Comparative:contrasts the sub-figure with another condition, baseline, or group. • Methodological/Functional:explains how a mechanism works or why a visual pattern appears. FAILif the text...
-
[48]
Perception.The trace first states the image-grounded observations needed to answer the question. This includes only clinically relevant visual evidence, such as the modality, 27 anatomical region, visible abnormality, spatial pattern, morphology, signal, density, uptake, or microscopic appearance, depending on the image type
-
[49]
Clinical interpretation and medical knowledge.The trace then explains how the per- ceptual evidence should be interpreted clinically or biomedically. This step uses relevant medical knowledge, together with the source context, to connect the observed findings to the diagnosis, mechanism, management decision, anatomical interpretation, risk assessment, or ...
-
[50]
decision
Answer justification.The trace ends with a concise justification that explicitly links the key perceptual evidence, clinical interpretation, and relevant medical knowledge to the selected answer. This structure keeps the rationale focused on the path from image evidence, through clinically grounded medical knowledge, to the final answer, while avoiding un...
2048
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.