Rule Taxonomy and Evolution in AI IDEs: A Mining and Survey Study
Pith reviewed 2026-06-27 09:04 UTC · model grok-4.3
The pith
Updating rules in AI IDEs raises average artifact compliance from 49% to 72%.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
An assessment of 160 rule evolution events shows that updating rules improves adherence of software artifacts, raising the average compliance rate by 22.99 percentage points from 49.14% to 72.13%.
What carries the argument
The artifact compliance assessment that measures software artifact adherence before and after each of 160 rule evolution events.
If this is right
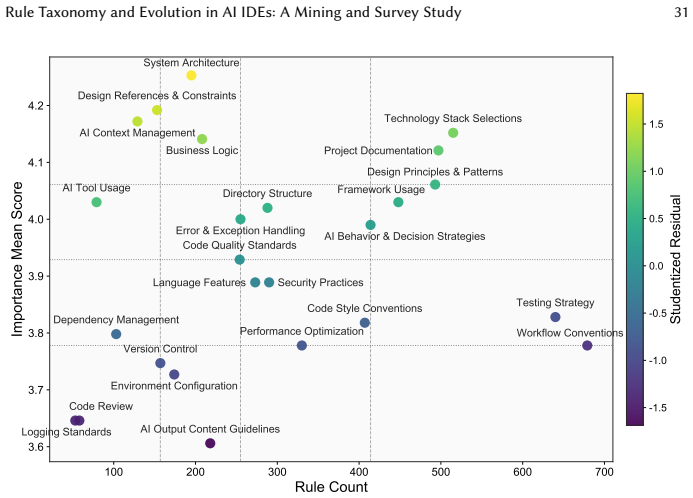
- Rule files in practice contain mostly low-level constraints even though developers rate architectural constraints as more important.
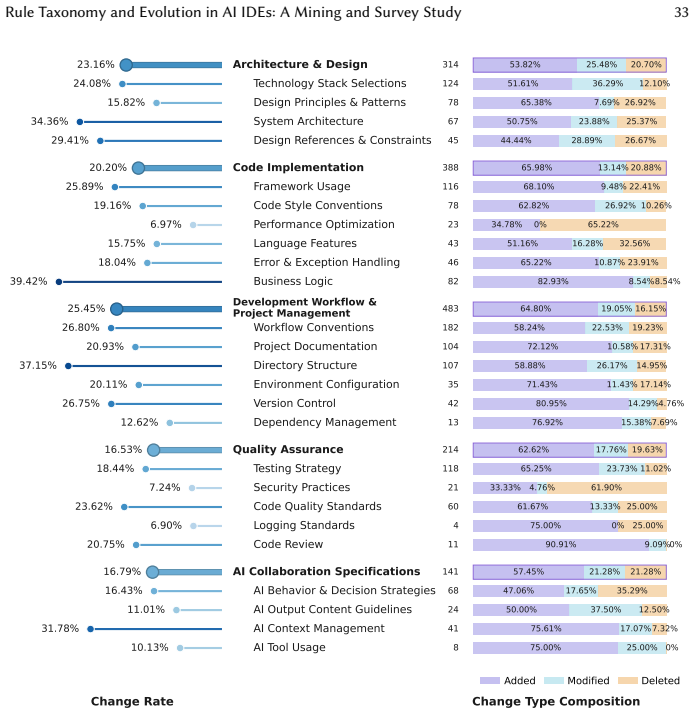
- Rule evolution occurs frequently and is driven by context expansions and enrichments according to repository data.
- Practitioners mainly add new negative constraints to correct AI errors rather than editing existing rules.
- The measured compliance gains suggest that maintaining and updating rules can serve as an effective prompting strategy.
Where Pith is reading between the lines
- Automated tools could monitor rule files for opportunities to trigger updates that would most improve compliance.
- Taxonomy categories might be used to detect conflicts between rules from different sources or team members.
- The gap between stated priorities and actual rule content points to a need for better default rule templates in AI IDEs.
Load-bearing premise
The manual or semi-automated classification of 7310 rules into the 5 primary and 25 secondary categories is accurate and consistent, and the 83 mined repositories plus 99 survey respondents are representative of typical AI IDE usage.
What would settle it
A replication that applies the same before-and-after compliance measurement to 160 new rule evolution events and finds no statistically significant rise in adherence rates.
Figures













read the original abstract
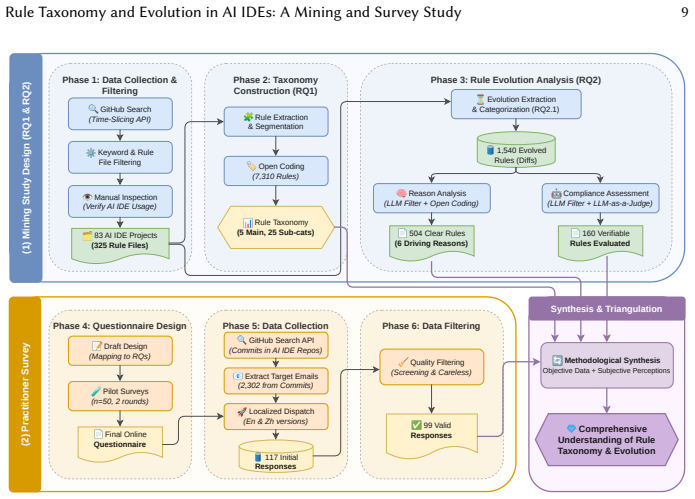
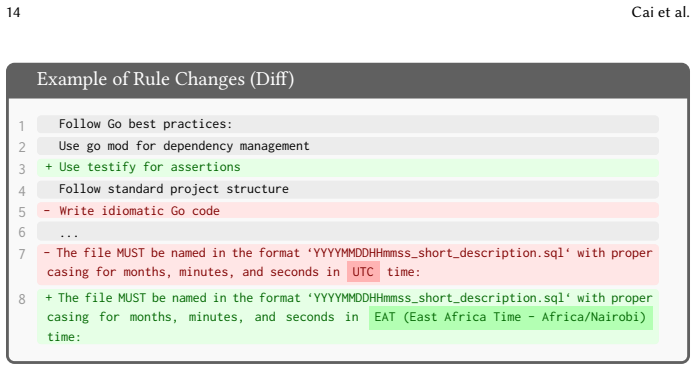
The adoption of AI-powered Integrated Development Environments (AI IDEs) has introduced "Rules" as a novel software artifact, allowing developers to persistently inject project-specific constraints and architectural guidelines into the context of Large Language Models (LLMs). Despite their role in aligning AI behavior with developer intent, the taxonomy, evolution, and practical impact of these rules remain largely unexplored. To bridge this gap, we conducted a mixed-methods empirical study on AI IDE rules. By mining 83 open-source projects and extracting 7,310 rules, we established a comprehensive taxonomy comprising 5 primary and 25 secondary categories. We then triangulated these artifacts with survey responses from 99 practitioners. Our analysis identified a contrast between developer priorities and actual configurations: while practitioners rate architectural constraints as highly important, rule files in repositories primarily consist of low-level workflow and code formatting constraints. Furthermore, our analysis of 1,540 rule evolution events revealed that rules are updated frequently. Repository data further indicate that rule evolution is primarily driven by constructive context expansions (29.17%) and enrichments (26.59%). In contrast, surveyed developers reported modifying rules primarily to correct AI errors (77.78%), typically by adding new negative constraints rather than editing existing ones. Finally, an artifact compliance assessment of 160 rule evolution events revealed that updating rules significantly improves the adherence of software artifacts, with the average artifact compliance rate increasing by 22.99% (from 49.14% to 72.13%) following an update. Our study provides empirical insights that can help developers optimize prompting strategies and guide tool builders in designing automated conflict-detection and context-management mechanisms for AI IDEs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper reports a mixed-methods empirical study of rules in AI IDEs. It mines 83 open-source repositories to extract 7,310 rules, derives a taxonomy of 5 primary and 25 secondary categories, triangulates with a survey of 99 practitioners, analyzes 1,540 rule-evolution events, and performs an artifact-compliance assessment on 160 events. Key findings include a mismatch between practitioner-rated importance of architectural constraints and the prevalence of low-level workflow rules, frequent rule updates driven by context expansion, and a 22.99% average increase in artifact compliance (49.14% to 72.13%) after rule updates.
Significance. If the compliance assessment is reproducible, the reported 22.99% improvement would supply concrete evidence that rule evolution measurably affects artifact adherence in AI IDEs, informing both developer prompting practices and tool design for conflict detection. The taxonomy and priority-configuration contrast also offer a baseline for future longitudinal studies of rule maintenance.
major comments (2)
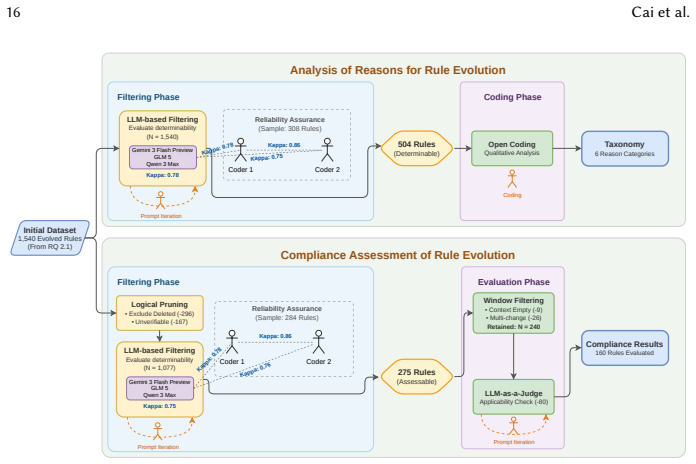
- [artifact compliance assessment] The artifact compliance assessment (abstract and § on compliance results): the selection protocol for the 160 events out of 1,540 evolution events is not described, nor is the operational definition of the compliance metric (e.g., fraction of rules satisfied by concrete code artifacts) or any inter-rater reliability statistics. Without these, the 22.99% delta cannot be attributed to rule updates rather than measurement artifact.
- [taxonomy and mining sections] Taxonomy construction and repository sampling (§ on mining and taxonomy): the paper supplies no inter-rater agreement figures for the manual or semi-automated classification of 7,310 rules into the 5+25 categories, nor explicit inclusion/exclusion criteria or sampling frame for the 83 projects. These omissions directly affect the reliability of the reported category distributions and the contrast with survey priorities.
minor comments (2)
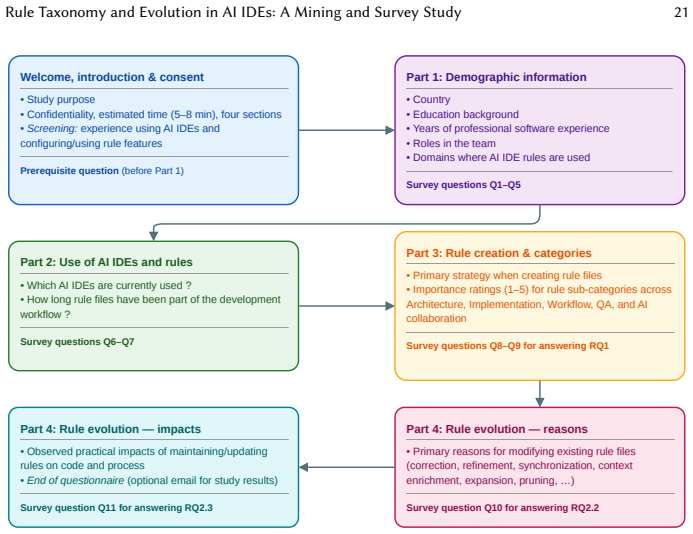
- [survey section] The survey response rate and any statistical tests for the 99 responses are not reported, which would help assess representativeness.
- [evolution events analysis] Clarify whether the 1,540 evolution events were exhaustively extracted or sampled, and provide the exact definition of 'constructive context expansions' versus 'enrichments'.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below and will incorporate the requested clarifications to enhance the manuscript's methodological transparency and reproducibility.
read point-by-point responses
-
Referee: [artifact compliance assessment] The artifact compliance assessment (abstract and § on compliance results): the selection protocol for the 160 events out of 1,540 evolution events is not described, nor is the operational definition of the compliance metric (e.g., fraction of rules satisfied by concrete code artifacts) or any inter-rater reliability statistics. Without these, the 22.99% delta cannot be attributed to rule updates rather than measurement artifact.
Authors: We agree that the selection protocol, operational definition of the compliance metric, and inter-rater reliability statistics were omitted from the original submission. In the revised manuscript we will describe the protocol used to select the 160 events from the 1,540 evolution events, provide the precise definition of the compliance metric as the fraction of rules satisfied by the concrete code artifacts, and report inter-rater reliability statistics for the compliance judgments. These additions will allow readers to evaluate the reliability of the reported 22.99% improvement. revision: yes
-
Referee: [taxonomy and mining sections] Taxonomy construction and repository sampling (§ on mining and taxonomy): the paper supplies no inter-rater agreement figures for the manual or semi-automated classification of 7,310 rules into the 5+25 categories, nor explicit inclusion/exclusion criteria or sampling frame for the 83 projects. These omissions directly affect the reliability of the reported category distributions and the contrast with survey priorities.
Authors: We concur that inter-rater agreement figures and explicit sampling details should have been reported. The revised manuscript will include inter-rater agreement statistics for the classification of the 7,310 rules into the taxonomy categories, together with the inclusion/exclusion criteria and sampling frame applied to select the 83 projects. These additions will strengthen the credibility of the category distributions and the observed contrast with practitioner priorities. revision: yes
Circularity Check
No circularity: purely observational empirical study
full rationale
The paper reports a mixed-methods study involving repository mining of 7310 rules from 83 projects, manual taxonomy construction into 5 primary/25 secondary categories, a survey of 99 practitioners, analysis of 1540 evolution events, and a compliance assessment on 160 events. No equations, fitted parameters, predictions, uniqueness theorems, or ansatzes appear. Claims rest on direct observation and triangulation rather than any reduction of outputs to inputs by definition or self-citation. The compliance delta is presented as a measured empirical outcome, not derived from prior fitted values or author self-references.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Shyam Agarwal, Hao He, and Bogdan Vasilescu. 2026. AI IDEs or Autonomous Agents? Measuring the Impact of Coding Agents on Software Development. InProceedings of the 23rd International Conference on Mining Software Repositories (MSR). ACM
2026
-
[2]
Sirwan Khalid Ahmed. 2024. How to choose a sampling technique and determine sample size for research: A simplified guide for researchers.Oral Oncology Reports12 (2024), 100662
2024
-
[3]
Alibaba. 2026. Qoder - Changelog. https://qoder.com/changelog Accessed: February 12, 2026
2026
-
[4]
Alibaba. 2026. Qoder - Rules. https://docs.qoder.com/user-guide/rules Accessed: February 12, 2026
2026
-
[5]
Alibaba. 2026. Qoder - The Agentic Coding Platform. https://qoder.com/ Accessed: February 12, 2026
2026
-
[6]
Amazon. 2026. Kiro - Changelog. https://kiro.dev/changelog Accessed: February 12, 2026
2026
-
[7]
Amazon. 2026. Kiro - Steering. https://kiro.dev/docs/steering/ Accessed: February 12, 2026
2026
-
[8]
Amazon. 2026. Kiro: Agentic AI Development from Prototype to Production. https://kiro.dev/ Accessed: February 12, 2026
2026
-
[9]
Anysphere. 2026. Cursor - Changelog. https://cursor.com/changelog Accessed: February 12, 2026
2026
-
[10]
Anysphere. 2026. Cursor - Rules. https://cursor.com/docs/context/rules/ Accessed: February 12, 2026
2026
-
[11]
Anysphere. 2026. Cursor - The AI Code Editor. https://www.cursor.com/
2026
-
[12]
Richard A Armstrong. 2014. When to use the B onferroni correction.Ophthalmic and Physiological Optics34, 5 (2014), 502–508
2014
-
[13]
2009.Software Architecture Knowledge Management
Muhammad Ali Babar, Torgeir Dingsøyr, Patricia Lago, and Hans Van Vliet. 2009.Software Architecture Knowledge Management. Springer
2009
-
[14]
Shraddha Barke, Michael B James, and Nadia Polikarpova. 2023. Grounded copilot: How programmers interact with code-generating models.Proceedings of the ACM on Programming Languages7, OOPSLA (2023), 85–111
2023
-
[15]
Joel Becker, Nate Rush, Elizabeth Barnes, and David Rein. 2025. Measuring the Impact of Early-2025 AI on Experienced Open-Source Developer Productivity.arXiv preprint arXiv:2507.09089(2025)
arXiv 2025
-
[16]
Alexander L Burton. 2021. OLS (Linear) regression.The Encyclopedia of Research Methods in Crimi- nology and Criminal Justice2 (2021), 509–514
2021
-
[17]
ByteDance. 2026. Trae - Changelog. https://www.trae.ai/changelog Accessed: February 12, 2026
2026
-
[18]
ByteDance. 2026. Trae - Collaborate with Intelligence. https://www.trae.ai/ Accessed: February 12, 2026. ACM Trans. Softw. Eng. Methodol., Vol. 1, No. 1, Article . Publication date: June 2026. 48 Cai et al
2026
-
[19]
ByteDance. 2026. Trae - Rules. https://docs.trae.ai/ide/rules?_lang=en Accessed: February 12, 2026
2026
-
[20]
Birgitta Böckeler. 2026. Harness engineering for coding agent users. https://martinfowler.com/ articles/harness-engineering.html Accessed: May 1, 2026
2026
-
[21]
Rule Taxonomy and Evolution in AI IDEs: A Mining and Survey Study
Guangzong Cai, Ruiyin Li, Peng Liang, Zengyang Li, and Mojtaba Shahin. 2026. Replication package for the paper “Rule Taxonomy and Evolution in AI IDEs: A Mining and Survey Study”. https: //github.com/breezesway/Rules_in_AI_IDEs
2026
-
[22]
John L Campbell, Charles Quincy, Jordan Osserman, and Ove K Pedersen. 2013. Coding in-depth semistructured interviews: Problems of unitization and intercoder reliability and agreement.Socio- logical Methods & Research42, 3 (2013), 294–320
2013
-
[23]
Worawalan Chatlatanagulchai, Hao Li, Yutaro Kashiwa, Brittany Reid, et al. 2025. Agent READMEs: An Empirical Study of Context Files for Agentic Coding.arXiv preprint arXiv:2511.12884(2025)
arXiv 2025
-
[24]
Worawalan Chatlatanagulchai, Kundjanasith Thonglek, Brittany Reid, Yutaro Kashiwa, Pattara Leelaprute, Arnon Rungsawang, Bundit Manaskasemsak, and Hajimu Iida. 2025. On the Use of Agentic Coding Manifests: An Empirical Study of Claude Code. InProceedings of the 26th International Conference on Product-Focused Software Process Improvement (PROFES). Springe...
2025
-
[25]
Qiu, Arran Zeyu Wang, Zilong Wang, and Yuqing Yang
Nan Chen, Luna K. Qiu, Arran Zeyu Wang, Zilong Wang, and Yuqing Yang. 2025. Screen Reader Users in the Vibe Coding Era: Adaptation, Empowerment, and New Accessibility Landscape.arXiv preprint arXiv:2506.13270(2025)
arXiv 2025
-
[26]
Xiongzhi Chen and Sanat K Sarkar. 2020. On Benjamini–Hochberg procedure applied to mid p-values. Journal of Statistical Planning and Inference205 (2020), 34–45
2020
-
[27]
Yi-Hung Chou, Boyuan Jiang, Yi Wen Chen, Mingyue Weng, Victoria Jackson, Thomas Zimmermann, and James Jones. 2026. Building Software by Rolling the Dice: A Qualitative Study of Vibe Coding. In Proceedings of the 22nd ACM SIGSOFT International Symposium on Foundations of Software Engineering (FSE). ACM
2026
-
[28]
Codeium. 2026. Windsurf - Changelog. https://windsurf.com/changelog Accessed: February 12, 2026
2026
-
[29]
Codeium. 2026. Windsurf - Rules. https://docs.windsurf.com/windsurf/cascade/memories/ Accessed: February 12, 2026
2026
-
[30]
Codeium. 2026. Windsurf - The best AI for Coding. https://windsurf.com/ Accessed: February 12, 2026
2026
-
[31]
J. Cohen. 1960. A coefficient of agreement for nominal scales.Educational and Psychological Measure- ment20, 1 (1960), 37–46
1960
-
[32]
Giuseppe Colavito, Filippo Lanubile, and Nicole Novielli. 2025. Benchmarking large language models for automated labeling: The case of issue report classification.Information and Software Technology 184 (2025), 107758
2025
-
[33]
Giuseppe Colavito, Filippo Lanubile, Nicole Novielli, and Luigi Quaranta. 2024. Leveraging gpt-like llms to automate issue labeling. InProceedings of the 21st International Conference on Mining Software Repositories (MSR). ACM, 469–480
2024
-
[34]
Ozren Dabic, Emad Aghajani, and Gabriele Bavota. 2021. Sampling projects in GitHub for MSR studies. InProceedings of the 18th International Conference on Mining Software Repositories (MSR). IEEE, 560–564
2021
-
[35]
Vincenzo De Martino, Joel Castaño, Fabio Palomba, Xavier Franch, and Silverio Martínez-Fernández
-
[36]
InProceedings of the 2nd IEEE/ACM International Workshop on Methodological Issues with Empirical Studies in Software Engineering (WSESE)
A Framework for Using LLMs for Repository Mining Studies in Empirical Software Engineering. InProceedings of the 2nd IEEE/ACM International Workshop on Methodological Issues with Empirical Studies in Software Engineering (WSESE). IEEE, 6–11
-
[37]
Antonio Della Porta, Stefano Lambiase, and Fabio Palomba. 2024. Do Prompt Patterns Affect Code Quality? A First Empirical Assessment of ChatGPT-Generated Code. InProceedings of the 28th International Conference on Evaluation and Assessment in Software Engineering (EASE). ACM, 181– 191
2024
-
[38]
Rosa Falotico and Piero Quatto. 2015. Fleiss’ kappa statistic without paradoxes.Quality & Quantity 49, 2 (2015), 463–470. ACM Trans. Softw. Eng. Methodol., Vol. 1, No. 1, Article . Publication date: June 2026. Rule Taxonomy and Evolution in AI IDEs: A Mining and Survey Study 49
2015
-
[39]
Jennifer Fereday and Eimear Muir-Cochrane. 2006. Demonstrating rigor using thematic analysis: A hybrid approach of inductive and deductive coding and theme development.International Journal of Qualitative Methods5, 1 (2006), 80–92
2006
-
[40]
Ehsan Firouzi and Mohammad Ghafari. 2026. Persistent Human Feedback, LLMs, and Static Analyzers for Secure Code Generation and Vulnerability Detection.arXiv preprint arXiv:2602.05868(2026)
arXiv 2026
-
[41]
Matthias Galster, Seyedmoein Mohsenimofidi, Jai Lal Lulla, Muhammad Auwal Abubakar, Christoph Treude, and Sebastian Baltes. 2026. Configuring Agentic AI Coding Tools: An Exploratory Study. arXiv preprint arXiv:2602.14690(2026)
Pith/arXiv arXiv 2026
-
[42]
Yuyao Ge, Lingrui Mei, Zenghao Duan, Tianhao Li, Yujia Zheng, Yiwei Wang, Lexin Wang, Jiayu Yao, Tianyu Liu, Yujun Cai, Baolong Bi, Fangda Guo, Jiafeng Guo, Shenghua Liu, and Xueqi Cheng. 2025. A Survey of Vibe Coding with Large Language Models.arXiv preprint arXiv:2510.12399(2025)
arXiv 2025
-
[43]
GitHub. 2026. GitHub Copilot - AI coding built your way. https://github.com/features/copilot/ai- code-editor Accessed: February 12, 2026
2026
-
[44]
Thibaud Gloaguen, Niels Mündler, Mark Müller, Veselin Raychev, and Martin Vechev. 2026. Evalu- ating AGENTS.md: Are Repository-Level Context Files Helpful for Coding Agents?arXiv preprint arXiv:2602.11988(2026)
Pith/arXiv arXiv 2026
-
[45]
Guild.ai. 2026. AI IDE (Artificial Intelligence Integrated Development Environment). https://www. guild.ai/glossary/ai-ide Accessed: March 8, 2026
2026
-
[46]
Hao He, Courtney Miller, Shyam Agarwal, Christian Kästner, and Bogdan Vasilescu. 2026. Speed at the Cost of Quality: How Cursor AI Increases Short-Term Velocity and Long-Term Complexity in Open-Source Projects. InProceedings of the 23rd International Conference on Mining Software Repositories (MSR). ACM
2026
-
[47]
Junda He, Jieke Shi, Terry Yue Zhuo, Christoph Treude, Jiamou Sun, Zhenchang Xing, Xiaoning Du, and David Lo. 2026. LLM-as-a-judge for software engineering: Literature review, vision, and the road ahead.ACM Transactions on Software Engineering and Methodology(2026)
2026
-
[48]
Andre Hora and Romain Robbes. 2026. Are Coding Agents Generating Over-Mocked Tests? An Empirical Study.arXiv preprint arXiv:2602.00409(2026)
arXiv 2026
-
[49]
Kosei Horikawa, Hao Li, Yutaro Kashiwa, Bram Adams, Hajimu Iida, and Ahmed E. Hassan. 2025. Agentic Refactoring: An Empirical Study of AI Coding Agents.arXiv preprint arXiv:2511.04824(2025)
arXiv 2025
-
[50]
Ruanqianqian Huang, Avery Reyna, Sorin Lerner, Haijun Xia, and Brian Hempel. 2025. Professional Software Developers Don’t Vibe, They Control: AI Agent Use for Coding in 2025.arXiv preprint arXiv:2512.14012(2025)
arXiv 2025
-
[51]
Shaokang Jiang and Daye Nam. 2026. Beyond the Prompt: An Empirical Study of Cursor Rules. In Proceedings of the 23rd International Conference on Mining Software Repositories (MSR). ACM
2026
-
[52]
Syed Mohammad Kashif, Ruiyin Li, Peng Liang, Amjed Tahir, Qiong Feng, Zengyang Li, and Mojtaba Shahin. 2026. Beyond Functional Correctness: Design Issues in AI IDE-Generated Large-Scale Projects. arXiv preprint arXiv:2604.06373(2026)
Pith/arXiv arXiv 2026
-
[53]
Ranim Khojah, Francisco Gomes de Oliveira Neto, Mazen Mohamad, and Philipp Leitner. 2025. The Impact of Prompt Programming on Function-Level Code Generation.IEEE Transactions on Software Engineering51, 8 (2025), 2381–2395
2025
-
[54]
Hae-Young Kim. 2017. Statistical notes for clinical researchers: Chi-squared test and Fisher’s exact test.Restorative Dentistry & Endodontics42, 2 (2017), 152
2017
-
[55]
Aayush Kumar, Yasharth Bajpai, Sumit Gulwani, Gustavo Soares, and Emerson Murphy-Hill. 2025. Why AI Agents Still Need You: Findings from Developer-Agent Collaborations in the Wild. In Proceedings of the 40th IEEE/ACM International Conference on Automated Software Engineering (ASE). IEEE, 432–444
2025
-
[56]
Kadakatla Pavan Kumar and Visweswararao Reddi. 2023. Significance of Spearman’s rank correlation coefficient.International Journal For Multidisciplinary Research5, 4 (2023), 1–4
2023
-
[57]
Hao Li, Haoxiang Zhang, and Ahmed E. Hassan. 2025. The Rise of AI Teammates in Software Engineering (SE) 3.0: How Autonomous Coding Agents Are Reshaping Software Engineering.arXiv preprint arXiv:2507.15003(2025). ACM Trans. Softw. Eng. Methodol., Vol. 1, No. 1, Article . Publication date: June 2026. 50 Cai et al
Pith/arXiv arXiv 2025
-
[58]
Jie Li, Youyang Hou, Laura Lin, Ruihao Zhu, Hancheng Cao, and Abdallah El Ali. 2026. Vibe Coding in Product Teams: Reconfiguring AI-Assisted Workflows, Prototyping, and Collaboration.arXiv preprint arXiv:2509.10652(2026)
Pith/arXiv arXiv 2026
-
[59]
Zongwei Li, Zhonghang Li, Zirui Guo, Xubin Ren, and Chao Huang. 2025. DeepCode: Open Agentic Coding.arXiv preprint arXiv:2512.07921(2025)
arXiv 2025
-
[60]
Nelson F Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang. 2024. Lost in the middle: How language models use long contexts.Transactions of the Association for Computational Linguistics12 (2024), 157–173
2024
-
[61]
Xinpeng Liu, Junming Liu, Peiyu Liu, Han Zheng, Qinying Wang, Mathias Payer, Shouling Ji, and Wenhai Wang. 2025. Cuckoo Attack: Stealthy and Persistent Attacks Against AI-IDE.arXiv preprint arXiv:2509.15572(2025)
arXiv 2025
-
[62]
Yue Liu, Yanjie Zhao, Yunbo Lyu, Ting Zhang, Haoyu Wang, and David Lo. 2026. “Your AI, My Shell”: Demystifying Prompt Injection Attacks on Agentic AI Coding Editors.arXiv preprint arXiv:2509.22040 (2026)
Pith/arXiv arXiv 2026
-
[63]
Zhang, Sebastian Baltes, and Christoph Treude
Jai Lal Lulla, Seyedmoein Mohsenimofidi, Matthias Galster, Jie M. Zhang, Sebastian Baltes, and Christoph Treude. 2026. On the Impact of AGENTS.md Files on the Efficiency of AI Coding Agents. arXiv preprint arXiv:2601.20404(2026)
arXiv 2026
-
[64]
Weidi Luo, Qiming Zhang, Tianyu Lu, Xiaogeng Liu, et al . 2025. Code Agent Can Be an End-to- End System Hacker: Benchmarking Real-World Threats of Computer-Use Agent.arXiv preprint arXiv:2510.06607(2025)
arXiv 2025
-
[65]
Damon McMillan. 2026. Instruction Adherence in Coding Agent Configuration Files.arXiv preprint arXiv:2605.10039(2026)
Pith/arXiv arXiv 2026
-
[66]
Damon McMillan. 2026. Structured Context Engineering for File-Native Agentic Systems: Evalu- ating Schema Accuracy, Format Effectiveness, and Multi-File Navigation at Scale.arXiv preprint arXiv:2602.05447(2026)
arXiv 2026
-
[67]
Seyedmoein Mohsenimofidi, Matthias Galster, Christoph Treude, and Sebastian Baltes. 2026. Context Engineering for AI Agents in Open-Source Software. InProceedings of the 23rd International Conference on Mining Software Repositories (MSR). ACM
2026
-
[68]
Daye Nam, Andrew Macvean, Vincent Hellendoorn, Bogdan Vasilescu, and Brad Myers. 2024. Using an LLM to Help with Code Understanding. InProceedings of the 46th IEEE/ACM International Conference on Software Engineering (ICSE). ACM, 1–13
2024
-
[69]
Ben Nassi, Bruce Schneier, and Oleg Brodt. 2026. The Promptware Kill Chain: How Prompt Injections Gradually Evolved Into a Multi-Step Malware.arXiv preprint arXiv:2601.09625(2026)
arXiv 2026
-
[70]
Yuzhou Nie, Zhun Wang, Yu Yang, Ruizhe Jiang, Yuheng Tang, Xander Davies, Yarin Gal, Bo Li, Wenbo Guo, and Dawn Song. 2025. SECODEPLT: A Unified Benchmark for Evaluating the Security Risks and Capabilities of Code GenAI. InProceedings of the 39th Annual Conference on Neural Information Processing Systems (NeurIPS). OpenReview.net, 1–43
2025
-
[71]
Junichiro Niimi. 2026. Distortion Instead of Hallucination: The Effect of Reasoning Under Strict Constraints.arXiv preprint arXiv:2601.01490(2026)
arXiv 2026
-
[72]
Selcan Yukcu, Mehmet Cevheri Bozoglan, and Mehmet S
Amirkia Rafiei Oskooei, S. Selcan Yukcu, Mehmet Cevheri Bozoglan, and Mehmet S. Aktas. 2026. Natural Language Summarization Enables Multi-Repository Bug Localization by LLMs in Microservice Architectures. InProceedings of the 3rd International Workshop on Large Language Models for Code (LLM4Code). ACM, 1–9
2026
-
[73]
Elise Paradis, Kate Grey, Quinn Madison, Daye Nam, Andrew Macvean, Vahid Meimand, Nan Zhang, Ben Ferrari-Church, and Satish Chandra. 2025. How Much Does AI Impact Development Speed? An Enterprise-Based Randomized Controlled Trial. InProceedings of the 47th IEEE/ACM International Conference on Software Engineering: Software Engineering in Practice (ICSE-SE...
2025
-
[74]
Hammond Pearce, Baleegh Ahmad, Benjamin Tan, Brendan Dolan-Gavitt, and Ramesh Karri. 2022. Asleep at the Keyboard? Assessing the Security of GitHub Copilot’s Code Contributions. InProceedings of the 43rd IEEE Symposium on Security and Privacy (SP). IEEE, 754–768
2022
-
[75]
Sida Peng, Eirini Kalliamvakou, Peter Cihon, and Mert Demirer. 2023. The Impact of AI on Developer Productivity: Evidence from GitHub Copilot.arXiv preprint arXiv:2302.06590(2023). ACM Trans. Softw. Eng. Methodol., Vol. 1, No. 1, Article . Publication date: June 2026. Rule Taxonomy and Evolution in AI IDEs: A Mining and Survey Study 51
Pith/arXiv arXiv 2023
-
[76]
Zhiyuan Peng, Xin Yin, Pu Zhao, Fangkai Yang, et al. 2026. RepoGenesis: Benchmarking End-to-End Microservice Generation from README to Repository.arXiv preprint arXiv:2601.13943(2026)
Pith/arXiv arXiv 2026
-
[77]
Ethan Perez, Saffron Huang, Francis Song, Trevor Cai, Roman Ring, John Aslanides, Amelia Glaese, Nat McAleese, and Geoffrey Irving. 2022. Red teaming language models with language models. In Proceedings of the 27th Conference on Empirical Methods in Natural Language Processing (EMNLP). ACL, 3419–3448
2022
-
[78]
Veronica Pimenova, Sarah Fakhoury, Christian Bird, Margaret-Anne Storey, and Madeline Endres
-
[79]
Good Vibrations? A Qualitative Study of Co-Creation, Communication, Flow, and Trust in Vibe Coding.arXiv preprint arXiv:2509.12491(2025)
arXiv 2025
-
[80]
Roshani K Prematunga. 2012. Correlational Analysis.Australian Critical Care25, 3 (2012), 195–199
2012
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.