Detect, Remask, Repair: Diffusion Editing for Faithful Summarization of Evolving Contexts
Pith reviewed 2026-06-27 07:05 UTC · model grok-4.3
The pith
Diffusion editing repairs only outdated spans in evolving summaries while preserving supported content.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
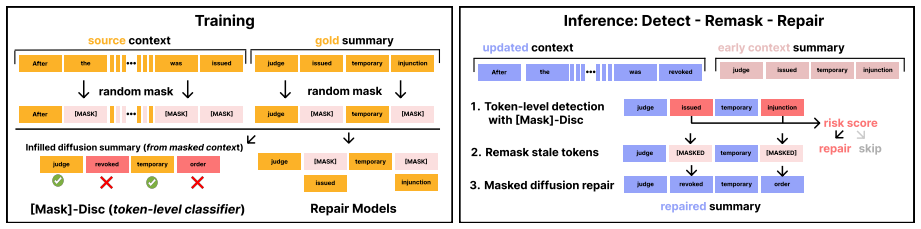
The Detect-Remask-Repair framework identifies unsupported or outdated spans in an existing summary, remasks those regions, and repairs them with masked diffusion language models, supplying a controllable alternative to full rewriting that improves faithfulness while preserving supported content and enabling fast one-step repairs.
What carries the argument
Detect-Remask-Repair: a three-stage process that uses masked diffusion language models to locate, remask, and regenerate only the outdated spans in a summary.
If this is right
- Faithfulness-steered repair improves the quality of early summary drafts.
- One-step repair reduces repair cost to under half a second.
- The framework enables explicit tradeoffs among faithfulness, speed, and content preservation across datasets.
- The same process supplies a post-hoc correction step that raises faithfulness scores for autoregressive summarizers.
Where Pith is reading between the lines
- The same localized detection-and-repair pattern could extend to other incremental text generation settings such as live reports or dialogue responses.
- Testing the approach on actual news timelines instead of the synthetic StreamSum benchmark would clarify how well detection generalizes beyond controlled event sequences.
- Because the method separates detection from repair, it could support interactive tools where users flag specific spans for update.
Load-bearing premise
The diffusion model can accurately detect and repair only the unsupported or outdated spans without introducing new errors or altering supported content.
What would settle it
An evaluation on StreamSum or DialogSum that measures whether repaired summaries contain new factual errors absent from the context or original draft, or fail to update all outdated claims.
Figures



read the original abstract
Summaries of real-world events can become outdated as contexts evolve and new information arrives. A common response is to generate a new summary from the updated context, but full regeneration discards the previous draft, can obscure what changed, and may be unnecessary when only a few claims are unsupported. We study localized faithfulness repair: updating outdated spans in an existing summary while preserving supported content. We propose DETECT-REMASK-REPAIR, a diffusion-based framework that identifies, remasks, and repairs outdated regions with masked diffusion language models. To evaluate evolving-context summarization, we introduce StreamSum, a benchmark of synthetic event timelines. Experiments on DialogSum and StreamSum show that localized diffusion repair provides a controllable alternative to full rewriting: faithfulness-steered repair improves early drafts, one-step repair reduces repair cost to under half a second, with the framework enabling faithfulness-speed-preservation tradeoffs across datasets. We also find that the framework can provide a post-hoc correction step that improves faithfulness for autoregressive systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that a diffusion-based DETECT-REMASK-REPAIR framework using masked diffusion language models can perform localized faithfulness repair on evolving-context summaries by detecting, remasking, and repairing only unsupported/outdated spans while preserving supported content. It introduces the synthetic StreamSum benchmark of event timelines and reports that the approach yields faithfulness improvements over early drafts, enables one-step repair under half a second, supports faithfulness-speed-preservation tradeoffs on DialogSum and StreamSum, and serves as an effective post-hoc correction step for autoregressive summarizers.
Significance. If the empirical claims hold, the work offers a practical, controllable alternative to full regeneration for maintaining summary faithfulness under context evolution, with explicit speed and edit-locality benefits that could reduce unnecessary rewriting in dynamic domains such as news or dialogue. The post-hoc correction result and the explicit tradeoff knobs are potentially useful contributions.
major comments (1)
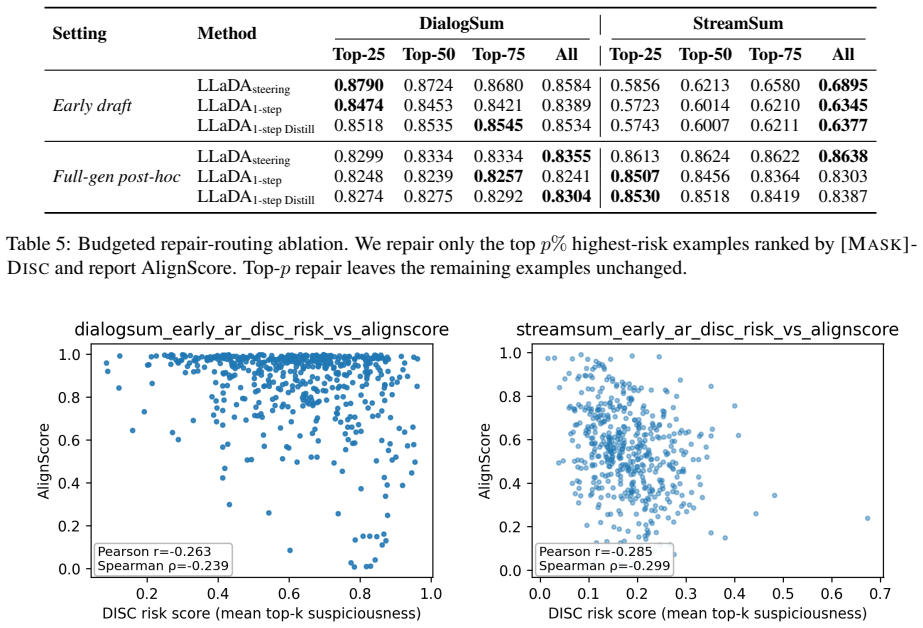
- [StreamSum benchmark construction] StreamSum benchmark construction (the section introducing the synthetic event timelines): the benchmark relies on explicit outdated claims inserted into timelines, which simplifies span detection relative to the implicit contradictions, gradual fact shifts, or subtle unsupported content that arise in natural evolving contexts. Because the central claim is that the diffusion model accurately detects and repairs only unsupported spans without introducing new errors or harming supported content, this construction choice is load-bearing; performance on StreamSum may not generalize, weakening the assertion that the framework provides a reliable controllable alternative to full rewriting.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the single major comment below.
read point-by-point responses
-
Referee: [StreamSum benchmark construction] StreamSum benchmark construction (the section introducing the synthetic event timelines): the benchmark relies on explicit outdated claims inserted into timelines, which simplifies span detection relative to the implicit contradictions, gradual fact shifts, or subtle unsupported content that arise in natural evolving contexts. Because the central claim is that the diffusion model accurately detects and repairs only unsupported spans without introducing new errors or harming supported content, this construction choice is load-bearing; performance on StreamSum may not generalize, weakening the assertion that the framework provides a reliable controllable alternative to full rewriting.
Authors: We agree that StreamSum relies on explicit insertion of outdated claims, which provides a controlled setting for measuring precise span detection and localized repair. This design enables ground-truth evaluation of whether the model identifies only unsupported regions and avoids introducing errors into supported content, which is essential for validating the DETECT-REMASK-REPAIR mechanism before moving to noisier data. We acknowledge that this choice does not capture all forms of natural evolution such as implicit contradictions or gradual shifts. In revision we will expand the benchmark section to explicitly discuss this limitation, clarify the rationale for the synthetic construction, and outline plans for future naturalistic extensions. revision: partial
Circularity Check
No significant circularity; empirical claims only
full rationale
The paper introduces a diffusion-based editing framework and a synthetic benchmark (StreamSum) for evaluating localized repair of outdated summary spans. All central claims are empirical performance statements (e.g., faithfulness improvements, runtime reductions, post-hoc correction benefits) measured on DialogSum and StreamSum. No equations, derivations, fitted parameters renamed as predictions, or self-citation chains appear in the abstract or described method. The evaluation is externally falsifiable through standard metrics on held-out data, making the work self-contained against external benchmarks with no load-bearing reductions to its own inputs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Javed Aslam, Fernando Diaz, Matthew Ekstrand-Abueg, Virgiliu Pavlu, and Tetsuya Sakai. 2013. Overview of the trec 2013 temporal summarization track. In Proceedings of the Twenty-Second Text REtrieval Conference (TREC 2013). NIST
2013
-
[3]
Fabbri, Wojciech Kryściński, Bryan McCann, Caiming Xiong, Richard Socher, and Dragomir Radev
Alexander R. Fabbri, Wojciech Kryściński, Bryan McCann, Caiming Xiong, Richard Socher, and Dragomir Radev. 2021. https://arxiv.org/abs/2007.12626 Summeval: Re-evaluating summarization evaluation . Preprint, arXiv:2007.12626
arXiv 2021
-
[4]
Fabbri, Chien-Sheng Wu, Wenhao Liu, and Caiming Xiong
Alexander R. Fabbri, Chien-Sheng Wu, Wenhao Liu, and Caiming Xiong. 2022. https://arxiv.org/abs/2112.08542 Qafacteval: Improved qa-based factual consistency evaluation for summarization . Preprint, arXiv:2112.08542
arXiv 2022
-
[5]
Tanya Goyal and Greg Durrett. 2020. Evaluating factuality in generation with dependency-level entailment. In Findings of the Association for Computational Linguistics: EMNLP 2020
2020
-
[6]
Ivan Habernal, Steffen Eger, and Iryna Gurevych. 2016. https://aclanthology.org/C16-1102/ Sequential clustering and contextual importance measures for incremental update summarization . In Proceedings of COLING 2016, the 26th International Conference on Computational Linguistics: Technical Papers, pages 1042--1053
2016
-
[10]
Wojciech Kry \'s ci \'n ski, Bryan McCann, Caiming Xiong, and Richard Socher. 2019. Evaluating the factual consistency of abstractive text summarization. arXiv preprint arXiv:1910.12840
arXiv 2019
-
[12]
Xiang Lisa Li, John Thickstun, Ishaan Gulrajani, Percy Liang, and Tatsunori Hashimoto. 2022. https://api.semanticscholar.org/CorpusID:249192356 Diffusion-lm improves controllable text generation . ArXiv, abs/2205.14217
arXiv 2022
-
[13]
Chin-Yew Lin. 2004. https://aclanthology.org/W04-1013/ ROUGE : A package for automatic evaluation of summaries . In Text Summarization Branches Out, pages 74--81, Barcelona, Spain. Association for Computational Linguistics
2004
-
[14]
Aman Madaan, Niket Tandon, Prakhar Gupta, Skyler Hallinan, Luyu Gao, Sarah Wiegreffe, Uri Alon, Nouha Dziri, Shrimai Prabhumoye, Yiming Yang, Shashank Gupta, Bodhisattwa Prasad Majumder, Katherine Hermann, Sean Welleck, Amir Yazdanbakhsh, and Peter Clark. 2023. https://arxiv.org/abs/2303.17651 Self-refine: Iterative refinement with self-feedback . Preprin...
Pith/arXiv arXiv 2023
-
[16]
Richard McCreadie, Craig Macdonald, and Iadh Ounis. 2014. https://www.dcs.gla.ac.uk/ richardm/papers/mccreadie2014_IUS.pdf Incremental update summarization: Adaptive sentence selection based on prevalence and novelty . In Proceedings of the 23rd ACM International Conference on Conference on Information and Knowledge Management (CIKM), pages 301--310
2014
-
[17]
Meta AI . 2024. https://ai.meta.com/blog/meta-llama-3 Introducing meta llama 3: The most capable openly available llm to date
2024
-
[18]
Feng Nan, Ramesh Nallapati, Zhiguo Wang, Cicero Nogueira dos Santos, Henghui Zhu, Dejiao Zhang, Kathleen McKeown, and Bing Xiang. 2021. https://arxiv.org/abs/2102.09130 Entity-level factual consistency of abstractive text summarization . Preprint, arXiv:2102.09130
arXiv 2021
-
[20]
Artidoro Pagnoni, Vidhisha Balachandran, and Yulia Tsvetkov. 2021. https://arxiv.org/abs/2104.13346 Understanding factuality in abstractive summarization with frank: A benchmark for factuality metrics . Preprint, arXiv:2104.13346
arXiv 2021
-
[21]
Subham Sekhar Sahoo, Marianne Arriola, Yair Schiff, Aaron Gokaslan, Edgar Marroquin, Justin T Chiu, Alexander Rush, and Volodymyr Kuleshov. 2024. https://api.semanticscholar.org/CorpusID:270380319 Simple and effective masked diffusion language models . ArXiv, abs/2406.07524
arXiv 2024
-
[22]
Thomas Scialom, Paul-Alexis Dray, Patrick Gallinari, Sylvain Lamprier, Benjamin Piwowarski, Jacopo Staiano, and Alex Wang. 2021. https://arxiv.org/abs/2103.12693 Questeval: Summarization asks for fact-based evaluation . Preprint, arXiv:2103.12693
arXiv 2021
-
[24]
Raghav Singhal, Zachary Horvitz, Ryan Teehan, Mengye Ren, Zhou Yu, Kathleen McKeown, and R V Ranganath. 2025. https://api.semanticscholar.org/CorpusID:275470889 A general framework for inference-time scaling and steering of diffusion models . ArXiv, abs/2501.06848
arXiv 2025
-
[25]
Liyan Tang, Philippe Laban, and Greg Durrett. 2024 a . https://arxiv.org/pdf/2404.10774 Minicheck: Efficient fact-checking of llms on grounding documents . In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics
arXiv 2024
-
[26]
Liyan Tang, Igor Shalyminov, Amy Wing mei Wong, Jon Burnsky, Jake W. Vincent, Yu'an Yang, Siffi Singh, Song Feng, Hwanjun Song, Hang Su, Lijia Sun, Yi Zhang, Saab Mansour, and Kathleen McKeown. 2024 b . https://arxiv.org/abs/2402.13249 Tofueval: Evaluating hallucinations of llms on topic-focused dialogue summarization . Preprint, arXiv:2402.13249
arXiv 2024
-
[27]
Manya Wadhwa, Xinyu Zhao, Junyi Jessy Li, and Greg Durrett. 2024. https://api.semanticscholar.org/CorpusID:270878552 Learning to refine with fine-grained natural language feedback . ArXiv, abs/2407.02397
arXiv 2024
-
[28]
David Wan, Mengwen Liu, Kathleen McKeown, Markus Dreyer, and Mohit Bansal. 2023. https://arxiv.org/abs/2303.03278 Faithfulness-aware decoding strategies for abstractive summarization . Preprint, arXiv:2303.03278
arXiv 2023
-
[29]
David Wan, Jesse Vig, Mohit Bansal, and Shafiq Joty. 2025. https://arxiv.org/abs/2410.23609 On positional bias of faithfulness for long-form summarization . Preprint, arXiv:2410.23609
arXiv 2025
-
[31]
Yuheng Zha, Yichi Yang, Ruichen Li, and Zhiting Hu. 2023. https://aclanthology.org/2023.acl-long.634 A lign S core: Evaluating factual consistency with a unified alignment function . In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 11328--11348, Toronto, Canada. Association for Compu...
2023
-
[32]
Tianyi Zhang, Varsha Kishore, Felix Wu, Kilian Q. Weinberger, and Yoav Artzi. 2020. https://arxiv.org/abs/1904.09675 Bertscore: Evaluating text generation with bert . Preprint, arXiv:1904.09675
Pith/arXiv arXiv 2020
-
[33]
Hao Zou, Zae Myung Kim, and Dongyeop Kang. 2023. https://arxiv.org/abs/2305.14671 A survey of diffusion models in natural language processing . Preprint, arXiv:2305.14671
arXiv 2023
-
[34]
Aho and Jeffrey D
Alfred V. Aho and Jeffrey D. Ullman , title =. 1972
1972
-
[35]
Publications Manual , year = "1983", publisher =
1983
-
[36]
Ashok K. Chandra and Dexter C. Kozen and Larry J. Stockmeyer , year = "1981", title =. doi:10.1145/322234.322243
-
[37]
Scalable training of
Andrew, Galen and Gao, Jianfeng , booktitle=. Scalable training of
-
[38]
Dan Gusfield , title =. 1997
1997
-
[39]
Tetreault , title =
Mohammad Sadegh Rasooli and Joel R. Tetreault , title =. Computing Research Repository , volume =. 2015 , url =
2015
-
[40]
A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =
Ando, Rie Kubota and Zhang, Tong , Issn =. A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =. Journal of Machine Learning Research , Month = dec, Numpages =
-
[41]
2021 , eprint=
Understanding Factuality in Abstractive Summarization with FRANK: A Benchmark for Factuality Metrics , author=. 2021 , eprint=
2021
-
[42]
Evaluating the Factual Consistency of Abstractive Text Summarization
Kryscinski, Wojciech and McCann, Bryan and Xiong, Caiming and Socher, Richard. Evaluating the Factual Consistency of Abstractive Text Summarization. Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP). 2020. doi:10.18653/v1/2020.emnlp-main.750
-
[43]
Evaluating the Factual Consistency of Abstractive Text Summarization , journal =
Wojciech Kry. Evaluating the Factual Consistency of Abstractive Text Summarization , journal =
-
[44]
Findings of the Association for Computational Linguistics: EMNLP 2020 , year=
Evaluating Factuality in Generation with Dependency-level Entailment , author=. Findings of the Association for Computational Linguistics: EMNLP 2020 , year=
2020
-
[45]
2021 , eprint=
QuestEval: Summarization Asks for Fact-based Evaluation , author=. 2021 , eprint=
2021
-
[46]
2023 , eprint=
Faithfulness-Aware Decoding Strategies for Abstractive Summarization , author=. 2023 , eprint=
2023
-
[47]
ArXiv , year=
Learning to Refine with Fine-Grained Natural Language Feedback , author=. ArXiv , year=
-
[48]
D ialog S um: A real-life scenario dialogue summarization dataset
Chen, Yulong and Liu, Yang and Chen, Liang and Zhang, Yue. D ialog S um: A Real-Life Scenario Dialogue Summarization Dataset. Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021. 2021. doi:10.18653/v1/2021.findings-acl.449
-
[49]
See, Abigail and Liu, Peter J. and Manning, Christopher D. Get To The Point: Summarization with Pointer-Generator Networks. Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2017. doi:10.18653/v1/P17-1099
-
[50]
On Faithfulness and Factuality in Abstractive Summarization
Maynez, Joshua and Narayan, Shashi and Bohnet, Bernd and McDonald, Ryan. On Faithfulness and Factuality in Abstractive Summarization. Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. 2020. doi:10.18653/v1/2020.acl-main.173
-
[51]
A lign S core: Evaluating Factual Consistency with A Unified Alignment Function
Zha, Yuheng and Yang, Yichi and Li, Ruichen and Hu, Zhiting. A lign S core: Evaluating Factual Consistency with A Unified Alignment Function. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2023
2023
-
[52]
Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , year =
MiniCheck: Efficient Fact-Checking of LLMs on Grounding Documents , author =. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , year =
2024
-
[53]
2021 , eprint=
Entity-level Factual Consistency of Abstractive Text Summarization , author=. 2021 , eprint=
2021
-
[54]
2023 , eprint=
Self-Refine: Iterative Refinement with Self-Feedback , author=. 2023 , eprint=
2023
-
[55]
ArXiv , year=
Diffusion-LM Improves Controllable Text Generation , author=. ArXiv , year=
-
[56]
ArXiv , year=
Simple and Effective Masked Diffusion Language Models , author=. ArXiv , year=
-
[57]
arXiv preprint arXiv:2502.09992 , year=
Large Language Diffusion Models , author=. arXiv preprint arXiv:2502.09992 , year=
-
[58]
arXiv preprint arXiv:2503.00307 , year=
Remasking Discrete Diffusion Models with Inference-Time Scaling , author=. arXiv preprint arXiv:2503.00307 , year=
-
[59]
arXiv preprint arXiv:2509.23653 , year=
Don't Settle Too Early: Self-Reflective Remasking for Diffusion Language Models , author=. arXiv preprint arXiv:2509.23653 , year=
-
[60]
ArXiv , year=
Don't Give Me the Details, Just the Summary! Topic-Aware Convolutional Neural Networks for Extreme Summarization , author=. ArXiv , year=
-
[61]
Enhancing Incremental Summarization with Structured Representations
Hwang, EunJeong and Zhou, Yichao and Wendt, James Bradley and Gunel, Beliz and Vo, Nguyen and Xie, Jing and Tata, Sandeep. Enhancing Incremental Summarization with Structured Representations. Findings of the Association for Computational Linguistics: EMNLP 2024. 2024. doi:10.18653/v1/2024.findings-emnlp.220
-
[62]
Proceedings of the Twenty-Second Text REtrieval Conference (TREC 2013) , year=
Overview of the TREC 2013 Temporal Summarization track , author=. Proceedings of the Twenty-Second Text REtrieval Conference (TREC 2013) , year=
2013
-
[63]
From Moments to Milestones: Incremental Timeline Summarization Leveraging Large Language Models
Hu, Qisheng and Moon, Geonsik and Ng, Hwee Tou. From Moments to Milestones: Incremental Timeline Summarization Leveraging Large Language Models. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2024. doi:10.18653/v1/2024.acl-long.390
-
[64]
Proceedings of the 23rd ACM International Conference on Conference on Information and Knowledge Management (CIKM) , pages=
Incremental update summarization: Adaptive sentence selection based on prevalence and novelty , author=. Proceedings of the 23rd ACM International Conference on Conference on Information and Knowledge Management (CIKM) , pages=. 2014 , url=
2014
-
[65]
Proceedings of COLING 2016, the 26th International Conference on Computational Linguistics: Technical Papers , pages=
Sequential Clustering and Contextual Importance Measures for Incremental Update Summarization , author=. Proceedings of COLING 2016, the 26th International Conference on Computational Linguistics: Technical Papers , pages=. 2016 , url=
2016
-
[66]
ArXiv , year=
A General Framework for Inference-time Scaling and Steering of Diffusion Models , author=. ArXiv , year=
-
[67]
arXiv preprint arXiv:2602.16813 , year=
Flow Map Language Models: One-step Language Modeling via Continuous Denoising , author=. arXiv preprint arXiv:2602.16813 , year=
-
[68]
2024 , url=
Introducing Meta Llama 3: The most capable openly available LLM to date , author=. 2024 , url=
2024
-
[69]
2020 , eprint=
BERTScore: Evaluating Text Generation with BERT , author=. 2020 , eprint=
2020
-
[70]
ROUGE : A Package for Automatic Evaluation of Summaries
Lin, Chin-Yew. ROUGE : A Package for Automatic Evaluation of Summaries. Text Summarization Branches Out. 2004
2004
-
[71]
BLEURT : Learning Robust Metrics for Text Generation
Sellam, Thibault and Das, Dipanjan and Parikh, Ankur. BLEURT : Learning Robust Metrics for Text Generation. Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. 2020. doi:10.18653/v1/2020.acl-main.704
-
[72]
2023 , eprint=
AlignScore: Evaluating Factual Consistency with a Unified Alignment Function , author=. 2023 , eprint=
2023
-
[73]
2021 , eprint=
SummEval: Re-evaluating Summarization Evaluation , author=. 2021 , eprint=
2021
-
[74]
2022 , eprint=
QAFactEval: Improved QA-Based Factual Consistency Evaluation for Summarization , author=. 2022 , eprint=
2022
-
[75]
2024 , eprint=
TofuEval: Evaluating Hallucinations of LLMs on Topic-Focused Dialogue Summarization , author=. 2024 , eprint=
2024
-
[76]
2025 , eprint=
On Positional Bias of Faithfulness for Long-form Summarization , author=. 2025 , eprint=
2025
-
[77]
2023 , eprint=
A Survey of Diffusion Models in Natural Language Processing , author=. 2023 , eprint=
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.