AIR-VLA+: Decoupling Movement and Manipulation via Cascaded Dual-Action Decoders with Asymmetric MoE for Aerial Robots
Pith reviewed 2026-06-27 06:49 UTC · model grok-4.3
The pith
Cascaded dual-action decoders with asymmetric MoE let UAV movement observe manipulator intent unidirectionally, raising aerial task scores to 48.0.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
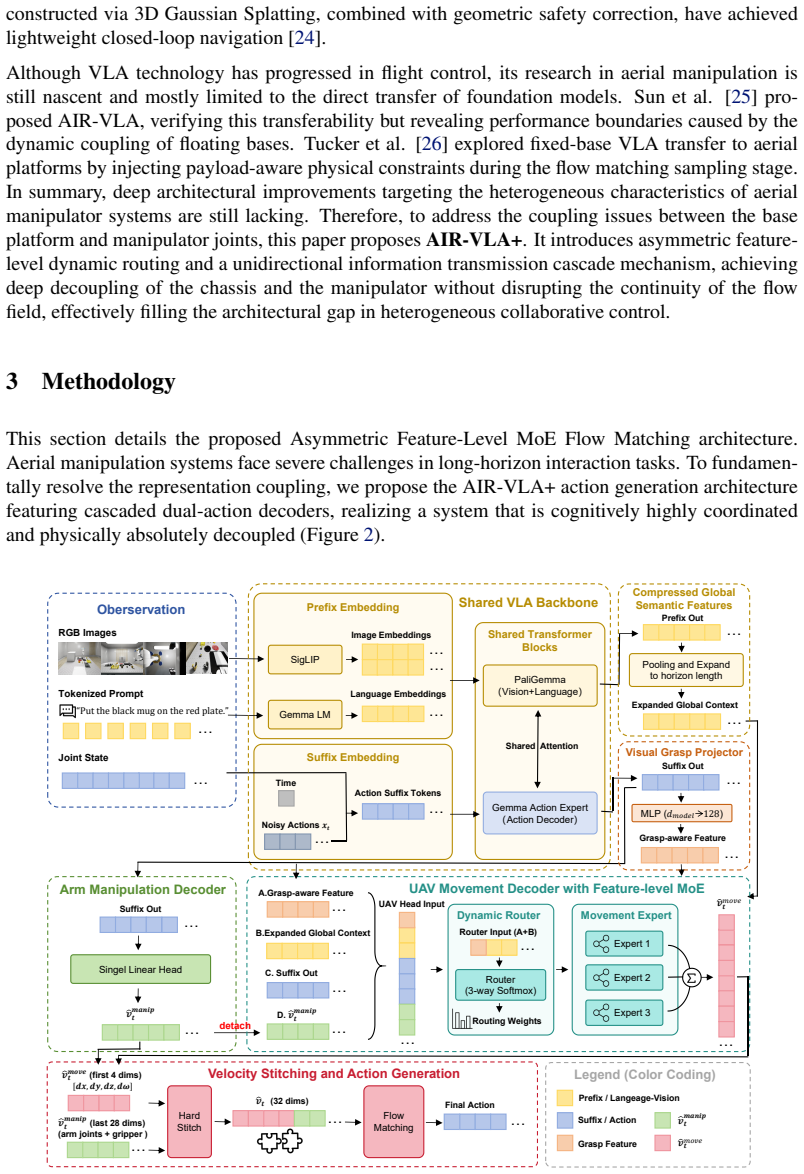
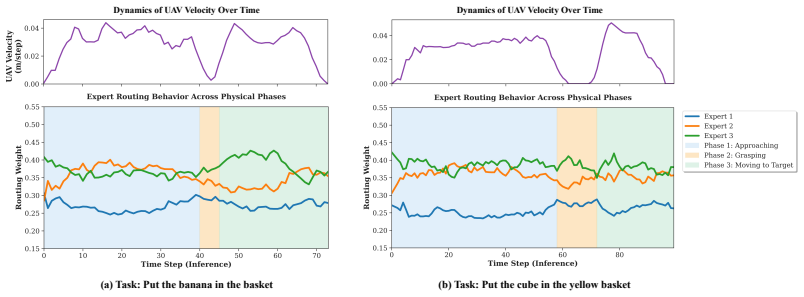
AIR-VLA+ constructs cascaded manipulation and movement decoders that allow unidirectional observation of manipulator intent by the UAV, isolates back-propagation from movement to manipulation, augments the movement decoder with an implicit visual grasp projector and global semantics, and deploys an implicit MoE so that movement experts spontaneously specialize across task stages; this yields an overall average score of 48.0 and an 80.2 percent improvement in task completion over the single-head π_{0.5} policy on the AIR-VLA benchmark.
What carries the argument
Cascaded dual-action decoders with unidirectional information flow and an asymmetric implicit MoE inside the movement decoder
If this is right
- Overall task completion improves 80.2 percent relative to the single-head π_{0.5} policy.
- The method mitigates heterogeneous coordinated control conflicts between UAV movement and arm manipulation.
- Movement experts inside the implicit MoE develop spontaneous capacity inclinations for distinct task stages during training.
- Dense soft blending on the feature manifold gives UAV movement stronger task-stage adaptability.
- The architecture comprehensively exceeds all tested baselines on the standardized AIR-VLA benchmark with an average score of 48.0.
Where Pith is reading between the lines
- The same unidirectional cascade could be tested on ground-based mobile manipulators where base motion and arm motion also differ in dynamics.
- Removing explicit task-stage labels might become feasible if the implicit MoE reliably discovers phase-specific experts across new robot morphologies.
- The visual grasp projector could be replaced by other low-dimensional state estimators to check whether the performance gain depends on that particular perception module.
- Scaling the asymmetric MoE to more experts might reveal whether the observed spontaneous specialization continues or saturates.
Load-bearing premise
Unidirectional observation from the movement decoder to the manipulation decoder together with the implicit visual grasp projector will maintain stable coordination without back-propagation interference across every task stage and object interaction.
What would settle it
Run the full AIR-VLA benchmark suite on a scenario where gripper-object contact changes rapidly during a mid-air transition; if the new method's score falls below the single-head baseline, the coordination claim does not hold.
Figures


read the original abstract
Aerial manipulation systems have long suffered from representation coupling in end-to-end control, as platform-level Unmanned Aerial Vehicle (UAV) movement and end-effector-level arm manipulation differ substantially in action scale, dynamics, and control objectives. In this paper, we propose AIR-VLA+, a flow matching action generation architecture specifically designed for aerial manipulation, featuring cascaded dual-action decoders and an asymmetric feature-level Mixture of Experts (MoE). We construct cascaded manipulation and movement decoders, allowing the UAV to unidirectionally observe the manipulator's intent during movement to achieve workflow coordination, while isolating the impact of UAV movement information backpropagation on arm manipulation stability. Addressing the characteristic that UAV movement is highly dependent on high-level semantics and responsible for task state transitions in aerial manipulation, we design an input feature enhancement module for the UAV movement decoder. This module introduces an implicit visual grasp projector to perceive the interaction state between the gripper and the object, and injects compressed global semantic features. Within the UAV movement decoder, we deploy an implicit MoE architecture, enabling different movement experts to spontaneously exhibit capacity inclinations for various task stages during training. Through dense soft blending computation on the feature manifold, the UAV movement is endowed with stronger task-stage adaptability. Experiments on the standardized AIR-VLA benchmark demonstrate that our method comprehensively surpasses all baselines with an overall average score of 48.0. The overall task completion score improves by 80.2\% compared to the single-head $\pi_{0.5}$ policy, effectively mitigating the heterogeneous coordinated control conflicts of composite robots.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes AIR-VLA+, a flow matching action generation architecture for aerial manipulation robots featuring cascaded dual-action decoders (manipulation and movement) with unidirectional observation from the movement decoder to the manipulation decoder, an implicit visual grasp projector for interaction state perception, and an asymmetric feature-level Mixture of Experts (MoE) in the movement decoder for task-stage adaptability. It claims this decouples UAV movement from arm manipulation to mitigate heterogeneous control conflicts, and reports an overall average score of 48.0 on the AIR-VLA benchmark with an 80.2% improvement in task completion over the single-head π_{0.5} policy.
Significance. If the reported benchmark gains can be rigorously attributed to the cascaded architecture and MoE via proper controls, the work would offer a meaningful advance in composite aerial manipulation systems by addressing action-scale and dynamics mismatches. The flow-matching and implicit MoE design for spontaneous expert specialization during training represents a targeted contribution to task-adaptive control, though its impact hinges on experimental transparency.
major comments (2)
- [Experiments] Experiments section: the central performance claim of an overall score of 48.0 and 80.2% improvement over the single-head π_{0.5} policy is presented without error bars, baseline implementation details, or ablations that isolate the cascaded dual-action decoders from the asymmetric MoE; these omissions prevent attribution of gains to the decoupling mechanism.
- [Method] Method section: the key assumption that unidirectional observation from movement decoder to manipulation decoder plus the implicit visual grasp projector produces stable coordination without back-propagation interference is not supported by gradient flow analysis, per-stage metrics, or interference ablations across task phases and object interactions in the AIR-VLA benchmark.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. The comments raise valid points regarding experimental transparency and methodological support. We address each major comment below and will make the necessary revisions to the manuscript.
read point-by-point responses
-
Referee: [Experiments] Experiments section: the central performance claim of an overall score of 48.0 and 80.2% improvement over the single-head π_{0.5} policy is presented without error bars, baseline implementation details, or ablations that isolate the cascaded dual-action decoders from the asymmetric MoE; these omissions prevent attribution of gains to the decoupling mechanism.
Authors: We acknowledge the need for greater experimental rigor to support attribution of the reported gains. In the revised version, we will add error bars computed over multiple training runs with different seeds, provide comprehensive implementation details for the baselines (including how the single-head π_{0.5} policy was trained and evaluated), and conduct additional ablation experiments that isolate the effects of the cascaded dual-action decoders from those of the asymmetric MoE. This will enable clearer attribution of the performance improvements to the proposed decoupling approach. revision: yes
-
Referee: [Method] Method section: the key assumption that unidirectional observation from movement decoder to manipulation decoder plus the implicit visual grasp projector produces stable coordination without back-propagation interference is not supported by gradient flow analysis, per-stage metrics, or interference ablations across task phases and object interactions in the AIR-VLA benchmark.
Authors: The unidirectional flow is a core design choice to allow the movement decoder to observe manipulation intent without allowing movement information to affect manipulation stability via backpropagation. The implicit visual grasp projector is introduced to enhance state perception for the movement decoder. While these elements were motivated by the need to mitigate interference, we did not provide explicit supporting analyses in the initial submission. We will revise the method section to include gradient flow analysis, per-stage performance metrics, and interference ablations across different task phases and object interactions to substantiate the claim of stable coordination. revision: yes
Circularity Check
No circularity: empirical benchmark results on external AIR-VLA dataset
full rationale
The paper proposes an architectural design (cascaded decoders + asymmetric MoE + unidirectional observation + implicit projector) and reports empirical task-completion scores on the standardized AIR-VLA benchmark. No mathematical derivation, first-principles prediction, or fitted-parameter claim is present that reduces to its own inputs by construction. No self-citations are invoked as load-bearing for the performance claims, and the reported 48.0 average / 80.2% improvement are external measurements rather than internal re-statements of the architecture definitions.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Q. Liu, Y . Liu, Z. Chen, K. Guo, X. Yu, Y . Zhang, and L. Guo. A compact aerial manipulator: Design and control for dexterous operations.Journal of Intelligent & Robotic Systems, 110 (2):66, Apr 2024. ISSN 1573-0409. doi:10.1007/s10846-024-02090-7. URLhttps://doi. org/10.1007/s10846-024-02090-7
-
[2]
R. Peng, Y . Wang, M. Lu, and P. Lu. A dexterous and compliant aerial continuum manipulator for cluttered and constrained environments.Nature Communications, 16(1):889, Jan 2025. ISSN 2041-1723. doi:10.1038/s41467-024-55157-2. URLhttps://doi.org/10.1038/ s41467-024-55157-2
-
[3]
S. Ghorbani, Z. Samadikhoshkho, and F. Janabi-Sharifi. Dual-arm aerial continuum ma- nipulation systems: modeling, pre-grasp planning, and control.Nonlinear Dynamics, 111 (8):7339–7355, Apr 2023. ISSN 1573-269X. doi:10.1007/s11071-022-08212-w. URL https://doi.org/10.1007/s11071-022-08212-w
-
[4]
J. Liang, Y . Chen, Y . Wu, Z. Miao, H. Zhang, and Y . Wang. Adaptive prescribed performance control of unmanned aerial manipulator with disturbances.IEEE Transactions on Automation Science and Engineering, 20(3):1804–1814, 2023. doi:10.1109/TASE.2022.3186315
-
[5]
S. Deshmukh, J. Alonso-Mora, and S. Sun. Global end-effector pose control of an underactu- ated aerial manipulator via reinforcement learning, 2025. URLhttps://arxiv.org/abs/ 2512.21085
arXiv 2025
-
[6]
M. Xu, A. Hu, and H. Wang. Image-based visual impedance force control for contact aerial manipulation.IEEE Transactions on Automation Science and Engineering, 20(1):518–527,
-
[7]
doi:10.1109/TASE.2022.3162207
-
[8]
M. Wang, S. Lyu, Q. Liu, Z. Yang, K. Guo, and X. Yu. Precise end-effector control for an aerial manipulator under composite disturbances: Theory and experiments.IEEE Transac- tions on Automation Science and Engineering, 22:4006–4021, 2025. doi:10.1109/TASE.2024. 3406754. 10
-
[9]
Z. Zhang, H. Yu, Y . Chai, Z. Yang, X. Liang, Y . Fang, and J. Han. An end-effector- oriented coupled motion planning method for aerial manipulators in constrained environments. IEEE/ASME Transactions on Mechatronics, 30(6):6027–6037, 2025. doi:10.1109/TMECH. 2025.3550562
-
[10]
C. P. Carvajal, G. M. Andaluz, V . H. Andaluz, F. Roberti, G. Palacios-Navarro, and R. Carelli. Multitask control of aerial manipulator robots with dynamic compensation based on numerical methods.Robotics and Autonomous Systems, 173:104614, 2024. ISSN 0921-8890. doi:https:// doi.org/10.1016/j.robot.2023.104614. URLhttps://www.sciencedirect.com/science/ ar...
-
[11]
W. Deng, H. Chen, B. Ye, H. Chen, Z. Li, and X. Lyu. Whole-body integrated motion planning for aerial manipulators.IEEE Transactions on Robotics, 41:6661–6679, 2025. doi:10.1109/ TRO.2025.3626619
arXiv 2025
-
[12]
A. Brohan, N. Brown, J. Carbajal, Y . Chebotar, J. Dabis, C. Finn, K. Gopalakrishnan, K. Haus- man, A. Herzog, J. Hsu, J. Ibarz, B. Ichter, A. Irpan, T. Jackson, S. Jesmonth, N. J. Joshi, R. Julian, D. Kalashnikov, Y . Kuang, I. Leal, K.-H. Lee, S. Levine, Y . Lu, U. Malla, D. Man- junath, I. Mordatch, O. Nachum, C. Parada, J. Peralta, E. Perez, K. Pertsc...
Pith/arXiv arXiv 2023
-
[13]
M. J. Kim, K. Pertsch, S. Karamcheti, T. Xiao, A. Balakrishna, S. Nair, R. Rafailov, E. Foster, G. Lam, P. Sanketi, Q. Vuong, T. Kollar, B. Burchfiel, R. Tedrake, D. Sadigh, S. Levine, P. Liang, and C. Finn. Openvla: An open-source vision-language-action model, 2024. URL https://arxiv.org/abs/2406.09246
Pith/arXiv arXiv 2024
-
[14]
K. Black, N. Brown, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusai, L. Groom, K. Haus- man, B. Ichter, S. Jakubczak, T. Jones, L. Ke, S. Levine, A. Li-Bell, M. Mothukuri, S. Nair, K. Pertsch, L. X. Shi, J. Tanner, Q. Vuong, A. Walling, H. Wang, and U. Zhilinsky.π 0: A vision-language-action flow model for general robot control, 2026. URLhttps://arxiv. o...
Pith/arXiv arXiv 2026
-
[15]
Black, N
K. Black, N. Brown, J. Darpinian, K. Dhabalia, D. Driess, A. Esmail, M. R. Equi, C. Finn, N. Fusai, M. Y . Galliker, D. Ghosh, L. Groom, K. Hausman, brian ichter, S. Jakubczak, T. Jones, L. Ke, D. LeBlanc, S. Levine, A. Li-Bell, M. Mothukuri, S. Nair, K. Pertsch, A. Z. Ren, L. X. Shi, L. Smith, J. T. Springenberg, K. Stachowicz, J. Tanner, Q. Vuong, H. Wa...
2025
-
[16]
P. Intelligence, A. Amin, R. Aniceto, A. Balakrishna, K. Black, K. Conley, G. Connors, J. Darpinian, K. Dhabalia, J. DiCarlo, D. Driess, M. Equi, A. Esmail, Y . Fang, C. Finn, C. Glos- sop, T. Godden, I. Goryachev, L. Groom, H. Hancock, K. Hausman, G. Hussein, B. Ichter, S. Jakubczak, R. Jen, T. Jones, B. Katz, L. Ke, C. Kuchi, M. Lamb, D. LeBlanc, S. Lev...
Pith/arXiv arXiv 2025
-
[17]
P. Intelligence, B. Ai, A. Amin, R. Aniceto, A. Balakrishna, G. Balke, K. Black, G. Bokin- sky, S. Cao, T. Charbonnier, V . Choudhary, F. Collins, K. Conley, G. Connors, J. Darpinian, K. Dhabalia, M. Dhaka, J. DiCarlo, D. Driess, M. Equi, A. Esmail, Y . Fang, C. Finn, C. Glos- sop, T. Godden, I. Goryachev, L. Groom, H. Habeeb, H. Hancock, K. Hausman, G. H...
Pith/arXiv arXiv 2026
-
[18]
X. Liu, Y . Liu, H. Qiu, Y . Qirong, and Z. Lian. Indooruav: Benchmarking vision-language uav navigation in continuous indoor environments, 2025. URLhttps://arxiv.org/abs/ 2512.19024
arXiv 2025
-
[19]
X. Sun, W. Si, W. Ni, Y . Li, D. Wu, F. Xie, R. Guan, H.-Y . Xu, H. Ding, Y . Wu, Y . Yue, Y . Huang, and H. Xiong. Autofly: Vision-language-action model for uav autonomous naviga- tion in the wild, 2026. URLhttps://arxiv.org/abs/2602.09657
arXiv 2026
-
[20]
Q. Zhang, S. Zheng, J. Sun, C. Li, X. Wu, Z. Song, Z. Cui, Y . Lv, and Y . Tian. Uav-track vla: Embodied aerial tracking via vision-language-action models, 2026. URLhttps://arxiv. org/abs/2604.02241
Pith/arXiv arXiv 2026
-
[21]
P. Xu, Z. Deng, J. Deng, Z. Gu, and S. Wan. Aerialvla: A vision-language-action model for uav navigation via minimalist end-to-end control, 2026. URLhttps://arxiv.org/abs/ 2603.14363
arXiv 2026
-
[22]
V . Serpiva, A. Lykov, A. Myshlyaev, M. H. Khan, A. A. Abdulkarim, O. Sautenkov, and D. Tsetserukou. Racevla: Vla-based racing drone navigation with human-like behaviour, 2025. URLhttps://arxiv.org/abs/2503.02572
arXiv 2025
-
[23]
X. Wang, D. Yang, Y . Liao, W. Zheng, wenjun wu, B. Dai, H. Li, and S. Liu. Uav-flow colosseo: A real-world benchmark for flying-on-a-word uav imitation learning, 2025. URL https://arxiv.org/abs/2505.15725
arXiv 2025
-
[24]
Lykov, V
A. Lykov, V . Serpiva, M. H. Khan, O. Sautenkov, A. Myshlyaev, G. Tadevosyan, Y . Yaqoot, and D. Tsetserukou. Cognitivedrone: A vla model and evaluation benchmark for real-time cognitive task solving and reasoning in uavs, 2025. URLhttps://arxiv.org/abs/2503. 01378
2025
-
[25]
Y . Wu, M. Zhu, X. Li, Y . Du, Y . Fan, W. Li, Z. Han, X. Zhou, and F. Gao. Vla-an: An efficient and onboard vision-language-action framework for aerial navigation in complex environments,
-
[26]
URLhttps://arxiv.org/abs/2512.15258
-
[27]
J. Sun, B. Tian, Q. Zhang, C. Li, Z. Song, Z. Cui, Y . Lv, and Y . Tian. Air-vla: Vision-language- action systems for aerial manipulation, icml 2026. URLhttps://arxiv.org/abs/2601. 21602
2026
-
[28]
Tucker, D
J. Tucker, D. Liu, A. Swann, A. Ren, J. Yu, J. Sun, B. Kim, L. McGranahan, Q. Vuong, and M. Schwager.π, but make it fly: Physics-guided transfer of vla models to aerial manipulation,
-
[29]
URLhttps://arxiv.org/abs/2603.25038. 12 A Implementation and Training Details Architecture Specifications:Our proposed AIR-VLA+ builds upon the Physical Intelligenceπ 0.5 foundation model as the primary vision-language backbone. To construct theinput feature enhance- ment module, we apply mean pooling over the sequence output of the prefix tokens (images ...
-
[30]
Gradients were clipped at a maximum norm of 1.0 to ensure stability. During the inference phase, the continuous trajectory generation is solved using an Euler ODE solver, configured with 10 Neural Function Evaluations (NFE) uniformly spaced across the integration time horizont∈[0,1]. Finally, to ensure statistical reliability during evaluation, the report...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.