Efficient, Robust, and Anti-Collusion Fingerprinting of Image Diffusion Models
Pith reviewed 2026-06-27 07:29 UTC · model grok-4.3
The pith
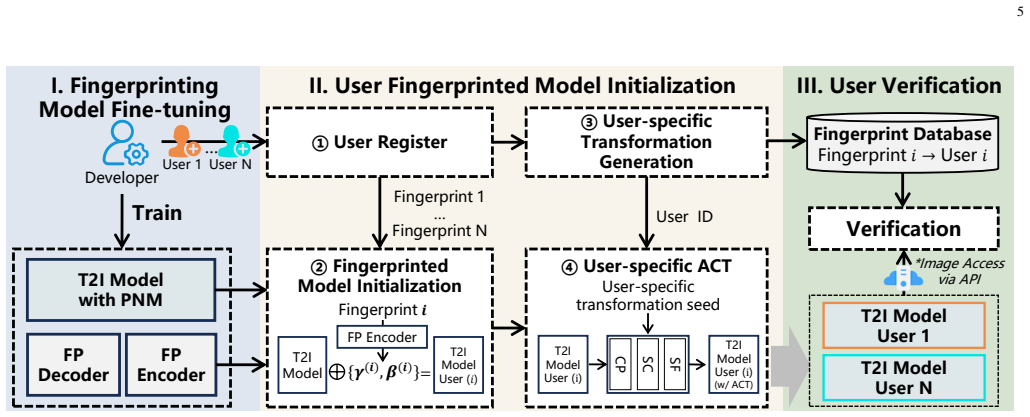
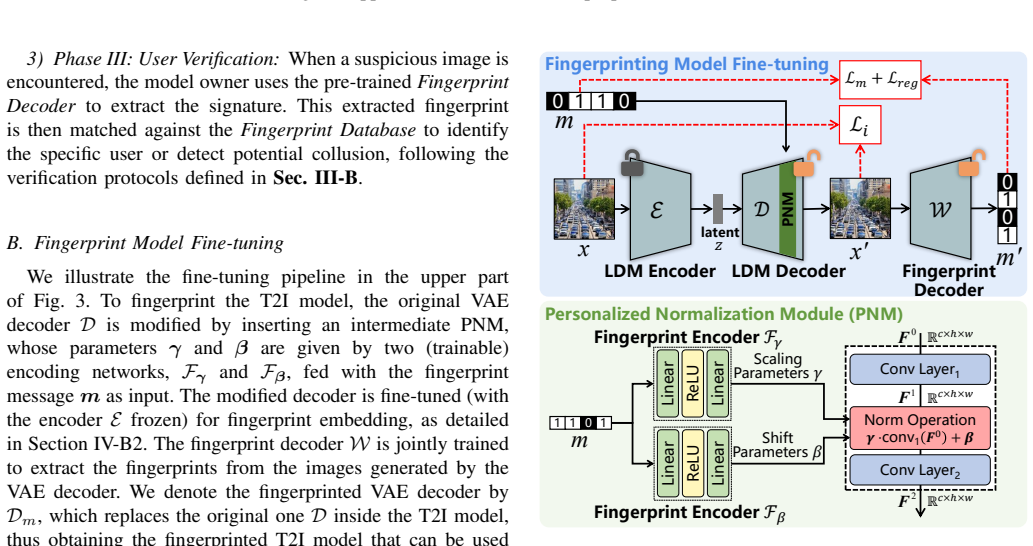
Text-to-image diffusion models can embed user fingerprints in a normalization module so that any generated image reveals the source while parameter transformations degrade colluded copies by raising their FID.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Fingerprints are encoded directly into the coefficients of a personalized normalization module incorporated into text-to-image diffusion models so that the bit string can be recovered from any generated image; an accompanying anti-collusion mechanism applies lossless function-invariant parameter transformations that leave single models unchanged yet cause any colluded combination to exhibit substantially higher FID scores, rendering the combined model unusable; multiple distinct fingerprinted copies can be produced efficiently by reparameterization alone, and a worst-case optimization step further strengthens robustness against model-level attacks, yielding extraction accuracy above 99.5 per
What carries the argument
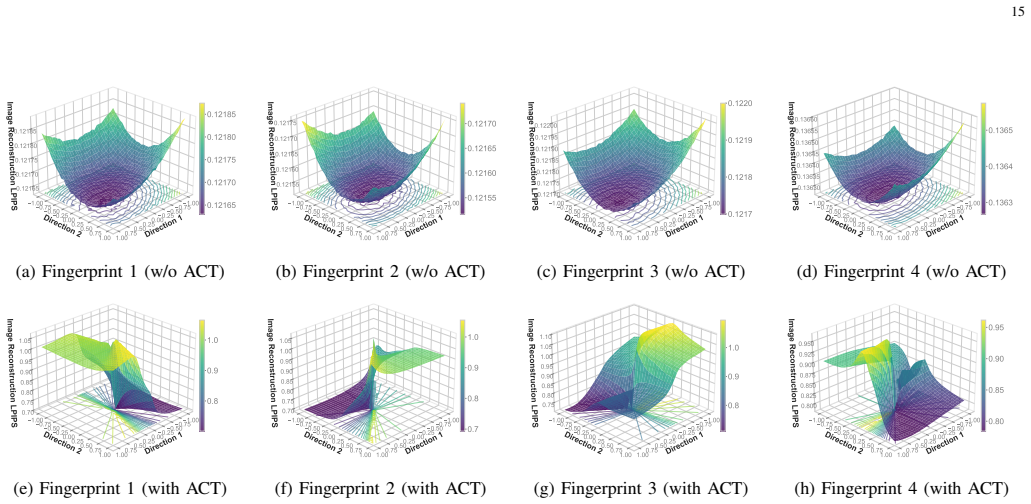
Personalized normalization module (PNM) whose coefficients store the fingerprint bits, paired with lossless function-invariant parameter transformations that enforce the anti-collusion effect.
If this is right
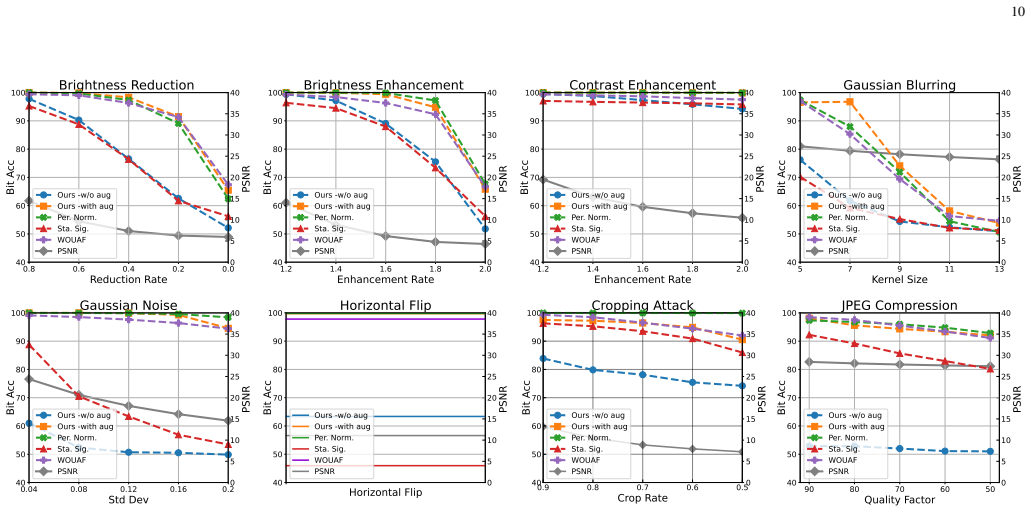
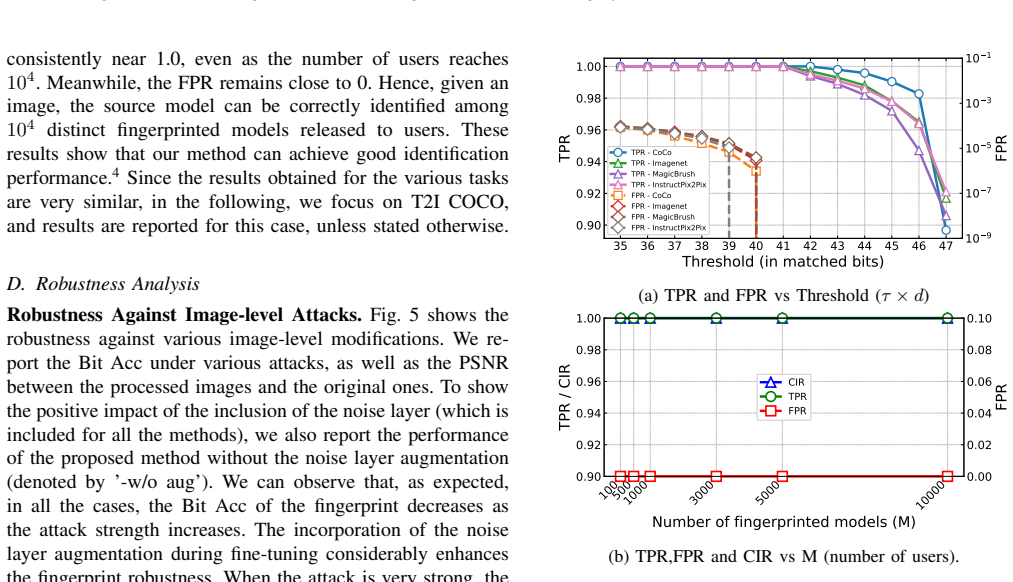
- Fingerprint extraction accuracy exceeds 99.5 percent on images from multiple text-to-image generation and editing tasks.
- Any model formed by collusion shows a significant increase in FID, making its outputs unusable for practical purposes.
- Developers can produce many distinct fingerprinted model copies through reparameterization of the normalization module without retraining.
- A worst-case optimization step improves resistance to attacks that operate at the model level.
- The method preserves the original generative fidelity for legitimate single-user copies across the tested tasks.
Where Pith is reading between the lines
- The same embedding and transformation pattern could be tested on other families of generative models that rely on normalization layers.
- If the transformations scale reliably, they suggest a route for embedding traceable identifiers directly into open-weight model releases without retraining each variant.
- The approach raises the possibility that parameter-level modifications can serve simultaneously as both identifiers and quality-based deterrents in broader digital-rights settings.
- Systematic trials with additional collusion strategies beyond the ones examined would clarify how far the proactive degradation effect extends.
Load-bearing premise
The parameter transformations remain completely lossless for any single authorized model yet produce a clear quality drop only when multiple fingerprinted models are combined, and the embedded bits remain reliably extractable from every output image.
What would settle it
Generate a colluded model from several fingerprinted copies using the described combination strategy, then measure whether its FID on standard prompts stays comparable to the original models or rises sharply, and check whether fingerprint extraction accuracy on its outputs falls below 99.5 percent.
Figures






read the original abstract
Model fingerprinting, embedding user-specific identifiers (fingerprints) into generated outputs, has recently emerged as a popular solution to protect the intellectual property rights (IPR) of generative text-to-image (T2I) models and prevent unauthorized redistribution. In this work, we reveal a previously unexplored systematic vulnerability in existing generative model fingerprinting methods: they lack robustness against collusion attacks, where multiple attackers combine their models to remove or obscure the fingerprints. To address this issue, we take the first step towards a robust fingerprinting method for T2I models with anti-collusion capabilities. The proposed method encodes strings of bits, namely fingerprints, into the coefficients of a personalized normalization module (PNM) incorporated into T2I models, so that fingerprints can be reliably recovered from any generated image. To defend against collusion attacks and prevent unauthorized model redistribution, we introduce an anti-collusion mechanism based on lossless function-invariant parameter transformations. This mechanism significantly degrades the image generation quality of colluded models, making them effectively unusable. Moreover, our method allows developers to efficiently create multiple copies of fingerprinted T2I models by reparameterizing the PNM without the need for retraining. We also introduce a worst-case optimization strategy to improve robustness against model-level attacks. Our experiments demonstrate that the proposed method achieves high fidelity and robustness across multiple T2I image generation and editing tasks, with fingerprint extraction accuracy exceeding 99.5%. Compared with existing methods, our method demonstrates, for the first time, a notable proactive robustness to collusion attacks by significantly increasing the FID of colluded models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
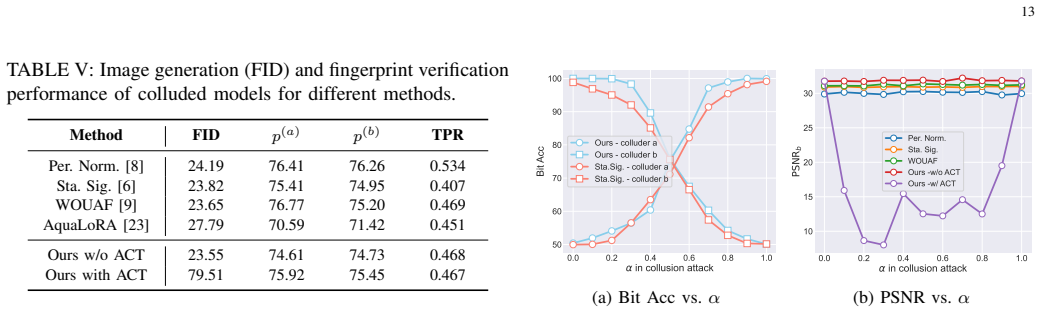
Summary. The paper introduces a fingerprinting scheme for text-to-image diffusion models that encodes bit-string fingerprints into the coefficients of a Personalized Normalization Module (PNM). It augments this with lossless function-invariant parameter transformations that preserve single-model behavior while degrading the output quality of colluded models. The method also supports efficient creation of multiple fingerprinted copies via reparameterization without retraining and employs a worst-case optimization for robustness. Experiments are reported to achieve >99.5% fingerprint extraction accuracy across generation and editing tasks together with a notable increase in FID for colluded models.
Significance. If the reported extraction accuracy and collusion-induced FID degradation hold under the stated conditions, the work provides the first explicit proactive defense against collusion attacks in generative-model fingerprinting. The lossless reparameterization technique that enables multiple distinct fingerprinted copies without retraining is a practical contribution that could be adopted more broadly. The combination of embedding and anti-collusion mechanisms addresses a previously unaddressed vulnerability in existing IPR-protection approaches for T2I models.
major comments (2)
- [Method description of the anti-collusion mechanism] The central claim of proactive robustness rests on the lossless function-invariant transformations preserving single-model usability while degrading colluded models. The manuscript should provide an explicit verification (e.g., a lemma or empirical table) that the transformations leave the forward pass of any single model unchanged; without this, the usability guarantee remains an assumption rather than a demonstrated property.
- [Experiments and results] The reported >99.5% extraction accuracy and FID increase for colluded models are presented as key results. The evaluation section should include the exact number of colluding parties tested, the precise FID values before and after collusion, and direct numerical comparison against at least two prior fingerprinting baselines under identical collusion settings; otherwise the “first time” novelty claim cannot be assessed quantitatively.
minor comments (2)
- Notation for the PNM coefficients and the transformation operators should be introduced once with consistent symbols across the method and appendix; repeated redefinition of the same symbols reduces readability.
- The abstract states “significantly increasing the FID of colluded models” without numerical values; the results section should state the observed FID deltas in the main text rather than only in figures.
Simulated Author's Rebuttal
We thank the referee for the constructive comments and the recommendation for minor revision. We address each major comment below and will update the manuscript accordingly to strengthen the presentation.
read point-by-point responses
-
Referee: [Method description of the anti-collusion mechanism] The central claim of proactive robustness rests on the lossless function-invariant transformations preserving single-model usability while degrading colluded models. The manuscript should provide an explicit verification (e.g., a lemma or empirical table) that the transformations leave the forward pass of any single model unchanged; without this, the usability guarantee remains an assumption rather than a demonstrated property.
Authors: We agree that an explicit verification strengthens the claim. In the revised manuscript we will add a short lemma proving that the function-invariant transformations leave the forward pass of any single model unchanged, together with an empirical table confirming identical outputs (within floating-point precision) before and after reparameterization for single models. revision: yes
-
Referee: [Experiments and results] The reported >99.5% extraction accuracy and FID increase for colluded models are presented as key results. The evaluation section should include the exact number of colluding parties tested, the precise FID values before and after collusion, and direct numerical comparison against at least two prior fingerprinting baselines under identical collusion settings; otherwise the “first time” novelty claim cannot be assessed quantitatively.
Authors: We will expand the evaluation section to state the exact range of colluding parties tested (2–5), report the precise FID numbers before and after collusion for each setting, and add a table providing direct numerical comparisons against two prior fingerprinting baselines under the identical collusion protocol. These additions will make the quantitative support for the novelty claim explicit. revision: yes
Circularity Check
No significant circularity
full rationale
The paper presents a constructive method for embedding fingerprints via PNM coefficients and lossless function-invariant reparameterizations, with anti-collusion effects and extraction accuracy reported as empirical experimental outcomes (>99.5% accuracy, FID degradation on colluded models). No derivation chain, equation, or claim reduces by construction to its own inputs; the central results are not self-definitional, fitted parameters renamed as predictions, or dependent on self-citation load-bearing premises. The construction is self-contained against external benchmarks and does not invoke uniqueness theorems or ansatzes from prior author work in a circular manner.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
High-resolution image synthesis with latent diffusion models,
R. Rombach, A. Blattmann, D. Lorenz, P. Esser, and B. Ommer, “High-resolution image synthesis with latent diffusion models,” inProc. IEEE/CVF Conf. Comput. Vis. Pattern Recog., New Orleans, Louisiana, USA, Jun. 2022, pp. 10 684–10 695
2022
-
[2]
Glide: Towards photorealistic image generation and editing with text-guided diffusion models,
A. Q. Nichol, P. Dhariwal, A. Ramesh, P. Shyam, P. Mishkin, B. Mc- grew, I. Sutskever, and M. Chen, “Glide: Towards photorealistic image generation and editing with text-guided diffusion models,” inProc. Int. Conf. Mach. Learn., Baltimore, Maryland, USA, Jul. 2022, pp. 16 784– 16 804
2022
-
[3]
Photorealistic text-to-image diffusion models with deep language understanding,
C. Saharia, W. Chan, S. Saxena, L. Li, J. Whang, E. L. Denton, K. Ghasemipour, R. Gontijo Lopes, B. Karagol Ayan, T. Salimans et al., “Photorealistic text-to-image diffusion models with deep language understanding,” inAdv. Neural Inf. Process. Syst., vol. 35, New Orleans, Louisiana, USA, Nov. 2022, pp. 36 479–36 494
2022
-
[4]
Artificial fingerprinting for generative models: Rooting deepfake attribution in training data,
N. Yu, V . Skripniuk, S. Abdelnabi, and M. Fritz, “Artificial fingerprinting for generative models: Rooting deepfake attribution in training data,” in Proc. IEEE/CVF Int. Conf. Comput. Vis., Montreal, QC, Canada, Oct. 2021, pp. 14 448–14 457
2021
-
[5]
Supervised gan watermarking for intellectual property protection,
J. Fei, Z. Xia, B. Tondi, and M. Barni, “Supervised gan watermarking for intellectual property protection,” inProc. IEEE Int. Workshop Inf. Forensics Secur., Shanghai, China, Dec. 2022, pp. 1–6
2022
-
[6]
The stable signature: Rooting watermarks in latent diffusion models,
P. Fernandez, G. Couairon, H. J ´egou, M. Douze, and T. Furon, “The stable signature: Rooting watermarks in latent diffusion models,” in Proc. IEEE/CVF Int. Conf. Comput. Vis., Paris, France, Oct. 2023, pp. 22 466–22 477
2023
-
[7]
Wide flat minimum watermark- ing for robust ownership verification of gans,
J. Fei, Z. Xia, B. Tondi, and M. Barni, “Wide flat minimum watermark- ing for robust ownership verification of gans,”IEEE Trans. Inf. Forensics Secur., vol. 19, pp. 8322–8337, Aug. 2024
2024
-
[8]
Robust retraining-free gan fingerprinting via personalized nor- malization,
——, “Robust retraining-free gan fingerprinting via personalized nor- malization,” inProc. IEEE Int. Workshop Inf. Forensics Secur., N¨urnberg, Germany, Dec. 2023, pp. 1–6
2023
-
[9]
Wouaf: Weight modulation for user attribution and fingerprinting in text-to-image diffu- sion models,
C. Kim, K. Min, M. Patel, S. Cheng, and Y . Yang, “Wouaf: Weight modulation for user attribution and fingerprinting in text-to-image diffu- sion models,” inProc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit., Seattle, W A, USA, Jun. 2024, pp. 8974–8983
2024
-
[10]
Responsible disclosure of generative models using scalable fingerprinting,
N. Yu, V . Skripniuk, D. Chen, L. S. Davis, and M. Fritz, “Responsible disclosure of generative models using scalable fingerprinting,” inInt. Conf. Learn. Represent., Virtual, Apr. 2022
2022
-
[11]
Collusion-secure fingerprinting for digital data,
D. Boneh and J. Shaw, “Collusion-secure fingerprinting for digital data,” IEEE Trans. Inf. Theory, vol. 44, no. 5, pp. 1897–1905, 1998
1905
-
[12]
Model soups: averaging weights of multiple fine-tuned models improves accuracy without increasing inference time,
M. Wortsman, G. Ilharco, S. Y . Gadre, R. Roelofs, R. Gontijo-Lopes, A. S. Morcos, H. Namkoong, A. Farhadi, Y . Carmon, S. Kornblith et al., “Model soups: averaging weights of multiple fine-tuned models improves accuracy without increasing inference time,” inProc. Int. Conf. Mach. Learn., Baltimore, Maryland, USA, Jul. 2022, pp. 23 965–23 998
2022
-
[13]
A survey of deep neural network watermarking techniques,
Y . Li, H. Wang, and M. Barni, “A survey of deep neural network watermarking techniques,”Neurocomputing, vol. 461, pp. 171–193, 2021
2021
-
[14]
Deepipr: Deep neural network ownership verification with passports,
L. Fan, K. W. Ng, C. S. Chan, and Q. Yang, “Deepipr: Deep neural network ownership verification with passports,”IEEE Trans. Pattern Anal. Mach. Intell., vol. 44, no. 10, pp. 6122–6139, 2021
2021
-
[15]
Deep model intellectual property protection via deep watermarking,
J. Zhang, D. Chen, J. Liao, W. Zhang, H. Feng, G. Hua, and N. Yu, “Deep model intellectual property protection via deep watermarking,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 44, no. 8, pp. 4005–4020, 2021
2021
-
[16]
Fedipr: Ownership verification for federated deep neural network models,
B. Li, L. Fan, H. Gu, J. Li, and Q. Yang, “Fedipr: Ownership verification for federated deep neural network models,”IEEE Trans. Pattern Anal. Mach. Intell., vol. 45, no. 4, pp. 4521–4536, 2022
2022
-
[17]
A recipe for watermarking diffusion models,
Y . Zhao, T. Pang, C. Du, X. Yang, N.-M. Cheung, and M. Lin, “A recipe for watermarking diffusion models,” arXiv:2303.10137, 2023, online: https://arxiv.org/abs/2303.10137
arXiv 2023
-
[18]
Watermarking for stable diffusion models,
Z. Yuan, L. Li, Z. Wang, and X. Zhang, “Watermarking for stable diffusion models,”IEEE Internet of Things Journal, vol. 11, no. 21, pp. 35 238–35 249, 2024
2024
-
[19]
Hiding images within images,
S. Baluja, “Hiding images within images,”IEEE Trans. Pattern Anal. Mach. Intell., vol. 42, no. 7, pp. 1685–1697, 2019
2019
-
[20]
A cyclegan watermarking method for ownership verification,
D. Lin, B. Tondi, B. Li, and M. Barni, “A cyclegan watermarking method for ownership verification,”IEEE Trans. Dependable Secure Comput., vol. 22, pp. 1040–1054, 2025
2025
-
[21]
Robust model watermarking for image processing networks via structure consistency,
J. Zhang, D. Chen, J. Liao, Z. Ma, H. Fang, W. Zhang, H. Feng, G. Hua, and N. Yu, “Robust model watermarking for image processing networks via structure consistency,”IEEE Trans. Pattern Anal. Mach. Intell., vol. 46, no. 10, pp. 6985–6992, 2024
2024
-
[22]
A watermark-conditioned diffusion model for ip protection,
R. Min, S. Li, H. Chen, and M. Cheng, “A watermark-conditioned diffusion model for ip protection,” inProc. Eur. Conf. Comput. Vis. Malm¨o, Sweden: Springer, Sep. 2024, pp. 104–120
2024
-
[23]
Aqualora: Toward white-box protection for customized stable diffusion models via watermark lora,
W. Feng, W. Zhou, J. He, J. Zhang, T. Wei, G. Li, T. Zhang, W. Zhang, and N. Yu, “Aqualora: Toward white-box protection for customized stable diffusion models via watermark lora,” inProc. Int. Conf. Mach. Learn., Vienna, Austria, Jul. 2024, pp. 13 423–13 444
2024
-
[24]
Waterf: Robust watermarks in radiance fields for protection of copyrights,
Y . Jang, D. I. Lee, M. Jang, J. W. Kim, F. Yang, and S. Kim, “Waterf: Robust watermarks in radiance fields for protection of copyrights,” in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit., Seattle, W A, USA, Jun. 2024, pp. 12 087–12 097. 17
2024
-
[25]
Protecting nerfs’ copyright via plug-and-play watermarking base model,
Q. Song, Z. Luo, K. C. Cheung, S. See, and R. Wan, “Protecting nerfs’ copyright via plug-and-play watermarking base model,” inProc. Eur. Conf. Comput. Vis., Milan, Italy, Sep. 2024, pp. 57–73
2024
-
[26]
The nerf signature: Codebook-aided watermarking for neural radiance fields,
Z. Luo, A. Rocha, B. Shi, Q. Guo, H. Li, and R. Wan, “The nerf signature: Codebook-aided watermarking for neural radiance fields,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 47, pp. 4652–4667, 2025
2025
-
[27]
Digital media fingerprinting: Techniques and trends,
W. Luh and D. Kundur, “Digital media fingerprinting: Techniques and trends,” inMultimedia Encryption and Authentication Techniques and Applications. Boca Raton, FL: Auerbach Publications, 2006, pp. 215– 241
2006
-
[28]
Omnimark: Efficient and scalable latent diffusion model fingerprinting,
J. Fei, Y . Dai, Z. Xia, F. Huang, and J. Zhou, “Omnimark: Efficient and scalable latent diffusion model fingerprinting,” inProc. AAAI Conf. Artif. Intell., vol. 39, no. 16, Pennsylvania, USA, Feb. 2025, pp. 16 550– 16 558
2025
-
[29]
Scalable dual fingerprinting for hierarchical attribution of text-to-image models,
J. Fei, Y . Dai, P. Yu, Z. Kong, J. Zhou, and Z. Xia, “Scalable dual fingerprinting for hierarchical attribution of text-to-image models,” in Proc. IEEE/CVF Int. Conf. Comput. Vis., Honolulu, Hawaii, Oct. 2025, pp. 15 025–15 034
2025
-
[30]
A style-based generator architecture for generative adversarial networks,
T. Karras, S. Laine, and T. Aila, “A style-based generator architecture for generative adversarial networks,”IEEE Trans. Pattern Anal. Mach. Intell., vol. 43, no. 12, pp. 4217–4228, 2021
2021
-
[31]
Optimal collusion attack for digital fingerprinting,
H. Feng, H. Ling, F. Zou, W. Yan, and Z. Lu, “Optimal collusion attack for digital fingerprinting,” inProc. ACM Int. Conf. Multimedia, Firenze, Italy, Oct. 2010, pp. 767–770
2010
-
[32]
Forensic analysis of nonlinear collusion attacks for multimedia fingerprinting,
H. V . Zhao, M. Wu, Z. J. Wang, and K. R. Liu, “Forensic analysis of nonlinear collusion attacks for multimedia fingerprinting,”IEEE Trans. Image Process., vol. 14, no. 5, pp. 646–661, 2005
2005
-
[33]
Collusion-resistant fingerprinting for multimedia,
M. Wu, W. Trappe, Z. J. Wang, and K. R. Liu, “Collusion-resistant fingerprinting for multimedia,”IEEE Signal Process. Mag., vol. 21, no. 2, pp. 15–27, 2004
2004
-
[34]
Tally-based simple decoders for traitor tracing and group testing,
B. ˇSkori´c, “Tally-based simple decoders for traitor tracing and group testing,”IEEE Trans. Inf. Forensics Secur., vol. 10, no. 6, pp. 1221– 1233, 2015
2015
-
[35]
Dnn watermarking: Four challenges and a funeral,
M. Barni, F. P ´erez-Gonz´alez, and B. Tondi, “Dnn watermarking: Four challenges and a funeral,” inProc. ACM Workshop Inf. Hiding Multi- media Secur., online, Jun. 2021, pp. 189–196
2021
-
[36]
Denoising diffusion probabilistic models,
J. Ho, A. Jain, and P. Abbeel, “Denoising diffusion probabilistic models,” Adv. Neural Inf. Process. Syst., vol. 33, pp. 6840–6851, Dec. 2020
2020
-
[37]
Diffusion models in vision: A survey,
F.-A. Croitoru, V . Hondru, R. T. Ionescu, and M. Shah, “Diffusion models in vision: A survey,”IEEE Trans. Pattern Anal. Mach. Intell., vol. 45, no. 9, pp. 10 850–10 869, 2023
2023
-
[38]
Adding conditional control to text-to-image diffusion models,
L. Zhang, A. Rao, and M. Agrawala, “Adding conditional control to text-to-image diffusion models,” inProc. IEEE/CVF Int. Conf. Comput. Vis., Paris, France, Oct. 2023, pp. 3836–3847
2023
-
[39]
T2i- adapter: Learning adapters to dig out more controllable ability for text- to-image diffusion models,
C. Mou, X. Wang, L. Xie, Y . Wu, J. Zhang, Z. Qi, and Y . Shan, “T2i- adapter: Learning adapters to dig out more controllable ability for text- to-image diffusion models,” inProc. AAAI Conf. Artif. Intell., vol. 38, no. 5, Vancouver, Canada, Feb. 2024, pp. 4296–4304
2024
-
[40]
Score-based generative modeling through stochastic differ- ential equations,
Y . Song, J. Sohl-Dickstein, D. P. Kingma, A. Kumar, S. Ermon, and B. Poole, “Score-based generative modeling through stochastic differ- ential equations,” inInt. Conf. Learn. Represent., Vienna, Austria, May 2021
2021
-
[41]
Cascaded diffusion models for high fidelity image generation,
J. Ho, C. Saharia, W. Chan, D. J. Fleet, M. Norouzi, and T. Salimans, “Cascaded diffusion models for high fidelity image generation,”J. Mach. Learn. Res., vol. 23, no. 47, pp. 1–33, 2022
2022
-
[42]
Renaissance: A survey into ai text-to-image generation in the era of large model,
F. Bie, Y . Yang, Z. Zhou, A. Ghanem, M. Zhang, Z. Yao, X. Wu, C. Holmes, P. Golnari, D. A. Cliftonet al., “Renaissance: A survey into ai text-to-image generation in the era of large model,”IEEE Trans. Pattern Anal. Mach. Intell., vol. 47, pp. 2212–2231, 2024
2024
-
[43]
Sdxl: Improving latent diffusion models for high-resolution image synthesis,
D. Podell, Z. English, K. Lacey, A. Blattmann, T. Dockhorn, J. M ¨uller, J. Penna, and R. Rombach, “Sdxl: Improving latent diffusion models for high-resolution image synthesis,” inInt. Conf. Learn. Represent., Vienna, Austria, May 2024
2024
-
[44]
Scalable diffusion models with transformers,
W. Peebles and S. Xie, “Scalable diffusion models with transformers,” inProc. IEEE/CVF Int. Conf. Comput. Vis., Paris, France, Oct. 2023, pp. 4195–4205
2023
-
[45]
stabilityai/sd-vae-ft-mse-original,
S. AI, “stabilityai/sd-vae-ft-mse-original,” https://huggingface.co/ stabilityai/sd-vae-ft-mse-original, Aug. 2024, [Online]. Available: https://huggingface.co/stabilityai/sd-vae-ft-mse-original
2024
-
[46]
The unreasonable effectiveness of deep features as a perceptual metric,
R. Zhang, P. Isola, A. A. Efros, E. Shechtman, and O. Wang, “The unreasonable effectiveness of deep features as a perceptual metric,” in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit., Salt Lake City, UT, USA, Jun. 2018, pp. 586–595
2018
-
[47]
Autoencoding beyond pixels using a learned similarity metric,
A. B. L. Larsen, S. K. Sønderby, H. Larochelle, and O. Winther, “Autoencoding beyond pixels using a learned similarity metric,” inProc. Int. Conf. Mach. Learn., New York City, NY , USA, Jun. 2016, pp. 1558– 1566
2016
-
[48]
Generating images with perceptual simi- larity metrics based on deep networks,
A. Dosovitskiy and T. Brox, “Generating images with perceptual simi- larity metrics based on deep networks,”Adv. Neural Inf. Process. Syst., vol. 29, Dec. 2016
2016
-
[49]
Loss surfaces, mode connectivity, and fast ensembling of dnns,
T. Garipov, P. Izmailov, D. Podoprikhin, D. P. Vetrov, and A. G. Wilson, “Loss surfaces, mode connectivity, and fast ensembling of dnns,”Adv. Neural Inf. Process. Syst., vol. 31, Dec. 2018
2018
-
[50]
Essentially no barriers in neural network energy landscape,
F. Draxler, K. Veschgini, M. Salmhofer, and F. Hamprecht, “Essentially no barriers in neural network energy landscape,” inInt. Conf. Mach. Learn., Vienna, Austria, Jul. 2018, pp. 1309–1318
2018
-
[51]
Averaging weights leads to wider optima and better generalization,
P. Izmailov, A. Wilson, D. Podoprikhin, D. Vetrov, and T. Garipov, “Averaging weights leads to wider optima and better generalization,” in Conf. Uncertain. Artif. Intell., Monterey, California, USA, Aug. 2018, pp. 876–885
2018
-
[52]
Microsoft coco: Common objects in context,
T.-Y . Lin, M. Maire, S. Belongie, J. Hays, P. Perona, D. Ramanan, P. Doll ´ar, and C. L. Zitnick, “Microsoft coco: Common objects in context,” inProc. Eur. Conf. Comput. Vis., Zurich, Switzerland, Sep. 2014, pp. 740–755
2014
-
[53]
Imagenet large scale visual recognition challenge,
O. Russakovsky, J. Deng, H. Su, J. Krause, S. Satheesh, S. Ma, Z. Huang, A. Karpathy, A. Khosla, M. Bernstein, A. C. Berg, and L. Fei- Fei, “Imagenet large scale visual recognition challenge,”Int. J. Comput. Vis., vol. 115, no. 3, pp. 211–252, 2015
2015
-
[54]
Magicbrush: A manually annotated dataset for instruction-guided image editing,
K. Zhang, L. Mo, W. Chen, H. Sun, and Y . Su, “Magicbrush: A manually annotated dataset for instruction-guided image editing,” inAdv. Neural Inf. Process. Syst., vol. 36, New Orleans, Louisiana, USA, Dec. 2023, pp. 31 428–31 449
2023
-
[55]
Instructpix2pix: Learning to follow image editing instructions,
T. Brooks, A. Holynski, and A. A. Efros, “Instructpix2pix: Learning to follow image editing instructions,” inProc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit., Vancouver, BC, Canada, Jun. 2023, pp. 18 392– 18 402
2023
-
[56]
Rectifier nonlinearities improve neural network acoustic models,
A. L. Maas, A. Y . Hannun, A. Y . Nget al., “Rectifier nonlinearities improve neural network acoustic models,” inProc. Int. Conf. Mach. Learn., vol. 30, no. 1, Atlanta, USA, Jun. 2013, p. 3
2013
-
[57]
Clipscore: A reference-free evaluation metric for image captioning,
J. Hessel, A. Holtzman, M. Forbes, R. Le Bras, and Y . Choi, “Clipscore: A reference-free evaluation metric for image captioning,” inProc. Conf. Empir. Methods Nat. Lang. Process., Punta Cana, Dominican Republic, Nov. 2021, pp. 7514–7528
2021
-
[58]
Optimal probabilistic fingerprint codes,
G. Tardos, “Optimal probabilistic fingerprint codes,”J. ACM, vol. 55, no. 2, pp. 1–24, 2008
2008
-
[59]
Learned image com- pression with discretized gaussian mixture likelihoods and attention modules,
Z. Cheng, H. Sun, M. Takeuchi, and J. Katto, “Learned image com- pression with discretized gaussian mixture likelihoods and attention modules,” inProc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit., Jun. 2020, pp. 7939–7948
2020
-
[60]
Variational image compression with a scale hyperprior,
J. Ball ´e, D. Minnen, S. Singh, S. J. Hwang, and N. Johnston, “Variational image compression with a scale hyperprior,” inProc. Int. Conf. Learn. Represent., Vancouver, BC, Canada, Apr. 2018
2018
-
[61]
Visualizing the loss landscape of neural nets,
H. Li, Z. Xu, G. Taylor, C. Studer, and T. Goldstein, “Visualizing the loss landscape of neural nets,”Adv. Neural Inf. Process. Syst., vol. 31, p. 6391–6401, Dec. 2018
2018
-
[62]
Scaling rectified flow transformers for high-resolution image synthesis,
P. Esser, S. Kulal, A. Blattmann, R. Entezari, J. M ¨uller, H. Saini, Y . Levi, D. Lorenz, A. Sauer, F. Boeselet al., “Scaling rectified flow transformers for high-resolution image synthesis,” inInt. Conf. Mach. Learn., Vienna, Austria, Jul. 2024, p. 28
2024
-
[63]
Open-sora: Democratizing efficient video production for all,
Z. Zheng, X. Peng, T. Yang, C. Shen, S. Li, H. Liu, Y . Zhou, T. Li, and Y . You, “Open-sora: Democratizing efficient video production for all,” arXiv preprint arXiv:2412.20404, 2024
Pith/arXiv arXiv 2024
-
[64]
Dreambooth: Fine tuning text-to-image diffusion models for subject- driven generation,
N. Ruiz, Y . Li, V . Jampani, Y . Pritch, M. Rubinstein, and K. Aberman, “Dreambooth: Fine tuning text-to-image diffusion models for subject- driven generation,” inProc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit., Vancouver, BC, Canada, Jun. 2023, pp. 22 500–22 510
2023
-
[65]
F. J. MacWilliams and N. J. A. Sloane,The theory of error-correcting codes. Elsevier, 1977, vol. 16. Jianwei Fei(Member, IEEE) received the Ph.D. degree in information security from Nanjing Uni- versity of Information Science and Technology in
1977
-
[66]
He is currently a Post-Doctoral Fellow at the University of Florence, Italy
From 2024 to 2025, he was a Post-Doctoral Fellow at the University of Macau. He is currently a Post-Doctoral Fellow at the University of Florence, Italy. His research interests include the security of generative AI, proactive and passive attribution of generative models, and digital forensics. 18 Yunshu Dai(Student Member, IEEE) is currently pursuing the ...
2024
-
[67]
Efficient, Robust, and Anti-Collusion Fingerprinting of Image Diffusion Models
He serves as a managing editor for IJAACS. His research interests include AI security, cloud computing security, and digital forensics. He has been a member of the IEEE since Mar. 1, 2014. Xiaochun Cao(Senior Member, IEEE) received the B.E. and M.E. degrees in computer science from Beihang University (BUAA), China, and the Ph.D. degree in computer science...
2014
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.