Mod-Guide: An LLM-based Content Moderation Feedback System to Address Insensitive Speech toward Indigenous Ethnic and Religious Minority Communities
Pith reviewed 2026-06-27 05:39 UTC · model grok-4.3
The pith
Integrating community co-created examples via RAG makes LLM moderation responses more contextually accurate for insensitive speech toward minority groups.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper claims that co-creating a culturally grounded corpus of insensitive speech examples with community members and integrating their narratives into LLM moderation via retrieval augmented generation allows the Mod-Guide tool to generate feedback that is more sensitive to the cultural and religious perspectives of minority communities, resulting in responses that evaluations show are more contextually accurate and perceived differently by minority versus majority participants.
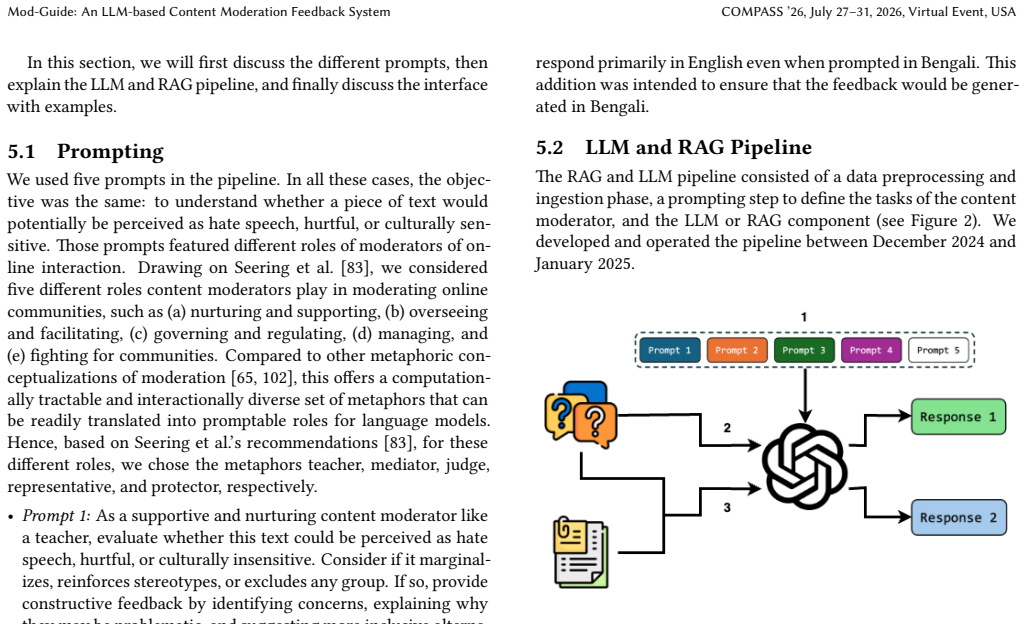
What carries the argument
Retrieval augmented generation pipeline that pulls contextual cues from a community co-created corpus of insensitive speech to guide LLM moderation feedback.
If this is right
- Moderation systems become more responsive to implicit cultural harms such as erasure and normative framing.
- Perceptions of moderation feedback differ systematically between minority and majority community members.
- Content moderation can incorporate principles of restorative justice by drawing on community-sourced narratives.
- LLM limitations in handling minority viewpoints can be addressed through targeted retrieval of lived-experience context.
Where Pith is reading between the lines
- The co-creation approach could be adapted to moderation tasks involving other minority groups or languages beyond the Bangladesh context.
- Similar RAG augmentation might reduce epistemic gaps in AI systems used for other culturally sensitive decisions.
- Scaling the method would require testing whether larger corpora maintain fidelity to original community input.
Load-bearing premise
The co-created corpus of insensitive speech examples accurately and representatively captures the cultural and religious perspectives of the minority communities without selection or framing bias.
What would settle it
Evaluations in which RAG-enhanced moderation responses show no improvement in contextual accuracy ratings or no difference in perception between minority and majority participants compared to standard LLM responses.
Figures



read the original abstract
Language operates as a mechanism of both marginalization and resistance, especially for minority communities navigating insensitive and harmful speech online. As content moderation increasingly depends on large language models (LLMs), concerns arise about whether these systems can recognize culturally insensitive speech-language that disregards or marginalizes the cultural and religious perspectives of historically underrepresented communities, often through implicit erasure, misrepresentation, or normative framing, rather than overt hostility. Focusing on Bangladesh's Hindu and Chakma communities -- the country's largest religious and Indigenous ethnic minorities, respectively -- this paper investigates the epistemic limits of LLM-based moderation systems and explores methods for incorporating minority perspectives. We co-created a culturally grounded corpus of insensitive speech with community members and integrated their narratives into moderation pipelines using retrieval augmented generation (RAG). Our tool, Mod-Guide, improves LLM sensitivity to minority viewpoints by leveraging contextual cues derived from lived experience. Through mixed-method evaluations involving both minority and majority participants, we demonstrate that RAG-enhanced moderation responses are more contextually accurate and perceived differently across ethnic lines. This work advances research in human-computer interaction, AI ethics, and social computing by foregrounding restorative justice and hermeneutical inclusion in the design of content moderation systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to develop Mod-Guide, an LLM-based content moderation feedback system that uses retrieval augmented generation (RAG) to incorporate culturally grounded perspectives from Bangladesh's Hindu and Chakma communities. It describes co-creating a corpus of insensitive speech examples with community members and integrating their narratives into moderation pipelines. Through mixed-method evaluations involving both minority and majority participants, the work asserts that RAG-enhanced responses are more contextually accurate and perceived differently across ethnic lines, advancing HCI, AI ethics, and social computing via restorative justice and hermeneutical inclusion.
Significance. If the empirical results hold, the work has potential significance for designing culturally sensitive AI moderation tools that foreground minority perspectives, with the co-creation approach and mixed-method design offering a participatory angle relevant to HCI. The emphasis on epistemic limits of LLMs for implicit cultural erasure is a timely contribution. However, the absence of any quantitative metrics, baselines, or measurement details in the abstract limits assessment of practical impact or generalizability.
major comments (1)
- [Abstract] Abstract: The central claim that RAG-enhanced moderation responses are more contextually accurate and perceived differently across ethnic lines provides no quantitative metrics, error bars, baseline comparisons, or details on how accuracy or perception differences were measured. This prevents evaluation of the soundness of the mixed-method results that support the paper's primary contribution.
Simulated Author's Rebuttal
We thank the referee for their review. We address the single major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that RAG-enhanced moderation responses are more contextually accurate and perceived differently across ethnic lines provides no quantitative metrics, error bars, baseline comparisons, or details on how accuracy or perception differences were measured. This prevents evaluation of the soundness of the mixed-method results that support the paper's primary contribution.
Authors: We agree that the abstract, as currently written, does not include quantitative metrics or measurement details. The body of the manuscript describes the mixed-method evaluation, including participant ratings for contextual accuracy and perception differences across ethnic groups. We will revise the abstract to add a concise summary of the key quantitative findings and evaluation approach so that the primary claims can be assessed from the abstract alone. revision: yes
Circularity Check
No significant circularity
full rationale
This is an empirical HCI/systems paper with no mathematical derivations, fitted parameters, or predictive claims that reduce to inputs by construction. The core contribution is a RAG-based moderation tool evaluated through mixed-method user studies with minority and majority participants; claims about contextual accuracy rest on those external evaluations rather than self-definition, self-citation load-bearing, or renamed known results. No load-bearing steps match the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Community members can identify and articulate instances of insensitive speech that reflect their cultural and religious perspectives
invented entities (1)
-
Mod-Guide
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Ahmed Agiza, Mohamed Mostagir, and Sherief Reda. 2024. Politune: Analyzing the impact of data selection and fine-tuning on economic and political biases in large language models. In Proceedings of the AAAI/ACM Conference on AI, Ethics, and Society , Vol. 7. 2–12
2024
-
[2]
Syed Ishtiaque Ahmed. 2022. Situating ethics: A postsecular perspective for HCI. Interactions 29, 4 (2022), 84–86
2022
-
[3]
Syed Ishtiaque Ahmed. 2022. Whose intelligence? Whose ethics?: Eth- ical pluralism and decolonizing AI. https://www.youtube.com/watch?v= ReSbgRSJ4WY. last accessed: Feb 22, 2025
2022
-
[4]
Chris Allen. 2016. Islamophobia. Routledge
2016
-
[5]
The Prothom Alo. 2024. 5–20 August: 1068 minority homes and businesses attacked (translated). https://www.prothomalo.com/bangladesh/6bm2lfn7bz. last accessed: Feb 21, 2025
2024
-
[6]
Tahmima Anam. 2013. Pakistan’s State of Denial. https://www.nytimes.com/ 2013/12/27/opinion/anam-pakistans-overdue-apology.html . Last accessed: July 7, 2023
2013
-
[7]
Arjun Appadurai. 2015. Fear of Small Numbers. Writing Religion: The Case for the Critical Study of Religion (2015), 73–95
2015
-
[8]
Mina Arzaghi, Florian Carichon, and Golnoosh Farnadi. 2024. Understanding Intrinsic Socioeconomic Biases in Large Language Models. In Proceedings of the AAAI/ACM Conference on AI, Ethics, and Society , Vol. 7. 49–60
2024
-
[9]
Anne Arzberger, Stefan Buijsman, Maria Luce Lupetti, Alessandro Bozzon, and Jie Yang. 2024. Nothing Comes Without Its World–Practical Challenges of Aligning LLMs to Situated Human Values through RLHF. In Proceedings of the AAAI/ACM Conference on AI, Ethics, and Society , Vol. 7. 61–73
2024
-
[10]
Jack Bandy. 2021. Problematic machine behavior: A systematic literature re- view of algorithm audits. Proceedings of the acm on human-computer interaction 5, CSCW1 (2021), 1–34
2021
-
[11]
Emily M Bender, Timnit Gebru, Angelina McMillan-Major, and Shmargaret Shmitchell. 2021. On the dangers of stochastic parrots: Can language models be too big?. In Proceedings of the 2021 ACM conference on fairness, accountability, and transparency. 610–623
2021
-
[12]
Robert Bowman, Camille Nadal, Kellie Morrissey, Anja Thieme, and Gavin Do- herty. 2023. Using thematic analysis in healthcare HCI at CHI: A scoping re- view. In Proceedings of the 2023 CHI Conference on Human Factors in Computing Systems. 1–18
2023
-
[13]
Venetia Brown, Retno Larasati, Aisling Third, and Tracie Farrell. 2024. A Qual- itative Study on Cultural Hegemony and the Impacts of AI. In Proceedings of the AAAI/ACM Conference on AI, Ethics, and Society , Vol. 7. 226–238
2024
-
[14]
Bangladesh Statistics Bureau BSB. 2022. Preliminary Report on Population and Housing Census 2022 : English Version. https://sid.portal.gov.bd/ Mod-Guide: An LLM-based Content Moderation Feedback System COMPASS ’26, July 27–31, 2026, Virtual Event, USA sites/default/files/files/sid.portal.gov.bd/publications/01ad1ffe_cfef_4811_ af97_594b6c64d7c3/PHC_Prelim...
2022
-
[15]
Judith Butler. 2021. Excitable speech: A politics of the performative . routledge
2021
-
[16]
Bhumitra Chakma. 2008. Assessing the 1997 Chittagong hill tracts peace accord. Asian Profile 36, 1 (2008), 93
2008
-
[17]
Bhumitra Chakma. 2010. The post-colonial state and minorities: ethnocide in the Chittagong Hill Tracts, Bangladesh. Commonwealth & comparative politics 48, 3 (2010), 281–300
2010
-
[18]
Jiawei Chen, Hongyu Lin, Xianpei Han, and Le Sun. 2024. Benchmarking large language models in retrieval-augmented generation. In Proceedings of the AAAI Conference on Artificial Intelligence, Vol. 38. 17754–17762
2024
-
[19]
Robert A Cummins and Eleonora Gullone. 2000. Why we should not use 5-point Likert scales: The case for subjective quality of life measurement. In Proceed- ings, second international conference on quality of life in cities , Vol. 74. 74–93
2000
-
[20]
Colonial Impulse
Dipto Das, Shion Guha, Jed R Brubaker, and Bryan Semaan. 2024. The“Colonial Impulse” of Natural Language Processing: An Audit of Bengali Sentiment Anal- ysis Tools and Their Identity-based Biases. In Proceedings of the 2024 CHI Con- ference on Human Factors in Computing Systems . 1–18
2024
-
[21]
Dipto Das, Carsten Østerlund, and Bryan Semaan. 2021. ” Jol” or” Pani”?: How Does Governance Shape a Platform’s Identity? Proceedings of the ACM on Human-Computer Interaction 5, CSCW2 (2021), 1–25
2021
-
[22]
William Edward Burghardt Du Bois. 2015. Souls of black folk . Routledge
2015
-
[23]
Upol Ehsan, Q Vera Liao, Michael Muller, Mark O Riedl, and Justin D Weisz
-
[24]
In Proceedings of the 2021 CHI conference on human factors in computing systems
Expanding explainability: Towards social transparency in ai systems. In Proceedings of the 2021 CHI conference on human factors in computing systems . 1–19
2021
-
[25]
Upol Ehsan and Mark O Riedl. 2020. Human-centered explainable ai: Towards a reflective sociotechnical approach. In International Conference on Human- Computer Interaction. Springer, 449–466
2020
-
[26]
Sheena Erete, Aarti Israni, and Tawanna Dillahunt. 2018. An intersectional approach to designing in the margins. Interactions 25, 3 (2018), 66–69
2018
-
[27]
Ilker Etikan, Sulaiman Abubakar Musa, Rukayya Sunusi Alkassim, et al. 2016. Comparison of convenience sampling and purposive sampling. American jour- nal of theoretical and applied statistics 5, 1 (2016), 1–4
2016
-
[28]
Agence France-Presse. 2015. American atheist blogger hacked to death in Bangladesh — theguardian.com. https://www.theguardian.com/world/2015/ feb/27/american-atheist-blogger-hacked-to-death-in-bangladesh . Last ac- cessed July 7, 2023
2015
-
[29]
Miranda Fricker. 2007. Epistemic injustice: Power and the ethics of knowing . Oxford University Press
2007
-
[30]
Batya Friedman and Helen Nissenbaum. 1996. Bias in computer systems. ACM Transactions on information systems (TOIS) 14, 3 (1996), 330–347
1996
-
[31]
Sumit Ganguly. 2021. Bangladesh’s Deadly Identity Crisis. https: //foreignpolicy.com/2021/10/29/bangladesh-communal-violence-hindu- muslim-identity-crisis/ . Last accessed: July 7, 2023
2021
-
[32]
Sourojit Ghosh. 2024. Interpretations, Representations, and Stereotypes of Caste within Text-to-Image Generators. In Proceedings of the AAAI/ACM Con- ference on AI, Ethics, and Society , Vol. 7. 490–502
2024
-
[33]
Sourojit Ghosh and Aylin Caliskan. 2023. Chatgpt perpetuates gender bias in machine translation and ignores non-gendered pronouns: Findings across bengali and five other low-resource languages. In Proceedings of the 2023 AAAI/ACM Conference on AI, Ethics, and Society . 901–912
2023
-
[34]
Sourojit Ghosh and Aylin Caliskan. 2023. ’Person’== Light-skinned, Western Man, and Sexualization of Women of Color: Stereotypes in Stable Diffusion. arXiv preprint arXiv:2310.19981 (2023)
arXiv 2023
-
[35]
Sourojit Ghosh, Pranav Narayanan Venkit, Sanjana Gautam, Shomir Wilson, and Aylin Caliskan. 2024. Do Generative AI Models Output Harm while Rep- resenting Non-Western Cultures: Evidence from A Community-Centered Ap- proach. In Proceedings of the AAAI/ACM Conference on AI, Ethics, and Society , Vol. 7. 476–489
2024
-
[36]
E. Goffman. 2009. Stigma: Notes on the Management of Spoiled Identity . Touch- stone
2009
-
[37]
Kimia Hamidieh, Haoran Zhang, Walter Gerych, Thomas Hartvigsen, and Marzyeh Ghassemi. 2024. Identifying implicit social biases in vision-language models. In Proceedings of the AAAI/ACM Conference on AI, Ethics, and Society , Vol. 7. 547–561
2024
-
[38]
David Hartmann, Amin Oueslati, and Dimitri Staufer. 2024. Watching the Watchers: A Comparative Fairness Audit of Cloud-based Content Moderation Services. arXiv preprint arXiv:2406.14154 (2024)
arXiv 2024
-
[39]
Mubashar Hasan. 2021. Minorities under attack in Bangladesh. https://www. lowyinstitute.org/the-interpreter/minorities-under-attack-bangladesh . Last accessed: July 7, 2023
2021
-
[40]
Emma Heywood, Beatrice Ivey, and Sacha Meuter. 2024. Reaching hard-to- reach communities: using WhatsApp to give conflict-affected audiences a voice. International Journal of Social Research Methodology 27, 1 (2024), 107–121
2024
-
[41]
Glen Hill and Kabita Chakma. 2022. Muscular nationalism, masculinist mili- tarism: the creation of situational motivators and opportunities for violence against the Indigenous peoples of the Chittagong Hill Tracts, Bangladesh. In- ternational Feminist Journal of Politics 24, 4 (2022), 519–543
2022
-
[42]
Robert R Hoffman, Shane T Mueller, Gary Klein, and Jordan Litman. 2018. Metrics for explainable AI: Challenges and prospects. arXiv preprint arXiv:1812.04608 (2018)
Pith/arXiv arXiv 2018
-
[43]
Sedat İnan, Hasan Çetin, and Nurettin Yakupoğlu. 2024. Spring water anom- alies before two consecutive earthquakes (M w 7.7 and M w 7.6) in Kahraman- maraş (Türkiye) on 6 February 2023. Natural Hazards and Earth System Sciences 24, 2 (2024), 397–409
2024
-
[44]
Amnesty International. 2021. Bangladesh: Protection of Hindus and others must be ensured amid ongoing violence. https://www.amnesty.org/en/ latest/news/2021/10/bangladesh-protection-of-hindus-and-others-must-be- ensured-amid-ongoing-violence/ . Last accessed: July 7, 2023
2021
-
[45]
Minority Rights Group International. 2018. Christians. https://minorityrights. org/minorities/christians-6/. Last accessed: July 7, 2023
2018
-
[46]
The Daily Ittefaq. 2014. Attacks on minorities continue. https: //web.archive.org/web/20140110191737/http://www.clickittefaq.com/more- stories/attacks-minorities-continue/ . Last accessed: July 7, 2023
arXiv 2014
-
[47]
Gautier Izacard and Edouard Grave. 2020. Leveraging passage retrieval with generative models for open domain question answering. arXiv preprint arXiv:2007.01282 (2020)
Pith/arXiv arXiv 2020
-
[48]
Shagun Jhaver, Iris Birman, Eric Gilbert, and Amy Bruckman. 2019. Human- machine collaboration for content regulation: The case of reddit automoderator. ACM Transactions on Computer-Human Interaction (TOCHI) 26, 5 (2019), 1–35
2019
-
[49]
Shagun Jhaver, Quan Ze Chen, Detlef Knauss, and Amy X Zhang. 2022. De- signing word filter tools for creator-led comment moderation. In Proceedings of the 2022 CHI conference on human factors in computing systems . 1–21
2022
-
[50]
Jialun Aaron Jiang, Peipei Nie, Jed R Brubaker, and Casey Fiesler. 2023. A trade- off-centered framework of content moderation.ACM Transactions on Computer- Human Interaction 30, 1 (2023), 1–34
2023
-
[51]
Jialun Aaron Jiang, Morgan Klaus Scheuerman, Casey Fiesler, and Jed R Brubaker. 2021. Understanding international perceptions of the severity of harmful content online. PloS one 16, 8 (2021), e0256762
2021
-
[52]
Hellen Koka, Solomon Langat, Francis Mulwa, James Mutisya, Samuel Owaka, Millicent Sifuna, Juliette R Ongus, Joel Lutomiah, and Rosemary Sang. 2024. Combining Morphological and Molecular Tools Can Enhance Tick Species Iden- tification for Improved Tick-Borne Disease Surveillance Among Pastoral Com- munities in Kenya. Vector-Borne and Zoonotic Diseases (2024)
2024
-
[53]
Mahi Kolla, Siddharth Salunkhe, Eshwar Chandrasekharan, and Koustuv Saha
-
[54]
In Ex- tended Abstracts of the CHI Conference on Human Factors in Computing Systems
Llm-mod: Can large language models assist content moderation?. In Ex- tended Abstracts of the CHI Conference on Human Factors in Computing Systems . 1–8
-
[55]
Shanu Kumar, Gauri Kholkar, Saish Mendke, Anubhav Sadana, Parag Agrawal, and Sandipan Dandapat. 2024. Socio-Culturally Aware Evaluation Framework for LLM-Based Content Moderation. arXiv preprint arXiv:2412.13578 (2024)
arXiv 2024
-
[56]
Louis Kwok, Michal Bravansky, and Lewis D Griffin. 2024. Evaluating cultural adaptability of a large language model via simulation of synthetic personas. arXiv preprint arXiv:2408.06929 (2024)
arXiv 2024
-
[57]
George Lakoff. 2007. Cognitive models and prototype theory. The cognitive linguistics reader (2007), 130–167
2007
-
[58]
Michelle S Lam, Mitchell L Gordon, Danaë Metaxa, Jeffrey T Hancock, James A Landay, and Michael S Bernstein. 2022. End-user audits: A system empowering communities to lead large-scale investigations of harmful algorithmic behavior. Proceedings of the ACM on Human-Computer Interaction6, CSCW2 (2022), 1–34
2022
-
[59]
Erika Lee. 2019. America for Americans: A history of xenophobia in the United States. Basic Books
2019
-
[60]
Maxyn Leitner, Rebecca Dorn, Fred Morstatter, and Kristina Lerman. 2025. Characterizing Network Structure of Anti-Trans Actors on TikTok. arXiv preprint arXiv:2501.16507 (2025)
arXiv 2025
-
[61]
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, et al. 2020. Retrieval-augmented generation for knowledge- intensive nlp tasks. Advances in neural information processing systems 33 (2020), 9459–9474
2020
-
[62]
Tianlin Li, Xiaoyu Zhang, Chao Du, Tianyu Pang, Qian Liu, Qing Guo, Chao Shen, and Yang Liu. 2024. Your large language model is secretly a fairness proponent and you should prompt it like one. arXiv preprint arXiv:2402.12150 (2024)
arXiv 2024
-
[63]
Calvin A Liang, Sean A Munson, and Julie A Kientz. 2021. Embracing four tensions in human-computer interaction research with marginalized people. ACM Transactions on Computer-Human Interaction (TOCHI) 28, 2 (2021), 1–47
2021
-
[64]
Haley MacLeod, Grace Bastin, Leslie S Liu, Katie Siek, and Kay Connelly. 2017. ” Be Grateful You Don’t Have a Real Disease” Understanding Rare Disease Rela- tionships. In Proceedings of the 2017 CHI Conference on Human Factors in Com- puting Systems. 1660–1673
2017
-
[65]
Haley MacLeod, Ben Jelen, Annu Prabhakar, Lora Oehlberg, Katie A Siek, and Kay Connelly. 2016. Asynchronous remote communities (ARC) for researching COMPASS ’26, July 27–31, 2026, Virtual Event, USA Das, Sultana, Chauhan, Alam, Shidujaman, Guha, Chakraborty, and Ahmed distributed populations.. In PervasiveHealth. 1–8
2016
-
[66]
Juan F Maestre, Haley MacLeod, Ciabhan L Connelly, Julia C Dunbar, Jordan Beck, Katie A Siek, and Patrick C Shih. 2018. Defining through expansion: conducting asynchronous remote communities (arc) research with stigmatized groups. In Proceedings of the 2018 CHI Conference on Human Factors in Comput- ing Systems. 1–13
2018
-
[67]
J Nathan Matias. 2019. The civic labor of volunteer moderators online. Social Media+ Society 5, 2 (2019), 2056305119836778
2019
-
[68]
Nora McDonald, Sarita Schoenebeck, and Andrea Forte. 2019. Reliability and inter-rater reliability in qualitative research: Norms and guidelines for CSCW and HCI practice. Proceedings of the ACM on human-computer interaction 3, CSCW (2019), 1–23
2019
-
[69]
Sewon Min, Kalpesh Krishna, Xinxi Lyu, Mike Lewis, Wen-tau Yih, Pang Wei Koh, Mohit Iyyer, Luke Zettlemoyer, and Hannaneh Hajishirzi. 2023. Factscore: Fine-grained atomic evaluation of factual precision in long form text genera- tion. arXiv preprint arXiv:2305.14251 (2023)
arXiv 2023
-
[70]
Mashfiq Mizan and Arafat Rahaman. 2025. Removal of word ‘adi- vasi’: Indigenous group attacked at NCTB; 20 hurt — thedailystar.net. https://www.thedailystar.net/news/bangladesh/news/removal-word-adivasi- indigenous-group-attacked-nctb-20-hurt-3799851 . Last accessed 21-02-2025]
2025
-
[71]
Sina Mohseni, Niloofar Zarei, and Eric D Ragan. 2021. A multidisciplinary survey and framework for design and evaluation of explainable AI systems. ACM Transactions on Interactive Intelligent Systems (TiiS) 11, 3-4 (2021), 1–45
2021
-
[72]
Jakob Mökander, Jonas Schuett, Hannah Rose Kirk, and Luciano Floridi. 2024. Auditing large language models: a three-layered approach. AI and Ethics 4, 4 (2024), 1085–1115
2024
-
[73]
Maria D Molina and S Shyam Sundar. 2022. When AI moderates online con- tent: effects of human collaboration and interactive transparency on user trust. Journal of Computer-Mediated Communication 27, 4 (2022), zmac010
2022
-
[74]
Marzieh Mozafari, Reza Farahbakhsh, and Noël Crespi. 2020. Hate speech de- tection and racial bias mitigation in social media based on BERT model. PloS one 15, 8 (2020), e0237861
2020
-
[75]
Abhijit Mukherjee, Poulomee Coomar, Soumyajit Sarkar, Karen H Johannes- son, Alan E Fryar, Madeline E Schreiber, Kazi Matin Ahmed, Mohammad Ayaz Alam, Prosun Bhattacharya, Jochen Bundschuh, et al. 2024. Arsenic and other geogenic contaminants in global groundwater. Nature Reviews Earth & Envi- ronment 5, 4 (2024), 312–328
2024
-
[76]
Richard R Orlandi, Todd T Kingdom, Timothy L Smith, Benjamin Bleier, Adam DeConde, Amber U Luong, David M Poetker, Zachary Soler, Kevin C Welch, Sarah K Wise, et al. 2021. International consensus statement on allergy and rhinology: rhinosinusitis 2021. In International forum of allergy & rhinology , Vol. 11. Wiley Online Library, 213–739
2021
-
[77]
Flor Miriam Plaza-del Arco, Debora Nozza, Dirk Hovy, et al. 2023. Respectful or toxic? using zero-shot learning with language models to detect hate speech. In The 7th workshop on online abuse and harms (woah) . Association for Compu- tational Linguistics
2023
-
[78]
Annu Sible Prabhakar, Lucia Guerra-Reyes, Vanessa M Kleinschmidt, Ben Jelen, Haley MacLeod, Kay Connelly, and Katie A Siek. 2017. Investigating the suit- ability of the asynchronous, remote, community-based method for pregnant and new mothers. In Proceedings of the 2017 CHI Conference on Human Factors in Computing Systems . 4924–4934
2017
-
[79]
Mohammad Rashidujjaman Rifat, Dipto Das, Arpon Poddar, Mahiratul Jannat, Robert Soden, Bryan Semaan, and Syed Ishtiaque Ahmed. 2024. The Politics of Fear and the Experience of Bangladeshi Religious Minority Communities Using Social Media Platforms. Proceedings of the ACM on Human-Computer Interaction 8, CSCW2 (2024), 1–32
2024
-
[80]
Mohammad Rashidujjaman Rifat, Abdullah Hasan Safir, Sourav Saha, Ja- hedul Alam Junaed, Maryam Saleki, Mohammad Ruhul Amin, and Syed Ish- tiaque Ahmed. 2024. Data, Annotation, and Meaning-Making: The Politics of Categorization in Annotating a Dataset of Faith-based Communal Violence. In Proceedings of the 2024 ACM Conference on Fairness, Accountability, a...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.