MuseVLA: An Adaptive Multimodal Sensing Vision-Language-Action Model for Robotic Manipulation
Pith reviewed 2026-06-27 00:46 UTC · model grok-4.3
The pith
MuseVLA lets a robot decide which extra sensor to query and folds its reading into the same image format used for planning actions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
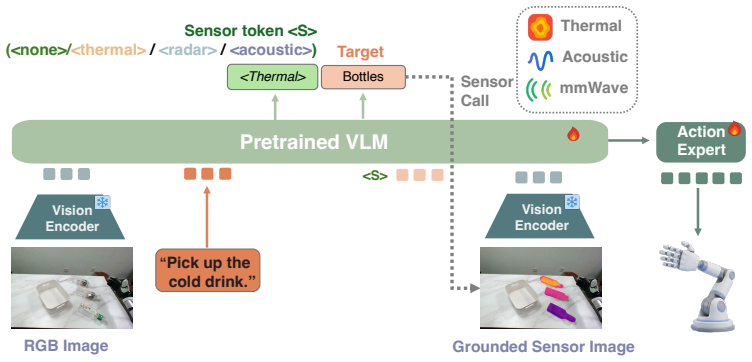
MuseVLA generates a sensor token and target description that act like a tool call, selects the appropriate modality, converts the raw sensor measurement into a grounded sensor image, and feeds that image together with RGB and language context into the VLA backbone to produce manipulation actions; the same pipeline, trained only on augmented RGB videos, transfers to real-robot tasks that require non-visual sensing.
What carries the argument
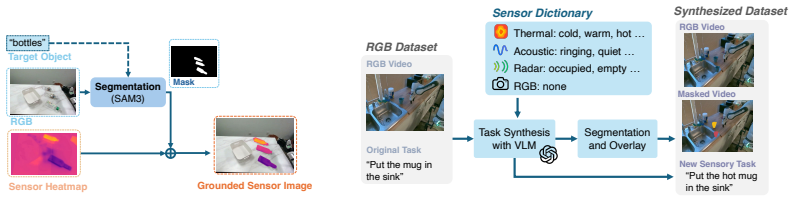
Sensor token generation followed by conversion of the selected reading into a grounded sensor image, which unifies heterogeneous sensor data for multimodal fusion inside the VLA model.
If this is right
- The model can invoke any new sensor whose reading can be rendered as an image without changing the VLA architecture.
- Training cost drops because no large-scale multisensory robot dataset is required.
- Performance on temperature-guided, audio-driven, and radar-assisted manipulation exceeds both RGB-only and prior multisensory VLA baselines.
- Zero-shot transfer occurs on tasks that combine unseen sensor combinations or object configurations.
Where Pith is reading between the lines
- The tool-call style interface could allow the same backbone to coordinate with external planners or other agents that supply additional sensor streams.
- Extending the image-conversion step to force, tactile, or chemical sensors would test how far the decoupling scales without new training data.
- If the synthesis pipeline works across robot embodiments it could reduce the data barrier for deploying sensor-rich manipulation in unstructured homes or warehouses.
Load-bearing premise
Augmenting existing RGB video datasets with synthesized grounded sensor images is enough to train a model that generalizes to real multisensory robot tasks.
What would settle it
Run the identical real-robot evaluation suite after training MuseVLA on a matched set of actual multisensory robot trajectories instead of the synthesized images and compare success rates.
Figures






read the original abstract
Humans naturally leverage diverse sensing modalities to interact with the physical world, while most Vision-Language-Action (VLA) models for robotics rely solely on RGB observations. This limits their ability to perceive physical properties that are difficult or impossible to infer from RGB cameras, such as temperature, sound, or radar response. We present MuseVLA, an adaptive multimodal sensing VLA model that integrates novel sensors as on-demand tools for robotic manipulation. Given a task instruction and visual context, MuseVLA first generates a sensor token and target description that select the sensing modality to invoke and what to attend to, analogous to a tool call with arguments. It then converts the selected sensor measurement into a grounded sensor image, a unified intermediate representation that encodes heterogeneous readings for multimodal fusion and action generation. This design decouples sensor-specific processing from the VLA backbone, enabling efficient integration of diverse modalities. To reduce the need for expensive multisensory robot datasets, we further introduce a data synthesis pipeline that augments existing RGB video datasets with grounded sensor images, enabling generalization to unseen sensor-guided tasks. We evaluate MuseVLA on a real-world robot across challenging dexterous hand manipulation tasks that require multimodal sensing inputs, including temperature-guided pick-and-place, audio-driven object search, and radar-assisted hidden object retrieval. MuseVLA achieves 80.6% success rate on average, outperforming RGB-only and multisensory VLA baselines significantly, and exhibits strong zero-shot capabilities on unseen tasks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents MuseVLA, a Vision-Language-Action model for robotic manipulation that integrates novel sensors (temperature, audio, radar) via an adaptive mechanism: it first generates a sensor token and target description to select the modality (analogous to a tool call), then converts the sensor measurement into a 'grounded sensor image' for fusion with the VLA backbone. To avoid costly real multisensory datasets, it introduces a data synthesis pipeline that augments existing RGB video datasets with these grounded images. On real-robot dexterous manipulation tasks (temperature-guided pick-and-place, audio-driven search, radar-assisted retrieval), it reports an average 80.6% success rate, outperforming RGB-only and other multisensory VLA baselines, with strong zero-shot generalization to unseen tasks.
Significance. If the central empirical claims hold after addressing the evaluation gaps, the work would be significant for the robotics and VLA communities by demonstrating a practical way to extend VLA models to heterogeneous sensors without requiring large-scale real multisensory data collection. The decoupling of sensor-specific processing through tokens and grounded images is a clean architectural contribution that could generalize to additional modalities. The data synthesis approach, if validated, addresses a key practical bottleneck in multimodal robotics.
major comments (2)
- [Abstract] Abstract: The abstract states a concrete success rate of 80.6% and claims significant outperformance over RGB-only and multisensory VLA baselines, yet supplies no trial counts, variance measures, statistical tests, or description of how baselines were matched in training data volume, compute, or fine-tuning procedure. This information is load-bearing for the central claim of multimodal integration benefits.
- [Methods / Data Synthesis] Data synthesis pipeline (described in the methods): The pipeline is presented only at the level of a high-level augmentation process that adds grounded sensor images to RGB datasets. No quantitative analysis, ablation, or distribution comparison (e.g., noise statistics, calibration fidelity, or temporal alignment) is provided to establish equivalence between the synthetic training signals and real sensor measurements on the robot. This assumption directly underpins the reported real-robot generalization and zero-shot results.
minor comments (2)
- [Introduction / Model Architecture] The notation for 'sensor token' and 'grounded sensor image' is introduced without an accompanying diagram or formal definition early in the paper, which would aid readability for readers unfamiliar with the tool-calling analogy.
- [Experiments] The manuscript would benefit from an explicit statement of the number of real-robot trials per task and condition in the main text (rather than solely in supplementary material, if present).
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and commit to revisions that strengthen the presentation of results and validation of the synthesis pipeline.
read point-by-point responses
-
Referee: [Abstract] Abstract: The abstract states a concrete success rate of 80.6% and claims significant outperformance over RGB-only and multisensory VLA baselines, yet supplies no trial counts, variance measures, statistical tests, or description of how baselines were matched in training data volume, compute, or fine-tuning procedure. This information is load-bearing for the central claim of multimodal integration benefits.
Authors: We agree the abstract would be strengthened by including these details. The full manuscript (Section 4 and supplementary material) already reports 50 trials per task with standard deviations and describes baseline matching on data volume and fine-tuning procedure; we will revise the abstract to explicitly state trial counts, variance, and a concise note on baseline equivalence. revision: yes
-
Referee: [Methods / Data Synthesis] Data synthesis pipeline (described in the methods): The pipeline is presented only at the level of a high-level augmentation process that adds grounded sensor images to RGB datasets. No quantitative analysis, ablation, or distribution comparison (e.g., noise statistics, calibration fidelity, or temporal alignment) is provided to establish equivalence between the synthetic training signals and real sensor measurements on the robot. This assumption directly underpins the reported real-robot generalization and zero-shot results.
Authors: We acknowledge that additional quantitative validation of the synthesis pipeline would improve rigor. In the revision we will add an ablation study together with direct comparisons of noise statistics, calibration fidelity, and temporal alignment between synthetic and real sensor measurements, placed in the Methods section and supplementary material. revision: yes
Circularity Check
No circularity: empirical model and evaluation with independent real-robot testing
full rationale
The paper describes an empirical VLA architecture, a data synthesis pipeline for augmenting RGB datasets, and real-robot evaluations achieving 80.6% success. No equations, fitted parameters, or derivations are present that reduce performance claims back to inputs by construction. The synthesis pipeline is a methodological choice whose validity is tested externally via real multisensory tasks; it does not self-define or rename its own outputs as predictions. No self-citation chains or uniqueness theorems are invoked as load-bearing. The work is self-contained against external benchmarks (real robot success rates vs. baselines).
Axiom & Free-Parameter Ledger
invented entities (2)
-
grounded sensor image
no independent evidence
-
sensor token
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Vineet Bhat, Yu-Hsiang Lan, Prashanth Krishnamurthy, Ramesh Karri, and Farshad Khorrami. 3D CA VLA: Leveraging depth and 3D context to generalize vision language action models for unseen tasks.arXiv preprint arXiv:2505.05800,
-
[2]
Jianxin Bi, Kevin Yuchen Ma, Ce Hao, Mike Zheng Shou, and Harold Soh. VLA-Touch: Enhancing vision-language-action models with dual-level tactile feedback.arXiv preprint arXiv:2507.17294,
-
[3]
Gr00t n1: An open foundation model for generalist humanoid robots.arXiv preprint arXiv:2503.14734,
Johan Bjorck, Fernando Castañeda, Nikita Cherniadev, Xingye Da, Runyu Ding, Linxi Fan, Yu Fang, Dieter Fox, Fengyuan Hu, Spencer Huang, et al. Gr00t n1: An open foundation model for generalist humanoid robots.arXiv preprint arXiv:2503.14734,
-
[4]
URLhttps://arxiv.org/abs/2410.24164. Kevin Black, Noah Brown, James Darpinian, Karan Dhabalia, Danny Driess, Adnan Esmail, Michael Robert Equi, Chelsea Finn, Niccolo Fusai, Manuel Y . Galliker, Dibya Ghosh, Lachy Groom, Karol Hausman, Brian Ichter, Szymon Jakubczak, Tim Jones, Liyiming Ke, Devin LeBlanc, Sergey Levine, Adrian Li-Bell, Mohith Mothukuri, Su...
-
[5]
URL https://proceedings.mlr.press/v305/black25a.html. Nicolas Carion, Laura Gustafson, Yuan-Ting Hu, Shoubhik Debnath, Ronghang Hu, Didac Suris, Chaitanya Ryali, Kalyan Vasudev Alwala, Haitham Khedr, Andrew Huang, et al. SAM 3: Segment anything with concepts.arXiv preprint arXiv:2511.16719,
-
[6]
Shenyuan Gao, William Liang, Kaiyuan Zheng, Ayaan Malik, Seonghyeon Ye, Sihyun Yu, Wei-Cheng Tseng, Yuzhu Dong, Kaichun Mo, Chen-Hsuan Lin, et al. Dreamdojo: A generalist robot world model from large-scale human videos.arXiv preprint arXiv:2602.06949,
-
[7]
10 Heyu Guo, Shanmu Wang, Ruichun Ma, Shiqi Jiang, Yasaman Ghasempour, Omid Abari, Baining Guo, and Lili Qiu. Omnivla: Physically-grounded multimodal vla with unified multi-sensor perception for robotic manipulation.arXiv preprint arXiv:2511.01210,
-
[8]
Xiaofeng Han, Shunpeng Chen, Zenghuang Fu, Zhe Feng, Lue Fan, Dong An, Changwei Wang, Li Guo, Weiliang Meng, Xiaopeng Zhang, et al. Multimodal fusion and vision-language models: A survey for robot vision.arXiv preprint arXiv:2504.02477,
-
[9]
Jialei Huang, Shuo Wang, Fanqi Lin, Yihang Hu, Chuan Wen, and Yang Gao. Tactile-VLA: Unlocking vision-language-action model’s physical knowledge for tactile generalization.arXiv preprint arXiv:2507.09160,
-
[10]
Physical Intelligence, Bo Ai, Ali Amin, Raichelle Aniceto, Ashwin Balakrishna, Greg Balke, Kevin Black, George Bokinsky, Shihao Cao, Thomas Charbonnier, et al. π0.7: A steerable generalist robotic foundation model with emergent capabilities.arXiv preprint arXiv:2604.15483,
-
[11]
Jisong Kim, Minjae Seong, and Jun Won Choi. Crt-fusion: Camera, radar, temporal fusion using motion information for 3d object detection.Advances in Neural Information Processing Systems, 37:108625–108648, 2024a. Moo Jin Kim, Karl Pertsch, Siddharth Karamcheti, Ted Xiao, Ashwin Balakrishna, Suraj Nair, Rafael Rafailov, Ethan Foster, Grace Lam, Pannag Sanke...
-
[12]
Chengmeng Li, Junjie Wen, Yan Peng, Yaxin Peng, Feifei Feng, and Yichen Zhu
URL https://arxiv.org/abs/2508.07917. Chengmeng Li, Junjie Wen, Yan Peng, Yaxin Peng, Feifei Feng, and Yichen Zhu. PointVLA: Injecting the 3D world into vision-language-action models.arXiv preprint arXiv:2503.07511, 2025a. Qixiu Li, Yu Deng, Yaobo Liang, Lin Luo, Lei Zhou, Chengtang Yao, Lingqi Zeng, Zhiyuan Feng, Huizhi Liang, Sicheng Xu, et al. Scalable...
-
[13]
Zhijian Liu, Haotian Tang, Alexander Amini, Xinyu Yang, Huizi Mao, Daniela Rus, and Song Han. Bevfusion: Multi-task multi-sensor fusion with unified bird’s-eye view representation.arXiv preprint arXiv:2205.13542,
-
[14]
Zhuoyang Liu, Jiaming Liu, Jiadong Xu, Nuowei Han, Chenyang Gu, Hao Chen, Kaichen Zhou, Ren- rui Zhang, Kai Chin Hsieh, Kun Wu, et al. MLA: A multisensory language-action model for multi- modal understanding and forecasting in robotic manipulation.arXiv preprint arXiv:2509.26642,
-
[15]
Octo: An open-source generalist robot policy
11 Oier Mees, Dibya Ghosh, Karl Pertsch, Kevin Black, Homer Rich Walke, Sudeep Dasari, Joey Hejna, Tobias Kreiman, Charles Xu, Jianlan Luo, et al. Octo: An open-source generalist robot policy. In First Workshop on Vision-Language Models for Navigation and Manipulation at ICRA 2024,
2024
-
[16]
Maxim A Patratskiy, Alexey K Kovalev, and Aleksandr I Panov. Spatial traces: Enhancing vla models with spatial-temporal understanding.arXiv preprint arXiv:2508.09032,
-
[17]
Delin Qu, Haoming Song, Qizhi Chen, Yuanqi Yao, Xinyi Ye, Yan Ding, Zhigang Wang, JiaYuan Gu, Bin Zhao, Dong Wang, et al. SpatialVLA: Exploring spatial representations for visual-language- action model.arXiv preprint arXiv:2501.15830,
-
[18]
Mustafa Shukor, Dana Aubakirova, Francesco Capuano, Pepijn Kooijmans, Steven Palma, Adil Zoui- tine, Michel Aractingi, Caroline Pascal, Martino Russi, Andres Marafioti, et al. SmolVLA: A vision- language-action model for affordable and efficient robotics.arXiv preprint arXiv:2506.01844,
-
[19]
Paligemma 2: A family of versatile vlms for transfer.arXiv preprint arXiv:2412.03555,
Andreas Steiner, André Susano Pinto, Michael Tschannen, Daniel Keysers, Xiao Wang, Yonatan Bit- ton, Alexey Gritsenko, Matthias Minderer, Anthony Sherbondy, Shangbang Long, et al. Paligemma 2: A family of versatile vlms for transfer.arXiv preprint arXiv:2412.03555,
-
[20]
Gemma 2: Improving open language models at a practical size.arXiv preprint arXiv:2408.00118,
Gemma Team, Morgane Riviere, Shreya Pathak, Pier Giuseppe Sessa, Cassidy Hardin, Surya Bhupatiraju, Léonard Hussenot, Thomas Mesnard, Bobak Shahriari, Alexandre Ramé, et al. Gemma 2: Improving open language models at a practical size.arXiv preprint arXiv:2408.00118,
-
[21]
Tai Wang, Xiaohan Mao, Chenming Zhu, Runsen Xu, Ruiyuan Lyu, Peisen Li, Xiao Chen, Wenwei Zhang, Kai Chen, Tianfan Xue, Xihui Liu, Cewu Lu, Dahua Lin, and Jiangmiao Pang
https://generalistai.com/blog/apr-02-2026-GEN-1. Tai Wang, Xiaohan Mao, Chenming Zhu, Runsen Xu, Ruiyuan Lyu, Peisen Li, Xiao Chen, Wenwei Zhang, Kai Chen, Tianfan Xue, Xihui Liu, Cewu Lu, Dahua Lin, and Jiangmiao Pang. Embod- iedscan: A holistic multi-modal 3d perception suite towards embodied ai. InProceedings of the IEEE/CVF Conference on Computer Visi...
2026
-
[22]
Junjie Wen, Yichen Zhu, Jinming Li, Zhibin Tang, Chaomin Shen, and Feifei Feng. DexVLA: Vision-language model with plug-in diffusion expert for general robot control.arXiv preprint arXiv:2502.05855,
-
[23]
Philipp Wolters, Johannes Gilg, Torben Teepe, Fabian Herzog, Anouar Laouichi, Martin Hofmann, and Gerhard Rigoll. Unleashing hydra: Hybrid fusion, depth consistency and radar for unified 3d perception.arXiv preprint arXiv:2403.07746,
-
[24]
A pragmatic vla foundation model.arXiv preprint arXiv:2601.18692v1,
Wei Wu, Fan Lu, Yunnan Wang, Shuai Yang, Shi Liu, Fangjing Wang, Shuailei Ma, He Sun, Yong Wang, Zhenqi Qiu, Houlong Xiong, Ziyu Wang, Shuai Zhou, Yiyu Ren, Kejia Zhang, Hui Yu, Jingmei Zhao, Qian Zhu, Ran Cheng, Yong-Lu Li, Yongtao Huang, Xing Zhu, Yujun Shen, and Kecheng Zheng. A pragmatic vla foundation model.arXiv preprint arXiv:2601.18692v1,
-
[25]
Jiawen Yu, Hairuo Liu, Qiaojun Yu, Jieji Ren, Ce Hao, Haitong Ding, Guangyu Huang, Guofan Huang, Yan Song, Panpan Cai, et al. Forcevla: Enhancing vla models with a force-aware moe for contact-rich manipulation.arXiv preprint arXiv:2505.22159,
-
[26]
Generalizable humanoid manipulation with 3d diffusion policies.arXiv preprint arXiv:2410.10803,
12 Yanjie Ze, Zixuan Chen, Wenhao Wang, Tianyi Chen, Xialin He, Ying Yuan, Xue Bin Peng, and Jiajun Wu. Generalizable humanoid manipulation with 3d diffusion policies.arXiv preprint arXiv:2410.10803,
-
[27]
Chubin Zhang, Jianan Wang, Zifeng Gao, Yue Su, Tianru Dai, Cai Zhou, Jiwen Lu, and Yansong Tang. Clap: Contrastive latent action pretraining for learning vision-language-action models from human videos.arXiv preprint arXiv:2601.04061,
-
[28]
VLAS: Vision-language-action model with speech instructions for customized robot manipulation
Wei Zhao, Pengxiang Ding, Min Zhang, Zhefei Gong, Shuanghao Bai, Han Zhao, and Donglin Wang. VLAS: Vision-language-action model with speech instructions for customized robot manipulation. arXiv preprint arXiv:2502.13508,
-
[29]
3D-VLA: A 3D vision-language-action generative world model.arXiv preprint arXiv:2403.09631,
Haoyu Zhen, Xiaowen Qiu, Peihao Chen, Jincheng Yang, Xin Yan, Yilun Du, Yining Hong, and Chuang Gan. 3D-VLA: A 3D vision-language-action generative world model.arXiv preprint arXiv:2403.09631,
-
[30]
Lianqing Zheng, Jianan Liu, Runwei Guan, Long Yang, Shouyi Lu, Yuanzhe Li, Xiaokai Bai, Jie Bai, Zhixiong Ma, Hui-Liang Shen, et al. Doracamom: Joint 3d detection and occupancy prediction with multi-view 4d radars and cameras for omnidirectional perception.arXiv preprint arXiv:2501.15394,
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.