A Framework for Evaluating Agentic Skills at Scale
Pith reviewed 2026-06-26 23:40 UTC · model grok-4.3
The pith
Access to skills changes LLM agent behavior substantially while models differ widely in following the encoded instructions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Access to a skill significantly changes model behavior compared to the no-skill setup, providing an essential mechanism for encoding opinionated workflows into LLM agents. Models vary widely in how closely they adhere to the instructions encoded in skills.
What carries the argument
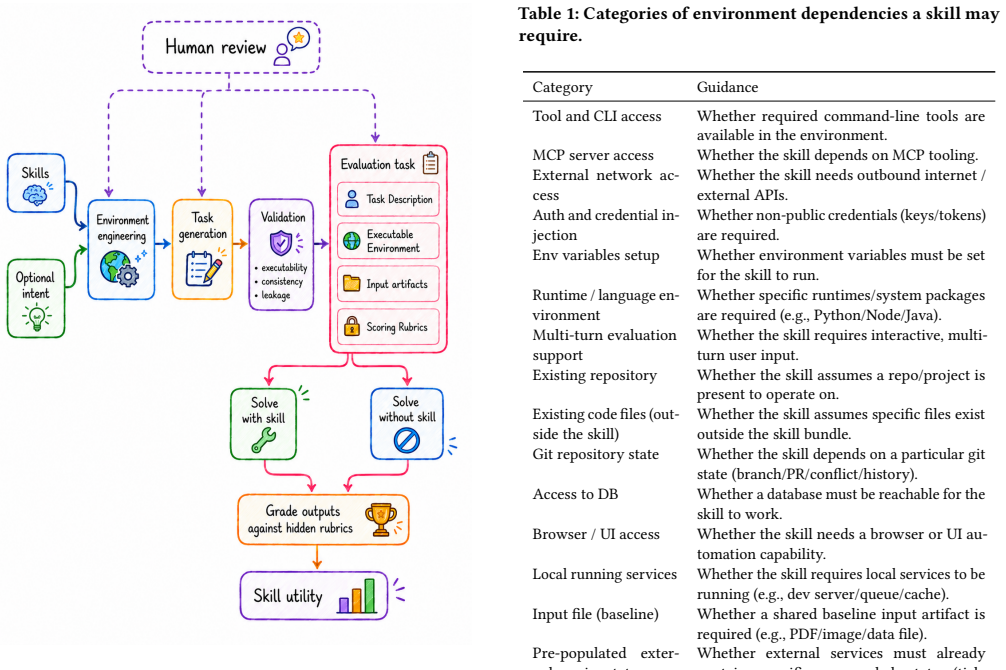
An evaluation framework that derives tasks from skill content and scores them with instruction-following and goal-completion rubrics to estimate skill utility.
If this is right
- Skills act as a practical way to embed specific workflows into agents.
- Performance improvements from skills are not uniform and depend on the model.
- The released dataset of 1000 tasks enables further comparative studies of agent skills.
- Skill authors can use the framework to test and iterate on the utility of individual skills.
Where Pith is reading between the lines
- Different models may need differently structured skills to achieve the same workflow goals.
- The framework could be adapted to evaluate other reusable artifacts in agent systems beyond skills.
- Large-scale evaluation of this kind could reveal which model families are better suited for instruction-heavy agent work.
Load-bearing premise
The tasks generated automatically from skill descriptions serve as realistic proxies for the aspects authors care about most, and the rubrics measure true skill utility without introducing post-hoc bias.
What would settle it
Finding no measurable difference in model behavior or task scores between the with-skill and no-skill conditions across the generated tasks would falsify the central claim.
Figures


read the original abstract
Agent skills -- structured, reusable knowledge artifacts that augment LLM agent capabilities -- have been rapidly adopted in industry, yet their cross-domain impact and use across commercial and open-source models remain under-studied, and no reusable methodology exists for evaluating an individual skill. In this work, we present an evaluation framework that lets a skill author construct realistic tasks to rigorously assess the aspects of a skill that matter most to them, and that estimates skill utility by solving those tasks. Further, we apply our evaluation approach at scale to 500 real-world skills, generating 1,000 tasks derived from the skills' content, along with instruction-following and goal-completion scoring rubrics. Using these metrics, we evaluate how 19 agent-model configurations, both proprietary and open-source, perform on the tasks. Our results show that models vary widely in how closely they adhere to the instructions encoded in skills, leading to substantial differences in their performance gains. Furthermore, we show that access to a skill significantly changes model behavior compared to the no-skill setup, providing an essential mechanism for encoding opinionated workflows into LLM agents. We release our evaluation dataset to support future work on agent skills.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to introduce a reusable evaluation framework allowing skill authors to construct realistic tasks from skill content and estimate utility via instruction-following and goal-completion rubrics; it applies the approach at scale to 500 real-world skills (generating 1,000 tasks and rubrics), evaluates 19 proprietary and open-source agent-model configurations, and reports that skill access significantly alters model behavior relative to no-skill baselines while models vary widely in adherence to encoded instructions. The evaluation dataset is released.
Significance. If the automatic task and rubric construction is shown to be unbiased, the framework would supply a needed methodology for assessing cross-domain skill utility in LLM agents, an area of rapid industrial adoption with little prior reusable evaluation. The release of the 1,000-task dataset is a concrete strength supporting reproducibility and future work.
major comments (2)
- [Abstract / evaluation methodology] Abstract and evaluation description: the headline claims that 'access to a skill significantly changes model behavior' and that 'models vary widely in how closely they adhere' rest on automatically derived tasks and rubrics whose realism and lack of bias are not validated (no human judgment, inter-rater reliability, or adversarial checks reported); this is load-bearing because any systematic favoritism toward verbose instruction-following or particular output formats would artifactually inflate the measured performance gap versus the no-skill baseline.
- [Framework and study application] Framework description: the paper states the framework 'lets a skill author construct realistic tasks to rigorously assess the aspects of a skill that matter most to them,' yet the reported study uses fully automatic derivation from skill content; the gap between author-driven construction and the automated proxy used for the 500-skill results is not quantified or justified, undermining the claim that the generated tasks serve as valid proxies.
minor comments (2)
- [Abstract] Abstract could more clearly distinguish the general author-driven framework from the specific automatic generation procedure employed in the 500-skill experiment.
- [Results] The number of models (19) and configurations is stated without a table or breakdown of which are proprietary vs. open-source; a summary table would improve clarity.
Simulated Author's Rebuttal
We thank the referee for their constructive comments on our paper. We address each of the major comments below.
read point-by-point responses
-
Referee: [Abstract / evaluation methodology] Abstract and evaluation description: the headline claims that 'access to a skill significantly changes model behavior' and that 'models vary widely in how closely they adhere' rest on automatically derived tasks and rubrics whose realism and lack of bias are not validated (no human judgment, inter-rater reliability, or adversarial checks reported); this is load-bearing because any systematic favoritism toward verbose instruction-following or particular output formats would artifactually inflate the measured performance gap versus the no-skill baseline.
Authors: We agree that the absence of human validation for the automatically generated tasks and rubrics is a limitation of the current study. The automatic derivation process is designed to extract tasks and rubrics directly from the skill descriptions to ensure they reflect the skill content. However, we recognize that without reported human judgment or inter-rater reliability, there is potential for unexamined bias. In the revised manuscript, we will expand the limitations section to explicitly discuss this issue and the assumptions underlying the automatic approach. We will also note that future work could include human validation to further strengthen the framework. revision: yes
-
Referee: [Framework and study application] Framework description: the paper states the framework 'lets a skill author construct realistic tasks to rigorously assess the aspects of a skill that matter most to them,' yet the reported study uses fully automatic derivation from skill content; the gap between author-driven construction and the automated proxy used for the 500-skill results is not quantified or justified, undermining the claim that the generated tasks serve as valid proxies.
Authors: The framework is intended to support skill authors in constructing tasks, with the automated derivation serving as a scalable method for large-scale application when manual construction is not feasible. The study applies the automated proxy to demonstrate the framework's utility at scale. We acknowledge that the manuscript does not quantify the differences between author-constructed and automatically derived tasks. In the revision, we will add a new subsection in the framework description that justifies the use of automation as a proxy, provides examples of how the automatic tasks align with skill content, and discusses the conditions under which it serves as a valid approximation. revision: yes
Circularity Check
No circularity: evaluation derives tasks externally and measures model behavior directly
full rationale
The paper constructs tasks from skill content and applies instruction-following plus goal-completion rubrics to compare model runs with versus without skills. This is a direct empirical measurement on generated tasks rather than any self-definitional loop, fitted parameter renamed as prediction, or load-bearing self-citation. No equations, uniqueness theorems, or ansatzes reduce the central claims to the inputs by construction; the performance gaps are outputs of independent model executions.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Tasks generated from skill content are representative of real-world use cases that matter to skill authors
Reference graph
Works this paper leans on
-
[1]
Alibaba Qwen Team. 2026. Qwen3-Coder-Next: Technical Report. (2026). arXiv:2603.00729 https://arxiv.org/abs/2603.00729
Pith/arXiv arXiv 2026
-
[2]
Anthropic. 2024. Introducing the Model Context Protocol. https://www.anthropic. com/news/model-context-protocol
2024
-
[3]
Anthropic. 2025. Agent Skills. https://docs.anthropic.com/agents/skills
2025
-
[4]
Anthropic. 2025. Claude Code. https://code.claude.com/docs/en/overview
2025
-
[5]
Anthropic. 2025. Claude Haiku 4.5. https://www.anthropic.com/news/claude- haiku-4-5
2025
-
[6]
Anthropic. 2025. Equipping Agents for the Real World with Agent Skills. An- thropic Engineering Blog. https://www.anthropic.com/engineering/equipping- agents-for-the-real-world-with-agent-skills
2025
-
[7]
Anthropic. 2026. Claude Opus 4.7. https://www.anthropic.com/news/claude- opus-4-7
2026
-
[8]
Anthropic. 2026. Claude Opus 4.8. https://www.anthropic.com/news/claude- opus-4-8
2026
-
[9]
Anthropic. 2026. Claude Sonnet 4.6. https://www.anthropic.com/news/claude- sonnet-4-6
2026
-
[10]
Anthropic. 2026. Demystifying Evals for AI Agents. Anthropic Engineering Blog. https://www.anthropic.com/engineering/demystifying-evals-for-ai-agents
2026
-
[11]
Ibragim Badertdinov et al. 2026. SWE-rebench V2: Language-Agnostic SWE Task Collection at Scale. (2026). arXiv:2602.23866 https://arxiv.org/abs/2602.23866
Pith/arXiv arXiv 2026
-
[12]
Ibragim Badertdinov, Alexander Golubev, Maksim Nekrashevich, Anton Shevtsov, Simon Karasik, Andrei Andriushchenko, Maria Trofimova, Daria Litvintseva, and Boris Yangel. 2025. SWE-rebench: An Automated Pipeline for Task Collec- tion and Decontaminated Evaluation of Software Engineering Agents. (2025). arXiv:2505.20411 https://arxiv.org/abs/2505.20411
arXiv 2025
-
[13]
DeepSeek. 2026. DeepSeek V4 Pro. https://huggingface.co/deepseek-ai/ DeepSeek-V4-Pro/blob/main/DeepSeek_V4.pdf
2026
-
[14]
Google DeepMind. 2026. Gemini 3 Flash Preview. https://ai.google.dev/gemini- api/docs/models/gemini-3-flash-preview
2026
-
[15]
Google DeepMind. 2026. Gemini 3.1 Flash Lite. https://ai.google.dev/gemini- api/docs/models/gemini-3.1-flash-lite-preview
2026
-
[16]
Google DeepMind. 2026. Gemini 3.1 Pro Preview. https://ai.google.dev/gemini- api/docs/models/gemini-3.1-pro-preview
2026
-
[17]
Google DeepMind. 2026. Gemini 3.5 Flash. https://ai.google.dev/gemini-api/ docs/models/gemini-3.5-flash
2026
-
[18]
Bowman, and Sara Price
Isha Gupta, Kai Fronsdal, Abhay Sheshadri, Jonathan Michala, Jacqueline Tay, Rowan Wang, Samuel R. Bowman, and Sara Price. 2025. Bloom: An Open- Source Tool for Automated Behavioral Evaluations. https://www.anthropic.com/ research/bloom
2025
-
[19]
Naman Jain, King Han, Alex Gu, Wen-Ding Li, Fanjia Yan, Tianjun Zhang, Sida Wang, Armando Solar-Lezama, Koushik Sen, and Ion Stoica. 2025. Live- CodeBench: Holistic and Contamination-Free Evaluation of Large Language Models for Code. InInternational Conference on Learning Representations (ICLR). arXiv:2403.07974 https://arxiv.org/abs/2403.07974
Pith/arXiv arXiv 2025
-
[20]
Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan
Carlos E. Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan. 2024. SWE-bench: Can Language Models Resolve Real- World GitHub Issues?. InInternational Conference on Learning Representations (ICLR). arXiv:2310.06770 https://arxiv.org/abs/2310.06770
Pith/arXiv arXiv 2024
-
[21]
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, et al
-
[22]
In Advances in Neural Information Processing Systems (NeurIPS)
Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks. In Advances in Neural Information Processing Systems (NeurIPS)
-
[23]
Xiangyi Li, Wenbo Chen, Yimin Liu, et al . 2026. SkillsBench: Benchmarking How Well Agent Skills Work Across Diverse Tasks. (2026). arXiv:2602.12670 https://arxiv.org/abs/2602.12670
Pith/arXiv arXiv 2026
-
[24]
Yujian Liu, Jiabao Ji, Li An, Tommi Jaakkola, Yang Zhang, and Shiyu Chang. 2026. How Well Do Agentic Skills Work in the Wild: Benchmarking LLM Skill Usage in Realistic Settings. (2026). arXiv:2604.04323 https://arxiv.org/abs/2604.04323
Pith/arXiv arXiv 2026
-
[25]
Mike A. Merrill, Alexander G. Shaw, Nicholas Carlini, Boxuan Li, et al . 2026. Terminal-Bench: Benchmarking Agents on Hard, Realistic Tasks in Command Line Interfaces. (2026). arXiv:2601.11868 https://arxiv.org/abs/2601.11868
Pith/arXiv arXiv 2026
-
[26]
MiniMax. 2026. MiniMax 2.7. https://www.minimax.io/models/text/m27
2026
-
[27]
Moonshot AI. 2026. Kimi K2.6. https://www.kimi.com/ai-models/kimi-k2-6
2026
-
[28]
NVIDIA. 2026. Nemotron 3 Nano 30B. https://build.nvidia.com/nvidia/nemotron- 3-nano-30b-a3b/modelcard
2026
-
[29]
NVIDIA. 2026. Nemotron 3 Super 120B. https://build.nvidia.com/nvidia/ nemotron-3-super-120b-a12b
2026
-
[30]
OpenAI. 2025. Codex. https://chatgpt.com/codex/
2025
-
[31]
OpenAI. 2026. GPT-5.4. https://developers.openai.com/api/docs/models/gpt-5.4
2026
-
[32]
OpenAI. 2026. GPT-5.4 mini. https://developers.openai.com/api/docs/models/gpt- 5.4-mini
2026
-
[33]
OpenAI. 2026. GPT-5.4 nano. https://developers.openai.com/api/docs/models/gpt- 5.4-nano
2026
-
[34]
Mohit Raghavendra, Anisha Gunjal, Bing Liu, and Yunzhong He. 2026. Agentic Rubrics as Contextual Verifiers for SWE Agents. (2026). arXiv:2601.04171 https: //arxiv.org/abs/2601.04171
arXiv 2026
-
[35]
Scale AI. 2025. SWE-Bench Pro: Can AI Agents Solve Long-Horizon Software Engineering Tasks? (2025). arXiv:2509.16941 https://arxiv.org/abs/2509.16941
Pith/arXiv arXiv 2025
-
[36]
Gorinova, Rob Willoughby, and Dru Knox
Maksim Shaposhnikov, Maria I. Gorinova, Rob Willoughby, and Dru Knox. 2025. A Proposed Evaluation Framework for Coding Agents: Tiles Enhance Proper Use of Public APIs by 35%.Tessl Blog(2025). https://tessl.io/blog/proposed- evaluation-framework-for-coding-agents/
2025
-
[37]
SkillsMP. 2025. SkillsMP: A Marketplace for Agent Skills. https://skillsmp.com/
2025
-
[38]
skills.sh. 2025. skills.sh: A Community Registry for Agent Skills. https://www. skills.sh/
2025
-
[39]
Sumers, Shunyu Yao, Karthik Narasimhan, and Thomas L
Theodore R. Sumers, Shunyu Yao, Karthik Narasimhan, and Thomas L. Griffiths
-
[40]
Cognitive Architectures for Language Agents. (2023). arXiv:2309.02427 https://arxiv.org/abs/2309.02427
Pith/arXiv arXiv 2023
-
[41]
Tessl. 2025. Tessl Skill Registry. https://tessl.io/registry
2025
-
[42]
Guanzhi Wang, Yuqi Xie, Yunfan Jiang, Ajay Mandlekar, Chaowei Xiao, Yuke Zhu, Linxi Fan, and Anima Anandkumar. 2023. Voyager: An Open-Ended Embodied Agent with Large Language Models. (2023). arXiv:2305.16291 https://arxiv.org/ abs/2305.16291
Pith/arXiv arXiv 2023
-
[43]
Xu, Xiangru Tang, Mingchen Zhuge, Jiayi Pan, Yueqi Song, Bowen Li, Jaskirat Singh, et al
Xingyao Wang, Boxuan Li, Yufan Song, Frank F. Xu, Xiangru Tang, Mingchen Zhuge, Jiayi Pan, Yueqi Song, Bowen Li, Jaskirat Singh, et al. 2025. OpenHands: An Open Platform for AI Software Developers as Generalist Agents. InInternational Conference on Learning Representations (ICLR). arXiv:2407.16741 https://arxiv. org/abs/2407.16741
Pith/arXiv arXiv 2025
-
[44]
Zhenting Wang, Qi Chang, Hemani Patel, Shashank Biju, Cheng-En Wu, Quan Liu, Aolin Ding, Alireza Rezazadeh, Ankit Shah, Yujia Bao, and Eugene Siow. 2025. MCP-Bench: Benchmarking Tool-Using LLM Agents with Complex Real-World Tasks via MCP Servers. (2025). arXiv:2508.20453 https://arxiv.org/abs/2508.20453
arXiv 2025
-
[45]
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed H. Chi, Quoc V. Le, and Denny Zhou. 2022. Chain-of-Thought Prompting Elicits Reasoning in Large Language Models. InAdvances in Neural Information Processing Systems (NeurIPS). arXiv:2201.11903 https://arxiv.org/abs/2201.11903
Pith/arXiv arXiv 2022
-
[46]
Yifan Yang, Ziyang Gong, Weiquan Huang, Qihao Yang, Ziwei Zhou, Zisu Huang, Yan Li, Xuemei Gao, Qi Dai, Bei Liu, Kai Qiu, Yuqing Yang, Dongdong Chen, Xue Yang, and Chong Luo. 2026. SkillOpt: Executive Strategy for Self-Evolving Agent Skills. (2026). arXiv:2605.23904 [cs.AI] https://arxiv.org/abs/2605.23904
Pith/arXiv arXiv 2026
-
[47]
Shunyu Yao, Noah Shinn, Pedram Razavi, and Karthik Narasimhan. 2024. 𝜏- bench: A Benchmark for Tool-Agent-User Interaction in Real-World Domains. (2024). arXiv:2406.12045 https://arxiv.org/abs/2406.12045
Pith/arXiv arXiv 2024
-
[48]
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. 2023. ReAct: Synergizing Reasoning and Acting in Lan- guage Models. InInternational Conference on Learning Representations (ICLR). arXiv:2210.03629 https://arxiv.org/abs/2210.03629
Pith/arXiv arXiv 2023
-
[49]
Z.ai. 2026. GLM 5.1. https://z.ai/blog/glm-5.1
2026
-
[50]
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric P. Xing, Hao Zhang, 9 Joseph E. Gonzalez, and Ion Stoica. 2023. Judging LLM-as-a-Judge with MT- Bench and Chatbot Arena. InAdvances in Neural Information Processing Systems (NeurIPS), Datasets and Benchmarks Track. arXiv:2306.05685 h...
Pith/arXiv arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.