Mixed-Precision Communication-Avoiding SGD for Generalized Linear Models on GPUs
Pith reviewed 2026-06-26 22:19 UTC · model grok-4.3
The pith
Mixed-precision CA-SGD stores inputs low, accumulates Gram high, and communicates high to match FP32 loss within 0.5% while delivering 5.1-6.8x speedup on A100 GPUs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
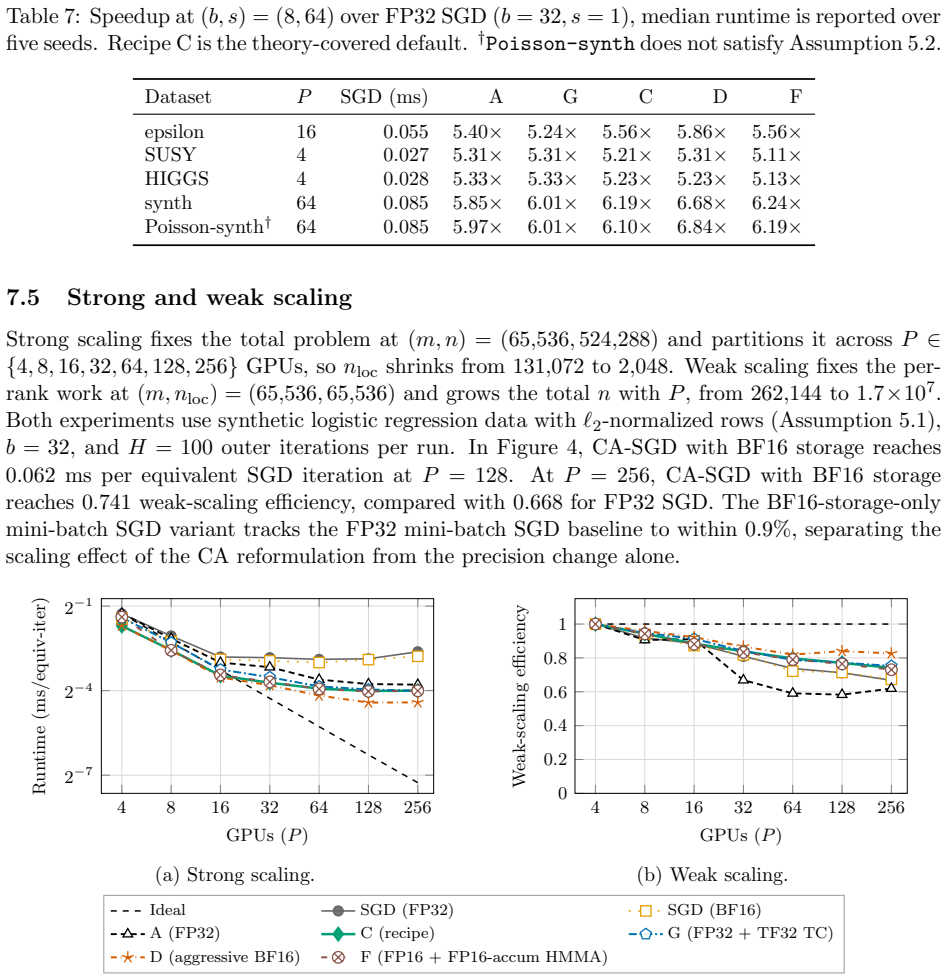
The finite-precision analysis decomposes the local rounding error of one CA-SGD outer iteration into nine independent precision choices depending on the hardware only through its low-precision unit roundoffs. The derived recipe stores the input matrix and margin vector in low precision, computes the Gram matrix from low-precision inputs with high-precision accumulation, communicates it in high precision, and performs the inner recurrence and weight updates in high precision. On A100 GPUs this produces loss within 0.5% of FP32 SGD on logistic, linear, and Poisson regression while achieving 5.1-6.8x speedup.
What carries the argument
The finite-precision error analysis that decomposes one CA-SGD outer iteration's rounding error into nine independent precision choices controlled by low-precision unit roundoffs.
If this is right
- The same precision recipe applies to logistic, linear, and Poisson generalized linear models.
- Loss stays within 0.5% of FP32 SGD while communication is reduced from s AllReduces to one Gram-matrix AllReduce.
- Speedups of 5.1-6.8x are observed on epsilon, SUSY, HIGGS, synth, and Poisson-synth datasets.
- The nine precision choices depend on hardware only through low-precision unit roundoffs, so the recipes transfer in principle across GPU generations.
Where Pith is reading between the lines
- The nine-choice decomposition supplies a template that could be reused to analyze rounding error in other iterative methods built around Gram-matrix AllReduces.
- Because the recipe separates low-precision storage from high-precision accumulation and communication, the same structure may reduce bandwidth pressure in distributed training of models beyond generalized linear models.
- Practitioners can adopt the listed precision assignments on any NVIDIA GPU supporting the same low-precision formats without re-deriving the error bounds.
Load-bearing premise
The nine rounding-error terms arising from different precision choices remain sufficiently independent that their aggregate effect on the final loss stays bounded without hardware-specific interactions beyond the unit roundoffs.
What would settle it
Measure the loss of the mixed-precision CA-SGD recipe on the same logistic, linear, or Poisson problems on a newer GPU generation; deviation greater than 0.5% from FP32 SGD would falsify transferability of the nine-choice decomposition.
Figures

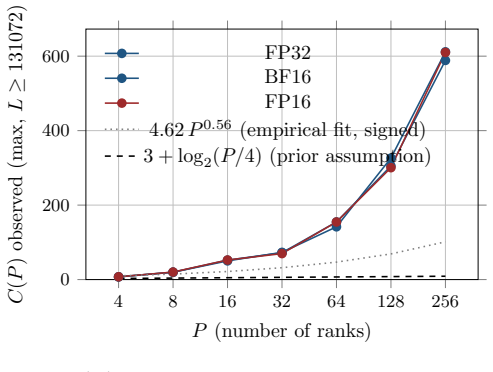
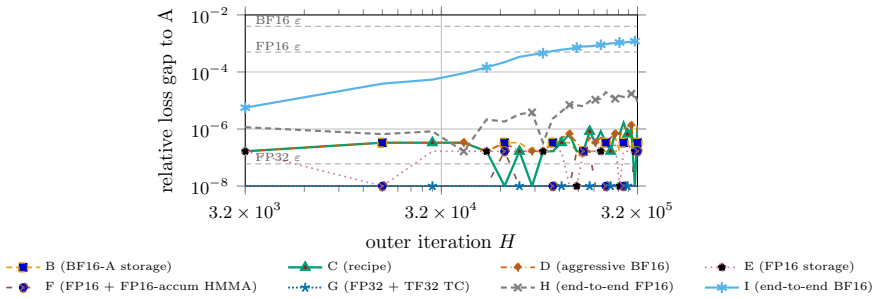
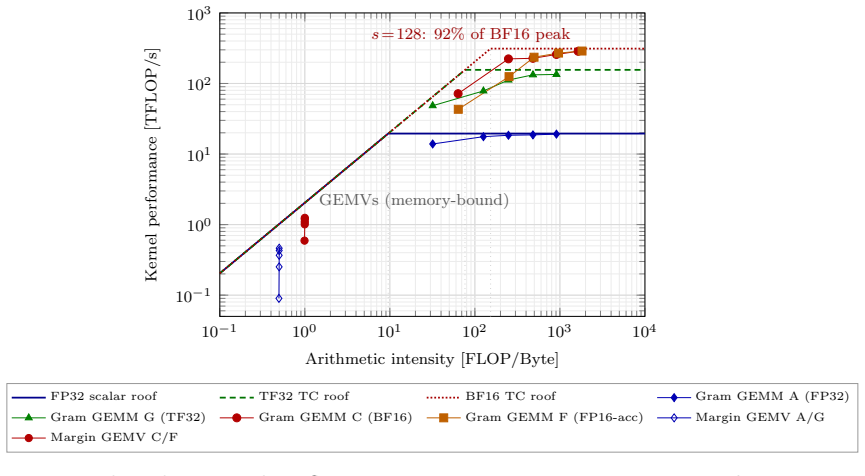
read the original abstract
Distributed stochastic gradient descent (SGD) is limited by communication rather than computation, since each iteration requires an AllReduce across processes. Communication-avoiding SGD (CA-SGD) amortizes communication over $s$ iterations by replacing $s$ consecutive AllReduces with a single AllReduce of an $sb\times sb$ Gram matrix, trading more computation and bandwidth for fewer synchronization points. Modern GPUs with matrix hardware and reduced-precision formats offset this by accelerating the Gram GEMM and shrinking BF16 traffic. We study mixed-precision CA-SGD for generalized linear models on NVIDIA GPUs. Our finite-precision analysis decomposes the local rounding error of one CA-SGD outer iteration into nine independent precision choices, depending on the hardware only through its low-precision unit roundoffs, so the resulting recipes transfer in principle across GPU generations. The recipe stores the input matrix and margin vector in low precision, computes the Gram matrix from low-precision inputs with high-precision accumulation, communicates it in high precision, and performs the inner recurrence and weight updates in high precision. On NERSC Perlmutter A100 GPUs, mixed-precision CA-SGD matches FP32 SGD loss within $0.5\%$ on logistic, linear, and Poisson problems and reaches $5.1$--$6.8\times$ speedup over FP32 SGD on epsilon, SUSY, HIGGS, synth, and Poisson-synth. Our software is available at https://doi.org/10.5281/zenodo.20448273
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces mixed-precision communication-avoiding SGD (CA-SGD) for generalized linear models on NVIDIA GPUs. It presents a finite-precision analysis that decomposes the local rounding error of one CA-SGD outer iteration into nine independent precision choices depending on hardware only through low-precision unit roundoffs. The resulting recipe stores the input matrix and margin vector in low precision, computes the Gram matrix from low-precision inputs with high-precision accumulation, communicates the Gram matrix in high precision, and performs the inner recurrence and weight updates in high precision. On NERSC Perlmutter A100 GPUs, the method matches FP32 SGD loss within 0.5% on logistic, linear, and Poisson problems while achieving 5.1--6.8× speedup over FP32 SGD on several datasets; open-source code is provided.
Significance. If the error decomposition holds and the reported speedups and accuracy are reproducible, the work provides a practical route to reduce communication overhead in distributed GLM training while preserving accuracy through mixed precision on tensor-core GPUs. The explicit dependence on unit roundoffs (rather than hardware-specific details) supports potential transferability across GPU generations, and the open code at the cited DOI is a clear strength for verification and extension.
major comments (2)
- [Abstract and §3] Abstract and §3 (finite-precision analysis): the claim that the local rounding error decomposes into nine independent precision choices depending on hardware solely through low-precision unit roundoffs underpins both the recipe and the transferability assertion. However, this decomposition does not address potential hardware-specific correlations from tensor-core FMA behavior, shared-memory bank conflicts, or warp-level reductions, which could introduce cross terms that vary with matrix dimensions and block size s; without explicit validation of the independence assumption against measured GPU roundoff for the tested s values, the 0.5% loss-matching guarantee may not transfer.
- [§5] §5 (experiments): the reported 5.1--6.8× speedup and 0.5% loss match are central to the practical claim, yet the manuscript provides no breakdown of how the nine precision choices were mapped to the actual A100 kernels (e.g., which operations used TF32 vs. BF16 accumulation) or ablation showing that altering any one choice violates the error bound; this makes it impossible to confirm that the observed results follow from the analysis rather than from unmodeled hardware effects.
minor comments (2)
- [Abstract] The abstract states the datasets (epsilon, SUSY, HIGGS, synth, Poisson-synth) but does not specify problem dimensions or the range of s values used; adding these would clarify the regime in which the speedups hold.
- Notation for the nine precision choices is introduced without an explicit table mapping each choice to the corresponding operation (input storage, Gram accumulation, etc.); a compact table would improve readability.
Simulated Author's Rebuttal
We thank the referee for the careful and constructive review. The comments highlight important aspects of the finite-precision analysis and its connection to experiments. We address each point below and propose targeted revisions to clarify assumptions and implementation details.
read point-by-point responses
-
Referee: [Abstract and §3] the claim that the local rounding error decomposes into nine independent precision choices depending on hardware solely through low-precision unit roundoffs underpins both the recipe and the transferability assertion. However, this decomposition does not address potential hardware-specific correlations from tensor-core FMA behavior, shared-memory bank conflicts, or warp-level reductions, which could introduce cross terms that vary with matrix dimensions and block size s; without explicit validation of the independence assumption against measured GPU roundoff for the tested s values, the 0.5% loss-matching guarantee may not transfer.
Authors: We appreciate the referee's observation on the independence assumption in the error model. The decomposition follows the standard floating-point analysis framework (bounding each operation's error by its unit roundoff independently), which is conventional in mixed-precision literature. The nine choices are identified by tracing distinct operations in one CA-SGD outer iteration. We acknowledge that tensor-core and memory-hierarchy effects may introduce correlations outside this model. In the revision we will add an explicit paragraph in §3 stating the assumption, its relation to hardware-specific behavior, and the resulting scope of the transferability claim, supported by references to standard error analysis texts. revision: partial
-
Referee: [§5] the reported 5.1--6.8× speedup and 0.5% loss match are central to the practical claim, yet the manuscript provides no breakdown of how the nine precision choices were mapped to the actual A100 kernels (e.g., which operations used TF32 vs. BF16 accumulation) or ablation showing that altering any one choice violates the error bound; this makes it impossible to confirm that the observed results follow from the analysis rather than from unmodeled hardware effects.
Authors: We agree that a clearer mapping between the nine choices and A100 kernels would strengthen the link between analysis and results. The recipe in §3 directly dictates the mapping: BF16 storage for inputs, FP32 accumulation in tensor-core GEMM for the Gram matrix, FP32 for the communicated Gram matrix, and FP32 for the inner recurrence and updates. In revision we will insert a table in §5 that explicitly lists each of the nine operations, the chosen format/accumulation mode, and the corresponding CUDA/Tensor Core primitive used on A100. A full per-choice ablation would require substantial new runs; however, the error bounds derived in §3 already indicate the necessity of each choice to keep the local error below the observed 0.5% threshold. We will add a short paragraph referencing the bounds to explain why deviations would be expected to increase error. revision: partial
Circularity Check
No circularity: error analysis uses standard roundoff model; results are empirical
full rationale
The paper presents a finite-precision decomposition of CA-SGD rounding error into nine independent choices governed solely by low-precision unit roundoffs, then reports direct experimental loss matching (within 0.5%) and speedups on A100 GPUs. No equation reduces a claimed prediction to a fitted parameter by construction, no load-bearing premise rests on a self-citation chain, and no ansatz is imported via prior work by the same authors. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Floating-point rounding errors in matrix operations can be decomposed into independent contributions from each precision choice and depend only on unit roundoffs
Reference graph
Works this paper leans on
-
[1]
Ahmad Ajalloeian and Sebastian U. Stich. On the convergence of SGD with biased gradients. arXiv preprint arXiv:2008.00051, 2020
arXiv 2008
-
[2]
doi:10.1137/16M1080173 , eprint =
L´ eon Bottou, Frank E. Curtis, and Jorge Nocedal. Optimization methods for large-scale machine learning.SIAM Review, 60(2):223–311, 2018. doi: 10.1137/16M1080173
-
[3]
Erin Carson. The adaptives-step conjugate gradient method.SIAM Journal on Matrix Analysis and Applications, 39(3):1318–1338, 2018. doi: 10.1137/16M1107942
-
[4]
Erin Carson and James Demmel. A residual replacement strategy for improving the maximum attainable accuracy ofs-step Krylov subspace methods.SIAM Journal on Matrix Analysis and Applications, 35(1):22–43, 2014. doi: 10.1137/120893057
-
[5]
Erin Carson and James Demmel. Accuracy of thes-step Lanczos method for the symmetric eigenproblem in finite precision.SIAM Journal on Matrix Analysis and Applications, 36(2): 793–819, 2015. doi: 10.1137/140990735
-
[6]
Erin Carson and Nicholas J. Higham. A new analysis of iterative refinement and its applica- tion to accurate solution of ill-conditioned sparse linear systems.SIAM Journal on Scientific Computing, 39(6):A2834–A2856, 2017. doi: 10.1137/17M1122918
-
[7]
Erin Carson and Nicholas J. Higham. Accelerating the solution of linear systems by iterative refinement in three precisions.SIAM Journal on Scientific Computing, 40(2):A817–A847,
-
[8]
doi: 10.1137/17M1140819
-
[9]
Erin Carson, Nicholas J. Higham, and Srikara Pranesh. Three-precision GMRES-based iter- ative refinement for least squares problems.SIAM Journal on Scientific Computing, 42(6): A4063–A4083, 2020. doi: 10.1137/20M1316822
-
[10]
Erin Carson, Tom´ aˇ s Gergelits, and Ichitaro Yamazaki. Mixed precisions-step Lanczos and conjugate gradient algorithms.Numerical Linear Algebra with Applications, 29(3):e2425, 2022. doi: 10.1002/nla.2425
-
[11]
PhD thesis, University of California, Berkeley, Berkeley, CA, 2015
Erin Claire Carson.Communication-Avoiding Krylov Subspace Methods in Theory and Prac- tice. PhD thesis, University of California, Berkeley, Berkeley, CA, 2015
2015
-
[12]
Ernie Chan, Marcel Heimlich, Avi Purkayastha, and Robert van de Geijn. Collective com- munication: Theory, practice, and experience.Concurrency and Computation: Practice and Experience, 19(13):1749–1783, 2007. doi: 10.1002/cpe.1206
-
[13]
James Demmel, Laura Grigori, Mark Hoemmen, and Julien Langou. Communication-optimal parallel and sequential QR and LU factorizations.SIAM Journal on Scientific Computing, 34 (1):A206–A239, 2012. doi: 10.1137/080731992. 17
-
[14]
James W. Demmel, Michael T. Heath, and Henk A. van der Vorst. Parallel numerical linear algebra. InActa Numerica, volume 2, pages 111–197, Cambridge, UK, 1993. Cambridge University Press. doi: 10.1017/S096249290000235X
-
[15]
Extending SLURM for dynamic resource-aware adaptive batch scheduling,
Aditya Devarakonda and James Demmel. Avoiding communication in logistic regression. In 2020 IEEE 27th International Conference on High Performance Computing, Data, and Ana- lytics (HiPC), pages 91–100. IEEE, 2020. doi: 10.1109/HiPC50609.2020.00023
-
[16]
Aditya Devarakonda and Ramakrishnan Kannan. Communication-efficient, 2d parallel stochas- tic gradient descent for distributed-memory optimization.arXiv preprint arXiv:2501.07526, 2025
Pith/arXiv arXiv 2025
-
[17]
Golub and Charles F
Gene H. Golub and Charles F. Van Loan.Matrix Computations. Johns Hopkins University Press, Baltimore, MD, 4 edition, 2013
2013
-
[18]
Azzam Haidar, Stanimire Tomov, Jack Dongarra, and Nicholas J. Higham. Harnessing GPU tensor cores for fast FP16 arithmetic to speed up mixed-precision iterative refinement solvers. InSC18: International Conference for High Performance Computing, Networking, Storage and Analysis, pages 603–613. IEEE Press, 2018. doi: 10.1109/SC.2018.00050
-
[19]
Higham.Accuracy and Stability of Numerical Algorithms
Nicholas J. Higham.Accuracy and Stability of Numerical Algorithms. SIAM, Philadelphia, PA, 2nd edition, 2002. doi: 10.1137/1.9780898718027
-
[20]
Nicholas J. Higham and Theo Mary. A new approach to probabilistic rounding error analysis. SIAM Journal on Scientific Computing, 41(5):A2815–A2835, 2019. doi: 10.1137/18M1226312
-
[21]
Nicholas J. Higham and Theo Mary. Sharper probabilistic backward error analysis for basic linear algebra kernels with random data.SIAM Journal on Scientific Computing, 42(5):A3427– A3446, 2020. doi: 10.1137/20M1314355
-
[22]
Nicholas J. Higham and Srikara Pranesh. Simulating low precision floating-point arithmetic. SIAM Journal on Scientific Computing, 41(5):C585–C602, 2019. doi: 10.1137/19M1251308
-
[23]
PhD thesis, University of California, Berkeley, Berkeley, CA, 2010
Mark Frederick Hoemmen.Communication-Avoiding Krylov Subspace Methods. PhD thesis, University of California, Berkeley, Berkeley, CA, 2010
2010
-
[24]
A study of BFLOAT16 for deep learning training
Dhiraj Kalamkar, Dheevatsa Mudigere, Naveen Mellempudi, Dipankar Das, Kunal Banerjee, Sasikanth Avancha, Dharma Teja Vooturi, Nataraj Jammalamadaka, Jianyu Huang, Hector Yuen, Jiyan Yang, Jongsoo Park, Alexander Heinecke, Evangelos Georganas, Sudarshan Srini- vasan, Abhisek Kundu, Misha Smelyanskiy, Bharat Kaul, and Pradeep Dubey. A study of BFLOAT16 for ...
Pith/arXiv arXiv 1905
-
[25]
Nelder.Generalized Linear Models
Peter McCullagh and John A. Nelder.Generalized Linear Models. Chapman & Hall, London, UK, 2nd edition, 1989. doi: 10.1007/978-1-4899-3242-6
-
[26]
Mixed precision training
Paulius Micikevicius, Sharan Narang, Jonah Alben, Gregory Diamos, Erich Elsen, David Gar- cia, Boris Ginsburg, Michael Houston, Oleksii Kuchaiev, Ganesh Venkatesh, and Hao Wu. Mixed precision training. InInternational Conference on Learning Representations (ICLR),
-
[27]
URLhttps://openreview.net/forum?id=r1gs9JgRZ
-
[28]
NVIDIA A100 tensor core GPU: Data sheet.https://www.nvidia
NVIDIA Corporation. NVIDIA A100 tensor core GPU: Data sheet.https://www.nvidia. com/content/dam/en-zz/Solutions/Data-Center/a100/pdf/nvidia-a100-datasheet. pdf, 2021. 18
2021
-
[29]
NVIDIA Collective Communications Library (NCCL) documentation
NVIDIA Corporation. NVIDIA Collective Communications Library (NCCL) documentation. https://docs.nvidia.com/deeplearning/nccl/user-guide/docs/env.html, 2024
2024
-
[30]
cuBLAS documentation.https://docs.nvidia.com/cuda/cublas/, 2026
NVIDIA Corporation. cuBLAS documentation.https://docs.nvidia.com/cuda/cublas/, 2026
2026
-
[31]
CUDA Programming Guide.https://docs.nvidia.com/cuda/ cuda-programming-guide/, 2026
NVIDIA Corporation. CUDA Programming Guide.https://docs.nvidia.com/cuda/ cuda-programming-guide/, 2026
2026
-
[32]
Rajeev Thakur, Rolf Rabenseifner, and William Gropp. Optimization of collective communi- cation operations in MPICH.International Journal of High Performance Computing Applica- tions, 19(1):49–66, 2005. doi: 10.1177/1094342005051521
-
[33]
Enhanced cyclic coordinate descent methods for elastic net penalized linear models
Yixiao Wang, Zishan Shao, Ting Jiang, and Aditya Devarakonda. Enhanced cyclic coordinate descent methods for elastic net penalized linear models. InAdvances in Neural Information Processing Systems (NeurIPS), 2025. URLhttps://openreview.net/forum?id=duunKHvWKz. 19
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.