SHIFT: Semantic Harmonization via Index-side Feature Transformation for Multilingual Information Retrieval
Pith reviewed 2026-06-26 19:36 UTC · model grok-4.3
The pith
SHIFT corrects language bias in multilingual retrieval by subtracting estimated language vectors from document embeddings at indexing time.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
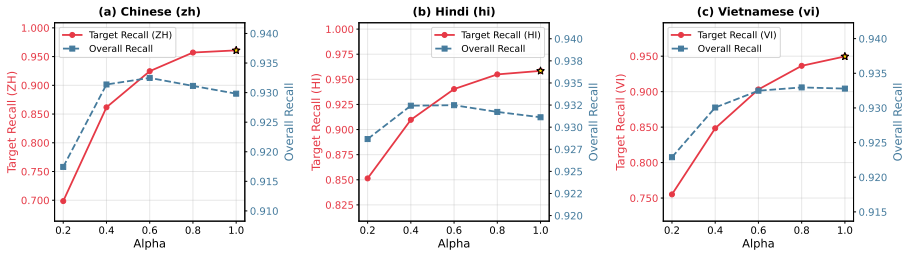
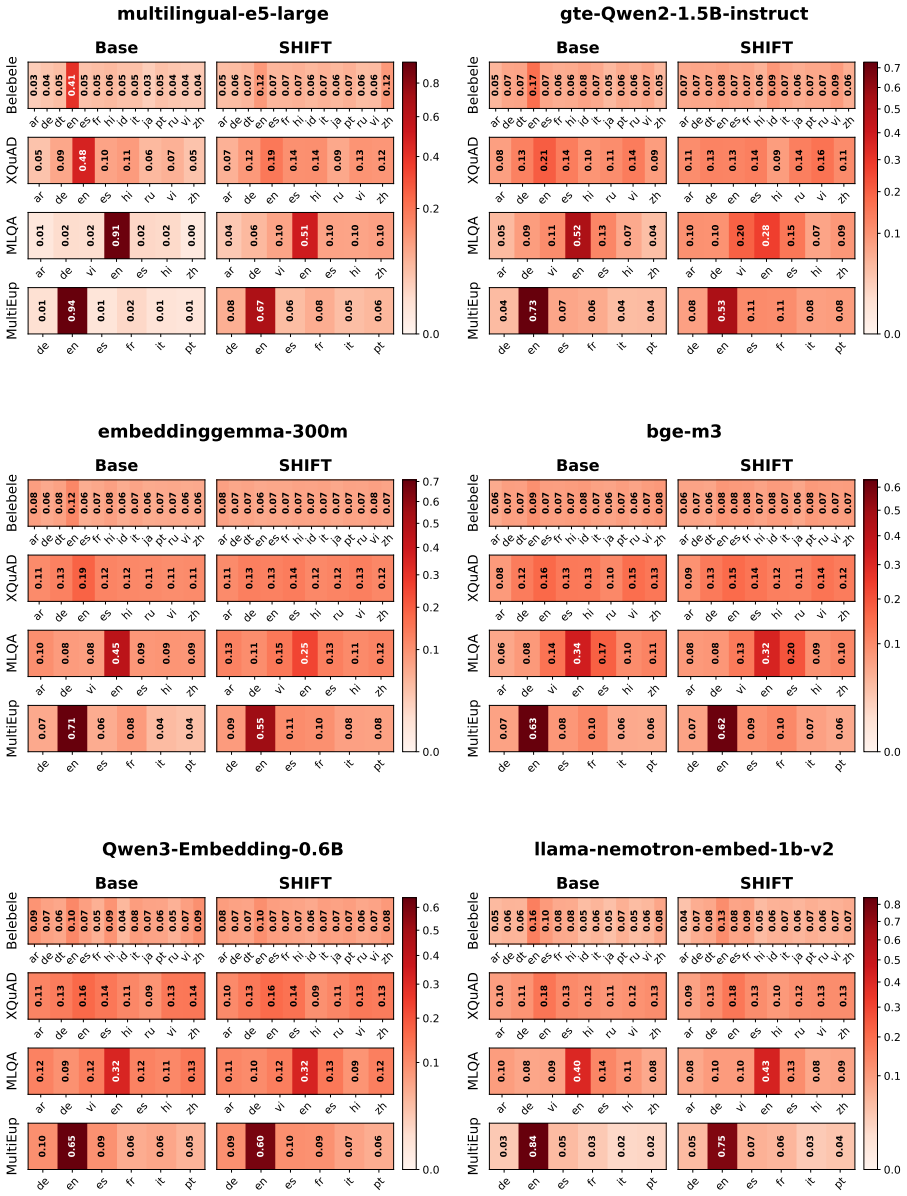
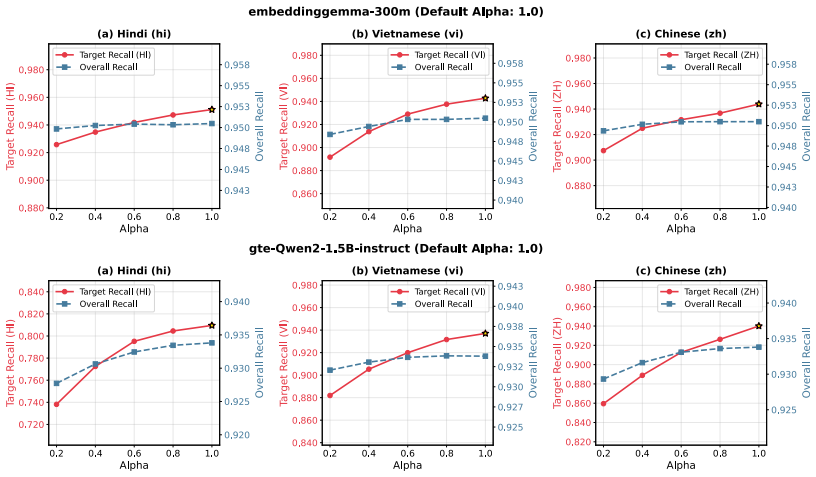
SHIFT estimates a relative language vector for each target language with respect to a source language using parallel translation pairs, then subtracts this vector from document embeddings at indexing time to remove language-specific offsets and reduce bias in multilingual dense retrieval.
What carries the argument
The relative language vector, computed once from parallel translation pairs, that captures and removes the language-specific offset in the embedding space.
If this is right
- Top-ranked results become less dominated by the query language even when relevant content exists in other languages.
- The same correction applies across multiple dense retrieval models without requiring model-specific retraining.
- Indexing-stage adjustment improves performance on existing MLIR benchmarks that test cross-language relevance.
- No additional parameters or training data beyond the parallel pairs are needed at inference time.
Where Pith is reading between the lines
- The same offset-subtraction idea could be tested on other embedding biases such as domain or temporal shifts if suitable parallel data exists.
- Dynamic per-query scaling of the vector might further refine results when language preference varies by topic.
- The method could be combined with query-side normalization to handle cases where both query and documents carry language offsets.
Load-bearing premise
Subtracting the estimated language vector removes bias while preserving the semantic similarity signals needed for accurate retrieval.
What would settle it
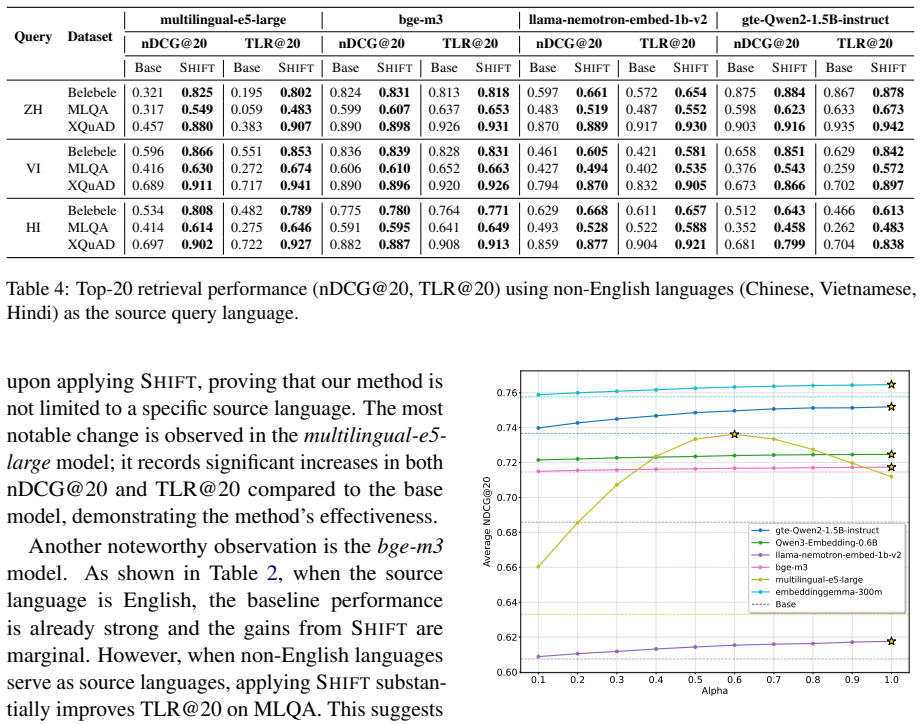
Apply SHIFT to a standard multilingual dense retriever on one of the four MLIR benchmarks and measure whether same-language documents still dominate the top ranks or whether nDCG drops compared with the uncorrected baseline.
Figures




read the original abstract
With the rapid expansion of massive multilingual corpora, Multilingual Information Retrieval (MLIR) has emerged as a critical technology for global information access. MLIR enables users to retrieve semantically relevant documents from multilingual text collections using a single-language query. However, recent multilingual dense retrieval models often exhibit a strong preference for documents in the same language as the query. This leads to severe language bias, where top-ranked results are dominated by documents of specific languages, even when documents in other languages contain more semantically relevant information. To address this issue, we propose SHIFT, a training-free method applicable in the indexing stage. Specifically, SHIFT utilizes parallel translation pairs to estimate a relative language vector for each target language with respect to a source language. Subsequently, SHIFT corrects the language-specific offset by subtracting this relative language vector from document embeddings during indexing. Our comprehensive evaluation across four MLIR benchmarks and diverse dense retrieval models confirms that SHIFT can effectively mitigate language bias and enhance MLIR performance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes SHIFT, a training-free index-side method for multilingual dense retrieval. It estimates one relative language vector per target language as the mean embedding difference over parallel translation pairs, then subtracts this vector from every document embedding of that language before indexing. The central claim is that this correction mitigates language bias (same-language preference) and improves retrieval effectiveness on four MLIR benchmarks across multiple dense models.
Significance. A training-free, index-time correction that demonstrably isolates language offset from semantic content would be a practical contribution to MLIR, especially for large corpora where retraining is costly. The approach builds on standard use of parallel data but would need to show that the estimated vector is stable across domains and preserves intra-language similarity structure.
major comments (2)
- [Abstract] Abstract: the claim of effectiveness after 'comprehensive evaluation across four MLIR benchmarks' is unsupported because no quantitative results, metrics, or error analysis are supplied, and the computation of the relative language vector is not described.
- [Method] Method description (parallel-pair estimation step): the manuscript does not provide evidence that the mean difference vector isolates a content-independent language offset rather than conflating language with topic-specific effects; without domain-stability checks or post-correction similarity preservation tests, the subtraction step risks distorting rankings instead of correcting bias.
minor comments (2)
- [Abstract] The abstract should at minimum state the four benchmarks and the retrieval models used.
- Notation for the estimated vector and the subtraction operation should be introduced with an equation.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. We address each major comment below and indicate the revisions planned for the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim of effectiveness after 'comprehensive evaluation across four MLIR benchmarks' is unsupported because no quantitative results, metrics, or error analysis are supplied, and the computation of the relative language vector is not described.
Authors: We agree that the abstract would benefit from greater specificity. In the revised manuscript we will expand the abstract to report key quantitative improvements (e.g., average nDCG@10 and MRR gains across the four benchmarks and models) and to state explicitly that the relative language vector is computed as the mean embedding difference over parallel translation pairs. The full experimental results, metrics, and error analysis already appear in Sections 4 and 5; the abstract revision will simply surface the most salient numbers. revision: yes
-
Referee: [Method] Method description (parallel-pair estimation step): the manuscript does not provide evidence that the mean difference vector isolates a content-independent language offset rather than conflating language with topic-specific effects; without domain-stability checks or post-correction similarity preservation tests, the subtraction step risks distorting rankings instead of correcting bias.
Authors: Because the estimation is performed exclusively on parallel translation pairs that share identical semantic content, the mean difference is designed to isolate language-specific offsets. We acknowledge, however, that explicit validation of this assumption strengthens the contribution. In the revision we will add (i) a short analysis showing that intra-language cosine similarities are largely preserved after subtraction and (ii) a stability check of the estimated vectors across the four benchmarks, which already span distinct domains. Full cross-domain stability experiments on entirely new corpora would require additional parallel data collection and are noted as future work. revision: partial
Circularity Check
No circularity: method uses external parallel data without self-referential fitting or derivation
full rationale
The paper proposes SHIFT as a training-free indexing correction that estimates a relative language vector from external parallel translation pairs and subtracts it from document embeddings. No step reduces by construction to the paper's own fitted parameters, self-citations, or target-task data; the vector estimation is performed on independent parallel corpora, and performance claims rest on separate benchmark evaluations rather than any tautological renaming or prediction-from-fit. The core assumption (uniform additive offset) is an external modeling choice, not a self-derived result.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
IEEE Data Eng
Modern information retrieval: A brief overview , author=. IEEE Data Eng. Bull. , volume=
-
[2]
ACM computing surveys (CSUR) , volume=
Information retrieval on the web , author=. ACM computing surveys (CSUR) , volume=. 2000 , publisher=
2000
-
[3]
Advances in neural information processing systems , volume=
Retrieval-augmented generation for knowledge-intensive nlp tasks , author=. Advances in neural information processing systems , volume=
-
[4]
arXiv preprint arXiv:2312.10997 , volume=
Retrieval-augmented generation for large language models: A survey , author=. arXiv preprint arXiv:2312.10997 , volume=
-
[5]
arXiv preprint arXiv:2501.09136 , year=
Agentic retrieval-augmented generation: A survey on agentic rag , author=. arXiv preprint arXiv:2501.09136 , year=
-
[6]
Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing , pages=
Cross-lingual sentence embedding using multi-task learning , author=. Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing , pages=
2021
-
[7]
Proceedings of the AAAI conference on artificial intelligence , volume=
Mind the gap: Cross-lingual information retrieval with hierarchical knowledge enhancement , author=. Proceedings of the AAAI conference on artificial intelligence , volume=
-
[8]
Proceedings of the 19th annual international ACM SIGIR conference on Research and development in information retrieval , pages=
Querying across languages: A dictionary-based approach to multilingual information retrieval , author=. Proceedings of the 19th annual international ACM SIGIR conference on Research and development in information retrieval , pages=
-
[9]
Proceedings of the 2021 Conference on Empirical Methods in Natural Language , pages=
IR like a SIR: Sense-enhanced information retrieval for multiple languages , author=. Proceedings of the 2021 Conference on Empirical Methods in Natural Language , pages=
2021
-
[10]
Workshop of the Cross-Language Evaluation Forum for European Languages , pages=
CLEF 2002—Overview of results , author=. Workshop of the Cross-Language Evaluation Forum for European Languages , pages=. 2002 , organization=
2002
-
[11]
European Conference on Information Retrieval , pages=
HC4: A new suite of test collections for ad hoc CLIR , author=. European Conference on Information Retrieval , pages=. 2022 , organization=
2022
-
[12]
, author=
Overview of the NTCIR-7 ACLIA Tasks: Advanced Cross-Lingual Information Access. , author=. NTCIR , year=
-
[13]
, author=
The Importance of Evaluation for Cross-Language System Development: the CLEF Experience. , author=. LREC , year=
-
[14]
Proceedings of the Fourth Workshop on Multilingual Representation Learning (MRL 2024) , pages=
Language Bias in Multilingual Information Retrieval: The Nature of the Beast and Mitigation Methods , author=. Proceedings of the Fourth Workshop on Multilingual Representation Learning (MRL 2024) , pages=
2024
-
[15]
The Fourteenth International Conference on Learning Representations , year=
Improving Semantic Proximity in English-Centric Information Retrieval through Cross-Lingual Alignment , author=. The Fourteenth International Conference on Learning Representations , year=
-
[16]
European Conference on Information Retrieval , pages=
Neural approaches to multilingual information retrieval , author=. European Conference on Information Retrieval , pages=. 2023 , organization=
2023
-
[17]
Proceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval , pages=
Language fairness in multilingual information retrieval , author=. Proceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval , pages=
-
[18]
Findings of the Association for Computational Linguistics: ACL 2023 , pages=
Language agnostic multilingual information retrieval with contrastive learning , author=. Findings of the Association for Computational Linguistics: ACL 2023 , pages=
2023
-
[19]
Proceedings of the 46th International ACM SIGIR Conference on Research and Development in Information Retrieval , pages=
Soft prompt decoding for multilingual dense retrieval , author=. Proceedings of the 46th International ACM SIGIR Conference on Research and Development in Information Retrieval , pages=
-
[20]
2025 , eprint=
Investigating Language Preference of Multilingual RAG Systems , author=. 2025 , eprint=
2025
-
[21]
Faux Polyglot: A Study on Information Disparity in Multilingual Large Language Models
Sharma, Nikhil and Murray, Kenton and Xiao, Ziang. Faux Polyglot: A Study on Information Disparity in Multilingual Large Language Models. Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers). 2025. doi:10.18653/v1/2025.naacl-long.411
-
[22]
2022 , eprint=
mMARCO: A Multilingual Version of the MS MARCO Passage Ranking Dataset , author=. 2022 , eprint=
2022
-
[23]
CLEF 2001 --- Overview of Results
Braschler, Martin. CLEF 2001 --- Overview of Results. Evaluation of Cross-Language Information Retrieval Systems. 2002
2001
-
[24]
Proceedings of the 26th annual international ACM SIGIR conference on Research and development in informaion retrieval , pages=
Probabilistic structured query methods , author=. Proceedings of the 26th annual international ACM SIGIR conference on Research and development in informaion retrieval , pages=
-
[25]
Computational Linguistics , volume=
Embedding web-based statistical translation models in cross-language information retrieval , author=. Computational Linguistics , volume=. 2003 , publisher=
2003
-
[26]
Proceedings of the 25th annual international ACM SIGIR conference on Research and development in information retrieval , pages=
Comparing cross-language query expansion techniques by degrading translation resources , author=. Proceedings of the 25th annual international ACM SIGIR conference on Research and development in information retrieval , pages=
-
[27]
2014 , publisher=
Multilingual information management: Information, technology and translators , author=. 2014 , publisher=
2014
-
[28]
European Conference on Information Retrieval , pages=
Should MT systems be used as black boxes in CLIR? , author=. European Conference on Information Retrieval , pages=. 2011 , organization=
2011
-
[29]
Information Retrieval Journal , volume=
Multilingual information retrieval in the language modeling framework , author=. Information Retrieval Journal , volume=. 2015 , publisher=
2015
-
[30]
2012 , publisher=
Multilingual information retrieval: From research to practice , author=. 2012 , publisher=
2012
-
[31]
Information Retrieval , volume=
An effective and efficient results merging strategy for multilingual information retrieval in federated search environments , author=. Information Retrieval , volume=. 2008 , publisher=
2008
-
[32]
Proceedings of the 31st annual international ACM SIGIR conference on Research and development in information retrieval , pages=
A study of learning a merge model for multilingual information retrieval , author=. Proceedings of the 31st annual international ACM SIGIR conference on Research and development in information retrieval , pages=
-
[33]
Unsupervised Cross-lingual Representation Learning at Scale
Conneau, Alexis and Khandelwal, Kartikay and Goyal, Naman and Chaudhary, Vishrav and Wenzek, Guillaume and Guzm \'a n, Francisco and Grave, Edouard and Ott, Myle and Zettlemoyer, Luke and Stoyanov, Veselin. Unsupervised Cross-lingual Representation Learning at Scale. Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. ...
-
[34]
2025 , eprint=
Llama-Embed-Nemotron-8B: A Universal Text Embedding Model for Multilingual and Cross-Lingual Tasks , author=. 2025 , eprint=
2025
-
[35]
Findings of the Association for Computational Linguistics: ACL 2024 , pages =
Chen, Jianlyu and Xiao, Shitao and Zhang, Peitian and Luo, Kun and Lian, Defu and Liu, Zheng. M 3-Embedding: Multi-Linguality, Multi-Functionality, Multi-Granularity Text Embeddings Through Self-Knowledge Distillation. Findings of the Association for Computational Linguistics: ACL 2024. 2024. doi:10.18653/v1/2024.findings-acl.137
-
[36]
2024 , eprint=
Arctic-Embed 2.0: Multilingual Retrieval Without Compromise , author=. 2024 , eprint=
2024
-
[37]
Distillation for Multilingual Information Retrieval , url=
Yang, Eugene and Lawrie, Dawn and Mayfield, James , year=. Distillation for Multilingual Information Retrieval , url=. doi:10.1145/3626772.3657955 , booktitle=
-
[38]
A Simple and Effective Method To Eliminate the Self Language Bias in Multilingual Representations
Yang, Ziyi and Yang, Yinfei and Cer, Daniel and Darve, Eric. A Simple and Effective Method To Eliminate the Self Language Bias in Multilingual Representations. Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing. 2021. doi:10.18653/v1/2021.emnlp-main.470
-
[39]
2022 , eprint=
Unsupervised Context Aware Sentence Representation Pretraining for Multi-lingual Dense Retrieval , author=. 2022 , eprint=
2022
-
[40]
Discovering Low-rank Subspaces for Language-agnostic Multilingual Representations
Xie, Zhihui and Zhao, Handong and Yu, Tong and Li, Shuai. Discovering Low-rank Subspaces for Language-agnostic Multilingual Representations. Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing. 2022. doi:10.18653/v1/2022.emnlp-main.379
-
[41]
The Belebele Benchmark: a Parallel Reading Comprehension Dataset in 122 Language Variants
Bandarkar, Lucas and Liang, Davis and Muller, Benjamin and Artetxe, Mikel and Shukla, Satya Narayan and Husa, Donald and Goyal, Naman and Krishnan, Abhinandan and Zettlemoyer, Luke and Khabsa, Madian. The Belebele Benchmark: a Parallel Reading Comprehension Dataset in 122 Language Variants. Proceedings of the 62nd Annual Meeting of the Association for Com...
2024
-
[42]
arXiv preprint arXiv:1910.07475 , year=
MLQA: Evaluating Cross-lingual Extractive Question Answering , author=. arXiv preprint arXiv:1910.07475 , year=
arXiv 1910
-
[43]
On the Cross-lingual Transferability of Monolingual Representations , url=
Artetxe, Mikel and Ruder, Sebastian and Yogatama, Dani , year=. On the Cross-lingual Transferability of Monolingual Representations , url=. doi:10.18653/v1/2020.acl-main.421 , booktitle=
-
[44]
2022 , eprint=
No Language Left Behind: Scaling Human-Centered Machine Translation , author=. 2022 , eprint=
2022
-
[45]
SQuAD: 100,000+ Questions for Machine Comprehension of Text
Rajpurkar, Pranav and Zhang, Jian and Lopyrev, Konstantin and Liang, Percy. SQ u AD : 100,000+ Questions for Machine Comprehension of Text. Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing. 2016. doi:10.18653/v1/D16-1264. 1606.05250 , archivePrefix=
work page internal anchor Pith review Pith/arXiv arXiv doi:10.18653/v1/d16-1264 2016
-
[46]
2025 , eprint=
Improving Korean-English Cross-Lingual Retrieval: A Data-Centric Study of Language Composition and Model Merging , author=. 2025 , eprint=
2025
-
[47]
arXiv preprint arXiv:2509.20354 , year=
Embeddinggemma: Powerful and lightweight text representations , author=. arXiv preprint arXiv:2509.20354 , year=
-
[48]
2024 , eprint=
Multilingual E5 Text Embeddings: A Technical Report , author=. 2024 , eprint=
2024
-
[49]
2024 , eprint=
BGE M3-Embedding: Multi-Lingual, Multi-Functionality, Multi-Granularity Text Embeddings Through Self-Knowledge Distillation , author=. 2024 , eprint=
2024
-
[50]
arXiv preprint arXiv:2506.05176 , year=
Qwen3 Embedding: Advancing Text Embedding and Reranking Through Foundation Models , author=. arXiv preprint arXiv:2506.05176 , year=
-
[51]
arXiv preprint arXiv:2308.03281 , year=
Towards general text embeddings with multi-stage contrastive learning , author=. arXiv preprint arXiv:2308.03281 , year=
-
[52]
2025 , eprint=
MMTEB: Massive Multilingual Text Embedding Benchmark , author=. 2025 , eprint=
2025
-
[53]
2025 , eprint=
Gemini Embedding: Generalizable Embeddings from Gemini , author=. 2025 , eprint=
2025
-
[54]
m T 5: A Massively Multilingual Pre-trained Text-to-Text Transformer
Xue, Linting and Constant, Noah and Roberts, Adam and Kale, Mihir and Al-Rfou, Rami and Siddhant, Aditya and Barua, Aditya and Raffel, Colin. m T 5: A Massively Multilingual Pre-trained Text-to-Text Transformer. Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. 2...
-
[55]
2023 , eprint=
NeuralMind-UNICAMP at 2022 TREC NeuCLIR: Large Boring Rerankers for Cross-lingual Retrieval , author=. 2023 , eprint=
2022
-
[56]
2025 , eprint=
Overview of the TREC 2024 NeuCLIR Track , author=. 2025 , eprint=
2024
-
[57]
2025 , eprint=
HLTCOE at TREC 2024 NeuCLIR Track , author=. 2025 , eprint=
2024
-
[58]
Proceedings of the 2022 ACM SIGIR International Conference on Theory of Information Retrieval , pages=
Language-Preference-Based Re-ranking for Multilingual Swahili Information Retrieval , author=. Proceedings of the 2022 ACM SIGIR International Conference on Theory of Information Retrieval , pages=
2022
-
[59]
On the Language Neutrality of Pre-trained Multilingual Representations
Libovick \'y , Jind r ich and Rosa, Rudolf and Fraser, Alexander. On the Language Neutrality of Pre-trained Multilingual Representations. Findings of the Association for Computational Linguistics: EMNLP 2020. 2020. doi:10.18653/v1/2020.findings-emnlp.150
-
[60]
Zhang, Xinyu and Ma, Xueguang and Shi, Peng and Lin, Jimmy. Mr. T y D i: A Multi-lingual Benchmark for Dense Retrieval. Proceedings of the 1st Workshop on Multilingual Representation Learning. 2021. doi:10.18653/v1/2021.mrl-1.12
-
[61]
MIRACL : A Multilingual Retrieval Dataset Covering 18 Diverse Languages
Zhang, Xinyu and Thakur, Nandan and Ogundepo, Odunayo and Kamalloo, Ehsan and Alfonso-Hermelo, David and Li, Xiaoguang and Liu, Qun and Rezagholizadeh, Mehdi and Lin, Jimmy. MIRACL : A Multilingual Retrieval Dataset Covering 18 Diverse Languages. Transactions of the Association for Computational Linguistics. 2023. doi:10.1162/tacl_a_00595
-
[62]
LAR e QA : Language-Agnostic Answer Retrieval from a Multilingual Pool
Roy, Uma and Constant, Noah and Al-Rfou, Rami and Barua, Aditya and Phillips, Aaron and Yang, Yinfei. LAR e QA : Language-Agnostic Answer Retrieval from a Multilingual Pool. Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP). 2020. doi:10.18653/v1/2020.emnlp-main.477
-
[63]
Journal of the ACM (JACM) , volume=
An optimal algorithm for approximate nearest neighbor searching fixed dimensions , author=. Journal of the ACM (JACM) , volume=. 1998 , publisher=
1998
-
[64]
Advances in neural information processing systems , volume=
An investigation of practical approximate nearest neighbor algorithms , author=. Advances in neural information processing systems , volume=
-
[65]
, author=
Cosine similarity scoring without score normalization techniques. , author=. Odyssey , volume=
-
[66]
2025 , eprint=
NeuCLIRBench: A Modern Evaluation Collection for Monolingual, Cross-Language, and Multilingual Information Retrieval , author=. 2025 , eprint=
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.