Mitigating Scoring Errors and Compensating for Nonverbal Subtests in Speech-Based Dementia Assessment
Pith reviewed 2026-06-26 19:30 UTC · model grok-4.3
The pith
Models fusing transcript scores and speech embeddings from verbal subtests can approximate expert overall dementia ratings despite omitting motor subtests.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Integrating transcript-derived scores and Whisper embeddings per verbal subtest produces fused representations that can approximate the expert overall rating of the Syndrom-Kurz-Test even when the nonverbal motor subtests are omitted, while also reducing the impact of transcription errors on the verbal subtests.
What carries the argument
Fused per-subtest representations that combine transcript-derived scores with Whisper speech embeddings from the verbal portions of the test.
If this is right
- Scoring of verbal subtests can be made more robust to transcription mistakes without human review.
- Overall test ratings remain usable for group discrimination even when motor subtests cannot be administered.
- Speech data alone becomes sufficient to produce ratings that track expert judgments across cognitive status categories.
- The same fused representations support both error mitigation on recorded subtests and compensation for entirely missing subtests.
Where Pith is reading between the lines
- The approach could be tested on other mixed verbal-nonverbal screening instruments to see whether verbal speech features routinely proxy motor performance.
- Deployment in telehealth settings would allow full test approximation from audio recordings without requiring in-person motor tasks.
- Longitudinal monitoring might become feasible if repeated speech samples can track changes in the approximated total score.
Load-bearing premise
The verbal subtests alone carry enough information for a model to recover the contribution that the omitted motor subtests would have made to the expert total score.
What would settle it
A direct head-to-head comparison on the same patients showing that the speech-only model predictions diverge substantially from the expert ratings once the motor subtest scores are added back into the ground truth.
Figures


read the original abstract
Early detection of cognitive impairment relies on neuropsychological tests to minimize subjectivity by assessing multiple cognitive domains. Speech-based evaluation can support diagnostics and improve accessibility, but transcription errors and the omission of nonverbal subtests (e.g., motor skills) limit accuracy. Beyond conventional test scores, speech-derived features can provide additional insights into cognitive status. This study investigates the speech-based evaluation of the German "Syndrom-Kurz-Test," a standardized dementia screening test comprising verbal and motor subtests. We train models that integrate transcript-derived scores and Whisper embeddings per verbal subtest to reduce scoring errors. To compensate for missing motor subtests, we then leverage these fused representations to approximate expert overall ratings. Despite omitting subtests, our models strongly correlate with expert ratings and efficiently and accurately discriminate between cognitive status groups.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript investigates speech-based evaluation of the German Syndrom-Kurz-Test for dementia screening. It trains models that fuse transcript-derived scores with Whisper embeddings from verbal subtests to mitigate scoring errors, then uses these representations to approximate the expert overall rating and thereby compensate for omitted nonverbal motor subtests. The central claim is that, despite the omissions, the resulting models achieve strong correlation with expert ratings and accurate, efficient discrimination between cognitive-status groups.
Significance. If the compensation mechanism proves robust, the work could improve accessibility of standardized dementia screening by enabling fully speech-based administration without loss of diagnostic utility. The use of Whisper embeddings to augment conventional scores is a constructive application of modern speech models. The result would be practically relevant for remote or low-resource settings, provided the approximation recovers sufficient variance from the omitted motor subtests.
major comments (2)
- [Abstract / §3] Abstract and §3 (Methods): the claim that fused verbal-only features can approximate the expert overall rating (which incorporates motor subtests) is load-bearing for both the correlation and discrimination results, yet no quantitative validation of this approximation—such as a comparison of verbal-only predictions versus full-test expert ratings or an analysis of residual variance attributable to motor subtests—is described.
- [Results] Results section: the reported 'strong correlation' and 'accurate discrimination' lack accompanying details on dataset size, cross-validation procedure, confidence intervals, or baseline comparisons (e.g., verbal-only vs. full-test performance), preventing assessment of whether the compensation step actually preserves diagnostic fidelity.
minor comments (2)
- [§3] Clarify the exact fusion architecture (how transcript scores and Whisper embeddings are combined per subtest) and the loss function used for the approximation step.
- [Results] Add a table or figure showing per-subtest contributions and the effect of omitting motor subtests on the final correlation and AUC metrics.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below and will revise the manuscript accordingly to improve clarity and completeness.
read point-by-point responses
-
Referee: [Abstract / §3] Abstract and §3 (Methods): the claim that fused verbal-only features can approximate the expert overall rating (which incorporates motor subtests) is load-bearing for both the correlation and discrimination results, yet no quantitative validation of this approximation—such as a comparison of verbal-only predictions versus full-test expert ratings or an analysis of residual variance attributable to motor subtests—is described.
Authors: We agree that the manuscript would benefit from an explicit quantitative validation of the approximation step. In the revised version we will add a direct comparison of the verbal-only fused predictions against the full expert ratings (including motor subtests), together with an analysis of residual variance attributable to the omitted motor components. revision: yes
-
Referee: [Results] Results section: the reported 'strong correlation' and 'accurate discrimination' lack accompanying details on dataset size, cross-validation procedure, confidence intervals, or baseline comparisons (e.g., verbal-only vs. full-test performance), preventing assessment of whether the compensation step actually preserves diagnostic fidelity.
Authors: We will expand the Results section to report dataset size, the cross-validation procedure, confidence intervals for all correlation and discrimination metrics, and explicit baseline comparisons (verbal-only fused model versus full-test performance) so that readers can evaluate the fidelity of the compensation. revision: yes
Circularity Check
No circularity; standard supervised approximation of expert ratings from verbal features
full rationale
The paper trains models on transcript-derived scores plus Whisper embeddings from verbal subtests to predict expert overall ratings (which incorporate omitted motor subtests). This is a conventional supervised regression setup with an external target variable; the prediction is not defined in terms of itself, nor does any fitted parameter get renamed as a prediction. No equations, self-citations, or uniqueness theorems appear in the abstract or description. The central claim remains an empirical correlation result rather than a definitional reduction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Speech-based assessments offer a non-invasive, cost-effective, and accessible approach that, in addition to automating clinical protocols, can yield dementia-related biomarkers
Introduction Gold standard dementia screening relies on neuropsycholog- ical tests, which, together with medical biomarkers, reduce subjectivity by quantifying performance across multiple cogni- tive domains (e.g., memory, language, and motor functioning). Speech-based assessments offer a non-invasive, cost-effective, and accessible approach that, in addi...
-
[2]
Related Work Research in speech-based dementia assessment mainly focuses on two principal approaches: (1) the feature extraction from elicited speech (e.g., picture descriptions) to predict and classify cognitive impairment utilizing established assessment scales [1, 2, 3, 4, 5] such as the MMSE [6] and MoCA [7]; and (2) the application of speech processi...
Pith/arXiv arXiv 2026
-
[3]
Demographic data for the diagnostic groups of no cognitive impairment (NCI), mild cognitive impairment (MCI), and dementia (DEM) is listed in [18, Table 1]
Data We use a subset of the corpus introduced in [13], which com- prises 158 German-speaking subjects (63 men, 95 women) aged between 49 and 89 years (µ= 73.69±9.02). Demographic data for the diagnostic groups of no cognitive impairment (NCI), mild cognitive impairment (MCI), and dementia (DEM) is listed in [18, Table 1]. All tests and recordings were con...
-
[4]
ABBABA
Method 4.1. Whisper Transcripts and Embeddings Table 1:Syndrom-Kurz-Test (SKT) verbal (/commen◎-do◎s) and motor (/hand-paper) subtests 1–9: WER (in %) for the whisper models (small and large-v3), and Pearson Correlation (r) with the SKT total score. SKT task function scoring small large r /commen◎-do◎s1naming attention 0-60 sec 45.3 27.5 .47 /commen◎-do◎s...
-
[5]
To assess model performance, we employ stratified five-fold cross-validation, partitioning the dataset into five speaker-distinct training (80%) and test (20%) sets
Experiments All experiments were conducted usingwhisper-smalland whisper-large-v3transcripts and their underlying en- coder and decoder embeddings. To assess model performance, we employ stratified five-fold cross-validation, partitioning the dataset into five speaker-distinct training (80%) and test (20%) sets. We use Root Mean Square Error (RMSE) to qua...
-
[6]
that only receive the encoder or decoder embeddings without RB inputs to investigate whether the scores can also be learned from embeddings alone. 5.2. Compensating for Nonverbal Subtests In order to enable efficient and accurate speech-based demen- tia assessment without motor subtests, we are investigating the subtest sequence that maximizes the overall...
-
[7]
component balancing
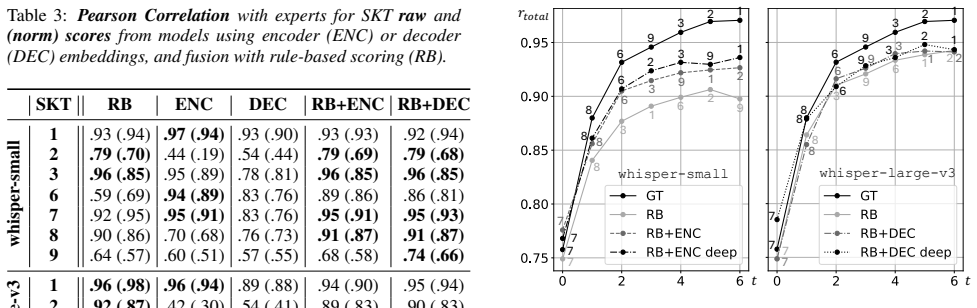
Results 6.1. Mitigating Transcription-Related Scoring Errors The results for thedeep correctionmodels (Sec. 5.1) are given as RMSE in Table 2 and Pearson correlation Table 3. The pre- Table 2:AverageRMSE and STDfor SKTraw scoresfrom models using encoder (ENC) or decoder (DEC) embeddings, and fusion with rule-based scoring (RB). SKT RB ENC DEC RB+ENC RB+DE...
-
[8]
Using data from routine clinical practice, we observed that ourdeep correctionmodels can mitigate scoring errors for the automated evaluation of the SKT
Conclusion We have introduced mitigation methods that utilize both tran- scripts and their embedded encoder and decoder representa- tions to improve robustness in speech-only dementia assess- ment. Using data from routine clinical practice, we observed that ourdeep correctionmodels can mitigate scoring errors for the automated evaluation of the SKT. Furth...
-
[9]
Acknowledgments Funded by the Deutsche Forschungsgemeinschaft (DFG) – Project Number 549142762 – FIP 160
-
[10]
Generative AI Use Disclosure Generative AI tools were used only for editing and polishing the manuscript; all scientific content, analyses, and conclusions are the responsibility of the authors
-
[11]
Alzheimer’s Dementia Recognition Through Spontaneous Speech: The ADReSS Challenge,
S. Luz, F. Haider, S. d. l. Fuente, D. Fromm, and B. MacWhin- ney, “Alzheimer’s Dementia Recognition Through Spontaneous Speech: The ADReSS Challenge,” inInterspeech 2020. ISCA, 2020, pp. 2172–2176
2020
-
[12]
Detecting Cognitive Decline Using Speech Only: The ADReSSo Challenge,
——, “Detecting Cognitive Decline Using Speech Only: The ADReSSo Challenge,” inInterspeech 2021. ISCA, Aug. 2021, pp. 3780–3784
2021
-
[13]
Multilingual alzheimer’s dementia recognition through spontaneous speech: a signal processing grand chal- lenge,
S. Luz, F. Haider, D. Fromm, I. Lazarou, I. Kompatsiaris, and B. MacWhinney, “Multilingual alzheimer’s dementia recognition through spontaneous speech: a signal processing grand chal- lenge,” 2023
2023
-
[14]
The interspeech 2024 taukadial challenge: Multilingual mild cognitive impairment detection with multimodal approach,
B. Barrera-Altuna, D. Lee, Z. Zarnaz, J. Han, and S. Kim, “The interspeech 2024 taukadial challenge: Multilingual mild cognitive impairment detection with multimodal approach,” inInterspeech 2024, 2024, pp. 967–971
2024
-
[15]
Clas- sifying Dementia in the Presence of Depression: A Cross-Corpus Study,
F. Braun, S. P. Bayerl, P. A. P ´erez-Toro, F. H ¨onig, H. Lehfeld, T. Hillemacher, E. N¨oth, T. Bocklet, and K. Riedhammer, “Clas- sifying Dementia in the Presence of Depression: A Cross-Corpus Study,” inProc. INTERSPEECH 2023, 2023, pp. 2308–2312
2023
-
[16]
“Mini-mental state
M. F. Folstein, S. E. Folstein, and P. R. McHugh, ““Mini-mental state” - a practical method for grading the cognitive state of pa- tients for the clinician,”Journal of Psychiatric Research, vol. 12, no. 3, pp. 189–198, 1975
1975
-
[17]
The Montreal Cognitive Assessment, MoCA: A Brief Screening Tool For Mild Cognitive Impairment,
Z. S. Nasreddine, N. A. Phillips, V . B ´edirian, S. Charbonneau, V . Whitehead, I. Collin, J. L. Cummings, and H. Chertkow, “The Montreal Cognitive Assessment, MoCA: A Brief Screening Tool For Mild Cognitive Impairment,”Journal of the American Geri- atrics Society, vol. 53, no. 4, pp. 695–699, Apr. 2005
2005
-
[18]
Telephone-based dementia screening i: Automated semantic verbal fluency assessment,
J. Tr ¨oger, N. Linz, A. K ¨onig, P. Robert, and J. Alexanders- son, “Telephone-based dementia screening i: Automated semantic verbal fluency assessment,” inProceedings of Pervasive Health, 2018, p. 59–66
2018
-
[19]
Fully Automatic Speech-Based Analysis of the Se- mantic Verbal Fluency Task,
A. K ¨onig, N. Linz, J. Tr ¨oger, M. Wolters, J. Alexandersson, and P. Robert, “Fully Automatic Speech-Based Analysis of the Se- mantic Verbal Fluency Task,”Dementia and Geriatric Cognitive Disorders, vol. 45, no. 3-4, pp. 198–209, 2018
2018
-
[20]
Automatic scoring of semantic fluency,
N. Kim, J.-H. Kim, M. K. Wolters, S. E. MacPherson, and J. C. Park, “Automatic scoring of semantic fluency,”Frontiers in Psy- chology, vol. 10, 2019
2019
-
[21]
Reliability and validity of alzheimer’s disease screening with a semi-automated smartphone application using verbal flu- ency,
S. J. Kwon, H. S. Kim, J. H. Han, J. B. Bae, J. W. Han, and K. W. Kim, “Reliability and validity of alzheimer’s disease screening with a semi-automated smartphone application using verbal flu- ency,”Frontiers in Neurology, vol. 12, 2021
2021
-
[22]
Breaking the flow of thought: In- crease of empty pauses in the connected speech of people with mild and moderate Alzheimer’s disease,
M. Lofgren and W. Hinzen, “Breaking the flow of thought: In- crease of empty pauses in the connected speech of people with mild and moderate Alzheimer’s disease,”Journal of Communica- tion Disorders, vol. 97, p. 106214, May 2022
2022
-
[23]
Automated Evaluation of Standardized Dementia Screening Tests,
F. Braun, M. F ¨orstel, B. Oppermann, A. Erzigkeit, H. Lehfeld, T. Hillemacher, and K. Riedhammer, “Automated Evaluation of Standardized Dementia Screening Tests,” inProc. Interspeech 2022, 2022, pp. 2478–2482
2022
-
[24]
Going Beyond the Cookie Theft Picture Test: Detecting Cognitive Impairments Using Acoustic Features,
F. Braun, A. Erzigkeit, H. Lehfeld, T. Hillemacher, K. Riedham- mer, and S. P. Bayerl, “Going Beyond the Cookie Theft Picture Test: Detecting Cognitive Impairments Using Acoustic Features,” inText, Speech, and Dialogue, P. Sojka, A. Hor ´ak, I. Kope ˇcek, and K. Pala, Eds. Springer International Publishing, 2022, pp. 437–448
2022
-
[25]
Normative data on the boston diagnostic aphasia examination, parietal lobe battery, and the boston naming Test,
J. C. Borod, H. Goodglass, and E. Kaplan, “Normative data on the boston diagnostic aphasia examination, parietal lobe battery, and the boston naming Test,”Journal of Clinical Neuropsychology, vol. 2, no. 3, pp. 209–215, Nov. 1980
1980
-
[26]
Erzigkeit,Der Syndrom-Kurztest zur Erfassung von Aufmerksamkeits- und Ged ¨achtnisst¨orungen
H. Erzigkeit,Der Syndrom-Kurztest zur Erfassung von Aufmerksamkeits- und Ged ¨achtnisst¨orungen. Vaterstetten, Germany: Vless Verlag-Ges., 1977, vol. 1
1977
-
[27]
Stemmler, H
M. Stemmler, H. Lehfeld, and R. Horn,SKT nach Erzigkeit - SKT Manual Edition 2015. Erlangen, Germany: Universit ¨at Erlangen- N¨urnberg, 2015, vol. 1
2015
-
[28]
Pitfalls and Limits in Automatic Dementia Assessment,
F. Braun, C. Witzl, A. Erzigkeit, H. Lehfeld, T. Hillemacher, T. Bocklet, and K. Riedhammer, “Pitfalls and Limits in Automatic Dementia Assessment,” inInterspeech 2025, 2025, pp. 5663– 5667
2025
-
[29]
Robust speech recognition via large-scale weak su- pervision,
A. Radford, J. W. Kim, T. Xu, G. Brockman, C. McLeavey, and I. Sutskever, “Robust speech recognition via large-scale weak su- pervision,” inProceedings of the 40th International Conference on Machine Learning, ser. ICML’23. JMLR.org, 2023
2023
-
[30]
Whisper features for dysarthric severity-level classification,
S. Rathod, M. Charola, A. V ora, Y . Jogi, and H. A. Patil, “Whisper features for dysarthric severity-level classification,” inInterspeech 2023, 2023, pp. 1523–1527
2023
-
[31]
Whister: Using whisper’s repre- sentations for stuttering detection,
V . Changawala and F. Rudzicz, “Whister: Using whisper’s repre- sentations for stuttering detection,” inInterspeech 2024, 2024, pp. 897–901
2024
-
[32]
Large Language Models for Dysfluency Detec- tion in Stuttered Speech,
D. Wagner, S. P. Bayerl, I. Baumann, E. Noeth, K. Riedhammer, and T. Bocklet, “Large Language Models for Dysfluency Detec- tion in Stuttered Speech,” inInterspeech 2024, 2024, pp. 5118– 5122
2024
-
[33]
Multilingual prediction of cognitive impairment with large language models and speech analysis,
F. Agbavor and H. Liang, “Multilingual prediction of cognitive impairment with large language models and speech analysis,” Brain Sciences, vol. 14, no. 12, 2024
2024
-
[34]
The parlo dementia corpus: A german multi-center re- source for alzheimer’s disease,
F. Braun, C. Witzl, F. H ¨onig, E. N ¨oth, T. Bocklet, and K. Ried- hammer, “The parlo dementia corpus: A german multi-center re- source for alzheimer’s disease,” inProceedings of the Fifteenth Language Resources and Evaluation Conference (LREC 2026), S. Piperidis, N. Bel, H. van den Heuvel, N. Ide, S. Krek, and A. Toral, Eds. Palma, Mallorca, Spain: Euro...
2026
-
[35]
Crisperwhisper: Accu- rate timestamps on verbatim speech transcriptions,
M. Zusag, L. Wagner, and B. Thallinger, “Crisperwhisper: Accu- rate timestamps on verbatim speech transcriptions,” inInterspeech 2024, 2024, pp. 1265–1269
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.