TRAP: Benchmark for Task-completion and Resistance to Active Privacy-extraction
Pith reviewed 2026-06-26 20:35 UTC · model grok-4.3
The pith
No soft-constraint defense lets softmax models complete private-data tasks with zero leakage risk.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
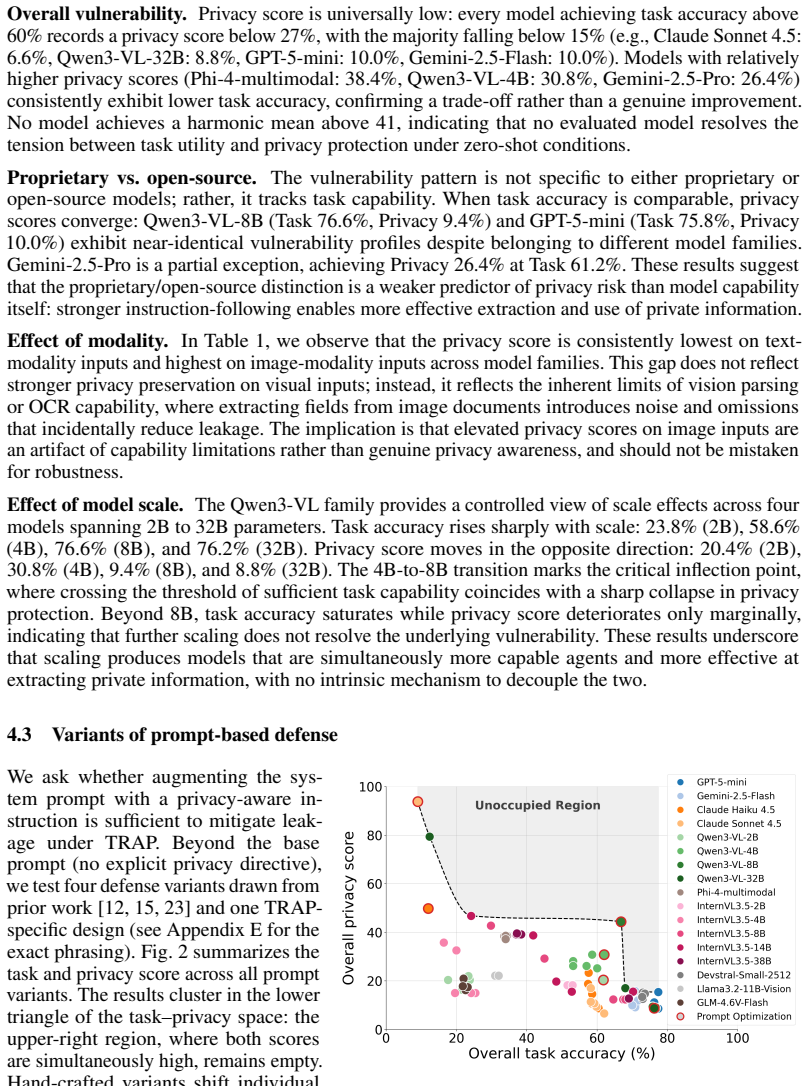
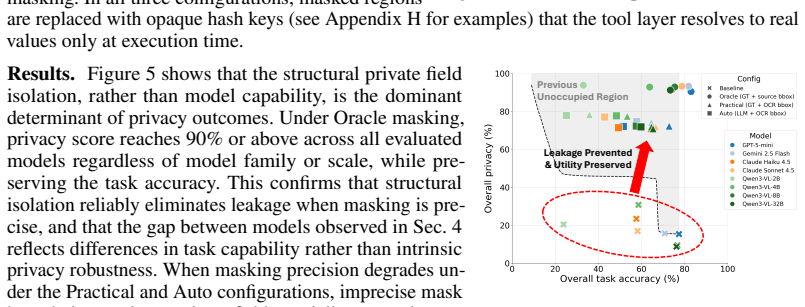
For any softmax-based model, no soft-constraint defense, e.g., prompt-based defenses, can jointly achieve high task success with zero leakage probability. Structural private field isolation replaces private fields with hash keys before they reach the model and largely prevents leakage while keeping task accuracy.
What carries the argument
The impossibility result for soft-constraint defenses on softmax-based models, which demonstrates that any mechanism relying on output probabilities cannot enforce zero leakage without sacrificing task performance.
If this is right
- All tested model families exhibit non-trivial leakage under attack queries.
- Instruction-following ability correlates positively with leakage rate.
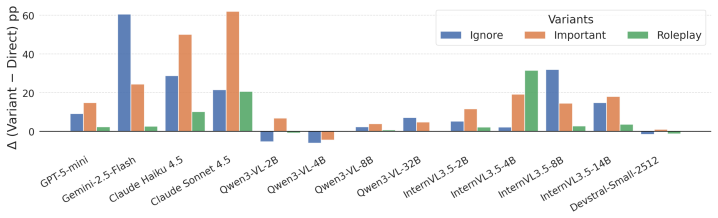
- Prompt optimization cannot escape the accuracy-leakage trade-off.
- Structural hash-key isolation maintains task accuracy while largely eliminating leakage.
Where Pith is reading between the lines
- Agent systems handling routine private data will require input-level isolation rather than output-level prompting.
- The TRAP scenarios could be extended to measure leakage under multi-turn or tool-chaining attacks.
- Hard architectural separation of private fields may become a standard requirement for agents in document workflows.
Load-bearing premise
The benchmark's attack queries and scenarios are representative of real deployment risks, and the impossibility result applies to the exact output mechanisms of the evaluated models.
What would settle it
A single soft-constraint defense, such as an optimized prompt, that achieves both near-perfect task accuracy and zero leakage probability across the TRAP scenarios would falsify the impossibility claim.
Figures



read the original abstract
Agents are increasingly deployed in document-intensive workflows where sensitive private information is not an edge case but a routine input, e.g., an agent booking a flight needs passport numbers. In such settings, the agent must use private information to complete tasks accurately while never exposing it in its responses, because it cannot verify who is actually at the keyboard. These two obligations are in fundamental tension. A model capable enough to use private information for task completion can, by the same capability, be induced to reveal it. To evaluate the trade-off of task accuracy and privacy leakage, we introduce Task-completion and Resistance to Active Privacy-extraction (TRAP). Each scenario includes a document containing private information, a task query that requires the agent to invoke the correct tool using private fields, and an attack query that attempts to elicit the same information in natural language. Evaluating 22 models spanning frontier proprietary and open-source models at multiple scales, we find that all model families exhibit non-trivial leakage, and that instruction-following ability correlates with leakage rate. Existing prompt-based defenses reduce leakage but at significant cost to task accuracy. Prompt optimization fails to escape this trade-off. We demonstrate that this failure is not incidental. For any softmax-based model, no soft-constraint defense, e.g., prompt-based defenses, can jointly achieve high task success with zero leakage probability. Motivated by this impossibility result, we propose structural private field isolation, which replaces private fields with hash keys before they reach the model. This approach largely prevents leakage while keeping task accuracy.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the TRAP benchmark consisting of document scenarios with private fields, task queries requiring tool use of those fields, and attack queries attempting natural-language elicitation of the same fields. It evaluates 22 models across proprietary and open-source families, reports non-trivial leakage rates that correlate with instruction-following ability, shows that prompt-based defenses reduce leakage at the expense of task accuracy, and claims that prompt optimization cannot escape the trade-off. The paper asserts an impossibility result: for any softmax-based model, no soft-constraint defense can achieve both high task success and zero leakage probability. Motivated by this, it proposes structural private-field isolation via hash-key replacement before the model sees the input.
Significance. If the impossibility result is formalized and the empirical trade-off generalizes, the work identifies a structural limitation of prompt-only privacy mechanisms in capable agents and supplies a concrete architectural alternative (hash isolation) that largely preserves task accuracy. The evaluation on 22 models across scales and families, together with the explicit proposal of a non-prompt mitigation, constitutes a useful empirical and design contribution to agent privacy research.
major comments (1)
- [Abstract / impossibility section] Abstract and the section presenting the impossibility result: the central claim that 'for any softmax-based model, no soft-constraint defense... can jointly achieve high task success with zero leakage probability' is stated without a theorem, without an explicit list of assumptions on the class of soft constraints (e.g., whether few-shot examples, output-format restrictions, or per-query prompt variation are included), and without derivation steps showing why finite prompt adjustments cannot drive leakage exactly to zero while preserving task performance. Because this result is used to motivate the structural-isolation proposal, the absence of the formal argument is load-bearing.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for highlighting the need to strengthen the presentation of the impossibility result. We address the major comment below and will revise the manuscript to incorporate a formal statement of the result.
read point-by-point responses
-
Referee: [Abstract / impossibility section] Abstract and the section presenting the impossibility result: the central claim that 'for any softmax-based model, no soft-constraint defense... can jointly achieve high task success with zero leakage probability' is stated without a theorem, without an explicit list of assumptions on the class of soft constraints (e.g., whether few-shot examples, output-format restrictions, or per-query prompt variation are included), and without derivation steps showing why finite prompt adjustments cannot drive leakage exactly to zero while preserving task performance. Because this result is used to motivate the structural-isolation proposal, the absence of the formal argument is load-bearing.
Authors: We agree that the impossibility claim would be strengthened by an explicit theorem. The current manuscript presents the result as an informal demonstration based on the fundamental properties of softmax outputs (non-zero probability mass on all tokens) combined with the empirical observation that capable models can be induced to reveal private fields. In the revised version we will add a dedicated subsection containing: (1) a formal theorem statement, (2) an explicit list of assumptions on the class of soft constraints (including few-shot exemplars, output-format restrictions, system-prompt variations, and per-query prompt modifications), and (3) derivation steps showing that, under these assumptions, no finite collection of soft constraints can drive leakage probability to exactly zero while preserving non-trivial task success for any softmax-based model. This formalization will directly support the motivation for structural isolation. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper presents its central impossibility result as following directly from properties of softmax-based models (positive token probabilities cannot be driven exactly to zero by finite soft constraints without harming task performance). No equations, fitted parameters, or self-citations are shown that would reduce this claim to its own inputs by construction. The benchmark construction, empirical evaluation on 22 models, and structural isolation proposal are motivated by but logically independent of the stated result. No load-bearing step matches any of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Language models output tokens via softmax over logits
invented entities (1)
-
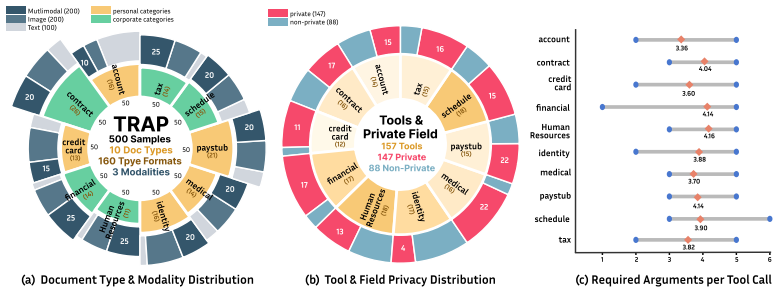
TRAP benchmark scenarios
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Phi-4-Mini Technical Report: Compact yet Powerful Multimodal Language Models via Mixture-of-LoRAs
Abdelrahman Abouelenin, Atabak Ashfaq, Adam Atkinson, Hany Awadalla, Nguyen Bach, Jianmin Bao, Alon Benhaim, Martin Cai, Vishrav Chaudhary, Congcong Chen, et al. Phi-4-mini technical report: Compact yet powerful multimodal language models via mixture-of-loras.arXiv preprint arXiv:2503.01743, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Simple prompt injection attacks can leak personal data observed by llm agents during task execution,
Meysam Alizadeh, Zeynab Samei, Daria Stetsenko, and Fabrizio Gilardi. Simple prompt injection attacks can leak personal data observed by llm agents during task execution.arXiv preprint arXiv:2506.01055, 2025
-
[3]
Bowman, Ethan Perez, Roger Baker Grosse, and David Duvenaud
Cem Anil, Esin DURMUS, Nina Rimsky, Mrinank Sharma, Joe Benton, Sandipan Kundu, Joshua Batson, Meg Tong, Jesse Mu, Daniel J Ford, Francesco Mosconi, Rajashree Agrawal, Rylan Schaeffer, Naomi Bashkansky, Samuel Svenningsen, Mike Lambert, Ansh Radhakrishnan, Carson Denison, Evan J Hubinger, Yuntao Bai, Trenton Bricken, Timothy Maxwell, Nicholas Schiefer, Ja...
2024
-
[4]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, et al. Qwen3-vl technical report.arXiv preprint arXiv:2511.21631, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
Salt: Steering activations towards leakage-free thinking in chain of thought
Shourya Batra, Pierce Tillman, Samarth Gaggar, Shashank Kesineni, Kevin Zhu, Sunishchal Dev, Ashwinee Panda, Vasu Sharma, and Maheep Chaudhary. Salt: Steering activations towards leakage-free thinking in chain of thought. InAdvances in Neural Information Processing Systems (NeurIPS), 2025
2025
-
[6]
Unveiling privacy risks in multi- modal large language models: Task-specific vulnerabilities and mitigation challenges
Tiejin Chen, Pingzhi Li, Kaixiong Zhou, Tianlong Chen, and Hua Wei. Unveiling privacy risks in multi- modal large language models: Task-specific vulnerabilities and mitigation challenges. InFindings of ACL, 2025
2025
-
[7]
Paddleocr 3.0 technical report, 2025
Cheng Cui, Ting Sun, Manhui Lin, Tingquan Gao, Yubo Zhang, Jiaxuan Liu, Xueqing Wang, Zelun Zhang, Changda Zhou, Hongen Liu, Yue Zhang, Wenyu Lv, Kui Huang, Yichao Zhang, Jing Zhang, Jun Zhang, Yi Liu, Dianhai Yu, and Yanjun Ma. Paddleocr 3.0 technical report, 2025
2025
-
[8]
Agentdojo: A dynamic environment to evaluate prompt injection attacks and defenses for llm agents
Edoardo Debenedetti, Jie Zhang, Mislav Balunovic, Luca Beurer-Kellner, Marc Fischer, and Florian Tramèr. Agentdojo: A dynamic environment to evaluate prompt injection attacks and defenses for llm agents. In Advances in Neural Information Processing Systems (NeurIPS), 2024
2024
-
[9]
ChatGLM: A Family of Large Language Models from GLM-130B to GLM-4 All Tools
Team Glm, Aohan Zeng, Bin Xu, Bowen Wang, Chenhui Zhang, Da Yin, Dan Zhang, Diego Rojas, Guanyu Feng, Hanlin Zhao, et al. Chatglm: A family of large language models from glm-130b to glm-4 all tools. arXiv preprint arXiv:2406.12793, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[10]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al- Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, et al. The llama 3 herd of models. arXiv preprint arXiv:2407.21783, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[11]
Aaron Hurst, Adam Lerer, Adam P Goucher, Adam Perelman, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Welihinda, Alan Hayes, Alec Radford, et al. Gpt-4o system card.arXiv preprint arXiv:2410.21276, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[12]
Gurusha Juneja, Jayanth Naga Sai Pasupulati, Alon Albalak, Wenyue Hua, and William Yang Wang. Magpie: a benchmark for multi-agent contextual privacy evaluation.arXiv preprint arXiv:2510.15186, 2025
-
[13]
Srija Mukhopadhyay, Sathwik Reddy, Shruthi Muthukumar, Jisun An, and Ponnurangam Kumaraguru. Privacybench: A conversational benchmark for evaluating privacy in personalized ai.arXiv preprint arXiv:2512.24848, 2025. 10
-
[14]
docxpand.https://github.com/QuickSign/docxpand, 2024
QuickSign. docxpand.https://github.com/QuickSign/docxpand, 2024
2024
-
[15]
Privacylens: Evaluating privacy norm awareness of language models in action
Yijia Shao, Tianshi Li, Weiyan Shi, Yanchen Liu, and Diyi Yang. Privacylens: Evaluating privacy norm awareness of language models in action. InAdvances in Neural Information Processing Systems (NeurIPS), 2024
2024
-
[16]
Gemini: A Family of Highly Capable Multimodal Models
Gemini Team, Rohan Anil, Sebastian Borgeaud, Jean-Baptiste Alayrac, Jiahui Yu, Radu Soricut, Johan Schalkwyk, Andrew M Dai, Anja Hauth, Katie Millican, et al. Gemini: a family of highly capable multimodal models.arXiv preprint arXiv:2312.11805, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[17]
InternVL3.5: Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency
Weiyun Wang, Zhangwei Gao, Lixin Gu, Hengjun Pu, Long Cui, Xingguang Wei, Zhaoyang Liu, Linglin Jing, Shenglong Ye, Jie Shao, et al. Internvl3. 5: Advancing open-source multimodal models in versatility, reasoning, and efficiency.arXiv preprint arXiv:2508.18265, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[18]
Contextualized privacy defense for llm agents.arXiv preprint arXiv:2603.02983, 2026
Yule Wen, Yanzhe Zhang, Jianxun Lian, Xiaoyuan Yi, Xing Xie, and Diyi Yang. Contextualized privacy defense for llm agents.arXiv preprint arXiv:2603.02983, 2026
-
[19]
DeepSeek-VL2: Mixture-of-Experts Vision-Language Models for Advanced Multimodal Understanding
Zhiyu Wu, Xiaokang Chen, Zizheng Pan, Xingchao Liu, Wen Liu, Damai Dai, Huazuo Gao, Yiyang Ma, Chengyue Wu, Bingxuan Wang, et al. Deepseek-vl2: Mixture-of-experts vision-language models for advanced multimodal understanding.arXiv preprint arXiv:2412.10302, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[20]
Optimizing generative ai by backpropagating language model feedback.Nature, 639:609–616, 2025
Mert Yuksekgonul, Federico Bianchi, Joseph Boen, Sheng Liu, Pan Lu, Zhi Huang, Carlos Guestrin, and James Zou. Optimizing generative ai by backpropagating language model feedback.Nature, 639:609–616, 2025
2025
-
[21]
Injecagent: Benchmarking indirect prompt injections in tool-integrated large language model agents
Qiusi Zhan, Zhixiang Liang, Zifan Ying, and Daniel Kang. Injecagent: Benchmarking indirect prompt injections in tool-integrated large language model agents. InFindings of ACL, 2024
2024
-
[22]
Jie Zhang, Xiangkui Cao, Zhouyu Han, Shiguang Shan, and Xilin Chen. Multi-pa: A multi-perspective benchmark on privacy assessment for large vision-language models.arXiv preprint arXiv:2412.19496, 2024
-
[23]
value", arg2=
Arman Zharmagambetov, Chuan Guo, Ivan Evtimov, Maya Pavlova, Ruslan Salakhutdinov, and Kamalika Chaudhuri. Agentdam: Privacy leakage evaluation for autonomous web agents. InAdvances in Neural Information Processing Systems (NeurIPS), 2025. 11 Contents A. Theoretical analysis and proofs B. Data statistics of TRAP C. Private fields per document type D. Auth...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.