SARLO-80: Worldwide Slant SAR Language Optic Dataset 80cm
Pith reviewed 2026-06-30 10:15 UTC · model grok-4.3
The pith
SARLO-80 supplies 119566 worldwide VHR SAR patches aligned with optical imagery and text captions in slant-range geometry.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
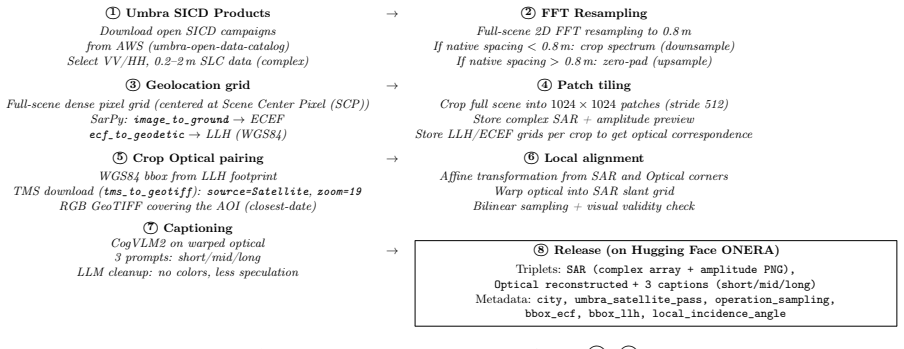
The paper establishes a public VHR SAR-optical-text dataset with 119566 triplets from 2500 Umbra scenes standardized to 80cm slant-range SAR patches paired with warped optical patches and three lengths of captions, enabling reproducible multimodal alignment benchmarks in native SAR geometry across diverse global sites.
What carries the argument
The SARLO-80 dataset of complex and amplitude 1024 by 1024 slant-range SAR patches with locally warped optical counterparts and natural-language descriptions generated in three variants.
If this is right
- Cross-modal retrieval models can now be trained and evaluated on aligned VHR SAR and optical data in slant geometry.
- Conditional generation from text to SAR or optical to SAR becomes feasible with public baselines.
- Fixed train validation and test splits support consistent comparison of multimodal methods worldwide.
- The released preprocessing pipeline allows replication and extension to additional SAR scenes.
Where Pith is reading between the lines
- Alignment in native slant range could reveal unique information preservation properties of SAR compared to ground-range products.
- Text descriptions might support zero-shot tasks in remote sensing applications where visual data alone is insufficient.
- Global coverage across land types could aid in developing models robust to varied environments and infrastructures.
Load-bearing premise
The local coordinate correspondences used to warp optical tiles onto the SAR grid produce accurate pixel-level alignment without significant residual geometric error or occlusion mismatch.
What would settle it
Finding a large number of samples where the warped optical patch shows visible misalignment with the SAR features, such as shifted building edges or road positions, would indicate the alignment step failed.
Figures

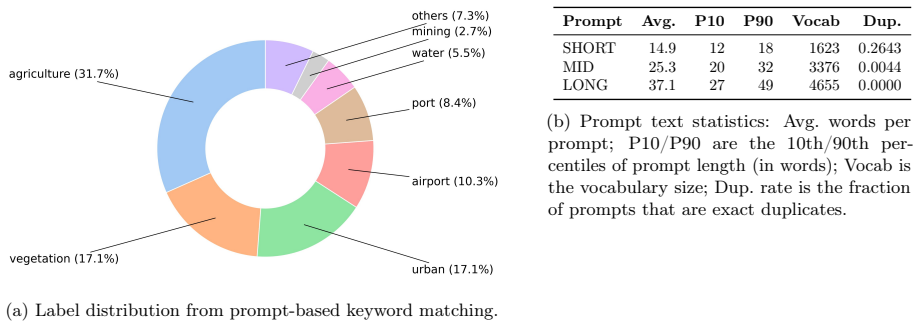
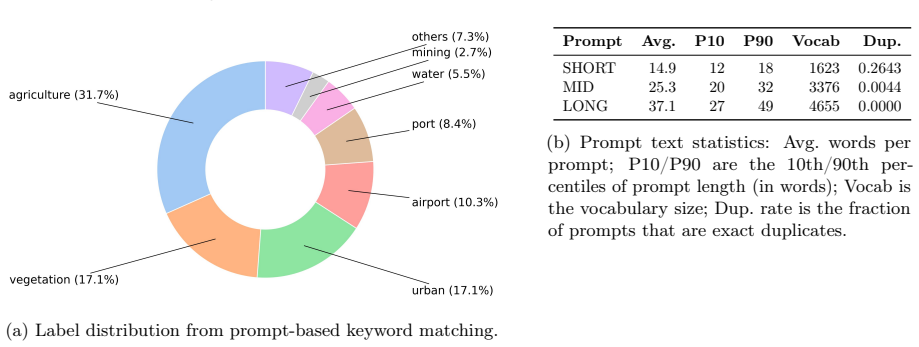





read the original abstract
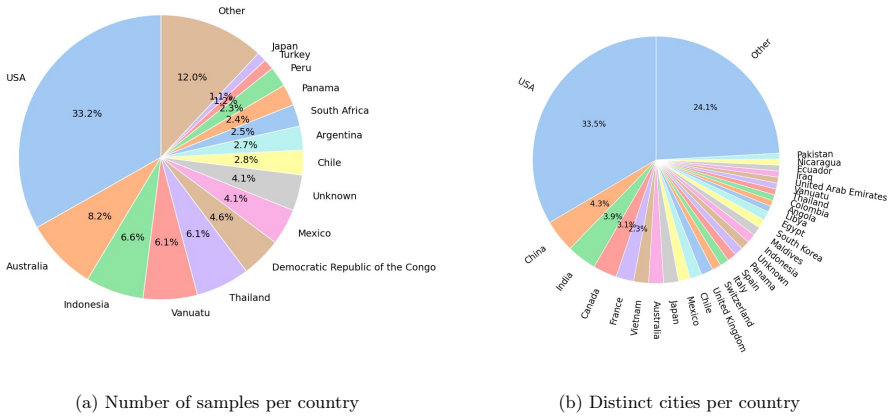
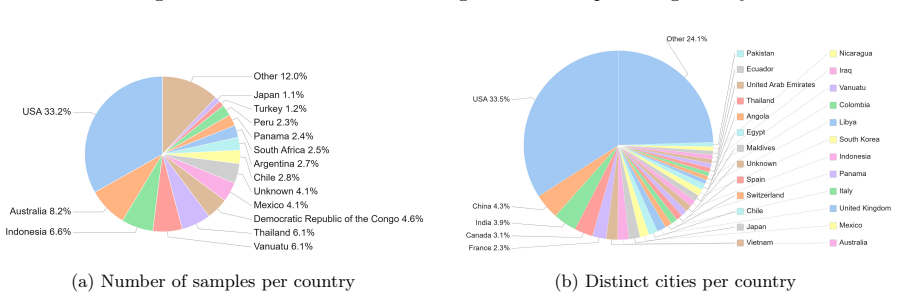
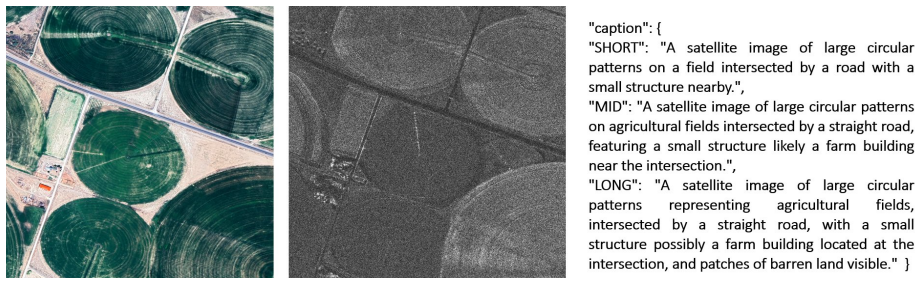
Multimodal foundation models have advanced rapidly thanks to large optical benchmarks, but comparable resources for synthetic aperture radar (SAR) remain limited. Existing SAR--optical datasets largely rely on low-resolution, intensity-only Ground Range Detected~(GRD) products and do not preserve complex-valued SAR measurements or native acquisition geometry, which restricts physically grounded multimodal learning. In particular, large-scale public datasets combining very-high-resolution (VHR) SAR SLC, aligned optical imagery, and natural-language descriptions are still lacking. We present a VHR SAR--optical--text dataset built from open-access Umbra spotlight acquisitions distributed as Sensor Independent Complex Data (SICD). From around 2,500 worldwide scenes (VV/HH, 20cm--2m native resolution), we standardize all SAR data to an 80cm slant-range grid via band-limited FFT resampling and tile the imagery into 1024 by 1024 patches. For each SAR patch, we retrieve a high-resolution optical tile and warp it into the SAR grid using local coordinate correspondences for local pixel-level alignment. We further generate three caption variants (SHORT/MID/LONG) per sample to support vision--language training and evaluation. Our dataset contains 119,566 triplets (complex and amplitude slant-range SAR patch, aligned optical patch, natural-language description) covering 257 locations across 72 countries and a broad range of land types and infrastructures. We release fixed train/validation/test splits and the full preprocessing and baseline code to enable reproducible benchmarks for multimodal alignment on cross-modal retrieval and conditional generation in native SAR geometry. The dataset is publicly available on the Hugging Face Hub at https://huggingface.co/datasets/ONERA/SARLO-80.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents SARLO-80, a dataset of 119,566 triplets (complex and amplitude 80 cm slant-range SAR patches, aligned optical patches, and natural-language captions in SHORT/MID/LONG variants) derived from ~2,500 Umbra spotlight SICD scenes. The pipeline standardizes SAR data to an 80 cm slant-range grid via band-limited FFT resampling, tiles into 1024×1024 patches, warps optical tiles onto the SAR grid using local coordinate correspondences, generates captions, and releases fixed train/validation/test splits plus preprocessing code on the Hugging Face Hub. Coverage spans 257 locations across 72 countries.
Significance. If the claimed alignments are accurate, the release would fill a documented gap by providing the first large-scale public VHR SAR-optical-text resource that retains complex-valued SLC data and native slant-range geometry, supporting reproducible cross-modal retrieval and conditional generation benchmarks.
major comments (1)
- [Abstract and data-construction section] Abstract (paragraph on optical warping) and corresponding methods description: the claim of 'local pixel-level alignment' via local coordinate correspondences is presented without any quantitative validation (RMSE, residual error statistics, terrain-correction details, or assessment of layover/foreshortening mismatches). This is load-bearing for the central claim that the triplets support multimodal learning in native SAR geometry.
minor comments (1)
- [Abstract] Abstract: the native resolution range (20 cm–2 m) is stated but the resampling target is fixed at 80 cm; clarify whether all input scenes are up- or down-sampled and any resulting artifacts.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comment on the alignment validation. We address the point below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract and data-construction section] Abstract (paragraph on optical warping) and corresponding methods description: the claim of 'local pixel-level alignment' via local coordinate correspondences is presented without any quantitative validation (RMSE, residual error statistics, terrain-correction details, or assessment of layover/foreshortening mismatches). This is load-bearing for the central claim that the triplets support multimodal learning in native SAR geometry.
Authors: We agree that the absence of quantitative validation metrics is a limitation. The alignment is performed by warping optical tiles onto the SAR slant-range grid using local coordinate correspondences extracted from the SICD metadata; this produces a deterministic pixel-to-pixel mapping by construction. However, the current manuscript provides no RMSE, residual statistics, explicit terrain-correction description, or analysis of layover/foreshortening effects. In the revised version we will expand the methods section with (i) a precise description of the coordinate-based warping pipeline, (ii) any available geolocation accuracy figures from the Umbra SICD products, and (iii) an explicit discussion of residual geometric mismatches that can arise in native slant-range geometry. If a modest validation subset can be generated from the released data without new acquisitions, we will also report basic alignment quality statistics. revision: yes
Circularity Check
Dataset release paper contains no derivation chain or self-referential predictions
full rationale
The paper is a data-release contribution describing collection, standardization, and alignment of SAR-optical-text triplets from open Umbra SICD scenes and optical tiles. No equations, fitted parameters, predictions, or uniqueness theorems appear. The central claim (existence of 119566 aligned triplets) is externally verifiable by inspecting the released Hugging Face dataset and does not reduce to any self-citation or input-by-construction step. Alignment is presented as a construction step, not a derived result.
Axiom & Free-Parameter Ledger
free parameters (1)
- target slant-range resolution =
80 cm
Reference graph
Works this paper leans on
-
[1]
In: 2009 IEEE International Geoscience and Remote Sensing Symposium
Angelliaume, S., Dubois-Fernandez, P., Dreuillet, P., Oriot, H., Coulombeix, C.: Sethi, the onera airborne sar sensor, and his low frequency capability. In: 2009 IEEE International Geoscience and Remote Sensing Symposium. pp. IV--177--IV--180 (Jul 2009). doi:10.1109/IGARSS.2009.5417343
- [2]
-
[3]
In: 2024 International Radar Conference (RADAR)
Debuysère, S., Trouvé, N., Letheule, N., Colin, E., Lévêque, O.: Synthesizing sar images with generative ai: Expanding to large-scale imagery. In: 2024 International Radar Conference (RADAR). pp. 1--6 (2024). doi:10.1109/RADAR58436.2024.10993695
- [5]
-
[6]
Podell, D., English, Z., Lacey, K., Blattmann, A., Dockhorn, T., Müller, J., Penna, J., Rombach, R.: Sdxl: Improving latent diffusion models for high-resolution image synthesis (2023), https://arxiv.org/abs/2307.01952
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[7]
Schmitt, M., Hughes, L.H., Zhu, X.X.: The sen1-2 dataset for deep learning in sar-optical data fusion. ISPRS Annals of the Photogrammetry, Remote Sensing and Spatial Information Sciences IV-1, 141--146 (2018). doi:10.5194/isprs-annals-IV-1-141-2018, https://isprs-annals.copernicus.org/articles/IV-1/141/2018/
-
[8]
Schmitt, M., Hughes, L.H., Qiu, C., Zhu, X.X.: Sen12ms -- a curated dataset of georeferenced multi-spectral sentinel-1/2 imagery for deep learning and data fusion (2019), https://arxiv.org/abs/1906.07789
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[10]
: Open data program
Umbra Lab Inc. : Open data program. https://umbra.space/open-data/ (2026), accessed: 2026-02-10
2026
-
[11]
Wenger, R., Puissant, A., Weber, J., Idoumghar, L., Forestier, G.: Multisenge: A multimodal and multitemporal benchmark dataset for land use/land cover remote sensing applications. ISPRS Annals of the Photogrammetry, Remote Sensing and Spatial Information Sciences V-3-2022, 635--640 (2022). doi:10.5194/isprs-annals-V-3-2022-635-2022, https://isprs-annals....
-
[12]
Frontiers in Handwriting Recognition (ICFHR), 2014 14th International Conference on , pages=
Real-time segmentation of on-line handwritten arabic script , author=. Frontiers in Handwriting Recognition (ICFHR), 2014 14th International Conference on , pages=. 2014 , organization=
2014
-
[13]
Soft Computing and Pattern Recognition (SoCPaR), 2014 6th International Conference of , pages=
Fast classification of handwritten on-line Arabic characters , author=. Soft Computing and Pattern Recognition (SoCPaR), 2014 6th International Conference of , pages=. 2014 , organization=
2014
-
[14]
Estimate and Replace: A Novel Approach to Integrating Deep Neural Networks with Existing Applications , author=. arXiv preprint arXiv:1804.09028 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
and Hughes, L
Schmitt, M. and Hughes, L. H. and Zhu, X. X. , TITLE =. ISPRS Annals of the Photogrammetry, Remote Sensing and Spatial Information Sciences , VOLUME =. 2018 , PAGES =
2018
-
[16]
2019 , eprint=
SEN12MS -- A Curated Dataset of Georeferenced Multi-Spectral Sentinel-1/2 Imagery for Deep Learning and Data Fusion , author=. 2019 , eprint=
2019
-
[17]
Sumbul, Gencer and de Wall, Arne and Kreuziger, Tristan and Marcelino, Filipe and Costa, Hugo and Benevides, Pedro and Caetano, Mario and Demir, Begum and Markl, Volker , year=. BigEarthNet-MM: A Large-Scale, Multimodal, Multilabel Benchmark Archive for Remote Sensing Image Classification and Retrieval [Software and Data Sets] , volume=. IEEE Geoscience a...
-
[18]
and Puissant, A
Wenger, R. and Puissant, A. and Weber, J. and Idoumghar, L. and Forestier, G. , TITLE =. ISPRS Annals of the Photogrammetry, Remote Sensing and Spatial Information Sciences , VOLUME =. 2022 , PAGES =
2022
-
[19]
2024 , eprint=
MMEarth: Exploring Multi-Modal Pretext Tasks For Geospatial Representation Learning , author=. 2024 , eprint=
2024
-
[20]
2025 , eprint=
TerraMesh: A Planetary Mosaic of Multimodal Earth Observation Data , author=. 2025 , eprint=
2025
-
[21]
2018 , eprint=
The SARptical Dataset for Joint Analysis of SAR and Optical Image in Dense Urban Area , author=. 2018 , eprint=
2018
-
[22]
Open Data Program , howpublished =
-
[23]
2023 , eprint=
SDXL: Improving Latent Diffusion Models for High-Resolution Image Synthesis , author=. 2023 , eprint=
2023
-
[24]
Solène Debuysère and Nicolas Trouvé and Nathan Letheule and Olivier Lévêque and Elise Colin , keywords =. Quantitative comparison of fine-tuning techniques for pretrained latent diffusion models in the generation of unseen SAR images , journal =. 2026 , issn =. doi:https://doi.org/10.1016/j.isprsjprs.2026.02.018 , url =
-
[25]
Synthesizing SAR Images with Generative AI: Expanding to Large-Scale Imagery , year=
Debuysère, Solène and Trouvé, Nicolas and Letheule, Nathan and Colin, Elise and Lévêque, Olivier , booktitle=. Synthesizing SAR Images with Generative AI: Expanding to Large-Scale Imagery , year=
-
[26]
and Dubois-Fernandez, Pascale and Dreuillet, Ph
Angelliaume, S. and Dubois-Fernandez, Pascale and Dreuillet, Ph. and Oriot, H. SETHI, the ONERA airborne SAR sensor, and his low frequency capability , booktitle =. 2009 , month = jul, pages =
2009
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.