Efficient Safety Benchmarking via Item Response Theory
Pith reviewed 2026-07-01 15:48 UTC · model grok-4.3
The pith
Item Response Theory enables adaptive selection of safety benchmark items that approximates full rankings at a fraction of the cost.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
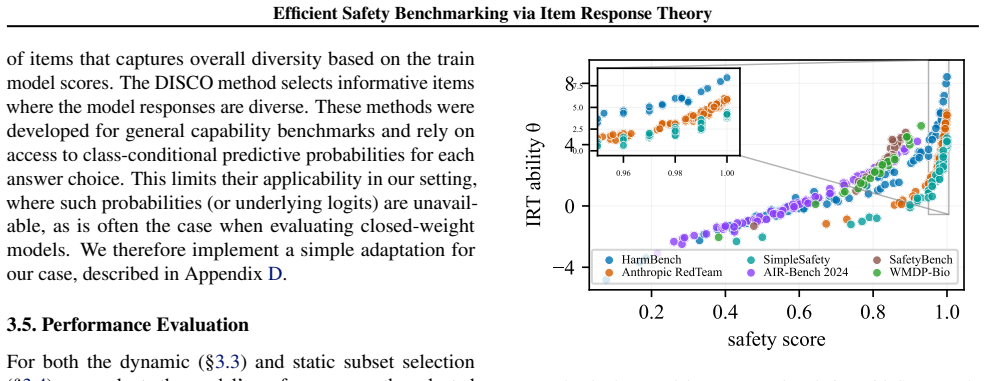
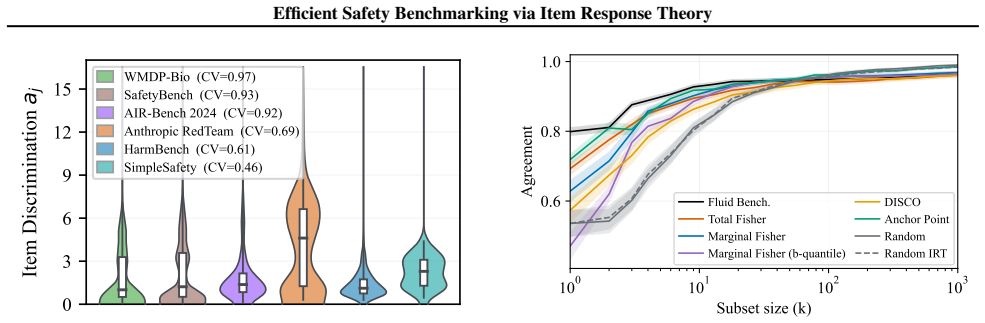
Item Response Theory recovers interpretable structure on safety benchmarks, with ability estimates resolving differences among models that cluster at the ceiling of raw safety metrics. Adaptive item selection approximates full-benchmark rankings while reducing evaluation cost by at least 80% on benchmarks where Spearman's ρ >90% with full-benchmark is attainable, and by up to 99.9% on AIR-Bench 2024. A fixed informative subset provides an alternative with savings up to 99.8%.
What carries the argument
Adaptive item selection using IRT, which dynamically chooses informative items for each model based on its responses.
If this is right
- Ability estimates from IRT can distinguish models that appear equivalent on raw scores.
- Fixed subsets of items can be pre-selected for efficient reuse across multiple models.
- The approach applies across a suite of widely used safety benchmarks.
- Cost reductions enable evaluation of more models or larger suites without proportional increase in compute.
Where Pith is reading between the lines
- This could extend to other AI evaluation domains with heterogeneous items, such as capability benchmarks.
- It suggests that current static benchmarks waste significant evaluation budget on uninformative items.
- Future benchmarks might be designed with IRT in mind from the start to maximize efficiency.
Load-bearing premise
The safety benchmark items follow the statistical assumptions of IRT models, including a single underlying ability trait, local independence of items, and monotonic response functions.
What would settle it
Observing that adaptive IRT selection fails to achieve Spearman's rho greater than 90% with full benchmarks even after substantial item reductions, or that the required item count does not drop below 20% of the original on suitable benchmarks.
Figures

read the original abstract
Safety benchmarks for language models are typically evaluated using static paradigms that treat all items as equally informative for all models, an assumption that is particularly problematic for adversarial, highly heterogeneous safety items. Applied in full to modern benchmark suites, the current evaluation procedures would require on the order of $10^5$ responses, most of which provide little ranking signal. We analyze a suite of widely used safety benchmarks and make three contributions toward more efficient safety evaluation. First, we show that Item Response Theory (IRT) recovers interpretable structure on safety benchmarks, with ability estimates resolving differences among models that cluster at the ceiling of raw safety metrics. Second, we show that adaptive item selection, which dynamically chooses informative items for each model based on its responses, approximates full-benchmark rankings while reducing evaluation cost by at least 80% on benchmarks where Spearman's $\rho >$90% with full-benchmark is attainable, and by up to 99.9% on AIR-Bench 2024. Third, we introduce a practical procedure for extracting a fixed, informative subset of items reusable across models, providing an alternative to adaptive selection with savings of up to 99.8% on AIR-Bench 2024. Together, these results establish that psychometric methods enable benchmark-aware reductions in evaluation costs across the safety evaluation pipeline.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that Item Response Theory (IRT) applied to safety benchmarks recovers interpretable structure in model abilities, enabling adaptive item selection that approximates full-benchmark rankings with at least 80% cost reduction (up to 99.9% on AIR-Bench 2024) when Spearman's ρ > 0.9 is attainable, plus a fixed-subset procedure achieving up to 99.8% savings, all while addressing the inefficiency of static full-benchmark evaluation requiring ~10^5 responses.
Significance. If the IRT assumptions hold and the empirical savings are robust, the work offers a concrete, benchmark-aware method to scale safety evaluation without sacrificing ranking fidelity, directly tackling the resource demands of modern adversarial benchmarks. The reported thresholds and percentages on real suites provide a practical baseline for future efficiency studies.
major comments (2)
- [Abstract / empirical results] Abstract and empirical results: The central efficiency claims rest on IRT producing stable ability estimates and informative item selection, yet no dimensionality tests (parallel analysis, eigenvalue ratios), residual correlation checks for local independence, or item-fit statistics are reported despite the heterogeneous item pool (toxicity, bias, jailbreaks). This is load-bearing for both the adaptive and fixed-subset results.
- [Adaptive item selection results] Adaptive selection procedure: The reported Spearman correlations compare adaptive rankings against the full static benchmark rather than held-out models or cross-validated ability estimates; without such checks, it is unclear whether the ρ > 0.9 threshold reflects genuine out-of-sample predictive power or in-sample artifact.
minor comments (2)
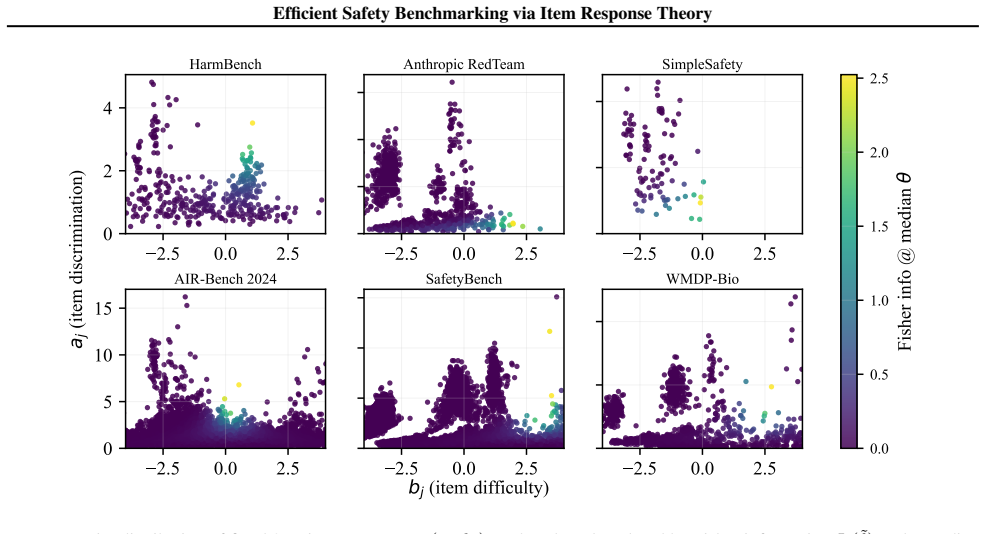
- [Methods] Notation for item parameters (difficulty, discrimination) should be introduced with explicit reference to the 1PL/2PL/graded-response model used.
- [Figures] Figure captions for cost-reduction plots should state the exact number of models and items per benchmark to allow replication.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments. We address each major point below and indicate where revisions will be made to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract / empirical results] Abstract and empirical results: The central efficiency claims rest on IRT producing stable ability estimates and informative item selection, yet no dimensionality tests (parallel analysis, eigenvalue ratios), residual correlation checks for local independence, or item-fit statistics are reported despite the heterogeneous item pool (toxicity, bias, jailbreaks). This is load-bearing for both the adaptive and fixed-subset results.
Authors: We agree that these diagnostics are important for validating IRT assumptions on heterogeneous safety data. The original manuscript applied standard IRT models and demonstrated high correlations with full rankings but omitted explicit reporting of dimensionality checks, residual correlations, and item-fit statistics. In revision we will add parallel analysis and eigenvalue ratios to assess dimensionality, average residual correlations to evaluate local independence, and item-fit statistics (e.g., infit/outfit or chi-square) for the safety item pools. These additions will be placed in a new subsection on model diagnostics. revision: yes
-
Referee: [Adaptive item selection results] Adaptive selection procedure: The reported Spearman correlations compare adaptive rankings against the full static benchmark rather than held-out models or cross-validated ability estimates; without such checks, it is unclear whether the ρ > 0.9 threshold reflects genuine out-of-sample predictive power or in-sample artifact.
Authors: The reported correlations measure how closely the adaptive procedure recovers the ranking that would have been obtained from the complete benchmark, which is the relevant practical target. Nevertheless, the concern about potential in-sample bias is valid. In the revision we will add cross-validation experiments that hold out models during item selection and ability estimation, as well as bootstrap-based checks on the ability estimates, to demonstrate that the ρ > 0.9 thresholds generalize out-of-sample. revision: yes
Circularity Check
No significant circularity; standard IRT application with external validation
full rationale
The paper applies standard Item Response Theory (1PL/2PL or graded-response models) to pre-existing safety benchmark response data, fits ability and item parameters, then evaluates adaptive selection and fixed-subset procedures by measuring Spearman rank correlation against the independently computed full-benchmark ability estimates. These correlations and the associated cost-reduction percentages are empirical results obtained by holding out or adaptively sampling from the complete item set rather than being algebraically forced by the fitted parameters themselves. No load-bearing self-citation, uniqueness theorem, or ansatz is invoked to justify the core efficiency claims; the derivation chain consists of off-the-shelf psychometric machinery plus direct comparison to the static benchmark, rendering the reported savings non-circular by construction.
Axiom & Free-Parameter Ledger
free parameters (1)
- item difficulty and discrimination parameters
axioms (1)
- domain assumption Safety benchmark responses can be modeled by a unidimensional latent trait with monotonic item characteristic curves and local independence.
Reference graph
Works this paper leans on
-
[1]
JailbreakBench: An Open Robustness Benchmark for Jailbreaking Large Language Models
Chao, P., Debenedetti, E., Robey, A., Andriushchenko, M., Croce, F., Sehwag, V ., Tramer, F., Hsieh, C.-J., Kolter, J. Z., et al. JailbreakBench: An open robustness bench- mark for jailbreaking large language models.arXiv preprint arXiv:2404.01318,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Red Teaming Language Models to Reduce Harms: Methods, Scaling Behaviors, and Lessons Learned
Ganguli, D., Lovitt, L., Kernion, J., Askell, A., Bai, Y ., Kadavath, S., Mann, B., Perez, E., Schiefer, N., Ndousse, K., et al. Red teaming language models to reduce harms: Methods, scaling behaviors, and lessons learned.arXiv preprint arXiv:2209.07858,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
WildGuard: Open One-Stop Moderation Tools for Safety Risks, Jailbreaks, and Refusals of LLMs
Han, S., Rao, K., Ettinger, A., Jiang, L., Lin, B. Y ., Lambert, N., Choi, Y ., and Dziri, N. WildGuard: Open one-stop moderation tools for safety risks, jailbreaks, and refusals of LLMs.arXiv preprint arXiv:2406.18495,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Stochastic Variational Inference
URL https: //arxiv.org/abs/1206.7051. Hofmann, V ., Heineman, D., Magnusson, I., Lo, K., Dodge, J., Sap, M., Koh, P. W., Wang, C., Hajishirzi, H., and Smith, N. A. Fluid language model benchmarking. In Proceedings of the Conference on Language Modeling (COLM),
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Lalor, J
URL https://crfm.stanford.edu/2024/11/ 08/helm-safety.html. Lalor, J. P. and Rodriguez, P. py-irt: Python implementation of item response theory models,
2024
-
[6]
Lalor, J
URL https: //github.com/nd-ball/py-irt. Lalor, J. P., Wu, H., and Yu, H. Learning latent param- eters without human response patterns: Item response theory with artificial crowds. InProceedings of the 2019 Conference on Empirical Methods in Natural Language Processing,
2019
-
[7]
URL https: //arxiv.org/abs/2506.11094. Lord, F. M.Applications of Item Response Theory to Prac- tical Testing Problems. Lawrence Erlbaum Associates, Hillsdale, NJ,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
HarmBench: A Standardized Evaluation Framework for Automated Red Teaming and Robust Refusal
Mazeika, M., Phan, L., Yin, X., Zou, A., Wang, Z., Mu, N., Sakhaee, E., Li, N., Basart, S., Li, B., Forsyth, D., and Hendrycks, D. HarmBench: A standardized evaluation framework for automated red teaming and robust refusal. arXiv preprint arXiv:2402.04249,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
doi: 10.1177/01466219922031310. URL https://doi. org/10.1177/01466219922031310. Polo, F. M., Choshen, L., Sun, W., Xu, Y ., and Raffel, C. tinyBenchmarks: Evaluating LLMs with fewer examples. InProceedings of the International Conference on Ma- chine Learning (ICML),
-
[10]
doi: 10.18653/v1/2021.acl-long.346
Association for Computational Linguis- tics. doi: 10.18653/v1/2021.acl-long.346. URL https: //aclanthology.org/2021.acl-long.346/. R¨ottger, P., Kirk, H. R., Vidgen, B., Attanasio, G., Bianchi, F., and Hovy, D. XSTest: A test suite for identifying exaggerated safety behaviours in large language models. Proceedings of NAACL,
-
[11]
URL https://arxiv.org/abs/ 2510.07959. Souly, A., Lu, Q., Bowen, D., Trinh, T., Hsieh, E., Pandey, S., Abbeel, P., Shin, J., Mazeika, M., Hoover, A., and Hendrycks, D. StrongREJECT: Jailbreaks don’t (empiri- cally) jailbreak.arXiv preprint arXiv:2402.10260,
-
[12]
Vidgen, B., R ¨ottger, P., Kirk, H. R., and Hale, S. A. SimpleSafetyTests: a test suite for identifying critical safety risks in large language models.arXiv preprint arXiv:2311.08370,
-
[13]
Do- not-answer: A dataset for evaluating safeguards in LLMs
Wang, Y ., Li, H., Han, X., Nakov, P., and Baldwin, T. Do- not-answer: A dataset for evaluating safeguards in LLMs. arXiv preprint arXiv:2308.13387,
-
[14]
MMLU-Pro: A More Robust and Challenging Multi-Task Language Understanding Benchmark
Wang, Y ., Ma, X., Zhang, G., Ni, Y ., Chandra, A., Guo, S., Ren, W., Arulraj, A., He, X., Jiang, Z., Li, T., Ku, M., Wang, K., Zhuang, A., Fan, R., Yue, X., and Chen, W. Mmlu-pro: A more robust and challenging multi- task language understanding benchmark, 2024a. URL https://arxiv.org/abs/2406.01574. Wang, Z. et al. ATLAS: Adaptive testing via latent abil...
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
URL https://onlinelibrary.wiley.com/ doi/abs/10.1111/j.1745-3984.1984
doi: https://doi.org/10.1111/j.1745-3984.1984.tb01040.x. URL https://onlinelibrary.wiley.com/ doi/abs/10.1111/j.1745-3984.1984. tb01040.x. Wikipedia contributors. Maximum a posteriori es- timation — Wikipedia, the free encyclopedia. https://en.wikipedia.org/w/index. php?title=Maximum_a_posteriori_ estimation&oldid=1346789558,
-
[16]
Xie, T., Qi, X., Zeng, Y ., Huang, Y ., Sehwag, U
[Online; accessed 9-May-2026]. Xie, T., Qi, X., Zeng, Y ., Huang, Y ., Sehwag, U. M., Huang, K., He, L., Wei, B., Li, D., Sheng, Y ., et al. SORRY-Bench: Systematically evaluating large lan- guage model safety refusal behaviors.arXiv preprint arXiv:2406.14598,
-
[17]
Z., Tu, Y ., Mai, Y ., Klyman, K., Pan, M., Jia, R., Song, D., Liang, P., and Li, B
Zeng, Y ., Yang, Y ., Zhou, A., Tan, J. Z., Tu, Y ., Mai, Y ., Klyman, K., Pan, M., Jia, R., Song, D., Liang, P., and Li, B. Air-bench 2024: A safety benchmark based on risk categories from regulations and policies,
2024
-
[18]
Zhan, Q., Liang, Z., Ying, Z., and Kang, D
URL https://arxiv.org/abs/2407.17436. Zhan, Q., Liang, Z., Ying, Z., and Kang, D. Injeca- gent: Benchmarking indirect prompt injections in tool- integrated large language model agents,
-
[19]
InjecAgent: Benchmarking Indirect Prompt Injections in Tool-Integrated Large Language Model Agents
URL https://arxiv.org/abs/2403.02691. Zhang, Z., Lei, L., Wu, L., Sun, R., Huang, Y ., Long, C., Liu, X., Lei, X., Tang, J., and Huang, M. Safetybench: Evaluating the safety of large language models,
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
Zou, A., Wang, Z., Carlini, N., Nasr, M., Kolter, J
URLhttps://arxiv.org/abs/2309.07045. Zou, A., Wang, Z., Carlini, N., Nasr, M., Kolter, J. Z., and Fredrikson, M. Universal and transferable adversarial attacks on aligned language models. InarXiv preprint arXiv:2307.15043,
-
[21]
Dataset Details The dataset model scores from AIR-Bench 2024, Anthropic Red Team, HarmBench, and SimpleSafetyTest are taken from HELM Safety (Kaiyom et al., 2024)
10 Efficient Safety Benchmarking via Item Response Theory A. Dataset Details The dataset model scores from AIR-Bench 2024, Anthropic Red Team, HarmBench, and SimpleSafetyTest are taken from HELM Safety (Kaiyom et al., 2024). We ran our own evaluation on SafetyBench and WMDP, scoring each model on the multiple-choice items via a standard zero-shot evaluati...
2024
-
[22]
For multiple-choice benchmarks (WMDP, SafetyBench), we code the safe-aligned response as1
that rely on an LLM judge to assess response safety (HarmBench, Anthropic Red Team, SimpleSafetyTest, AIR-Bench 2024), we label a response as 1 if the judge assigns it the highest safety category and 0 otherwise. For multiple-choice benchmarks (WMDP, SafetyBench), we code the safe-aligned response as1. Binarization discards information about response seve...
2024
-
[23]
We therefore defined a metric similar to the Jensen-Shannon Divergence metric used in the original paper
is not directly usable with the 0 and 1 evaluation scores. We therefore defined a metric similar to the Jensen-Shannon Divergence metric used in the original paper. Our approach uses entropy for a binary outcome as a criterion to identify items with higher model disagreement. The items are therefore ordered based on Hj(pj) =−p j logp j −(1−p j) log(1−p j)...
2024
-
[24]
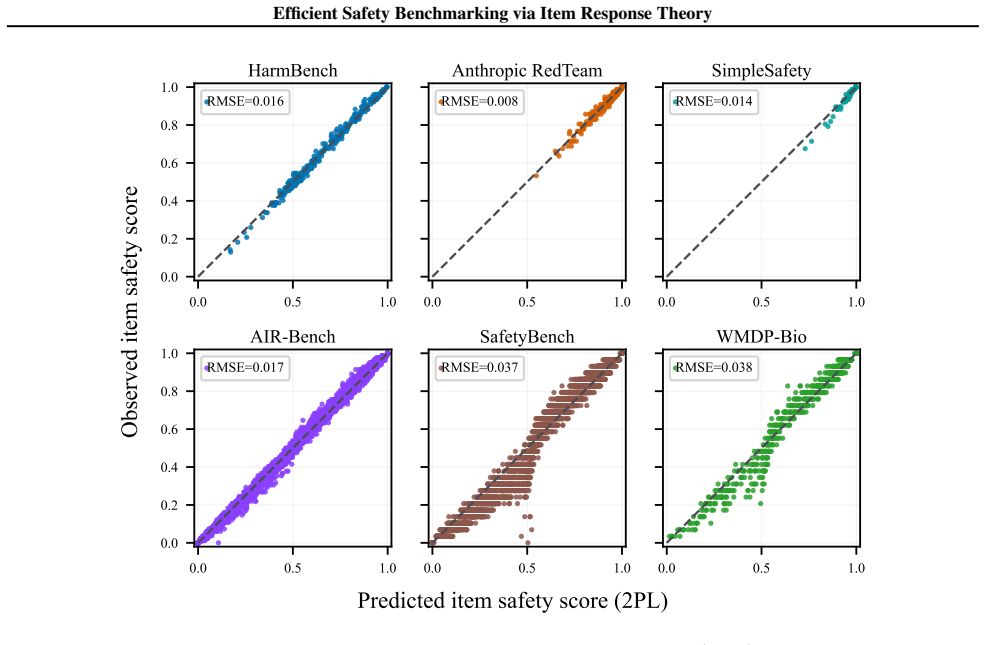
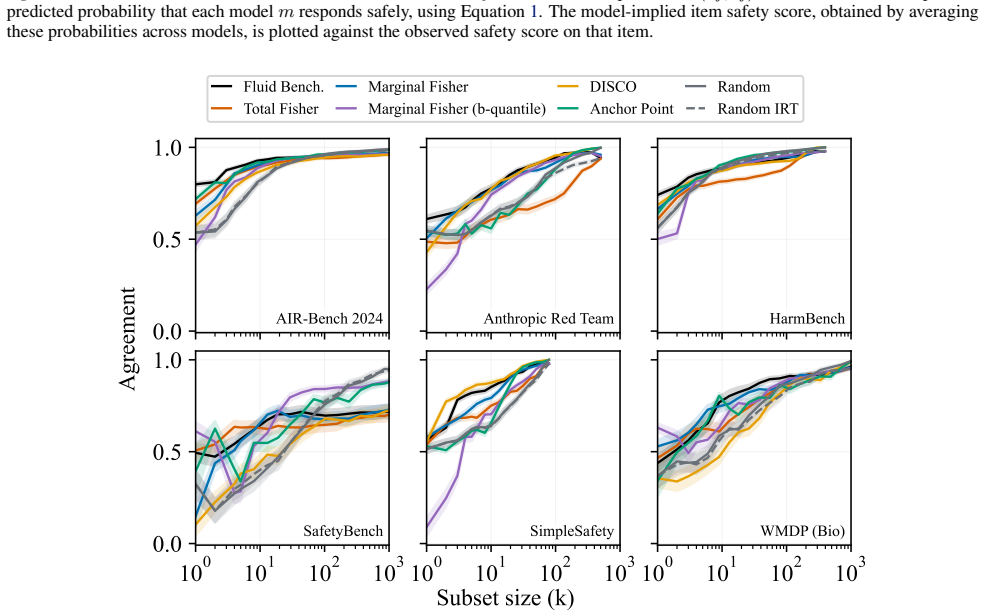
The model-implied item safety score, obtained by averaging these probabilities across models, is plotted against the observed safety score on that item. 0.0 0.5 1.0 AIR-Bench 2024 Anthropic Red Team HarmBench 100 101 102 103 0.0 0.5 1.0 SafetyBench 100 101 102 103 SimpleSafety 100 101 102 103 WMDP (Bio) Subset size (k) Agreement Fluid Bench. Total Fisher ...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.