BioInsight: Multi-Agent Orchestration for Interactive Biomedical Knowledge Discovery
Pith reviewed 2026-06-26 14:53 UTC · model grok-4.3
The pith
BioInsight uses multi-agent orchestration to convert biomedical data into interactive, citation-grounded evidence interfaces and leads on standard QA and reasoning benchmarks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
BioInsight achieves the best results on standardized biomedical QA, challenging protein-function reasoning, and end-to-end biomedical evidence synthesis by organizing evidence through typed intermediate artifacts and converting the same structured evidence into interactive interfaces, thereby moving beyond static report generation.
What carries the argument
Multi-agent orchestration that decomposes evidence retrieval from mechanistic reasoning and converts structured evidence into interactive interfaces.
If this is right
- BioInsight outperforms prior systems on standardized biomedical QA tasks.
- It leads on challenging protein-function reasoning evaluations.
- It achieves top scores on end-to-end biomedical evidence synthesis.
- Biomedical AI systems should prioritize provenance-preserving interactive evidence artifacts over static reports.
Where Pith is reading between the lines
- The interactive dashboards could let researchers directly compare competing mechanisms without leaving the evidence layer.
- Similar typed-artifact pipelines might reduce citation drift in other evidence-heavy fields such as clinical trial synthesis.
- If the deterministic citation step scales, it offers a route to audit trails that current LLM-only biomedical tools lack.
Load-bearing premise
That strong results on the described standardized tasks and evidence synthesis evaluations indicate improved real-world research decisions and that the multi-agent breakdown does not add errors in evidence handling.
What would settle it
A user study in which biologists perform a fixed set of hypothesis-refinement tasks on protein-disease links and show measurably different accuracy or speed when given BioInsight interfaces versus static reports generated from the same inputs.
Figures


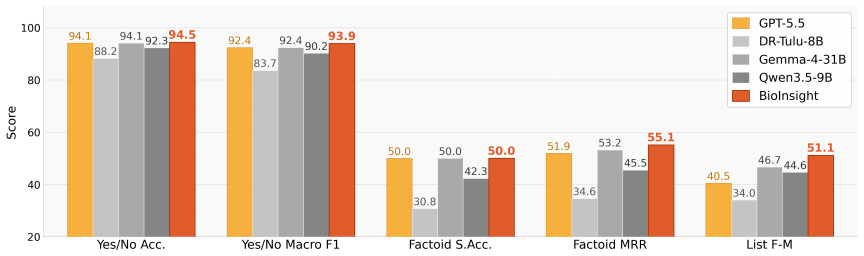

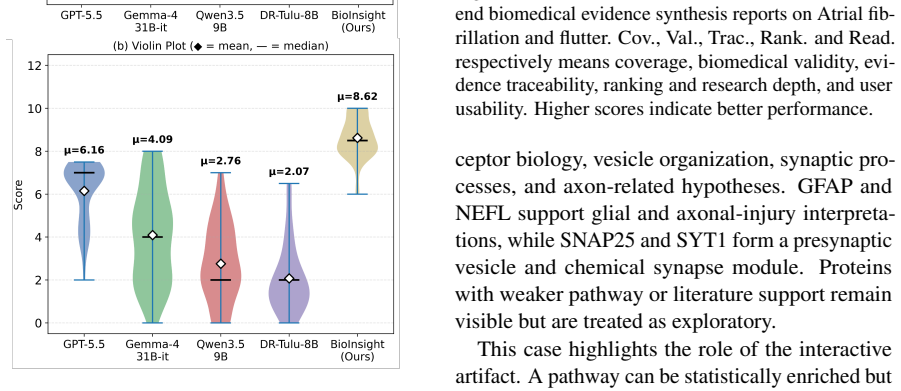
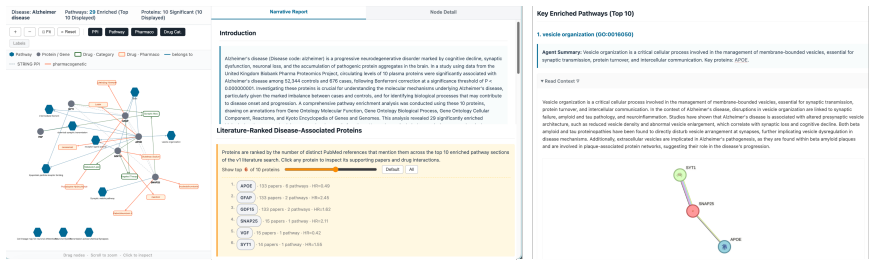

read the original abstract
Biomedical researchers increasingly use AI-generated analyses and reports to interpret protein-level signals, but static outputs are often insufficient for research decision-making, where users need to inspect evidence, assess uncertainty, compare mechanisms, and refine hypotheses. We present \textsc{BioInsight}, a multi-agent system that moves from static biomedical report generation to interactive evidence-centered interactive interface generation. Given a disease name, a protein association table, and optional cohort metadata, BioInsight organizes disease-specific evidence through typed intermediate artifacts, including ranked pathways, literature evidence packets, protein-level reasoning notes, citation-grounded reports, dashboard schemas, and rendered interactive interfaces. The system decomposes evidence retrieval from mechanistic reasoning, normalizes citations through deterministic components, and converts the same structured evidence used in the report into an interactive interface. We evaluate BioInsight on standardized biomedical QA, challenging protein-function reasoning, and end-to-end biomedical evidence synthesis. Results show that BioInsight achieves best, and suggest that biomedical AI systems should move beyond text-only and static reports toward provenance-preserving, interactive evidence artifacts.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents BioInsight, a multi-agent system for interactive biomedical knowledge discovery. Given a disease name, protein association table, and optional cohort metadata, the system generates typed intermediate artifacts (ranked pathways, literature evidence packets, protein-level reasoning notes, citation-grounded reports, dashboard schemas, and rendered interactive interfaces). It decomposes evidence retrieval from mechanistic reasoning, applies deterministic citation normalization, and converts structured evidence into interactive interfaces. The paper evaluates the system on standardized biomedical QA, challenging protein-function reasoning, and end-to-end biomedical evidence synthesis tasks, claiming that BioInsight achieves best performance and advocating a shift from static reports to provenance-preserving interactive evidence artifacts.
Significance. If the performance claims are substantiated with rigorous evaluation, the work could meaningfully advance biomedical AI by showing how multi-agent orchestration with typed artifacts enables interactive, inspectable outputs that support research decision-making. The separation of retrieval and reasoning plus deterministic citation handling are strengths that could improve transparency and reduce certain classes of errors compared to monolithic generation approaches.
major comments (2)
- [Abstract] Abstract: The central claim that BioInsight 'achieves best' on standardized biomedical QA, protein-function reasoning, and end-to-end evidence synthesis is unsupported by any metrics, baselines, error bars, or methodology details. This omission is load-bearing because the manuscript's primary contribution and recommendation rest on these performance assertions; without them, the advantage of the multi-agent decomposition into typed artifacts cannot be assessed.
- [Evaluation section] Evaluation section: No quantitative results, ablation studies, or error analysis are provided to test whether the typed intermediate artifacts reliably avoid introducing errors in evidence handling or whether performance on the described tasks translates to improved real-world research decisions. This leaves the weakest assumption in the abstract unexamined.
minor comments (1)
- [Abstract] Abstract: The phrasing 'achieves best' is imprecise and should be replaced with a specific statement such as 'achieves the highest scores on X, Y, Z metrics' once the results are added.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. We agree that the performance claims in the abstract and the evaluation section require substantial quantitative support, which is currently absent from the manuscript. We will undertake a major revision to address these points directly.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that BioInsight 'achieves best' on standardized biomedical QA, protein-function reasoning, and end-to-end evidence synthesis is unsupported by any metrics, baselines, error bars, or methodology details. This omission is load-bearing because the manuscript's primary contribution and recommendation rest on these performance assertions; without them, the advantage of the multi-agent decomposition into typed artifacts cannot be assessed.
Authors: We accept this assessment. The submitted abstract asserts that BioInsight 'achieves best' without including or referencing any supporting metrics, baselines, or methodology in the manuscript. In the revision we will rewrite the abstract to remove the unsubstantiated claim and instead summarize the concrete quantitative results that will be added to the evaluation section, including specific metrics, baselines, error bars, and task definitions. revision: yes
-
Referee: [Evaluation section] Evaluation section: No quantitative results, ablation studies, or error analysis are provided to test whether the typed intermediate artifacts reliably avoid introducing errors in evidence handling or whether performance on the described tasks translates to improved real-world research decisions. This leaves the weakest assumption in the abstract unexamined.
Authors: We agree that the evaluation section is a critical weakness. The current manuscript describes the tasks but supplies no numerical results, ablations, or error analysis. In the revised manuscript we will add a full quantitative evaluation that reports performance metrics with baselines and error bars on the three tasks, ablation experiments isolating the contribution of the typed artifacts to error reduction in evidence handling, and a discussion of how the observed performance relates to real-world research decision-making. revision: yes
Circularity Check
No significant circularity
full rationale
The paper presents a multi-agent orchestration system that ingests external inputs (disease name, protein association table, cohort metadata) and produces typed artifacts and interactive interfaces via decomposition, normalization, and conversion steps. No equations, fitted parameters, predictions, or first-principles derivations are described that reduce to the inputs by construction. No self-citations, uniqueness theorems, or ansatzes are invoked in the abstract or summary. The evaluation claims rest on performance on standardized external tasks rather than internal self-referential fitting. This is the expected honest non-finding for a systems description paper.
Axiom & Free-Parameter Ledger
invented entities (1)
-
typed intermediate artifacts
no independent evidence
Reference graph
Works this paper leans on
-
[1]
DR Tulu: Reinforcement Learning with Evolving Rubrics for Deep Research
DR Tulu: Reinforcement Learning with Evolving Rubrics for Deep Research , author =. International Conference on Machine Learning , year =. doi:10.48550/arXiv.2511.19399 , url =. 2511.19399 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2511.19399
-
[2]
2025 , eprint =
WebExplorer: Explore and Evolve for Training Long-Horizon Web Agents , author =. 2025 , eprint =
2025
-
[3]
WebThinker: Empowering Large Reasoning Models with Deep Research Capability
WebThinker: Empowering Large Reasoning Models with Deep Research Capability , author =. Advances in Neural Information Processing Systems , year =. doi:10.48550/arXiv.2504.21776 , url =. 2504.21776 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2504.21776
-
[4]
Search-R1: Training LLMs to Reason and Leverage Search Engines with Reinforcement Learning
Search-R1: Training LLMs to Reason and Leverage Search Engines with Reinforcement Learning , author =. 2025 , eprint =. doi:10.48550/arXiv.2503.09516 , url =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2503.09516 2025
-
[5]
Nature Reviews Genetics , year =
Network Medicine: A Network-Based Approach to Human Disease , author =. Nature Reviews Genetics , year =. doi:10.1038/nrg2918 , pmid =
-
[6]
Disease Networks: Uncovering Disease-Disease Relationships through the Incomplete Interactome , author =. Science , year =. doi:10.1126/science.1257601 , pmid =
-
[7]
Drug-Target Network , author =. Nature Biotechnology , year =. doi:10.1038/nbt1338 , pmid =
-
[8]
Pacific Symposium on Biocomputing 2020 , year =
A Literature-Based Knowledge Graph Embedding Method for Identifying Drug Repurposing Opportunities in Rare Diseases , author =. Pacific Symposium on Biocomputing 2020 , year =. doi:10.1142/9789811215636_0041 , pmid =
-
[9]
Scientific Data , year =
An Open Source Knowledge Graph Ecosystem for the Life Sciences , author =. Scientific Data , year =
-
[10]
Nucleic Acids Research , year =
Open Targets Platform: Facilitating Therapeutic Hypotheses Building in Drug Discovery , author =. Nucleic Acids Research , year =. doi:10.1093/nar/gkae1128 , pmid =
-
[11]
Nature Reviews Drug Discovery , year =
Improving Target Assessment in Biomedical Research: The GOT-IT Recommendations , author =. Nature Reviews Drug Discovery , year =. doi:10.1038/s41573-020-0087-3 , pmid =
-
[12]
Nucleic Acids Research , year =
Open Targets: A Platform for Therapeutic Target Identification and Validation , author =. Nucleic Acids Research , year =. doi:10.1093/nar/gkw1055 , pmid =
-
[13]
Pacific Symposium on Biocomputing , volume=
Large-scale analysis of disease pathways in the human interactome , author=. Pacific Symposium on Biocomputing , volume=
-
[14]
In: arXiv preprint arXiv:2508.07976 (2025)
Beyond Ten Turns: Unlocking Long-Horizon Agentic Search with Large-Scale Asynchronous RL , author =. 2025 , eprint =. doi:10.48550/arXiv.2508.07976 , url =
-
[15]
Tongyi DeepResearch Technical Report
Tongyi DeepResearch Technical Report , author =. 2025 , eprint =. doi:10.48550/arXiv.2510.24701 , url =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2510.24701 2025
-
[16]
arXiv preprint arXiv:2603.25723 , year=
Natural-Language Agent Harnesses , author=. arXiv preprint arXiv:2603.25723 , year=
-
[17]
Advances in Neural Information Processing Systems , year=
SWE-agent: Agent-Computer Interfaces Enable Automated Software Engineering , author=. Advances in Neural Information Processing Systems , year=
-
[18]
2026 , url =
Agent Harness Engineering: A Survey , author =. 2026 , url =
2026
-
[19]
First Conference on Language Modeling , year =
AutoGen: Enabling Next-Gen LLM Applications via Multi-Agent Conversation , author =. First Conference on Language Modeling , year =
-
[20]
International Conference on Learning Representations , year =
ReAct: Synergizing Reasoning and Acting in Language Models , author =. International Conference on Learning Representations , year =. 2210.03629 , archivePrefix =
-
[21]
Corrective Retrieval Augmented Generation
Corrective Retrieval Augmented Generation , author =. 2024 , eprint =. doi:10.48550/arXiv.2401.15884 , url =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2401.15884 2024
-
[22]
International Conference on Learning Representations , year =
Self-RAG: Learning to Retrieve, Generate, and Critique through Self-Reflection , author =. International Conference on Learning Representations , year =. 2310.11511 , archivePrefix =
-
[23]
RAGAs: Automated Evaluation of Retrieval Augmented Generation , author =. Proceedings of the 18th Conference of the European Chapter of the Association for Computational Linguistics: System Demonstrations , year =. doi:10.18653/v1/2024.eacl-demo.16 , url =
-
[24]
PaperVoyager : Building Interactive Web with Visual Language Models
PaperVoyager: Building Interactive Web with Visual Language Models , author =. 2026 , eprint =. doi:10.48550/arXiv.2603.22999 , url =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2603.22999 2026
-
[25]
Generative UI: LLMs are Effective UI Generators
Generative UI: LLMs are Effective UI Generators , author =. 2026 , eprint =. doi:10.48550/arXiv.2604.09577 , url =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2604.09577 2026
-
[26]
2026 , month = apr, howpublished =
A2UI v0.9: The New Standard for Portable, Framework-Agnostic Generative UI , author =. 2026 , month = apr, howpublished =
2026
-
[27]
bioRxiv (2025) https://doi.org/10.1101/2025.05.30.656746
Biomni: A General-Purpose Biomedical AI Agent , author =. bioRxiv , year =. doi:10.1101/2025.05.30.656746 , publisher =
-
[28]
Briefings in Bioinformatics , volume =
BioRAGent: Natural Language Biomedical Querying with Retrieval-Augmented Multiagent Systems , author =. Briefings in Bioinformatics , volume =. 2025 , doi =
2025
-
[29]
arXiv preprint arXiv:2505.01146 , year =
Retrieval-Augmented Generation in Biomedicine: A Survey of Technologies, Datasets, and Clinical Applications , author =. arXiv preprint arXiv:2505.01146 , year =
-
[30]
An Introduction to and Survey of Biological Network Visualization , author =. Computers & Graphics , year =. doi:10.1016/j.cag.2024.104115 , url =
-
[31]
BioMedSearch: A Multi-Source Biomedical Retrieval Framework Based on LLMs , author =. 2025 , eprint =. doi:10.48550/arXiv.2510.13926 , url =
-
[32]
BMJ , volume =
The PRISMA 2020 statement: an updated guideline for reporting systematic reviews , author =. BMJ , volume =. 2021 , doi =
2020
-
[33]
Research Synthesis Methods , year =
Position statement on artificial intelligence use in evidence synthesis , author =. Research Synthesis Methods , year =
-
[34]
Research Synthesis Methods , year =
Generative artificial intelligence use in evidence synthesis: a systematic review , author =. Research Synthesis Methods , year =
-
[35]
npj Digital Medicine , volume =
Accelerating Clinical Evidence Synthesis with Large Language Models , author =. npj Digital Medicine , volume =. 2025 , month = aug, doi =
2025
-
[36]
Journal of Biomedical Informatics , volume =
Leveraging Generative AI for Clinical Evidence Synthesis Needs to Ensure Trustworthiness , author =. Journal of Biomedical Informatics , volume =. 2024 , month = may, doi =
2024
-
[37]
Cell , volume =
Empowering Biomedical Discovery with AI Agents , author =. Cell , volume =. 2024 , month = oct, doi =
2024
-
[38]
Journal of Medical Internet Research , volume =
Provenance Information for Biomedical Data and Workflows: Scoping Review , author =. Journal of Medical Internet Research , volume =. 2024 , month = aug, doi =
2024
-
[39]
Deep research: A survey of autonomous research agents.arXiv preprint arXiv:2508.12752, 2025
Deep Research: A Survey of Autonomous Research Agents , author =. arXiv preprint arXiv:2508.12752 , year =. doi:10.48550/arXiv.2508.12752 , url =. 2508.12752 , archivePrefix =
-
[40]
Towards Trustworthy Report Generation: A Deep Research Agent with Progressive Confidence Estimation and Calibration , author =. arXiv preprint arXiv:2604.05952 , year =. doi:10.48550/arXiv.2604.05952 , url =. 2604.05952 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2604.05952
-
[41]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing: System Demonstrations , pages=
Tinyscientist: An interactive, extensible, and controllable framework for building research agents , author=. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing: System Demonstrations , pages=
2025
-
[42]
S afe S cientist: Enhancing AI Scientist Safety for Risk-Aware Scientific Discovery
Zhu, Kunlun and Zhang, Jiaxun and Qi, Ziheng and Shang, Nuoxing and Liu, Zijia and Han, Peixuan and Su, Yue and Yu, Haofei and You, Jiaxuan. S afe S cientist: Enhancing AI Scientist Safety for Risk-Aware Scientific Discovery. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. 2025. doi:10.18653/v1/2025.emnlp-main.116
-
[43]
An Evidence-Grounded Research Assistant for Functional Genomics and Drug Target Assessment , author =. bioRxiv , year =. doi:10.64898/2025.12.30.697073 , url =
-
[44]
Experimental IR Meets Multilinguality, Multimodality, and Interaction , publisher =
Overview of BioASQ 2025: The Thirteenth BioASQ Challenge on Large-Scale Biomedical Semantic Indexing and Question Answering , author =. Experimental IR Meets Multilinguality, Multimodality, and Interaction , publisher =. 2025 , eprint =. doi:10.48550/arXiv.2508.20554 , url =
-
[45]
Widesearch: Benchmarking agentic broad info-seeking, 2025
WideSearch: Benchmarking Agentic Broad Info-Seeking , author =. 2025 , eprint =. doi:10.48550/arXiv.2508.07999 , url =
-
[46]
arXiv preprint arXiv:2601.11957 , year=
PEARL: Self-Evolving Assistant for Time Management with Reinforcement Learning , author=. arXiv preprint arXiv:2601.11957 , year=
-
[47]
METAL : A Multi-Agent Framework for Chart Generation with Test-Time Scaling
Li, Bingxuan and Wang, Yiwei and Gu, Jiuxiang and Chang, Kai-Wei and Peng, Nanyun. METAL : A Multi-Agent Framework for Chart Generation with Test-Time Scaling. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2025. doi:10.18653/v1/2025.acl-long.1452
-
[48]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =
Li, Bingxuan and Cui, Yiming and He, Yicheng and Wang, Yiwei and Zhang, Shu and Wen, Longyin and Niu, Yulei , title =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =. 2026 , pages =
2026
-
[49]
arXiv preprint arXiv:2603.07978 , year=
Osexpert: Computer-use agents learning professional skills via exploration , author=. arXiv preprint arXiv:2603.07978 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.