Scalable Hierarchical Attention Transformers for Multi-Turn Jailbreak Detection in Long Conversations
Pith reviewed 2026-06-26 14:21 UTC · model grok-4.3
The pith
A hierarchical attention transformer detects multi-turn jailbreaks by encoding turns separately then applying a lightweight conversation module.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that encoding individual turns into compact representations and routing them through a conversation module that combines cross-attention and self-attention produces accurate conversation-level classification of jailbreak intent, delivering higher F1 and lower false positives than strong baselines on a large held-out set of 14,038 dialogues.
What carries the argument
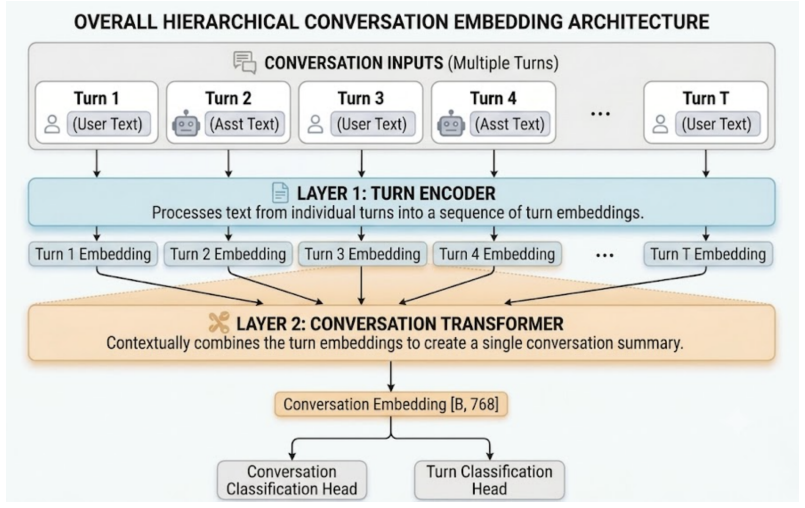
The hierarchical detector that first encodes each turn separately and then applies a conversation module combining cross-attention and self-attention to capture dialogue dynamics.
If this is right
- The method scales detection to long conversations without the quadratic cost of full-context concatenation.
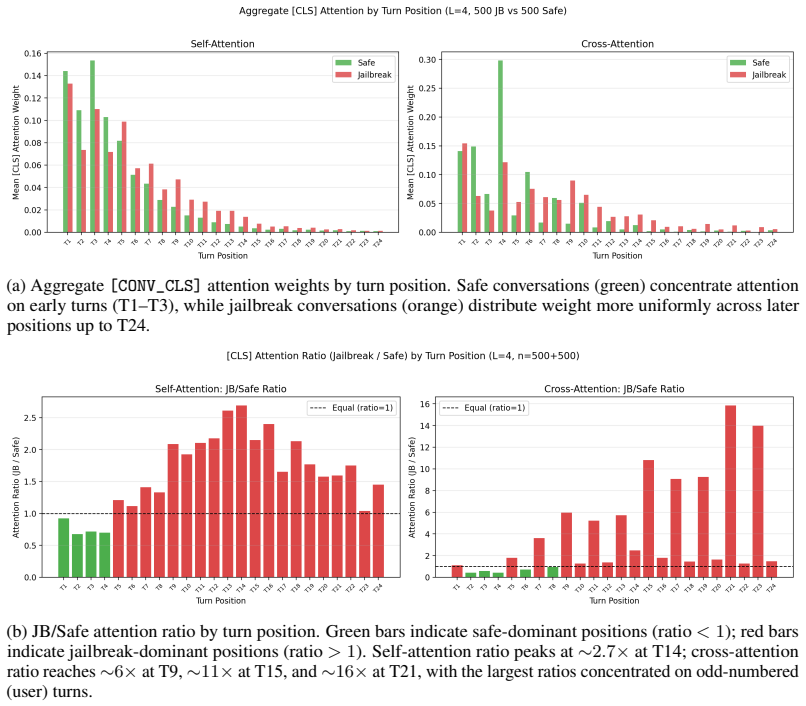
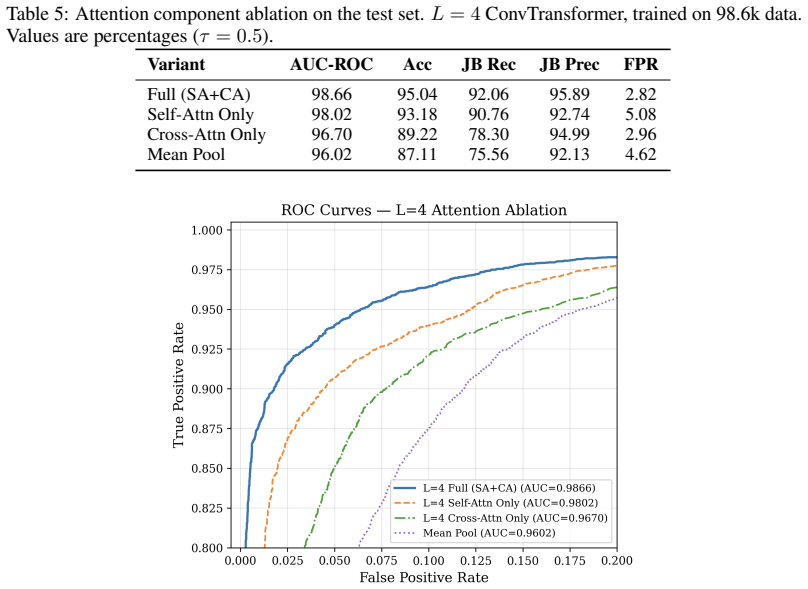
- Combining cross-attention and self-attention inside the conversation module reduces the false-positive rate by 2.26 percentage points relative to self-attention alone.
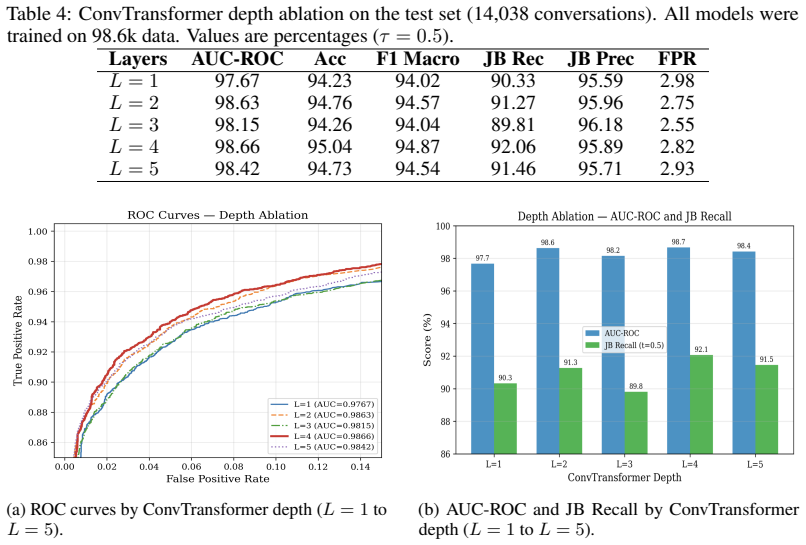
- Each architectural component contributes measurably to overall accuracy, as shown by ablation results.
- The detector outperforms Claude Opus 4.7 by 0.07 F1 while halving its false-positive rate on the 14,038-conversation benchmark.
Where Pith is reading between the lines
- The same turn-then-conversation structure could be tested on other gradual dialogue-safety tasks such as detecting persistent misinformation or manipulation.
- Deployment in production chat systems would allow moderators to review only the flagged evidence segments rather than entire histories.
- Extending the conversation module with additional lightweight layers might further improve capture of very long-range dependencies while preserving efficiency.
Load-bearing premise
The 14,038-conversation benchmark accurately represents the distribution and difficulty of real-world multi-turn jailbreak attempts and the architecture captures all necessary cross-turn dynamics without loss of critical information.
What would settle it
Performance falling substantially below the reported F1 on an independent set of conversations that use escalation patterns or reframing tactics absent from the original benchmark would falsify the claim of robust detection.
Figures
read the original abstract
Multi-turn jailbreaks can evade turn-level moderation by spreading unsafe intent across a dialogue through gradual escalation, reframing, and role manipulation. We address multi-turn jailbreak detection as a conversation-level classification problem and introduce an efficient hierarchical detector that avoids expensive long-context concatenation while retaining cross-turn reasoning. The model encodes individual turns to form compact turn representations and applies a lightweight conversation module that captures dialogue dynamics and selectively attends to fine-grained evidence when needed. On a challenging evaluation benchmark of 14,038 conversations, our approach achieves an F1 of 0.9394, outperforming Claude Opus 4.7, the strongest competing baseline, by 0.07 while halving its false-positive rate. Ablation studies confirm that each architectural component contributes meaningfully, with combining cross-attention and self-attention in the conversation module yielding a 2.26 percentage point reduction in false-positive rate over the self-attention-only variant.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces a hierarchical attention transformer architecture for conversation-level multi-turn jailbreak detection. Individual turns are encoded into compact representations, after which a lightweight conversation module combines cross-attention and self-attention to model dialogue dynamics and selectively attend to evidence. On a benchmark of 14,038 conversations the model reports an F1 of 0.9394, exceeding Claude Opus 4.7 by 0.07 while halving its false-positive rate; ablation experiments are cited to show that each architectural component contributes.
Significance. If the evaluation benchmark is representative, the work supplies a computationally efficient alternative to full long-context models for an important safety task. The explicit ablation results that quantify the contribution of the combined attention mechanism constitute a methodological strength.
major comments (2)
- [§5.1] §5.1 (Benchmark Construction): No description is given of how the 14,038 conversations were sourced, labeled, or stratified with respect to escalation strategies, reframing, or role manipulation. Because the headline F1=0.9394 and false-positive halving are measured exclusively on this corpus, the absence of these details makes it impossible to determine whether the reported gains generalize beyond the particular distribution used for evaluation.
- [§5.3] §5.3 (Ablation and Statistical Reporting): The ablation table reports a 2.26 percentage-point false-positive reduction when cross-attention is added, yet no confidence intervals, p-values, or information on the number of random seeds or data splits is supplied. Without these, the claim that each component “contributes meaningfully” cannot be assessed for robustness.
minor comments (1)
- The abstract states quantitative results but the main text should ensure that every table and figure caption explicitly lists the exact metric definitions and the precise baseline versions (e.g., “Claude Opus 4.7”) used for comparison.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and agree that revisions will strengthen the manuscript's clarity and rigor.
read point-by-point responses
-
Referee: [§5.1] §5.1 (Benchmark Construction): No description is given of how the 14,038 conversations were sourced, labeled, or stratified with respect to escalation strategies, reframing, or role manipulation. Because the headline F1=0.9394 and false-positive halving are measured exclusively on this corpus, the absence of these details makes it impossible to determine whether the reported gains generalize beyond the particular distribution used for evaluation.
Authors: We acknowledge that the manuscript does not provide a detailed description of benchmark construction. In the revised version we will expand §5.1 to include the sourcing methodology, labeling protocol, and stratification approach with respect to escalation strategies, reframing, and role manipulation. This addition will allow readers to assess generalizability of the reported F1 and false-positive improvements. revision: yes
-
Referee: [§5.3] §5.3 (Ablation and Statistical Reporting): The ablation table reports a 2.26 percentage-point false-positive reduction when cross-attention is added, yet no confidence intervals, p-values, or information on the number of random seeds or data splits is supplied. Without these, the claim that each component “contributes meaningfully” cannot be assessed for robustness.
Authors: We agree that the ablation results would benefit from statistical details. In the revision we will update §5.3 to report performance across multiple random seeds, include confidence intervals, and provide p-values supporting the contribution of each component, including the observed 2.26 percentage-point false-positive reduction. revision: yes
Circularity Check
No derivation chain or equations present; results are direct empirical measurements.
full rationale
The paper describes a hierarchical attention model for conversation-level classification and reports F1=0.9394 on a fixed benchmark of 14,038 conversations. No equations, derivations, fitted parameters renamed as predictions, or self-citation load-bearing steps appear in the provided text. Performance claims are presented as measurements against external baselines (Claude Opus 4.7) rather than reductions to model inputs. The benchmark construction is an assumption about data representativeness, not a circularity in any claimed derivation.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
2025 , note =
Mitigating Many-Shot Jailbreaking , author =. 2025 , note =
2025
-
[2]
The Echo Chamber Multi-Turn
Alobaid, Ahmad and Jord. The Echo Chamber Multi-Turn. 2026 , note =
2026
-
[3]
Advances in Neural Information Processing Systems , year =
Many-shot Jailbreaking , author =. Advances in Neural Information Processing Systems , year =
-
[4]
Constitutional
Bai, Yuntao and others , year =. Constitutional
-
[5]
2020 , note =
Longformer: The Long-Document Transformer , author =. 2020 , note =
2020
-
[6]
Proceedings of the World Wide Web Conference (WWW) , year =
Nuanced Metrics for Measuring Unintended Bias with Real Data for Text Classification , author =. Proceedings of the World Wide Web Conference (WWW) , year =
-
[7]
Advances in Neural Information Processing Systems , year =
Jailbreaking Black Box Large Language Models in Twenty Queries , author =. Advances in Neural Information Processing Systems , year =
-
[8]
International Conference on Learning Representations , year =
Rethinking Attention with Performers , author =. International Conference on Learning Representations , year =
-
[9]
and Salakhutdinov, Ruslan , booktitle =
Dai, Zihang and Yang, Zhilin and Yang, Yiming and Carbonell, Jaime and Le, Quoc V. and Salakhutdinov, Ruslan , booktitle =. Transformer-
-
[10]
Not What You
Greshake, Kai and Abdelnabi, Sahar and Mishra, Shailesh and Endres, Christoph and Holz, Thorsten and Fritz, Mario , booktitle =. Not What You
-
[11]
2020 , howpublished =
Detoxify , author =. 2020 , howpublished =
2020
-
[12]
International Conference on Learning Representations , year =
Reformer: The Efficient Transformer , author =. International Conference on Learning Representations , year =
-
[13]
Automating Deception: Scalable Multi-Turn
Kumarappan, Adarsh and Mujoo, Ananya , year =. Automating Deception: Scalable Multi-Turn
-
[14]
Liu, Xiaogeng and Xu, Nan and Chen, Muhao and Xiao, Chaowei , year =
-
[15]
Tree of Attacks: Jailbreaking Black-Box
Mehrotra, Anay and others , year =. Tree of Attacks: Jailbreaking Black-Box
-
[16]
Narula, Sidhant and Rafiei Asl, Javad and Ghasemigol, Mohammad and Blanco, Eduardo and Takabi, Daniel , year =
-
[17]
Advances in Neural Information Processing Systems , year =
Training Language Models to Follow Instructions with Human Feedback , author =. Advances in Neural Information Processing Systems , year =
-
[18]
Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing , year =
Red Teaming Language Models with Language Models , author =. Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing , year =
2022
-
[19]
International Conference on Learning Representations , year =
Compressive Transformers for Long-Range Sequence Modelling , author =. International Conference on Learning Representations , year =
-
[20]
Great, Now Write an Article About That: The Crescendo Multi-Turn
Russinovich, Mark and Salem, Ahmed and Eldan, Ronen , year =. Great, Now Write an Article About That: The Crescendo Multi-Turn
-
[21]
2020 , note =
Linformer: Self-Attention with Linear Complexity , author =. 2020 , note =
2020
-
[22]
Jailbroken: How Does
Wei, Alexander and Haghtalab, Nika and Steinhardt, Jacob , booktitle =. Jailbroken: How Does
-
[23]
Proceedings of NAACL-HLT , year =
Hierarchical Attention Networks for Document Classification , author =. Proceedings of NAACL-HLT , year =
-
[24]
2025 , note =
Many-Turn Jailbreaking , author =. 2025 , note =
2025
-
[25]
Advances in Neural Information Processing Systems , year =
Big Bird: Transformers for Longer Sequences , author =. Advances in Neural Information Processing Systems , year =
-
[26]
Zhan, Qiusi and Liang, Zhixiang and Ying, Zifan and Kang, Daniel , booktitle =
-
[27]
Advances in Neural Information Processing Systems , year =
Universal and Transferable Adversarial Attacks on Aligned Language Models , author =. Advances in Neural Information Processing Systems , year =
-
[28]
Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing (EMNLP) , year =
Enhancing Chat Language Models by Scaling High-quality Instructional Conversations , author =. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing (EMNLP) , year =
2023
-
[29]
Zhao, Wenting and Ren, Xiang and Hessel, Jack and Cardie, Claire and Choi, Yejin and Deng, Yuntian , booktitle =
-
[30]
2023 , howpublished =
2023
-
[31]
Advances in Neural Information Processing Systems (NeurIPS), Datasets and Benchmarks Track , year =
K. Advances in Neural Information Processing Systems (NeurIPS), Datasets and Benchmarks Track , year =
-
[32]
Derail Yourself: Multi-turn
Ren, Qibing and Li, Hao and Liu, Dongrui and Xie, Zhanxu and Lu, Xiaoya and Qiao, Yu and Sha, Lei and Yan, Junchi and Ma, Lizhuang and Shao, Jing , journal =. Derail Yourself: Multi-turn
-
[33]
Abishethvarman, Vigneswar and Naseem, Usman and others , journal =
-
[34]
Findings of the Association for Computational Linguistics (ACL) , year =
Red Queen: Exposing Latent Multi-Turn Risks in Large Language Models , author =. Findings of the Association for Computational Linguistics (ACL) , year =
-
[35]
Cao, Hongyu and Wang, Yuyang and Jing, Shuo and others , journal =
-
[36]
arXiv preprint arXiv:2409.00137 , year =
Emerging Vulnerabilities in Frontier Models: Multi-Turn Jailbreak Attacks , author =. arXiv preprint arXiv:2409.00137 , year =
-
[37]
Malicious-Educator: A Benchmark for Stress-Testing
Zhang, Jiahao and Kuo, Michael and Chen, Yuheng and Li, Hai , journal =. Malicious-Educator: A Benchmark for Stress-Testing. 2025 , note =
2025
-
[38]
Priyanshu, Aman and Vijay, Supriti , journal =
-
[39]
arXiv preprint arXiv:2410.10700 , year =
Gradual Escalation: A Multi-Turn Jailbreak Attack on Large Language Models , author =. arXiv preprint arXiv:2410.10700 , year =
-
[40]
arXiv preprint arXiv:2212.03533 , year =
Text Embeddings by Weakly-Supervised Contrastive Pre-training , author =. arXiv preprint arXiv:2212.03533 , year =
-
[41]
Dubey, Abhimanyu and Jauhri, Akhil and Pandey, Abhinav and Kadian, Abhishek and others , journal =. The
-
[42]
2026 , howpublished =
Claude: Model Card and Evaluations , author =. 2026 , howpublished =
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.