Decodable but Not Faithful: Coupling Natural-Language Rationales to Programmatic Verifiers
Pith reviewed 2026-06-26 14:31 UTC · model grok-4.3
The pith
Consistency training makes verifier signals decodable from rationale representations without guaranteeing that generated explanations match the model's actual reasoning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
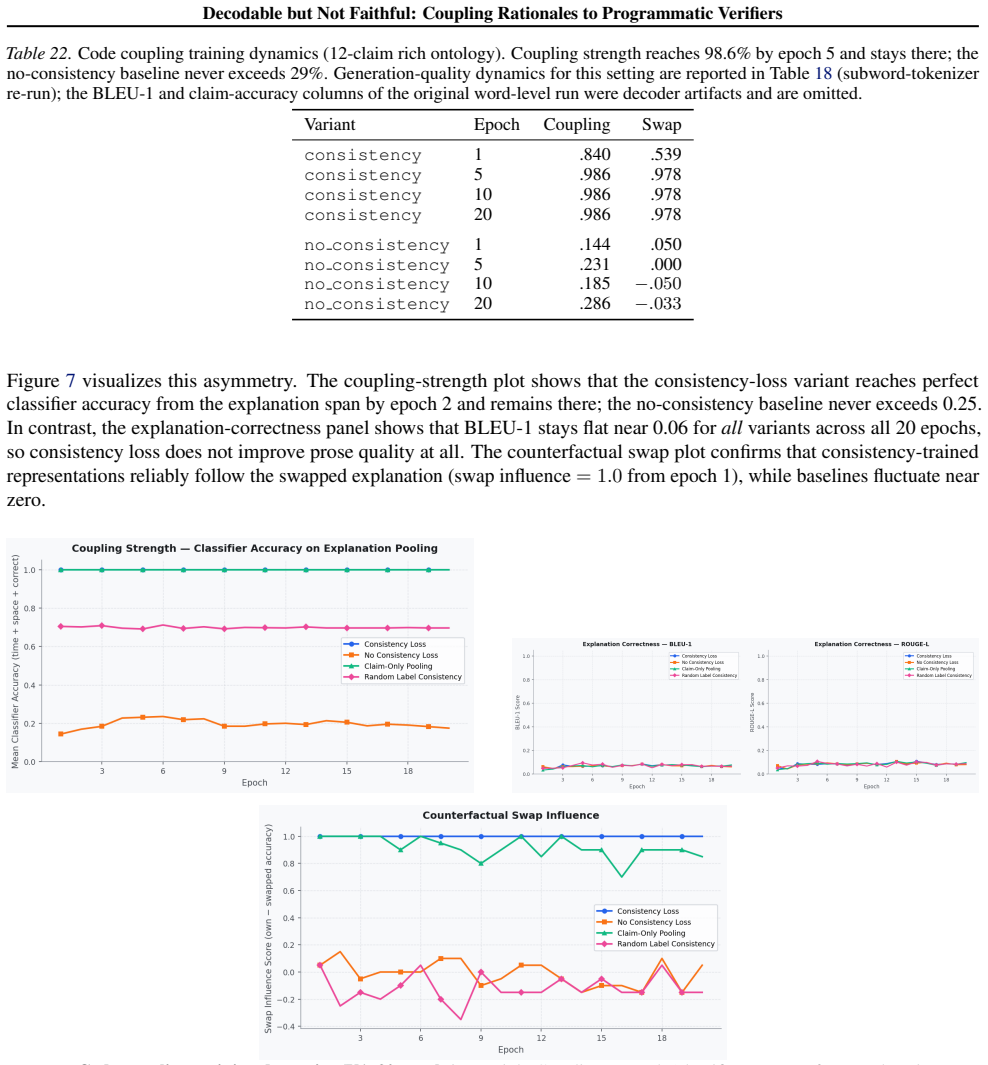
The central claim is that consistency training reliably makes verifier information decodable from rationale representations, but decodability does not guarantee faithful generation. In LeanCheck, rationale-only and proof-only pooling achieve perfect directional separation under counterfactual conflict. In KataGo, commentary spans encode 10-way win-rate buckets at 81 percent accuracy. In a code setting the model reaches 98.6 percent coupling while its generated explanations remain unfaithful, describing unrelated algorithms despite correct structured claims; a pretrained-versus-from-scratch comparison shows the gap is not driven by capacity. Synthetic activation patching confirms causal influ
What carries the argument
verifier-coupled reasoning framework that inserts inline claims into reasoning traces and trains an auxiliary consistency head to predict programmatic verifier outputs from rationale-span hidden states
If this is right
- Consistency training serves as a diagnostic and representation-shaping tool across theorem proving, game commentary, and code generation.
- High coupling accuracy can coexist with explanations that describe unrelated algorithms while preserving correct structured claims.
- The gap between decodability and faithfulness persists after controlling for model capacity via pretrained versus from-scratch comparisons.
- Consistency loss improves fine-grained claim alignment more than binary claim alignment.
- Evidence-only pooling in fact-verification settings isolates genuine evidence sensitivity at the cost of raw accuracy.
Where Pith is reading between the lines
- Additional constraints beyond consistency losses may be required to close the observed gap between decodable information and faithful output text.
- The same training dynamic could be tested in other domains that supply programmatic verifiers, such as symbolic mathematics or automated planning.
- If verifier choice itself encodes incomplete criteria, the measured gap might shrink or widen when alternative verifiers are substituted.
Load-bearing premise
The programmatic verifiers used in each domain correctly capture the reasoning the model should be faithful to.
What would settle it
A controlled experiment in which the same model is trained to high verifier-decodability accuracy yet, under activation patching that selectively alters rationale hidden states, produces explanations whose factual content changes while the final prediction remains fixed.
Figures








read the original abstract
Language models can generate plausible rationales for their predictions, but these explanations may not faithfully represent the model's internal reasoning. We propose verifier-coupled reasoning, a framework that inserts inline claims into reasoning traces and trains an auxiliary consistency head to predict programmatic verifier outputs from rationale-span hidden states. The central finding is a gap between decodability and faithfulness: consistency training reliably makes verifier information decodable from rationale representations, but decodability does not guarantee faithful generation. In LeanCheck (formal theorem proving), rationale-only and proof-only pooling achieve perfect directional separation under counterfactual conflict. In KataGo (Go engine), commentary spans encode 10-way win-rate buckets at 81% accuracy. Yet in a code setting, the model achieves 98.6% coupling while its generated explanations remain unfaithful: fluent prose with correct structured claims, but describing unrelated algorithms; a controlled pretrained-vs-from-scratch comparison shows the gap is not capacity-driven. Synthetic activation patching confirms causal influence (73-89% vs. 31% baseline), FEVER reveals that evidence-only pooling isolates genuine evidence sensitivity at the cost of raw accuracy, and per-claim analysis shows that consistency loss disproportionately benefits fine-grained claims over binary ones. These results establish that consistency losses are effective diagnostics and representation-shaping tools, but not sufficient conditions for faithful reasoning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces verifier-coupled reasoning, a framework that augments rationale generation with inline claims checked by programmatic verifiers (LeanCheck, KataGo, code execution) and trains an auxiliary consistency head to decode verifier outputs from rationale-span hidden states. The central empirical claim is a decodability-faithfulness gap: consistency training reliably renders verifier information decodable (98.6% coupling in code; 81% accuracy for 10-way win-rate buckets in KataGo; perfect directional separation in LeanCheck), yet does not guarantee faithful generation, as shown by unfaithful code rationales (correct structured claims but unrelated algorithms), activation patching (73-89% vs. 31% baseline), FEVER evidence sensitivity, and per-claim loss analysis.
Significance. If the reported gap holds under the experimental controls, the work supplies a concrete diagnostic and representation-shaping tool (consistency losses) while demonstrating its insufficiency for faithful reasoning. The pretrained-vs-from-scratch control and synthetic patching results are strengths that help isolate the effect from capacity; the framework is falsifiable via the reported metrics and could inform future interpretability methods that couple external verifiers to internal states.
major comments (2)
- [code setting experiments] Code-domain results: the 98.6% coupling with unfaithful outputs is load-bearing for the decodability-faithfulness gap. The manuscript rules out capacity via the pretrained-vs-from-scratch comparison but does not report a direct test that the code-execution verifier aligns with the model's actual computation trace (rather than an incomplete or divergent criterion), leaving open the possibility that the observed mismatch is a verifier-model artifact rather than an intrinsic limitation of rationale generation.
- [synthetic activation patching] Activation patching results: the 73-89% recovery (vs. 31% baseline) demonstrates causal influence of the consistency head on the patched representations, but the manuscript does not show that the same interventions also increase faithfulness of the generated rationales (as opposed to merely restoring consistency-head accuracy). This weakens the link between the patching evidence and the claim that decodability does not guarantee faithfulness.
minor comments (2)
- [LeanCheck experiments] Notation for pooling operations (rationale-only vs. proof-only) is introduced without an explicit equation; adding a short definition would improve reproducibility.
- [per-claim analysis] The per-claim analysis states that consistency loss disproportionately benefits fine-grained claims; a table or figure breaking down accuracy by claim granularity would make this quantitative claim easier to evaluate.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback and positive evaluation of the work's significance. We address each major comment below.
read point-by-point responses
-
Referee: [code setting experiments] Code-domain results: the 98.6% coupling with unfaithful outputs is load-bearing for the decodability-faithfulness gap. The manuscript rules out capacity via the pretrained-vs-from-scratch comparison but does not report a direct test that the code-execution verifier aligns with the model's actual computation trace (rather than an incomplete or divergent criterion), leaving open the possibility that the observed mismatch is a verifier-model artifact rather than an intrinsic limitation of rationale generation.
Authors: We appreciate this observation. The code-execution verifier serves as an external check on the specific claims embedded in the rationales. In the unfaithful cases, the rationales contain correct structured claims (passing the verifier) but describe algorithms unrelated to the actual code generated by the model. This indicates a disconnect between the rationale content and the computation, independent of whether the verifier perfectly matches every aspect of the model's trace. The from-scratch control helps rule out capacity issues. We will add a discussion paragraph acknowledging that a more granular alignment between verifier criteria and model internals could further strengthen the interpretation, though the current evidence supports the gap as reported. revision: partial
-
Referee: [synthetic activation patching] Activation patching results: the 73-89% recovery (vs. 31% baseline) demonstrates causal influence of the consistency head on the patched representations, but the manuscript does not show that the same interventions also increase faithfulness of the generated rationales (as opposed to merely restoring consistency-head accuracy). This weakens the link between the patching evidence and the claim that decodability does not guarantee faithfulness.
Authors: The synthetic activation patching is intended to establish the causal role of the consistency-trained representations in enabling the high decodability. It shows that the head's influence is not merely correlational. The core evidence for the decodability-faithfulness gap remains the code-domain results, where high coupling (98.6%) co-occurs with unfaithful rationales. We agree that directly assessing whether patching improves faithfulness metrics would provide a tighter link and will include this as a suggested direction for future work in the revised manuscript. The current results still demonstrate that consistency training shapes representations for decodability without ensuring faithfulness. revision: partial
Circularity Check
No significant circularity; empirical results rest on external verifiers
full rationale
The paper reports empirical measurements of decodability (e.g., 81% accuracy on KataGo win-rate buckets, 98.6% coupling in code) and faithfulness gaps using independent programmatic verifiers (LeanCheck, KataGo, code execution) that are not defined or fitted within the paper's own training loops. Activation patching, pretrained-vs-from-scratch controls, and per-claim analyses compare against these external oracles rather than reducing to self-referential quantities. No equations, self-citations, or ansatzes are invoked to derive the central decodability-faithfulness distinction; the work is self-contained against the stated benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Programmatic verifiers in each domain (Lean, KataGo, code execution) provide a reliable external signal against which faithfulness can be measured.
Reference graph
Works this paper leans on
-
[1]
Evaluating Large Language Models Trained on Code
URL https://arxiv.org/abs/ 2107.03374. Christiano, P. F., Leike, J., Brown, T., Martic, M., Legg, S., and Amodei, D. Deep reinforcement learning from hu- man preferences. InAdvances in Neural Information Pro- cessing Systems,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Deep reinforcement learning from human preferences
URL https://arxiv.org/ abs/1706.03741. Cobbe, K., Kosaraju, V ., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al. Training verifiers to solve math word problems,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Training Verifiers to Solve Math Word Problems
URL https://arxiv.org/abs/ 2110.14168. de Moura, L. and Ullrich, S. The lean 4 the- orem prover and programming language. In Automated Deduction – CADE 28, pp. 625–635. Springer,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
doi: 10.1007/978-3-030-79876-5
-
[5]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
URL https://arxiv.org/abs/2501.12948. 9 Decodable but Not Faithful: Coupling Rationales to Programmatic Verifiers Dong, Y ., Jiang, X., Jin, Z., and Li, G. Self-play with execution feedback: Improving instruction-following ca- pabilities of large language models,
work page internal anchor Pith review Pith/arXiv arXiv
- [6]
-
[7]
acl-main.386/
URL https://aclanthology.org/2020. acl-main.386/. Lambert, N., Morrison, J., Pyatkin, V ., Huang, S., Ivi- son, H., Brahman, F., Miranda, L. J. V ., Liu, A., Dziri, N., Lyu, S., et al. T ¨ulu 3: Pushing frontiers in open language model post-training,
2020
-
[8]
Tulu 3: Pushing Frontiers in Open Language Model Post-Training
URL https: //arxiv.org/abs/2411.15124. Lanham, T., Chen, A., Radhakrishnan, A., Steiner, B., Denison, C., Hernandez, D., Li, D., Durmus, E., Hub- inger, E., Kernion, J., et al. Measuring faithfulness in chain-of-thought reasoning,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Measuring Faithfulness in Chain-of-Thought Reasoning
URL https: //arxiv.org/abs/2307.13702. Lightman, H., Kosaraju, V ., Burda, Y ., Edwards, H., Baker, B., Lee, T., Leike, J., Schulman, J., Sutskever, I., and Cobbe, K. Let’s verify step by step,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
URL https: //arxiv.org/abs/2305.20050. Luo, L., Liu, Y ., Liu, R., Phatale, S., Lara, H., Li, Y ., Shu, L., Zhu, Y ., Meng, L., Sun, J., and Rastogi, A. Im- prove mathematical reasoning in language models by automated process supervision,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Improve Mathematical Reasoning in Language Models by Automated Process Supervision
URL https: //arxiv.org/abs/2406.06592. Marks, S. and Tegmark, M. The geometry of truth: Emer- gent linear structure in large language model represen- tations of true/false datasets,
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
URL https:// arxiv.org/abs/2310.06824. Meng, K., Bau, D., Andonian, A., and Belinkov, Y . Locat- ing and editing factual associations in gpt. InAdvances in Neural Information Processing Systems,
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
Locating and Editing Factual Associations in GPT
URL https://arxiv.org/abs/2202.05262. Ouyang, L., Wu, J., Jiang, X., Almeida, D., Wainwright, C., Mishkin, P., Zhang, C., Agarwal, S., Slama, K., Ray, A., et al. Training language models to follow instruc- tions with human feedback. InAdvances in Neural Information Processing Systems,
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
Training language models to follow instructions with human feedback
URL https: //arxiv.org/abs/2203.02155. Pimentel, T., Valvoda, J., Hall Maudslay, R., Zmigrod, R., Williams, A., and Cotterell, R. Information-theoretic probing for linguistic structure. InProceedings of the 58th Annual Meeting of the Association for Computational Linguistics,
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
org/2020.acl-main.420/
URL https://aclanthology. org/2020.acl-main.420/. Shao, Z., Wang, P., Zhu, Q., Xu, R., Song, J., Bi, X., Zhang, H., Zhang, M., Li, Y . K., Wu, Y ., and Guo, D. Deepseekmath: Pushing the limits of mathemat- ical reasoning in open language models,
2020
-
[16]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
URL https://arxiv.org/abs/2402.03300. Silver, D., Huang, A., Maddison, C. J., Guez, A., Sifre, L., van den Driessche, G., Schrittwieser, J., Antonoglou, I., Panneershelvam, V ., Lanctot, M., et al. Mastering the game of go with deep neural networks and tree search.Nature, 529:484–489,
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
arXiv preprint arXiv:2406.10625 , year=
URL https://arxiv.org/ abs/2406.10625. Thorne, J., Vlachos, A., Christodoulopoulos, C., and Mit- tal, A. Fever: A large-scale dataset for fact extraction and verification. InProceedings of the 2018 Confer- ence of the North American Chapter of the Associa- tion for Computational Linguistics,
-
[18]
URLhttps://arxiv.org/abs/2305.04388. Uesato, J., Kushman, N., Kumar, R., Song, F., Siegel, N., Wang, L., Creswell, A., Irving, G., and Higgins, I. Solv- ing math word problems with process- and outcome- based feedback,
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
Solving math word problems with process- and outcome-based feedback
URL https://arxiv.org/ abs/2211.14275. Wang, P., Li, L., Shao, Z., Xu, R. X., Dai, D., Li, Y ., Chen, D., Wu, Y ., and Sui, Z. Math-shepherd: Ver- ify and reinforce llms step-by-step without human an- notations, 2023a. URL https://arxiv.org/abs/ 2312.08935. 10 Decodable but Not Faithful: Coupling Rationales to Programmatic Verifiers Wang, X., Wei, J., Sch...
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
URL https://arxiv.org/abs/ 2201.11903. Wu, D. J. Accelerating self-play learning in go,
work page internal anchor Pith review Pith/arXiv arXiv
- [21]
-
[22]
URLhttps://arxiv.org/abs/2309.16042. 11 Decodable but Not Faithful: Coupling Rationales to Programmatic Verifiers A Detailed Variant Tables A.1 Synthetic controls and scalar-claim variants The synthetic tables show why the auxiliary consistency objective is needed. The language-modeling objective can reach perfect generation while the rationale span carri...
work page internal anchor Pith review Pith/arXiv arXiv
-
[23]
Eval acc
Epoch Train acc. Eval acc. Train F1 Eval F1 1 .4858 .4889 .1953 .1955 2 .5272 .5228 .2440 .2375 3 .5561 .5539 .2747 .2674 4 .5873 .5544 .3964 .3206 5 .6288 .5617 .4573 .3123 Table 13.Go GPT-OSS per-claim results at epoch
1953
-
[24]
columns H–L,
Position Early opening with stones spread across the board; Black at Q3, N3, Q17, E17, D14, C13; White at F17, F16, D17, R16, S6, R5, S4. SmolLM output (verbatim, truncated) You are a Go review assistant. Given only a board position, write concise commentary... <|user|> Write commentary about this Go position. Use only the board position below... Board si...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.