Latent Confidence Alignment for LLM Self-Assessment
Pith reviewed 2026-06-26 11:19 UTC · model grok-4.3
The pith
A Rasch model metric called Latent Confidence Alignment Error measures how consistently an LLM's stated confidence matches the error probability implied by its ability and question difficulty.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We adopt a Rasch model-based latent ability framework and a metacognitive perspective, and propose Latent Confidence Alignment Error (LCAE) to measure the consistency between model self-assessment and the latent error probability implied by model ability and item difficulty. We further incorporate item difficulty as an external signal with a reasoning mechanism. Experiments on a medical-domain dataset with 20 models show that the proposed approach improves self-assessment quality without affecting model ability, and reveals an association between reliability and inference cost.
What carries the argument
Latent Confidence Alignment Error (LCAE), a metric that quantifies alignment between an LLM's confidence and the error probability derived from its latent ability and item difficulty under the Rasch model.
If this is right
- Optimizing for LCAE raises self-assessment quality on medical tasks while leaving model accuracy unchanged.
- Model reliability shows a measurable association with the computational cost required for inference.
- Item difficulty can be used as an external signal to separate genuine self-assessment from generation artifacts.
Where Pith is reading between the lines
- The same Rasch-based alignment could be tested on non-medical question sets to check whether the reliability-cost link holds outside the reported domain.
- Directly training models to minimize LCAE might produce systems whose confidence statements are more usable in high-stakes settings such as diagnosis support.
- If inference cost and reliability remain linked, cheaper inference methods could be screened early by their expected effect on self-assessment alignment.
Load-bearing premise
The Rasch model accurately represents the relationship between an LLM's ability, item difficulty, and the probability it will produce an erroneous response.
What would settle it
Re-running the experiments after deliberately violating Rasch model assumptions (for example by randomizing item difficulty labels) and checking whether LCAE optimization still improves self-assessment quality.
Figures

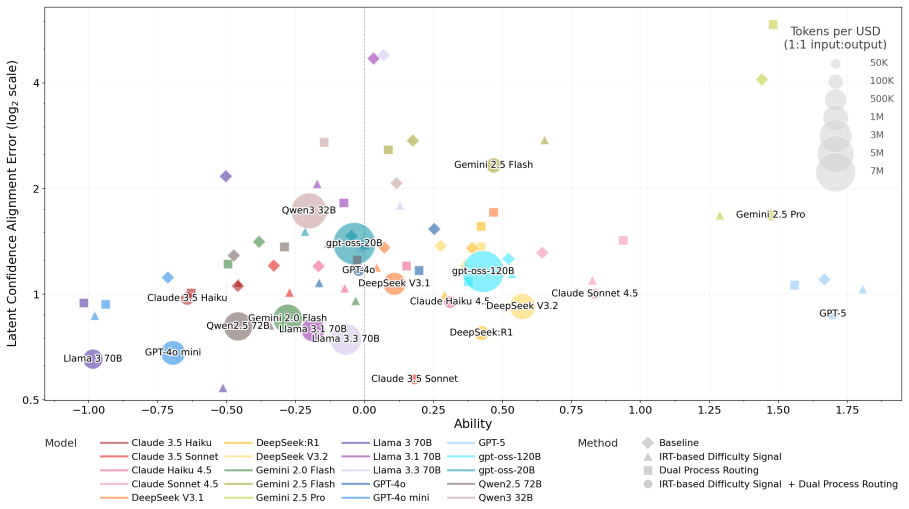
read the original abstract
Confidence calibration in large language models (LLMs) is commonly evaluated by comparing predicted confidence with observed accuracy. However, such approaches do not model item difficulty, making it difficult to interpret discrepancies and to determine whether model confidence reflects genuine self-assessment or is merely a byproduct of the response generation process. To address this, we adopt a Rasch model-based latent ability framework and a metacognitive perspective, and propose Latent Confidence Alignment Error (LCAE) to measure the consistency between model self-assessment and the latent error probability implied by model ability and item difficulty. We further incorporate item difficulty as an external signal with a reasoning mechanism. Experiments on a medical-domain dataset with 20 models show that the proposed approach improves self-assessment quality without affecting model ability, and reveals an association between reliability and inference cost.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript adopts a Rasch model-based latent ability framework to define Latent Confidence Alignment Error (LCAE) as a measure of consistency between LLM self-assessments and the latent error probability implied by model ability and item difficulty. It further incorporates item difficulty via a reasoning mechanism and reports experiments on a medical-domain dataset with 20 models claiming that the approach improves self-assessment quality without affecting model ability while revealing an association between reliability and inference cost.
Significance. If the Rasch model is shown to fit the observed LLM error patterns and LCAE adds information beyond the fitted parameters, the metric could provide a difficulty-aware alternative to standard calibration measures, with potential value for high-stakes applications such as medical question answering.
major comments (3)
- [Rasch model framework and experimental validation] The central empirical claims rest on the Rasch model P(error) = 1/(1+exp(θ−δ)) accurately describing error rates across the 20 LLMs and medical items, yet the manuscript supplies no item-response fit diagnostics, no test of unidimensionality, and no comparison against alternative IRT models or direct empirical error rates (see abstract and the Rasch model-based latent ability framework section).
- [Definition of LCAE] LCAE is defined directly from the latent error probability produced by the same Rasch model fitted to the data; without reported checks it is unclear whether the metric supplies independent information or largely restates the fitted ability and difficulty parameters (see definition of LCAE and the circularity concern in the metacognitive perspective section).
- [Abstract and Experiments section] The abstract states that the approach improves self-assessment quality but supplies no equations, validation statistics, or controls for how the Rasch parameters were estimated or how difficulty was incorporated, leaving the central empirical claim unsupported by visible evidence.
minor comments (1)
- [Methods] Notation for the Rasch parameters (θ, δ) and the exact formula for LCAE should be stated explicitly with equation numbers for reproducibility.
Simulated Author's Rebuttal
We thank the referee for their thorough review and constructive suggestions. We address each of the major comments point-by-point below, providing clarifications and committing to revisions where appropriate to strengthen the manuscript.
read point-by-point responses
-
Referee: [Rasch model framework and experimental validation] The central empirical claims rest on the Rasch model P(error) = 1/(1+exp(θ−δ)) accurately describing error rates across the 20 LLMs and medical items, yet the manuscript supplies no item-response fit diagnostics, no test of unidimensionality, and no comparison against alternative IRT models or direct empirical error rates (see abstract and the Rasch model-based latent ability framework section).
Authors: We agree that additional validation of the Rasch model assumptions would strengthen the paper. The current manuscript focuses on applying the Rasch framework to define LCAE rather than conducting a full IRT validation study. In the revised manuscript, we will include item fit diagnostics (e.g., infit and outfit statistics), a test of unidimensionality via principal component analysis of residuals, and a comparison to a 2PL IRT model. We will also report observed error rates binned by estimated difficulty to show alignment with the model predictions. revision: yes
-
Referee: [Definition of LCAE] LCAE is defined directly from the latent error probability produced by the same Rasch model fitted to the data; without reported checks it is unclear whether the metric supplies independent information or largely restates the fitted ability and difficulty parameters (see definition of LCAE and the circularity concern in the metacognitive perspective section).
Authors: LCAE is defined as the mean absolute deviation between self-reported confidence and the Rasch-derived latent error probability, serving as a measure of alignment rather than a restatement of θ or δ. To demonstrate that it provides independent information, we will add in the revision an analysis of the partial correlation between LCAE and model performance metrics after controlling for ability and difficulty. This will clarify its value as a metacognitive consistency metric beyond the base parameters. revision: yes
-
Referee: [Abstract and Experiments section] The abstract states that the approach improves self-assessment quality but supplies no equations, validation statistics, or controls for how the Rasch parameters were estimated or how difficulty was incorporated, leaving the central empirical claim unsupported by visible evidence.
Authors: The abstract provides a concise overview without technical details, as is standard. The Experiments section describes the dataset, models, and results, including how difficulty is incorporated via the reasoning mechanism. However, to better support the claims, we will revise the abstract to reference the key quantitative improvements (e.g., reduction in LCAE) and ensure the Experiments section explicitly states the estimation method (maximum likelihood for Rasch parameters) and any controls used. revision: partial
Circularity Check
No circularity: LCAE defined via external Rasch framework; empirical improvements shown separately
full rationale
The paper adopts the Rasch model (an established external IRT framework) to estimate latent ability/difficulty and define LCAE as alignment between self-assessment and the implied error probability. The central experiments then test an added reasoning mechanism that incorporates item difficulty as an external signal, reporting improved self-assessment quality (via LCAE) without change to model ability. No equation or step reduces the claimed result to a tautological restatement of fitted parameters, a self-citation chain, or a renaming of inputs; the Rasch choice is an independent modeling assumption whose validity is a separate empirical question, not a definitional loop. The derivation chain remains self-contained against the stated experimental benchmarks.
Axiom & Free-Parameter Ledger
free parameters (2)
- Rasch item difficulty parameters
- Rasch model ability parameters
axioms (1)
- domain assumption Rasch model provides a valid latent-variable representation of LLM ability and item difficulty
invented entities (1)
-
Latent Confidence Alignment Error (LCAE)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
A Survey on Large Language Models for Critical Societal Domains: Finance, Healthcare, and Law,
Z. Z. Chenet al., “A Survey on Large Language Models for Critical Societal Domains: Finance, Healthcare, and Law,” arXiv:2405.01769, 2024
arXiv 2024
-
[2]
Can LLMs Express Their Uncertainty? An Empirical Evaluation of Confidence Elicitation in LLMs,
M. Xionget al., “Can LLMs Express Their Uncertainty? An Empirical Evaluation of Confidence Elicitation in LLMs,” arXiv:2306.13063, 2024
Pith/arXiv arXiv 2024
-
[3]
A Survey of Confidence Estimation and Calibration in Large Language Models,
J. Geng, F. Cai, Y . Wang, H. Koeppl, P. Nakov, and I. Gurevych, “A Survey of Confidence Estimation and Calibration in Large Language Models,” arXiv:2311.08298, 2024
arXiv 2024
-
[4]
Large Language Models Have Intrinsic Meta-Cognition, but Need a Good Lens,
Z. Ma, Q. Yuan, Z. Wang, and D. Zhou, “Large Language Models Have Intrinsic Meta-Cognition, but Need a Good Lens,” arXiv:2506.08410, 2025
arXiv 2025
-
[5]
On Calibration of Modern Neural Networks,
C. Guo, G. Pleiss, Y . Sun, and K. Q. Weinberger, “On Calibration of Modern Neural Networks,” arXiv:1706.04599, 2017
Pith/arXiv arXiv 2017
-
[6]
Verification of forecasts expressed in terms of probability,
G. W. Brier, “Verification of forecasts expressed in terms of probability,” Mon. Weather Rev., vol. 78, no. 1, pp. 1–3, 1950
1950
-
[7]
Lost in Benchmarks? Rethinking Large Language Model Benchmarking with Item Response Theory,
H. Zhouet al., “Lost in Benchmarks? Rethinking Large Language Model Benchmarking with Item Response Theory,” arXiv:2505.15055, 2026
arXiv 2026
-
[8]
Item Response Theory: A Statistical Framework for Educational and Psychological Measurement,
Y . Chen, X. Li, J. Liu, and Z. Ying, “Item Response Theory: A Statistical Framework for Educational and Psychological Measurement,” arXiv:2108.08604, 2021
arXiv 2021
-
[9]
Metacognition and cognitive monitoring: A new area of cognitive-developmental inquiry,
J. H. Flavell, “Metacognition and cognitive monitoring: A new area of cognitive-developmental inquiry,”Am. Psychol., vol. 34, no. 10, pp. 906–911, 1979
1979
-
[10]
Cost- of-Pass: An Economic Framework for Evaluating Language Models,
M. H. Erol, B. El, M. Suzgun, M. Yuksekgonul, and J. Zou, “Cost- of-Pass: An Economic Framework for Evaluating Language Models,” arXiv:2504.13359, 2026
arXiv 2026
-
[11]
Holistic Evaluation of Language Models,
P. Lianget al., “Holistic Evaluation of Language Models,” arXiv:2211.09110, 2023
Pith/arXiv arXiv 2023
-
[12]
Easy2Hard-Bench: Standardized Difficulty Labels for Profiling LLM Performance and Generalization,
M. Dinget al., “Easy2Hard-Bench: Standardized Difficulty Labels for Profiling LLM Performance and Generalization,” arXiv:2409.18433, 2025
arXiv 2025
-
[13]
LLMs Encode How Difficult Problems Are,
W. Lugoloobi and C. Russell, “LLMs Encode How Difficult Problems Are,” arXiv:2510.18147, 2025
arXiv 2025
-
[14]
Do Language Models Mirror Human Confidence? Exploring Psychological Insights to Address Overconfidence in LLMs
C. Xu, B. Wen, B. Han, R. Wolfe, L. L. Wang, and B. Howe, “Do Language Models Mirror Human Confidence? Exploring Psychological Insights to Address Overconfidence in LLMs.”
-
[15]
Bond,Applying the Rasch Model
T. Bond,Applying the Rasch Model. Routledge, 2015
2015
-
[16]
Rasch Measurement v. Item Response Theory: Knowing When to Cross the Line,
S. E. Stemler and A. Naples, “Rasch Measurement v. Item Response Theory: Knowing When to Cross the Line,” 2021
2021
-
[17]
On Specific Objectivity: An Attempt at Formalizing the Request for Generality and Validity of Scientific Statements,
G. Rasch, “On Specific Objectivity: An Attempt at Formalizing the Request for Generality and Validity of Scientific Statements,”Dan. Yearb. Philos., vol. 14, no. 1, pp. 58–94, 1977
1977
-
[18]
Reliable and Efficient Amortized Model-based Evaluation,
S. Truong, Y . Tu, P. Liang, B. Li, and S. Koyejo, “Reliable and Efficient Amortized Model-based Evaluation,” arXiv:2503.13335, 2025
arXiv 2025
-
[19]
Metacognitive Prompting Improves Understand- ing in Large Language Models,
Y . Wang and Y . Zhao, “Metacognitive Prompting Improves Understand- ing in Large Language Models,” arXiv:2308.05342, 2024
arXiv 2024
-
[20]
How to measure metacognition,
S. M. Fleming and H. C. Lau, “How to measure metacognition,”Front. Hum. Neurosci., vol. 8, 2014
2014
-
[21]
Dual-Process Theories of Higher Cognition: Advancing the Debate,
J. St. B. T. Evans and K. E. Stanovich, “Dual-Process Theories of Higher Cognition: Advancing the Debate,”Perspect. Psychol. Sci., vol. 8, no. 3, pp. 223–241, 2013
2013
-
[22]
Kahneman,Thinking, Fast and Slow
D. Kahneman,Thinking, Fast and Slow. New York: Farrar, Straus and Giroux, 2011
2011
-
[23]
Dual- process theory and decision-making in large language models,
O. Brady, P. Nulty, L. Zhang, T. E. Ward, and D. P. McGovern, “Dual- process theory and decision-making in large language models,”Nat. Rev. Psychol., vol. 4, no. 12, pp. 777–792, 2025
2025
-
[24]
Reliable Decision Making via Calibration Oriented Retrieval Augmented Generation,
C. Jang, D. Cho, S. Lee, H. Lee, and J. Lee, “Reliable Decision Making via Calibration Oriented Retrieval Augmented Generation,” arXiv:2411.08891, 2025
arXiv 2025
-
[25]
Loss Functions and Metrics in Deep Learning,
J. Terven, D. M. Cordova-Esparza, A. Ramirez-Pedraza, E. A. Chavez- Urbiola, and J. A. Romero-Gonzalez, “Loss Functions and Metrics in Deep Learning,”Artif. Intell. Rev., vol. 58, no. 7, p. 195, 2025
2025
-
[26]
Menu Pricing of Large Language Models,
D. Bergemann, A. Bonatti, and A. Smolin, “Menu Pricing of Large Language Models,” arXiv:2502.07736, 2026
arXiv 2026
-
[27]
MedXpertQA: Benchmarking Expert-Level Medical Reasoning and Understanding,
Y . Zuoet al., “MedXpertQA: Benchmarking Expert-Level Medical Reasoning and Understanding,” arXiv:2501.18362, 2025
Pith/arXiv arXiv 2025
-
[28]
Benchmarking proprietary and open-source language and vision-language models for gastroenterology clinical rea- soning,
S. A. A. Safavi-Nainiet al., “Benchmarking proprietary and open-source language and vision-language models for gastroenterology clinical rea- soning,”npj Digit. Med., vol. 8, no. 1, p. 797, 2025
2025
-
[29]
A novel evaluation benchmark for medical LLMs illuminating safety and effectiveness in clinical domains,
S. Wanget al., “A novel evaluation benchmark for medical LLMs illuminating safety and effectiveness in clinical domains,”npj Digit. Med., vol. 9, no. 1, p. 91, 2025
2025
-
[30]
Benchmark evaluation of DeepSeek large language models in clinical decision-making,
S. Sandmannet al., “Benchmark evaluation of DeepSeek large language models in clinical decision-making,”Nat. Med., vol. 31, no. 8, pp. 2546–2549, 2025
2025
-
[31]
State of What Art? A Call for Multi-Prompt LLM Eval- uation,
M. Mizrahi, G. Kaplan, D. Malkin, R. Dror, D. Shahaf, and G. Stanovsky, “State of What Art? A Call for Multi-Prompt LLM Eval- uation,” arXiv:2401.00595, 2024
arXiv 2024
-
[32]
Fact-and-Reflection Improves Confidence Calibration of Large Language Models,
X. Zhaoet al., “Fact-and-Reflection Improves Confidence Calibration of Large Language Models,” arXiv:2402.17124, 2024
arXiv 2024
-
[33]
The Effect of Sampling Temperature on Problem Solving in Large Language Models,
M. Renze and E. Guven, “The Effect of Sampling Temperature on Problem Solving in Large Language Models,” inFindings of EMNLP 2024, pp. 7346–7356, 2024
2024
-
[34]
SNAPPS: A Learner- centered Model for Outpatient Education,
T. M. Wolpaw, D. R. Wolpaw, and K. K. Papp, “SNAPPS: A Learner- centered Model for Outpatient Education,”Acad. Med., vol. 78, no. 9, pp. 893–898, 2003
2003
-
[35]
The Use of Ranks to Avoid the Assumption of Normality Implicit in the Analysis of Variance,
M. Friedman, “The Use of Ranks to Avoid the Assumption of Normality Implicit in the Analysis of Variance,”J. Am. Stat. Assoc., vol. 32, no. 200, pp. 675–701, 1937
1937
-
[36]
Individual Comparisons by Ranking Methods,
F. Wilcoxon, “Individual Comparisons by Ranking Methods,”Biom. Bull., vol. 1, no. 6, pp. 80–83, 1945
1945
-
[37]
A Simple Sequentially Rejective Multiple Test Procedure,
S. Holm, “A Simple Sequentially Rejective Multiple Test Procedure,” Scand. J. Stat., vol. 6, no. 2, pp. 65–70, 1979
1979
-
[38]
G. Comaniciet al., “Gemini 2.5: Pushing the Frontier with Advanced Reasoning, Multimodality, Long Context, and Next Generation Agentic Capabilities,” arXiv:2507.06261, 2025
Pith/arXiv arXiv 2025
-
[39]
A. Singhet al., “OpenAI GPT-5 System Card,” arXiv:2601.03267, 2025
Pith/arXiv arXiv 2025
-
[40]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning,
DeepSeek-AIet al., “DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning,” arXiv:2501.12948, 2025
Pith/arXiv arXiv 2025
-
[41]
DeepSeek-V3.2: Pushing the Frontier of Open Large Language Models,
DeepSeek-AIet al., “DeepSeek-V3.2: Pushing the Frontier of Open Large Language Models,” arXiv:2512.02556, 2025
Pith/arXiv arXiv 2025
-
[42]
gpt-oss-120b & gpt-oss-20b Model Card,
OpenAIet al., “gpt-oss-120b & gpt-oss-20b Model Card,” arXiv:2508.10925, 2025
Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.