TraceView: Interactive Visualization of Agentic Program Repair Trajectories
Pith reviewed 2026-06-26 11:33 UTC · model grok-4.3
The pith
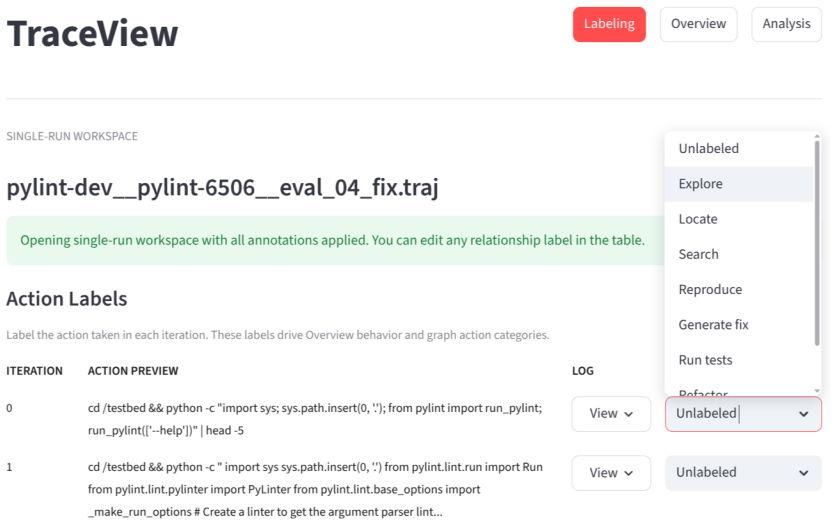
TraceView structures agent repair trajectories into labeled Thought-Action-Result graphs to diagnose how LLM patches are generated.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
TraceView organizes raw and pre-labeled agentic runs with Thought, Action, and Result components to support semantic relation labeling and diagnosis, and renders the resulting trajectory as graph views with relation filters, patch outcome summaries, metrics, and node-level evidence panels.
What carries the argument
The graph view of Thought-Action-Result components that enables labeling, filtering by relations, and inspection of connections across repair steps.
If this is right
- Users can identify repetitive or misaligned steps that cause repair failures.
- Relation labeling makes it possible to compare behavior across multiple repair attempts.
- Overview-to-detail navigation supports quicker diagnosis than raw logs.
- Metrics and outcome summaries highlight patterns in successful versus failed runs.
Where Pith is reading between the lines
- The same component labeling and graph rendering could apply to agent trajectories in other domains such as web navigation or code generation.
- Collected labels might serve as training signals to reduce misalignment in future agent designs.
- Integration into APR pipelines could shift evaluation from patch success alone to process-level analysis.
Load-bearing premise
Raw agent trajectories contain semantically meaningful Thought-Action-Result components that users can reliably label to support diagnosis.
What would settle it
A study in which participants using TraceView show no measurable improvement in identifying failure points or understanding repair steps compared to viewing unprocessed trajectory logs.
Figures

read the original abstract
LLM-based automated program repair (APR) agents generate patches to fix software bugs with minimal human intervention. These agents often produce long trajectories of reasoning, tool use, and feedback to produce candidate patches. Final patch outcomes show whether a repair attempt succeeded or failed, but they do not show how the agent reached that outcome, or where the process became repetitive or misaligned with the task. This makes agentic repair failures difficult to diagnose, reproduce, and prevent. To help developers address these challenges, we present TraceView, an interactive tool for labeling and visualizing repair trajectories from APR systems. TraceView organizes raw and pre-labeled agentic runs with Thought, Action, and Result components to support semantic relation labeling and diagnosis, and renders the resulting trajectory as graph views. Furthermore, TraceView provides relation filters, patch outcome summaries, metrics, and node-level evidence panels to help users inspect how reasoning, actions, and feedback connect across the various steps of an agentic repair attempt. We evaluate TraceView with five researchers through a survey-based user study. Participants reported that TraceView made trajectories easier to scan and that its overview-to-detail workflow helped them better understand repair behavior. The TraceView source code is available at https://github.com/SOAR-Lab/agent-traj-visualization. A screencast of TraceView is available at https://youtu.be/9ZCh7Ifj2AQ.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents TraceView, an interactive tool for labeling and visualizing trajectories from LLM-based automated program repair (APR) agents. It organizes raw and pre-labeled runs into Thought-Action-Result components, renders them as graph views with relation filters, patch outcome summaries, metrics, and node-level evidence panels, and evaluates the tool via a survey-based user study with five researchers. Participants reported that TraceView made trajectories easier to scan and that its overview-to-detail workflow helped them better understand repair behavior. Source code and a screencast are provided.
Significance. If the reported benefits hold, TraceView addresses a practical gap in diagnosing failures in agentic APR by making long reasoning trajectories more interpretable beyond final patch outcomes. The open-source release supports reproducibility and extension within the software engineering community.
major comments (1)
- [Evaluation] Evaluation section: the usability claims rest on qualitative self-reports from only five participants with no quantitative metrics (e.g., task completion time, error rates), no baseline comparison to existing visualization tools, and no details on survey questions or participant demographics; while the central claim is scoped to what participants reported, this design limits the strength of evidence for the overview-to-detail workflow benefit.
minor comments (2)
- [Abstract / Introduction] Abstract and §1: the description of how Thought-Action-Result components are obtained (manual labeling, automated extraction, or both) is not fully specified, which affects readers' understanding of the tool's input requirements.
- [Figures / Implementation] Figure captions and §3: ensure all graph view screenshots include explicit legends for node/edge types and filter controls to improve standalone readability.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and the recommendation for minor revision. We address the evaluation comment below by clarifying the study scope and offering to enhance transparency.
read point-by-point responses
-
Referee: [Evaluation] Evaluation section: the usability claims rest on qualitative self-reports from only five participants with no quantitative metrics (e.g., task completion time, error rates), no baseline comparison to existing visualization tools, and no details on survey questions or participant demographics; while the central claim is scoped to what participants reported, this design limits the strength of evidence for the overview-to-detail workflow benefit.
Authors: We acknowledge the limitations of the evaluation design. The user study was intentionally scoped as an initial, exploratory assessment with five researchers to gather qualitative feedback on whether TraceView improves scanability and understanding of trajectories, as explicitly stated in the abstract and evaluation section. Quantitative metrics, task timings, error rates, and comparisons to baseline tools were not collected because the primary aim was to validate the core visualization concepts (Thought-Action-Result organization and overview-to-detail workflow) rather than to perform a controlled comparative usability experiment. We agree that this limits the strength of evidence for broader claims. To improve transparency, we will add the survey questions, participant demographics, and background details in a revision. A larger quantitative study with baselines would require substantial new work outside the current scope. revision: partial
Circularity Check
No significant circularity
full rationale
The paper presents a visualization tool and reports direct results from a five-participant survey on usability. No mathematical derivations, predictions, fitted parameters, or uniqueness theorems appear anywhere in the text. The central claim is a factual summary of self-reported participant feedback on scanning ease and workflow helpfulness; it does not reduce to any input by construction, self-citation chain, or ansatz. The description of Thought-Action-Result organization is presented as a design choice of the tool rather than a derived result. This is a standard non-circular tool-description paper whose claims are scoped exactly to the reported user responses.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
What characteristics make chatgpt effective for software issue resolution? an empirical study of task, project, and conversational signals in github issues,
R. Ehsani, S. Pathak, E. Parra, S. Haiduc, and P. Chatterjee, “What characteristics make chatgpt effective for software issue resolution? an empirical study of task, project, and conversational signals in github issues,”Empirical software engineering, 2026
2026
-
[2]
Hierarchical knowl- edge injection for improving llm-based program repair,
R. Ehsani, E. Parra, S. Haiduc, and P. Chatterjee, “Hierarchical knowl- edge injection for improving llm-based program repair,” inProceedings of the 40th IEEE/ACM International Conference on Automated Software Engineering (ASE’25), 2025
2025
-
[3]
Automated program repair via conversation: Fixing 162 out of 337 bugs for $0.42 each using chatgpt,
C. S. Xia and L. Zhang, “Automated program repair via conversation: Fixing 162 out of 337 bugs for $0.42 each using chatgpt,” in Proceedings of the 33rd ACM SIGSOFT International Symposium on Software Testing and Analysis, ser. ISSTA 2024. New York, NY , USA: Association for Computing Machinery, 2024, p. 819–831. [Online]. Available: https://doi.org/10.11...
-
[4]
Z. Fan, X. Gao, M. Mirchev, A. Roychoudhury, and S. H. Tan, “Automated repair of programs from large language models,” inProceedings of the 45th International Conference on Software Engineering, ser. ICSE ’23. IEEE Press, 2023, p. 1469–1481. [Online]. Available: https://doi.org/10.1109/ICSE48619.2023.00128
-
[5]
Autocoderover: Autonomous program improvement,
Y . Zhang, H. Ruan, Z. Fan, and A. Roychoudhury, “Autocoderover: Autonomous program improvement,” inProceedings of the 33rd ACM SIGSOFT International Symposium on Software Testing and Analysis, 2024, pp. 1592–1604
2024
-
[6]
Swe-agent: Agent-computer interfaces enable automated soft- ware engineering,
J. Yang, C. E. Jimenez, A. Wettig, K. Lieret, S. Yao, K. Narasimhan, and O. Press, “Swe-agent: Agent-computer interfaces enable automated soft- ware engineering,”Advances in Neural Information Processing Systems, vol. 37, pp. 50 528–50 652, 2024
2024
-
[7]
Understanding software engineering agents: A study of thought-action-result trajectories,
I. Bouzenia and M. Pradel, “Understanding software engineering agents: A study of thought-action-result trajectories,” 2025. [Online]. Available: https://arxiv.org/abs/2506.18824
arXiv 2025
-
[8]
Process-centric analysis of agentic software systems,
S. Liu, Y . Chen, R. Krishna, S. Sinha, J. Ganhotra, and R. Jabbarvand, “Process-centric analysis of agentic software systems,”Proceedings of the ACM on Programming Languages, vol. 10, no. OOPSLA1, p. 1961–1988, Apr. 2026. [Online]. Available: http://dx.doi.org/10.1145/ 3798271
1961
-
[9]
Demystifying errors in llm reasoning traces: An empirical study of code execution simulation,
M. Abdollahi, K. R. Tasnia, S. K. Saha, J. Yang, S. Wang, and H. Hemmati, “Demystifying errors in llm reasoning traces: An empirical study of code execution simulation,” 2025. [Online]. Available: https://arxiv.org/abs/2512.00215
arXiv 2025
-
[10]
Repairagent: An autonomous, llm-based agent for program repair,
I. Bouzenia, P. Devanbu, and M. Pradel, “Repairagent: An autonomous, llm-based agent for program repair,” in2025 IEEE/ACM 47th Interna- tional Conference on Software Engineering (ICSE). IEEE, 2025, pp. 2188–2200
2025
-
[11]
Wink: Recovering from misbehaviors in coding agents,
R. Nanda, C. Maddila, S. Jha, E. M. Khan, M. Paltenghi, and S. Chandra, “Wink: Recovering from misbehaviors in coding agents,”
-
[12]
Available: https://arxiv.org/abs/2602.17037
[Online]. Available: https://arxiv.org/abs/2602.17037
-
[13]
A nested model for visualization design and validation,
T. Munzner, “A nested model for visualization design and validation,” IEEE Transactions on Visualization and Computer Graphics, vol. 15, no. 6, pp. 921–928, 2009
2009
-
[14]
The eyes have it: a task by data type taxonomy for information visualizations,
B. Shneiderman, “The eyes have it: a task by data type taxonomy for information visualizations,” inProceedings 1996 IEEE Symposium on Visual Languages, 1996, pp. 336–343
1996
-
[15]
Anteater: Interactive visualization of program execution values in context,
R. Faust, K. Isaacs, W. Z. Bernstein, M. Sharp, and C. Scheidegger, “Anteater: Interactive visualization of program execution values in context,” 2024. [Online]. Available: https://arxiv.org/abs/1907.02872
arXiv 2024
-
[16]
Agentlens: Visual analysis for agent behaviors in llm-based autonomous systems,
J. Lu, B. Pan, J. Chen, Y . Feng, J. Hu, Y . Peng, and W. Chen, “Agentlens: Visual analysis for agent behaviors in llm-based autonomous systems,”
-
[17]
Available: https://arxiv.org/abs/2402.08995
[Online]. Available: https://arxiv.org/abs/2402.08995
-
[18]
Proceedings of the AAAI Conference on Artificial Intelligence39(28), 29634–29636 (2025)
M. Desmond, J. Y . Lee, I. Ibrahim, J. M. Johnson, A. Sil, J. MacNair, and R. Puri, “Agent trajectory explorer: visualizing and providing feedback on agent trajectories,” inProceedings of the Thirty-Ninth AAAI Conference on Artificial Intelligence and Thirty-Seventh Conference on Innovative Applications of Artificial Intelligence and Fifteenth Symposium o...
-
[19]
Retrace: Interactive visualizations for reasoning traces of large reasoning models,
L. Felder, J. Miller, M. Wallinger, S. Kobourov, and C. Chen, “Retrace: Interactive visualizations for reasoning traces of large reasoning models,” 2025. [Online]. Available: https://arxiv.org/abs/2511.11187
arXiv 2025
-
[20]
Inconlens: Interactive visual diagnosis of behavioral inconsistencies in llm-based agentic systems,
S. Yan, X. Wen, S. Ruan, Y . Zhang, J. Mi, Y . Sun, H. Qu, and R. Sheng, “Inconlens: Interactive visual diagnosis of behavioral inconsistencies in llm-based agentic systems,” 2026. [Online]. Available: https://arxiv.org/abs/2603.28106
arXiv 2026
-
[21]
Seaview: Software engineering agent visual interface for enhanced workflow,
T. Bula, S. Pujar, L. Buratti, M. Bornea, and A. Sil, “Seaview: Software engineering agent visual interface for enhanced workflow,”
-
[22]
Available: https://arxiv.org/abs/2504.08696
[Online]. Available: https://arxiv.org/abs/2504.08696
-
[23]
Illuminating llm coding agents: Visual analytics for deeper understanding and enhancement,
J. Wang, Y . Chen, M. Pan, C.-C. M. Yeh, and M. Das, “Illuminating llm coding agents: Visual analytics for deeper understanding and enhancement,” 2025. [Online]. Available: https://arxiv.org/abs/2508. 12555
2025
-
[24]
Zeno: An interactive framework for behavioral evaluation of machine learning,
A. A. Cabrera, E. Fu, D. Bertucci, K. Holstein, A. Talwalkar, J. I. Hong, and A. Perer, “Zeno: An interactive framework for behavioral evaluation of machine learning,” inProceedings of the 2023 CHI Conference on Human Factors in Computing Systems, ser. CHI ’23. ACM, 2023, pp. 1–14. [Online]. Available: https://doi.org/10.1145/3544548.3581268
-
[25]
Principles of explanatory debugging to personalize interactive machine learning,
T. Kulesza, M. Burnett, W.-K. Wong, and S. Stumpf, “Principles of explanatory debugging to personalize interactive machine learning,” inProceedings of the 20th International Conference on Intelligent User Interfaces, ser. IUI ’15. New York, NY , USA: Association for Computing Machinery, 2015, p. 126–137. [Online]. Available: https://doi.org/10.1145/267802...
-
[26]
Interactive debugging and steering of multi-agent ai systems,
W. Epperson, G. Bansal, V . C. Dibia, A. Fourney, J. Gerrits, E. E. Zhu, and S. Amershi, “Interactive debugging and steering of multi-agent ai systems,” inProceedings of the 2025 CHI Conference on Human Factors in Computing Systems, ser. CHI ’25. ACM, Apr. 2025, p. 1–15. [Online]. Available: http://dx.doi.org/10.1145/3706598.3713581
-
[27]
Agentstepper: Interactive debugging of software development agents,
R. Hutter and M. Pradel, “Agentstepper: Interactive debugging of software development agents,” 2026. [Online]. Available: https: //arxiv.org/abs/2602.06593
arXiv 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.