BioMatrix: Towards a Comprehensive Biological Foundation Model Spanning the Modality Matrix of Sequences, Structures, and Language
Pith reviewed 2026-06-26 11:44 UTC · model grok-4.3
The pith
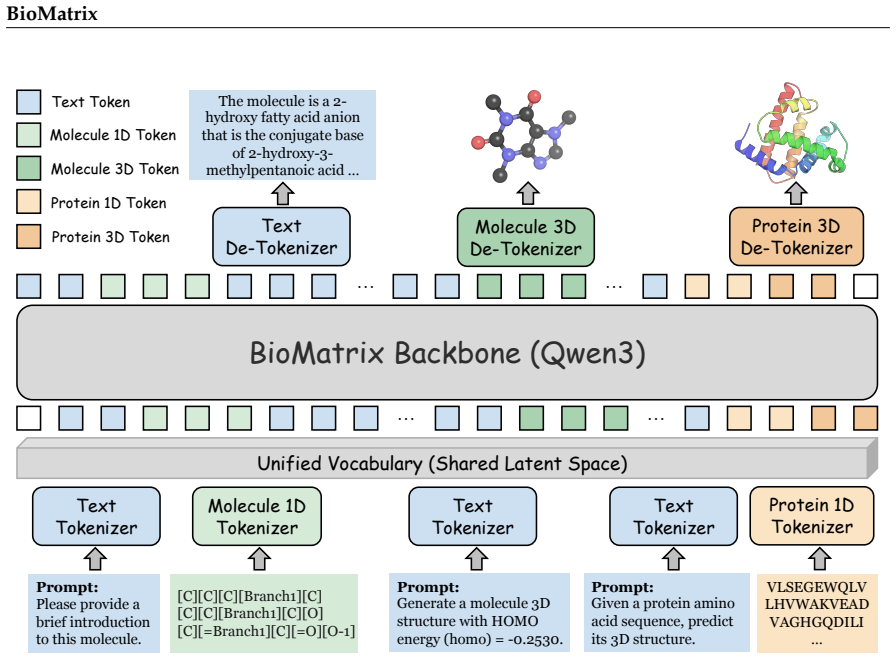
A unified tokenization scheme maps molecular sequences, structures, protein sequences, structures and natural language into one shared space so a single decoder-only model can consume and generate all of them under next-token prediction.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
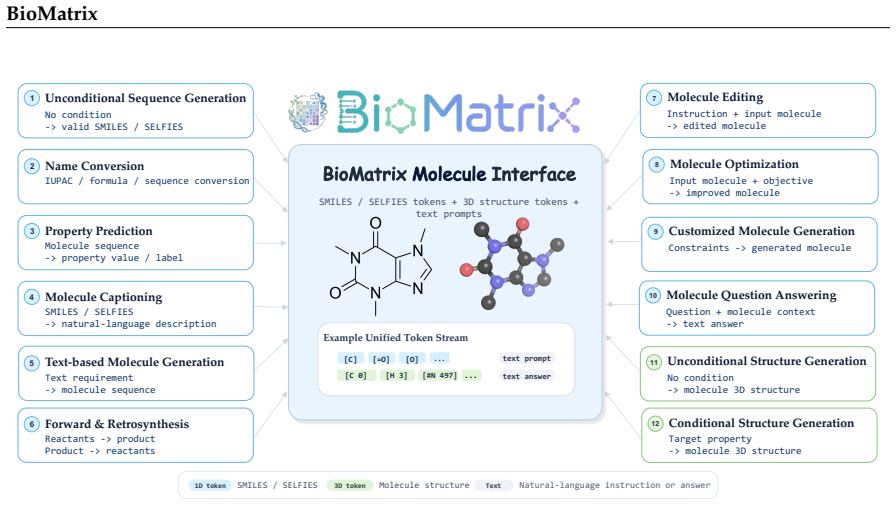
BioMatrix is the first multimodal foundation model that natively integrates sequences, structures, and natural language for both molecules and proteins within a single decoder-only architecture. It achieves this by mapping molecular sequences (SMILES and SELFIES), molecular structures, protein sequences, protein structures, and natural language into a shared discrete token space through a unified tokenization scheme, so that all modalities are consumed and produced uniformly under a single next-token prediction objective without external encoders, projection adapters, or modality-specific output heads.
What carries the argument
The unified tokenization scheme that converts every modality into tokens from a single vocabulary, enabling uniform next-token prediction across sequences, structures and language.
If this is right
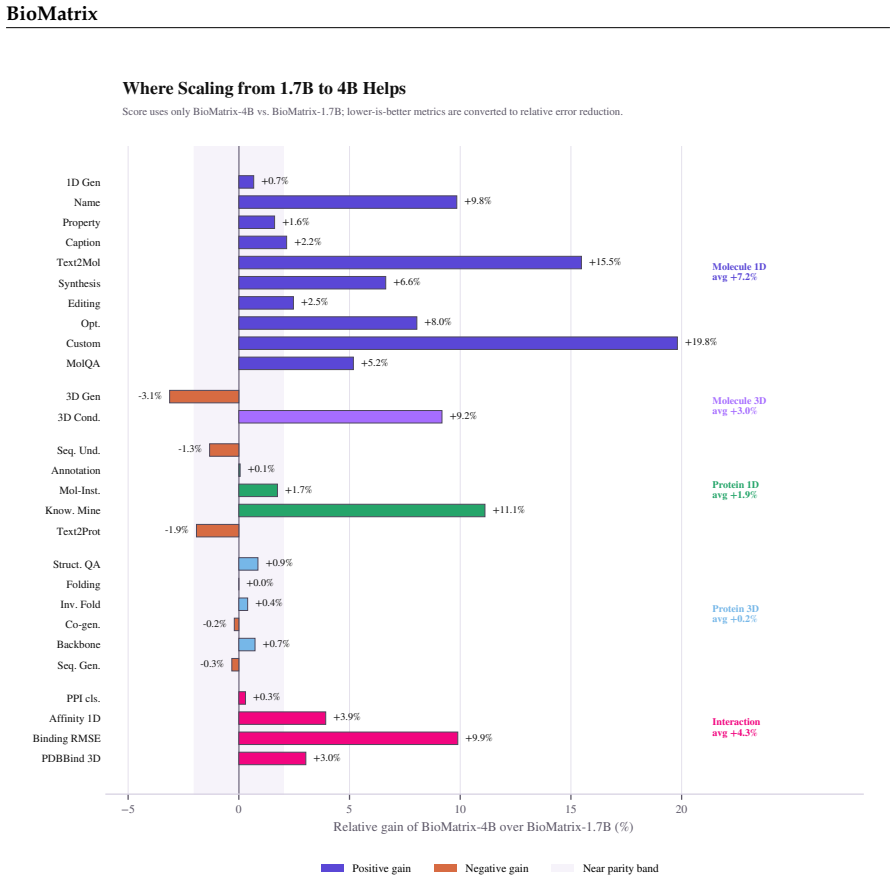
- The model reaches state-of-the-art or competitive results on 77 of 80 tasks spanning understanding and generation within and across modalities.
- Both single-entity and multi-entity tasks, including molecule-protein and protein-protein interactions, become addressable inside one model.
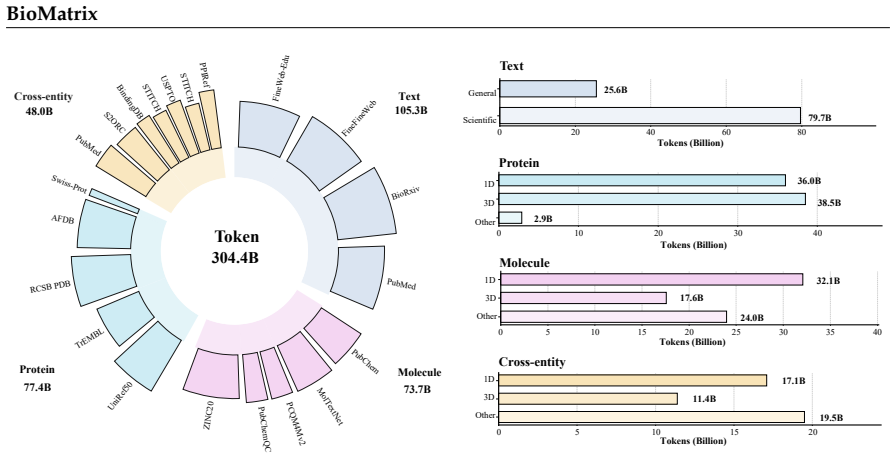
- Continual pretraining on hundreds of billions of tokens that mix text, sequences, structures and cross-modal pairs produces the observed breadth of capability.
- Specialized models are no longer required for most of the covered biological tasks once the unified token space is in place.
Where Pith is reading between the lines
- The same tokenization logic could be tested on additional entity types such as metabolites or genes to check whether the generalist pattern extends further.
- Deployment cost may drop because one set of weights replaces multiple modality-specific models and their associated adapters.
- Zero-shot transfer between previously separate tasks, such as generating a protein structure directly from a textual description of its function, becomes a natural next measurement.
- If the token space preserves enough geometric detail, downstream simulation or docking tools could operate directly on the model's generated tokens.
Load-bearing premise
A single discrete tokenization scheme can represent both sequence and three-dimensional structural information for molecules and proteins without meaningful loss or the need for modality-specific components.
What would settle it
Demonstration that the model cannot produce chemically valid molecular structures or biologically plausible protein folds when asked to generate from sequence tokens alone, or that removing the structure tokens from training collapses performance on structure-related tasks.
Figures

read the original abstract
We present BioMatrix, the first multimodal foundation model that natively integrates sequences, structures, and natural language for both molecules and proteins within a single decoder-only architecture. Existing biological foundation models pursue native multimodality and broad entity coverage separately: those that fuse multiple modalities under a shared objective remain confined to a single entity type, while those spanning multiple entity types either omit explicit structural modeling or rely on adapter-based designs in which the model cannot natively generate the very modalities it can read. BioMatrix closes this gap by mapping molecular sequences (supporting both SMILES and SELFIES notations), molecular structures, protein sequences, protein structures, and natural language into a shared discrete token space through a unified tokenization scheme, so that all modalities are consumed and produced uniformly under a single next-token prediction objective -- without external encoders, projection adapters, or modality-specific output heads. Built upon the Qwen3 language model (1.7B and 4B), BioMatrix is continually pretrained on 304.4 billion tokens spanning general and domain-specific text, sequence and structure views of molecules and proteins, and cross-modal corpora that interleave biomolecular entities with scientific text and link distinct entities through molecule-protein and protein-protein interaction data. After tuning on a comprehensive suite of downstream applications covering 80 tasks across 6 categories -- encompassing single-entity and multi-entity understanding and generation tasks across and within modalities -- BioMatrix achieves state-of-the-art or competitive performance on 77 out of 80 tasks, demonstrating that a single, natively multimodal generalist model can effectively match or surpass specialized approaches across a wide range of biological tasks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces BioMatrix, a decoder-only foundation model built on Qwen3 (1.7B/4B) that maps molecular sequences (SMILES/SELFIES), molecular structures, protein sequences, protein structures, and natural language into a shared discrete token space via a unified tokenization scheme. All modalities are handled uniformly under next-token prediction pretraining on 304.4B tokens (including cross-modal interaction data), followed by tuning on 80 tasks across 6 categories of single- and multi-entity understanding/generation; it reports SOTA or competitive results on 77/80 tasks.
Significance. If the unified tokenization supports lossless native generation of 3D structures under pure next-token prediction and the performance results are shown to be robust, this would be a notable contribution by demonstrating that a single generalist decoder-only model can span multiple biological entity types and modalities without adapters or modality-specific heads, potentially simplifying the landscape of biological foundation models.
major comments (2)
- [Abstract] Abstract: the central claim that BioMatrix 'achieves state-of-the-art or competitive performance on 77 out of 80 tasks' supplies no information on task definitions, baselines, data splits, statistical significance testing, or how structures are tokenized and generated; without these, the performance claim cannot be evaluated and is load-bearing for the paper's main result.
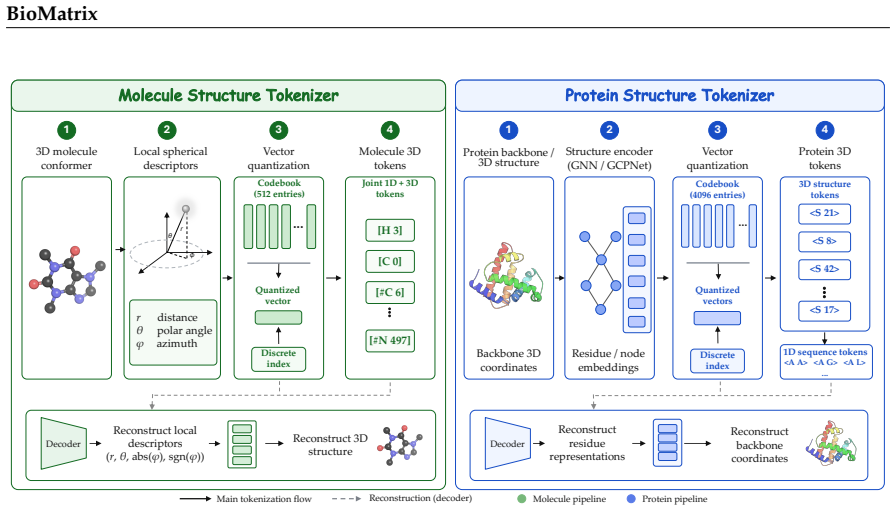
- [Abstract] Abstract (and the section describing the unified tokenization scheme): no equations, pseudocode, or algorithmic detail is given for discretizing 3D molecular/protein structures (coordinates or graphs) into the shared vocabulary alongside SMILES/SELFIES and text; this leaves open whether generation remains purely next-token prediction without information loss or implicit modality-specific logic, which directly underpins the 'natively integrates ... without external encoders, projection adapters, or modality-specific output heads' claim.
Simulated Author's Rebuttal
We thank the referee for the detailed feedback. We address each major comment below, indicating where revisions will be made to improve clarity and evaluability while preserving the manuscript's core contributions.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that BioMatrix 'achieves state-of-the-art or competitive performance on 77 out of 80 tasks' supplies no information on task definitions, baselines, data splits, statistical significance testing, or how structures are tokenized and generated; without these, the performance claim cannot be evaluated and is load-bearing for the paper's main result.
Authors: We agree the abstract is high-level by design. Full details on the 80 tasks (definitions, baselines, splits, and significance testing) appear in Section 4 and the supplementary material; structure tokenization/generation is covered in Section 3. To address evaluability concerns, we will revise the abstract to briefly reference the evaluation protocol and direct readers to the relevant sections for complete information. revision: partial
-
Referee: [Abstract] Abstract (and the section describing the unified tokenization scheme): no equations, pseudocode, or algorithmic detail is given for discretizing 3D molecular/protein structures (coordinates or graphs) into the shared vocabulary alongside SMILES/SELFIES and text; this leaves open whether generation remains purely next-token prediction without information loss or implicit modality-specific logic, which directly underpins the 'natively integrates ... without external encoders, projection adapters, or modality-specific output heads' claim.
Authors: We acknowledge the need for greater explicitness. While Section 3 describes the unified tokenization scheme that places all modalities (including 3D structures) into a shared discrete vocabulary for uniform next-token prediction, we will add equations and pseudocode for the 3D discretization process to the main text. This will explicitly confirm the absence of information loss or modality-specific logic. revision: yes
Circularity Check
No circularity; empirical claims rest on downstream evaluation
full rationale
The paper describes an empirical multimodal foundation model built on Qwen3 with a unified tokenization scheme for sequences, structures, and language. No equations, derivations, or parameter-fitting steps are presented that would reduce any claimed prediction or result to inputs by construction. Performance on 80 tasks is reported as external validation rather than a quantity defined by the pretraining objective. No self-citations, uniqueness theorems, or ansatzes are invoked in a load-bearing way within the provided text. The architecture claim is an engineering choice evaluated empirically, not a self-referential derivation.
Axiom & Free-Parameter Ledger
free parameters (1)
- base model sizes
axioms (1)
- domain assumption Next-token prediction on a shared discrete token space is sufficient to learn and generate across sequences, structures, and language without modality-specific components.
Reference graph
Works this paper leans on
-
[1]
Uniprot: the universal protein knowledgebase in 2023.Nucleic acids research, 51(D1):D523–D531, 2023
2023
-
[2]
Open-AlphaSeq: Open protein–protein interaction affinity datasets, 2025
A-Alpha Bio. Open-AlphaSeq: Open protein–protein interaction affinity datasets, 2025. URL https: //huggingface.co/datasets/aalphabio/open-alphaseq
2025
-
[3]
Prot2text: Multi- modal protein’s function generation with gnns and transformers
Hadi Abdine, Michail Chatzianastasis, Costas Bouyioukos, and Michalis Vazirgiannis. Prot2text: Multi- modal protein’s function generation with gnns and transformers. InProceedings of the AAAI conference on artificial intelligence, volume 38, pages 10757–10765, 2024
2024
-
[4]
Accurate structure prediction of biomolecular interactions with alphafold 3.Nature, 630(8016):493–500, 2024
Josh Abramson, Jonas Adler, Jack Dunger, Richard Evans, Tim Green, Alexander Pritzel, Olaf Ronneberger, Lindsay Willmore, Andrew J Ballard, Joshua Bambrick, et al. Accurate structure prediction of biomolecular interactions with alphafold 3.Nature, 630(8016):493–500, 2024
2024
-
[5]
Gpt-4 technical report.arXiv preprint arXiv:2303.08774, 2023
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report.arXiv preprint arXiv:2303.08774, 2023
Pith/arXiv arXiv 2023
-
[6]
gpt-oss-120b & gpt-oss-20b model card.arXiv preprint arXiv:2508.10925, 2025
Sandhini Agarwal, Lama Ahmad, Jason Ai, Sam Altman, Andy Applebaum, Edwin Arbus, Rahul K Arora, Yu Bai, Bowen Baker, Haiming Bao, et al. gpt-oss-120b & gpt-oss-20b model card.arXiv preprint arXiv:2508.10925, 2025
Pith/arXiv arXiv 2025
-
[7]
Protein generation with evolutionary diffusion: sequence is all you need
Sarah Alamdari, Nitya Thakkar, Rianne van den Berg, Alex Lu, Nicolo Fusi, Ava Amini, and Kevin Yang. Protein generation with evolutionary diffusion: sequence is all you need. InNeurIPS 2023 Generative AI and Biology (GenBio) Workshop
2023
-
[8]
Claude 3.5 Sonnet model card addendum, 2024
Anthropic. Claude 3.5 Sonnet model card addendum, 2024. URL https://www-cdn.anthropic.com/ fed9cc193a14b84131812372d8d5857f8f304c52/Model Card Claude 3 Addendum.pdf
2024
-
[9]
Claude Opus 4.6 system card
Anthropic. Claude Opus 4.6 system card. Technical report, Anthropic, February 2026. URL https: //www.anthropic.com/claude-opus-4-6-system-card
2026
-
[10]
The claude 3 model family: Opus, sonnet, haiku.Claude-3 Model Card, 1(1):4, 2024
AI Anthropic. The claude 3 model family: Opus, sonnet, haiku.Claude-3 Model Card, 1(1):4, 2024
2024
-
[11]
Viraj Bagal, Rishal Aggarwal, P . K. Vinod, and U. Deva Priyakumar. Molgpt: Molecular generation using a transformer-decoder model.J. Chem. Inf. Model., 62(9):2064–2076, 2022
2064
-
[12]
Equivariant energy-guided SDE for inverse molecular design
Fan Bao, Min Zhao, Zhongkai Hao, Peiyao Li, Chongxuan Li, and Jun Zhu. Equivariant energy-guided SDE for inverse molecular design. InICLR. OpenReview.net, 2023
2023
-
[13]
The protein data bank.Nucleic acids research, 28(1):235–242, 2000
Helen M Berman, John Westbrook, Zukang Feng, Gary Gilliland, Talapady N Bhat, Helge Weissig, Ilya N Shindyalov, and Philip E Bourne. The protein data bank.Nucleic acids research, 28(1):235–242, 2000. 53 BioMatrix
2000
-
[14]
Alphafold protein structure database 2025: a redesigned interface and updated structural coverage.Nucleic Acids Research, 54 (D1):D358–D362, 2026
Damian Bertoni, Maxim Tsenkov, Paulyna Magana, Sreenath Nair, Ivanna Pidruchna, Marcelo Querino Lima Afonso, Adam Midlik, Urmila Paramval, Dare Lawal, Ahsan Tanweer, et al. Alphafold protein structure database 2025: a redesigned interface and updated structural coverage.Nucleic Acids Research, 54 (D1):D358–D362, 2026
2025
-
[15]
Bronstein, and Alexander Tong
Avishek Joey Bose, Tara Akhound-Sadegh, Guillaume Huguet, Kilian Fatras, Jarrid Rector-Brooks, Cheng- Hao Liu, Andrei Cristian Nica, Maksym Korablyov, Michael M. Bronstein, and Alexander Tong. Se(3)- stochastic flow matching for protein backbone generation. InICLR. OpenReview.net, 2024
2024
-
[16]
Nathan Brown, Marco Fiscato, Marwin H. S. Segler, and Alain C. Vaucher. Guacamol: Benchmarking models for de novo molecular design.J. Chem. Inf. Model., 59(3):1096–1108, 2019
2019
-
[17]
Learning to design protein- protein interactions with enhanced generalization
Anton Bushuiev, Roman Bushuiev, Petr Kouba, Anatolii Filkin, Marketa Gabrielova, Michal Gabriel, Jir´ı Sedl´ar, Tom´as Pluskal, Jir´ı Damborsk´y, Stanislav Mazurenko, and Josef Sivic. Learning to design protein- protein interactions with enhanced generalization. InICLR. OpenReview.net, 2024
2024
-
[18]
Jaakkola
Andrew Campbell, Jason Yim, Regina Barzilay, Tom Rainforth, and Tommi S. Jaakkola. Generative flows on discrete state-spaces: Enabling multimodal flows with applications to protein co-design. InICML, Proceedings of Machine Learning Research, pages 5453–5512. PMLR / OpenReview.net, 2024
2024
-
[19]
PRESTO: progressive pretraining enhances synthetic chemistry outcomes
He Cao, Yanjun Shao, Zhiyuan Liu, Zijing Liu, Xiangru Tang, Yuan Yao, and Yu Li. PRESTO: progressive pretraining enhances synthetic chemistry outcomes. InEMNLP (Findings), Findings of ACL, pages 10197– 10224. Association for Computational Linguistics, 2024
2024
-
[20]
Lifan Chen, Xiaoqin Tan, Dingyan Wang, Feisheng Zhong, Xiaohong Liu, Tianbiao Yang, Xiaomin Luo, Kaixian Chen, Hualiang Jiang, Mingyue Zheng, and Arne Elofsson. Transformercpi: improving compound- protein interaction prediction by sequence-based deep learning with self-attention mechanism and label reversal experiments.Bioinform., 36(16):4406–4414, 2020
2020
-
[21]
Xiaokang Chen, Zhiyu Wu, Xingchao Liu, Zizheng Pan, Wen Liu, Zhenda Xie, Xingkai Yu, and Chong Ruan. Janus-pro: Unified multimodal understanding and generation with data and model scaling.arXiv preprint arXiv:2501.17811, 2025
Pith/arXiv arXiv 2025
-
[22]
Toward de novo protein design from natural language.BioRxiv, pages 2024–08, 2024
Fengyuan Dai, Shiyang You, Yudian Zhu, Yuan Gao, Lihao Fu, Xibin Zhou, Jin Su, Chentong Wang, Yuliang Fan, Xiaoxiao Ma, et al. Toward de novo protein design from natural language.BioRxiv, pages 2024–08, 2024
2024
-
[23]
Robust deep learning–based protein sequence design using proteinmpnn.Science, 378(6615):49–56, 2022
Justas Dauparas, Ivan Anishchenko, Nathaniel Bennett, Hua Bai, Robert J Ragotte, Lukas F Milles, Basile IM Wicky, Alexis Courbet, Rob J de Haas, Neville Bethel, et al. Robust deep learning–based protein sequence design using proteinmpnn.Science, 378(6615):49–56, 2022
2022
-
[24]
Translation between molecules and natural language
Carl Edwards, Tuan Manh Lai, Kevin Ros, Garrett Honke, Kyunghyun Cho, and Heng Ji. Translation between molecules and natural language. InEMNLP, pages 375–413. Association for Computational Linguistics, 2022
2022
-
[25]
Prottrans: toward understanding the language of life through self-supervised learning.IEEE transactions on pattern analysis and machine intelligence, 44(10): 7112–7127, 2021
Ahmed Elnaggar, Michael Heinzinger, Christian Dallago, Ghalia Rehawi, Yu Wang, Llion Jones, Tom Gibbs, Tamas Feher, Christoph Angerer, Martin Steinegger, et al. Prottrans: toward understanding the language of life through self-supervised learning.IEEE transactions on pattern analysis and machine intelligence, 44(10): 7112–7127, 2021
2021
-
[26]
Interleaved tool-call reasoning for protein function understanding, 2026
Chuanliu Fan, Zicheng Ma, Huanran Meng, Aijia Zhang, Wenjie Du, Jun Zhang, Yi Qin Gao, Ziqiang Cao, and Guohong Fu. Interleaved tool-call reasoning for protein function understanding, 2026. URL https://arxiv.org/abs/2601.03604
arXiv 2026
-
[27]
Run-Ze Fan, Zengzhi Wang, and Pengfei Liu. Megascience: Pushing the frontiers of post-training datasets for science reasoning.arXiv preprint arXiv:2507.16812, 2025
arXiv 2025
-
[28]
Mol-instructions: A large-scale biomolecular instruction dataset for large language models
Yin Fang, Xiaozhuan Liang, Ningyu Zhang, Kangwei Liu, Rui Huang, Zhuo Chen, Xiaohui Fan, and Huajun Chen. Mol-instructions: A large-scale biomolecular instruction dataset for large language models. InICLR. OpenReview.net, 2024
2024
-
[29]
Domain-agnostic molecular generation with chemical feedback
Yin Fang, Ningyu Zhang, Zhuo Chen, Lingbing Guo, Xiaohui Fan, and Huajun Chen. Domain-agnostic molecular generation with chemical feedback. InICLR. OpenReview.net, 2024. 54 BioMatrix
2024
-
[30]
Prediction of membrane protein types based on the hydrophobic index of amino acids.Journal of protein chemistry, 19(4):269–275, 2000
Zhi-Ping Feng and Chun-Ting Zhang. Prediction of membrane protein types based on the hydrophobic index of amino acids.Journal of protein chemistry, 19(4):269–275, 2000
2000
-
[31]
Francoeur, Tomohide Masuda, Jocelyn Sunseri, Andrew Jia, Richard B
Paul G. Francoeur, Tomohide Masuda, Jocelyn Sunseri, Andrew Jia, Richard B. Iovanisci, Ian Snyder, and David Ryan Koes. Three-dimensional convolutional neural networks and a cross-docked data set for structure-based drug design.J. Chem. Inf. Model., 60(9):4200–4215, 2020
2020
-
[32]
Tokenizing 3d molecule structure with quantized spherical coordinates
Kaiyuan Gao, Yusong Wang, Haoxiang Guan, Zun Wang, Qizhi Pei, John Hopcroft, Kun He, and Lijun Wu. Tokenizing 3d molecule structure with quantized spherical coordinates. InProceedings of the 32nd ACM SIGKDD Conference on Knowledge Discovery and Data Mining V . 1, pages 291–301, 2026
2026
-
[33]
Niklas W. A. Gebauer, Michael Gastegger, and Kristof Sch¨utt. Symmetry-adapted generation of 3d point sets for the targeted discovery of molecules. InNeurIPS, pages 7564–7576, 2019
2019
-
[34]
Binding affinity training data set, 2021
J Glaser. Binding affinity training data set, 2021. URLhttps://huggingface.co/datasets/jglaser/binding affinity
2021
-
[35]
Gemini 2.5: Our most intelligent AI model
Google DeepMind. Gemini 2.5: Our most intelligent AI model. Google DeepMind Blog, March 2025. URL https://blog.google/technology/google-deepmind/gemini-model-thinking-updates-march-2025/ . Ac- cessed: 2025-08-12
2025
-
[36]
The llama 3 herd of models.arXiv preprint arXiv:2407.21783, 2024
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al- Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, et al. The llama 3 herd of models.arXiv preprint arXiv:2407.21783, 2024
Pith/arXiv arXiv 2024
-
[37]
3d equivariant diffusion for target-aware molecule generation and affinity prediction
Jiaqi Guan, Wesley Wei Qian, Xingang Peng, Yufeng Su, Jian Peng, and Jianzhu Ma. 3d equivariant diffusion for target-aware molecule generation and affinity prediction. InICLR. OpenReview.net, 2023
2023
-
[38]
Gabriel Lima Guimaraes, Benjamin Sanchez-Lengeling, Carlos Outeiral, Pedro Luis Cunha Farias, and Al´an Aspuru-Guzik. Objective-reinforced generative adversarial networks (organ) for sequence generation models.arXiv preprint arXiv:1705.10843, 2017
Pith/arXiv arXiv 2017
-
[39]
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948, 2025
Pith/arXiv arXiv 2025
-
[40]
Using support vector machine combined with auto covariance to predict protein–protein interactions from protein sequences.Nucleic acids research, 36(9): 3025–3030, 2008
Yanzhi Guo, Lezheng Yu, Zhining Wen, and Menglong Li. Using support vector machine combined with auto covariance to predict protein–protein interactions from protein sequences.Nucleic acids research, 36(9): 3025–3030, 2008
2008
-
[41]
J ¨urgen Haas, Alessandro Barbato, Dario Behringer, Gabriel Studer, Steven Roth, Martino Bertoni, Khaled Mostaguir, Rafal Gumienny, and Torsten Schwede. Continuous automated model evaluation (cameo) complementing the critical assessment of structure prediction in casp12.Proteins: Structure, Function, and Bioinformatics, 86:387–398, 2018
2018
-
[42]
Simulating 500 million years of evolution with a language model.Science, 387(6736):850–858, 2025
Thomas Hayes, Roshan Rao, Halil Akin, Nicholas J Sofroniew, Deniz Oktay, Zeming Lin, Robert Verkuil, Vincent Q Tran, Jonathan Deaton, Marius Wiggert, et al. Simulating 500 million years of evolution with a language model.Science, 387(6736):850–858, 2025
2025
-
[43]
Measuring massive multitask language understanding
Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. Measuring massive multitask language understanding. InICLR. OpenReview.net, 2021
2021
-
[44]
Equivariant diffusion for molecule generation in 3d
Emiel Hoogeboom, Victor Garcia Satorras, Cl´ement Vignac, and Max Welling. Equivariant diffusion for molecule generation in 3d. InICML, Proceedings of Machine Learning Research, pages 8867–8887. PMLR, 2022
2022
-
[45]
OGB-LSC: A large-scale challenge for machine learning on graphs
Weihua Hu, Matthias Fey, Hongyu Ren, Maho Nakata, Yuxiao Dong, and Jure Leskovec. OGB-LSC: A large-scale challenge for machine learning on graphs. InNeurIPS Datasets and Benchmarks, 2021
2021
-
[46]
Conditional diffusion based on discrete graph structures for molecular graph generation
Han Huang, Leilei Sun, Bowen Du, and Weifeng Lv. Conditional diffusion based on discrete graph structures for molecular graph generation. InAAAI, pages 4302–4311. AAAI Press, 2023
2023
-
[47]
Learning joint 2-d and 3-d graph diffusion models for complete molecule generation.IEEE Trans
Han Huang, Leilei Sun, Bowen Du, and Weifeng Lv. Learning joint 2-d and 3-d graph diffusion models for complete molecule generation.IEEE Trans. Neural Networks Learn. Syst., 35(9):11857–11871, 2024. 55 BioMatrix
2024
-
[48]
MDM: molecular diffusion model for 3d molecule generation
Lei Huang, Hengtong Zhang, Tingyang Xu, and Ka-Chun Wong. MDM: molecular diffusion model for 3d molecule generation. InAAAI, pages 5105–5112. AAAI Press, 2023
2023
-
[49]
Qwen2.5-coder technical report.CoRR, abs/2409.12186, 2024
Binyuan Hui, Jian Yang, Zeyu Cui, Jiaxi Yang, Dayiheng Liu, Lei Zhang, Tianyu Liu, Jiajun Zhang, Bowen Yu, Kai Dang, An Yang, Rui Men, Fei Huang, Xingzhang Ren, Xuancheng Ren, Jingren Zhou, and Junyang Lin. Qwen2.5-coder technical report.CoRR, abs/2409.12186, 2024
Pith/arXiv arXiv 2024
-
[50]
Gpt-4o system card.arXiv preprint arXiv:2410.21276, 2024
Aaron Hurst, Adam Lerer, Adam P Goucher, Adam Perelman, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Welihinda, Alan Hayes, Alec Radford, et al. Gpt-4o system card.arXiv preprint arXiv:2410.21276, 2024
Pith/arXiv arXiv 2024
-
[51]
Illuminating protein space with a programmable generative model.Nature, 623(7989):1070–1078, 2023
John B Ingraham, Max Baranov, Zak Costello, Karl W Barber, Wujie Wang, Ahmed Ismail, Vincent Frappier, Dana M Lord, Christopher Ng-Thow-Hing, Erik R Van Vlack, et al. Illuminating protein space with a programmable generative model.Nature, 623(7989):1070–1078, 2023
2023
-
[52]
Dejun Jiang, Chang-Yu Hsieh, Zhenxing Wu, Yu Kang, Jike Wang, Ercheng Wang, Ben Liao, Chao Shen, Lei Xu, Jian Wu, et al. Interactiongraphnet: A novel and efficient deep graph representation learning framework for accurate protein–ligand interaction predictions.Journal of medicinal chemistry, 64(24):18209–18232, 2021
2021
-
[53]
Jaakkola
Wengong Jin, Regina Barzilay, and Tommi S. Jaakkola. Junction tree variational autoencoder for molecular graph generation. InICML, Proceedings of Machine Learning Research, pages 2328–2337. PMLR, 2018
2018
-
[54]
Pubchem 2025 update.Nucleic acids research, 53(D1):D1516–D1525, 2025
Sunghwan Kim, Jie Chen, Tiejun Cheng, Asta Gindulyte, Jia He, Siqian He, Qingliang Li, Benjamin A Shoemaker, Paul A Thiessen, Bo Yu, et al. Pubchem 2025 update.Nucleic acids research, 53(D1):D1516–D1525, 2025
2025
-
[55]
Kingma and Max Welling
Diederik P . Kingma and Max Welling. Auto-encoding variational bayes. InICLR, 2014
2014
-
[56]
Self- referencing embedded strings (SELFIES): A 100% robust molecular string representation.Mach
Mario Krenn, Florian H ¨ase, AkshatKumar Nigam, Pascal Friederich, and Al ´an Aspuru-Guzik. Self- referencing embedded strings (SELFIES): A 100% robust molecular string representation.Mach. Learn. Sci. Technol., 1(4):45024, 2020
2020
-
[57]
Efficient memory management for large language model serving with pagedattention
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph Gonza- lez, Hao Zhang, and Ion Stoica. Efficient memory management for large language model serving with pagedattention. InSOSP, pages 611–626. ACM, 2023
2023
-
[58]
Compressed graph representation for scalable molecular graph generation.J
Youngchun Kwon, Dongseon Lee, Youn-Suk Choi, Kyoham Shin, and Seokho Kang. Compressed graph representation for scalable molecular graph generation.J. Cheminformatics, 12(1):58, 2020
2020
-
[59]
Sch ¨utt
Tuan Le, Julian Cremer, Frank No ´e, Djork-Arn ´e Clevert, and Kristof T. Sch ¨utt. Navigating the design space of equivariant diffusion-based generative models for de novo 3d molecule generation. InICLR. OpenReview.net, 2024
2024
-
[60]
Speak-to-structure: Evaluating llms in open-domain natural language-driven molecule generation
Jiatong Li, Junxian Li, Weida Wang, Yunqing Liu, Changmeng Zheng, Dongzhan Zhou, Xiao-yong Wei, and Qing Li. Speak-to-structure: Evaluating llms in open-domain natural language-driven molecule generation. arXiv preprint arXiv:2412.14642, 2024
Pith/arXiv arXiv 2024
-
[61]
Mingyang Li, Yurou Liu, Jieping Ye, Bing Su, Ji-Rong Wen, and Zheng Wang. Speaking the language of science: Toward a general-purpose generative foundation model for the natural sciences.arXiv preprint arXiv:2606.16905, 2026
arXiv 2026
-
[62]
Monn: a multi-objective neural network for predicting compound-protein interactions and affinities.Cell systems, 10(4):308–322, 2020
Shuya Li, Fangping Wan, Hantao Shu, Tao Jiang, Dan Zhao, and Jianyang Zeng. Monn: a multi-objective neural network for predicting compound-protein interactions and affinities.Cell systems, 10(4):308–322, 2020
2020
-
[63]
Towards 3d molecule-text interpretation in language models
Sihang Li, Zhiyuan Liu, Yanchen Luo, Xiang Wang, Xiangnan He, Kenji Kawaguchi, Tat-Seng Chua, and Qi Tian. Towards 3d molecule-text interpretation in language models. InICLR. OpenReview.net, 2024
2024
-
[64]
Sc2mol: a scaffold-based two-step molecule generator with variational autoencoder and transformer.Bioinform., 39(1), 2023
Zhirui Liao, Lei Xie, Hiroshi Mamitsuka, and Shanfeng Zhu. Sc2mol: a scaffold-based two-step molecule generator with variational autoencoder and transformer.Bioinform., 39(1), 2023
2023
-
[65]
Evolutionary-scale prediction of atomic-level protein structure with a language model.Science, 379(6637):1123–1130, 2023
Zeming Lin, Halil Akin, Roshan Rao, Brian Hie, Zhongkai Zhu, Wenting Lu, Nikita Smetanin, Robert Verkuil, Ori Kabeli, Yaniv Shmueli, et al. Evolutionary-scale prediction of atomic-level protein structure with a language model.Science, 379(6637):1123–1130, 2023. 56 BioMatrix
2023
-
[66]
Protein design with dynamic protein vocabulary
Nuowei Liu, Jiahao Kuang, Yanting Liu, Tao Ji, Changzhi Sun, Man Lan, and Yuanbin Wu. Protein design with dynamic protein vocabulary. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems
-
[67]
A text-guided protein design framework.arXiv preprint arXiv:2302.04611, 2023
Shengchao Liu, Yutao Zhu, Jiarui Lu, Zhao Xu, Weili Nie, Anthony Gitter, Chaowei Xiao, Jian Tang, Hongyu Guo, and Anima Anandkumar. A text-guided protein design framework.arXiv preprint arXiv:2302.04611, 2023
arXiv 2023
-
[68]
Jorissen, and Michael K
Tiqing Liu, Yuhmei Lin, Xin Wen, Robert N. Jorissen, and Michael K. Gilson. Bindingdb: a web-accessible database of experimentally determined protein-ligand binding affinities.Nucleic Acids Res., 35(Database- Issue):198–201, 2007
2007
-
[69]
Bindingdb in 2024: a fair knowledgebase of protein-small molecule binding data
Tiqing Liu, Linda Hwang, Stephen K Burley, Carmen I Nitsche, Christopher Southan, W Patrick Walters, and Michael K Gilson. Bindingdb in 2024: a fair knowledgebase of protein-small molecule binding data. Nucleic acids research, 53(D1):D1633–D1644, 2025
2024
-
[70]
Forging the basis for developing protein–ligand interaction scoring functions.Accounts of chemical research, 50(2):302–309, 2017
Zhihai Liu, Minyi Su, Li Han, Jie Liu, Qifan Yang, Yan Li, and Renxiao Wang. Forging the basis for developing protein–ligand interaction scoring functions.Accounts of chemical research, 50(2):302–309, 2017
2017
-
[71]
Molca: Molecular graph-language modeling with cross-modal projector and uni-modal adapter
Zhiyuan Liu, Sihang Li, Yanchen Luo, Hao Fei, Yixin Cao, Kenji Kawaguchi, Xiang Wang, and Tat-Seng Chua. Molca: Molecular graph-language modeling with cross-modal projector and uni-modal adapter. In EMNLP, pages 15623–15638. Association for Computational Linguistics, 2023
2023
-
[72]
Prott3: Protein-to-text generation for text-based protein understanding
Zhiyuan Liu, An Zhang, Hao Fei, Enzhi Zhang, Xiang Wang, Kenji Kawaguchi, and Tat-Seng Chua. Prott3: Protein-to-text generation for text-based protein understanding. InACL (1), pages 5949–5966. Association for Computational Linguistics, 2024
2024
-
[73]
Next-mol: 3d diffusion meets 1d language modeling for 3d molecule generation
Zhiyuan Liu, Yanchen Luo, Han Huang, Enzhi Zhang, Sihang Li, Junfeng Fang, Yaorui Shi, Xiang Wang, Kenji Kawaguchi, and Tat-Seng Chua. Next-mol: 3d diffusion meets 1d language modeling for 3d molecule generation. InICLR. OpenReview.net, 2025
2025
-
[74]
Kyle Lo, Lucy Lu Wang, Mark Neumann, Rodney Kinney, and Daniel S. Weld. S2ORC: the semantic scholar open research corpus. InACL, pages 4969–4983. Association for Computational Linguistics, 2020
2020
-
[75]
Chemical reactions from us patents, 2017
Daniel Lowe. Chemical reactions from us patents, 2017
2017
-
[76]
Fineweb-edu: the finest collection of educational content, 2024
Anton Lozhkov, Loubna Ben Allal, Leandro von Werra, and Thomas Wolf. Fineweb-edu: the finest collection of educational content, 2024. URLhttps://huggingface.co/datasets/HuggingFaceFW/fineweb-edu
2024
-
[77]
Tankbind: Trigonometry- aware neural networks for drug-protein binding structure prediction
Wei Lu, Qifeng Wu, Jixian Zhang, Jiahua Rao, Chengtao Li, and Shuangjia Zheng. Tankbind: Trigonometry- aware neural networks for drug-protein binding structure prediction. InNeurIPS, 2022
2022
-
[78]
Moleculeqa: A dataset to evaluate factual accuracy in molecular comprehension
Xingyu Lu, He Cao, Zijing Liu, Shengyuan Bai, Leqing Chen, Yuan Yao, Hai-Tao Zheng, and Yu Li. Moleculeqa: A dataset to evaluate factual accuracy in molecular comprehension. InEMNLP (Findings), Findings of ACL, pages 3769–3789. Association for Computational Linguistics, 2024
2024
-
[79]
Yizhen Luo, Jiahuan Zhang, Siqi Fan, Kai Yang, Yushuai Wu, Mu Qiao, and Zaiqing Nie. Biomedgpt: Open multimodal generative pre-trained transformer for biomedicine.arXiv preprint arXiv:2308.09442, 2023
arXiv 2023
-
[80]
An autoregressive flow model for 3d molecular geometry generation from scratch
Youzhi Luo and Shuiwang Ji. An autoregressive flow model for 3d molecular geometry generation from scratch. InICLR. OpenReview.net, 2022
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.