Large Language Model-Assisted Cleaning of Report-Derived Labels in a Large-Scale Chest CT Dataset
Pith reviewed 2026-06-26 09:52 UTC · model grok-4.3
The pith
LLM-assisted review finds that radiologists often agree more with model labels than with original CT-RATE annotations
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
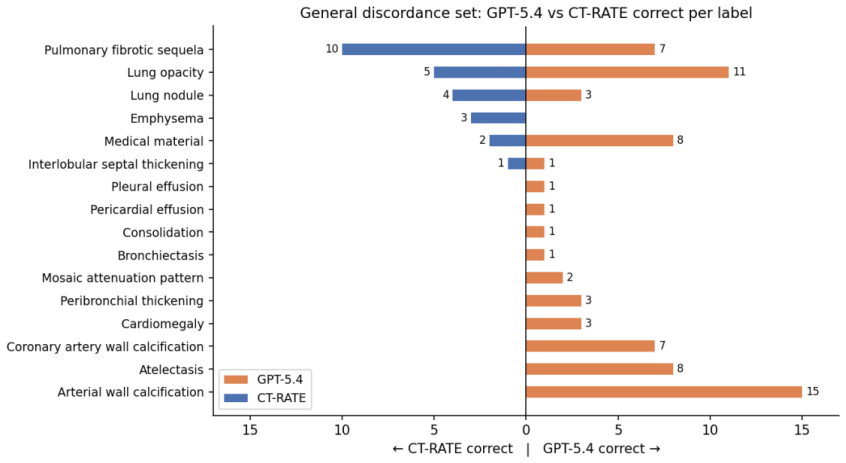
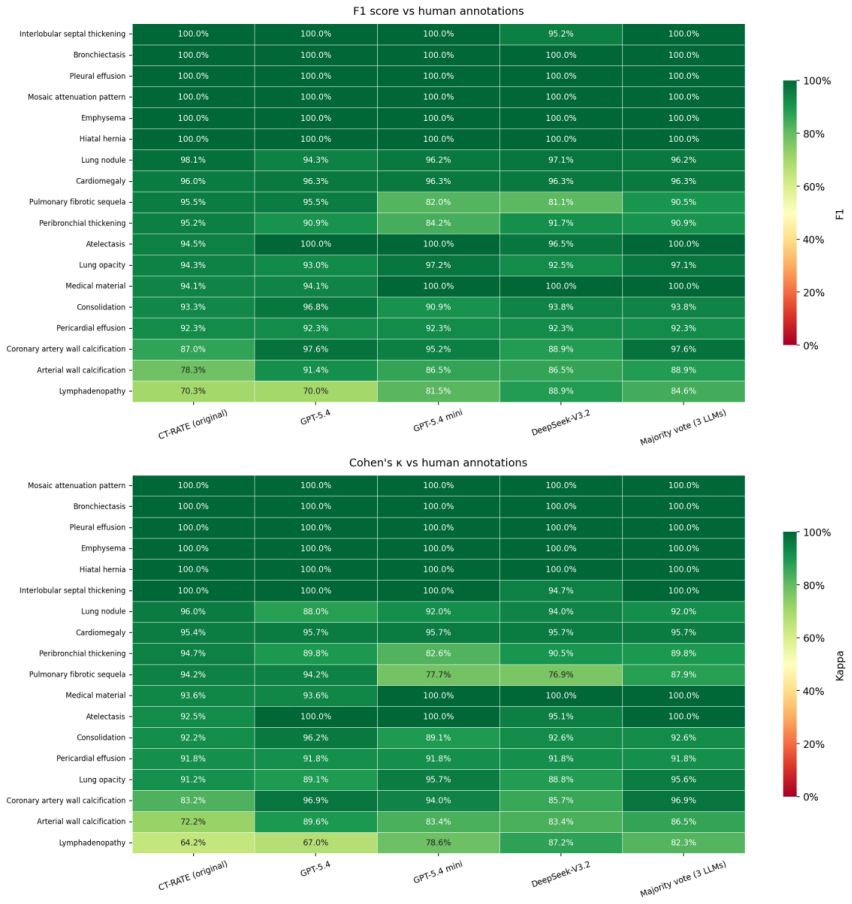
GPT-5.4-generated binary labels from report text agree with the existing CT-RATE labels at 96.4 percent overall (Cohen's kappa 0.884), with the lowest agreement observed for lymphadenopathy. When discordant instances are presented to radiologists for adjudication, the LLM label is supported in 72 of 97 general cases (74.2 percent) and 91 of 99 lymphadenopathy cases (91.9 percent). Against a radiologist-annotated reference set, multi-LLM majority-vote labels achieve the highest macro-averaged F1 score and kappa of any compared method.
What carries the argument
Generation of structured binary abnormality labels from free-text radiology reports via GPT-5.4, followed by direct comparison to CT-RATE labels and targeted radiologist adjudication of every discordance.
If this is right
- The cleaned version of the CT-RATE dataset can be released for downstream research use.
- LLM-assisted cleaning offers a scalable route to improve label quality in other public medical imaging collections.
- Multi-LLM majority voting outperforms both the original dataset labels and single-LLM outputs when measured against human reference annotations.
- Lymphadenopathy labels show the largest benefit from this cleaning step and may require targeted attention in future datasets.
Where Pith is reading between the lines
- The same report-to-label comparison pipeline could be applied to other imaging modalities or body regions to surface similar quality issues.
- Integrating LLM cleaning at the time of dataset construction might reduce the need for later correction.
- Measuring whether models trained on the cleaned labels show improved detection performance on independent test sets would quantify the practical impact.
Load-bearing premise
The radiologist decisions on the sampled discordances accurately reflect the correct label for the full collection of 439,812 instances.
What would settle it
A larger or complete radiologist review of all discordant label instances to determine whether the observed rates of support for LLM labels remain stable.
Figures

read the original abstract
Purpose: To evaluate whether large language model (LLM)-assisted label cleaning can identify label-report discordance in CT-RATE, a large-scale public chest CT dataset. Materials and Methods: After report-level deduplication, 24,446 unique radiology reports were identified. Twelve reports were excluded from the primary GPT-5.4 analysis because of Microsoft Azure AI Foundry content-safety filtering, leaving 24,434 reports and 439,812 label instances across 18 abnormality categories. GPT-5.4-derived binary labels were generated from report text using structured JSON output and compared with existing CT-RATE labels. Discordant instances were adjudicated by radiologists. In addition, 100 randomly sampled reports were manually annotated to compare CT-RATE labels, individual LLM-derived labels, and multi-LLM majority-vote labels against radiologist-annotated reference labels. Results: Overall agreement between GPT-5.4-derived and CT-RATE labels was 96.4%, with Cohen's kappa of 0.884. Lymphadenopathy showed the lowest agreement and kappa. In discordance review, radiologist adjudication supported GPT-5.4-derived labels in 72 of 97 (74.2%) general discordant instances and 91 of 99 (91.9%) targeted lymphadenopathy discordant instances. Against radiologist-annotated reference labels, multi-LLM majority-vote labels achieved the highest label-macro-averaged F1 score and Cohen's kappa. Conclusion: LLM-assisted label cleaning identified clinically meaningful label-report discordance in CT-RATE and may support scalable quality improvement of public imaging datasets. The cleaned dataset will be made publicly available to support future research.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript evaluates LLM-assisted label cleaning on the CT-RATE chest CT dataset. After deduplication, GPT-5.4 was used to derive binary labels from 24,434 reports (439,812 label instances across 18 categories), yielding 96.4% agreement (kappa 0.884) with existing CT-RATE labels. Radiologist adjudication of sampled discordants supported the LLM labels in 74.2% of 97 general cases and 91.9% of 99 lymphadenopathy cases. A separate 100-report manual annotation set showed multi-LLM majority vote outperforming single LLM and CT-RATE labels. The authors conclude that the approach identifies clinically meaningful discordance and can support scalable quality improvement, with the cleaned dataset to be released publicly.
Significance. If the sampling of discordants is representative, the work provides empirical evidence that LLM label cleaning can surface actionable errors in a large public chest CT dataset at scale, with the planned public release of cleaned labels offering a concrete resource for the community. The direct comparison to radiologist adjudication and the multi-LLM evaluation are strengths of the empirical design.
major comments (3)
- [Materials and Methods] Materials and Methods: The selection process for the 97 general and 99 lymphadenopathy discordant instances submitted for radiologist adjudication is not described (e.g., random sampling, stratification by report length or abnormality prevalence, or other criteria). With an implied total discordant pool of approximately 15,833 instances, the reported support rates (74.2% and 91.9%) cannot be assumed to generalize without evidence that the reviewed subset is representative; this directly underpins the central claim of identifying clinically meaningful discordance.
- [Materials and Methods] Materials and Methods: The 12 reports excluded due to Microsoft Azure AI Foundry content-safety filtering are not characterized (e.g., by report length, abnormality types, or reasons for filtering), and no sensitivity analysis is provided on how their exclusion affects the overall agreement or discordance statistics.
- [Materials and Methods] Materials and Methods / Results: Prompt engineering details for the GPT-5.4 structured JSON output (including system prompt, few-shot examples, or temperature settings) are not provided, limiting reproducibility of the label derivation step that drives the reported 96.4% agreement and downstream adjudication findings.
minor comments (2)
- [Materials and Methods] The 100-report manual annotation set is described as randomly sampled, but no power calculation or justification is given for why this size suffices to benchmark against the much larger discordance adjudication.
- Clarify the exact model version referenced as 'GPT-5.4' and whether it corresponds to a publicly available checkpoint.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript. We address each major comment point by point below and will make the indicated revisions to improve transparency and reproducibility.
read point-by-point responses
-
Referee: [Materials and Methods] Materials and Methods: The selection process for the 97 general and 99 lymphadenopathy discordant instances submitted for radiologist adjudication is not described (e.g., random sampling, stratification by report length or abnormality prevalence, or other criteria). With an implied total discordant pool of approximately 15,833 instances, the reported support rates (74.2% and 91.9%) cannot be assumed to generalize without evidence that the reviewed subset is representative; this directly underpins the central claim of identifying clinically meaningful discordance.
Authors: We agree that the sampling process must be explicitly stated. The 97 general and 99 lymphadenopathy discordant instances were obtained via random sampling from the respective discordant pools (total discordants across all categories: 15,833). We will revise the Materials and Methods section to document the random sampling procedure and report the total discordant count to allow readers to assess representativeness. revision: yes
-
Referee: [Materials and Methods] Materials and Methods: The 12 reports excluded due to Microsoft Azure AI Foundry content-safety filtering are not characterized (e.g., by report length, abnormality types, or reasons for filtering), and no sensitivity analysis is provided on how their exclusion affects the overall agreement or discordance statistics.
Authors: The 12 excluded reports represent only 0.05% of the deduplicated set. We will add a short characterization of these reports (including report length and primary abnormality categories where available) to the revised Materials and Methods and include a sensitivity analysis confirming that their exclusion has negligible impact on the 96.4% agreement and kappa statistics. revision: yes
-
Referee: [Materials and Methods] Materials and Methods / Results: Prompt engineering details for the GPT-5.4 structured JSON output (including system prompt, few-shot examples, or temperature settings) are not provided, limiting reproducibility of the label derivation step that drives the reported 96.4% agreement and downstream adjudication findings.
Authors: We recognize that full prompt details are required for reproducibility. The revised manuscript will include the complete system prompt, any few-shot examples, and the exact model parameters (including temperature) used to generate the structured JSON outputs from GPT-5.4. revision: yes
Circularity Check
Empirical evaluation study with direct radiologist adjudication; no derivations or fitted parameters
full rationale
The paper describes an empirical workflow: LLM label generation from reports, comparison to existing CT-RATE labels, radiologist adjudication of discordants (97+99 cases), and a separate 100-report manual annotation set for F1/kappa comparison. No equations, parameter fitting, self-citations as load-bearing premises, or renamings of known results appear. All performance claims rest on external human judgments rather than internal consistency or self-definition. The representativeness concern raised by the skeptic is a sampling-validity issue, not circularity.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Standard inter-rater agreement metrics such as Cohen's kappa are valid for evaluating label concordance
Reference graph
Works this paper leans on
-
[1]
Sourlos N, Vliegenthart R, Santinha J, et al. Recommendations for the creation of benchmark datasets for reproducible artificial intelligence in radiology. Insights Imaging. 2024;15(1):248. doi: 10.1186/s13244-024-01833-2
-
[2]
Zhou SK, Greenspan H, Davatzikos C, et al. A Review of Deep Learning in Medical Imaging: Imaging Traits, Technology Trends, Case Studies With Progress Highlights, and Future Promises. Proceedings of the IEEE. 2021;109(5):820 –838. doi: 10.1109/JPROC.2021.3054390
-
[3]
Smit A, Jain S, Rajpurkar P , Pareek A, Ng A, Lungren M. Combining Automatic Labelers and Expert Annotations for Accurate Radiology Report Labeling Using BERT. In: Webber B, Cohn T, He Y , Liu Y , editors. Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP). Online: Association for Computational Linguistics; 2020...
-
[4]
Exploring Large -scale Public Medical Image Datasets
Oakden-Rayner L. Exploring Large -scale Public Medical Image Datasets. Academic Radiology. 2020;27(1):106–112. doi: 10.1016/j.acra.2019.10.006
-
[5]
Generalist foundation models from a multimodal dataset for 3d computed tomography,
Hamamci IE, Er S, Wang C, et al. Generalist foundation models from a multimodal dataset for 3D computed tomography. Nat Biomed Eng. Nature Publishing Group; 2026;1 –19. doi: 10.1038/s41551-025-01599-y
-
[6]
Reichenpfader D, Müller H, Denecke K. A scoping review of large language model based approaches for information extraction from radiology reports. npj Digit Med. Nature Publishing Group; 2024;7(1):222. doi: 10.1038/s41746-024-01219-0
-
[7]
Privacy -preserving large language models for structured medical information retrieval
Wiest IC, Ferber D, Zhu J, et al. Privacy -preserving large language models for structured medical information retrieval. npj Digit Med. Nature Publishing Group; 2024;7(1):257. doi: 10.1038/s41746-024-01233-2
-
[8]
A critical assessment of using ChatGPT for extracting structured data from clinical notes
Huang J, Yang DM, Rong R, et al. A critical assessment of using ChatGPT for extracting structured data from clinical notes. npj Digit Med. Nature Publishing Group; 2024;7(1):106. doi: 10.1038/s41746-024-01079-8
-
[9]
Adams LC, Truhn D, Busch F , et al. Leveraging GPT-4 for Post Hoc Transformation of Free - text Radiology Reports into Structured Reporting: A Multilingual Feasibility Study. Radiology. Radiological Society of North Ame rica; 2023;307(4):e230725. doi: 10.1148/radiol.230725
-
[10]
OpenAI Deployment Safety Hub
GPT-5.4 Thinking System Card. OpenAI Deployment Safety Hub. https://deploymentsafety.openai.com/gpt-5-4-thinking. Accessed April 19, 2026
2026
-
[11]
DeepSeek -V3.2: Pushing the Frontier of Open Large Language Models
DeepSeek-AI, Liu A, Mei A, et al. DeepSeek -V3.2: Pushing the Frontier of Open Large Language Models. arXiv.org. 2025. https://arxiv.org/abs/2512.02556v1. Accessed March 23, 2026
Pith/arXiv arXiv 2025
-
[12]
The measurement of observer agreement for categorical data
Landis JR, Koch GG. The measurement of observer agreement for categorical data. Biometrics. 1977;33(1):159–174
1977
-
[13]
A Review on Medical Image Segmentation: Datasets, Technical Models, Challenges and Solutions
Gan H-S, Ramlee MH, Wang Z, Shimizu A. A Review on Medical Image Segmentation: Datasets, Technical Models, Challenges and Solutions. WIREs Data Mining and Knowledge Discovery. 2025;15(1):e1574. doi: 10.1002/widm.1574
-
[14]
Understanding Biases and Disparities in Radiology AI Datasets: A Review
Tripathi S, Gabriel K, Dheer S, et al. Understanding Biases and Disparities in Radiology AI Datasets: A Review. Journal of the American College of Radiology. 2023;20(9):836 –841. doi: 10.1016/j.jacr.2023.06.015
-
[15]
Roy SG, Digumarthy SR. Imaging Evaluation of Mediastinal and Hilar Lymphadenopathy: Approach, Classification, and Differential Diagnosis. Seminars in Roentgenology. 2025;60(2):105–122. doi: 10.1053/j.ro.2025.02.007
-
[16]
Thoracic lymphadenopathy in benign diseases: A state of the art review
Nin CS, de Souza VVS, do Amaral RH, et al. Thoracic lymphadenopathy in benign diseases: A state of the art review. Respiratory Medicine. 2016;112:10 –17. doi: 10.1016/j.rmed.2016.01.021
-
[17]
McInerney D, Young G, van de Meent J -W, Wallace B. CHiLL: Zero -shot Custom Interpretable Feature Extraction from Clinical Notes with Large Language Models. In: Bouamor H, Pino J, Bali K, editors. Findings of the Association for Computational Linguistics: EMNLP 2023. Singapore: Association for Computational Linguistics; 2023. p. 8477–8494. doi: 10.18653/...
-
[18]
Large language models are few - shot clinical information extractors
Agrawal M, Hegselmann S, Lang H, Kim Y , Sontag D. Large language models are few - shot clinical information extractors. In: Goldberg Y , Kozareva Z, Zhang Y , editors. Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing. Abu Dhabi, United Arab Emirates: Association for Computational Linguistics; 2022. p. 1998–
2022
-
[19]
doi: 10.18653/v1/2022.emnlp-main.130
-
[20]
Chavoshi M, Trivedi H, Mansuri A, et al. Impact of Label Noise from Large Language Model-generated Annotations on Evaluation of Diagnostic Model Performance. Radiol Artif Intell. 2026;8(2):e250477. doi: 10.1148/ryai.250477
-
[21]
Kitamura FC, Prevedello LM, Colak E, et al. Lessons Learned in Building Expertly Annotated Multi-Institution Datasets and Hosting the RSNA AI Challenges. Radiol Artif Intell. 2024;6(3):e230227. doi: 10.1148/ryai.230227. Figures Figure 1. Workflow of the LLM-assisted label-cleaning and validation framework. After report- level deduplication of CT-RATE, uni...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.