Humanoid-OmniOcc: Stereo-Based Full-View Occupancy Dataset for Embodied AI
Pith reviewed 2026-06-26 08:26 UTC · model grok-4.3
The pith
A stereo panoramic dataset built via Real2Sim2Real lets humanoid robots predict full-view occupancy more accurately than monocular methods and transfers to real captures.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that a closed-loop Real2Sim2Real pipeline, in which real camera specifications drive physically accurate simulation to produce large-scale labeled panoramic stereo data, enables a stereo-guided occupancy model to outperform monocular baselines while generalizing to both unseen simulated scenes and real-world captures.
What carries the argument
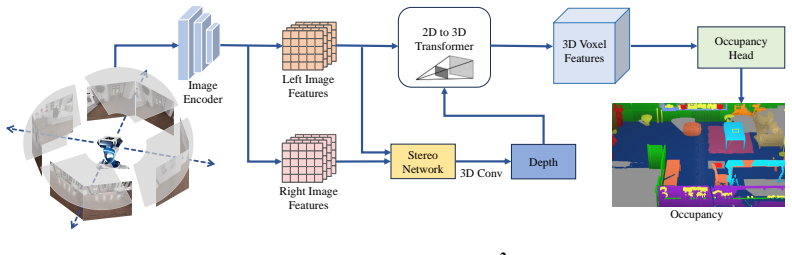
The Humanoid Surround Stereo-guided Occupancy model that uses stereo depth priors to perform accurate 2D-to-3D lifting, supported by the Real2Sim2Real dataset construction process.
If this is right
- Stereo inputs produce higher occupancy accuracy than monocular inputs across the evaluated scenes.
- Models trained on the simulated data maintain performance on previously unseen simulated indoor environments.
- The same models retain usable accuracy when evaluated on real-world stereo captures.
- The Real2Sim2Real loop supports repeated cycles of simulation improvement and model retraining.
Where Pith is reading between the lines
- The same sensor-driven simulation approach could be applied to other robot morphologies that require wide-field perception.
- Full-view occupancy maps may lower collision rates during close-range manipulation tasks inside homes or offices.
- The dataset supplies a controlled testbed for measuring how much stereo information reduces depth ambiguity relative to monocular methods.
Load-bearing premise
The simulation accurately reproduces real sensor behavior and physical environments so models trained inside it perform well on actual robot captures.
What would settle it
A large accuracy drop on the real-world test captures compared with the simulated test scenes after training on the simulated data.
Figures



read the original abstract
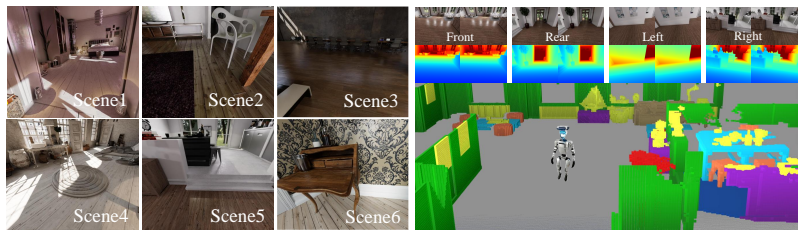
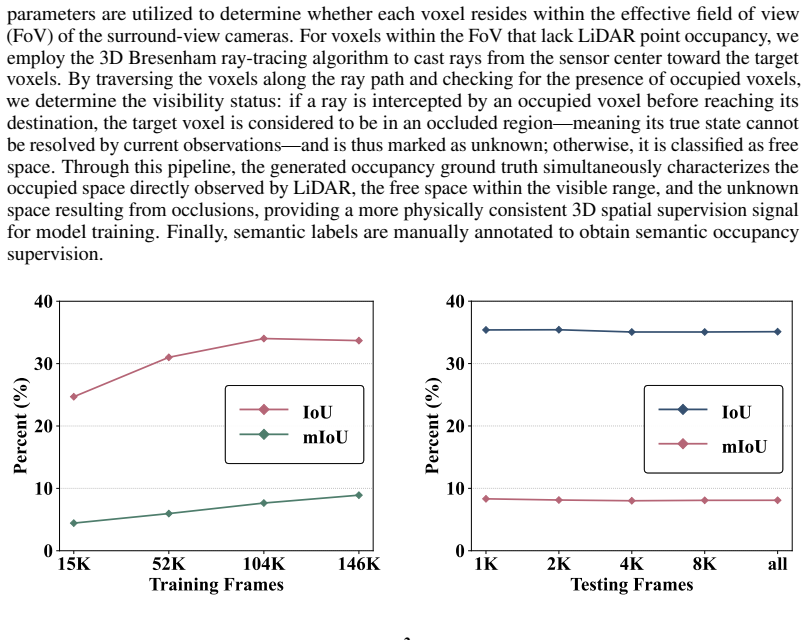
Occupancy prediction at voxel-level granularity is essential for safe robotic navigation and interaction in complex environments. Existing occupancy datasets, however, are predominantly designed for autonomous driving with vehicle-centric biases -- forward-facing cameras, far-field geometry, and static road priors -- limiting their applicability to embodied humanoid perception. We present Humanoid-OmniOcc, a large-scale panoramic stereo-based occupancy dataset tailored for humanoid robots. The dataset encompasses 15 diverse simulated indoor scenes and 5 real-world environments, yielding over 155K samples with broad scene and style diversity. Importantly, the dataset is designed around a Real2Sim2Real closed-loop paradigm: real sensor specifications drive physically accurate simulation, simulation produces large-scale annotated training data, and models trained in simulation are directly evaluated on real-world captures -- enabling iterative refinement of the sim-to-real pipeline. We further propose \textbf{H}umanoid \textbf{S}urround \textbf{S}tereo-guided \textbf{Occ}upancy model (Humanoid-OmniOcc) that exploits robust depth priors for accurate 2D-to-3D lifting. Extensive experiments show that Humanoid-OmniOcc consistently outperforms monocular baselines and generalizes well to both unseen simulated test scenes and real-world environments, validating the effectiveness of the Real2Sim2Real design. Code and data will be available upon acceptance at https://d-robotics-ai-lab.github.io/humanoid-omniocc.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to introduce Humanoid-OmniOcc, a large-scale panoramic stereo-based occupancy dataset for humanoid robots comprising 15 simulated indoor scenes and 5 real-world environments with over 155K samples. It follows a Real2Sim2Real closed-loop paradigm in which real sensor specifications drive physically accurate simulation to generate annotated training data, with models trained in simulation then evaluated directly on real captures. The authors also propose the Humanoid Surround Stereo-guided Occupancy model that exploits robust depth priors for 2D-to-3D lifting. Extensive experiments are reported to show consistent outperformance over monocular baselines together with good generalization to unseen simulated test scenes and real-world environments, thereby validating the Real2Sim2Real design.
Significance. If the quantitative results and sim-to-real transfer claims hold, the work would supply a valuable humanoid-centric occupancy resource that addresses the forward-facing, far-field, and road-prior biases of existing autonomous-driving datasets. The closed-loop paradigm and the explicit commitment to release code and data would further strengthen reproducibility and enable iterative refinement of sim-to-real pipelines for embodied perception.
major comments (2)
- [Experiments] Experiments section: The central claim that the Real2Sim2Real design is validated by successful generalization to real-world captures rests on the unverified assumption that simulated stereo observations (noise, calibration errors, matching failures) statistically match the real sensor. No quantitative fidelity checks—such as depth-distribution KL divergence, disparity-error histograms, or calibration-residual comparisons—are reported between the simulated and real data in the five environments.
- [Abstract and §4] Abstract and §4: The statement that Humanoid-OmniOcc 'consistently outperforms monocular baselines' is presented without any numerical results, error bars, specific metrics (e.g., IoU, mIoU), baseline implementations, or statistical significance tests, preventing assessment of whether the empirical support is load-bearing for the generalization claim.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major comment below.
read point-by-point responses
-
Referee: [Experiments] Experiments section: The central claim that the Real2Sim2Real design is validated by successful generalization to real-world captures rests on the unverified assumption that simulated stereo observations (noise, calibration errors, matching failures) statistically match the real sensor. No quantitative fidelity checks—such as depth-distribution KL divergence, disparity-error histograms, or calibration-residual comparisons—are reported between the simulated and real data in the five environments.
Authors: We agree that the manuscript does not report quantitative fidelity checks between simulated and real stereo observations. To address this, we will incorporate depth-distribution KL divergence, disparity-error histograms, and calibration-residual comparisons for the five real environments in a revised Experiments section. revision: yes
-
Referee: [Abstract and §4] Abstract and §4: The statement that Humanoid-OmniOcc 'consistently outperforms monocular baselines' is presented without any numerical results, error bars, specific metrics (e.g., IoU, mIoU), baseline implementations, or statistical significance tests, preventing assessment of whether the empirical support is load-bearing for the generalization claim.
Authors: We agree that the abstract summarizes results at a high level without numbers. We will revise §4 to explicitly present numerical results (including IoU and mIoU with error bars), baseline implementation details, and any statistical significance tests, and will update the abstract to reference key quantitative findings. revision: yes
Circularity Check
No circularity; empirical dataset and evaluation are self-contained
full rationale
The paper introduces a dataset via Real2Sim2Real design and evaluates a proposed model through direct experiments on real-world captures, showing outperformance versus monocular baselines. No equations, parameter fits, or derivations are present in the provided text. Claims rest on empirical measurements rather than reducing by construction to inputs, self-citations, or renamed known results. The sim-to-real transfer is an empirical assumption tested by real-data performance, not a definitional loop.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Behley, M
J. Behley, M. Garbade, A. Milioto, J. Quenzel, S. Behnke, C. Stachniss, and J. Gall. SemanticKITTI: A Dataset for Semantic Scene Understanding of LiDAR Sequences . In ICCV, 2019
2019
-
[2]
Surroundocc: Multi-camera 3d occupancy prediction for autonomous driving
Yi Wei, Linqing Zhao, Wenzhao Zheng, Zheng Zhu, Jie Zhou, and Jiwen Lu. Surroundocc: Multi-camera 3d occupancy prediction for autonomous driving. In ICCV, 2023
2023
-
[3]
Openoccupancy: A large scale benchmark for surrounding semantic occupancy perception
Xiaofeng Wang, Zheng Zhu, Wenbo Xu, Yunpeng Zhang, Yi Wei, Xu Chi, Yun Ye, Dalong Du, Jiwen Lu, and Xingang Wang. Openoccupancy: A large scale benchmark for surrounding semantic occupancy perception. In ICCV, 2023 a
2023
-
[4]
Wei Cui, Haoyu Wang, Wenkang Qin, Yijie Guo, Gang Han, Wen Zhao, Jiahang Cao, Zhang Zhang, Jiaru Zhong, Jingkai Sun, Pihai Sun, Shuai Shi, Botuo Jiang, Jiahao Ma, Jiaxu Wang, Hao Cheng, Zhichao Liu, Yang Wang, Zheng Zhu, Guan Huang, Jian Tang, and Qiang Zhang. Humanoid occupancy: Enabling a generalized multimodal occupancy perception system on humanoid ro...
arXiv 2025
-
[7]
Lightstereo: Channel boost is all you need for efficient 2d cost aggregation
Xianda Guo, Chenming Zhang, Youmin Zhang, Wenzhao Zheng, Dujun Nie, Matteo Poggi, and Long Chen. Lightstereo: Channel boost is all you need for efficient 2d cost aggregation. In ICRA, 2025 a
2025
-
[8]
Kitti-360: A novel dataset and benchmarks for urban scene understanding in 2d and 3d
Yiyi Liao, Jun Xie, and Andreas Geiger. Kitti-360: A novel dataset and benchmarks for urban scene understanding in 2d and 3d. TPAMI, 2022
2022
-
[9]
Occ3d: A large-scale 3d occupancy prediction benchmark for autonomous driving, 2023
Xiaoyu Tian, Tao Jiang, Longfei Yun, Yucheng Mao, Huitong Yang, Yue Wang, Yilun Wang, and Hang Zhao. Occ3d: A large-scale 3d occupancy prediction benchmark for autonomous driving, 2023. URL https://arxiv.org/abs/2304.14365
arXiv 2023
-
[10]
Stereovoxelnet: Real-time obstacle detection based on occupancy voxels from a stereo camera using deep neural networks
Hongyu Li, Zhengang Li, Neset Unver Akmandor, Huaizu Jiang, Yanzhi Wang, and Taskin Padir. Stereovoxelnet: Real-time obstacle detection based on occupancy voxels from a stereo camera using deep neural networks. In ICRA, 2023 a
2023
-
[11]
Wildocc: A benchmark for off-road 3d semantic occupancy prediction, 2024
Heng Zhai, Jilin Mei, Chen Min, Liang Chen, Fangzhou Zhao, and Yu Hu. Wildocc: A benchmark for off-road 3d semantic occupancy prediction, 2024. URL https://arxiv.org/abs/2410.15792
arXiv 2024
-
[12]
Omnihd-scenes: A next-generation multimodal dataset for autonomous driving, 2025
Lianqing Zheng, Long Yang, Qunshu Lin, Wenjin Ai, Minghao Liu, Shouyi Lu, Jianan Liu, Hongze Ren, Jingyue Mo, Xiaokai Bai, Jie Bai, Zhixiong Ma, and Xichan Zhu. Omnihd-scenes: A next-generation multimodal dataset for autonomous driving, 2025. URL https://arxiv.org/abs/2412.10734
arXiv 2025
-
[13]
Hanlin Wu, Pengfei Lin, Ehsan Javanmardi, Naren Bao, Bo Qian, Hao Si, and Manabu Tsukada. A synthetic benchmark for collaborative 3d semantic occupancy prediction in v2x autonomous driving, 2025 a . URL https://arxiv.org/abs/2506.17004
arXiv 2025
-
[14]
Event-aided semantic scene completion, 2025 b
Shangwei Guo, Hao Shi, Song Wang, Xiaoting Yin, Kailun Yang, and Kaiwei Wang. Event-aided semantic scene completion, 2025 b . URL https://arxiv.org/abs/2502.02334
arXiv 2025
-
[15]
Chen Min, Jilin Mei, Heng Zhai, Shuai Wang, Tong Sun, Fanjie Kong, Haoyang Li, Fangyuan Mao, Fuyang Liu, Shuo Wang, Yiming Nie, Qi Zhu, Liang Xiao, Dawei Zhao, and Yu Hu. Advancing off-road autonomous driving: The large-scale orad-3d dataset and comprehensive benchmarks, 2025. URL https://arxiv.org/abs/2510.16500
arXiv 2025
-
[16]
Chang, Manolis Savva, and Thomas Funkhouser
Shuran Song, Fisher Yu, Andy Zeng, Angel X. Chang, Manolis Savva, and Thomas Funkhouser. Semantic scene completion from a single depth image. In CVPR, 2017
2017
-
[17]
Monocular occupancy prediction for scalable indoor scenes
Hongxiao Yu, Yuqi Wang, Yuntao Chen, and Zhaoxiang Zhang. Monocular occupancy prediction for scalable indoor scenes. In ECCV, 2024
2024
-
[18]
Embodiedscan: A holistic multi-modal 3d perception suite towards embodied ai, 2023 b
Tai Wang, Xiaohan Mao, Chenming Zhu, Runsen Xu, Ruiyuan Lyu, Peisen Li, Xiao Chen, Wenwei Zhang, Kai Chen, Tianfan Xue, Xihui Liu, Cewu Lu, Dahua Lin, and Jiangmiao Pang. Embodiedscan: A holistic multi-modal 3d perception suite towards embodied ai, 2023 b . URL https://arxiv.org/abs/2312.16170
arXiv 2023
-
[19]
Embodiedocc: Embodied 3d occupancy prediction for vision-based online scene understanding
Yuqi Wu, Wenzhao Zheng, Sicheng Zuo, Yuanhui Huang, Jie Zhou, and Jiwen Lu. Embodiedocc: Embodied 3d occupancy prediction for vision-based online scene understanding. In ICCV, 2025 b
2025
-
[20]
Embodiedscan: A holistic multi-modal 3d perception suite towards embodied ai
Tai Wang, Xiaohan Mao, Chenming Zhu, Runsen Xu, Ruiyuan Lyu, Peisen Li, Xiao Chen, Wenwei Zhang, Kai Chen, Tianfan Xue, et al. Embodiedscan: A holistic multi-modal 3d perception suite towards embodied ai. In CVPR, 2024 a
2024
-
[21]
Monoscene: Monocular 3d semantic scene completion
Anh-Quan Cao and Raoul De Charette. Monoscene: Monocular 3d semantic scene completion. In CVPR, 2022
2022
-
[22]
Tri-perspective view for vision-based 3d semantic occupancy prediction
Yuanhui Huang, Wenzhao Zheng, Yunpeng Zhang, Jie Zhou, and Jiwen Lu. Tri-perspective view for vision-based 3d semantic occupancy prediction. In CVPR, 2023
2023
-
[24]
Flashocc: Fast and memory-efficient occupancy prediction via channel-to-height plugin
Zichen Yu, Changyong Shu, Jiajun Deng, Kangjie Lu, Zongdai Liu, Jiangyong Yu, Dawei Yang, Hui Li, and Yan Chen. Flashocc: Fast and memory-efficient occupancy prediction via channel-to-height plugin. arXiv preprint arXiv:2311.12058, 2023
arXiv 2023
-
[25]
Gaussianformer: Scene as gaussians for vision-based 3d semantic occupancy prediction
Yuanhui Huang, Wenzhao Zheng, Yunpeng Zhang, Jie Zhou, and Jiwen Lu. Gaussianformer: Scene as gaussians for vision-based 3d semantic occupancy prediction. In ECCV, 2024
2024
-
[26]
Gaussianformer-2: Probabilistic gaussian superposition for efficient 3d occupancy prediction
Yuanhui Huang, Amonnut Thammatadatrakoon, Wenzhao Zheng, Yunpeng Zhang, Dalong Du, and Jiwen Lu. Gaussianformer-2: Probabilistic gaussian superposition for efficient 3d occupancy prediction. In CVPR, 2025
2025
-
[27]
Embodiedocc: Embodied 3d occupancy prediction for vision-based online scene understanding
Yuqi Wu, Wenzhao Zheng, Sicheng Zuo, Yuanhui Huang, Jie Zhou, and Jiwen Lu. Embodiedocc: Embodied 3d occupancy prediction for vision-based online scene understanding. In ICCV, 2025 c
2025
-
[28]
Occfusion: Multi-sensor fusion framework for 3d semantic occupancy prediction
Zhenxing Ming, Julie Stephany Berrio, Mao Shan, and Stewart Worrall. Occfusion: Multi-sensor fusion framework for 3d semantic occupancy prediction. TIV, 2024
2024
-
[29]
Pyramid stereo matching network
Jia-Ren Chang and Yong-Sheng Chen. Pyramid stereo matching network. In CVPR, 2018
2018
-
[30]
Group-wise correlation stereo network
Xiaoyang Guo, Kai Yang, Wukui Yang, Xiaogang Wang, and Hongsheng Li. Group-wise correlation stereo network. In CVPR, 2019
2019
-
[31]
Hierarchical neural architecture search for deep stereo matching
Xuelian Cheng, Yiran Zhong, Mehrtash Harandi, Yuchao Dai, Xiaojun Chang, Hongdong Li, Tom Drummond, and Zongyuan Ge. Hierarchical neural architecture search for deep stereo matching. In NeurIPS, 2020
2020
-
[32]
Attention concatenation volume for accurate and efficient stereo matching
Gangwei Xu, Junda Cheng, Peng Guo, and Xin Yang. Attention concatenation volume for accurate and efficient stereo matching. In CVPR, 2022
2022
-
[33]
Iterative geometry encoding volume for stereo matching
Gangwei Xu, Xianqi Wang, Xiaohuan Ding, and Xin Yang. Iterative geometry encoding volume for stereo matching. In CVPR, 2023 a
2023
-
[34]
Igev++: iterative multi-range geometry encoding volumes for stereo matching
Gangwei Xu, Xianqi Wang, Zhaoxing Zhang, Junda Cheng, Chunyuan Liao, and Xin Yang. Igev++: iterative multi-range geometry encoding volumes for stereo matching. TPAMI, 2025
2025
-
[35]
Accurate and efficient stereo matching via attention concatenation volume
Gangwei Xu, Yun Wang, Junda Cheng, Jinhui Tang, and Xin Yang. Accurate and efficient stereo matching via attention concatenation volume. TPAMI, 2023 b
2023
-
[36]
Selective-stereo: Adaptive frequency information selection for stereo matching
Xianqi Wang, Gangwei Xu, Hao Jia, and Xin Yang. Selective-stereo: Adaptive frequency information selection for stereo matching. In CVPR, 2024 b
2024
-
[37]
Correlate-and-excite: Real-time stereo matching via guided cost volume excitation
Antyanta Bangunharcana, Jae Won Cho, Seokju Lee, In So Kweon, Kyung-Soo Kim, and Soohyun Kim. Correlate-and-excite: Real-time stereo matching via guided cost volume excitation. In IROS, 2021
2021
-
[38]
FADNet : A fast and accurate network for disparity estimation
Qiang Wang, Shaohuai Shi, Shizhen Zheng, Kaiyong Zhao, and Xiaowen Chu. FADNet : A fast and accurate network for disparity estimation. In ICRA, 2020
2020
-
[39]
Deeppruner: Learning efficient stereo matching via differentiable patchmatch
Shivam Duggal, Shenlong Wang, Wei-Chiu Ma, Rui Hu, and Raquel Urtasun. Deeppruner: Learning efficient stereo matching via differentiable patchmatch. In ICCV, 2019
2019
-
[40]
Mobilestereonet: Towards lightweight deep networks for stereo matching
Faranak Shamsafar, Samuel Woerz, Rafia Rahim, and Andreas Zell. Mobilestereonet: Towards lightweight deep networks for stereo matching. In WACV, 2022
2022
-
[41]
Stereonet: Guided hierarchical refinement for real-time edge-aware depth prediction
Sameh Khamis, Sean Fanello, Christoph Rhemann, Adarsh Kowdle, Julien Valentin, and Shahram Izadi. Stereonet: Guided hierarchical refinement for real-time edge-aware depth prediction. In ECCV, 2018
2018
-
[42]
Match-stereo-videos: Bidirectional alignment for consistent dynamic stereo matching
Junpeng Jing, Ye Mao, and Krystian Mikolajczyk. Match-stereo-videos: Bidirectional alignment for consistent dynamic stereo matching. In ECCV, 2024 a
2024
-
[45]
Foundationstereo: Zero-shot stereo matching
Bowen Wen, Matthew Trepte, Joseph Aribido, Jan Kautz, Orazio Gallo, and Stan Birchfield. Foundationstereo: Zero-shot stereo matching. In CVPR, 2025
2025
-
[46]
Depth anything: Unleashing the power of large-scale unlabeled data
Lihe Yang, Bingyi Kang, Zilong Huang, Xiaogang Xu, Jiashi Feng, and Hengshuang Zhao. Depth anything: Unleashing the power of large-scale unlabeled data. In CVPR, 2024 a
2024
-
[49]
Stereoscene: Bev-assisted stereo matching empowers 3d semantic scene completion
Bohan Li, Yasheng Sun, Xin Jin, Wenjun Zeng, Zheng Zhu, Xiaoefeng Wang, Yunpeng Zhang, James Okae, Hang Xiao, and Dalong Du. Stereoscene: Bev-assisted stereo matching empowers 3d semantic scene completion. In IJCAI, 2024
2024
-
[50]
Cvt-occ: Cost volume temporal fusion for 3d occupancy prediction
Zhangchen Ye, Tao Jiang, Chenfeng Xu, Yiming Li, and Hang Zhao. Cvt-occ: Cost volume temporal fusion for 3d occupancy prediction. In ECCV, 2024
2024
-
[52]
arXiv preprint arXiv:2312.00343 , year=
Openstereo: A comprehensive benchmark for stereo matching and strong baseline , author=. arXiv preprint arXiv:2312.00343 , year=
-
[53]
arXiv preprint arXiv:2411.14053 , year=
Stereo anything: Unifying stereo matching with large-scale mixed data , author=. arXiv preprint arXiv:2411.14053 , year=
-
[54]
ICRA , year=
Lightstereo: Channel boost is all you need for efficient 2d cost aggregation , author=. ICRA , year=
-
[55]
IROS , year=
A simple baseline for supervised surround-view depth estimation , author=. IROS , year=
-
[56]
ECCV , year=
Diffusiondepth: Diffusion denoising approach for monocular depth estimation , author=. ECCV , year=
-
[57]
CVPR , year=
Completionformer: Depth completion with convolutions and vision transformers , author=. CVPR , year=
-
[58]
3DV , year=
Monovit: Self-supervised monocular depth estimation with a vision transformer , author=. 3DV , year=
-
[59]
arXiv preprint arXiv:2204.05088 , year=
M2BEV: Multi-camera joint 3D detection and segmentation with unified birds-eye view representation , author=. arXiv preprint arXiv:2204.05088 , year=
-
[60]
ECCV , year=
Match-Stereo-Videos: Bidirectional Alignment for Consistent Dynamic Stereo Matching , author=. ECCV , year=
-
[61]
arXiv preprint arXiv:2409.20283 , year=
Match stereo videos via bidirectional alignment , author=. arXiv preprint arXiv:2409.20283 , year=
-
[62]
arXiv preprint arXiv:2503.05549 , year=
Stereo Any Video: Temporally Consistent Stereo Matching , author=. arXiv preprint arXiv:2503.05549 , year=
-
[63]
CoRL , year=
Behavior-1k: A benchmark for embodied ai with 1,000 everyday activities and realistic simulation , author=. CoRL , year=
-
[64]
arXiv preprint arXiv:2505.16148 , year=
NAN: A Training-Free Solution to Coefficient Estimation in Model Merging , author=. arXiv preprint arXiv:2505.16148 , year=
-
[65]
arXiv preprint arXiv:2505.12082 , year=
Model Merging in Pre-training of Large Language Models , author=. arXiv preprint arXiv:2505.12082 , year=
-
[66]
ECCV , year=
Training-free model merging for multi-target domain adaptation , author=. ECCV , year=
-
[67]
CVPR , year=
Defom-stereo: Depth foundation model based stereo matching , author=. CVPR , year=
-
[68]
CVPR , year=
MonSter: Marry Monodepth to Stereo Unleashes Power , author=. CVPR , year=
-
[69]
CVPR , year=
FoundationStereo: Zero-Shot Stereo Matching , author=. CVPR , year=
-
[70]
CVPR , year=
Stereo anywhere: Robust zero-shot deep stereo matching even where either stereo or mono fail , author=. CVPR , year=
-
[71]
TPAMI , year=
IGEV++: iterative multi-range geometry encoding volumes for stereo matching , author=. TPAMI , year=
-
[72]
ICCV , year=
Swin transformer: Hierarchical vision transformer using shifted windows , author=. ICCV , year=
-
[73]
ACM TOG , year=
Realfill: Reference-driven generation for authentic image completion , author=. ACM TOG , year=
-
[74]
TPAMI , year=
Booster: a benchmark for depth from images of specular and transparent surfaces , author=. TPAMI , year=
-
[75]
CVPR , year =
Yu, Fisher and Chen, Haofeng and Wang, Xin and Xian, Wenqi and Chen, Yingying and Liu, Fangchen and Madhavan, Vashisht and Darrell, Trevor , title =. CVPR , year =
-
[76]
and Araujo, A
Weyand, T. and Araujo, A. and Cao, B. and Sim, J. , title =. 2020 , booktitle =
2020
-
[77]
IJCV , year=
Imagenet large scale visual recognition challenge , author=. IJCV , year=
-
[78]
arXiv preprint arXiv:1506.03365 , year=
Lsun: Construction of a large-scale image dataset using deep learning with humans in the loop , author=. arXiv preprint arXiv:1506.03365 , year=
-
[79]
TPAMI , year=
Places: A 10 million image database for scene recognition , author=. TPAMI , year=
-
[80]
CVPR , year=
A large dataset to train convolutional networks for disparity, optical flow, and scene flow estimation , author=. CVPR , year=
-
[81]
CVPR , year=
Are we ready for autonomous driving? the kitti vision benchmark suite , author=. CVPR , year=
-
[82]
CVPR , year=
Object scene flow for autonomous vehicles , author=. CVPR , year=
-
[83]
GCPR , year=
High-resolution stereo datasets with subpixel-accurate ground truth , author=. GCPR , year=
-
[84]
CVPR , year=
A multi-view stereo benchmark with high-resolution images and multi-camera videos , author=. CVPR , year=
-
[85]
CVPR , year=
DrivingStereo: A Large-Scale Dataset for Stereo Matching in Autonomous Driving Scenarios , author=. CVPR , year=
-
[86]
CVPRW , pages=
Falling things: A synthetic dataset for 3d object detection and pose estimation , author=. CVPRW , pages=
-
[87]
Science China Information Sciences , year=
Instereo2k: a large real dataset for stereo matching in indoor scenes , author=. Science China Information Sciences , year=
-
[88]
ECCV , year=
A naturalistic open source movie for optical flow evaluation , author=. ECCV , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.