A Generative Model for Closed-Loop Microsimulation of Signalized Intersections
Pith reviewed 2026-06-26 08:23 UTC · model grok-4.3
The pith
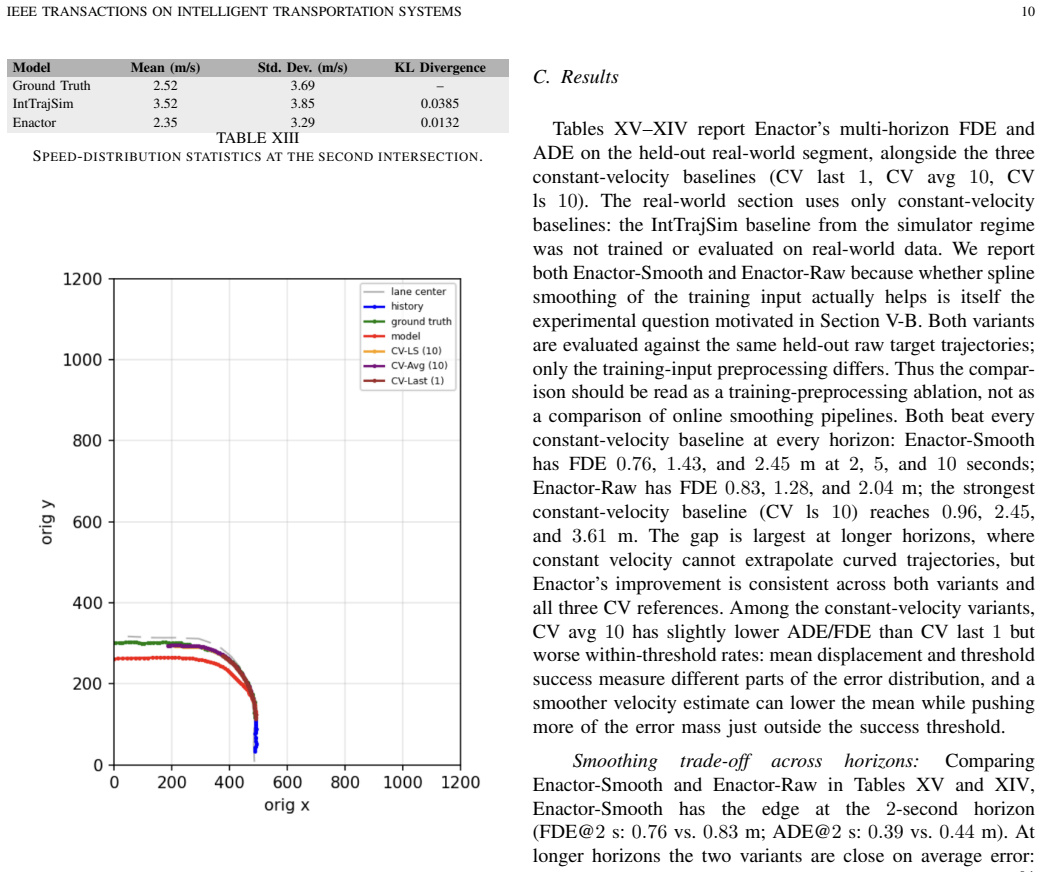
Enactor generates vehicle trajectories at signalized intersections that match a SUMO simulator's speed and travel-time distributions with over ten times lower KL divergence than a transformer baseline while cutting red-light violations by m
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
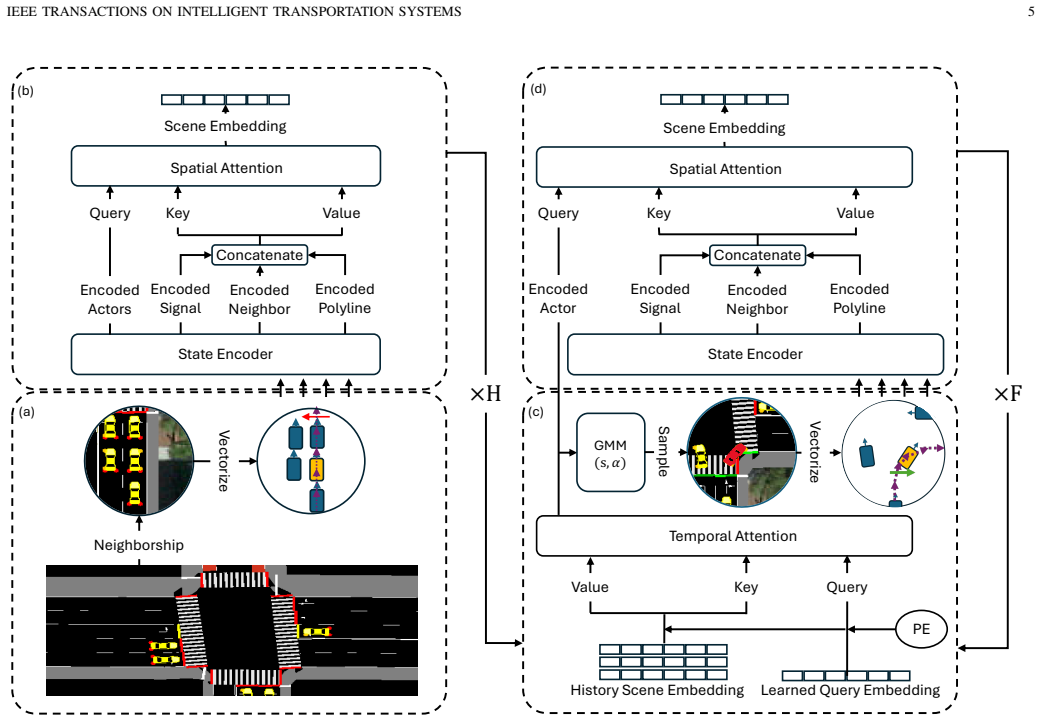
Enactor is an actor-centric generative model that encodes dynamic vehicles and lane polylines in polar coordinates referenced to the intersection center, uses a transformer with separate spatial and temporal attention blocks to output a distribution over each actor's next-step motion (s, α), and is trained with a closed-loop curriculum so that it learns to condition on its own predictions; when run in full closed-loop simulation-in-the-loop against a refreshing actor set it recovers the SUMO generator's speed and travel-time distributions with KL divergence more than an order of magnitude lower than a recent transformer baseline on travel time and roughly 5× lower on speed at one site, while
What carries the argument
Actor-centric transformer that predicts per-vehicle (s, α) distributions from polar-encoded actors and lanes, trained with closed-loop curriculum on its own rollouts.
If this is right
- Enactor recovers the SUMO data generator's speed and travel-time distributions with KL divergence over an order of magnitude lower than a recent transformer baseline on travel time.
- Enactor reduces red-light violations by more than an order of magnitude relative to the same baseline.
- An ablation shows the leader rear-bumper feature produces the largest improvement on intersection-aware safety metrics.
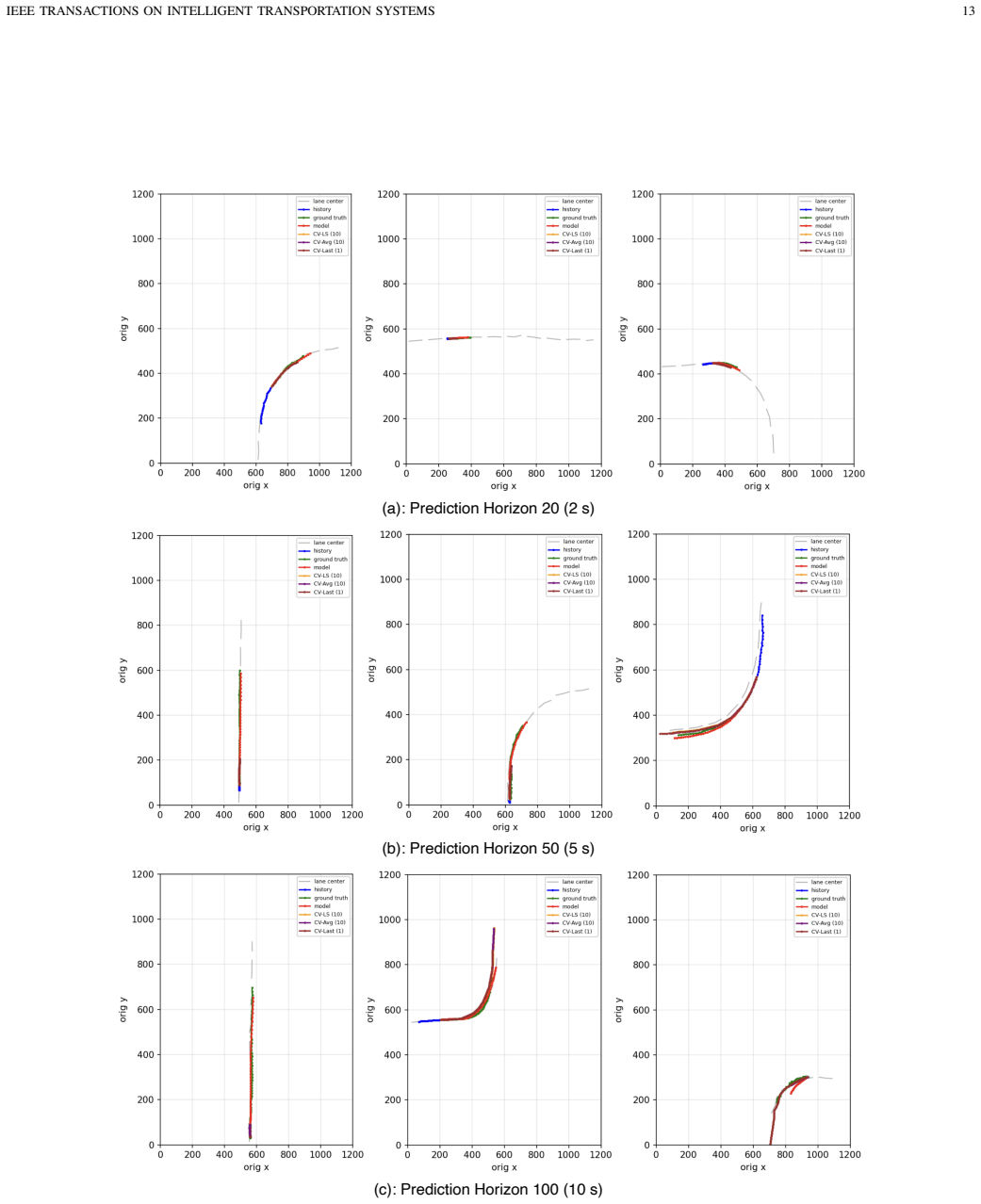
- The same architecture outperforms a constant-velocity baseline at every horizon on naturalistic vehicle trajectories from a fish-eye camera.
- Pedestrians are treated only as context that can influence vehicle decisions but are not themselves predicted.
Where Pith is reading between the lines
- The polar encoding and dual-attention design may allow the same model to be fine-tuned on limited real-world data without retraining from scratch.
- Because the model already handles a continuously refreshed actor set, it could be coupled directly to live sensor feeds for on-line traffic forecasting.
- The closed-loop curriculum's emphasis on long-horizon stability suggests the architecture could be adapted to multi-agent settings beyond intersections, such as highway merging.
- The ablation result on the leader rear-bumper feature indicates that explicit inclusion of immediate leader state is a high-leverage inductive bias for safety-critical motion models.
Load-bearing premise
A model trained via closed-loop curriculum on SUMO-generated data will remain stable and produce realistic long-horizon behavior when run in full simulation-in-the-loop with a refreshing actor set and when transferred to real field data.
What would settle it
Running the trained Enactor for 10 000+ seconds in closed loop on a new intersection geometry and measuring whether the KL divergence on travel-time distributions stays below the reported baseline level or begins to rise sharply.
Figures

read the original abstract
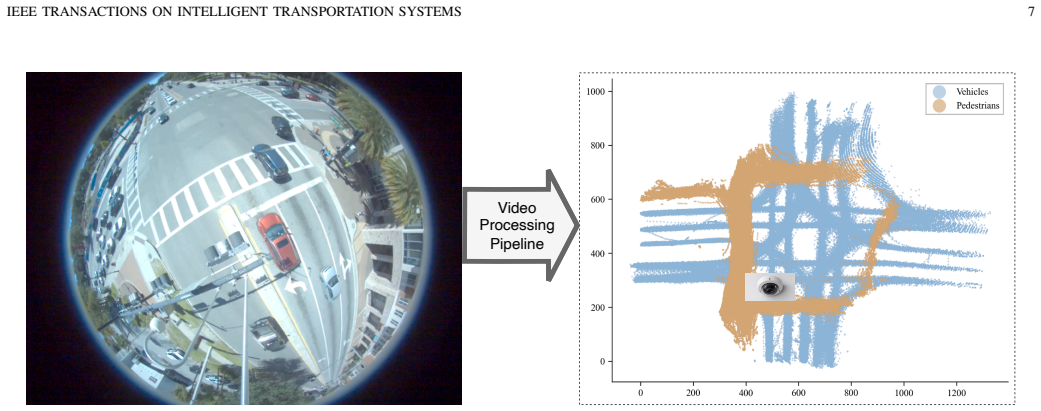
Traffic microsimulators rely on hand-crafted behavior models that reproduce aggregate flow but miss the heterogeneous interactions between vehicles at signalized intersections. Learned trajectory predictors capture richer interactions but are short-horizon and tend to be unstable when run in closed loop. We present Enactor, an actor-centric generative model for closed-loop intersection microsimulation. The model focuses on vehicles; pedestrians are included as context that can influence vehicle decisions but not predicted. Dynamic actors and lane polylines are encoded in polar coordinates referenced to the intersection center. A transformer with separate spatial and temporal attention blocks predicts a distribution over each actor's next-step motion ($s$, $\alpha$). Training uses a closed-loop curriculum so the model is exposed to its own predictions. We evaluate Enactor in two regimes. In a 4000-second simulation-in-the-loop test at two intersection geometries, Enactor controls every dynamic vehicle against a continuously refreshing actor set rather than the fixed cohort that learned trajectory predictors are usually evaluated against. It recovers the SUMO data generator's speed and travel-time distributions with KL divergence over an order of magnitude lower than a recent transformer baseline on travel time, and substantially lower on speed (roughly $5\times$ lower at Site 1), and reduces red-light violations relative to the same baseline by more than an order of magnitude. An ablation isolates the leader rear-bumper feature as the change with the largest effect on intersection-aware safety metrics. We also evaluate on real-world field data and apply the same architecture to naturalistic vehicle trajectories from a fish-eye camera at a signalized intersection and evaluate it on multi-horizon predictive tasks. Enactor outperforms a constant-velocity baseline at every horizon evaluated.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Enactor, an actor-centric generative model for closed-loop microsimulation of signalized intersections. Vehicles are encoded in polar coordinates relative to the intersection center; a transformer with separate spatial and temporal attention blocks outputs a distribution over each actor's next-step motion (s, α). Training employs a closed-loop curriculum. In 4000-second simulation-in-the-loop experiments at two sites, Enactor controls every dynamic vehicle against a continuously refreshing actor set and recovers the SUMO generator's speed and travel-time distributions with KL divergence more than an order of magnitude lower than a recent transformer baseline on travel time (roughly 5× lower on speed at Site 1) while reducing red-light violations by more than an order of magnitude. An ablation identifies the leader rear-bumper feature as most impactful on safety metrics. On real-world fish-eye camera trajectories the same architecture outperforms a constant-velocity baseline on multi-horizon open-loop prediction.
Significance. If the reported gains in distributional fidelity and violation reduction hold under the closed-loop regime with refreshing actors, the work supplies a concrete, reproducible route to stable long-horizon learned microsimulation that improves upon both hand-crafted SUMO models and short-horizon trajectory predictors. The explicit separation of closed-loop SUMO evaluation from open-loop real-world evaluation, together with the leader-rear-bumper ablation, strengthens the central claim that curriculum training plus actor-centric polar encoding enables realistic intersection behavior.
minor comments (3)
- [Abstract, §4] Abstract and §4: the factor-of-5× speed KL improvement at Site 1 and the order-of-magnitude travel-time and violation claims should be accompanied by the exact KL values, sample sizes, and any statistical significance tests in the main results tables so that readers can assess effect magnitude directly.
- [§3.2] §3.2: the precise definition of the polar encoding (origin at intersection center, reference frame for α) and the handling of lane-polyline context should be stated with an equation or pseudocode; current prose leaves the coordinate transformation ambiguous for re-implementation.
- [Introduction, Conclusion] The manuscript states that real-world evaluation is restricted to open-loop multi-horizon prediction; this distinction from the closed-loop SUMO regime should be reiterated in the introduction and conclusion to prevent readers from conflating the two settings.
Simulated Author's Rebuttal
We thank the referee for the detailed and accurate summary of our work, the positive assessment of its significance, and the recommendation for minor revision. No specific major comments were provided in the report.
Circularity Check
No significant circularity identified
full rationale
The manuscript describes an empirical generative model (Enactor) trained via closed-loop curriculum on SUMO data and evaluated in 4000-second simulation-in-the-loop runs that recover the generator's speed/travel-time distributions with lower KL than a transformer baseline, plus open-loop multi-horizon prediction on independent real-world camera trajectories. The closed-loop curriculum is a standard technique for exposing the model to its own outputs and does not force the reported distribution matches or violation reductions by construction; the baseline comparison and separate real-world test supply independent content. No self-definitional equations, fitted inputs renamed as predictions, load-bearing self-citations, or imported uniqueness theorems appear in the provided text.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Transformer attention blocks can effectively capture spatial and temporal dependencies in multi-actor trajectory data
- domain assumption Polar coordinate encoding centered at the intersection is adequate to represent lane polylines and actor states
Reference graph
Works this paper leans on
-
[1]
Enactor: From traffic simulators to surrogate world models,
Y . Ranjan, R. Sengupta, A. Rangarajan, and S. Ranka, “Enactor: From traffic simulators to surrogate world models,” inProceedings of the 12th International Conference on Vehicle Technology and Intelligent Transport Systems - VEHITS, INSTICC. SciTePress, 2026, pp. 430– 438
2026
-
[2]
Limitations of current traffic models and strategies to address them,
D. Ni, “Limitations of current traffic models and strategies to address them,”Simulation Modelling Practice and Theory, vol. 104, p. 102137, 2020. [Online]. Available: https://www.sciencedirect.com/ science/article/pii/S1569190X20300769
2020
-
[3]
Trajectron++: Dynamically-feasible trajectory forecasting with heterogeneous data,
T. Salzmann, B. Ivanovic, P. Chakravarty, and M. Pavone, “Trajectron++: Dynamically-feasible trajectory forecasting with heterogeneous data,”
-
[4]
Available: https://arxiv.org/abs/2001.03093
[Online]. Available: https://arxiv.org/abs/2001.03093
arXiv 2001
-
[5]
Motion transformer with global intention localization and local movement refinement,
S. Shi, L. Jiang, D. Dai, and B. Schiele, “Motion transformer with global intention localization and local movement refinement,” 2023. [Online]. Available: https://arxiv.org/abs/2209.13508
arXiv 2023
-
[6]
Trafficbots: Towards world models for autonomous driving simulation and motion prediction,
L. Zhang, J. Gao, W. Liet al., “Trafficbots: Towards world models for autonomous driving simulation and motion prediction,” inIEEE Intl. Conf. on Robotics and Automation (ICRA), 2023
2023
-
[7]
Social LSTM: Human trajectory prediction in crowded spaces,
A. Alahi, K. Goel, V . Ramanathan, A. Robicquet, L. Fei-Fei, and S. Savarese, “Social LSTM: Human trajectory prediction in crowded spaces,” inIEEE Conference on Computer Vision and Pattern Recogni- tion (CVPR), 2016, pp. 961–971. IEEE TRANSACTIONS ON INTELLIGENT TRANSPORTATION SYSTEMS 12
2016
-
[8]
Convolutional social pooling for vehicle trajectory prediction,
N. Deo and M. M. Trivedi, “Convolutional social pooling for vehicle trajectory prediction,” inIEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), 2018, pp. 1468–1476
2018
-
[9]
Social GAN: Socially acceptable trajectories with generative adversarial net- works,
A. Gupta, J. Johnson, L. Fei-Fei, S. Savarese, and A. Alahi, “Social GAN: Socially acceptable trajectories with generative adversarial net- works,” inIEEE Conference on Computer Vision and Pattern Recogni- tion (CVPR), 2018, pp. 2255–2264
2018
-
[10]
Attention is all you need,
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. Kaiser, and I. Polosukhin, “Attention is all you need,” inAdvances in Neural Information Processing Systems (NeurIPS), 2017
2017
-
[11]
Attention based vehicle trajectory prediction,
K. Messaoud, I. Yahiaoui, A. Verroust-Blondet, and F. Nashashibi, “Attention based vehicle trajectory prediction,”IEEE Transactions on Intelligent Vehicles, vol. 6, no. 1, pp. 175–185, Mar. 2021
2021
-
[12]
AI-TP: Attention- based interaction-aware trajectory prediction for autonomous driving,
K. Zhang, L. Zhao, C. Dong, L. Wu, and L. Zheng, “AI-TP: Attention- based interaction-aware trajectory prediction for autonomous driving,” IEEE Transactions on Intelligent Vehicles, vol. 8, no. 1, pp. 73–83, Jan. 2023
2023
-
[13]
Intention- aware vehicle trajectory prediction based on spatial-temporal dynamic attention network for internet of vehicles,
X. Chen, H. Zhang, F. Zhao, Y . Hu, C. Tan, and J. Yang, “Intention- aware vehicle trajectory prediction based on spatial-temporal dynamic attention network for internet of vehicles,”IEEE Transactions on Intel- ligent Transportation Systems, vol. 23, no. 10, pp. 19 471–19 483, Oct. 2022
2022
-
[14]
Adaptive and simultaneous trajectory prediction for heterogeneous agents via transferable hierarchical transformer network,
M. Geng, J. Li, C. Li, N. Xie, X. Chen, and D.-H. Lee, “Adaptive and simultaneous trajectory prediction for heterogeneous agents via transferable hierarchical transformer network,”IEEE Transactions on Intelligent Transportation Systems, vol. 24, no. 10, pp. 11 479–11 492, Oct. 2023
2023
-
[15]
Hdgt: Heterogeneous driving graph transformer for multi-agent trajectory prediction via scene encoding,
X. Jia, P. Wu, L. Chenet al., “Hdgt: Heterogeneous driving graph transformer for multi-agent trajectory prediction via scene encoding,” IEEE Trans. on Pattern Analysis and Machine Intelligence (TPAMI), 2023
2023
-
[16]
Bayesian network for red-light-running prediction at signalized intersections,
X. Chen, L. Zhou, and L. Li, “Bayesian network for red-light-running prediction at signalized intersections,”Journal of Intelligent Transporta- tion Systems, vol. 23, no. 2, pp. 120–132, Mar. 2019
2019
-
[17]
Vehicle motion prediction at intersections based on the turning intention and prior trajectories model,
T. Zhang, W. Song, M. Fu, Y . Yang, and M. Wang, “Vehicle motion prediction at intersections based on the turning intention and prior trajectories model,”IEEE/CAA Journal of Automatica Sinica, vol. 8, no. 10, pp. 1657–1666, Oct. 2021
2021
-
[18]
A hierarchical vehicle behavior prediction framework with traffic signals and interactive agents,
Z. Yang, R. Zhang, G. Pandey, N. Masoud, and H. X. Liu, “A hierarchical vehicle behavior prediction framework with traffic signals and interactive agents,”IEEE Transactions on Intelligent Transportation Systems, vol. 24, no. 10, pp. 11 066–11 079, Oct. 2023
2023
-
[19]
Impact of traffic lights on trajectory forecasting of human-driven vehicles near signalized intersections,
G. Oh and H. Peng, “Impact of traffic lights on trajectory forecasting of human-driven vehicles near signalized intersections,” 2019
2019
-
[20]
D2-TPred: Discontinuous dependency for trajectory prediction under traffic lights,
Y . Zhang, W. Wang, W. Guo, P. Lv, M. Xu, W. Chen, and D. Manocha, “D2-TPred: Discontinuous dependency for trajectory prediction under traffic lights,” inEuropean Conference on Computer Vision (ECCV), 2022, pp. 522–539
2022
-
[21]
Ki-gan: Knowledge-informed generative adversarial networks for vehicle trajectory prediction at signalized intersections,
C. Wei, L. Zhang, W. Liet al., “Ki-gan: Knowledge-informed generative adversarial networks for vehicle trajectory prediction at signalized intersections,” inIEEE/CVF Conf. on Computer Vision and Pattern Recognition Workshops (CVPRW), 2024
2024
-
[22]
Multi-modal interaction-aware motion prediction at unsignalized intersections,
V . Trentin, A. Artu ˜nedo, J. Godoy, and J. Villagra, “Multi-modal interaction-aware motion prediction at unsignalized intersections,”IEEE Transactions on Intelligent Vehicles, vol. 8, no. 5, pp. 3349–3365, May 2023
2023
-
[23]
MMH-STA: A macro-micro- hierarchical spatio-temporal attention method for multi-agent trajectory prediction in unsignalized roundabouts,
Y . Sun, T. Xu, J. Li, Y . Chu, and X. Ji, “MMH-STA: A macro-micro- hierarchical spatio-temporal attention method for multi-agent trajectory prediction in unsignalized roundabouts,”IEEE Transactions on Vehicu- lar Technology, vol. 72, no. 9, pp. 11 237–11 250, Sep. 2023
2023
-
[24]
Vehicle trajectory prediction at intersections using interaction based generative adversar- ial networks,
D. Roy, T. Ishizaka, C. K. Mohan, and A. Fukuda, “Vehicle trajectory prediction at intersections using interaction based generative adversar- ial networks,” inIEEE Intelligent Transportation Systems Conference (ITSC), Auckland, New Zealand, 2019, pp. 2318–2323
2019
-
[25]
A data- driven approach for probabilistic traffic prediction and simulation at signalized intersections,
A. Wu, Y . Ranjan, R. Sengupta, A. Rangarajan, and S. Ranka, “A data- driven approach for probabilistic traffic prediction and simulation at signalized intersections,” in2024 IEEE Intelligent Vehicles Symposium (IV), 2024, pp. 3092–3099
2024
-
[26]
Large scale interactive motion forecasting for autonomous driving: The waymo open motion dataset,
S. Ettinger, A. Timofeev, M. Krivokon, A. Gao, A. Joshi, Y . Zhang, J. Shlens, and D. Anguelov, “Large scale interactive motion forecasting for autonomous driving: The waymo open motion dataset,” inProceed- ings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2021, pp. 4378–4387
2021
-
[27]
Building transportation foundation model via generative graph transformer,
X. Wang, D. Wang, L. Chen, and Y . Lin, “Building transportation foundation model via generative graph transformer,” 2023. [Online]. Available: https://arxiv.org/abs/2305.14826
arXiv 2023
-
[28]
Transworldng: Traffic simulation via foundation model,
Y . Zhang, X. Chen, Y . Liuet al., “Transworldng: Traffic simulation via foundation model,” inIEEE Intl. Conf. on Smart Computing (SMART- COMP), 2023
2023
-
[29]
Scenediffuser++: City-scale traffic simulation via a generative world model,
S. Tan, J. Lambert, H. Jeon, S. Kulshrestha, Y . Bai, J. Luo, D. Anguelov, M. Tan, and C. M. Jiang, “Scenediffuser++: City-scale traffic simulation via a generative world model,” 2025. [Online]. Available: https://arxiv.org/abs/2506.21976
arXiv 2025
-
[30]
Beyond simulation: Benchmarking world models for planning and causality in autonomous driving,
K. Zheng, J. Gao, W. Liet al., “Beyond simulation: Benchmarking world models for planning and causality in autonomous driving,”arXiv preprint arXiv:2508.01922, 2025
arXiv 2025
-
[31]
Inttrajsim: Trajectory prediction for simulating multi-vehicle driving at signalized intersections,
Y . Ranjan, R. Sengupta, A. Rangarajan, and S. Ranka, “Inttrajsim: Trajectory prediction for simulating multi-vehicle driving at signalized intersections,” 2025. [Online]. Available: https://arxiv.org/abs/2506. 08957
2025
-
[32]
Evaluating generative vehicle trajectory models for nbsp;traffic intersection dynamics,
——, “Evaluating generative vehicle trajectory models for nbsp;traffic intersection dynamics,” inData Science: Foundations and Applications: 29th Pacific-Asia Conference on Knowledge Discovery and Data Mining, PAKDD 2025, Sydney, NSW, Australia, June 10-13, 2025, Proceedings, Part VI. Berlin, Heidelberg: Springer-Verlag, 2025, p. 262–274. [Online]. Availab...
-
[33]
Beyond centrality: Understanding urban street network typologies through intersection patterns,
A. Kuncheria, J. L. Walker, and J. Macfarlane, “Beyond centrality: Understanding urban street network typologies through intersection patterns,” 2025. [Online]. Available: https://arxiv.org/abs/2511.06747
arXiv 2025
-
[34]
The waymo open sim agents challenge,
N. Montali, J. Lambert, P. Mougin, A. Kuefler, N. Rhinehart, M. Li, C. Gulino, T. Emrich, Z. Yang, S. Whiteson, B. White, and D. Anguelov, “The waymo open sim agents challenge,” 2023. [Online]. Available: https://arxiv.org/abs/2305.12032
arXiv 2023
-
[35]
Relative position matters: Trajectory prediction and planning with polar representation,
B. Zhang, N. Song, B. Gao, and L. Zhang, “Relative position matters: Trajectory prediction and planning with polar representation,” 2025. [Online]. Available: https://arxiv.org/abs/2508.11492
arXiv 2025
-
[36]
Vectornet: Encoding hd maps and agent dynamics from vectorized representation,
J. Gao, C. Sun, H. Zhao, Y . Shen, D. Anguelov, C. Li, and C. Schmid, “Vectornet: Encoding hd maps and agent dynamics from vectorized representation,” 2020. [Online]. Available: https: //arxiv.org/abs/2005.04259
arXiv 2020
-
[37]
Machine-learning-based real-time multi-camera vehicle tracking and travel-time estimation,
X. Huang, P. He, A. Rangarajan, and S. Ranka, “Machine-learning-based real-time multi-camera vehicle tracking and travel-time estimation,” Journal of Imaging, vol. 8, no. 4, 2022. [Online]. Available: https://www.mdpi.com/2313-433X/8/4/101 IEEE TRANSACTIONS ON INTELLIGENT TRANSPORTATION SYSTEMS 13 (a): Prediction Horizon 20 (2 s) (b): Prediction Horizon 5...
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.