EMAgnet: Parameter-Space EMA Regularization for Policy Gradient Self-Play in Large Games
Pith reviewed 2026-06-26 08:30 UTC · model grok-4.3
The pith
Replacing uniform regularization with an EMA of policy parameters reduces exploitability in policy-gradient self-play.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
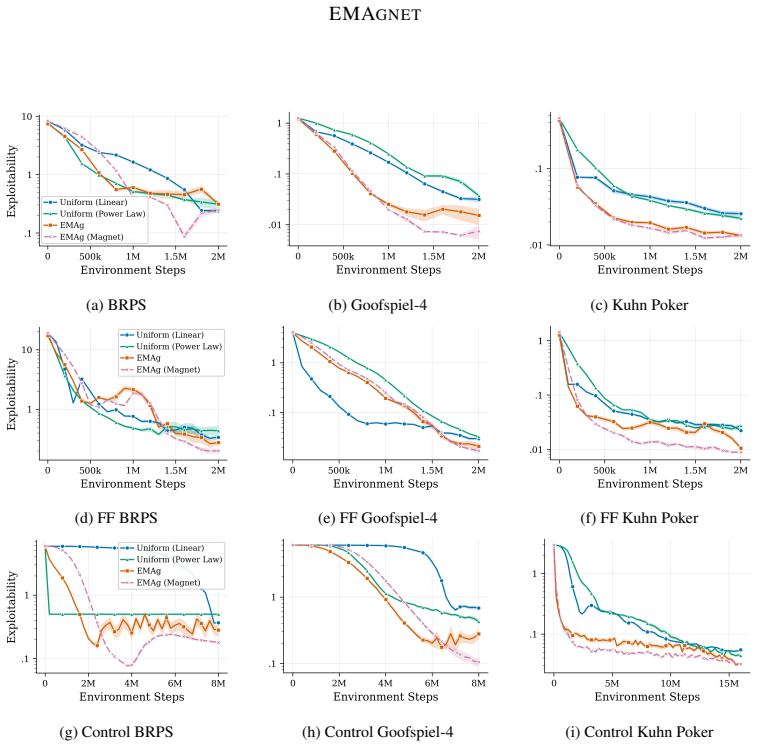
EMAgnet regularizes toward an exponential moving average of the last-iterate policy parameters rather than a uniform distribution, providing an adaptive target that changes as the strategy improves. When evaluated against PPO self-play with uniform-magnet regularization under linear and power-law annealing, it produces lower exploitability in the majority of environments, including those with exploration challenges, and delivers consistent gains whenever strictly dominated strategies are present.
What carries the argument
Exponential moving average of policy parameters as the regularization target in parameter space.
If this is right
- Self-play algorithms can benefit from adaptive rather than fixed regularization targets.
- Games with strictly dominated strategies see reliable improvements from this change.
- The method integrates directly into PPO without altering the core self-play loop or annealing.
- Exploitability reductions hold across both standard benchmarks and modified ones with added exploration challenges.
Where Pith is reading between the lines
- The approach may extend to other policy optimization methods beyond PPO.
- Further gains could come from combining EMA targets with learned or game-specific regularization.
- Testing on three-player or non-zero-sum settings would reveal if the benefit is specific to two-player zero-sum dynamics.
- Parameter-space EMA might interact differently with function approximation in very large state spaces.
Load-bearing premise
An exponential moving average of policy parameters supplies a meaningfully better adaptive regularization target than a static uniform distribution when self-play dynamics and annealing schedules remain unchanged.
What would settle it
A replication study on the same benchmarks that finds uniform regularization achieving equal or lower exploitability in most environments would falsify the performance advantage.
Figures

read the original abstract
Recent work has established that regularized policy gradient methods such as PPO, when used in self-play, can match or exceed specialized game-theoretic algorithms for solving two-player zero-sum imperfect-information games. The uniform distribution has emerged as a strong policy regularization target for this purpose, but it regularizes equally toward all actions regardless of their viability. We introduce EMAgnet, which instead regularizes toward an exponential moving average (EMA) of the last-iterate policy's parameters, providing an adaptive regularization target that evolves with the agent's improving strategy. We evaluate EMAgnet on both standard two-player zero-sum benchmarks and modified benchmarks with exploration challenges and large numbers of strictly dominated strategies. Relative to PPO self-play with uniform-magnet regularization under both linear and power-law annealing schedules, EMAgnet achieves lower exploitability in the majority of tested environments, with consistent performance gains across games containing strictly dominated strategies.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces EMAgnet, a regularization technique for PPO self-play in two-player zero-sum imperfect-information games that replaces the uniform distribution with an exponential moving average of the policy parameters as the regularization target. It reports that EMAgnet attains lower exploitability than uniform-magnet PPO under both linear and power-law annealing schedules in the majority of tested environments, with consistent gains on modified benchmarks containing strictly dominated strategies.
Significance. If the empirical comparisons are robust, the work demonstrates that a simple adaptive parameter-space target can outperform a static uniform regularizer in self-play without introducing new hyperparameters beyond the EMA decay rate, offering a practical enhancement to existing policy-gradient methods for large games.
major comments (2)
- [Experiments] Experiments section: the central claim that EMAgnet wins in the majority of environments (including those with strictly dominated strategies) is load-bearing, yet the supplied text provides no quantitative exploitability tables, error bars, number of independent runs, or statistical tests; without these the majority claim cannot be verified.
- [Methods] Methods section: the construction of the modified benchmarks with exploration challenges and strictly dominated strategies is not described in sufficient detail to allow reproduction or to assess whether the performance gains are attributable to the EMA target rather than benchmark-specific artifacts.
minor comments (2)
- [Abstract] Abstract: the phrase 'majority of tested environments' would be strengthened by stating the total number of environments and the exact count on which EMAgnet improved.
- [Method] Notation: the EMA update rule for policy parameters should be written explicitly with the decay factor to distinguish it from the uniform-magnet baseline.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We agree that the experimental claims require stronger quantitative support and that the benchmark modifications need clearer documentation for reproducibility. We will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Experiments] Experiments section: the central claim that EMAgnet wins in the majority of environments (including those with strictly dominated strategies) is load-bearing, yet the supplied text provides no quantitative exploitability tables, error bars, number of independent runs, or statistical tests; without these the majority claim cannot be verified.
Authors: We agree that the current presentation lacks the necessary quantitative details. In the revised version we will add full exploitability tables reporting mean values and standard deviations across independent runs (minimum 5 seeds per environment), error bars on all plots, and statistical tests (e.g., paired t-tests or Wilcoxon tests) comparing EMAgnet against uniform-magnet PPO under both annealing schedules. These additions will directly substantiate the majority-win claim. revision: yes
-
Referee: [Methods] Methods section: the construction of the modified benchmarks with exploration challenges and strictly dominated strategies is not described in sufficient detail to allow reproduction or to assess whether the performance gains are attributable to the EMA target rather than benchmark-specific artifacts.
Authors: We acknowledge the need for greater detail. The revised Methods section will explicitly describe the benchmark modifications: for each game we will list the added dominated actions, their payoff structure, and the precise mechanism used to create exploration challenges (e.g., reward scaling or action masking). This will enable reproduction and allow readers to evaluate whether observed gains stem from the adaptive EMA target. revision: yes
Circularity Check
No significant circularity
full rationale
The paper introduces EMAgnet as an empirical regularization technique in PPO self-play and reports comparative exploitability results across environments. No derivation chain, equations, or first-principles claims are present; the method is defined by a hyper-parameter choice (EMA of policy parameters) whose performance is tested directly against uniform regularization baselines under matched annealing schedules. The central claim is therefore an experimental outcome rather than a reduction of any prediction to fitted inputs or self-citations. No load-bearing self-citation, ansatz smuggling, or renaming of known results occurs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Dota 2 with large scale deep reinforcement learning
Christopher Berner, Greg Brockman, Brooke Chan, Vicki Cheung, et al. Dota 2 with large scale deep reinforcement learning. arXiv preprint arXiv:1912.06680, 2019
Pith/arXiv arXiv 1912
-
[2]
George W. Brown. Iterative solution of games by fictitious play. In T. C. Koopmans, editor, Activity Analysis of Production and Allocation . Wiley, New York, 1951
1951
-
[3]
Superhuman AI for heads-up no-limit poker: Libratus beats top professionals
Noam Brown and Tuomas Sandholm. Superhuman AI for heads-up no-limit poker: Libratus beats top professionals. Science, 359(6374):418–424, 2018. 6 EMA GNET
2018
-
[4]
Combining deep reinforce- ment learning and search for imperfect-information games
Noam Brown, Anton Bakhtin, Adam Lerer, and Qucheng Gong. Combining deep reinforce- ment learning and search for imperfect-information games. InAdvances in Neural Information Processing Systems, volume 33, pages 17057–17069, 2020
2020
-
[5]
Enhancing robustness in multi-agent reinforcement learn- ing via temporal consistency regularization: A self-distillation framework
Huang Chen and MingJun Dai. Enhancing robustness in multi-agent reinforcement learn- ing via temporal consistency regularization: A self-distillation framework. Knowledge-Based Systems, page 115940, 2026
2026
-
[6]
V ortices instead of equilibria in minmax opti- mization: Chaos and butterfly effects of online learning in zero-sum games
Yun Kuen Cheung and Georgios Piliouras. V ortices instead of equilibria in minmax opti- mization: Chaos and butterfly effects of online learning in zero-sum games. In Proceedings of the Thirty-Second Conference on Learning Theory , volume 99 of Proceedings of Machine Learning Research, pages 807–834. PMLR, 2019
2019
-
[7]
Deep reinforcement learning from self-play in imperfect- information games, 2016
Johannes Heinrich and David Silver. Deep reinforcement learning from self-play in imperfect- information games, 2016
2016
-
[8]
Neural replicator dynamics: Multiagent learning via hedging policy gradients
Daniel Hennes, Dustin Morrill, Shayegan Omidshafiei, R ´emi Munos, Julien Perolat, Marc Lanctot, Audrunas Gruslys, Jean-Baptiste Lespiau, Paavo Parmas, Edgar Du ´e˜nez-Guzm´an, et al. Neural replicator dynamics: Multiagent learning via hedging policy gradients. In Pro- ceedings of the 19th International Conference on Autonomous Agents and Multiagent Syste...
2020
-
[9]
Averaging weights leads to wider optima and better generalization
Pavel Izmailov, Dmitrii Podoprikhin, Timur Garipov, Dmitry Vetrov, and Andrew Gordon Wilson. Averaging weights leads to wider optima and better generalization. arXiv preprint arXiv:1803.05407, 2018
Pith/arXiv arXiv 2018
-
[10]
A unified game-theoretic approach to multiagent reinforcement learning
Marc Lanctot, Vinicius Zambaldi, Audrunas Gruslys, Angeliki Lazaridou, Karl Tuyls, Julien Perolat, David Silver, and Thore Graepel. A unified game-theoretic approach to multiagent reinforcement learning. In Advances in Neural Information Processing Systems , volume 30, 2017
2017
-
[12]
URL http://arxiv.org/abs/1908.09453
arXiv 1908
-
[13]
Data-augmented game starts for accelerating self-play exploration in imperfect information games
JB Lanier, Nathan Monette, Pierre Baldi, and Roy Fox. Data-augmented game starts for accelerating self-play exploration in imperfect information games. preprint, 2026
2026
-
[14]
Slow and steady wins the race: Maintaining plasticity with hare and tortoise networks
Hojoon Lee, Hyeonseo Cho, Hyunseung Kim, Donghu Kim, Dugki Min, Jaegul Choo, and Clare Lyle. Slow and steady wins the race: Maintaining plasticity with hare and tortoise networks. arXiv preprint arXiv:2406.02596, 2024
arXiv 2024
-
[15]
Continuous control with deep reinforcement learning, September 15 2020
Timothy Paul Lillicrap, Jonathan James Hunt, Alexander Pritzel, Nicolas Manfred Otto Heess, Tom Erez, Yuval Tassa, David Silver, and Daniel Pieter Wierstra. Continuous control with deep reinforcement learning, September 15 2020. US Patent 10,776,692. 7 EMA GNET
2020
-
[16]
NeuPL: Neural population learning
Siqi Liu, Luke Marris, Daniel Hennes, Josh Merel, Nicolas Heess, and Thore Graepel. NeuPL: Neural population learning. In International Conference on Learning Representations , 2022
2022
-
[17]
Pipeline PSRO: A scalable approach for finding approximate Nash equilibria in large games
Stephen McAleer, John Banister Lanier, Roy Fox, and Pierre Baldi. Pipeline PSRO: A scalable approach for finding approximate Nash equilibria in large games. In Advances in Neural Information Processing Systems, volume 33, pages 20238–20248, 2020
2020
-
[18]
Wang, Pierre Baldi, Tuomas Sandholm, and Roy Fox
Stephen McAleer, John Banister Lanier, Kevin A. Wang, Pierre Baldi, Tuomas Sandholm, and Roy Fox. Toward optimal policy population growth in two-player zero-sum games. In International Conference on Learning Representations , 2024
2024
-
[19]
Wang, Pierre Baldi, and Roy Fox
Stephen Marcus McAleer, John Banister Lanier, Kevin A. Wang, Pierre Baldi, and Roy Fox. XDO: A double oracle algorithm for extensive-form games. In Advances in Neural Informa- tion Processing Systems, 2021
2021
-
[20]
Escher: Eschewing importance sampling in games by computing a history value function to estimate regret
Stephen Marcus McAleer, Gabriele Farina, Marc Lanctot, and Tuomas Sandholm. Escher: Eschewing importance sampling in games by computing a history value function to estimate regret. In The Eleventh International Conference on Learning Representations , 2023
2023
-
[21]
Exponential moving average of weights in deep learning: Dynamics and benefits
Daniel Morales-Brotons, Thijs V ogels, and Hadrien Hendrikx. Exponential moving average of weights in deep learning: Dynamics and benefits. arXiv preprint arXiv:2411.18704, 2024
arXiv 2024
-
[22]
Connor, Neil Burch, Thomas Anthony, Stephen McAleer, Romuald Elie, Sarah H
Julien P ´erolat, Bart De Vylder, Daniel Hennes, Eugene Tarassov, Florian Strub, Vincent de Boer, Paul Muller, Jerome T. Connor, Neil Burch, Thomas Anthony, Stephen McAleer, Romuald Elie, Sarah H. Cen, Zhe Wang, Audrunas Gruslys, Aleksandra Malysheva, Mina Khan, Sherjil Ozair, Finbarr Timbers, Tobias Pohlen, Tom Eccles, Mark Rowland, Marc Lanc- tot, Jean-...
2022
-
[23]
Warp: On the benefits of weight averaged rewarded policies.arXiv preprint arXiv:2406.16768, 2024
Alexandre Ram ´e, Johan Ferret, Nino Vieillard, Robert Dadashi, L ´eonard Hussenot, Pierre- Louis Cedoz, Pier Giuseppe Sessa, Sertan Girgin, Arthur Douillard, and Olivier Bachem. Warp: On the benefits of weight averaged rewarded policies.arXiv preprint arXiv:2406.16768, 2024
arXiv 2024
-
[24]
Zico Kolter, Amy Zhang, Gabriele Farina, Eugene Vinitsky, and Samuel Sokota
Max Rudolph, Nathan Lichtle, Sobhan Mohammadpour, Alexandre Bayen, J. Zico Kolter, Amy Zhang, Gabriele Farina, Eugene Vinitsky, and Samuel Sokota. Reevaluating policy gra- dient methods for imperfect-information games. In International Conference on Learning Representations (ICLR), 2026
2026
-
[25]
Proximal policy optimization algorithms, 2017
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms, 2017
2017
-
[26]
A unified approach to reinforcement learning, quantal response equilibria, and two-player zero-sum games
Samuel Sokota, Ryan D’Orazio, J Zico Kolter, Nicolas Loizou, Marc Lanctot, Ioannis Mitliagkas, Noam Brown, and Christian Kroer. A unified approach to reinforcement learning, quantal response equilibria, and two-player zero-sum games. In The Eleventh International Conference on Learning Representations, 2023. 8 EMA GNET
2023
-
[27]
Zico Kolter, and Gabriele Farina
Samuel Sokota, Eugene Vinitsky, Hengyuan Hu, J. Zico Kolter, and Gabriele Farina. Superhu- man ai for stratego using self-play reinforcement learning and test-time search. arXiv preprint arXiv:2511.07312, 2025
arXiv 2025
-
[28]
DREAM: Deep regret minimization with advantage baselines and model-free learning, 2020
Eric Steinberger, Adam Lerer, and Noam Brown. DREAM: Deep regret minimization with advantage baselines and model-free learning, 2020
2020
-
[29]
Czarnecki, et al
Oriol Vinyals, Igor Babuschkin, Wojciech M. Czarnecki, et al. Grandmaster level in starcraft ii using multi-agent reinforcement learning. Nature, 575:350–354, 2019
2019
-
[30]
Model soups: averaging weights of multiple fine-tuned models improves accuracy without increasing inference time
Mitchell Wortsman, Gabriel Ilharco, Samir Ya Gadre, Rebecca Roelofs, Raphael Gontijo- Lopes, Ari S Morcos, Hongseok Namkoong, Ali Farhadi, Yair Carmon, Simon Kornblith, et al. Model soups: averaging weights of multiple fine-tuned models improves accuracy without increasing inference time. In International conference on machine learning , pages 23965– 2399...
2022
-
[31]
Ema policy gradient: Taming reinforcement learning for llms with ema anchor and top-k kl
Lunjun Zhang and Jimmy Ba. Ema policy gradient: Taming reinforcement learning for llms with ema anchor and top-k kl. arXiv preprint arXiv:2602.04417, 2026. Appendix A. Related Work A.1. Two-Player Zero-Sum Game Solving A central challenge in two-player zero-sum imperfect-information games is that naive self-play with policy gradient methods can cycle or d...
arXiv 2026
-
[32]
and ESCHER [19] adapt counterfactual regret minimization to function approximation. A third family of regularized policy-gradient methods, including NeuRD [8], R-NaD [21], and magnetic mirror descent [MMD, 25], stabilizes last-iterate convergence through explicit regularization terms in the policy objective. Our work builds on this last family, proposing ...
-
[33]
model soups
takes a different approach, regularizing via reward shaping toward a periodically updated ref- erence policy. At scale, DeepNash gradually transitions between regularization targets using linear interpolation and uses an EMA of the policy parameters to approximate fixed points. However, the regularization targets themselves remain discrete snapshots set a...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.