AutoSpec: Safety Rule Evolution for LLM Agents via Inductive Logic Programming
Pith reviewed 2026-06-25 23:15 UTC · model grok-4.3
The pith
AutoSpec evolves expert safety rules for LLM agents by using inductive logic programming to guide edits from user annotations on execution traces.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
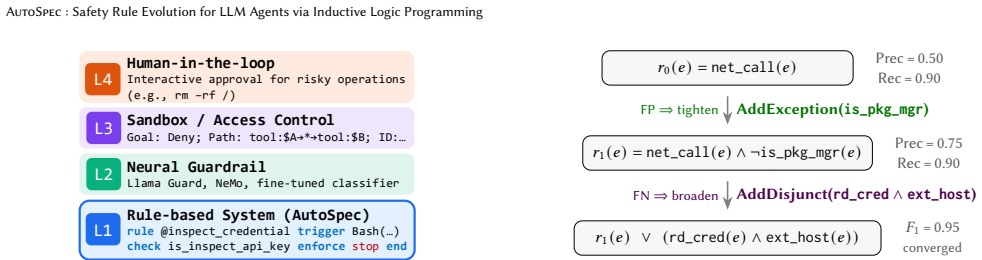
AutoSpec iteratively evaluates current rules against annotated traces, mines false-positive and false-negative counterexamples, uses ILP to identify predicates that appear frequently in one error type but rarely in the other, generates candidate rule edits from those predicates, verifies the candidates, and adopts the revision that best improves the precision-recall balance until the rule set converges.
What carries the argument
Inductive logic programming (ILP) inside counterexample-guided inductive synthesis (CEGIS), which extracts discriminating predicates to prune the search over possible rule modifications.
If this is right
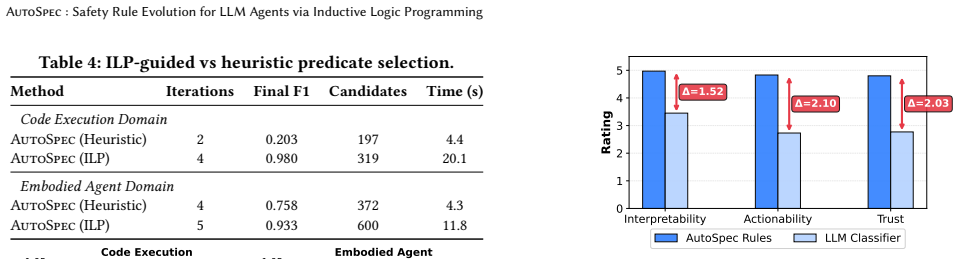
- Rule F1 reaches 0.98 on code execution traces and 0.93 on embodied agent traces.
- False positive rates fall by as much as 94 percent while recall remains high.
- The refinement process converges after 4-5 iterations on the tested domains.
- The ILP-guided search produces up to 4.8 times higher F1 than heuristic CEGIS without ILP.
- The final rules stay human-readable, auditable, and generalize to unseen traces.
Where Pith is reading between the lines
- The same annotation-plus-ILP loop could be applied to evolve safety constraints in other rule-based autonomous systems such as robotic planners.
- If collecting user labels proves expensive, the method could be paired with active learning to choose which traces most need annotation.
- Extending the predicate vocabulary automatically from new traces might allow the system to handle domains where the initial set of predicates is insufficient.
- Continuous logging of agent traces combined with occasional user labels could keep rules current without requiring periodic full redesigns.
Load-bearing premise
The framework assumes that the stream of user-provided safe/unsafe annotations on execution traces is sufficiently accurate and representative to drive reliable rule edits, and that the available predicate vocabulary can discriminate the counterexamples.
What would settle it
Supplying the system with systematically noisy or non-representative annotations and checking whether rule F1 stops improving or declines would test whether the annotation-driven ILP process actually produces better rules.
Figures



read the original abstract
Large language model (LLM) agents increasingly automate complex tasks by integrating language models with external tools and environments. However, their autonomy poses significant safety risks: agents may execute destructive commands, leak sensitive data, or violate domain constraints. Existing safety approaches face a fundamental tradeoff: hand-crafted rules are interpretable but brittle, with overly conservative rules blocking safe operations (high false positives) while permissive rules miss unsafe behaviors (high false negatives). Neural classifiers lack the interpretability required for safety-critical deployments. We present AutoSpec, a framework that automatically evolves deployed expert-designed safety rules from user safe/unsafe annotations through counterexample-guided inductive synthesis (CEGIS) guided by inductive logic programming (ILP). Starting from the expert rules and a stream of annotated traces, AutoSpec iteratively evaluates rules, mines false-positive and false-negative counterexamples, uses ILP to learn which predicates discriminate them, generates candidate rule edits, and verifies candidates to select the best revision. The key insight is that ILP efficiently identifies predicates that appear frequently in false negatives but rarely in false positives (or vice versa), dramatically pruning the exponential search space of rule edits. This continues until convergence, producing interpretable rules that balance precision and recall. We evaluate AutoSpec on 291 execution traces spanning code execution and embodied agent domains. AutoSpec raises rule F1 to 0.98 and 0.93 across the two domains, achieving up to 94% false positive reduction while maintaining high recall, and converges within 4-5 iterations. The ILP-guided approach achieves up to 4.8x higher F1 than heuristic CEGIS. The learned rules are human-readable, auditable, and generalize to unseen scenarios.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces AutoSpec, a framework that evolves expert-designed safety rules for LLM agents via counterexample-guided inductive synthesis (CEGIS) guided by inductive logic programming (ILP). Starting from initial rules and a stream of user-annotated execution traces (safe/unsafe), the method iteratively mines false-positive and false-negative counterexamples, uses ILP to identify discriminating predicates, generates candidate rule edits, and verifies them until convergence. Evaluation on 291 traces across code execution and embodied agent domains reports F1 scores rising to 0.98 and 0.93, up to 94% false-positive reduction with high recall, convergence in 4-5 iterations, and up to 4.8x higher F1 than heuristic CEGIS; the resulting rules are claimed to be human-readable and generalizable.
Significance. If the empirical results are robust, the work is significant for enabling adaptive, interpretable safety mechanisms in autonomous LLM agents without sacrificing auditability. The core technical insight—using ILP to efficiently prune the space of rule edits by identifying predicates that discriminate counterexamples—addresses a key scalability issue in CEGIS for safety rules. The reported gains over baselines and rapid convergence suggest practical value for maintaining safety in evolving agent deployments.
major comments (2)
- [Abstract] Abstract (performance claims paragraph): The headline results (F1=0.98/0.93, 94% FP reduction, 4.8x gain over heuristic CEGIS, 4-5 iteration convergence) are presented without any description of trace collection methodology, the supplied predicate vocabulary, the exact ILP encoding of the rule-edit problem, statistical significance testing, or ablation controls; these omissions make the central empirical claims unverifiable from the provided information.
- [Abstract] Abstract (framework description): The approach assumes that the stream of user-provided safe/unsafe annotations is sufficiently accurate and representative and that the predicate vocabulary can discriminate mined counterexamples, yet no experiments test sensitivity to annotation noise, incomplete predicates, or spurious correlations; if either assumption fails, the ILP step will synthesize edits from noise and the reported improvements will not hold.
minor comments (1)
- [Abstract] The abstract would benefit from one sentence clarifying the two domains' safety constraints or example predicates to help readers assess predicate completeness.
Simulated Author's Rebuttal
We thank the referee for the constructive review and for highlighting areas where the abstract could better support the empirical claims. We respond to each major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract (performance claims paragraph): The headline results (F1=0.98/0.93, 94% FP reduction, 4.8x gain over heuristic CEGIS, 4-5 iteration convergence) are presented without any description of trace collection methodology, the supplied predicate vocabulary, the exact ILP encoding of the rule-edit problem, statistical significance testing, or ablation controls; these omissions make the central empirical claims unverifiable from the provided information.
Authors: We agree that the abstract would be stronger if it supplied minimal context for the headline numbers. The full manuscript already details trace collection (291 user-annotated traces across the two domains), the predicate vocabulary (domain-specific logical predicates defined in Section 3.2), the ILP encoding of rule edits (Section 3.3), statistical significance testing (paired t-tests reported in Section 5), and ablation controls (Section 5). In the revision we will expand the abstract by one sentence to reference these elements concisely (e.g., “evaluated on 291 traces using domain predicates, with ablations and significance tests confirming the ILP contribution”). revision: yes
-
Referee: [Abstract] Abstract (framework description): The approach assumes that the stream of user-provided safe/unsafe annotations is sufficiently accurate and representative and that the predicate vocabulary can discriminate mined counterexamples, yet no experiments test sensitivity to annotation noise, incomplete predicates, or spurious correlations; if either assumption fails, the ILP step will synthesize edits from noise and the reported improvements will not hold.
Authors: The referee correctly notes that the current evaluation does not contain controlled experiments on annotation noise, missing predicates, or spurious correlations. The manuscript relies on the assumption that user annotations are reliable ground truth and that the supplied predicates are sufficiently expressive; the ILP step is intended to mitigate some noise by selecting only discriminating predicates, but this has not been quantified. We will add an explicit limitations paragraph in the revised manuscript acknowledging these assumptions and outlining planned sensitivity analyses as future work. revision: partial
Circularity Check
No significant circularity; empirical metrics derived from external traces
full rationale
The paper presents AutoSpec as an iterative CEGIS+ILP process that consumes user-provided safe/unsafe annotations on execution traces to synthesize rule edits. Reported outcomes (F1 scores of 0.98/0.93, 94% FP reduction, 4-5 iteration convergence, 4.8x gain over heuristic CEGIS) are measured results of running this process on a fixed set of 291 external traces across two domains, with explicit claims of generalization to unseen scenarios. No equations, parameters, or performance quantities are defined in terms of themselves; the ILP step identifies discriminating predicates from the supplied annotations rather than presupposing the final F1 values. No self-citation chains, fitted-input-as-prediction, or ansatz smuggling appear in the described derivation. The evaluation is therefore self-contained against the external trace benchmark.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption User-provided safe/unsafe annotations on traces are treated as ground truth for counterexample mining.
Reference graph
Works this paper leans on
-
[1]
Michael Ahn, Anthony Brohan, Noah Brown, Yevgen Chebotar, Omar Cortes, Byron David, Chelsea Finn, Chuyuan Fu, Keerthana Gopalakrishnan, Karol Hausman, et al. 2022. Do as I can, not as I say: Grounding language in robotic affordances. InConference on robot learning. PMLR, 287–318
2022
-
[2]
Rajeev Alur, Rastislav Bodik, Garvit Juniwal, Milo MK Martin, Mukund Raghothaman, Sanjit A Seshia, Rishabh Singh, Armando Solar-Lezama, Em- ina Torlak, and Abhishek Udupa. 2013. Syntax-guided synthesis. In2013 Formal Methods in Computer-Aided Design. IEEE, 1–8
2013
-
[3]
Yuntao Bai, Saurav Kadavath, Sandipan Kundu, Amanda Askell, Jackson Kernion, Andy Jones, Anna Chen, Anna Goldie, Azalia Mirhoseini, Cameron McKinnon, et al. 2022. Constitutional AI: Harmlessness from AI feedback.arXiv preprint arXiv:2212.08073(2022)
Pith/arXiv arXiv 2022
-
[4]
Peter Clark and Tim Niblett. 1989. The CN2 induction algorithm.Machine learning3, 4, 261–283
1989
-
[5]
William W Cohen. 1995. Fast effective rule induction. InMachine learning proceedings 1995. Elsevier, 115–123
1995
-
[6]
Sirui Hong, Xiawu Zheng, Jonathan Chen, Yuheng Cheng, Jinlin Wang, Ceyao Zhang, Zili Wang, Steven Ka Shing Yau, Zijuan Lin, Liyang Zhou, et al . 2024. MetaGPT: Meta programming for multi-agent collaborative framework. InInter- national Conference on Learning Representations
2024
-
[7]
Xinyi Hou, Yanjie Zhao, Shenao Wang, and Haoyu Wang. 2025. Model Context Protocol (MCP): Landscape, Security Threats, and Future Research Directions. arXiv preprint arXiv:2503.23278(2025)
Pith/arXiv arXiv 2025
-
[8]
Hakan Inan, Kartikeya Upasani, Jianfeng Chi, Rashi Rungta, Krithika Iyer, Yuning Mao, Michael Tontchev, Qing Hu, Brian Fuller, Davide Testuggine, et al. 2023. Llama guard: LLM-based input-output safeguard for human-AI conversations. arXiv preprint arXiv:2312.06674(2023)
Pith/arXiv arXiv 2023
-
[9]
Susmit Jha, Sumit Gulwani, Sanjit A Seshia, and Ashish Tiwari. 2010. Oracle- guided component-based program synthesis. In2010 ACM/IEEE 32nd Interna- tional Conference on Software Engineering, Vol. 1. IEEE, 215–224
2010
-
[10]
Zimo Ji, Daoyuan Wu, Wenyuan Jiang, Pingchuan Ma, Zongjie Li, Yudong Gao, Shuai Wang, and Yingjiu Li. 2026. Taming various privilege escalation in LLM- based agent systems: A mandatory access control framework.arXiv preprint arXiv:2601.11893(2026)
arXiv 2026
-
[11]
Ron Koymans. 1990. Specifying real-time properties with metric temporal logic. Real-time systems2, 4 (1990), 255–299
1990
-
[12]
Mark Law, Alessandra Russo, and Krysia Broda. 2014. The ILASP system for learning answer set programs.arXiv preprint arXiv:1407.3898(2014)
Pith/arXiv arXiv 2014
-
[13]
Martin Leucker and Christian Schallhart. 2009. A brief account of runtime verification.The Journal of Logic and Algebraic Programming78, 5 (2009), 293– 303
2009
-
[14]
Chengquan Li, Zikang Ouyang, Yixin Liu, Yifan Zhao, Jianfeng Huang, Chuyue Xiao, Kaixin Jiang, Yongchao Ding, Sheng Yin, Chao Xu, et al. 2024. RedCode: Risky code execution and generation benchmark for code agents. InNeurIPS 2024 Datasets and Benchmarks Track
2024
-
[15]
Shuyuan Liu, Jiawei Chen, Shouwei Ruan, Hang Su, and Zhaoxia Yin. 2024. Exploring the robustness of decision-level through adversarial attacks on llm- based embodied models. InProceedings of the 32nd ACM international conference on multimedia. 8120–8128
2024
-
[16]
Yi Liu, Gelei Deng, Yuekang Li, Kailong Wang, Zihao Wang, Xiaofeng Wang, Tianwei Zhang, Yepang Liu, Haoyu Wang, Yan Zheng, and Yang Liu. 2023. Prompt Injection attack against LLM-integrated Applications.arXiv preprint arXiv:2306.05499(2023)
Pith/arXiv arXiv 2023
-
[17]
Mahmoud Mohammadi, Yipeng Li, Jane Lo, and Wendy Yip. 2025. Evaluation and benchmarking of llm agents: A survey. InProceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V. 2. 6129–6139
2025
-
[18]
Stephen Muggleton. 1995. Inverse entailment and Progol.New generation computing13, 3-4 (1995), 245–286
1995
-
[19]
Stephen Muggleton and Luc De Raedt. 1994. Inductive logic programming: Theory and methods.The Journal of Logic Programming19 (1994), 629–679
1994
-
[20]
Ethan Perez, Saffron Huang, Francis Song, Trevor Cai, Roman Ring, John Aslanides, Amelia Glaese, Nat McAleese, and Geoffrey Irving. 2022. Red teaming language models with language models. InProceedings of the 2022 Conference on Empirical Methods in Natural Language Processing. 3419–3448
2022
-
[21]
Amir Pnueli. 1977. The temporal logic of programs. In18th Annual Symposium on Foundations of Computer Science (sfcs 1977). IEEE, 46–57
1977
-
[22]
Yewen Pu, Zachery Miranda, Armando Solar-Lezama, and Leslie Kaelbling. 2018. Selecting representative examples for program synthesis. InInternational Con- ference on Machine Learning. PMLR, 4161–4170
2018
-
[23]
Chen Qian, Xin Cong, Cheng Yang, Weize Chen, Yusheng Su, Juyuan Xu, Zhiyuan Liu, and Maosong Sun. 2024. ChatDev: Communicative agents for software development. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics. 608–626
2024
-
[24]
J Ross Quinlan. 1990. Learning logical definitions from relations.Machine learning5, 3 (1990), 239–266
1990
-
[25]
Qibing Ren, Hao Li, Dongrui Liu, Zhanxu Xie, Xiaoya Lu, Yu Qiao, Lei Sha, Junchi Yan, Lizhuang Ma, and Jing Shao. 2025. Llms know their vulnerabilities: Uncover safety gaps through natural distribution shifts. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 24763–24785
2025
-
[26]
Yangjun Ruan, Honghua Dong, Andrew Wang, Silviu Pitis, Yongchao Zhou, Jimmy Ba, Yann Dubois, Chris J Maddison, and Tatsunori Hashimoto. 2024. Identifying the risks of LM agents with an LM-emulated sandbox. InInternational Conference on Learning Representations
2024
-
[27]
Timo Schick, Jane Dwivedi-Yu, Roberto Dessì, Roberta Raileanu, Maria Lomeli, Luke Zettlemoyer, Nicola Cancedda, and Thomas Scialom. 2023. Toolformer: Lan- guage models can teach themselves to use tools.arXiv preprint arXiv:2302.04761 (2023)
Pith/arXiv arXiv 2023
-
[28]
Md Shamsujjoha, Qinghua Lu, Dehai Zhao, and Liming Zhu. 2024. Swiss Cheese Model for AI Safety: A Taxonomy and Reference Architecture for Multi-Layered Guardrails of Foundation Model Based Agents.arXiv preprint arXiv:2408.02205 (2024)
arXiv 2024
-
[29]
Tianneng Shi, Jingxuan He, Zhun Wang, Hongwei Li, Linyu Wu, Wenbo Guo, and Dawn Song. 2025. Progent: Programmable privilege control for LLM agents. arXiv preprint arXiv:2504.11703(2025)
Pith/arXiv arXiv 2025
-
[30]
Armando Solar-Lezama, Liviu Tancau, Rastislav Bodik, Sanjit Seshia, and Vijay Saraswat. 2006. Combinatorial sketching for finite programs. InACM SIGPLAN Notices, Vol. 41. ACM, 404–415
2006
-
[31]
Ashwin Srinivasan. 2001. The Aleph manual.Machine Learning at the Computing Laboratory, Oxford University(2001)
2001
-
[32]
Eric Wallace, Shi Feng, Nikhil Kandpal, Matt Gardner, and Sameer Singh. 2019. Universal adversarial triggers for attacking and analyzing NLP. InProceedings of the 2019 Conference on Empirical Methods in Natural Language Processing. 2153–2162
2019
-
[33]
Haoyu Wang, Christopher M Poskitt, and Jun Sun. 2025. AgentSpec: Customiz- able Runtime Enforcement for Safe and Reliable LLM Agents.arXiv preprint arXiv:2503.18666(2025)
Pith/arXiv arXiv 2025
-
[34]
Poskitt, Jun Sun, and Jiali Wei
Haoyu Wang, Chris M. Poskitt, Jun Sun, and Jiali Wei. 2025. Pro2Guard: Proactive Runtime Enforcement of LLM Agent Safety via Probabilistic Model Checking. arXiv preprint arXiv:2508.00500(2025)
arXiv 2025
-
[35]
Licheng Wen, Daocheng Fu, Xin Li, Xinyu Cai, Tao Ma, Pinlong Cai, Min Dou, Botian Shi, Liang He, and Yu Qiao. 2023. DiLu: A knowledge-driven approach to autonomous driving with large language models.arXiv preprint arXiv:2309.16292 (2023)
arXiv 2023
-
[36]
Zhiheng Xi, Wenxiang Chen, Xin Guo, Wei He, Yiwen Ding, Boyang Hong, Ming Zhang, Junzhe Wang, Senjie Jin, Enyu Zhou, et al. 2023. The rise and potential of large language model based agents: A survey.arXiv preprint arXiv:2309.07864 (2023)
Pith/arXiv arXiv 2023
-
[37]
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. 2023. ReAct: Synergizing reasoning and acting in language models. InInternational Conference on Learning Representations
2023
-
[38]
Sheng Yin, Xianghe Hu, Qi Qi, Jing Hu, Chao Xu, and Haifeng Zhang. 2024. SafeAgentBench: A benchmark for safe task planning of embodied LLM agents. InarXiv preprint arXiv:2410.17359
arXiv 2024
-
[39]
Tongxin Yuan, Zhiwei He, Lingzhong Dong, Yiming Wang, Ruijie Zhao, Tian Xia, Lizhen Xu, Binglin Zhou, Fangqi Li, Zhuosheng Zhang, et al. 2024. R-judge: Benchmarking safety risk awareness for llm agents. InFindings of the Association Ma et al. for Computational Linguistics: EMNLP 2024. 1467–1490
2024
-
[40]
Tongxin Yuan, Zhiwei He, Lingzhong Dong, Yiming Wang, Ruijie Zhao, Tian Xia, Lizhen Xu, Binglin Zhou, Fangqi Liang, Zhuosheng Han, et al . 2024. R- Judge: Benchmarking safety risk awareness for LLM agents. InFindings of the Association for Computational Linguistics: EMNLP 2024
2024
-
[41]
Kaiyuan Zhang, Zian Su, Pin-Yu Chen, Elisa Bertino, Xiangyu Zhang, and Ninghui Li. 2025. LLM Agents Should Employ Security Principles.arXiv preprint arXiv:2505.24019(2025)
arXiv 2025
-
[42]
Shaokun Zhang, Ming Yin, Jieyu Zhang, Jiale Liu, Zhiguang Han, Jingyang Zhang, Beibin Li, Chi Wang, Huazheng Wang, Yiran Chen, and Qingyun Wu
-
[43]
InForty-second International Conference on Machine Learning
Which Agent Causes Task Failures and When? On Automated Failure Attribution of LLM Multi-Agent Systems. InForty-second International Conference on Machine Learning. https://openreview.net/forum?id=GazlTYxZss
-
[44]
Yedi Zhang, Yufan Cai, Xinyue Zuo, Xiaokun Luan, Kailong Wang, Zhe Hou, Yifan Zhang, Zhiyuan Wei, Meng Sun, Jun Sun, Jing Sun, and Jin Song Dong. 2024. The Fusion of Large Language Models and Formal Methods for Trustworthy AI Agents: A Roadmap.arXiv preprint arXiv:2412.06512(2024)
arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.