G³VLA: Geometric inductive bias for Vision-Language-Action Models
Pith reviewed 2026-06-26 00:07 UTC · model grok-4.3
The pith
Injecting calibrated camera geometry into VLA visual tokens improves performance on spatial robot tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
G³VLA is a camera-aware geometric module that injects calibrated structure into the visual-token stream of a pretrained VLA using intrinsic-conditioned ray embeddings, projective positional encoding (PRoPE), and bidirectional cross-view fusion. Geometric supervision is supplied either from ground-truth point maps or from confidence-gated π³X teacher predictions. When instantiated on π₀ and tested on π_{0.5} and GR00T 1.5, the module yields consistent gains across simulation suites and real-robot settings, with the largest improvements on spatially and object-sensitive tasks, and with geometry-aware tokens proving most effective when they reach the action generation pathway directly.
What carries the argument
The G³VLA module that supplies geometric inductive bias through ray embeddings conditioned on camera intrinsics, PRoPE, and bidirectional cross-view fusion added to the visual token stream.
If this is right
- Consistent performance gains appear across LIBERO suites, RoboCasa24, RoboTwin2.0, and real-robot settings.
- The largest improvements occur on tasks that depend on spatial relations and object sensitivity.
- Geometry-aware tokens produce the strongest effect when they have direct access to the action generation pathway.
- The same module transfers across different VLA backbones including π₀, π_{0.5}, and GR00T 1.5.
Where Pith is reading between the lines
- The same geometric token injection could be tested on non-robotic vision-language models that process calibrated multi-view imagery.
- Replacing ground-truth points entirely with teacher predictions may allow the method to scale to settings where depth data are unavailable.
- Combining the module with other forms of structured bias could further reduce data requirements for spatial generalization.
- Evaluating the approach on longer-horizon tasks would reveal whether the geometric signal also aids planning beyond single-step manipulation.
Load-bearing premise
The geometric supervision signal from point maps or predictions is accurate enough to integrate with the pretrained VLA token stream without harming the imitation objective.
What would settle it
Adding the G³VLA module to a VLA baseline and observing no gain or a clear drop in success rate on spatially demanding manipulation tasks in controlled multi-camera experiments would falsify the central claim.
Figures







read the original abstract
Vision-language-action (VLA) models have made rapid progress in generalist robot manipulation by harnessing semantic knowledge from pretrained vision-language backbones, but their visual tokens remain grounded in 2D image coordinates rather than the calibrated geometry of the robot's cameras -- a mismatch especially pronounced in multi-camera setups, where views are coupled by known intrinsics and extrinsics yet processed as independent images. We propose G$^3$VLA, a camera-aware geometric module that injects calibrated structure into the visual-token stream of a pretrained VLA without altering its action space or imitation objective, combining intrinsic-conditioned ray embeddings, projective positional encoding (PRoPE), and bidirectional cross-view fusion. Geometric supervision is provided either from ground-truth point maps when available, or from confidence-gated $\pi^3$X teacher predictions, requiring no depth sensors or manual annotations. Instantiated on $\pi_0$, G$^3$VLA yields consistent gains across the LIBERO suites, RoboCasa24, RoboTwin2.0, and real-robot settings, with the largest improvements on spatially and object-sensitive tasks. We further validate on $\pi_{0.5}$ and GR00T 1.5, with results suggesting that geometric transfer is most effective when geometry-aware tokens have direct access to the action generation pathway. Our project page is at https://sites.google.com/view/g3vla
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces G³VLA, a camera-aware geometric module added to pretrained vision-language-action models. It combines intrinsic-conditioned ray embeddings, projective positional encoding (PRoPE), and bidirectional cross-view fusion to inject calibrated 3D structure into the visual token stream without changing the action space or imitation objective. Geometric supervision comes from ground-truth point maps or confidence-gated π³X predictions. When instantiated on π₀ (and tested on π₀.₅ and GR00T 1.5), the method reports consistent gains on LIBERO suites, RoboCasa24, RoboTwin2.0, and real-robot tasks, with largest improvements on spatially and object-sensitive tasks.
Significance. If the reported gains hold under rigorous controls, the work demonstrates a practical route for adding geometric inductive bias to existing VLA token streams via optional external supervision, which could improve spatial reasoning in multi-camera robot manipulation without retraining the core policy.
major comments (2)
- [Abstract and §4] The abstract and architecture description provide no quantitative results, baseline comparisons, ablation studies, or statistical significance tests for the claimed gains; without these in the main text or appendix, it is impossible to evaluate whether the geometric module produces additive improvements beyond what could be obtained by other token-level modifications.
- [§5] The claim that geometric transfer is 'most effective when geometry-aware tokens have direct access to the action generation pathway' (§5) is presented as a suggestion from results on π₀.₅ and GR00T 1.5, but no controlled comparison isolating the access pathway (e.g., via frozen vs. unfrozen fusion layers) is described, leaving the causal link unsupported.
minor comments (2)
- [§3] Notation for PRoPE and ray embeddings should be defined with explicit equations in §3 before describing their integration with the VLA token stream.
- [Abstract] The project page URL is given but no link to code or model checkpoints is provided, which would aid reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the two major comments below and will revise the manuscript to strengthen the presentation of results and causal claims.
read point-by-point responses
-
Referee: [Abstract and §4] The abstract and architecture description provide no quantitative results, baseline comparisons, ablation studies, or statistical significance tests for the claimed gains; without these in the main text or appendix, it is impossible to evaluate whether the geometric module produces additive improvements beyond what could be obtained by other token-level modifications.
Authors: We agree the abstract lacks specific numbers and that §4 (architecture) does not reference quantitative validation. In revision we will (i) update the abstract with key success-rate deltas on LIBERO, RoboCasa24 and real-robot tasks plus mention of ablations, (ii) add a short paragraph in §4 summarizing the experimental controls and statistical tests reported in §5 and the appendix, and (iii) ensure all baseline comparisons include significance markers. These changes will make the additive benefit of the geometric module explicit without altering the technical claims. revision: yes
-
Referee: [§5] The claim that geometric transfer is 'most effective when geometry-aware tokens have direct access to the action generation pathway' (§5) is presented as a suggestion from results on π₀.₅ and GR00T 1.5, but no controlled comparison isolating the access pathway (e.g., via frozen vs. unfrozen fusion layers) is described, leaving the causal link unsupported.
Authors: The current text draws the claim from observed performance gaps when the geometric module is attached to different VLA backbones, but we acknowledge the absence of an explicit frozen-vs-unfrozen ablation isolating the pathway. We will add this controlled experiment (freezing the cross-view fusion layers while keeping the rest of the policy trainable) to §5 and the appendix, allowing a direct test of the causal hypothesis. revision: yes
Circularity Check
No significant circularity
full rationale
The paper introduces an additive geometric module (ray embeddings + PRoPE + cross-view fusion) to a pretrained VLA token stream, with supervision drawn from independent external sources (ground-truth point maps or gated teacher predictions). No equations, derivations, or load-bearing steps reduce the reported empirical gains to fitted parameters, self-definitions, or self-citation chains. The imitation objective and action space remain unchanged, and performance improvements are validated across multiple external benchmarks without internal reduction to the inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Pretrained VLA models can accept additional geometric tokens in the visual stream without retraining or changing the action head or imitation loss.
Reference graph
Works this paper leans on
-
[1]
Zitkovich, T
B. Zitkovich, T. Yu, S. Xu, P. Xu, T. Xiao, F. Xia, J. Wu, P. Wohlhart, S. Welker, A. Wahid, Q. Vuong, V . Vanhoucke, H. Tran, R. Soricut, A. Singh, J. Singh, P. Sermanet, P. R. San- keti, G. Salazar, M. S. Ryoo, K. Reymann, K. Rao, K. Pertsch, I. Mordatch, H. Michalewski, Y . Lu, S. Levine, L. Lee, T.-W. E. Lee, I. Leal, Y . Kuang, D. Kalashnikov, R. Jul...
2023
-
[2]
M. J. Kim, K. Pertsch, S. Karamcheti, T. Xiao, A. Balakrishna, S. Nair, R. Rafailov, E. Foster, G. Lam, P. Sanketi, Q. Vuong, T. Kollar, B. Burchfiel, R. Tedrake, D. Sadigh, S. Levine, P. Liang, and C. Finn. OpenVLA: An open-source vision-language-action model.arXiv preprint arXiv:2406.09246, 2024. doi:10.48550/arXiv.2406.09246. URLhttps://arxiv. org/abs/...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2406.09246 2024
-
[3]
Black, N
K. Black, N. Brown, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusai, L. Groom, K. Haus- man, B. Ichter, S. Jakubczak, T. Jones, L. Ke, S. Levine, A. Li-Bell, M. Mothukuri, S. Nair, K. Pertsch, L. X. Shi, J. Tanner, Q. Vuong, A. Walling, H. Wang, and U. Zhilin- sky.π 0: A vision-language-action flow model for general robot control. InProceedings of Roboti...
2025
-
[4]
J. Bjorck, F. Casta ˜neda, N. Cherniadev, X. Da, R. Ding, L. Fan, Y . Fang, D. Fox, F. Hu, S. Huang, et al. Gr00t n1: An open foundation model for generalist humanoid robots.arXiv preprint arXiv:2503.14734, 2025
Pith/arXiv arXiv 2025
-
[5]
Shridhar, L
M. Shridhar, L. Manuelli, and D. Fox. Perceiver-actor: A multi-task transformer for robotic manipulation. InProceedings of The 6th Conference on Robot Learning, volume 205 of Proceedings of Machine Learning Research, pages 785–799. PMLR, 2023. URLhttps: //proceedings.mlr.press/v205/shridhar23a.html
2023
-
[6]
Goyal, J
A. Goyal, J. Xu, Y . Guo, V . Blukis, Y .-W. Chao, and D. Fox. RVT: Robotic view transformer for 3d object manipulation. InProceedings of The 7th Conference on Robot Learning, volume 229 ofProceedings of Machine Learning Research, pages 694–710. PMLR, 2023. URLhttps: //proceedings.mlr.press/v229/goyal23a.html
2023
-
[7]
Gervet, Z
T. Gervet, Z. Xian, N. Gkanatsios, and K. Fragkiadaki. Act3D: 3d feature field transformers for multi-task robotic manipulation. InProceedings of The 7th Conference on Robot Learning, volume 229 ofProceedings of Machine Learning Research, pages 3949–3965. PMLR, 2023. URLhttps://proceedings.mlr.press/v229/gervet23a.html
2023
-
[8]
D. Qu, H. Song, Q. Chen, Y . Yao, X. Ye, Y . Ding, Z. Wang, J. Gu, B. Zhao, D. Wang, and X. Li. SpatialVLA: Exploring spatial representations for visual-language-action model.arXiv preprint arXiv:2501.15830, 2025. doi:10.48550/arXiv.2501.15830. URLhttps://arxiv. org/abs/2501.15830. 9
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2501.15830 2025
-
[9]
H. Zhen, X. Qiu, P. Chen, J. Yang, X. Yan, Y . Du, Y . Hong, and C. Gan. 3D-VLA: A 3d vision-language-action generative world model.arXiv preprint arXiv:2403.09631, 2024. doi: 10.48550/arXiv.2403.09631. URLhttps://arxiv.org/abs/2403.09631
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2403.09631 2024
-
[10]
Zhang, A
J. Zhang, A. Lin, M. Kumar, T.-H. Yang, D. Ramanan, and S. Tulsiani. Cameras as rays: Pose estimation via ray diffusion. InInternational Conference on Learning Representations, volume 2024, pages 23345–23366, 2024
2024
-
[11]
R. Li, B. Yi, J. Liu, H. Gao, Y . Ma, and A. Kanazawa. Cameras as relative positional encoding. InAdvances in Neural Information Processing Systems, vol- ume 38, 2025. URLhttps://papers.neurips.cc/paper_files/paper/2025/hash/ 17a7075094632c88cccdd86270ad715b-Abstract-Conference.html
2025
-
[12]
Y . Wang, J. Zhou, H. Zhu, W. Chang, Y . Zhou, Z. Li, J. Chen, J. Pang, C. Shen, and T. He.π3: Permutation-equivariant visual geometry learning.arXiv preprint arXiv:2507.13347, 2025. doi:10.48550/arXiv.2507.13347. URLhttps://arxiv.org/abs/2507.13347
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2507.13347 2025
-
[13]
A. Brohan, N. Brown, J. Carbajal, Y . Chebotar, J. Dabis, C. Finn, K. Gopalakrishnan, K. Haus- man, et al. RT-1: Robotics transformer for real-world control at scale. InProceedings of Robotics: Science and Systems, Daegu, Republic of Korea, 2023. doi:10.15607/RSS.2023. XIX.025. URLhttps://roboticsproceedings.org/rss19/p025.html
-
[14]
$\pi_{0.5}$: a Vision-Language-Action Model with Open-World Generalization
Physical Intelligence, K. Black, N. Brown, J. Darpinian, K. Dhabalia, D. Driess, A. Esmail, M. Equi, C. Finn, et al.π 0.5: A vision-language-action model with open-world generalization. arXiv preprint arXiv:2504.16054, 2025. doi:10.48550/arXiv.2504.16054. URLhttps:// arxiv.org/abs/2504.16054
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2504.16054 2025
-
[15]
S. Chen, R. G. Pinel, C. Schmid, and I. Laptev. PolarNet: 3d point clouds for language-guided robotic manipulation. InProceedings of The 7th Conference on Robot Learning, volume 229 ofProceedings of Machine Learning Research, pages 1761–1781. PMLR, 2023. URLhttps: //proceedings.mlr.press/v229/chen23b.html
2023
-
[16]
T.-W. Ke, N. Gkanatsios, and K. Fragkiadaki. 3D diffuser actor: Policy diffusion with 3D scene representations. InProceedings of the 8th Conference on Robot Learning (CoRL), volume 270 ofProceedings of Machine Learning Research, pages 1949–1974. PMLR, 2024
1949
-
[17]
B. Chen, Z. Xu, S. Kirmani, B. Ichter, D. Sadigh, L. Guibas, and F. Xia. SpatialVLM: Endowing vision-language models with spatial reasoning capabilities. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 14455– 14465, 2024. URLhttps://openaccess.thecvf.com/content/CVPR2024/html/ Chen_SpatialVLM_Endowing_Vision-Lang...
2024
-
[18]
X. Li, L. Heng, J. Liu, Y . Shen, C. Gu, Z. Liu, H. Chen, N. Han, R. Zhang, H. Tang, S. Zhang, and H. Dong. 3DS-VLA: A 3d spatial-aware vision language action model for robust multi- task manipulation. InProceedings of The 9th Conference on Robot Learning, volume 305 of Proceedings of Machine Learning Research, pages 2344–2359. PMLR, 2025. URLhttps: //pro...
2025
-
[19]
S. Wang, V . Leroy, Y . Cabon, B. Chidlovskii, and J. Revaud. DUSt3R: Geometric 3D vision made easy. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 20697–20709, 2024
2024
-
[20]
J. Wang, M. Chen, N. Karaev, A. Vedaldi, C. Rupprecht, and D. Novotny. VGGT: Visual geometry grounded transformer. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2025. 10
2025
-
[21]
A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. De- hghani, M. Minderer, G. Heigold, S. Gelly, et al. An image is worth 16x16 words: Transform- ers for image recognition at scale.arXiv preprint arXiv:2010.11929, 2020
Pith/arXiv arXiv 2010
-
[22]
X. Zhai, B. Mustafa, A. Kolesnikov, and L. Beyer. Sigmoid loss for language image pre- training. InProceedings of the IEEE/CVF international conference on computer vision, pages 11975–11986, 2023
2023
-
[23]
B. Liu, Y . Zhu, C. Gao, Y . Feng, Q. Liu, Y . Zhu, and P. Stone. LIBERO: Bench- marking knowledge transfer for lifelong robot learning. InAdvances in Neural In- formation Processing Systems, volume 36, pages 44776–44791. Curran Associates, Inc.,
-
[24]
URLhttps://proceedings.neurips.cc/paper_files/paper/2023/hash/ 8c3c666820ea055a77726d66fc7d447f-Abstract-Datasets_and_Benchmarks.html
2023
-
[25]
S. Nasiriany, A. Maddukuri, L. Zhang, A. Parikh, A. Lo, A. Joshi, A. Mandlekar, and Y . Zhu. Robocasa: Large-scale simulation of everyday tasks for generalist robots.arXiv preprint arXiv:2406.02523, 2024
Pith/arXiv arXiv 2024
-
[26]
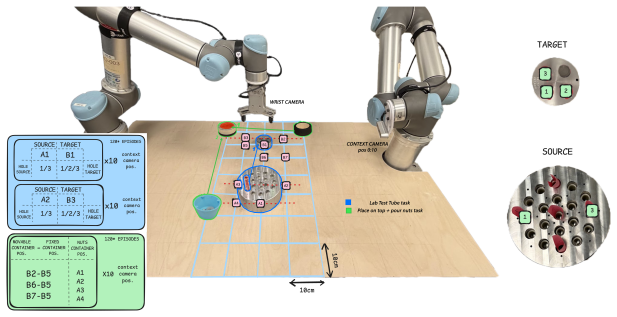
T. Chen, Z. Chen, B. Chen, Z. Cai, Y . Liu, Z. Li, Q. Liang, X. Lin, Y . Ge, Z. Gu, et al. Robotwin 2.0: A scalable data generator and benchmark with strong domain randomization for robust bimanual robotic manipulation.arXiv preprint arXiv:2506.18088, 2025. 11 A Implementation Details The main experiments instantiate G 3VLA on top ofπ 0 without changing t...
Pith/arXiv arXiv 2025
-
[27]
The environment seed is fixed to 7, and each rollout begins with 10 dummy actions to let objects settle
Each suite is evaluated with 50 rollouts per task from the official LIBERO initial states. The environment seed is fixed to 7, and each rollout begins with 10 dummy actions to let objects settle. The maximum episode lengths are 220 steps for Spatial, 280 for Object, 300 for Goal, and 520 for LIBERO-10, matching the evaluation script. At each policy query,...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.