Compact Object-Level Representations with Open-Vocabulary Understanding for Indoor Visual Relocalization
Pith reviewed 2026-06-26 00:26 UTC · model grok-4.3
The pith
OpenReLoc organizes indoor scenes into object units with open-vocabulary semantics to drive camera relocalization.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
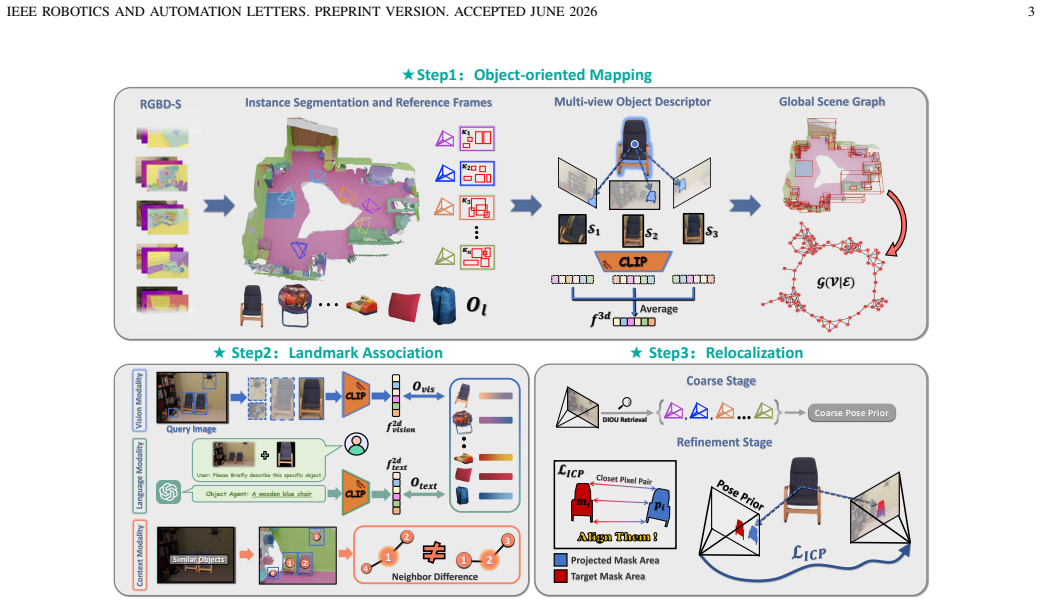
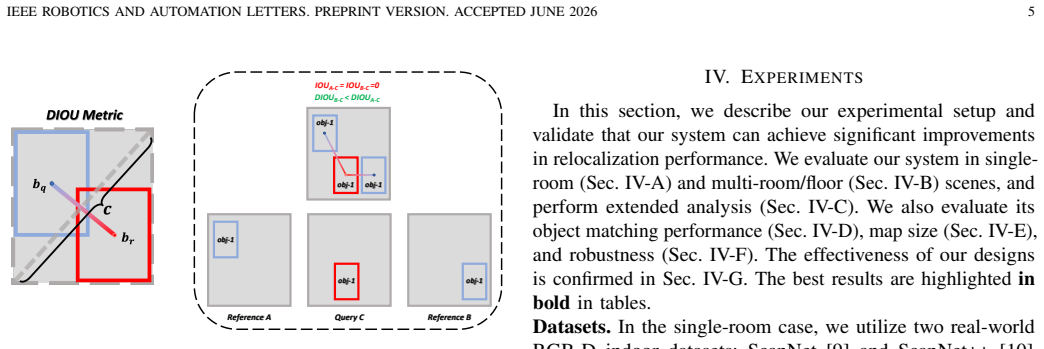
OpenReLoc provides scene understanding and accurate pose estimation by first applying a multi-modal mechanism that fuses open-vocabulary semantic knowledge for 2D-3D object matching, then using object-oriented reference frames with a DIOU-based selection strategy, and finally optimizing pose via a dual-path 2D Iterative Closest Pixel loss guided by object shape.
What carries the argument
multi-modal mechanism that integrates open-vocabulary semantic knowledge from foundation models to produce 2D-3D object matches
If this is right
- Object units alone become sufficient to solve the full relocalization task without dense feature maps.
- Reference-frame selection by Distance-IoU extends the method to scenes larger than a single room.
- The dual-path loss keeps pose estimates stable when object shapes vary or are partially observed.
Where Pith is reading between the lines
- The same object map could support downstream tasks such as object-level navigation or semantic querying without additional processing.
- Replacing the foundation model with a lighter or domain-specific one would test whether the performance gain depends on particular model scale.
- Extending the reference-frame strategy to handle dynamic objects would reveal whether the current static-scene assumption is necessary.
Load-bearing premise
The open-vocabulary matches between 2D images and 3D objects are reliable enough to serve directly as input to pose optimization.
What would settle it
A test set in which the majority of detected objects receive incorrect semantic labels or mismatched 3D correspondences, causing the reported relocalization recall to drop below prior low-level methods.
Figures



read the original abstract
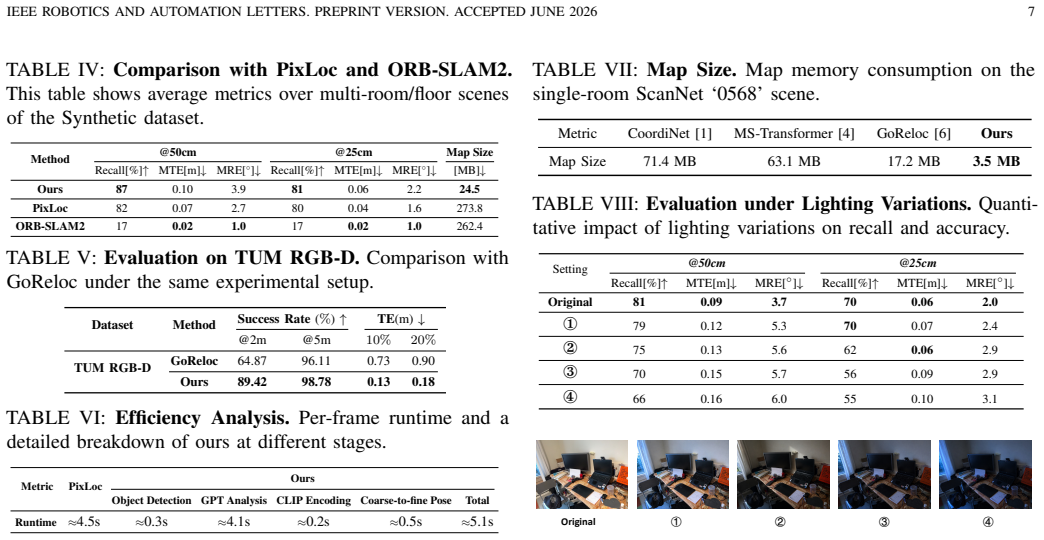
Indoor visual relocalization plays a critical role in emerging spatial and embodied AI applications. However, prior research was predominantly devoted to low-level vision schemes, struggling to perceive scene semantics and compositions, which limits both interpretability and applicability. In this paper, we explore the issue of how to organize rich object information in a scene, including semantics, layout, and geometry, into a structured map representation, thereby utilizing object units exclusively to drive the camera relocalization task. To this end, we propose OpenReLoc, a camera relocalization system designed to provide scene understanding and accurate pose estimation capabilities. Leveraging recent foundation models, we first introduce a multi-modal mechanism to integrate open-vocabulary semantic knowledge for effective 2D-3D object matching. Additionally, we design object-oriented reference frames as position priors, paired with a reference frame selection strategy based on the Distance-IoU (DIOU), enabling extension to scalable scenes. Moreover, to ensure stable and accurate pose optimization, we also propose a dual-path 2D Iterative Closest Pixel loss guided by object shape. Experimental results demonstrate that OpenReLoc achieves superior relocalization recall and accuracy across various datasets. Our source code will be released upon acceptance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes OpenReLoc, an object-centric indoor visual relocalization system that builds compact scene maps from object units incorporating semantics, layout, and geometry. It integrates open-vocabulary knowledge from foundation models via a multi-modal 2D-3D matching mechanism, uses object-oriented reference frames selected by a DIOU-based strategy for scalability, and optimizes poses with a dual-path 2D Iterative Closest Pixel loss guided by object shape. The central claim is that this yields superior relocalization recall and accuracy across various datasets.
Significance. If the experimental claims hold with proper validation, the work could advance interpretable, semantics-aware relocalization beyond low-level feature methods, with potential benefits for embodied AI applications through structured object-level representations.
major comments (1)
- [Abstract] Abstract: the claim that 'OpenReLoc achieves superior relocalization recall and accuracy across various datasets' is presented without any quantitative tables, baseline comparisons, error bars, dataset specifications, or numerical results, making the central experimental contribution unverifiable from the manuscript.
Simulated Author's Rebuttal
We thank the referee for the review. We address the single major comment below regarding the abstract.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that 'OpenReLoc achieves superior relocalization recall and accuracy across various datasets' is presented without any quantitative tables, baseline comparisons, error bars, dataset specifications, or numerical results, making the central experimental contribution unverifiable from the manuscript.
Authors: The abstract functions as a high-level summary of the work, which is standard practice. The full manuscript contains a dedicated Experiments section with quantitative tables, baseline comparisons on multiple indoor datasets, numerical recall and accuracy metrics, dataset specifications, and supporting error analysis. The central claims are therefore verifiable from the complete manuscript rather than the abstract alone. We do not believe a change to the abstract is required. revision: no
Circularity Check
No significant circularity detected
full rationale
The paper describes a relocalization system OpenReLoc whose components (multi-modal open-vocabulary 2D-3D matching via foundation models, DIOU-based reference-frame selection, dual-path shape-guided ICP loss) are presented as engineering choices rather than derived quantities. The central claim of superior recall and accuracy rests on experimental results across datasets, with no equations, fitted parameters, or predictions shown that reduce to the inputs by construction. No load-bearing self-citations, uniqueness theorems, or ansatzes are invoked in the provided text. The derivation chain is therefore self-contained and non-circular.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Foundation models provide effective open-vocabulary semantic knowledge for 2D-3D object matching.
Reference graph
Works this paper leans on
-
[1]
Coordinet: uncertainty-aware pose regressor for reliable vehicle localiza- tion,
A. Moreau, N. Piasco, D. Tsishkou, B. Stanciulescu, and A. de La Fortelle, “Coordinet: uncertainty-aware pose regressor for reliable vehicle localiza- tion,” inProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, 2022, pp. 2229–2238
2022
-
[2]
Back to the feature: Learning robust camera localization from pixels to pose,
P.-E. Sarlin, A. Unagar, M. Larsson, H. Germain, C. Toft, V . Larsson, M. Pollefeys, V . Lepetit, L. Hammarstrand, F. Kahlet al., “Back to the feature: Learning robust camera localization from pixels to pose,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2021, pp. 3247–3257
2021
-
[3]
Orb-slam2: An open-source slam system for monocular, stereo, and rgb-d cameras,
R. Mur-Artal and J. D. Tard ´os, “Orb-slam2: An open-source slam system for monocular, stereo, and rgb-d cameras,”IEEE transactions on robotics, vol. 33, no. 5, pp. 1255–1262, 2017
2017
-
[4]
Learning multi-scene absolute pose regression with transformers,
Y . Shavit, R. Ferens, and Y . Keller, “Learning multi-scene absolute pose regression with transformers,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2021, pp. 2733–2742
2021
-
[5]
Oa-slam: Leveraging objects for camera relocalization in visual slam,
M. Zins, G. Simon, and M.-O. Berger, “Oa-slam: Leveraging objects for camera relocalization in visual slam,” in2022 IEEE international symposium on mixed and augmented reality (ISMAR). IEEE, 2022, pp. 720–728
2022
-
[6]
Goreloc: Graph-based object-level relocalization for visual slam,
Y . Wang, C. Jiang, and X. Chen, “Goreloc: Graph-based object-level relocalization for visual slam,”IEEE Robotics and Automation Letters, 2024
2024
-
[7]
Openscene: 3d scene understanding with open vocabularies,
S. Peng, K. Genova, C. Jiang, A. Tagliasacchi, M. Pollefeys, T. Funkhouseret al., “Openscene: 3d scene understanding with open vocabularies,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2023, pp. 815–824
2023
-
[8]
Learning transferable visual models from natural language supervision,
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clarket al., “Learning transferable visual models from natural language supervision,” inInternational conference on machine learning. PmLR, 2021, pp. 8748–8763
2021
-
[9]
Scannet: Richly-annotated 3d reconstructions of indoor scenes,
A. Dai, A. X. Chang, M. Savva, M. Halber, T. Funkhouser, and M. Nießner, “Scannet: Richly-annotated 3d reconstructions of indoor scenes,” inProceedings of the IEEE conference on computer vision and pattern recognition, 2017, pp. 5828–5839
2017
-
[10]
Scannet++: A high- fidelity dataset of 3d indoor scenes,
C. Yeshwanth, Y .-C. Liu, M. Nießner, and A. Dai, “Scannet++: A high- fidelity dataset of 3d indoor scenes,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 12–22
2023
-
[11]
Habitat: A Platform for Embodied AI Research,
M. Savva, A. Kadian, O. Maksymets, Y . Zhao, E. Wijmans, B. Jain, J. Straub, J. Liu, V . Koltun, J. Malik, D. Parikh, and D. Batra, “Habitat: A Platform for Embodied AI Research,” inProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2019
2019
-
[12]
Scaling up visual and vision-language representation learning with noisy text supervision,
C. Jia, Y . Yang, Y . Xia, Y .-T. Chen, Z. Parekh, H. Pham, Q. Le, Y .-H. Sung, Z. Li, and T. Duerig, “Scaling up visual and vision-language representation learning with noisy text supervision,” inInternational conference on machine learning. PMLR, 2021, pp. 4904–4916
2021
-
[13]
Openmask3d: open-vocabulary 3d instance segmenta- tion,
A. Takmaz, E. Fedele, R. W. Sumner, M. Pollefeys, F. Tombari, and F. Engelmann, “Openmask3d: open-vocabulary 3d instance segmenta- tion,” inProceedings of the 37th International Conference on Neural Information Processing Systems, 2023, pp. 68 367–68 390
2023
-
[14]
Open3dis: Open-vocabulary 3d instance segmentation with 2d mask guidance,
P. Nguyen, T. D. Ngo, E. Kalogerakis, C. Gan, A. Tran, C. Pham, and K. Nguyen, “Open3dis: Open-vocabulary 3d instance segmentation with 2d mask guidance,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 4018–4028
2024
-
[15]
Maskclustering: View consensus based mask graph clustering for open-vocabulary 3d instance segmentation,
M. Yan, J. Zhang, Y . Zhu, and H. Wang, “Maskclustering: View consensus based mask graph clustering for open-vocabulary 3d instance segmentation,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 28 274–28 284
2024
-
[16]
Ovir-3d: Open-vocabulary 3d instance retrieval without training on 3d data,
S. Lu, H. Chang, E. P. Jing, A. Boularias, and K. Bekris, “Ovir-3d: Open-vocabulary 3d instance retrieval without training on 3d data,” in Conference on Robot Learning. PMLR, 2023, pp. 1610–1620
2023
-
[17]
Cubeslam: Monocular 3-d object slam,
S. Yang and S. Scherer, “Cubeslam: Monocular 3-d object slam,”IEEE Transactions on Robotics, vol. 35, no. 4, pp. 925–938, 2019
2019
-
[18]
Clip-loc: Multi-modal landmark association for global localization in object-based maps,
S. Matsuzaki, T. Sugino, K. Tanaka, Z. Sha, S. Nakaoka, S. Yoshizawa, and K. Shintani, “Clip-loc: Multi-modal landmark association for global localization in object-based maps,” in2024 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2024, pp. 13 673–13 679
2024
-
[19]
Clip-clique: Graph-based correspondence matching augmented by vision language models for object-based global localization,
S. Matsuzaki, K. Tanaka, and K. Shintani, “Clip-clique: Graph-based correspondence matching augmented by vision language models for object-based global localization,”IEEE Robotics and Automation Letters, 2024
2024
-
[20]
3dmatch: Learning local geometric descriptors from rgb-d reconstruc- tions,
A. Zeng, S. Song, M. Nießner, M. Fisher, J. Xiao, and T. Funkhouser, “3dmatch: Learning local geometric descriptors from rgb-d reconstruc- tions,” inProceedings of the IEEE conference on computer vision and pattern recognition, 2017, pp. 1802–1811
2017
-
[21]
You only look once: Unified, real-time object detection,
J. Redmon, S. Divvala, R. Girshick, and A. Farhadi, “You only look once: Unified, real-time object detection,” inProceedings of the IEEE conference on computer vision and pattern recognition, 2016, pp. 779– 788
2016
-
[22]
Habitat synthetic scenes dataset (hssd-200): An analysis of 3d scene scale and realism tradeoffs for objectgoal navigation,
M. Khanna, Y . Mao, H. Jiang, S. Haresh, B. Shacklett, D. Batra, A. Clegg, E. Undersander, A. X. Chang, and M. Savva, “Habitat synthetic scenes dataset (hssd-200): An analysis of 3d scene scale and realism tradeoffs for objectgoal navigation,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 16 384–16 393
2024
-
[23]
A benchmark for the evaluation of rgb-d slam systems,
J. Sturm, N. Engelhard, F. Endres, W. Burgard, and D. Cremers, “A benchmark for the evaluation of rgb-d slam systems,” inProc. of the International Conference on Intelligent Robot Systems (IROS), Oct. 2012
2012
-
[24]
Nice-slam: Neural implicit scalable encoding for slam,
Z. Zhu, S. Peng, V . Larsson, W. Xu, H. Bao, Z. Cui, M. R. Oswald, and M. Pollefeys, “Nice-slam: Neural implicit scalable encoding for slam,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2022, pp. 12 786–12 796
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.