FLUX3D: High-Fidelity 3D Gaussian Generation with Diffusion-Aligned Sparse Representation
Pith reviewed 2026-06-26 00:12 UTC · model grok-4.3
The pith
FLUX3D uses diffusion-aligned structured latents and a sparse multimodal transformer to overcome representation and alignment bottlenecks in image-to-3D Gaussian Splatting generation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
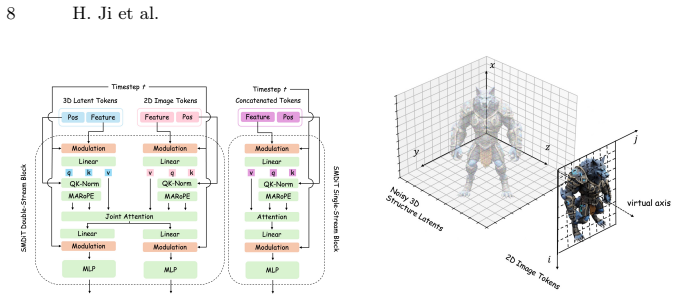
FLUX3D addresses the representation bottleneck by replacing standard 2D features with Diffusion-Aligned Structured Latents (DA-SLAT) inside a decoder-only architecture and resolves the cross-modal alignment bottleneck by introducing the Sparse-structure Multimodal Diffusion Transformer (SMDiT) together with Modal-Aware Rotary Positional Embedding (MARoPE), which together enable higher-fidelity 3D Gaussian Splatting from single images.
What carries the argument
Diffusion-Aligned Structured Latents (DA-SLAT) paired with SMDiT and MARoPE, which together select reconstructive 2D features and enforce explicit 2D-3D token correspondence inside the diffusion process.
If this is right
- Generated 3DGS assets preserve high-frequency texture and edge information from the source photograph.
- The framework scales to larger sparse voxel grids without the previous loss of reconstructive cues.
- Cross-modal alignment occurs without requiring explicit geometry supervision during diffusion.
- Benchmark scores exceed all prior sparse-voxel 3DGS generators on standard fidelity metrics.
Where Pith is reading between the lines
- The same alignment mechanism could be tested on multi-view or video inputs to produce temporally consistent 4D assets.
- MARoPE-style embeddings might transfer to other sparse-dense modality pairs such as point-cloud-to-image tasks.
- If the representation change proves robust, it could reduce reliance on large-scale discriminative pretraining for 3D reconstruction pipelines.
Load-bearing premise
The two bottlenecks identified in the paper are the dominant causes of fidelity loss, and the proposed DA-SLAT plus SMDiT/MARoPE components directly eliminate them.
What would settle it
A side-by-side ablation on the same training data showing that removing DA-SLAT or the MARoPE alignment terms produces no measurable drop in PSNR, LPIPS, or visual detail on held-out images.
Figures







read the original abstract
Sparse voxel representation has emerged as a scalable foundation for image-to-3D Gaussian Splatting (3DGS) generation, yet current methods struggle to preserve high-frequency visual details of input images due to two structural bottlenecks. First, they adopt discriminative 2D features optimized for semantic abstraction to construct sparse voxel latents, which suppress reconstructive cues and induce a representation bottleneck. Second, in the generation stage, standard diffusion transformers lack effective mechanisms to align dense 2D image tokens with sparse 3D voxel latents, resulting in a cross-modal correspondence bottleneck. To address these issues, we propose FLUX3D, a scalable image-to-3DGS framework that boosts both representation learning and cross-modal alignment during generation. We first revisit 2D feature selection for sparse-voxel-based 3D representation learning, propose Diffusion-Aligned Structured Latents (DA-SLAT) and couple it with a decoder-only architecture to improve 3DGS reconstruction fidelity. We also design a sparse-structure-aware diffusion framework, which integrates the Sparse-structure Multimodal Diffusion Transformer (SMDiT) and Modal-Aware Rotary Positional Embedding (MARoPE) to achieve geometry-agnostic 2D-3D alignment. Extensive benchmark experiments demonstrate that FLUX3D yields substantial improvements in appearance fidelity and significantly outperforms all state-of-the-art (SOTA) methods in generating high-quality 3DGS assets.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper identifies two bottlenecks in sparse voxel-based image-to-3D Gaussian Splatting generation—use of discriminative 2D features that suppress reconstructive cues, and ineffective 2D-3D alignment in diffusion transformers—and proposes FLUX3D to address them via Diffusion-Aligned Structured Latents (DA-SLAT) paired with a decoder-only architecture, plus a Sparse-structure Multimodal Diffusion Transformer (SMDiT) and Modal-Aware Rotary Positional Embedding (MARoPE) for geometry-agnostic alignment. It claims that these changes yield substantial improvements in appearance fidelity and significantly outperform all state-of-the-art methods on benchmark experiments.
Significance. If the empirical claims hold with proper ablations and controlled comparisons, the work could advance scalable high-fidelity 3DGS asset generation by refining feature selection and cross-modal mechanisms in sparse representations. However, the abstract provides no quantitative metrics, ablation results, or implementation details, so the significance cannot be assessed from the given material.
major comments (1)
- Abstract: the central claim that DA-SLAT plus SMDiT/MARoPE directly resolve the two stated bottlenecks and produce substantial fidelity gains is presented without any supporting quantitative evidence, ablation studies, error bars, or references to tables/figures; this is load-bearing for the paper's contribution and cannot be evaluated from the provided text.
Simulated Author's Rebuttal
We thank the referee for their review and the opportunity to clarify the presentation of our contributions. We respond to the major comment below.
read point-by-point responses
-
Referee: Abstract: the central claim that DA-SLAT plus SMDiT/MARoPE directly resolve the two stated bottlenecks and produce substantial fidelity gains is presented without any supporting quantitative evidence, ablation studies, error bars, or references to tables/figures; this is load-bearing for the paper's contribution and cannot be evaluated from the provided text.
Authors: We agree that the abstract, being a concise high-level summary, does not embed specific quantitative metrics, ablation details, or direct table/figure references. The full manuscript contains the supporting evidence for these claims, including benchmark results demonstrating fidelity improvements, controlled ablations on the proposed components, and comparisons against prior methods. To address the concern and improve standalone readability of the abstract, we will revise it to incorporate key quantitative highlights and pointers to the relevant experimental sections. revision: partial
Circularity Check
No significant circularity in derivation chain
full rationale
The paper is a methodological contribution proposing DA-SLAT, SMDiT, and MARoPE to address two stated bottlenecks in image-to-3DGS pipelines. No equations, fitted parameters, or first-principles derivations are present that reduce to inputs by construction. Claims rest on architectural design choices and benchmark comparisons rather than self-referential definitions, renamed empirical patterns, or load-bearing self-citations. The provided abstract and description contain no instances matching any of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
1 kontext: Flow matching for in-context image generation and editing in latent space
Batifol, S., Blattmann, A., Boesel, F., Consul, S., Diagne, C., Dockhorn, T., En- glish, J., English, Z., Esser, P., Kulal, S., et al.: Flux. 1 kontext: Flow matching for in-context image generation and editing in latent space. arXiv e-prints pp. arXiv–2506 (2025)
2025
-
[2]
In: Proceed- ings of the IEEE/CVF International Conference on Computer Vision
Cai, Y., Zhang, H., Zhang, K., Liang, Y., Ren, M., Luan, F., Liu, Q., Kim, S.Y., Zhang,J.,Zhang,Z.,etal.:Bakinggaussiansplattingintodiffusiondenoiserforfast and scalable single-stage image-to-3D generation and reconstruction. In: Proceed- ings of the IEEE/CVF International Conference on Computer Vision. pp. 25062– 25072 (2025)
2025
-
[3]
arXiv preprint arXiv:2507.17745 (2025)
Chen, Y., Li, Z., Wang, Y., Zhang, H., Li, Q., Zhang, C., Lin, G.: Ultra3D: Efficient and high-fidelity 3D generation with part attention. arXiv preprint arXiv:2507.17745 (2025)
-
[4]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Chen, Z., Tang, J., Dong, Y., Cao, Z., Hong, F., Lan, Y., Wang, T., Xie, H., Wu, T., Saito, S., et al.: 3Dtopia-xl: Scaling high-quality 3D asset generation via prim- itive diffusion. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 26576–26586 (2025)
2025
-
[5]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Collins, J., Goel, S., Deng, K., Luthra, A., Xu, L., Gundogdu, E., Zhang, X., Vicente, T.F.Y., Dideriksen, T., Arora, H., et al.: Abo: Dataset and benchmarks for real-world 3D object understanding. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 21126–21136 (2022)
2022
-
[6]
Advances in Neural Information Processing Systems36, 35799–35813 (2023)
Deitke, M., Liu, R., Wallingford, M., Ngo, H., Michel, O., Kusupati, A., Fan, A., Laforte, C., Voleti, V., Gadre, S.Y., et al.: Objaverse-xl: A universe of 10m+ 3D objects. Advances in Neural Information Processing Systems36, 35799–35813 (2023)
2023
-
[7]
In: Forty-first international conference on machine learning (2024)
Esser, P., Kulal, S., Blattmann, A., Entezari, R., Müller, J., Saini, H., Levi, Y., Lorenz, D., Sauer, A., Boesel, F., et al.: Scaling rectified flow transformers for high-resolution image synthesis. In: Forty-first international conference on machine learning (2024)
2024
-
[8]
arXiv preprint arXiv:2503.19011 (2025)
Feng, Y., Yang, M., Yang, S., Zhang, S., Yu, J., Zhao, Z., Liu, Y., Jiang, J., Guo, C.: Romantex: Decoupling 3d-aware rotary positional embedded multi-attention network for texture synthesis. arXiv preprint arXiv:2503.19011 (2025)
-
[9]
International Journal of Computer Vision129(12), 3313–3337 (2021)
Fu, H., Jia, R., Gao, L., Gong, M., Zhao, B., Maybank, S., Tao, D.: 3D-future: 3D furniture shape with texture. International Journal of Computer Vision129(12), 3313–3337 (2021)
2021
-
[10]
CAT3D: Create Anything in 3D with Multi-View Diffusion Models
Gao, R., Holynski, A., Henzler, P., Brussee, A., Martin-Brualla, R., Srinivasan, P., Barron, J.T., Poole, B.: Cat3D: Create anything in 3D with multi-view diffusion models. arXiv preprint arXiv:2405.10314 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[11]
Seedance 1.0: Exploring the Boundaries of Video Generation Models
Gao, Y., Guo, H., Hoang, T., Huang, W., Jiang, L., Kong, F., Li, H., Li, J., Li, L., Li, X., et al.: Seedance 1.0: Exploring the boundaries of video generation models. arXiv preprint arXiv:2506.09113 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[12]
arXiv preprint arXiv:2403.13788 (2024)
Gui, M., Fischer, J.S., Prestel, U., Ma, P., Kotovenko, D., Grebenkova, O., Bau- mann, S.A., Hu, V.T., Ommer, B.: Depthfm: Fast monocular depth estimation with flow matching. arXiv preprint arXiv:2403.13788 (2024)
-
[13]
Advances in neural information processing systems33, 6840–6851 (2020)
Ho, J., Jain, A., Abbeel, P.: Denoising diffusion probabilistic models. Advances in neural information processing systems33, 6840–6851 (2020)
2020
-
[14]
LRM: Large Reconstruction Model for Single Image to 3D
Hong, Y., Zhang, K., Gu, J., Bi, S., Zhou, Y., Liu, D., Liu, F., Sunkavalli, K., Bui, T., Tan, H.: Lrm: Large reconstruction model for single image to 3D. arXiv preprint arXiv:2311.04400 (2023) 16 H. Ji et al
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[15]
arXiv preprint arXiv:2401.08930 (2024)
Ji, H., Li, H.: 3d human pose analysis via diffusion synthesis. arXiv preprint arXiv:2401.08930 (2024)
-
[16]
arXiv preprint arXiv:2412.20506 (2024)
Ji, H., Lin, T., Li, H.: Dpbridge: Latent diffusion bridge for dense prediction. arXiv preprint arXiv:2412.20506 (2024)
-
[17]
arXiv preprint arXiv:2412.20470 (2024)
Ji, H., Wang, R., Lin, T., Li, H.: Jade: Joint-aware latent diffusion for 3d human generative modeling. arXiv preprint arXiv:2412.20470 (2024)
-
[18]
Shap-E: Generating Conditional 3D Implicit Functions
Jun, H., Nichol, A.: Shap-e: Generating conditional 3D implicit functions. arXiv preprint arXiv:2305.02463 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[19]
In: ProceedingsoftheIEEE/CVFConferenceonComputerVisionandPatternRecog- nition
Ke, B., Obukhov, A., Huang, S., Metzger, N., Daudt, R.C., Schindler, K.: Re- purposing diffusion-based image generators for monocular depth estimation. In: ProceedingsoftheIEEE/CVFConferenceonComputerVisionandPatternRecog- nition. pp. 9492–9502 (2024)
2024
-
[20]
ACM Trans
Kerbl, B., Kopanas, G., Leimkühler, T., Drettakis, G.: 3d gaussian splatting for real-time radiance field rendering. ACM Trans. Graph.42(4), 139–1 (2023)
2023
-
[21]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Khanna, M., Mao, Y., Jiang, H., Haresh, S., Shacklett, B., Batra, D., Clegg, A., Undersander, E., Chang, A.X., Savva, M.: Habitat synthetic scenes dataset (hssd- 200): An analysis of 3D scene scale and realism tradeoffs for objectgoal navigation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 16384–16393 (2024)
2024
-
[22]
Labs, B.F.: Flux.https://github.com/black-forest-labs/flux(2024)
2024
-
[23]
arXiv preprint arXiv:2411.08033 (2024)
Lan, Y., Zhou, S., Lyu, Z., Hong, F., Yang, S., Dai, B., Pan, X., Loy, C.C.: Gaus- siananything: Interactive point cloud flow matching for 3d object generation. arXiv preprint arXiv:2411.08033 (2024)
-
[24]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Li, W., Liu, J., Yan, H., Chen, R., Liang, Y., Chen, X., Tan, P., Long, X.: Crafts- man3d: High-fidelity mesh generation with 3d native diffusion and interactive ge- ometry refiner. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 5307–5317 (2025)
2025
-
[25]
TripoSG: High-Fidelity 3D Shape Synthesis using Large-Scale Rectified Flow Models
Li, Y., Zou, Z.X., Liu, Z., Wang, D., Liang, Y., Yu, Z., Liu, X., Guo, Y.C., Liang, D., Ouyang, W., et al.: Triposg: High-fidelity 3D shape synthesis using large-scale rectified flow models. arXiv preprint arXiv:2502.06608 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[26]
arXiv preprint arXiv:2505.14521 (2025)
Li, Z., Wang, Y., Zheng, H., Luo, Y., Wen, B.: Sparc3D: Sparse representa- tion and construction for high-resolution 3D shapes modeling. arXiv preprint arXiv:2505.14521 (2025)
-
[27]
Flow Matching for Generative Modeling
Lipman, Y., Chen, R.T., Ben-Hamu, H., Nickel, M., Le, M.: Flow matching for generative modeling. arXiv preprint arXiv:2210.02747 (2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[28]
Advances in Neural Information Processing Systems36, 22226–22246 (2023)
Liu, M., Xu, C., Jin, H., Chen, L., Varma T, M., Xu, Z., Su, H.: One-2-3-45: Any single image to 3D mesh in 45 seconds without per-shape optimization. Advances in Neural Information Processing Systems36, 22226–22246 (2023)
2023
-
[29]
In: Proceedings of the IEEE/CVF inter- national conference on computer vision
Liu, R., Wu, R., Van Hoorick, B., Tokmakov, P., Zakharov, S., Vondrick, C.: Zero- 1-to-3: Zero-shot one image to 3D object. In: Proceedings of the IEEE/CVF inter- national conference on computer vision. pp. 9298–9309 (2023)
2023
-
[30]
Flow Straight and Fast: Learning to Generate and Transfer Data with Rectified Flow
Liu, X., Gong, C., Liu, Q.: Flow straight and fast: Learning to generate and transfer data with rectified flow. arXiv preprint arXiv:2209.03003 (2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[31]
Decoupled Weight Decay Regularization
Loshchilov, I., Hutter, F.: Decoupled weight decay regularization. arXiv preprint arXiv:1711.05101 (2017)
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[32]
DINOv2: Learning Robust Visual Features without Supervision
Oquab, M., Darcet, T., Moutakanni, T., Vo, H., Szafraniec, M., Khalidov, V., Fernandez, P., Haziza, D., Massa, F., El-Nouby, A., et al.: Dinov2: Learning robust visual features without supervision. arXiv preprint arXiv:2304.07193 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[33]
SDXL: Improving Latent Diffusion Models for High-Resolution Image Synthesis
Podell, D., English, Z., Lacey, K., Blattmann, A., Dockhorn, T., Müller, J., Penna, J., Rombach, R.: Sdxl: Improving latent diffusion models for high-resolution image synthesis. arXiv preprint arXiv:2307.01952 (2023) FLUX3D 17
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[34]
DreamFusion: Text-to-3D using 2D Diffusion
Poole, B., Jain, A., Barron, J.T., Mildenhall, B.: Dreamfusion: Text-to-3D using 2D diffusion. arXiv preprint arXiv:2209.14988 (2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[35]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Ren, X., Huang, J., Zeng, X., Museth, K., Fidler, S., Williams, F.: Xcube: Large- scale 3D generative modeling using sparse voxel hierarchies. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 4209–4219 (2024)
2024
-
[36]
Seedream 4.0: Toward Next-generation Multimodal Image Generation
Seedream, T., Chen, Y., Gao, Y., Gong, L., Guo, M., Guo, Q., Guo, Z., Hou, X., Huang, W., Huang, Y., et al.: Seedream 4.0: Toward next-generation multimodal image generation, 2025. URL https://arxiv. org/abs/2509.20427
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[37]
ACM Transactions on Graphics (TOG)42(4), 1–16 (2023)
Shen, T., Munkberg, J., Hasselgren, J., Yin, K., Wang, Z., Chen, W., Gojcic, Z., Fidler, S., Sharp, N., Gao, J.: Flexible isosurface extraction for gradient-based mesh optimization. ACM Transactions on Graphics (TOG)42(4), 1–16 (2023)
2023
-
[38]
Siméoni, O., Vo, H.V., Seitzer, M., Baldassarre, F., Oquab, M., Jose, C., Khali- dov, V., Szafraniec, M., Yi, S., Ramamonjisoa, M., et al.: Dinov3. arXiv preprint arXiv:2508.10104 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[39]
Score-Based Generative Modeling through Stochastic Differential Equations
Song, Y., Sohl-Dickstein, J., Kingma, D.P., Kumar, A., Ermon, S., Poole, B.: Score- based generative modeling through stochastic differential equations. arXiv preprint arXiv:2011.13456 (2020)
work page internal anchor Pith review Pith/arXiv arXiv 2011
-
[40]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Stojanov, S., Thai, A., Rehg, J.M.: Using shape to categorize: Low-shot learn- ing with an explicit shape bias. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 1798–1808 (2021)
2021
-
[41]
Neurocomputing568, 127063 (2024)
Su, J., Ahmed, M., Lu, Y., Pan, S., Bo, W., Liu, Y.: Roformer: Enhanced trans- former with rotary position embedding. Neurocomputing568, 127063 (2024)
2024
-
[42]
arXiv preprint arXiv:2411.15098 (2024)
Tan, Z., Liu, S., Yang, X., Xue, Q., Wang, X.: Ominicontrol: Minimal and universal control for diffusion transformer. arXiv preprint arXiv:2411.15098 (2024)
-
[43]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Tan, Z., Liu, S., Yang, X., Xue, Q., Wang, X.: Ominicontrol: Minimal and universal control for diffusion transformer. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 14940–14950 (2025)
2025
-
[44]
In: European Conference on Computer Vision
Tang, J., Chen, Z., Chen, X., Wang, T., Zeng, G., Liu, Z.: Lgm: Large multi-view gaussian model for high-resolution 3D content creation. In: European Conference on Computer Vision. pp. 1–18. Springer (2024)
2024
-
[45]
In: Proceedings of the IEEE/CVF international conference on computer vision
Tang, J., Wang, T., Zhang, B., Zhang, T., Yi, R., Ma, L., Chen, D.: Make-it-3D: High-fidelity 3D creation from a single image with diffusion prior. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 22819–22829 (2023)
2023
-
[46]
arXiv preprint arXiv:2503.09277 (2025)
Wang, H., Peng, J., He, Q., Yang, H., Jin, Y., Wu, J., Hu, X., Pan, Y., Gan, Z., Chi, M., et al.: Unicombine: Unified multi-conditional combination with diffusion transformer. arXiv preprint arXiv:2503.09277 (2025)
-
[47]
Wu, C., Li, J., Zhou, J., Lin, J., Gao, K., Yan, K., Yin, S.m., Bai, S., Xu, X., Chen, Y., et al.: Qwen-image technical report. arXiv preprint arXiv:2508.02324 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[48]
arXiv preprint arXiv:2505.17412 (2025)
Wu, S., Lin, Y., Zhang, F., Zeng, Y., Yang, Y., Bao, Y., Qian, J., Zhu, S., Cao, X., Torr, P., et al.: Direct3D-s2: Gigascale 3D generation made easy with spatial sparse attention. arXiv preprint arXiv:2505.17412 (2025)
-
[49]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Xiang, J., Lv, Z., Xu, S., Deng, Y., Wang, R., Zhang, B., Chen, D., Tong, X., Yang, J.: Structured 3D latents for scalable and versatile 3D generation. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 21469–21480 (2025)
2025
-
[50]
Xu, J., Cheng, W., Gao, Y., Wang, X., Gao, S., Shan, Y.: Instantmesh: Efficient 3D mesh generation from a single image with sparse-view large reconstruction models. arXiv preprint arXiv:2404.07191 (2024) 18 H. Ji et al
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[51]
In: European Conference on Computer Vision
Xu, Y., Shi, Z., Yifan, W., Chen, H., Yang, C., Peng, S., Shen, Y., Wetzstein, G.: Grm: Large gaussian reconstruction model for efficient 3D reconstruction and gen- eration. In: European Conference on Computer Vision. pp. 1–20. Springer (2024)
2024
-
[52]
ACM Transactions On Graphics (TOG)42(4), 1–16 (2023)
Zhang, B., Tang, J., Niessner, M., Wonka, P.: 3dshape2vecset: A 3D shape repre- sentation for neural fields and generative diffusion models. ACM Transactions On Graphics (TOG)42(4), 1–16 (2023)
2023
-
[53]
Advances in Neural Information Processing Systems37, 55761–55784 (2024)
Zhang, C., Song, H., Wei, Y., Yu, C., Lu, J., Tang, Y.: Geolrm: Geometry-aware large reconstruction model for high-quality 3D gaussian generation. Advances in Neural Information Processing Systems37, 55761–55784 (2024)
2024
-
[54]
Zhang, L., Wang, Z., Zhang, Q., Qiu, Q., Pang, A., Jiang, H., Yang, W., Xu, L., Yu, J.: Clay: A controllable large-scale generative model for creating high-quality 3D assets. ACM Transactions on Graphics (TOG)43(4), 1–20 (2024) FLUX3D: High-Fidelity 3D Gaussian Generation with Diffusion-Aligned Sparse Representation (Supplementary Materials) 1 Additional ...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.