What Does a Pathological Speech Assessment Model Know about Acoustic Features? A Case Study on Oral and Oropharyngeal Cancer Patients
Pith reviewed 2026-06-25 22:49 UTC · model grok-4.3
The pith
A Wav2Vec 2.0 model for cancer patient speech assessment encodes spectral and prosodic features more strongly than voice quality ones.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
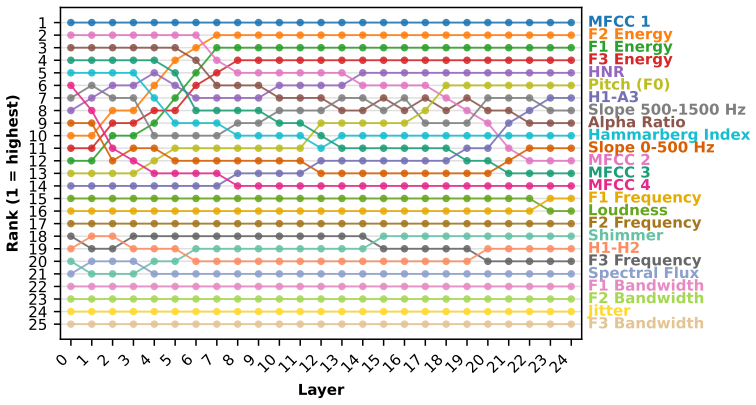
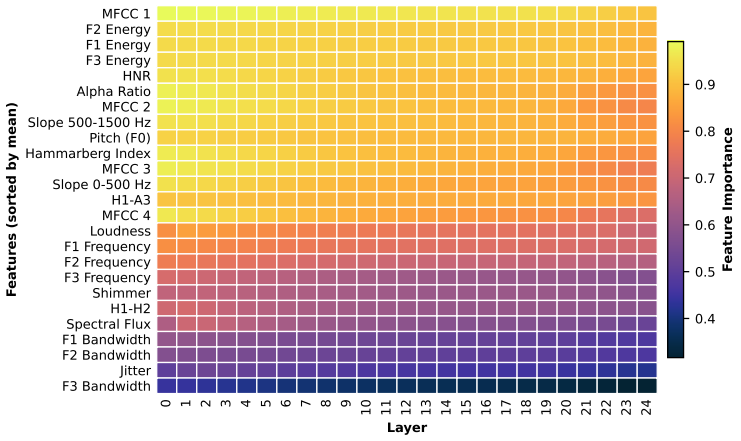
The learned representations are most strongly correlated with spectral and prosodic features, with the first MFCC coefficient yielding the highest correlations across all layers. At the group level, spectral and prosodic groups achieve correlations of 0.77 and 0.71 respectively, while voice quality reaches 0.65.
What carries the argument
Canonical correlation analysis between the model's layer-wise embeddings and eGeMAPS low-level descriptors, performed both per descriptor and by acoustic group.
If this is right
- Spectral and prosodic descriptors should receive priority when selecting features for pathological speech assessment models.
- The model appears to rely more on frequency content and timing patterns than on voice quality measures for its judgments.
- Layer-wise inspection can indicate which parts of the network capture the most usable acoustic detail for this task.
Where Pith is reading between the lines
- The same correlation method could be applied to compare what different speech foundation models have learned about acoustic structure.
- Feature-selection pipelines for cancer speech tasks could be guided by these correlation rankings rather than by general-purpose acoustic sets.
- The emphasis on spectral and prosodic information may reflect the specific effects of oral and oropharyngeal cancer on intelligibility.
Load-bearing premise
The eGeMAPS low-level descriptors supply a sufficient and unbiased reference for the acoustic information the model actually uses.
What would settle it
A re-analysis that replaces eGeMAPS descriptors with a different acoustic feature set and finds either higher overall correlations or a reversal in which group leads.
Figures

read the original abstract
This work investigates the interpretability of a Wav2Vec 2.0based speech intelligibility assessment model for oral and oropharyngeal cancer patients through canonical correlation analysis. By measuring the correlation between the model embeddings and eGeMAPS low-level descriptors (LLDs) as an interpretable reference, we analyze how acoustic information is encoded across the model layers. The analysis is conducted at two levels: individual LLDs layer-wise, and group-level: prosodic, spectral, and voice quality. Results show that the learned representations are most strongly correlated with spectral and prosodic features, with the first MFCC coefficient yielding the highest correlations across all layers. At the group level, spectral and prosodic groups achieve correlations of 0.77 and 0.71 respectively, while voice quality reaches 0.65. Beyond model interpretability, this work also offers practical guidance on acoustic feature selection for pathological speech assessment.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper applies canonical correlation analysis (CCA) between embeddings from a Wav2Vec 2.0-based speech intelligibility assessment model and eGeMAPS low-level descriptors (LLDs) on oral/oropharyngeal cancer patient speech. It reports layer-wise correlations, finding the strongest associations with spectral and prosodic features (group-level CCA values 0.77 and 0.71), with the first MFCC coefficient highest across layers, and voice quality at 0.65; the work positions this as both interpretability analysis and guidance for acoustic feature selection in pathological speech assessment.
Significance. If the reported correlations are shown to be robust, the work provides a concrete demonstration of how self-supervised speech representations encode standard acoustic dimensions in a clinical population, which could inform both model debugging and the design of compact feature sets for intelligibility assessment. The use of CCA with an external reference set is a standard and transparent approach that avoids circularity.
major comments (2)
- [Abstract] Abstract: the central results (layer-wise MFCC1 dominance; group CCA values of 0.77 spectral, 0.71 prosodic, 0.65 voice quality) are presented without any information on dataset size, number of speakers or utterances, statistical testing procedures, or controls for speaker-level confounds. These omissions make it impossible to assess whether the reported correlations are reliable or generalizable, directly undermining evaluation of the interpretability claims.
- [Abstract] Abstract: the analysis treats the eGeMAPS LLD set (prosodic/spectral/voice-quality groups) as a sufficient reference for the acoustic information encoded by the model. No ablation against an expanded descriptor bank (e.g., formant trajectories, additional spectral moments, or glottal-source parameters) is described, so the reported correlations only quantify overlap with this particular subset and do not establish that the model has or has not captured other pathology-relevant cues.
minor comments (1)
- [Abstract] Abstract contains the typo "Wav2Vec 2.0based" (missing space).
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We agree that the abstract requires additional details on the dataset and methods to support evaluation of the results, and we will revise it accordingly. Below we respond point by point to the major comments.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central results (layer-wise MFCC1 dominance; group CCA values of 0.77 spectral, 0.71 prosodic, 0.65 voice quality) are presented without any information on dataset size, number of speakers or utterances, statistical testing procedures, or controls for speaker-level confounds. These omissions make it impossible to assess whether the reported correlations are reliable or generalizable, directly undermining evaluation of the interpretability claims.
Authors: We agree that the abstract as currently written omits key contextual information needed to evaluate the reported correlations. The full manuscript describes the dataset (speech recordings from oral and oropharyngeal cancer patients), the number of speakers and utterances, the CCA procedure, and speaker-level controls via per-speaker normalization. We will revise the abstract to include a concise statement of dataset size, speaker count, and the statistical approach, thereby addressing this concern directly. revision: yes
-
Referee: [Abstract] Abstract: the analysis treats the eGeMAPS LLD set (prosodic/spectral/voice-quality groups) as a sufficient reference for the acoustic information encoded by the model. No ablation against an expanded descriptor bank (e.g., formant trajectories, additional spectral moments, or glottal-source parameters) is described, so the reported correlations only quantify overlap with this particular subset and do not establish that the model has or has not captured other pathology-relevant cues.
Authors: We acknowledge the limitation: the reported CCA values quantify overlap specifically with the eGeMAPS LLD groups and do not claim to cover all possible pathology-relevant acoustic cues. The choice of eGeMAPS follows its established use as a compact, interpretable reference set in clinical speech analysis. We will add explicit language in the abstract and discussion clarifying that the results pertain to this reference set and do not constitute an exhaustive mapping of all acoustic dimensions. revision: partial
Circularity Check
No circularity: standard CCA with external reference features
full rationale
The paper computes canonical correlations between Wav2Vec embeddings and the independent eGeMAPS LLD set (prosodic/spectral/voice-quality groups) at layer and group levels. This is a direct statistical measurement with no fitted parameters renamed as predictions, no self-definitional loops, and no load-bearing self-citations or ansatzes. The reported values (e.g., MFCC1 highest, group correlations 0.77/0.71/0.65) are outputs of the CCA procedure applied to external descriptors, not reductions of the inputs by construction. The analysis is self-contained against the chosen reference.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Canonical correlation analysis captures the linear relationships between model embeddings and acoustic descriptors
Reference graph
Works this paper leans on
-
[1]
Introduction Speech processing has a long history of development, with ad- vances spanning text-to-speech, speech recognition, and speech translation, among others, and pathological speech assessment has increasingly benefited from these advances. Traditionally, speech and voice disorders are evaluated through human-based clinical assessment, which is inh...
-
[2]
To this end, we employ Canoni- cal Correlation Analysis (CCA) [12] to bridge these two worlds
Methodology In this paper, we address the trade-off between handcrafted fea- tures and deep learning-based representations by focusing on the interpretability of the latter. To this end, we employ Canoni- cal Correlation Analysis (CCA) [12] to bridge these two worlds. CCA, first introduced by Hotelling in 1936 [13], is a statis- tical method that measures...
Pith/arXiv arXiv 1936
-
[3]
Corpus This work uses the French corpus C2SI [21], which contains recordings from both healthy control speakers and patients di- agnosed with oral and oropharyngeal cancer (OOC)
Experimental Setup 3.1. Corpus This work uses the French corpus C2SI [21], which contains recordings from both healthy control speakers and patients di- agnosed with oral and oropharyngeal cancer (OOC). C2SI was developed under the Carcinologic Speech Severity Index project from 2015 to 2017, initiated to address the need for objective assessment tools fo...
2015
-
[4]
Results 4.1. Individual-level analysis Figure 1 illustrates the layer-wise evolution of individual eGeMAPS LLDs in terms of their PWCCA correlation rank- ing with Wav2Vec 2.0 representations, where rank 1 indicates the highest correlation and rank 25 the lowest. The ranking re- veals that certain features undergo considerable changes across layers, sugges...
-
[5]
Conclusion This work presents an analysis of a Wav2Vec 2.0-based speech intelligibility assessment model, focused on interpretability, using eGeMAPS LLDs as an interpretable reference and the PWCCA-based approach. The results show that the model rep- resentations are most correlated with Spectral and Prosodic fea- tures, while first MFCC coefficient is th...
-
[6]
This work was granted ac- cess to the HPC resources of IDRIS under the allocation 2025- AD011016558 made by GENCI
Acknowledgments This research was funded, in whole, by Chair LIAvignon, and in part, by the French National Research Agency (ANR), project OLINPIC (ANR-24-CE38-2819). This work was granted ac- cess to the HPC resources of IDRIS under the allocation 2025- AD011016558 made by GENCI. For the purpose of open ac- cess, the author has applied a CC-BY public cop...
2025
-
[7]
All scientific content, ideas, analyses, and conclu- sions are solely the work of the authors
Generative AI Use Disclosure Generative AI tools were used for editing and polishing the manuscript. All scientific content, ideas, analyses, and conclu- sions are solely the work of the authors
-
[8]
Interpretable speech features vs. dnn embeddings: What to use in the automatic assessment of parkinson’s disease in multi-lingual scenarios,
A. Favaro, Y .-T. Tsai, A. Butala, T. Thebaud, J. Villalba, N. Dehak, and L. Moro-Vel´azquez, “Interpretable speech features vs. dnn embeddings: What to use in the automatic assessment of parkinson’s disease in multi-lingual scenarios,” Computers in Biology and Medicine , vol. 166, p. 107559, 2023. [On- line]. Available: https://www.sciencedirect.com/scie...
2023
-
[9]
M. Balaguer, J. Pinquier, J. Farinas, and V . Woisard, “Prediction of speech impairment in patients treated for oral or oropharyngeal cancer using automatic speech analysis,” International Journal of Language & Communication Disorders , vol. 60, no. 5, p. e70103, 2025. [Online]. Available: https://onlinelibrary.wiley. com/doi/abs/10.1111/1460-6984.70103
-
[10]
Towards an automatic evaluation of the dysarthria level of patients with parkinson’s disease,
J. V ´asquez-Correa, J. Orozco-Arroyave, T. Bocklet, and E. N¨oth, “Towards an automatic evaluation of the dysarthria level of patients with parkinson’s disease,” Journal of Communication Disorders, vol. 76, pp. 21–36, 2018. [Online]. Available: https:// www.sciencedirect.com/science/article/pii/S002199241730076X
2018
-
[11]
Acoustic correlates of speech intelligibility: the usability of the eGeMAPS feature set for atypical speech,
W. Xue, C. Cucchiarini, R. van Hout, and H. Strik, “Acoustic correlates of speech intelligibility: the usability of the eGeMAPS feature set for atypical speech,” in 8th ISCA Workshop on Speech and Language Technology in Education (SLaTE 2019) , 2019, pp. 48–52
2019
-
[12]
Dysarthric Speech Classification Using Glot- tal Features Computed from Non-words, Words and Sentences,
N. N P and P. Alku, “Dysarthric Speech Classification Using Glot- tal Features Computed from Non-words, Words and Sentences,” in Interspeech 2018, 2018, pp. 3403–3407
2018
-
[13]
Glottal flow patterns anal- yses for parkinson’s disease detection: Acoustic and nonlinear approaches,
E. A. Belalc ´azar-Bola˜nos, J. R. Orozco-Arroyave, J. F. Vargas- Bonilla, T. Haderlein, and E. N ¨oth, “Glottal flow patterns anal- yses for parkinson’s disease detection: Acoustic and nonlinear approaches,” in Text, Speech, and Dialogue , P. Sojka, A. Hor ´ak, I. Kope ˇcek, and K. Pala, Eds. Cham: Springer International Publishing, 2016, pp. 400–407
2016
-
[14]
Prosody-based measures for automatic severity assessment of dysarthric speech,
A. Hernandez, S. Kim, and M. Chung, “Prosody-based measures for automatic severity assessment of dysarthric speech,” Applied Sciences , vol. 10, no. 19, 2020. [Online]. Available: https://www.mdpi.com/2076-3417/10/19/6999
2020
-
[15]
Exploring pathological speech quality assessment with ASR-powered Wav2Vec2 in data-scarce context,
T. Nguyen, C. Fredouille, A. Ghio, M. Balaguer, and V . Woisard, “Exploring pathological speech quality assessment with ASR-powered Wav2Vec2 in data-scarce context,” in Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024) , N. Calzolari, M.-Y . Kan, V . Hoste, A. Lenci, S...
2024
-
[16]
Towards reducing patient effort for the automatic prediction of speech intelligibility in head and neck cancers,
S. Quintas, A. Abad, J. Mauclair, V . Woisard, and J. Pinquier, “Towards reducing patient effort for the automatic prediction of speech intelligibility in head and neck cancers,” in ICASSP 2023 - 2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2023, pp. 1–5
2023
-
[17]
Multimodal assessment of parkinson’s disease: A deep learning approach,
J. C. V ´asquez-Correa, T. Arias-Vergara, J. R. Orozco-Arroyave, B. Eskofier, J. Klucken, and E. N¨oth, “Multimodal assessment of parkinson’s disease: A deep learning approach,”IEEE Journal of Biomedical and Health Informatics, vol. 23, no. 4, pp. 1618–1630, 2019
2019
-
[18]
Con- volutional Neural Network to Model Articulation Impairments in Patients with Parkinson’s Disease,
J. V ´asquez-Correa, J. R. Orozco-Arroyave, and E. N ¨oth, “Con- volutional Neural Network to Model Articulation Impairments in Patients with Parkinson’s Disease,” inInterspeech 2017, 2017, pp. 314–318
2017
-
[19]
Breakthroughs in statistics: methodology and distribution,
K. Pearson, S. Kotz, and N. Johnson, “Breakthroughs in statistics: methodology and distribution,” 1992
1992
-
[20]
Simplified calculation of principal components,
H. Hotelling, “Simplified calculation of principal components,” Psychometrika, vol. 1, no. 1, pp. 27–35, 1936
1936
-
[21]
Cca based fea- ture selection with application to continuous depression recog- nition from acoustic speech features,
H. Kaya, F. Eyben, A. A. Salah, and B. Schuller, “Cca based fea- ture selection with application to continuous depression recog- nition from acoustic speech features,” in 2014 IEEE Interna- tional Conference on Acoustics, Speech and Signal Processing (ICASSP), 2014, pp. 3729–3733
2014
-
[22]
Multi-modality canonical fea- ture selection for alzheimer’s disease diagnosis,
X. Zhu, H.-I. Suk, and D. Shen, “Multi-modality canonical fea- ture selection for alzheimer’s disease diagnosis,” inInternational Conference on Medical Image Computing and Computer-Assisted Intervention. Springer, 2014, pp. 162–169
2014
-
[23]
Svcca: Singular vector canonical correlation analysis for deep learning dynamics and interpretability,
M. Raghu, J. Gilmer, J. Yosinski, and J. Sohl-Dickstein, “Svcca: Singular vector canonical correlation analysis for deep learning dynamics and interpretability,” in Advances in Neural Information Processing Systems , I. Guyon, U. V . Luxburg, S. Bengio, H. Wallach, R. Fergus, S. Vishwanathan, and R. Garnett, Eds., vol. 30. Curran Associates, Inc., 2017. [...
2017
-
[24]
Insights on representa- tional similarity in neural networks with canonical correlation,
A. Morcos, M. Raghu, and S. Bengio, “Insights on representa- tional similarity in neural networks with canonical correlation,” in Advances in Neural Information Processing Systems , S. Bengio, H. Wallach, H. Larochelle, K. Grauman, N. Cesa-Bianchi, and R. Garnett, Eds., vol. 31. Curran Associates, Inc., 2018. [Online]. Available: https://proceedings.neuri...
2018
-
[25]
Layer-wise analysis of a self-supervised speech representation model,
A. Pasad, J.-C. Chou, and K. Livescu, “Layer-wise analysis of a self-supervised speech representation model,” in2021 IEEE Auto- matic Speech Recognition and Understanding Workshop (ASRU) , 2021, pp. 914–921
2021
-
[26]
Comparative layer-wise anal- ysis of self-supervised speech models,
A. Pasad, B. Shi, and K. Livescu, “Comparative layer-wise anal- ysis of self-supervised speech models,” in ICASSP 2023 - 2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2023, pp. 1–5
2023
-
[27]
Exploring asr-based wav2vec2 for automated speech disorder as- sessment: Insights and analysis,
T. Nguyen, C. Fredouille, A. Ghio, M. Balaguer, and V . Woisard, “Exploring asr-based wav2vec2 for automated speech disorder as- sessment: Insights and analysis,” in 2024 IEEE Spoken Language Technology Workshop (SLT), 2024, pp. 975–982
2024
-
[28]
C2si corpus: a database of speech disorder productions to assess intel- ligibility and quality of life in head and neck cancers,
V . Woisard, C. Ast ´esano, M. Balaguer, J. Farinas, C. Fredouille, P. Gaillard, A. Ghio, L. Giusti, I. Laaridh, M. Lalain et al., “C2si corpus: a database of speech disorder productions to assess intel- ligibility and quality of life in head and neck cancers,” Language Resources and Evaluation, vol. 55, no. 1, pp. 173–190, 2021
2021
-
[29]
Wav2vec-based detection and severity level classification of dysarthria from speech,
F. Javanmardi, S. Tirronen, M. Kodali, S. R. Kadiri, and P. Alku, “Wav2vec-based detection and severity level classification of dysarthria from speech,” in Icassp 2023-2023 IEEE international conference on acoustics, speech and signal processing (icassp) . IEEE, 2023, pp. 1–5
2023
-
[30]
Investigation of self- supervised pre-trained models for classification of voice quality from speech and neck surface accelerometer signals,
S. R. Kadiri, F. Javanmardi, and P. Alku, “Investigation of self- supervised pre-trained models for classification of voice quality from speech and neck surface accelerometer signals,” Computer Speech & Language, vol. 83, p. 101550, 2024
2024
-
[31]
wav2vec 2.0: A framework for self-supervised learning of speech representa- tions,
A. Baevski, Y . Zhou, A. Mohamed, and M. Auli, “wav2vec 2.0: A framework for self-supervised learning of speech representa- tions,” in Advances in Neural Information Processing Systems , H. Larochelle, M. Ranzato, R. Hadsell, M. Balcan, and H. Lin, Eds., vol. 33. Curran Associates, Inc., 2020, pp. 12 449–12 460. [Online]. Available: https://proceedings.ne...
2020
-
[32]
Can we use speaker embeddings on spontaneous speech obtained from medical conversations to predict intelligibility?
S. Quintas, M. Balaguer, J. Mauclair, V . Woisard, and J. Pinquier, “Can we use speaker embeddings on spontaneous speech obtained from medical conversations to predict intelligibility?” in 2023 IEEE Automatic Speech Recognition and Understanding Work- shop (ASRU), 2023, pp. 1–7
2023
-
[33]
Interpretable assessment of speech intelligibility using deep learning: A case study on speech disorders due to head and neck cancers,
S. Abderrazek, C. Fredouille, A. Ghio, M. Lalain, C. Meunier, M. Balaguer, and V . Woisard, “Interpretable assessment of speech intelligibility using deep learning: A case study on speech disorders due to head and neck cancers,” in Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-...
2024
-
[34]
The geneva minimalistic acoustic parameter set (gemaps) for voice research and affective computing,
F. Eyben, K. R. Scherer, B. W. Schuller, J. Sundberg, E. Andr ´e, C. Busso, L. Y . Devillers, J. Epps, P. Laukka, S. S. Narayanan, and K. P. Truong, “The geneva minimalistic acoustic parameter set (gemaps) for voice research and affective computing,” IEEE Transactions on Affective Computing , vol. 7, no. 2, pp. 190–202, 2016
2016
-
[35]
The INTERSPEECH 2013 Computational Paralinguis- tics Challenge: Social Signals, Conflict, Emotion, Autism,
B. Schuller, S. Steidl, A. Batliner, A. Vinciarelli, K. R. Scherer, F. Ringeval, M. Chetouani, F. Weninger, F. Eyben, E. Marchi, M. Mortillaro, H. Salamin, A. Polychroniou, F. Valente, and S. Kim, “The INTERSPEECH 2013 Computational Paralinguis- tics Challenge: Social Signals, Conflict, Emotion, Autism,” in INTERSPEECH 201314thAnnual Conference of the Int...
2013
-
[36]
Cross-language speech emotion recognition using bag-of-word representations, domain adapta- tion, and data augmentation,
S. Kshirsagar and T. H. Falk, “Cross-language speech emotion recognition using bag-of-word representations, domain adapta- tion, and data augmentation,” Sensors, vol. 22, no. 17, p. 6445, 2022
2022
-
[37]
Schuller, M
B. Schuller, M. W ¨ollmer, F. Eyben, and G. Rigoll,Prosodic, spec- tral or voice quality? Feature type relevance for the discrimina- tion of emotion pairs , 01 2009
2009
-
[38]
Prosodic feature analysis for automatic speech assessment and individual report generation in people with down syndrome,
M. Corrales-Astorgano, C. Gonz ´alez-Ferreras, D. Escudero- Mancebo, and V . Carde˜noso-Payo, “Prosodic feature analysis for automatic speech assessment and individual report generation in people with down syndrome,” Applied Sciences, vol. 14, no. 1, p. 293, 2023
2023
-
[39]
F. Eyben, M. W ¨ollmer, and B. Schuller, “Opensmile: the munich versatile and fast open-source audio feature extractor,” in Proceedings of the 18th ACM International Conference on Multimedia, ser. MM ’10. New York, NY , USA: Association for Computing Machinery, 2010, p. 1459–1462. [Online]. Available: https://doi.org/10.1145/1873951.1874246
-
[40]
Interpreting deep representations of phonetic features via neuro-based concept detector: Application to speech disorders due to head and neck cancer,
S. Abderrazek, C. Fredouille, A. Ghio, M. Lalain, C. Meunier, and V . Woisard, “Interpreting deep representations of phonetic features via neuro-based concept detector: Application to speech disorders due to head and neck cancer,” IEEE/ACM Transactions on Audio, Speech, and Language Processing , vol. 31, pp. 200– 214, 2023
2023
-
[41]
Automatic intelligibility assessment of dysarthric speech using glottal parameters,
N. P. Narendra and P. Alku, “Automatic intelligibility assessment of dysarthric speech using glottal parameters,” Speech Communi- cation, vol. 123, pp. 1–9, 2020
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.