ADM-Fusion: Adaptive Deep Multi-Sensor Fusion for Robust Ego-Motion Estimation in Diverse Conditions
Pith reviewed 2026-06-26 00:01 UTC · model grok-4.3
The pith
An adaptive multi-sensor fusion network dynamically weights inputs to keep ego-motion estimates accurate when sensors degrade.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
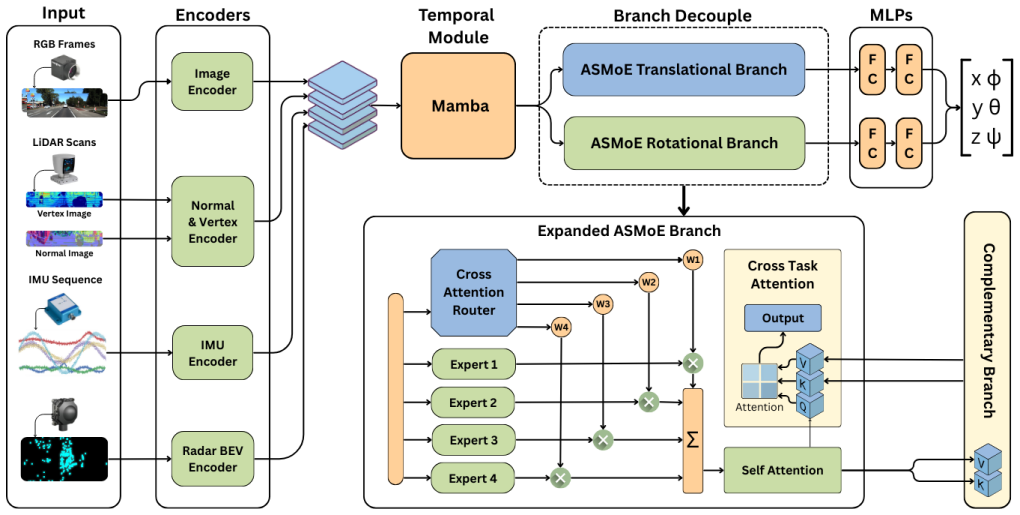
ADM-Fusion employs an adaptive sensor mixture-of-experts framework with content-aware routing to dynamically assign weights to sensor inputs in real time. Separate translation and rotation branches are coupled through a cross-task attention mechanism that preserves task-specific specialization while enabling information sharing. The network is trained on the CARLA-LOC simulated dataset with added degradations and then fine-tuned on KITTI real-world data, after which it remains robust under degraded conditions while staying competitive with prior methods.
What carries the argument
adaptive sensor mixture-of-experts framework with content-aware routing that dynamically weights each sensor input according to scene content
If this is right
- Dynamic weighting lets the network reduce the influence of a failing sensor and increase the influence of reliable ones without manual intervention.
- Cross-task attention allows translation and rotation estimates to benefit from shared features while each branch retains its own specialization.
- Simulation-to-real fine-tuning enables the routing policy to transfer from controlled degradations to natural sensor failures.
- The overall fusion remains accurate across changing conditions without requiring changes to the sensor suite or fixed weighting schedules.
Where Pith is reading between the lines
- The same routing logic could be tested on other robotics tasks such as object detection or semantic segmentation where sensor reliability also varies.
- Designers might be able to reduce the number of redundant sensors if the adaptive mechanism reliably substitutes one modality for another.
- Analysis of the learned routing decisions could highlight which environmental cues most strongly predict when a given sensor becomes unreliable.
Load-bearing premise
The content-aware routing and cross-task attention trained on simulated degradations will correctly identify and compensate for the failure patterns that occur in actual sensors after fine-tuning on standard real recordings.
What would settle it
Ego-motion error rates measured on real-world sequences that contain sensor degradations different from those introduced in simulation would rise sharply beyond the levels reported for the fine-tuned model.
Figures


read the original abstract
Robust multi-sensor fusion is essential for reliable autonomy in diverse and degraded environments, where sensor reliability can fluctuate rapidly. Because different modalities fail in distinct ways, effective fusion should adaptively balance complementary cues rather than rely on fixed weighting. This adaptability is particularly important for ego-motion estimation, since accurate updates depend on the consistent integration of complementary sensor information. We propose ADM-Fusion, an end-to-end deep learning based multi-sensor fusion method designed to adapt to environmental changes and sensor degradation. ADM-Fusion employs an adaptive sensor mixture-of-experts framework with content-aware routing to dynamically assign weights to sensor inputs in real time. The system further incorporates separate translation and rotation branches, coupled through a cross-task attention mechanism to preserve task-specific specialization while enabling information sharing. ADM-Fusion is trained on the CARLA-LOC simulated dataset and subsequently fine-tuned on KITTI real-world data, demonstrating effective simulation-to-real transfer. Experiments show that ADM-Fusion remains robust under degraded conditions while maintaining competitive performance against existing methods.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes ADM-Fusion, an end-to-end deep multi-sensor fusion architecture for ego-motion estimation. It employs a mixture-of-experts framework with content-aware routing to dynamically weight sensor modalities, separate translation and rotation heads linked by cross-task attention, and a training protocol that first uses the CARLA-LOC simulated dataset with degradations before fine-tuning on KITTI. The central claim is that this yields robustness under degraded conditions while remaining competitive with existing methods.
Significance. If the content-aware routing and cross-task attention prove to generalize from simulated degradations to genuine real-world sensor failures, the work would address a practically important gap in adaptive fusion for autonomous systems operating in variable conditions.
major comments (2)
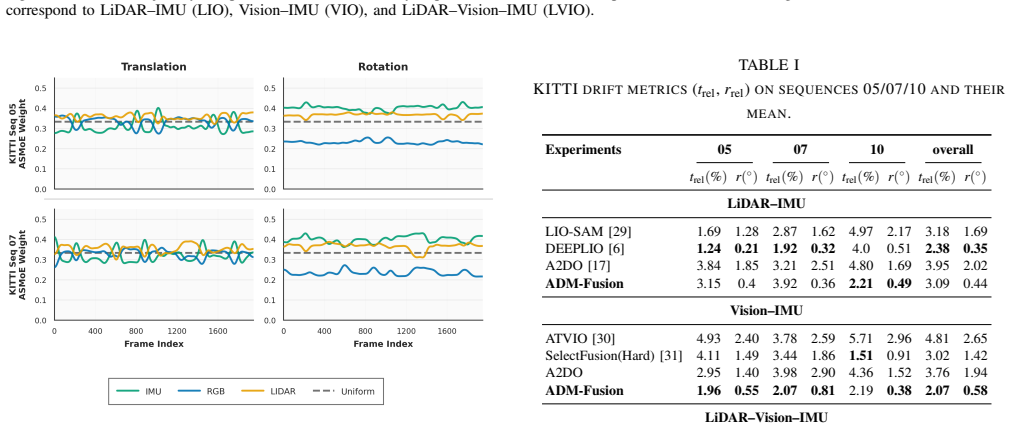
- [Abstract] Abstract: the statement that 'Experiments show that ADM-Fusion remains robust under degraded conditions while maintaining competitive performance against existing methods' is presented without any quantitative metrics, baselines, or ablation tables, leaving the central empirical claim unsupported in the provided text.
- [Abstract] Training protocol (described in Abstract): KITTI contains no systematic sensor degradations, so the fine-tuning step only adapts the model to clean real data; the claim of effective simulation-to-real transfer for the mixture-of-experts routing policy therefore rests on an unverified assumption. No ablation isolates the routing component on real sensor dropouts or environmental interference.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract and training protocol. We address each comment below and will revise the manuscript to improve clarity and support for the claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: the statement that 'Experiments show that ADM-Fusion remains robust under degraded conditions while maintaining competitive performance against existing methods' is presented without any quantitative metrics, baselines, or ablation tables, leaving the central empirical claim unsupported in the provided text.
Authors: We agree that the abstract should provide quantitative support. In the revised version we will incorporate specific metrics (e.g., mean translation/rotation errors under degradation levels) and reference the main result tables and baselines to substantiate the central claim. revision: yes
-
Referee: [Abstract] Training protocol (described in Abstract): KITTI contains no systematic sensor degradations, so the fine-tuning step only adapts the model to clean real data; the claim of effective simulation-to-real transfer for the mixture-of-experts routing policy therefore rests on an unverified assumption. No ablation isolates the routing component on real sensor dropouts or environmental interference.
Authors: The protocol trains the adaptive routing on CARLA-LOC with explicit simulated degradations before fine-tuning on KITTI; robustness is evaluated on the degraded simulation data while fine-tuning demonstrates domain transfer on clean real data. We acknowledge that no direct ablations on real sensor dropouts exist and that the sim-to-real transfer of the routing policy is therefore an assumption. We will revise the abstract to clarify the evaluation scope and add a limitations paragraph discussing this point. revision: partial
Circularity Check
No circularity in derivation chain
full rationale
The paper describes an empirical neural architecture (mixture-of-experts routing, cross-task attention) trained on CARLA-LOC then fine-tuned on KITTI. No equations, derivations, or parameter-fitting steps are presented that reduce a claimed prediction to its own inputs by construction. No self-citation load-bearing uniqueness theorems or ansatzes appear. The central claims rest on experimental results rather than any self-referential mathematical reduction, making the derivation chain self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Are we ready for autonomous driving? the KITTI vision benchmark suite,
A. Geiger, P. Lenz, and R. Urtasun, “Are we ready for autonomous driving? the KITTI vision benchmark suite,” inProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2012, pp. 3354–3361
2012
-
[2]
Past, present, and future of simultaneous localization and mapping: Toward the robust-perception age,
C. Cadena, L. Carlone, H. Carrillo, Y . Latif, D. Scaramuzza, J. Neira, I. Reid, and J. J. Leonard, “Past, present, and future of simultaneous localization and mapping: Toward the robust-perception age,”IEEE Transactions on Robotics, vol. 32, no. 6, pp. 1309–1332, 2016
2016
-
[3]
Parallel tracking and mapping for small AR workspaces,
G. Klein and D. Murray, “Parallel tracking and mapping for small AR workspaces,” inProceedings of the 6th IEEE and ACM International Symposium on Mixed and Augmented Reality (ISMAR), 2007, pp. 225– 234
2007
-
[4]
Orb-slam2: An open-source slam system for monocular, stereo, and rgb-d cameras,
R. Mur-Artal and J. D. Tard ´os, “Orb-slam2: An open-source slam system for monocular, stereo, and rgb-d cameras,”IEEE transactions on robotics, vol. 33, no. 5, pp. 1255–1262, 2017
2017
-
[5]
H-slam: Hybrid direct– indirect visual slam,
G. Younes, D. Khalil, J. Zelek, and D. Asmar, “H-slam: Hybrid direct– indirect visual slam,”Robotics and Autonomous Systems, vol. 179, p. 104729, 2024
2024
-
[6]
Deeplio: Deep lidar inertial sensor fusion for odometry estimation,
A. Javanmard-Ghareshiran, D. Iwaszczuk, and S. Roth, “Deeplio: Deep lidar inertial sensor fusion for odometry estimation,” inISPRS Annals of the Photogrammetry, Remote Sensing and Spatial Informa- tion Sciences, vol. V-1-2021, 2021, pp. 47–54
2021
-
[7]
Probabilistic algorithms in robotics,
S. Thrun, “Probabilistic algorithms in robotics,”Ai Magazine, vol. 21, no. 4, pp. 93–93, 2000
2000
-
[8]
Lsd-slam: Large-scale di- rect monocular slam,
J. Engel, T. Sch ¨ops, and D. Cremers, “Lsd-slam: Large-scale di- rect monocular slam,” inEuropean Conference on Computer Vision (ECCV). Springer, 2014, pp. 834–849
2014
-
[9]
A multi-state constraint kalman filter for vision-aided inertial navigation,
A. I. Mourikis and S. I. Roumeliotis, “A multi-state constraint kalman filter for vision-aided inertial navigation,” inProceedings of the IEEE International Conference on Robotics and Automation (ICRA), 2007
2007
-
[10]
High-precision, consistent ekf-based visual–inertial odometry,
M. Li and A. I. Mourikis, “High-precision, consistent ekf-based visual–inertial odometry,”The International Journal of Robotics Re- search, vol. 32, no. 6, pp. 690–711, 2013
2013
-
[11]
Keyframe-based visual-inertial slam using nonlinear optimization,
S. Leutenegger, P. Furgale, V . Rabaud, M. Chli, K. Konolige, and R. Siegwart, “Keyframe-based visual-inertial slam using nonlinear optimization,” inRobotics: Science and Systems (RSS), 2013
2013
-
[12]
Integrating multi- modal sensors: A review of fusion techniques for intelligent vehicles,
C. Wei, Z. Qin, Z. Zhang, G. Wu, and M. J. Barth, “Integrating multi- modal sensors: A review of fusion techniques for intelligent vehicles,” arXiv preprint arXiv:2506.21885, 2025
arXiv 2025
-
[13]
A comparative review on multi-modal sensors fusion based on deep learning,
Q. Tang, J. Liang, and F. Zhu, “A comparative review on multi-modal sensors fusion based on deep learning,”Signal Processing, vol. 213, p. 109165, 2023
2023
-
[14]
Deepvo: Towards end-to-end visual odometry with deep recurrent convolutional neural networks,
S. Wang, R. Clark, H. Wen, and N. Trigoni, “Deepvo: Towards end-to-end visual odometry with deep recurrent convolutional neural networks,”arXiv preprint arXiv:1709.08429, 2017
Pith/arXiv arXiv 2017
-
[15]
Eliot: End-to-end lidar odometry using 3-d transformer frameworks,
D.-K. Lee, H.-C. Shimet al., “Eliot: End-to-end lidar odometry using 3-d transformer frameworks,”arXiv preprint arXiv:2307.11998, 2023
arXiv 2023
-
[16]
L. Han, Y . Lin, G. Du, and S. Lian, “Deepvio: Self- supervised deep learning of monocular visual inertial odometry using 3d geometric constraints,” 2019. [Online]. Available: https://arxiv.org/abs/1906.11435
Pith/arXiv arXiv 2019
-
[17]
A2do: Adaptive anti-degradation odometry with deep multi-sensor fusion for autonomous navigation,
H. Lai, Q. Chen, J. Zhang, and J. Pu, “A2do: Adaptive anti-degradation odometry with deep multi-sensor fusion for autonomous navigation,” arXiv preprint arXiv:2502.20767, 2025
arXiv 2025
-
[18]
Rangenet++: Fast and accurate lidar semantic segmentation,
A. Milioto, I. Vizzo, J. Behley, and C. Stachniss, “Rangenet++: Fast and accurate lidar semantic segmentation,” in2019 IEEE/RSJ international conference on intelligent robots and systems (IROS). IEEE, 2019, pp. 4213–4220
2019
-
[19]
Bevfusion: A simple and robust lidar-camera fusion framework,
T. Liang, H. Xie, K. Yu, Z. Xia, Z. Lin, Y . Wang, T. Tang, B. Wang, and Z. Tang, “Bevfusion: A simple and robust lidar-camera fusion framework,”Advances in neural information processing systems, vol. 35, pp. 10 421–10 434, 2022
2022
-
[20]
Gate-variants of gated recurrent unit (gru) neural networks,
R. Dey and F. M. Salem, “Gate-variants of gated recurrent unit (gru) neural networks,” in2017 IEEE 60th international midwest symposium on circuits and systems (MWSCAS). IEEE, 2017, pp. 1597–1600
2017
-
[21]
Deep residual learning for image recognition,
K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” inProceedings of the IEEE conference on computer vision and pattern recognition, 2016, pp. 770–778
2016
-
[22]
Rethinking raft for efficient optical flow,
N. Eslami, F. Arefi, A. M. Mansourian, and S. Kasaei, “Rethinking raft for efficient optical flow,” in2024 13th Iranian/3rd International Machine Vision and Image Processing Conference (MVIP). IEEE, 2024, pp. 1–7
2024
-
[23]
Mamba: Linear-time sequence modeling with selective state spaces,
A. Gu and T. Dao, “Mamba: Linear-time sequence modeling with selective state spaces,” inFirst conference on language modeling, 2024
2024
-
[24]
Attention is all you need,
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin, “Attention is all you need,” Advances in neural information processing systems, vol. 30, 2017
2017
-
[25]
Multi-task learning using uncertainty to weigh losses for scene geometry and semantics,
A. Kendall, Y . Gal, and R. Cipolla, “Multi-task learning using uncertainty to weigh losses for scene geometry and semantics,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2018, pp. 7482–7491
2018
-
[26]
Y . Han, Z. Liu, S. Sun, D. Li, J. Sun, C. Yuan, and M. H. Ang Jr, “Carla-loc: synthetic slam dataset with full-stack sensor setup in challenging weather and dynamic environments,”arXiv preprint arXiv:2309.08909, 2023
arXiv 2023
-
[27]
Vision meets robotics: The kitti dataset,
A. Geiger, P. Lenz, C. Stiller, and R. Urtasun, “Vision meets robotics: The kitti dataset,”The international journal of robotics research, vol. 32, no. 11, pp. 1231–1237, 2013
2013
-
[28]
evo: Python package for the evaluation of odometry and slam,
M. Grupp, “evo: Python package for the evaluation of odometry and slam,” https://github.com/MichaelGrupp/evo, 2017, accessed: 2026- 02-24
2017
-
[29]
Lio-sam: Tightly-coupled lidar inertial odometry via smoothing and mapping,
T. Shan, B. Englot, D. Meyers, W. Wang, C. Ratti, and D. Rus, “Lio-sam: Tightly-coupled lidar inertial odometry via smoothing and mapping,” in2020 IEEE/RSJ international conference on intelligent robots and systems (IROS). IEEE, 2020, pp. 5135–5142
2020
-
[30]
Atvio: Attention guided visual-inertial odometry,
L. Liu, G. Li, and T. H. Li, “Atvio: Attention guided visual-inertial odometry,” inICASSP 2021-2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2021, pp. 4125–4129
2021
-
[31]
Learning selective sensor fusion for state estimation,
C. Chen, S. Rosa, C. X. Lu, B. Wang, N. Trigoni, and A. Markham, “Learning selective sensor fusion for state estimation,”IEEE Trans- actions on Neural Networks and Learning Systems, vol. 36, no. 3, pp. 4103–4117, 2025
2025
-
[32]
Fast-lio2: Fast direct lidar- inertial odometry,
W. Xu, Y . Cai, D. He, J. Lin, and F. Zhang, “Fast-lio2: Fast direct lidar- inertial odometry,”IEEE Transactions on Robotics, vol. 38, no. 4, pp. 2053–2073, 2022
2053
-
[33]
LOAM: Lidar odometry and mapping in real- time,
J. Zhang and S. Singh, “LOAM: Lidar odometry and mapping in real- time,” inRobotics: Science and Systems (RSS), 2014
2014
-
[34]
Orb-slam3: An accurate open-source library for visual, visual–inertial, and multimap slam,
C. Campos, R. Elvira, J. J. G. Rodr ´ıguez, J. M. Montiel, and J. D. Tard ´os, “Orb-slam3: An accurate open-source library for visual, visual–inertial, and multimap slam,”IEEE transactions on robotics, vol. 37, no. 6, pp. 1874–1890, 2021
2021
-
[35]
A general optimisation-based framework for global pose estimation with multiple sensors,
T. Qin, S. Cao, J. Pan, and S. Shen, “A general optimisation-based framework for global pose estimation with multiple sensors,”IET Cyber-Systems and Robotics, vol. 7, no. 1, p. e70023, 2025
2025
-
[36]
P. Veli ˇckovi´c, G. Cucurull, A. Casanova, A. Romero, P. Lio, and Y . Bengio, “Graph attention networks,”arXiv preprint arXiv:1710.10903, 2017
Pith/arXiv arXiv 2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.