TheoremGraph: Bridging Formal and Informal Mathematics
Pith reviewed 2026-06-25 20:44 UTC · model grok-4.3
The pith
TheoremGraph builds one statement-level dependency graph that spans informal arXiv papers and formal Lean libraries.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
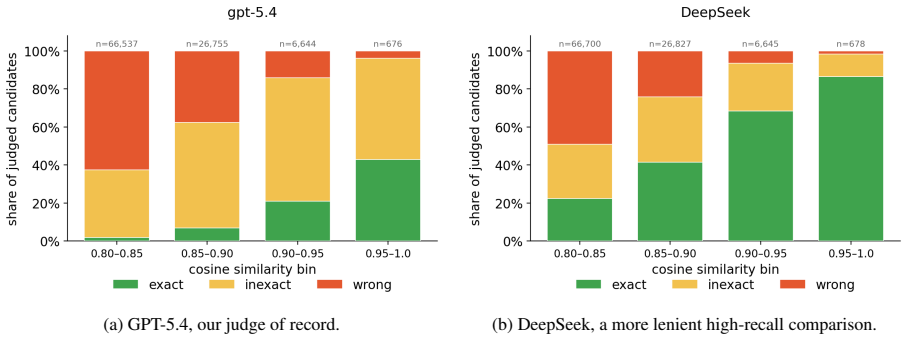
TheoremGraph is a unified statement-level dependency graph spanning both informal and formal mathematics, constructed by parsing arXiv to recover 18.3M candidate directed dependencies labeled by extractor, extracting 388,105 nodes and 11.3M edges via a Lean 4 elaborator, and bridging the domains by embedding generated natural-language slogans to produce 47,952 LLM-affirmed matches above a 0.8 cosine threshold with acceptance rising to 87 percent at 0.9.
What carries the argument
TheoremGraph, the unified statement-level dependency graph that links informal extractions and formal Lean graphs through slogan embeddings in a shared semantic space.
Load-bearing premise
The candidate directed dependencies from the informal extractors and the LLM-accepted cross-matches are accurate enough to support downstream search and reasoning tasks without substantial noise or systematic error.
What would settle it
A manual audit of 100 randomly sampled matches from the 0.8-0.9 cosine tier that finds an acceptance rate below 70 percent would show the bridging links are too noisy for reliable use.
Figures








read the original abstract
Mathematical knowledge is organized around statements and their dependencies, but this structure is exposed unevenly: informal papers cite mostly at the document level, while formal libraries record fine-grained dependencies over a much smaller body of mathematics. We introduce TheoremGraph, a unified statement-level dependency graph spanning both informal and formal mathematics. On the informal side, we parse 11.7M theorem-like environments from mathematics arXiv and recover 18.3M candidate directed dependencies, each labeled by the extractor that proposed it so downstream users can trade coverage for precision. On the formal side, we release LeanGraph, a Lean 4 elaborator-level extractor producing 388,105 declaration nodes and 11.3M typed edges across 25 Lean projects. We bridge the two graphs by embedding generated natural-language slogans into a shared semantic space, linking related statements across papers and across the informal/formal divide; an LLM judge affirms 47,952 such matches above a 0.8 cosine floor, with the judge-acceptance rate rising from 48% across the floor to 87% in the >=0.9 tier. On formal concept retrieval, our name-and-signature representation with graph expansion comes within 0.5pp of LeanSearch v2's reranked Recall@10 (0.775 vs. 0.780) without an LM reranker. We release the dataset, extractors, HTTP API, and MCP interface as infrastructure for mathematical search, attribution, and retrieval-augmented reasoning, available at theoremsearch.com and huggingface.co/datasets/uw-math-ai/theorem-matching.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces TheoremGraph, a unified statement-level dependency graph spanning informal mathematics (parsed from 11.7M theorem-like environments in arXiv yielding 18.3M candidate directed dependencies) and formal mathematics (via the released LeanGraph extractor producing 388,105 nodes and 11.3M typed edges across 25 Lean projects). Informal-formal bridging is performed by embedding generated slogans into a shared space and applying an LLM judge to affirm 47,952 matches above a 0.8 cosine threshold (with acceptance rising from 48% to 87% in the >=0.9 tier). A retrieval evaluation shows the name-and-signature representation with graph expansion achieving 0.775 Recall@10 on formal concept retrieval, within 0.5pp of LeanSearch v2 without an LM reranker. The dataset, extractors, HTTP API, and MCP interface are released at theoremsearch.com and Hugging Face.
Significance. If the extracted dependencies and cross-matches prove sufficiently accurate, TheoremGraph would supply useful shared infrastructure for mathematical search, attribution, and retrieval-augmented reasoning. The explicit labeling of candidate dependencies by extractor (allowing users to trade coverage for precision), the release of the Lean 4 elaborator-level extractor, the public API, and the reproducible retrieval baseline are concrete strengths supporting downstream use and verification.
major comments (1)
- [Abstract] Abstract: The central claim that TheoremGraph supplies a usable unified dependency graph for search and RAG tasks rests on the premise that the 18.3M informal candidates and 47,952 LLM-accepted matches contain acceptably low noise. However, the manuscript reports only the tiered judge-acceptance rate and a single downstream Recall@10 figure; it provides no precision, recall, or human-validated accuracy metrics for either the informal dependency extractors or the slogan-embedding matches against any gold-standard set. This validation gap directly affects whether the released graph can be treated as reliable infrastructure.
minor comments (1)
- The retrieval comparison (0.775 vs. 0.780 Recall@10) is presented without error bars, variance estimates, or statistical significance testing, which would clarify whether the 0.5pp gap is meaningful.
Simulated Author's Rebuttal
We thank the referee for the careful review and for emphasizing the need for stronger validation evidence. We address the single major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that TheoremGraph supplies a usable unified dependency graph for search and RAG tasks rests on the premise that the 18.3M informal candidates and 47,952 LLM-accepted matches contain acceptably low noise. However, the manuscript reports only the tiered judge-acceptance rate and a single downstream Recall@10 figure; it provides no precision, recall, or human-validated accuracy metrics for either the informal dependency extractors or the slogan-embedding matches against any gold-standard set. This validation gap directly affects whether the released graph can be treated as reliable infrastructure.
Authors: We acknowledge that the manuscript does not report direct precision or recall figures against gold-standard annotations for the dependency extractors or the LLM-validated matches. The design instead labels every candidate dependency by its source extractor, explicitly enabling users to select higher-precision subsets, and reports tiered LLM-judge acceptance rates (48% overall, rising to 87% at cosine ≥0.9) together with competitive downstream retrieval performance. These choices reflect the scale of the data (18.3 M candidates) and the absence of existing gold standards at this breadth. We agree that human-validated accuracy metrics would strengthen the infrastructure claim and will add a targeted human evaluation on sampled dependencies and matches in the revision. revision: yes
Circularity Check
Data-construction paper; no derivations or self-referential predictions
full rationale
The manuscript describes a pipeline that parses arXiv papers, extracts candidate dependencies, embeds slogans, applies an LLM judge to accept matches above a cosine threshold, and releases the resulting graph plus LeanGraph. All reported quantities (18.3M candidates, 47,952 matches, acceptance rates 48%→87%, Recall@10 0.775) are direct outputs of this construction process rather than predictions derived from fitted parameters or prior self-citations. No equations, uniqueness theorems, or ansatzes are invoked that reduce to the inputs by definition. The central claim is the release of the dataset and tools; it does not rest on any load-bearing self-citation chain or renaming of known results. This is the normal, non-circular outcome for an infrastructure paper.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Akiko Aizawa, Michael Kohlhase, Iadh Ounis, and Moritz Schubotz. 2014. Ntcir-11 math-2 task overview
2014
-
[2]
Jesse Alama, Lionel Mamane, and Josef Urban. 2012. https://arxiv.org/abs/1109.3687 Dependencies in formal mathematics: Applications and extraction for Coq and Mizar . Preprint, arXiv:1109.3687
Pith/arXiv arXiv 2012
-
[3]
Luke Alexander, Eric Leonen, Sophie Szeto, Artemii Remizov, Ignacio Tejeda, Jarod Alper, Giovanni Inchiostro, and Vasily Ilin. 2026. https://arxiv.org/abs/2602.05216 Semantic search over 9 million mathematical theorems . arXiv preprint
arXiv 2026
-
[4]
Artifex Software, Inc. 2026. https://pymupdf.readthedocs.io/en/latest/ PyMuPDF Documentation . Accessed: 2026-06-22
2026
-
[5]
Michael Artin. 2011. Algebra, 2 edition. Pearson
2011
-
[6]
Andrej Bauer, Matej Petković, and Ljupčo Todorovski. 2023. https://arxiv.org/abs/2310.16005 Mlfmf: Data sets for machine learning for mathematical formalization . Preprint, arXiv:2310.16005
arXiv 2023
-
[7]
Carl Bergstrom. 2007. https://doi.org/10.5860/crln.68.5.7804 Eigenfactor: Measuring the value and prestige of scholarly journals . College and Research Libraries News, 68(5):314--316
-
[8]
Rong Bian, Yu Geng, Zijian Yang, and Bing Cheng. 2025. https://arxiv.org/abs/2505.13406 Automathkg: The automated mathematical knowledge graph based on llm and vector database . Preprint, arXiv:2505.13406
arXiv 2025
-
[9]
Lukas Blecher, Guillem Cucurull, Thomas Scialom, and Robert Stojnic. 2023. https://arxiv.org/abs/2308.13418 Nougat: Neural optical understanding for academic documents . Preprint, arXiv:2308.13418
Pith/arXiv arXiv 2023
-
[10]
Jiangjie Chen, Wenxiang Chen, Jiacheng Du, Jinyi Hu, Zhicheng Jiang, Allan Jie, Xiaoran Jin, Xing Jin, Chenggang Li, Wenlei Shi, Zhihong Wang, Mingxuan Wang, Chenrui Wei, Shufa Wei, Huajian Xin, Fan Yang, Weihao Gao, Zheng Yuan, Tianyang Zhan, and 3 others. 2025. https://arxiv.org/abs/2512.17260 Seed-prover 1.5: Mastering undergraduate-level theorem provi...
arXiv 2025
-
[11]
frenzymath . 2024. jixia: A static analysis tool for lean 4. https://github.com/frenzymath/jixia. GitHub repository, accessed 2026-05-23
2024
-
[12]
Guoxiong Gao, Haocheng Ju, Jiedong Jiang, Zihan Qin, and Bin Dong. 2025. https://arxiv.org/abs/2403.13310 A semantic search engine for mathlib4 . Preprint, arXiv:2403.13310
arXiv 2025
-
[13]
Guoxiong Gao, Zeming Sun, Jiedong Jiang, Yutong Wang, Jingda Xu, Peihao Wu, Bryan Dai, and Bin Dong. 2026. https://arxiv.org/abs/2605.13137 Leansearch v2: Global premise retrieval for lean 4 theorem proving . Preprint, arXiv:2605.13137
Pith/arXiv arXiv 2026
-
[14]
Eugene Garfield. 1972. https://doi.org/10.1126/science.178.4060.471 Citation analysis as a tool in journal evaluation . Science, 178(4060):471--479
-
[15]
Xiaojun Guo, Ang Li, Yifei Wang, Stefanie Jegelka, and Yisen Wang. 2025. https://arxiv.org/abs/2505.18499 G1: Teaching llms to reason on graphs with reinforcement learning . Preprint, arXiv:2505.18499
arXiv 2025
-
[16]
J. E. Hirsch. 2005. https://doi.org/10.1073/pnas.0507655102 An index to quantify an individual's scientific research output . Proceedings of the National Academy of Sciences, 102(46):16569--16572
-
[17]
Jonas Hübotter, Frederike Lübeck, Lejs Behric, Anton Baumann, Marco Bagatella, Daniel Marta, Ido Hakimi, Idan Shenfeld, Thomas Kleine Buening, Carlos Guestrin, and Andreas Krause. 2026. https://arxiv.org/abs/2601.20802 Reinforcement learning via self-distillation . Preprint, arXiv:2601.20802
Pith/arXiv arXiv 2026
-
[18]
Vladimir Karpukhin, Barlas Oğuz, Sewon Min, Patrick Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, and Wen tau Yih. 2020. https://arxiv.org/abs/2004.04906 Dense passage retrieval for open-domain question answering . Preprint, arXiv:2004.04906
Pith/arXiv arXiv 2020
-
[19]
Lean FRO . 2026. https://github.com/leanprover/lean4export lean4export : Plain-text declaration export for lean 4 . GitHub repository. Accessed: 2026-05-25
2026
-
[20]
Lean Prover Community . 2026. https://github.com/leanprover/doc-gen4 doc-gen4 : Document generator for lean 4 . Accessed May 25, 2026
2026
-
[21]
Xinze Li, Nanyun Peng, Simone Severini, and Patrick Shafto. 2026. https://arxiv.org/abs/2604.24797 The network structure of mathlib . Preprint, arXiv:2604.24797
Pith/arXiv arXiv 2026
-
[22]
Minhua Lin, Zongyu Wu, Zhichao Xu, Hui Liu, Xianfeng Tang, Qi He, Charu Aggarwal, Hui Liu, Xiang Zhang, and Suhang Wang. 2025. https://arxiv.org/abs/2510.16724 A comprehensive survey on reinforcement learning-based agentic search: Foundations, roles, optimizations, evaluations, and applications . Preprint, arXiv:2510.16724
arXiv 2025
-
[23]
Junqi Liu, Zihao Zhou, Zekai Zhu, Marco Dos Santos, Weikun He, Jiawei Liu, Ran Wang, Yunzhou Xie, Junqiao Zhao, Qiufeng Wang, Lihong Zhi, Jia Li, and Wenda Li. 2026. https://arxiv.org/abs/2601.14027 Numina-lean-agent: An open and general agentic reasoning system for formal mathematics . Preprint, arXiv:2601.14027
arXiv 2026
-
[24]
Yu. A. Malkov and D. A. Yashunin. 2018. https://arxiv.org/abs/1603.09320 Efficient and robust approximate nearest neighbor search using hierarchical navigable small world graphs . Preprint, arXiv:1603.09320
Pith/arXiv arXiv 2018
-
[25]
Behrooz Mansouri, V\' t Novotn\' y , Anurag Agarwal, Douglas W. Oard, and Richard Zanibbi. 2022. https://doi.org/10.1007/978-3-031-13643-6_20 Overview of arqmath-3 (2022): Third clef lab on answer retrieval for questions on math . In Experimental IR Meets Multilinguality, Multimodality, and Interaction: 13th International Conference of the CLEF Associatio...
-
[26]
Patrick Massot. 2020. leanblueprint: A plastex plugin for writing blueprints of lean formalization projects. https://github.com/PatrickMassot/leanblueprint. GitHub repository; originally developed for the Sphere Eversion Project. Accessed 2026-05-26
2020
-
[27]
Mathpix . 2026. Mathpix Markdown : Markdown for math and science. https://mathpix.com/mathpix-markdown. Accessed: 2026-06-22
2026
-
[28]
Shrey Mishra, Yacine Brihmouche, Th\' e o Delemazure, Antoine Gauquier, and Pierre Senellart. 2024. https://aclanthology.org/2024.sdp-1.16 First steps in building a knowledge base of mathematical results . In Proceedings of the Fourth Workshop on Scholarly Document Processing
2024
-
[29]
Azim Ospanov, Farzan Farnia, and Roozbeh Yousefzadeh. 2025. https://arxiv.org/abs/2511.03108 minif2f-lean revisited: Reviewing limitations and charting a path forward . Preprint, arXiv:2511.03108
arXiv 2025
-
[30]
Gabriel Pinski and Francis Narin. 1976. https://doi.org/10.1016/0306-4573(76)90048-0 Citation influence for journal aggregates of scientific publications: Theory, with application to the literature of physics . Information Processing and Management, 12(5):297--312
-
[31]
Stanislas Polu and Ilya Sutskever. 2020. https://arxiv.org/abs/2009.03393 Generative language modeling for automated theorem proving . Preprint, arXiv:2009.03393
Pith/arXiv arXiv 2020
-
[32]
Delip Rao, Jonathan Young, Thomas Dietterich, and Chris Callison-Burch. 2024. https://arxiv.org/abs/2412.03775 Withdrarxiv: A large-scale dataset for retraction study . Preprint, arXiv:2412.03775
arXiv 2024
-
[33]
Borja Requena, Austin Letson, Krystian Nowakowski, Izan Beltran-Ferreiro, and Leopoldo Sarra. 2026. https://arxiv.org/abs/2602.24273 A minimal agent for automated theorem proving . Preprint, arXiv:2602.24273
Pith/arXiv arXiv 2026
-
[34]
Christian Steinfeldt and Helena Mihaljevi\' c . 2024. https://doi.org/10.1007/978-3-031-66997-2_14 Evaluation and domain adaptation of similarity models for short mathematical texts . In Intelligent Computer Mathematics: 17th International Conference, CICM 2024, Montr\' e al, QC, Canada, August 5–9, 2024, Proceedings , page 241–260, Berlin, Heidelberg. Sp...
-
[35]
Qwen Team. 2025. https://arxiv.org/abs/2505.09388 Qwen3 technical report . Preprint, arXiv:2505.09388
Pith/arXiv arXiv 2025
-
[36]
George Tsoukalas, Jasper Lee, John Jennings, Jimmy Xin, Michelle Ding, Michael Jennings, Amitayush Thakur, and Swarat Chaudhuri. 2024. https://arxiv.org/abs/2407.11214 Putnambench: Evaluating neural theorem-provers on the putnam mathematical competition . Preprint, arXiv:2407.11214
arXiv 2024
-
[37]
Dylan Walker, Huafeng Xie, Koon-Kiu Yan, and Sergei Maslov. 2007. https://doi.org/10.1088/1742-5468/2007/06/p06010 Ranking scientific publications using a model of network traffic . Journal of Statistical Mechanics: Theory and Experiment, 2007(06):P06010–P06010
-
[38]
Sean Welleck, Jiacheng Liu, Ronan Le Bras, Hannaneh Hajishirzi, Yejin Choi, and Kyunghyun Cho. 2021. https://arxiv.org/abs/2104.01112 Naturalproofs: Mathematical theorem proving in natural language . Preprint, arXiv:2104.01112
arXiv 2021
-
[39]
Banri Yanahama and Akiyoshi Sannai. 2026. https://arxiv.org/abs/2604.16347 Lean atlas: An integrated proof environment for scalable human-ai collaborative formalization . Preprint, arXiv:2604.16347
Pith/arXiv arXiv 2026
-
[40]
Kaiyu Yang, Aidan M. Swope, Alex Gu, Rahul Chalamala, Peiyang Song, Shixing Yu, Saad Godil, Ryan Prenger, and Anima Anandkumar. 2023. https://arxiv.org/abs/2306.15626 Leandojo: Theorem proving with retrieval-augmented language models . Preprint, arXiv:2306.15626
arXiv 2023
-
[41]
Richard Zanibbi, Akiko Aizawa, Michael Kohlhase, Iadh Ounis, Goran Topic, and Kenny Davila. 2016. https://api.semanticscholar.org/CorpusID:9102694 Ntcir-12 mathir task overview . In NTCIR Conference on Evaluation of Information Access Technologies
2016
-
[42]
Richard Zanibbi, Kenny Davila, Andrew Kane, and Frank Tompa. 2015. https://arxiv.org/abs/1507.06235 The tangent search engine: Improved similarity metrics and scalability for math formula search . Preprint, arXiv:1507.06235
Pith/arXiv arXiv 2015
-
[43]
Yanzhao Zhang, Mingxin Li, Dingkun Long, Xin Zhang, Huan Lin, Baosong Yang, Pengjun Xie, An Yang, Dayiheng Liu, Junyang Lin, Fei Huang, and Jingren Zhou. 2025 a . https://arxiv.org/abs/2506.05176 Qwen3 embedding: Advancing text embedding and reranking through foundation models . Preprint, arXiv:2506.05176
Pith/arXiv arXiv 2025
-
[44]
Yizhuo Zhang, Heng Wang, Shangbin Feng, Zhaoxuan Tan, Xinyun Liu, and Yulia Tsvetkov. 2025 b . https://arxiv.org/abs/2506.00845 Generalizable llm learning of graph synthetic data with post-training alignment . Preprint, arXiv:2506.00845
arXiv 2025
-
[45]
Kunhao Zheng, Jesse Michael Han, and Stanislas Polu. 2022. https://arxiv.org/abs/2109.00110 Minif2f: a cross-system benchmark for formal olympiad-level mathematics . Preprint, arXiv:2109.00110
Pith/arXiv arXiv 2022
-
[46]
Karol Zyczkowski. 2009. https://doi.org/10.1007/s11192-010-0208-6 Citation graph, weighted impact factors and performance indices . Scientometrics, 85
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.