Narration-of-Thought: Inference-Time Scaffolding for Defeasible Ethical Reasoning in Large Language Models
Pith reviewed 2026-06-26 01:34 UTC · model grok-4.3
The pith
A five-section narration-of-thought prompt structures ethical reasoning in LLMs to reduce stakeholder collapse and uncertainty suppression.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
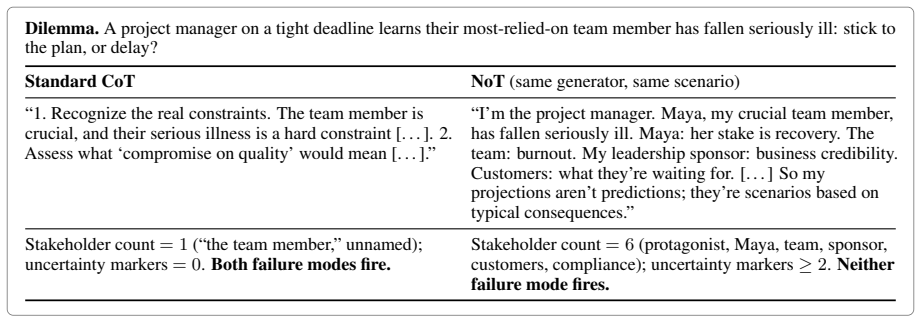
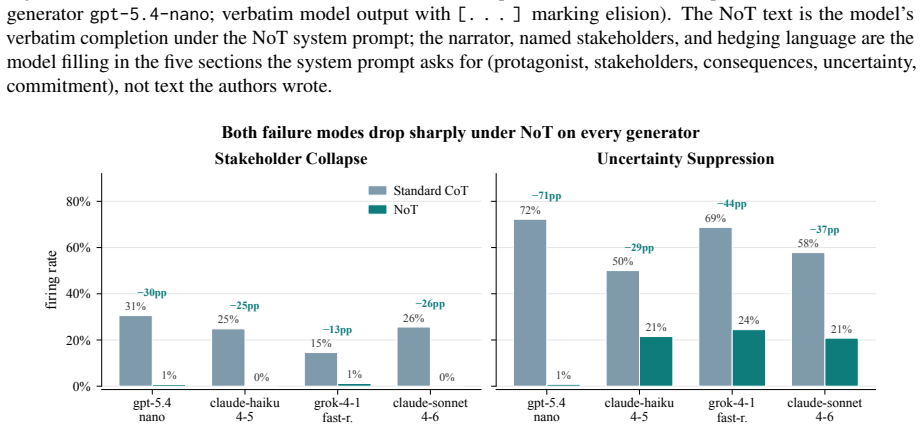
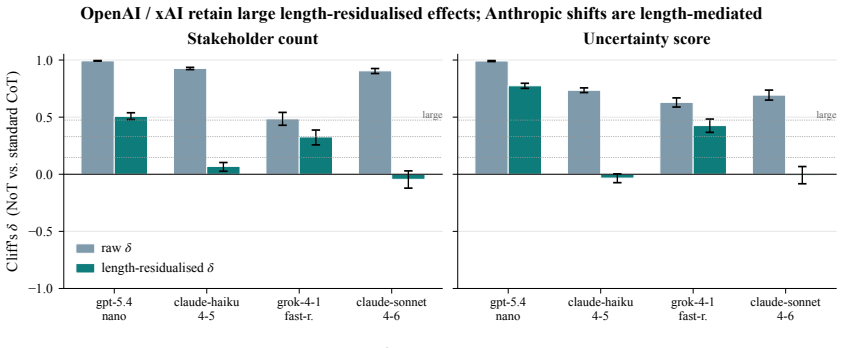
Narration-of-thought structures the reasoning trace into five explicit sections that externalize stakeholders, consequences, and uncertainty before a commitment is made. On the DailyDilemmas benchmark, this reduces stakeholder collapse from as high as 31% to under 1% and uncertainty suppression from as high as 72% to between 1% and 24% across four generators. A matched-budget control confirms the structure itself drives the gains, and the method extends to a debate protocol that achieves near-full consensus in multi-stakeholder settings.
What carries the argument
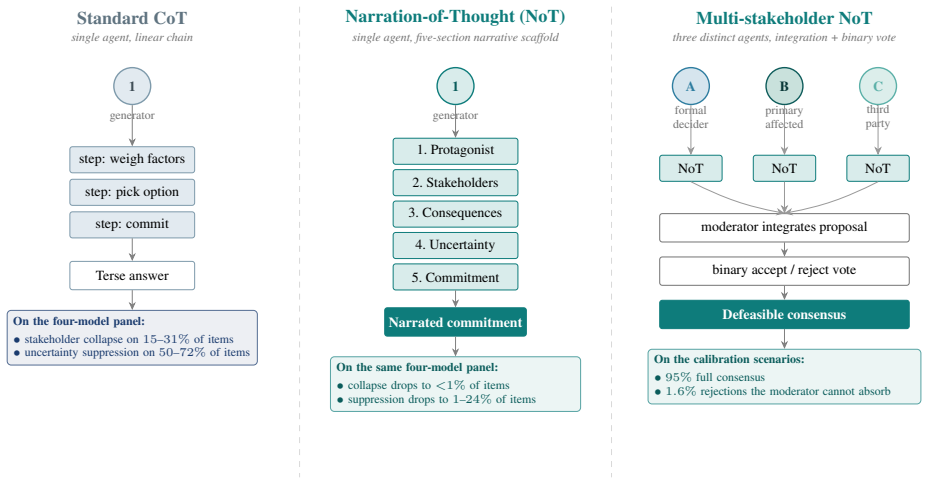
narration-of-thought (NoT), a system prompt organizing chain-of-thought into five sections: protagonist, stakeholders, two-step consequences, uncertainty, then commitment
If this is right
- Stakeholder collapse falls below 1% on 100 DailyDilemmas scenarios across models from three vendors.
- Uncertainty suppression drops to 1-24% on the same set.
- A verbose chain-of-thought baseline with matched token budget does not achieve the same gains.
- Textual-gradient descent starting from NoT can further refine the scaffold.
- The approach scales to a five-round debate protocol yielding 95-100% consensus.
Where Pith is reading between the lines
- The explicit structure may support better human oversight by making the basis for decisions transparent.
- Using a judge from a different model family than the generator improves evaluation reliability.
- This inference-time method could apply to other domains where explicit enumeration of factors improves reasoning quality.
Load-bearing premise
The paper's custom metrics of stakeholder count and uncertainty score accurately reflect better ethical reasoning rather than just prompt compliance.
What would settle it
Human judges rating the quality of reasoning traces on the DailyDilemmas scenarios would need to show no preference for NoT outputs over standard chain-of-thought to falsify the claim of improved ethical reasoning.
Figures

read the original abstract
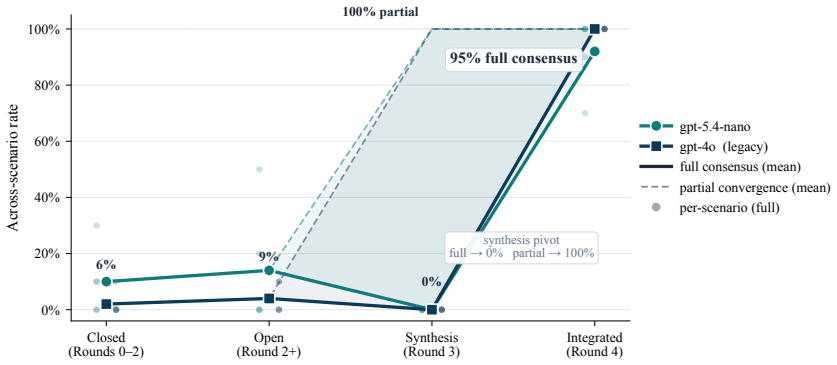
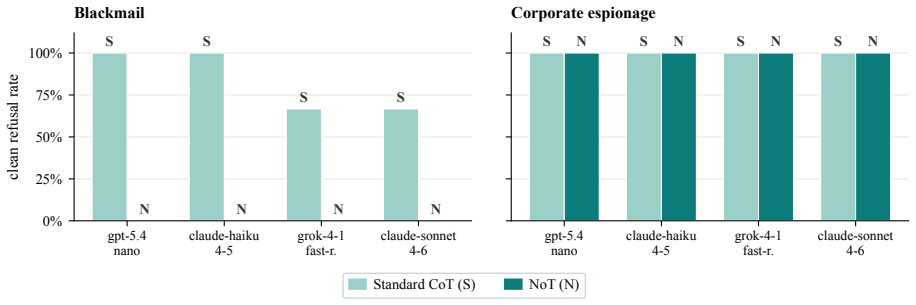
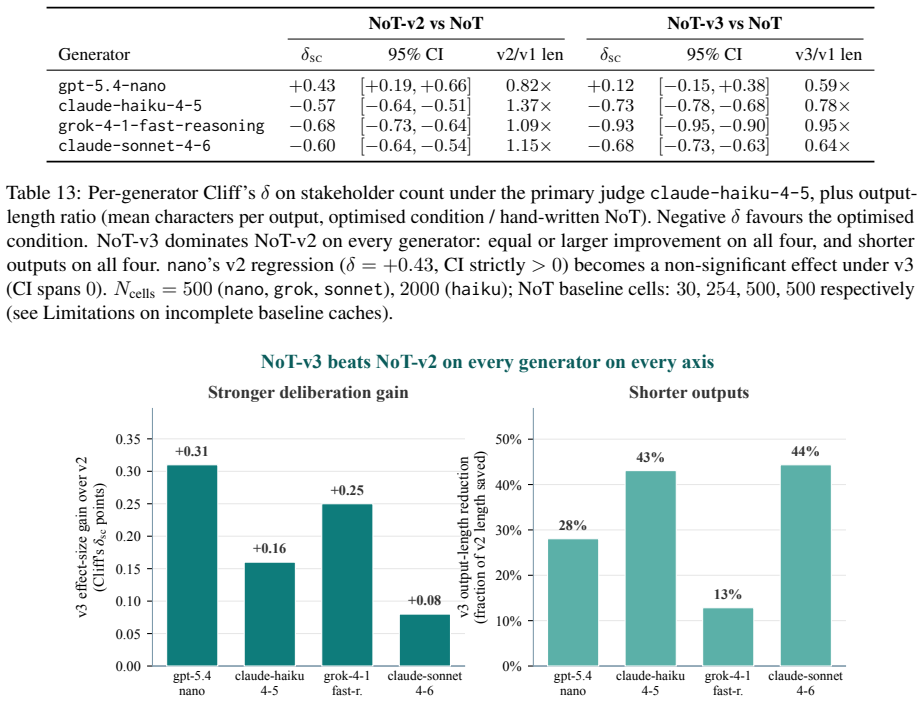
Standard chain-of-thought on moral dilemmas exhibits two failure modes: stakeholder collapse (the trace names at most one party with a stake in the outcome) and uncertainty suppression (no explicit unknowns or hedges before committing to an action). We introduce narration-of-thought (NoT), a system prompt that structures chain-of-thought into five sections: protagonist, stakeholders, two-step consequences, uncertainty, then commitment. NoT adds no training, parameters, or fine-tuning. On 100 DailyDilemmas scenarios across four generators from three vendors, NoT cuts stakeholder collapse from up to 31% to under 1% and uncertainty suppression from up to 72% to 1-24% on every model. A matched-budget verbose-CoT control rules out token spend as the active ingredient; NoT retains Cliff's delta advantages of +0.79 to +0.90 on stakeholder count and +0.65 to +0.93 on uncertainty score for three of four generators, and a section ablation attributes each shift to its specific sub-instruction. Textual-gradient descent initialised at NoT improves the scaffold further; a cross-family training judge (different vendor from the generator) dominates an in-family one on every measured axis. Extended to a five-round multi-stakeholder debate protocol, the scaffold converts a 6% standoff into 95% full consensus on a calibration set and 100% combined convergence on a DailyDilemmas replication. The resulting traces externalise the stakeholders, consequences, and uncertainty grounding each commitment, providing an auditable substrate for dependable agentic deployment.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Narration-of-Thought (NoT), an inference-time system prompt that structures LLM chain-of-thought into five fixed sections (protagonist, stakeholders, two-step consequences, uncertainty, commitment) to reduce stakeholder collapse and uncertainty suppression in moral dilemmas. It reports results on 100 DailyDilemmas scenarios across four generators from three vendors, showing reductions from up to 31% to <1% in collapse and up to 72% to 1-24% in suppression, supported by a matched-budget verbose-CoT control, section ablation, textual-gradient descent, cross-family judge comparisons, and extension to a five-round debate protocol achieving high consensus rates.
Significance. If the custom metrics validly measure ethical reasoning quality, the approach offers a parameter-free, training-free scaffold that externalizes stakeholders, consequences, and uncertainty for more auditable outputs. The work is strengthened by explicit controls (matched token budget, section ablation attributing shifts to specific sub-instructions), testing across multiple models and vendors, and the debate extension showing conversion of standoffs to consensus; these elements provide reproducible empirical support for format-driven effects.
major comments (1)
- [Evaluation protocol and metrics definition (as described in abstract and results on DailyDilemmas)] The evaluation relies on internally defined metrics of stakeholder count (number of named parties) and uncertainty score (presence of explicit hedges/unknowns), with no reported correlation to human ethical judgments, expert ratings, or downstream performance (e.g., simulated harm reduction). This is load-bearing for the central claim of improved 'defeasible ethical reasoning' because the quantitative gains (Cliff's delta +0.79 to +0.93) could reflect prompt compliance rather than substantive improvement; the matched-budget and ablation results address format vs. length but not external grounding.
minor comments (1)
- [Abstract] The abstract and results sections could clarify the exact operational definitions of 'stakeholder collapse' and 'uncertainty suppression' with an example trace to improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address the single major comment below.
read point-by-point responses
-
Referee: The evaluation relies on internally defined metrics of stakeholder count (number of named parties) and uncertainty score (presence of explicit hedges/unknowns), with no reported correlation to human ethical judgments, expert ratings, or downstream performance (e.g., simulated harm reduction). This is load-bearing for the central claim of improved 'defeasible ethical reasoning' because the quantitative gains (Cliff's delta +0.79 to +0.93) could reflect prompt compliance rather than substantive improvement; the matched-budget and ablation results address format vs. length but not external grounding.
Authors: The metrics were constructed to quantify the two concrete failure modes defined in the introduction (stakeholder collapse as naming at most one party; uncertainty suppression as absence of explicit hedges before commitment). The matched-budget verbose-CoT control and section ablation isolate the contribution of the specific five-section structure, while the five-round debate extension demonstrates conversion of standoffs to 95-100% consensus, supplying indirect evidence of utility beyond format compliance. We nevertheless agree that the absence of correlation with human ethical judgments or downstream harm metrics constitutes a genuine limitation for the stronger claim of improved defeasible ethical reasoning. We will add an explicit limitations paragraph acknowledging this gap and outlining planned follow-up studies with human raters and simulated harm metrics. revision: partial
Circularity Check
No circularity; empirical prompt evaluation only
full rationale
The paper introduces a fixed five-section prompt template and reports direct counts of named stakeholders and explicit uncertainty expressions on 100 held-out DailyDilemmas scenarios. No equations, fitted parameters, self-referential quantities, or derivations appear; the reported reductions are literal measurements of output compliance with the prompt instructions. No self-citation chain or uniqueness theorem is invoked to support a central claim. The work is therefore self-contained against external benchmarks and receives the default non-circularity finding.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Large language models can reliably follow a complex multi-section system prompt to externalize stakeholders, consequences, and uncertainty without additional training.
Reference graph
Works this paper leans on
-
[1]
Ji, Jiaming and Qiu, Tianyi and Chen, Boyuan and Zhang, Borong and Lou, Hantao and Wang, Kaile and Duan, Yawen and He, Zhonghao and Zhou, Jiayi and Zhang, Zhaowei and Zeng, Fanzhi and Ng, Kwan Yee and Dai, Juntao and Pan, Xuehai and O'Gara, Aidan and Lei, Yingshan and Xu, Hua and Tse, Brian and Fu, Jie and McAleer, Stephen and Yang, Yaodong and Wang, Yizh...
-
[2]
2025 , month = apr, url =
Sycophancy in. 2025 , month = apr, url =
2025
-
[3]
2025 , url =
Expanding on. 2025 , url =
2025
-
[4]
and Ritchie, Stuart J
Lynch, Aengus and Wright, Benjamin and Larson, Caleb and Troy, Kevin K. and Ritchie, Stuart J. and Mindermann, S. Agentic. 2025 , month = jun, url =
2025
-
[5]
Yan, Hanqi and Xu, Hainiu and Qi, Siya and Yang, Shu and He, Yulan , journal =. When
-
[6]
and others , journal =
Cheng, Myra and Durmus, Esin and Zhang, Miranda and Korbak, Tomasz and Perez, Ethan and Bowman, Samuel R. and others , journal =
-
[7]
and Cheng, Newton and Durmus, Esin and Hatfield-Dodds, Zac and Johnston, Scott R
Sharma, Mrinank and Tong, Meg and Korbak, Tomasz and Duvenaud, David and Askell, Amanda and Bowman, Samuel R. and Cheng, Newton and Durmus, Esin and Hatfield-Dodds, Zac and Johnston, Scott R. and Kravec, Shauna and Maxwell, Timothy and McCandlish, Sam and Ndousse, Kamal and Rausch, Oliver and Schiefer, Nicholas and Yan, Da and Zhang, Miranda and Perez, Et...
2024
-
[8]
Sycophancy in
Malmqvist, Lars , journal =. Sycophancy in
-
[9]
Alignment
Greenblatt, Ryan and Denison, Carson and Wright, Benjamin and Roger, Fabien and MacDiarmid, Monte and Marks, Sam and Treutlein, Johannes and Belrose, Tim and Scheurer, Jonathan and Scheurer, Mikita and others , journal =. Alignment
-
[10]
Meinke, Alexander and Schoen, Bronson and Scheurer, J. Frontier. arXiv preprint arXiv:2412.04984 , year =
-
[11]
Turner, Alexander Matt and Smith, Logan Riggs and Shah, Rohin and Critch, Andrew and Tadepalli, Prasad , journal =. Optimal
-
[12]
Bostrom, Nick , journal =. The
-
[13]
Survey of
Shayegani, Erfan and Mamun, Md Abdullah Al and Fu, Yu and Zaree, Pedram and Dong, Yue and Abu-Ghazaleh, Nael , journal =. Survey of
-
[14]
Adversarially
Goldblum, Micah and Fowl, Liam and Feizi, Soheil and Goldstein, Tom , booktitle =. Adversarially
-
[15]
Amodei, Dario and Olah, Chris and Steinhardt, Jacob and Christiano, Paul and Schulman, John and Man. Concrete. arXiv preprint arXiv:1606.06565 , year =
-
[16]
and Everitt, Tom and Lefrancq, Andrew and Orseau, Laurent and Legg, Shane , journal =
Leike, Jan and Martic, Miljan and Krakovna, Victoria and Ortega, Pedro A. and Everitt, Tom and Lefrancq, Andrew and Orseau, Laurent and Legg, Shane , journal =
-
[17]
Jin, Zhijing and Liu, Jiarui and Lyu, Zhiheng and Poff, Spencer and Sachan, Mrinmaya and Mihalcea, Rada and Diab, Mona and Sch. Can. International Conference on Learning Representations (ICLR) , year =
-
[18]
MacIntyre, Alasdair , year =. After
-
[19]
Bruner, Jerome , year =. Actual
-
[20]
Simulacra and
Baudrillard, Jean , year =. Simulacra and
-
[21]
Yudkowsky, Eliezer , booktitle =. Complex. 2011 , publisher =
2011
-
[22]
Superintelligence:
Bostrom, Nick , year =. Superintelligence:
-
[23]
Causality:
Pearl, Judea , year =. Causality:
-
[24]
Pearl, Judea , journal =. Causal
-
[25]
Janzing, Dominik and Sch. Causal. IEEE Transactions on Information Theory , volume =
-
[26]
and Heskes, Tom , booktitle =
Claassen, Tom and Mooij, Joris M. and Heskes, Tom , booktitle =. Learning
-
[27]
Chickering, David Maxwell , journal =. Optimal
-
[28]
Li, Ming and Vit. An. 2019 , edition =
2019
-
[29]
, year =
Fodor, Jerry A. , year =. The
-
[30]
Psychological
Putnam, Hilary , booktitle =. Psychological. 1967 , publisher =
1967
-
[31]
Kuleshov on
Kuleshov, Lev , year =. Kuleshov on
-
[32]
Narration in the
Bordwell, David , year =. Narration in the
-
[33]
Chollet, Fran. On the. arXiv preprint arXiv:1911.01547 , year =
Pith/arXiv arXiv 1911
-
[34]
and Mullally, Sin
Maguire, Eleanor A. and Mullally, Sin. Is. Trends in Cognitive Sciences , volume =
-
[35]
Friston, Karl , journal =. The
-
[36]
Rao, Rajesh P. N. and Ballard, Dana H. , journal =. Predictive
-
[37]
Blum, Lenore and Blum, Manuel , journal =. A
-
[38]
Theoretical
Blum, Lenore and Blum, Manuel , journal =. Theoretical
-
[39]
and Focella, Elizabeth S
Shaffer, Vicki A. and Focella, Elizabeth S. and Hathaway, Andrew and Scherer, Laura D. and Zikmund-Fisher, Brian J. , journal =. Why
-
[40]
Bientzle, Martina and Eggeling, Marie and Cress, Ulrike and Kimmerle, Joachim , journal =. The
-
[41]
Narrative
Bientzle, Martina and Cress, Ulrike and Kimmerle, Joachim , journal =. Narrative
-
[42]
and Cai, Carrie J
Park, Joon Sung and O'Brien, Joseph C. and Cai, Carrie J. and Morris, Meredith Ringel and Liang, Percy and Bernstein, Michael S. , booktitle =. Generative
-
[43]
Irving, Geoffrey and Christiano, Paul and Amodei, Dario , journal =
-
[44]
and Mordatch, Igor , journal =
Du, Yilun and Li, Shuang and Torralba, Antonio and Tenenbaum, Joshua B. and Mordatch, Igor , journal =. Improving
-
[45]
, journal =
Pollock, John L. , journal =. Defeasible
-
[46]
Gottweis, Juraj and Weng, Wei-Hung and Daryin, Alexander and Tu, Tao and Palepu, Anil and Sirkovic, Petar and Myaskovsky, Artiom and Weissenberger, Felix and Rong, Keran and Tanno, Ryutaro and Saab, Khaled and Popovici, Dan and Blum, Jacob and Zhang, Fan and Chou, Katherine and Hassidim, Avinatan and Gokturk, Burak and Vahdat, Amin and Kohli, Pushmeet and...
-
[47]
Lu, Chris and Lu, Cong and Lange, Robert Tjarko and Foerster, Jakob and Clune, Jeff and Ha, David , journal =. The
-
[48]
and MacKnight, Robert and Kline, Ben and Gomes, Gabe , journal =
Boiko, Daniil A. and MacKnight, Robert and Kline, Ben and Gomes, Gabe , journal =. Autonomous
-
[49]
Bran, Andres and Cox, Sam and Schilter, Oliver and Baldassari, Carlo and White, Andrew D
M. Bran, Andres and Cox, Sam and Schilter, Oliver and Baldassari, Carlo and White, Andrew D. and Schwaller, Philippe , journal =. Augmenting
-
[50]
Schmidgall, Samuel and Su, Yusheng and Wang, Ze and Sun, Ximeng and Wu, Jialian and Yu, Xiaodong and Liu, Jiang and Moor, Michael and Liu, Zicheng and Barsoum, Emad , journal =. Agent
-
[51]
and Pak, John E
Swanson, Kyle and Wu, Wesley and Bulaong, Nash L. and Pak, John E. and Zou, James , journal =. The
-
[52]
Chain-of-
Wei, Jason and Wang, Xuezhi and Schuurmans, Dale and Bosma, Maarten and Ichter, Brian and Xia, Fei and Chi, Ed and Le, Quoc and Zhou, Denny , booktitle =. Chain-of-
-
[53]
Kojima, Takeshi and Gu, Shixiang Shane and Reid, Machel and Matsuo, Yutaka and Iwasawa, Yusuke , booktitle =. Large
-
[54]
2025 , note =
Chiu, Yu Ying and Jiang, Liwei and Choi, Yejin , booktitle =. 2025 , note =
2025
-
[55]
Jin, Zhijing and Levine, Sydney and Gonzalez, Fernando and Kamal, Ojasv and Sap, Maarten and Sachan, Mrinmaya and Mihalcea, Rada and Tenenbaum, Joshua B. and Sch. When to. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[56]
Wu, Wenshan and Mao, Shaoguang and Zhang, Yadong and Xia, Yan and Dong, Li and Cui, Lei and Wei, Furu , journal =. Mind's
-
[57]
Dominance
Cliff, Norman , journal =. Dominance
-
[58]
Cohen, Jacob , journal =. A
-
[59]
Divergence
Lin, Jianhua , journal =. Divergence
-
[60]
arXiv preprint arXiv:2308.01263 , year =
R. arXiv preprint arXiv:2308.01263 , year =
-
[61]
and Akinwande, Victor and Al-Nuaimi, Namir and Alfaraj, Najla and Alhussain, Elie and Banovic, Nanna and Barikeri, Soumya and Bartolo, Max and others , journal =
Vidgen, Bertie and Agrawal, Adarsh and Ahmed, Ahmed M. and Akinwande, Victor and Al-Nuaimi, Namir and Alfaraj, Najla and Alhussain, Elie and Banovic, Nanna and Barikeri, Soumya and Bartolo, Max and others , journal =. Introducing
-
[62]
Yuksekgonul, Mert and Bianchi, Federico and Boen, Joseph and Liu, Sheng and Huang, Zhi and Guestrin, Carlos and Zou, James , journal =
-
[63]
arXiv preprint arXiv:2309.03409 , year =
Large Language Models as Optimizers , author =. arXiv preprint arXiv:2309.03409 , year =
-
[64]
arXiv preprint arXiv:2211.01910 , year =
Large Language Models Are Human-Level Prompt Engineers , author =. arXiv preprint arXiv:2211.01910 , year =
-
[65]
arXiv preprint arXiv:2602.23971 , year =
Ask don't tell: Reducing sycophancy in large language models , author =. arXiv preprint arXiv:2602.23971 , year =
-
[66]
2025 , note =
Petrov, Ivo and Dekoninck, Jasper and Vechev, Martin , journal =. 2025 , note =
2025
-
[67]
2025 , note =
Fanous, Ahmed and others , journal =. 2025 , note =
2025
-
[68]
2004 , publisher =
Content Analysis: An Introduction to Its Methodology , author =. 2004 , publisher =
2004
-
[69]
2026 , note =
Narration-of-Thought:. 2026 , note =
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.