PressMimic: Pressure-Guided Motion Capture and Control for Humanoid Robot Imitation
Pith reviewed 2026-06-26 05:07 UTC · model grok-4.3
The pith
Pressure readings from the floor resolve vision ambiguities and enforce stable contacts when humanoids copy human motion.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
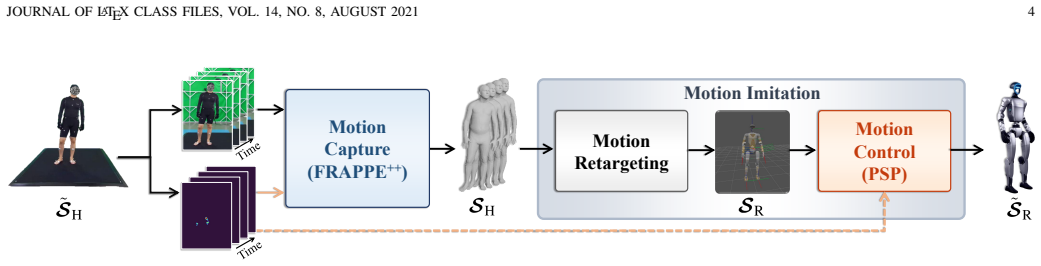
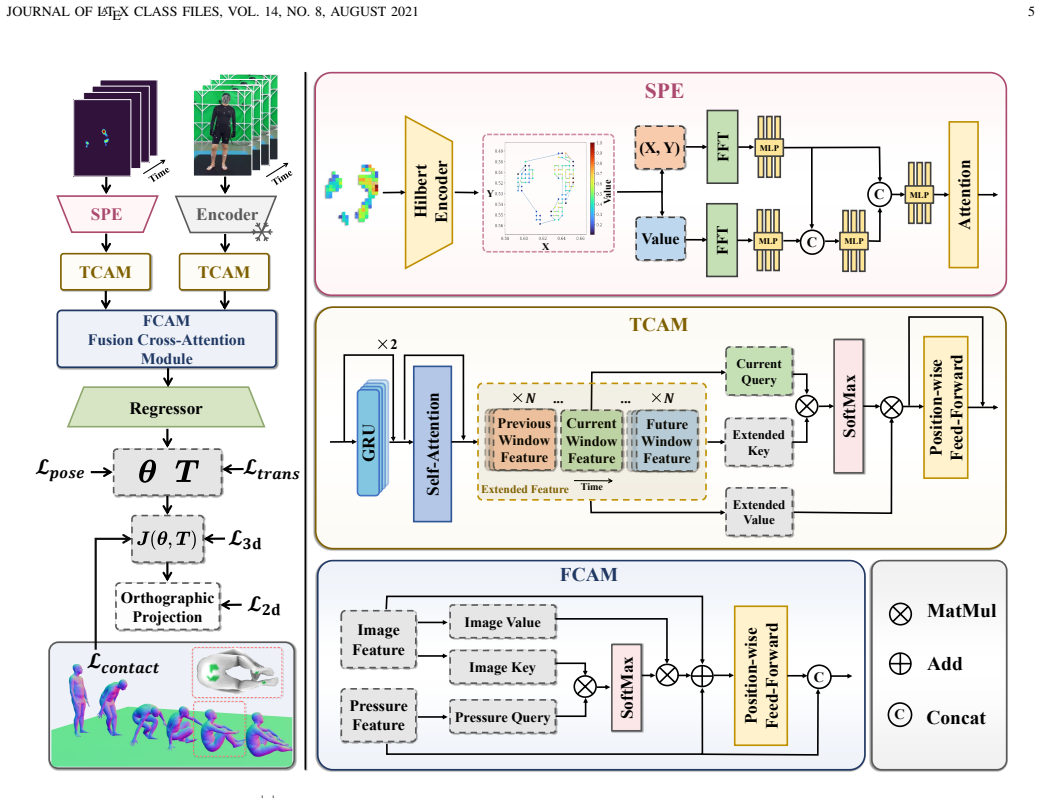
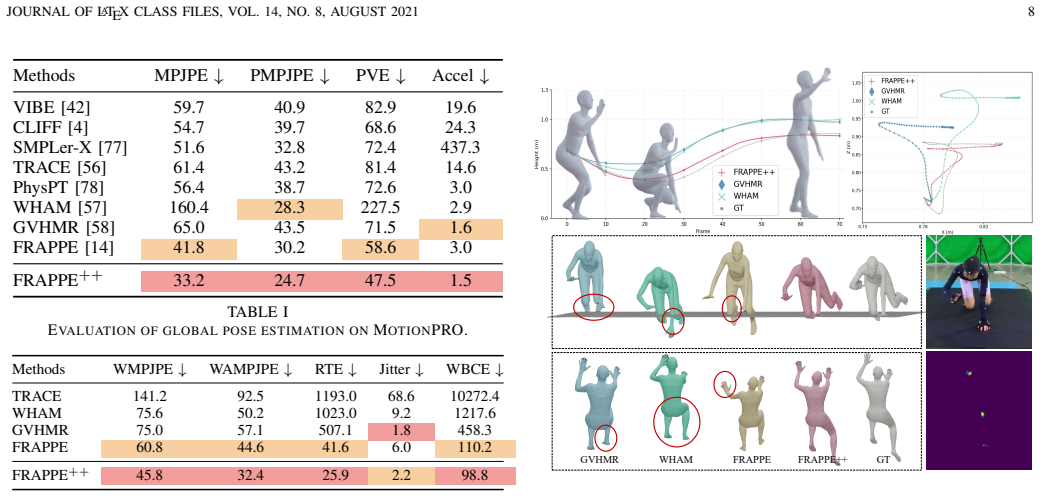
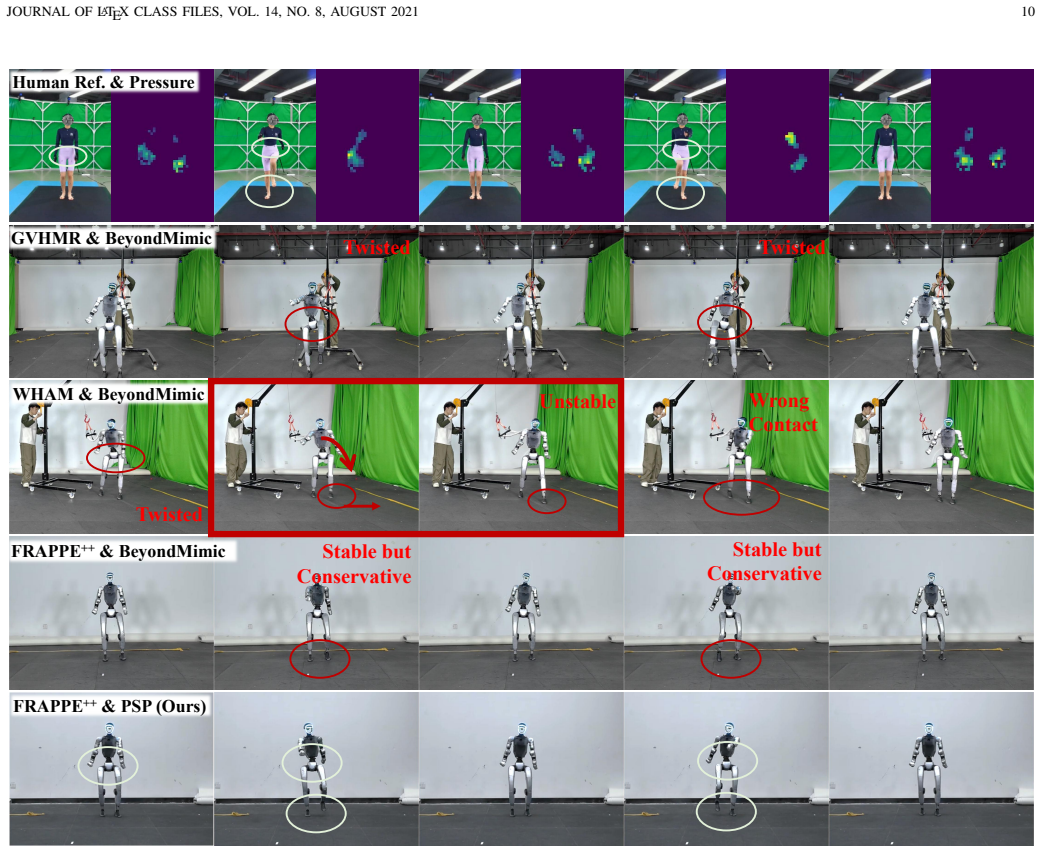
The central claim is that pressure serves as an effective physical grounding signal, bridging perception and control for physically consistent humanoid motion imitation. In the perception stage, the FRAPPE++ model fuses RGB and pressure to jointly estimate 3D pose and global motion, with pressure providing explicit contact and support constraints that resolve vision ambiguities. In the control stage, a pressure-supervised policy incorporates pressure-derived signals into reinforcement learning so that execution matches observed contact patterns. Experiments on the MotionPRO dataset demonstrate gains in motion-estimation accuracy, trajectory consistency, and execution stability.
What carries the argument
The PressMimic framework, which routes pressure data through both a multimodal perception model (FRAPPE++) and a pressure-supervised control policy (PSP) to enforce physical contact constraints.
If this is right
- Motion estimation becomes more accurate because pressure supplies explicit support constraints that vision alone cannot resolve.
- Trajectory consistency rises as the policy learns to reproduce the pressure patterns recorded during human motion.
- Execution stability improves, reducing foot sliding and floor penetration in real-robot runs.
- Perception and control become unified through one physical signal instead of being optimized separately.
Where Pith is reading between the lines
- The pressure-grounding approach could be tested on other contact-rich behaviors such as carrying objects or climbing stairs without changing the core fusion method.
- If pressure maps remain informative across different floor materials, the perception model might transfer to new environments with minimal retraining.
- One could check whether retrofitting existing vision-only motion datasets with simulated pressure yields comparable gains, avoiding new hardware collection.
Load-bearing premise
Pressure data can be reliably captured, synchronized with RGB and motion capture, and fused to provide explicit contact and support constraints that resolve vision ambiguities.
What would settle it
Compare imitation performance on identical tasks with and without pressure inputs; if the pressure-free version matches or exceeds accuracy, consistency, and stability, the claim that pressure supplies necessary grounding would fail.
Figures



read the original abstract
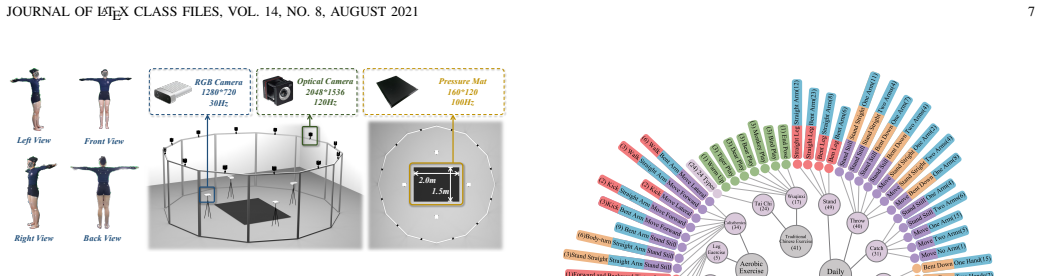
Humanoid motion imitation requires not only accurate perception of human kinematics but also faithful reproduction of physical interactions with the environment. However, existing pipelines rely primarily on vision-based motion capture and kinematic imitation, largely ignoring contact dynamics, leading to artifacts such as foot sliding, floor penetration, and unstable behaviors. In this work, we revisit humanoid motion imitation from the perspective of physical grounding and leverage pressure as a unified modality across perception and control. We present PressMimic, a framework that integrates pressure into the full pipeline from motion capture to humanoid control. In the perception stage, we introduce FRAPPE++, a multimodal model that fuses RGB and pressure to jointly estimate 3D pose and global motion, where pressure provides explicit contact and support constraints to resolve ambiguity in vision-based estimation. In the control stage, we propose a pressure-supervised policy (PSP) that incorporates pressure-derived signals into reinforcement learning, enabling physically consistent contact patterns during execution. We further construct MotionPRO, a large-scale dataset with synchronized RGB, pressure, and motion capture data. Experiments show that pressure improves motion estimation accuracy, trajectory consistency, and execution stability. These results demonstrate that pressure serves as an effective physical grounding signal, bridging perception and control for physically consistent humanoid motion imitation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents PressMimic, a framework for humanoid motion imitation that incorporates pressure sensing as a physical grounding modality across the full pipeline. In perception, FRAPPE++ fuses RGB and pressure to estimate 3D pose and global motion while using pressure for explicit contact and support constraints. In control, a pressure-supervised policy (PSP) incorporates pressure-derived signals into reinforcement learning for consistent contact patterns. The work also introduces the MotionPRO dataset containing synchronized RGB, pressure, and motion capture data. The central claim is that pressure improves motion estimation accuracy, trajectory consistency, and execution stability relative to vision-only methods.
Significance. If the empirical claims are substantiated with quantitative evidence, the work would be significant for humanoid robotics by showing how a single additional modality (pressure) can address common artifacts in kinematic imitation such as foot sliding and instability, while providing a unified signal from perception through control. The release of a large-scale synchronized multimodal dataset would also be a concrete enabling contribution for the community.
major comments (1)
- [Abstract] Abstract: The assertion that 'Experiments show that pressure improves motion estimation accuracy, trajectory consistency, and execution stability' supplies no quantitative metrics, ablation results, baseline comparisons, or implementation details. This absence is load-bearing for evaluating whether the central claim that pressure serves as an effective physical grounding signal holds.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and positive assessment of the work's potential significance. We address the single major comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: The assertion that 'Experiments show that pressure improves motion estimation accuracy, trajectory consistency, and execution stability' supplies no quantitative metrics, ablation results, baseline comparisons, or implementation details. This absence is load-bearing for evaluating whether the central claim that pressure serves as an effective physical grounding signal holds.
Authors: We agree that the abstract statement would be strengthened by explicit quantitative support. The full manuscript provides these details in Section 4 (Experiments), including tables with pose estimation errors, trajectory metrics (e.g., foot sliding and penetration), stability scores, ablations isolating the pressure modality, and comparisons against vision-only baselines, along with implementation specifics for FRAPPE++ and PSP. To make the abstract self-contained and directly substantiate the central claim, we will revise it to incorporate key numerical highlights and pointers to the experimental results. This change will be reflected in the next version of the manuscript. revision: yes
Circularity Check
Empirical framework exhibits no derivational circularity
full rationale
The paper describes an empirical pipeline: FRAPPE++ fuses RGB+pressure for pose estimation, PSP uses pressure signals in RL for control, and MotionPRO supplies synchronized data. No equations, fitted parameters renamed as predictions, self-citations as load-bearing premises, or ansatzes imported via prior work are present in the provided text. Claims rest on experimental improvements rather than any closed logical reduction to inputs by construction. This is the expected honest outcome for a data-driven robotics framework.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
End-to- end recovery of human shape and pose,
A. Kanazawa, M. J. Black, D. W. Jacobs, and J. Malik, “End-to- end recovery of human shape and pose,” inProceedings of the IEEE conference on computer vision and pattern recognition, 2018, pp. 7122– 7131
2018
-
[2]
3d human pose estimation via intuitive physics,
S. Tripathi, L. M ¨uller, C.-H. P. Huang, O. Taheri, M. J. Black, and D. Tzionas, “3d human pose estimation via intuitive physics,” inPro- ceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2023, pp. 4713–4725
2023
-
[3]
Learning to reconstruct 3d human pose and shape via model-fitting in the loop,
N. Kolotouros, G. Pavlakos, M. J. Black, and K. Daniilidis, “Learning to reconstruct 3d human pose and shape via model-fitting in the loop,” inProceedings of the IEEE/CVF international conference on computer vision, 2019, pp. 2252–2261
2019
-
[4]
Cliff: Carrying location information in full frames into human pose and shape estimation,
Z. Li, J. Liu, Z. Zhang, S. Xu, and Y . Yan, “Cliff: Carrying location information in full frames into human pose and shape estimation,” in European Conference on Computer Vision. Springer, 2022, pp. 590– 606
2022
-
[5]
Reconstructing 3d human pose by watching humans in the mirror,
Q. Fang, Q. Shuai, J. Dong, H. Bao, and X. Zhou, “Reconstructing 3d human pose by watching humans in the mirror,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2021, pp. 12 814–12 823
2021
-
[6]
Hybrik: A hybrid analytical-neural inverse kinematics solution for 3d human pose and shape estimation,
J. Li, C. Xu, Z. Chen, S. Bian, L. Yang, and C. Lu, “Hybrik: A hybrid analytical-neural inverse kinematics solution for 3d human pose and shape estimation,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2021, pp. 3383–3393
2021
-
[7]
Humans in 4d: Reconstructing and tracking humans with transformers,
S. Goel, G. Pavlakos, J. Rajasegaran, A. Kanazawa, and J. Malik, “Humans in 4d: Reconstructing and tracking humans with transformers,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 14 783–14 794
2023
-
[8]
Deep inertial poser: Learning to reconstruct human pose from sparse inertial measurements in real time,
Y . Huang, M. Kaufmann, E. Aksan, M. J. Black, O. Hilliges, and G. Pons-Moll, “Deep inertial poser: Learning to reconstruct human pose from sparse inertial measurements in real time,”ACM Transactions on Graphics (TOG), vol. 37, no. 6, pp. 1–15, 2018
2018
-
[9]
Physical inertial poser (pip): Physics-aware real-time human motion tracking from sparse inertial sensors,
X. Yi, Y . Zhou, M. Habermann, S. Shimada, V . Golyanik, C. Theobalt, and F. Xu, “Physical inertial poser (pip): Physics-aware real-time human motion tracking from sparse inertial sensors,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2022, pp. 13 167–13 178
2022
-
[10]
Avatars grow legs: Generating smooth human motion from sparse tracking inputs with diffusion model,
Y . Du, R. Kips, A. Pumarola, S. Starke, A. Thabet, and A. Sanakoyeu, “Avatars grow legs: Generating smooth human motion from sparse tracking inputs with diffusion model,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 481– 490
2023
-
[11]
Humanoid locomotion and manipulation: Current progress and challenges in control, planning, and learning,
Z. Gu, J. Li, W. Shen, W. Yu, Z. Xie, S. McCrory, X. Cheng, A. Shamsah, R. Griffin, C. K. Liuet al., “Humanoid locomotion and manipulation: Current progress and challenges in control, planning, and learning,”IEEE/ASME Transactions on Mechatronics, vol. 31, no. 2, pp. 2300–2330, 2026
2026
-
[12]
A review: Robust locomotion for biped humanoid robots,
Y . Xie, B. Lou, A. Xie, and D. Zhang, “A review: Robust locomotion for biped humanoid robots,” inJournal of Physics: Conference Series, vol. 1487, no. 1. IOP Publishing, 2020, p. 012048
2020
-
[13]
Humanoid robots and humanoid ai: Review, perspectives and directions,
L. Cao, “Humanoid robots and humanoid ai: Review, perspectives and directions,”ACM Computing Surveys, vol. 58, no. 4, pp. 1–37, 2025
2025
-
[14]
Motionpro: exploring the role of pressure in human mocap and beyond,
S. Ren, Y . Lu, J. Huang, J. Zhao, H. Zhang, T. Yu, Q. Shen, and X. Cao, “Motionpro: exploring the role of pressure in human mocap and beyond,” inProceedings of the Computer Vision and Pattern Recognition Conference, 2025, pp. 27 760–27 770
2025
-
[15]
Real-time imitation of human whole-body motions by humanoids,
J. Koenemann, F. Burget, and M. Bennewitz, “Real-time imitation of human whole-body motions by humanoids,” in2014 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2014, pp. 2806–2812
2014
-
[16]
Humanoid teleoperation using task-relevant haptic feedback,
F. Abi-Farrajl, B. Henze, A. Werner, M. Panzirsch, C. Ott, and M. A. Roa, “Humanoid teleoperation using task-relevant haptic feedback,” in 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2018, pp. 5010–5017
2018
-
[17]
Telexistence and teleoperation for walking humanoid robots,
M. Elobaid, Y . Hu, G. Romualdi, S. Dafarra, J. Babic, and D. Pucci, “Telexistence and teleoperation for walking humanoid robots,” inPro- ceedings of SAI Intelligent Systems Conference. Springer, 2019, pp. 1106–1121
2019
-
[18]
Motion retargeting for humanoid robots based on simultaneous morphing parameter identification and motion optimization,
K. Ayusawa and E. Yoshida, “Motion retargeting for humanoid robots based on simultaneous morphing parameter identification and motion optimization,”IEEE Transactions on Robotics, vol. 33, no. 6, pp. 1343– 1357, 2017
2017
-
[19]
Adaptive whole-body manipulation in human-to-humanoid multi-contact motion retargeting,
K. Otani and K. Bouyarmane, “Adaptive whole-body manipulation in human-to-humanoid multi-contact motion retargeting,” in2017 IEEE-RAS 17th International Conference on Humanoid Robotics (Hu- manoids). IEEE, 2017, pp. 446–453
2017
-
[20]
Robust real-time whole- body motion retargeting from human to humanoid,
L. Penco, B. Cl ´ement, V . Modugno, E. M. Hoffman, G. Nava, D. Pucci, N. G. Tsagarakis, J.-B. Mouret, and S. Ivaldi, “Robust real-time whole- body motion retargeting from human to humanoid,” in2018 IEEE- RAS 18th International Conference on Humanoid Robots (Humanoids). IEEE, 2018, pp. 425–432
2018
-
[21]
Whole-body geometric retargeting for humanoid robots,
K. Darvish, Y . Tirupachuri, G. Romualdi, L. Rapetti, D. Ferigo, F. J. A. Chavez, and D. Pucci, “Whole-body geometric retargeting for humanoid robots,” in2019 IEEE-RAS 19th International Conference on Humanoid Robots (Humanoids). IEEE, 2019, pp. 679–686
2019
-
[22]
icub3 avatar system: Enabling remote fully immersive embodiment of humanoid robots,
S. Dafarra, U. Pattacini, G. Romualdi, L. Rapetti, R. Grieco, K. Darvish, G. Milani, E. Valli, I. Sorrentino, P. M. Viceconteet al., “icub3 avatar system: Enabling remote fully immersive embodiment of humanoid robots,”Science Robotics, vol. 9, no. 86, p. eadh3834, 2024
2024
-
[23]
Deepmimic: example-guided deep reinforcement learning of physics-based character skills,
X. B. Peng, P. Abbeel, S. Levine, and M. van de Panne, “Deepmimic: example-guided deep reinforcement learning of physics-based character skills,”ACM Trans. Graph., vol. 37, no. 4, p. 143, 2018
2018
-
[24]
Perpetual humanoid control for real-time simulated avatars,
Z. Luo, J. Cao, K. Kitani, W. Xuet al., “Perpetual humanoid control for real-time simulated avatars,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 10 895–10 904
2023
-
[25]
Universal humanoid motion representations for physics-based control,
Z. Luo, J. Cao, J. Merel, A. Winkler, J. Huang, K. Kitani, and W. Xu, “Universal humanoid motion representations for physics-based control,” inInternational Conference on Learning Representations, vol. 2024, 2024, pp. 56 766–56 782
2024
-
[26]
Masked- mimic: Unified physics-based character control through masked motion JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, AUGUST 2021 12 inpainting,
C. Tessler, Y . Guo, O. Nabati, G. Chechik, and X. B. Peng, “Masked- mimic: Unified physics-based character control through masked motion JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, AUGUST 2021 12 inpainting,”ACM Transactions On Graphics (TOG), vol. 43, no. 6, pp. 1–21, 2024
2021
-
[27]
Omni- grasp: Grasping diverse objects with simulated humanoids,
Z. Luo, J. Cao, S. Christen, A. Winkler, K. Kitani, and W. Xu, “Omni- grasp: Grasping diverse objects with simulated humanoids,”Advances in Neural Information Processing Systems, vol. 37, pp. 2161–2184, 2024
2024
-
[28]
L. Yang, X. Huang, Z. Wu, A. Kanazawa, P. Abbeel, C. Sferrazza, C. K. Liu, R. Duan, and G. Shi, “Omniretarget: Interaction-preserving data generation for humanoid whole-body loco-manipulation and scene interaction,”arXiv preprint arXiv:2509.26633, 2025
Pith/arXiv arXiv 2025
-
[29]
Track any motions under any disturbances,
Z. Zhang, J. Guo, C. Chen, J. Wang, C. Lin, Y . Lian, H. Xue, Z. Wang, M. Liu, J. Lyuet al., “Track any motions under any disturbances,”arXiv preprint arXiv:2509.13833, 2025
arXiv 2025
-
[30]
Sonic: Supersizing motion tracking for natural humanoid whole-body control,
Z. Luo, Y . Yuan, T. Wang, C. Li, S. Chen, F. Castaneda, Z.-A. Cao, J. Li, D. Minor, Q. Benet al., “Sonic: Supersizing motion tracking for natural humanoid whole-body control,”arXiv preprint arXiv:2511.07820, 2025
Pith/arXiv arXiv 2025
-
[31]
Omnih2o: Universal and dexterous human-to- humanoid whole-body teleoperation and learning,
T. He, Z. Luo, X. He, W. Xiao, C. Zhang, W. Zhang, K. M. Kitani, C. Liu, and G. Shi, “Omnih2o: Universal and dexterous human-to- humanoid whole-body teleoperation and learning,” inConference on Robot Learning. PMLR, 2025, pp. 1516–1540
2025
-
[32]
Kungfubot: Physics-based humanoid whole-body control for learning highly-dynamic skills,
W. Xie, J. Han, J. Zheng, H. Li, X. Liu, J. Shi, W. Zhang, C. Bai, and X. Li, “Kungfubot: Physics-based humanoid whole-body control for learning highly-dynamic skills,”Advances in Neural Information Processing Systems, vol. 38, pp. 62 406–62 433, 2026
2026
-
[33]
Asap: Aligning simulation and real-world physics for learning agile humanoid whole-body skills,
T. He, J. Gao, W. Xiao, Y . Zhang, Z. Wang, J. Wang, Z. Luo, G. He, N. Sobanbab, C. Panet al., “Asap: Aligning simulation and real-world physics for learning agile humanoid whole-body skills,”arXiv preprint arXiv:2502.01143, 2025
arXiv 2025
-
[34]
Y . Li, Z. Luo, T. Zhang, C. Dai, A. Kanervisto, A. Tirinzoni, H. Weng, K. Kitani, M. Guzek, A. Touatiet al., “Bfm-zero: A promptable behavioral foundation model for humanoid control using unsupervised reinforcement learning,”arXiv preprint arXiv:2511.04131, 2025
arXiv 2025
-
[35]
Twist2: Scalable, portable, and holistic humanoid data collection system,
Y . Ze, S. Zhao, W. Wang, A. Kanazawa, R. Duan, P. Abbeel, G. Shi, J. Wu, and C. K. Liu, “Twist2: Scalable, portable, and holistic humanoid data collection system,”arXiv preprint arXiv:2511.02832, 2025
arXiv 2025
-
[36]
Beyondmimic: From motion tracking to versatile humanoid control via guided diffusion,
Q. Liao, T. E. Truong, X. Huang, Y . Gao, G. Tevet, K. Sreenath, and C. K. Liu, “Beyondmimic: From motion tracking to versatile humanoid control via guided diffusion,”arXiv preprint arXiv:2508.08241, 2025
Pith/arXiv arXiv 2025
-
[37]
A study of vicon system positioning performance,
P. Merriaux, Y . Dupuis, R. Boutteau, P. Vasseur, and X. Savatier, “A study of vicon system positioning performance,”Sensors, vol. 17, no. 7, p. 1591, 2017
2017
-
[38]
A review of accelerometer sensor and gyroscope sensor in imu sensors on motion capture,
I. A. Faisal, T. W. Purboyo, and A. S. R. Ansori, “A review of accelerometer sensor and gyroscope sensor in imu sensors on motion capture,”J. Eng. Appl. Sci, vol. 15, no. 3, pp. 826–829, 2019
2019
-
[39]
Questsim: Human motion tracking from sparse sensors with simulated avatars,
A. Winkler, J. Won, and Y . Ye, “Questsim: Human motion tracking from sparse sensors with simulated avatars,” inSIGGRAPH Asia 2022 conference papers, 2022, pp. 1–8
2022
-
[40]
Humanplus: Humanoid shadowing and imitation from humans,
Z. Fu, Q. Zhao, Q. Wu, G. Wetzstein, and C. Finn, “Humanplus: Humanoid shadowing and imitation from humans,”arXiv preprint arXiv:2406.10454, 2024
arXiv 2024
-
[41]
Exbody2: Advanced expressive humanoid whole-body control,
M. Ji, X. Peng, F. Liu, J. Li, G. Yang, X. Cheng, and X. Wang, “Exbody2: Advanced expressive humanoid whole-body control,”arXiv preprint arXiv:2412.13196, 2024
arXiv 2024
-
[42]
Vibe: Video inference for human body pose and shape estimation,
M. Kocabas, N. Athanasiou, and M. J. Black, “Vibe: Video inference for human body pose and shape estimation,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2020, pp. 5253–5263
2020
-
[43]
Beyond static features for temporally consistent 3d human pose and shape from a video,
H. Choi, G. Moon, J. Y . Chang, and K. M. Lee, “Beyond static features for temporally consistent 3d human pose and shape from a video,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2021, pp. 1964–1973
2021
-
[44]
Learning 3d human dynamics from video,
A. Kanazawa, J. Y . Zhang, P. Felsen, and J. Malik, “Learning 3d human dynamics from video,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2019, pp. 5614–5623
2019
-
[45]
Human mesh recov- ery from monocular images via a skeleton-disentangled representation,
Y . Sun, Y . Ye, W. Liu, W. Gao, Y . Fu, and T. Mei, “Human mesh recov- ery from monocular images via a skeleton-disentangled representation,” inProceedings of the IEEE/CVF international conference on computer vision, 2019, pp. 5349–5358
2019
-
[46]
Exploiting temporal context for 3d human pose estimation in the wild,
A. Arnab, C. Doersch, and A. Zisserman, “Exploiting temporal context for 3d human pose estimation in the wild,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2019, pp. 3395–3404
2019
-
[47]
Keep it smpl: Automatic estimation of 3d human pose and shape from a single image,
F. Bogo, A. Kanazawa, C. Lassner, P. Gehler, J. Romero, and M. J. Black, “Keep it smpl: Automatic estimation of 3d human pose and shape from a single image,” inEuropean conference on computer vision. Springer, 2016, pp. 561–578
2016
-
[48]
Expressive body capture: 3d hands, face, and body from a single image,
G. Pavlakos, V . Choutas, N. Ghorbani, T. Bolkart, A. A. Osman, D. Tzionas, and M. J. Black, “Expressive body capture: 3d hands, face, and body from a single image,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2019, pp. 10 975–10 985
2019
-
[49]
Weakly supervised 3d human pose and shape reconstruction with normalizing flows,
A. Zanfir, E. G. Bazavan, H. Xu, W. T. Freeman, R. Sukthankar, and C. Sminchisescu, “Weakly supervised 3d human pose and shape reconstruction with normalizing flows,” inEuropean Conference on Computer Vision. Springer, 2020, pp. 465–481
2020
-
[50]
Beyond weak perspective for monocular 3d human pose estimation,
I. Kissos, L. Fritz, M. Goldman, O. Meir, E. Oks, and M. Kliger, “Beyond weak perspective for monocular 3d human pose estimation,” inEuropean Conference on Computer Vision. Springer, 2020, pp. 541– 554
2020
-
[51]
Spec: Seeing people in the wild with an estimated camera,
M. Kocabas, C.-H. P. Huang, J. Tesch, L. M ¨uller, O. Hilliges, and M. J. Black, “Spec: Seeing people in the wild with an estimated camera,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2021, pp. 11 035–11 045
2021
-
[52]
Zolly: Zoom focal length correctly for perspective- distorted human mesh reconstruction,
W. Wang, Y . Ge, H. Mei, Z. Cai, Q. Sun, Y . Wang, C. Shen, L. Yang, and T. Komura, “Zolly: Zoom focal length correctly for perspective- distorted human mesh reconstruction,” inProceedings of the IEEE/CVF international conference on computer vision, 2023, pp. 3925–3935
2023
-
[53]
Glamr: Global occlusion-aware human mesh recovery with dynamic cameras,
Y . Yuan, U. Iqbal, P. Molchanov, K. Kitani, and J. Kautz, “Glamr: Global occlusion-aware human mesh recovery with dynamic cameras,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2022, pp. 11 038–11 049
2022
-
[54]
Decoupling human and camera motion from videos in the wild,
V . Ye, G. Pavlakos, J. Malik, and A. Kanazawa, “Decoupling human and camera motion from videos in the wild,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2023, pp. 21 222–21 232
2023
-
[55]
Tram: Global trajectory and motion of 3d humans from in-the-wild videos,
Y . Wang, Z. Wang, L. Liu, and K. Daniilidis, “Tram: Global trajectory and motion of 3d humans from in-the-wild videos,” inEuropean Conference on Computer Vision. Springer, 2024, pp. 467–487
2024
-
[56]
Trace: 5d temporal regression of avatars with dynamic cameras in 3d environments,
Y . Sun, Q. Bao, W. Liu, T. Mei, and M. J. Black, “Trace: 5d temporal regression of avatars with dynamic cameras in 3d environments,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 8856–8866
2023
-
[57]
Wham: Reconstructing world-grounded humans with accurate 3d motion,
S. Shin, J. Kim, E. Halilaj, and M. J. Black, “Wham: Reconstructing world-grounded humans with accurate 3d motion,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 2070–2080
2024
-
[58]
World-grounded human motion recovery via gravity-view coordinates,
Z. Shen, H. Pi, Y . Xia, Z. Cen, S. Peng, Z. Hu, H. Bao, R. Hu, and X. Zhou, “World-grounded human motion recovery via gravity-view coordinates,” inSIGGRAPH Asia 2024 Conference Papers, 2024, pp. 1–11
2024
-
[59]
3d human pose estimation on a configurable bed from a pressure image,
H. M. Clever, A. Kapusta, D. Park, Z. Erickson, Y . Chitalia, and C. C. Kemp, “3d human pose estimation on a configurable bed from a pressure image,” in2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2018, pp. 54–61
2018
-
[60]
Bodies at rest: 3d human pose and shape estimation from a pressure image using synthetic data,
H. M. Clever, Z. Erickson, A. Kapusta, G. Turk, K. Liu, and C. C. Kemp, “Bodies at rest: 3d human pose and shape estimation from a pressure image using synthetic data,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2020, pp. 6215–6224
2020
-
[61]
Multimodal in-bed pose and shape estimation under the blankets,
Y . Yin, J. P. Robinson, and Y . Fu, “Multimodal in-bed pose and shape estimation under the blankets,” inProceedings of the 30th ACM International Conference on Multimedia, 2022, pp. 2411–2419
2022
-
[62]
Bodymap-jointly predicting body mesh and 3d applied pressure map for people in bed,
A. Tandon, A. Goyal, H. M. Clever, and Z. Erickson, “Bodymap-jointly predicting body mesh and 3d applied pressure map for people in bed,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 2480–2489
2024
-
[63]
Simultaneously-collected multimodal lying pose dataset: Enabling in- bed human pose monitoring,
S. Liu, X. Huang, N. Fu, C. Li, Z. Su, and S. Ostadabbas, “Simultaneously-collected multimodal lying pose dataset: Enabling in- bed human pose monitoring,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 45, no. 1, pp. 1106–1118, 2022
2022
-
[64]
Bodypressure - inferring body pose and contact pressure from a depth image,
H. M. Clever, P. L. Grady, G. Turk, and C. C. Kemp, “Bodypressure - inferring body pose and contact pressure from a depth image,”IEEE Trans. Pattern Anal. Mach. Intell., vol. 45, no. 1, pp. 137–153, 2023
2023
-
[65]
Seeing through the tactile: 3d human shape estimation from temporal in-bed pressure images,
Z. Wu, F. Xie, Y . Fang, Z. Liang, Q. Wan, Y . Xiong, and X. Cai, “Seeing through the tactile: 3d human shape estimation from temporal in-bed pressure images,”Proc. ACM Interact. Mob. Wearable Ubiquitous Technol., vol. 8, no. 2, pp. 86:1–86:39, 2024
2024
-
[66]
Mmvp: A multimodal mocap dataset with vision and pressure sensors,
H. Zhang, S. Ren, H. Yuan, J. Zhao, F. Li, S. Sun, Z. Liang, T. Yu, Q. Shen, and X. Cao, “Mmvp: A multimodal mocap dataset with vision and pressure sensors,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 21 842–21 852
2024
-
[67]
Groundlink: A dataset unifying human body movement and ground reaction dynamics,
X. Han, B. Senderling, S. To, D. Kumar, E. Whiting, and J. Saito, “Groundlink: A dataset unifying human body movement and ground reaction dynamics,” inSIGGRAPH Asia 2023 Conference Papers, 2023, pp. 1–10. JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, AUGUST 2021 13
2023
-
[68]
Underpressure: Deep learning for foot contact detection, ground reaction force estimation and footskate cleanup,
L. Mourot, L. Hoyet, F. L. Clerc, and P. Hellier, “Underpressure: Deep learning for foot contact detection, ground reaction force estimation and footskate cleanup,” inComputer Graphics F orum, vol. 41, no. 8. Wiley Online Library, 2022, pp. 195–206
2022
-
[69]
From image to stability: Learning dynamics from human pose,
J. Scott, B. Ravichandran, C. Funk, R. T. Collins, and Y . Liu, “From image to stability: Learning dynamics from human pose,” inEuropean conference on computer vision. Springer, 2020, pp. 536–554
2020
-
[70]
Intelligent carpet: Inferring 3d human pose from tactile signals,
Y . Luo, Y . Li, M. Foshey, W. Shou, P. Sharma, T. Palacios, A. Torralba, and W. Matusik, “Intelligent carpet: Inferring 3d human pose from tactile signals,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2021, pp. 11 255–11 265
2021
-
[71]
Leveraging rgb-pressure for whole- body human-to-humanoid motion imitation,
Y . Lu, S. Ren, Q. Shen, and X. Cao, “Leveraging rgb-pressure for whole- body human-to-humanoid motion imitation,” inProceedings of the 32nd ACM International Conference on Multimedia, 2024, pp. 8932–8941
2024
-
[72]
Prox- imal policy optimization algorithms,
J. Schulman, F. Wolski, P. Dhariwal, A. Radford, and O. Klimov, “Prox- imal policy optimization algorithms,”arXiv preprint arXiv:1707.06347, 2017
Pith/arXiv arXiv 2017
-
[73]
Retargeting matters: General motion retargeting for humanoid motion tracking,
J. P. Araujo, Y . Ze, P. Xu, J. Wu, and C. K. Liu, “Retargeting matters: General motion retargeting for humanoid motion tracking,” arXiv preprint arXiv:2510.02252, 2025
arXiv 2025
-
[74]
Make tracking easy: Neural motion retargeting for humanoid whole-body control,
Q. Zhao, K. Yang, X. Wang, S. Zhao, Y . Lu, X. Zhang, Q. Shen, X.-X. Long, and X. Cao, “Make tracking easy: Neural motion retargeting for humanoid whole-body control,”arXiv preprint arXiv:2603.22201, 2026
Pith/arXiv arXiv 2026
-
[75]
Smpl: A skinned multi-person linear model,
M. Loper, N. Mahmood, J. Romero, G. Pons-Moll, and M. J. Black, “Smpl: A skinned multi-person linear model,” inSeminal Graphics Papers: Pushing the Boundaries, V olume 2, 2023, pp. 851–866
2023
-
[76]
Amass: Archive of motion capture as surface shapes,
N. Mahmood, N. Ghorbani, N. F. Troje, G. Pons-Moll, and M. J. Black, “Amass: Archive of motion capture as surface shapes,” inProceedings of the IEEE/CVF international conference on computer vision, 2019, pp. 5442–5451
2019
-
[77]
Smpler-x: Scaling up expressive human pose and shape estimation,
Z. Cai, W. Yin, A. Zeng, C. Wei, Q. Sun, W. Yanjun, H. E. Pang, H. Mei, M. Zhang, L. Zhanget al., “Smpler-x: Scaling up expressive human pose and shape estimation,”Advances in Neural Information Processing Systems, vol. 36, pp. 11 454–11 468, 2023
2023
-
[78]
Physpt: Physics-aware pretrained transformer for estimating human dynamics from monocular videos,
Y . Zhang, J. O. Kephart, Z. Cui, and Q. Ji, “Physpt: Physics-aware pretrained transformer for estimating human dynamics from monocular videos,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 2305–2317. Yi Luis a graduate student for Ph.D degree at the School of Electronic Science and Engineering, Nan- jing ...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.