TempAct: Advancing Temporal Plausibility in Autoregressive Video Generation via Planner-Executor RL
Pith reviewed 2026-06-29 04:43 UTC · model grok-4.3
The pith
A planner-executor RL setup lets autoregressive video models follow step-wise prompts without delayed reactions or error buildup across chunks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
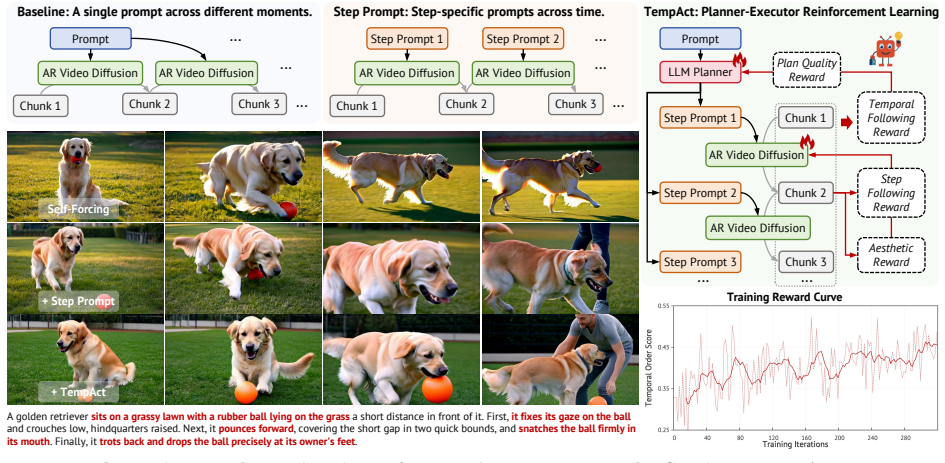
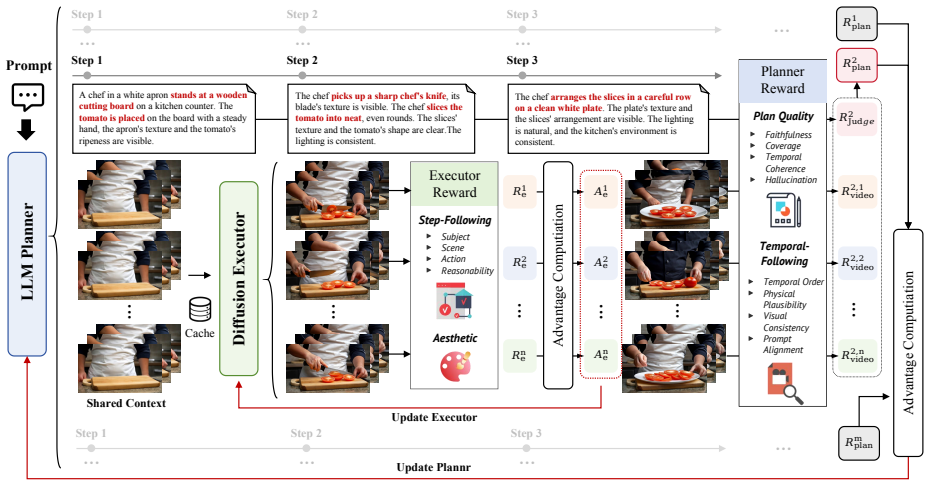
TempAct is a planner-executor reinforcement learning framework that jointly optimizes temporal decomposition and step-conditioned execution for autoregressive video diffusion models; an LLM planner explores span-aware step prompts that the video executor must follow under its own generated histories, with hierarchical group exploration forming planning groups and execution groups from shared visual contexts to support plan-level and executor-level credit assignment, together with hierarchical rewards that combine plan-quality feedback, full-video temporal signals, local transition rewards, aesthetic regularization, and KL constraints.
What carries the argument
Hierarchical group exploration, in which candidate plans form planning groups and each plan induces an execution group of multiple continuations from a shared visual context, enabling plan-level and transition-level credit assignment.
If this is right
- Temporal consistency improves on Self-Forcing and LongLive while overall visual quality is preserved.
- Prompt transitions avoid delayed reactions, blended semantics, and cross-chunk error accumulation.
- Joint optimization of temporal decomposition and step-conditioned execution becomes feasible for existing AR video diffusion models.
- Credit assignment can be performed separately at the plan horizon and at individual prompt-switch points.
Where Pith is reading between the lines
- The planner-executor split could be tested on autoregressive generation tasks outside video, such as audio or 3D scene sequences.
- Hierarchical rewards may offer a template for long-horizon credit assignment in other sequential decision settings.
- Scaling the number of execution continuations per plan could expose trade-offs between exploration cost and stability not measured in the reported experiments.
Load-bearing premise
Hierarchical group exploration and the designed rewards enable reliable plan-level and transition-level credit assignment without introducing new forms of error propagation or instability in the executor.
What would settle it
Apply TempAct to the Self-Forcing model and observe no measurable gain in temporal consistency metrics or a drop in visual quality scores relative to the unadapted baseline.
Figures






read the original abstract
Autoregressive (AR) video diffusion models enable low-latency streaming generation by synthesizing videos chunk by chunk with cached visual context, but this chunk-wise formulation makes temporal instruction following ambiguous. A single global prompt does not specify which sub-event should be realized in each chunk, while naively switching to step-wise prompts often leads to delayed reactions, blended step semantics, and error propagation across prompt transitions. These failures are difficult to address with supervised fine-tuning or distillation alone: SFT suffers from exposure bias, while rollout-based distillation still optimizes low-level denoising or teacher-distribution matching rather than directly enforcing action ordering and prompt-transition correctness. We address these challenges with TempAct, a planner--executor reinforcement learning framework that jointly optimizes temporal decomposition and step-conditioned execution for temporally plausible AR video generation. TempAct uses an LLM planner to explore span-aware step prompts that are executable by the video model, and trains an AR diffusion executor to follow these prompts under its own generated histories. Its key mechanism is hierarchical group exploration: candidate plans form planning groups, and each plan induces an execution group of multiple continuations from a shared visual context, enabling plan-level credit assignment for long-horizon temporal outcomes and executor-level credit assignment for prompt-switch behavior. We further design hierarchical rewards that combine plan-quality and full-video temporal feedback for the planner with local transition-level step-following rewards, aesthetic regularization, and KL constraints for the executor. Experiments on Self-Forcing and LongLive show that TempAct improves temporal consistency while preserving overall visual quality.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes TempAct, a planner-executor RL framework for autoregressive video diffusion models. An LLM planner explores span-aware step prompts via hierarchical group exploration (planning groups inducing execution groups from shared visual context), while the AR diffusion executor is trained with hierarchical rewards (plan-quality and full-video feedback for the planner; local transition, aesthetic, and KL terms for the executor) to enforce temporal ordering and prompt-transition correctness beyond what SFT or distillation achieve.
Significance. If the empirical claims hold, the approach would supply a direct optimization route for long-horizon temporal plausibility and prompt-switch behavior in streaming AR video generation, where error propagation is acute; the hierarchical credit-assignment mechanism could be a useful template for other chunk-wise generative settings.
major comments (2)
- [Abstract] Abstract: the central claim that hierarchical group exploration plus the designed rewards produces reliable plan-level and transition-level credit assignment is unsupported, as no equations for the reward functions, no description of LLM plan-executability enforcement, and no training-dynamics analysis are supplied; this leaves open the possibility that group-based advantage estimates amplify variance or permit local-reward satisfaction at the expense of global temporal ordering.
- [Abstract] Abstract: the reported improvements on Self-Forcing and LongLive are stated without any quantitative numbers, ablation tables, statistical significance tests, or failure-mode analysis, rendering it impossible to evaluate whether the method actually advances temporal consistency while preserving visual quality.
minor comments (1)
- [Abstract] The abstract would benefit from a brief statement of the exact benchmark metrics used (e.g., temporal consistency score, FID, or human preference) to allow readers to gauge the magnitude of the claimed gains.
Simulated Author's Rebuttal
We thank the referee for the detailed feedback on the abstract. We address each major comment below. The full manuscript contains the requested technical details in Sections 3 and 4; the abstract is intentionally high-level due to length constraints. We propose targeted revisions to improve clarity.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that hierarchical group exploration plus the designed rewards produces reliable plan-level and transition-level credit assignment is unsupported, as no equations for the reward functions, no description of LLM plan-executability enforcement, and no training-dynamics analysis are supplied; this leaves open the possibility that group-based advantage estimates amplify variance or permit local-reward satisfaction at the expense of global temporal ordering.
Authors: The abstract summarizes the framework at a high level. The full paper defines the hierarchical rewards explicitly in Equations (3)–(5) of Section 3.2, describes LLM plan-executability enforcement through constrained prompt generation in Section 3.1, and analyzes training dynamics including variance of group-based advantages in Section 4.3 and Appendix B. The group exploration design shares visual context across execution groups precisely to mitigate variance and enforce global ordering, as shown by the ablation removing shared context. We will revise the abstract to include one sentence referencing the credit-assignment mechanism and add a pointer to the equations in the introduction. revision: yes
-
Referee: [Abstract] Abstract: the reported improvements on Self-Forcing and LongLive are stated without any quantitative numbers, ablation tables, statistical significance tests, or failure-mode analysis, rendering it impossible to evaluate whether the method actually advances temporal consistency while preserving visual quality.
Authors: The abstract provides a qualitative summary of results. Quantitative metrics (e.g., temporal consistency scores, aesthetic quality, and prompt adherence), ablation tables, statistical significance, and failure-mode analysis appear in Tables 1–4, Figures 3–6, and Section 4.2–4.4 of the main paper plus the appendix. We will add two concrete improvement percentages (e.g., +X% temporal consistency on Self-Forcing) to the abstract while staying within word limits, and ensure the introduction explicitly references the ablation and significance results. revision: partial
Circularity Check
No significant circularity; framework presented as independent RL procedure
full rationale
The provided abstract and description introduce TempAct as a new planner-executor RL framework with hierarchical group exploration and hierarchical rewards for AR video generation. No equations, fitted parameters, or self-citations are shown that reduce any claimed improvement or temporal consistency gain to a re-expression of prior inputs by construction. The method is described as an independent training procedure addressing exposure bias and error propagation, with experiments on external benchmarks (Self-Forcing, LongLive) presented as empirical validation rather than a closed derivation. This matches the default expectation of self-contained work without load-bearing circular steps.
Axiom & Free-Parameter Ledger
free parameters (1)
- hierarchical reward coefficients
axioms (1)
- domain assumption LLM planner produces step prompts that remain executable by the frozen video model
Reference graph
Works this paper leans on
-
[1]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, Wenbin Ge, Zhifang Guo, Qidong Huang, Jie Huang, Fei Huang, Binyuan Hui, Shutong Jiang, Zhaohai Li, Mingsheng Li, Mei Li, Kaixin Li, Zicheng Lin, Junyang Lin, Xuejing Liu, Jiawei Liu, Chenglong Liu, Yang Liu, Dayiheng Liu, Shixuan ...
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
SkyReels-V2: Infinite-length Film Generative Model
Guibin Chen, Dixuan Lin, Jiangping Yang, Chunze Lin, Junchen Zhu, Mingyuan Fan, Hao Zhang, Sheng Chen, Zheng Chen, Chengcheng Ma, et al. Skyreels-v2: Infinite-length film generative model. arXiv preprint arXiv:2504.13074,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Self-Forcing++: Towards Minute-Scale High-Quality Video Generation
Justin Cui, Jie Wu, Ming Li, Tao Yang, Xiaojie Li, Rui Wang, Andrew Bai, Yuanhao Ban, and Cho-Jui Hsieh. Self-forcing++: Towards minute-scale high-quality video generation.arXiv preprint arXiv:2510.02283,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Ca2- VDM: Efficient Autoregressive Video Diffusion Model with Causal Generation and Cache Sharing
Kaifeng Gao, Jiaxin Shi, Hanwang Zhang, Chunping Wang, Jun Xiao, and Long Chen. Ca2-vdm: Efficient autoregressive video diffusion model with causal generation and cache sharing.arXiv preprint arXiv:2411.16375,
-
[5]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Dailan He, Guanlin Feng, Xingtong Ge, Yi Zhang, Bingqi Ma, Guanglu Song, Yu Liu, and Hongsheng Li. Ar-copo: Align autoregressive video generation with contrastive policy optimization.arXiv preprint arXiv:2603.17461,
-
[7]
Gardo: Reinforcing diffusion models without reward hacking
Haoran He, Yuxiao Ye, Jie Liu, Jiajun Liang, Zhiyong Wang, Ziyang Yuan, Xintao Wang, Hangyu Mao, Pengfei Wan, and Ling Pan. Gardo: Reinforcing diffusion models without reward hacking. arXiv preprint arXiv:2512.24138,
-
[8]
Jinyi Hu, Shengding Hu, Yuxuan Song, Yufei Huang, Mingxuan Wang, Hao Zhou, Zhiyuan Liu, Wei-Ying Ma, and Maosong Sun. Acdit: Interpolating autoregressive conditional modeling and diffusion transformer.arXiv preprint arXiv:2412.07720,
-
[9]
16 Aaron Jaech, Adam Kalai, Adam Lerer, Adam Richardson, Ahmed El-Kishky, Aiden Low, Alec Helyar, Aleksander Madry, Alex Beutel, Alex Carney, et al. Openai o1 system card.arXiv preprint arXiv:2412.16720,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Sihui Ji, Xi Chen, Shuai Yang, Xin Tao, Pengfei Wan, and Hengshuang Zhao. Memflow: Flowing adaptive memory for consistent and efficient long video narratives.arXiv preprint arXiv:2512.14699,
-
[11]
Forcing-KV: Hybrid KV Cache Compression for Efficient Autoregressive Video Diffusion Models
Yicheng Ji, Zhizhou Zhong, Jun Zhang, Qin Yang, XiTai Jin, Ying Qin, Wenhan Luo, Shuiyang Mao, Wei Liu, and Huan Li. Forcing-kv: Hybrid kv cache compression for efficient autoregressive video diffusion models.arXiv preprint arXiv:2605.09681,
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Pyramidal flow matching for efficient video generative modeling
Yang Jin, Zhicheng Sun, Ningyuan Li, Kun Xu, Hao Jiang, Nan Zhuang, Quzhe Huang, Yang Song, Yadong Mu, and Zhouchen Lin. Pyramidal flow matching for efficient video generative modeling. InInternational Conference on Learning Representations, volume 2025, pages 23378–23402,
2025
-
[13]
MixGRPO: Unlocking Flow-based GRPO Efficiency with Mixed ODE-SDE
Junzhe Li, Yutao Cui, Tao Huang, Yinping Ma, Chun Fan, Yiming Cheng, Miles Yang, Zhao Zhong, and Liefeng Bo. Mixgrpo: Unlocking flow-based grpo efficiency with mixed ode-sde.arXiv preprint arXiv:2507.21802, 2025a. Yuming Li, Yikai Wang, Yuying Zhu, Zhongyu Zhao, Ming Lu, Qi She, and Shanghang Zhang. Branchgrpo: Stable and efficient grpo with structured br...
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
Flow Matching for Generative Modeling
Yaron Lipman, Ricky TQ Chen, Heli Ben-Hamu, Maximilian Nickel, and Matt Le. Flow matching for generative modeling.arXiv preprint arXiv:2210.02747,
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
Flow-GRPO: Training Flow Matching Models via Online RL
Jie Liu, Gongye Liu, Jiajun Liang, Yangguang Li, Jiaheng Liu, Xintao Wang, Pengfei Wan, Di Zhang, and Wanli Ouyang. Flow-grpo: Training flow matching models via online rl.arXiv preprint arXiv:2505.05470,
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
Flow Straight and Fast: Learning to Generate and Transfer Data with Rectified Flow
Xingchao Liu, Chengyue Gong, and Qiang Liu. Flow straight and fast: Learning to generate and transfer data with rectified flow.arXiv preprint arXiv:2209.03003,
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
Elucidating the exposure bias in diffusion models
Mang Ning, Mingxiao Li, Jianlin Su, Albert Ali Salah, and Itir Onal Ertugrul. Elucidating the exposure bias in diffusion models. InInternational Conference on Learning Representations, volume 2024, pages 15167–15189,
2024
-
[18]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347,
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, Y. K. Li, Y. Wu, and Daya Guo. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300,
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
Wan: Open and Advanced Large-Scale Video Generative Models
Team Wan, Ang Wang, Baole Ai, Bin Wen, Chaojie Mao, Chen-Wei Xie, Di Chen, Feiwu Yu, Haiming Zhao, Jianxiao Yang, Jianyuan Zeng, Jiayu Wang, Jingfeng Zhang, Jingren Zhou, Jinkai Wang, Jixuan Chen, Kai Zhu, Kang Zhao, Keyu Yan, Lianghua Huang, Mengyang Feng, Ningyi Zhang, Pandeng Li, Pingyu Wu, Ruihang Chu, Ruili Feng, Shiwei Zhang, Siyang Sun, Tao Fang, T...
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
Feng Wang and Zihao Yu. Coefficients-preserving sampling for reinforcement learning with flow matching.arXiv preprint arXiv:2509.05952,
-
[22]
TAGRPO: Boosting GRPO on Image-to-Video Generation with Direct Trajectory Alignment
Jin Wang, Jianxiang Lu, Guangzheng Xu, Comi Chen, Haoyu Yang, Linqing Wang, Peng Chen, Mingtao Chen, Zhichao Hu, Longhuang Wu, et al. Tagrpo: Boosting grpo on image-to-video generation with direct trajectory alignment.arXiv preprint arXiv:2601.05729, 2026a. Jing Wang, Ao Ma, Jiasong Feng, Dawei Leng, Yuhui Yin, and Xiaodan Liang. Pt-t2i/v: An efficient pr...
work page internal anchor Pith review Pith/arXiv arXiv
-
[23]
DanceGRPO: Unleashing GRPO on Visual Generation
Zeyue Xue, Jie Wu, Yu Gao, Fangyuan Kong, Lingting Zhu, Mengzhao Chen, Zhiheng Liu, Wei Liu, Qiushan Guo, Weilin Huang, et al. Dancegrpo: Unleashing grpo on visual generation.arXiv preprint arXiv:2505.07818,
work page internal anchor Pith review Pith/arXiv arXiv
-
[24]
18 An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, Chujie Zheng, Dayiheng Liu, Fan Zhou, Fei Huang, Feng Hu, Hao Ge, Haoran Wei, Huan Lin, Jialong Tang, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jing Zhou, Jingren Zhou, Junyang Lin, Kai Dang, Keqin Bao, Kexin Yan...
work page internal anchor Pith review Pith/arXiv arXiv
-
[25]
Deep Forcing: Training-Free Long Video Generation with Deep Sink and Participative Compression
Jung Yi, Wooseok Jang, Paul Hyunbin Cho, Jisu Nam, Heeji Yoon, and Seungryong Kim. Deep forcing: Training-free long video generation with deep sink and participative compression.arXiv preprint arXiv:2512.05081,
-
[26]
KVPO: ODE-Native GRPO for Autoregressive Video Alignment via KV Semantic Exploration
Tianwei Yin, Michaël Gharbi, Richard Zhang, Eli Shechtman, Fredo Durand, William T Freeman, and Taesung Park. One-step diffusion with distribution matching distillation. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 6613–6623, 2024a. Tianwei Yin, Qiang Zhang, Richard Zhang, William T Freeman, Fredo Durand, Eli ...
work page internal anchor Pith review Pith/arXiv arXiv
-
[27]
Group Sequence Policy Optimization
Chujie Zheng, Shixuan Liu, Mingze Li, Xiong-Hui Chen, Bowen Yu, Chang Gao, Kai Dang, Yuqiong Liu, Rui Men, An Yang, et al. Group sequence policy optimization.arXiv preprint arXiv:2507.18071,
work page internal anchor Pith review Pith/arXiv arXiv
-
[28]
Hongzhou Zhu, Min Zhao, Guande He, Hang Su, Chongxuan Li, and Jun Zhu. Causal forcing: Autoregressive diffusion distillation done right for high-quality real-time interactive video generation. arXiv preprint arXiv:2602.02214,
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.