Mitigating Batch Effects in Histopathology via Language-Mediated Robust Embedding Generation
Pith reviewed 2026-06-30 09:58 UTC · model grok-4.3
The pith
GLMP generates robust pathology embeddings by routing images through text descriptions of histological features.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
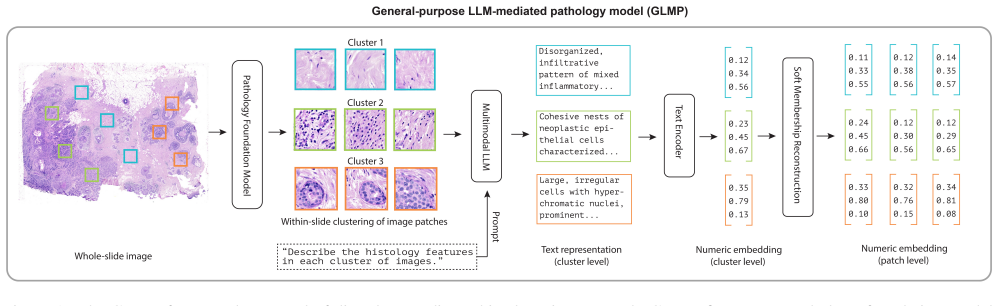
GLMP is the first pathology model to use text descriptions of histological features as an intermediate representation for generating numerical embeddings from histology images. By leveraging pretrained general-purpose multimodal large language models and text encoders, GLMP effectively prioritizes biologically meaningful signals over TSI-specific artifacts, thereby improving cross-institutional generalization.
What carries the argument
The language-mediated embedding generation process, where images are first converted to text descriptions by MLLMs before numerical encoding to suppress institution-specific artifacts.
If this is right
- Pathology models achieve better performance on images from institutions not seen during training.
- Batch effects are mitigated without dependence on stain normalization or other conventional preprocessing.
- Versatile pathology models can be constructed using off-the-shelf, non-specialized MLLMs.
- A new paradigm emerges for building generalizable and robust pathology foundation models via textual intermediates.
Where Pith is reading between the lines
- The same text-intermediate route might transfer to other medical imaging tasks where acquisition-site variations create similar artifacts.
- One could test whether the generated text descriptions retain fine-grained biological details that matter for rare subtypes or edge cases.
- Combining GLMP-style embeddings with existing pathology models might improve their cross-site reliability without full retraining.
Load-bearing premise
Routing images through pretrained general-purpose MLLMs and text encoders will automatically suppress institution-specific artifacts while preserving biological signal, without pathology-specific fine-tuning or explicit batch supervision.
What would settle it
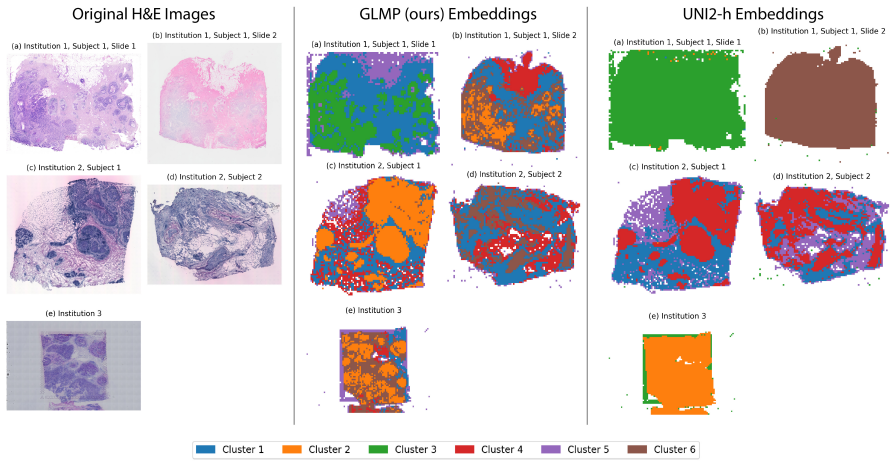
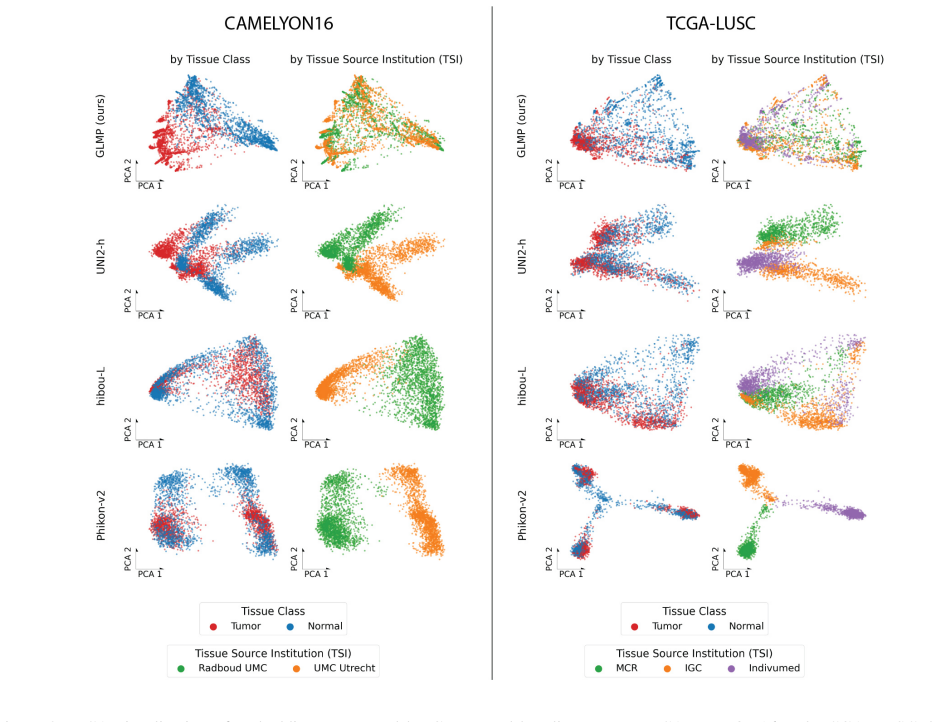
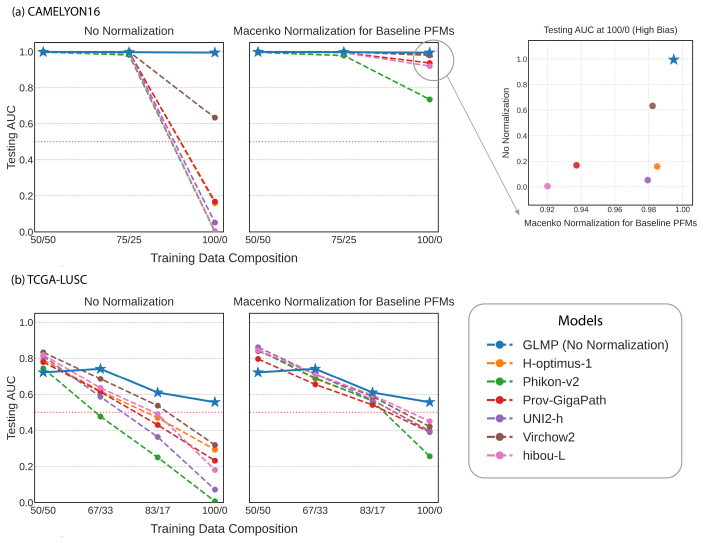
On a held-out multi-institutional dataset, GLMP embeddings continue to show strong clustering by tissue source institution in a visualization such as t-SNE rather than by biological category.
Figures
read the original abstract
Pathology foundation models (PFMs) have demonstrated strong potential across clinical and scientific applications, yet their performance is often hindered by batch effects, which are non-biological variations across tissue source institutions (TSIs) that distort learned feature representations and impair generalization. Conventional mitigation strategies, such as stain normalization, offer limited success in addressing these high-dimensional, complex artifacts. We present GLMP (General-purpose LLM-Mediated Pathology model), a novel framework that generates robust numerical embeddings from histology image patches through an intermediate textual representation. By leveraging pretrained general-purpose multimodal large language models (MLLMs) and text encoders, GLMP effectively prioritizes biologically meaningful signals over TSI-specific artifacts, thereby improving cross-institutional generalization. To our knowledge, GLMP is the first pathology model to use text descriptions of histological features as an intermediate representation for generating numerical embeddings from histology images. Our results highlight the untapped potential of broad-domain, non-specialized MLLMs in computational pathology and introduce a new paradigm for building versatile, generalizable, and robust pathology models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces GLMP, a framework for generating robust numerical embeddings from histology image patches. It routes patches through off-the-shelf general-purpose MLLMs to produce text descriptions of histological features, then encodes those texts with text encoders. The approach is claimed to mitigate batch effects from different tissue source institutions (TSIs) by prioritizing biological signals over institution-specific artifacts, thereby improving cross-institutional generalization. It is presented as the first pathology model to use text as an intermediate representation, with results said to highlight the potential of non-specialized MLLMs in computational pathology.
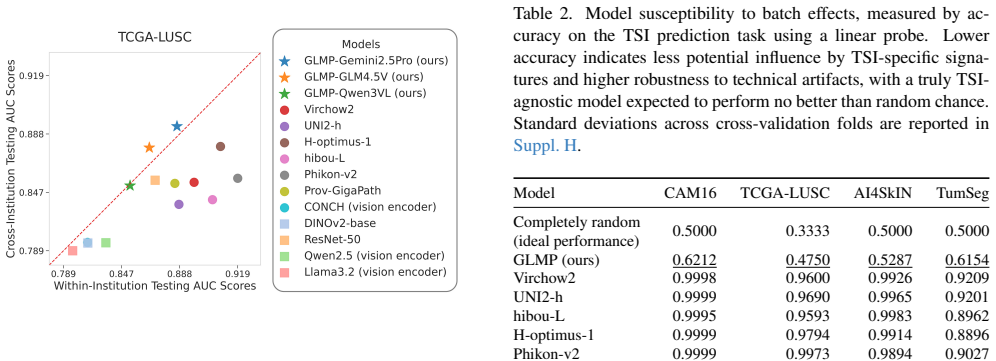
Significance. If the method demonstrably improves generalization via text mediation without pathology-specific fine-tuning or batch supervision, the work would be significant as a new paradigm for robust pathology embeddings that leverages broad-domain MLLMs' inductive biases to suppress TSI artifacts.
major comments (2)
- [Abstract] Abstract: the central claim that routing images through pretrained MLLMs and text encoders 'effectively prioritizes biologically meaningful signals over TSI-specific artifacts' lacks any supporting evidence. No ablation studies, batch-effect metrics (e.g., institution predictability or domain-shift error), quantitative results, or comparisons to direct image encoders are presented to verify that the text-mediated embeddings reduce batch effects relative to baselines.
- [Abstract] Abstract: the assertion that GLMP improves cross-institutional generalization rests on the unverified assumption that separation of biological signal from TSI artifacts emerges automatically from the pretrained models' biases alone, without pathology adaptation or explicit batch-label supervision. No controlled experiments are described to test this mechanism.
Simulated Author's Rebuttal
We thank the referee for the thoughtful review and for highlighting the need for stronger support of the claims made in the abstract. We address each major comment below and will revise the manuscript to incorporate the requested evidence and clarifications.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that routing images through pretrained MLLMs and text encoders 'effectively prioritizes biologically meaningful signals over TSI-specific artifacts' lacks any supporting evidence. No ablation studies, batch-effect metrics (e.g., institution predictability or domain-shift error), quantitative results, or comparisons to direct image encoders are presented to verify that the text-mediated embeddings reduce batch effects relative to baselines.
Authors: We agree that the abstract currently states the claim without sufficient direct references to supporting analyses. The manuscript reports cross-institutional generalization results but does not contain the specific ablation studies, institution predictability metrics, domain-shift error measurements, or head-to-head comparisons against direct image encoders that the referee requests. We will revise the abstract to remove or qualify the unsupported phrasing and add the requested experiments and metrics to the results section of the revised manuscript. revision: yes
-
Referee: [Abstract] Abstract: the assertion that GLMP improves cross-institutional generalization rests on the unverified assumption that separation of biological signal from TSI artifacts emerges automatically from the pretrained models' biases alone, without pathology adaptation or explicit batch-label supervision. No controlled experiments are described to test this mechanism.
Authors: We acknowledge that the current manuscript does not include controlled experiments that isolate the contribution of the pretrained models' inductive biases versus other factors. While the reported generalization improvements are consistent with the proposed mechanism, they do not constitute a direct test of it. We will add such controlled experiments in the revision and update the abstract to reflect only what the new experiments demonstrate. revision: yes
Circularity Check
No significant circularity; no derivations or fitted quantities present
full rationale
The abstract and method description contain no equations, parameter fittings, or derivation chains. Claims rest on the design choice of routing through off-the-shelf MLLMs and text encoders to suppress batch effects, presented as an empirical outcome rather than a self-referential prediction or self-citation load-bearing step. No self-definitional loops, fitted inputs renamed as predictions, or ansatz smuggling via citation are identifiable. The framework is self-contained at the conceptual level with no reduction of outputs to inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Human Breast Cancer: Visium Fresh Frozen, Whole Transcriptome
10x Genomics. Human Breast Cancer: Visium Fresh Frozen, Whole Transcriptome. Spatial Gene Expression Dataset by Space Ranger v1.3.0, 2022. 3
2022
-
[2]
Atish Agarwala, Jeffrey Pennington, Yann Dauphin, and Sam Schoenholz. Temperature check: theory and practice for training models with softmax-cross-entropy losses.arXiv preprint arXiv:2010.07344, 2020. 14
-
[3]
Val- idation of histopathology foundation models through whole slide image retrieval.Scientific Reports, 15(1):3990, 2025
Saghir Alfasly, Ghazal Alabtah, Sobhan Hemati, Kr- ishna Rani Kalari, Joaquin J Garcia, and HR Tizhoosh. Val- idation of histopathology foundation models through whole slide image retrieval.Scientific Reports, 15(1):3990, 2025. 1, 14
2025
-
[4]
Make your llm fully utilize the context.Advances in Neural Information Processing Sys- tems, 37:62160–62188, 2024
Shengnan An, Zexiong Ma, Zeqi Lin, Nanning Zheng, Jian- Guang Lou, and Weizhu Chen. Make your llm fully utilize the context.Advances in Neural Information Processing Sys- tems, 37:62160–62188, 2024. 14
2024
-
[5]
Wu, Ghamdan Al-Eryani, Daniel Roden, Alex Swarbrick, ˚Ake Borg, Jonas Fris ´en, Camilla Engblom, and Joakim Lundeberg
Alma Andersson, Ludvig Larsson, Linnea Stenbeck, Fredrik Salm´en, Anna Ehinger, Sunny Z. Wu, Ghamdan Al-Eryani, Daniel Roden, Alex Swarbrick, ˚Ake Borg, Jonas Fris ´en, Camilla Engblom, and Joakim Lundeberg. Spatial decon- volution of HER2-positive breast cancer delineates tumor- associated cell type interactions.Nature Communications, 12(1):6012, 2021. 3
2021
-
[6]
The Claude 3 Model Family: Opus, Son- net, Haiku.https://www- cdn.anthropic.com/ claude-3-model-card.pdf, 2024
Anthropic. The Claude 3 Model Family: Opus, Son- net, Haiku.https://www- cdn.anthropic.com/ claude-3-model-card.pdf, 2024. 2
2024
-
[7]
Diagnostic assess- ment of deep learning algorithms for detection of lymph node metastases in women with breast cancer.JAMA, 318 (22):2199–2210, 2017
Babak Ehteshami Bejnordi, Mitko Veta, Paul J van Di- est, Bram van Ginneken, Nico Karssemeijer, Geert Litjens, Jeroen AWM van der Laak, Meyke Hermsen, Quirine F Manson, Maschenka Balkenhol, et al. Diagnostic assess- ment of deep learning algorithms for detection of lymph node metastases in women with breast cancer.JAMA, 318 (22):2199–2210, 2017. 3
2017
-
[8]
H-optimus-1, 2025
Bioptimus. H-optimus-1, 2025. 18
2025
-
[9]
Springer, 2006
Christopher M Bishop and Nasser M Nasrabadi.Pattern recognition and machine learning. Springer, 2006. 4
2006
-
[10]
Impact of tissue staining and scanner vari- ation on the performance of pathology foundation models: a study of sarcomas and their mimics.bioRxiv, pages 2025– 08, 2025
Binghao Chai, Jianan Chen, Paul Cool, Fatine Oumlil, Anna Tollitt, David F Steiner, Tapabrata Chakraborti, and Adri- enne M Flanagan. Impact of tissue staining and scanner vari- ation on the performance of pathology foundation models: a study of sarcomas and their mimics.bioRxiv, pages 2025– 08, 2025. 1
2025
-
[11]
Weishaupt, Drew F
Chengkuan Chen, Luca L. Weishaupt, Drew F. K. Williamson, Richard J. Chen, Tong Ding, Bowen Chen, Anurag Vaidya, Long Phi Le, Guillaume Jaume, Ming Y . Lu, and Faisal Mahmood. Evidence-based diagnostic reasoning with multi-agent copilot for human pathology, 2025. 1
2025
-
[12]
Towards a general-purpose foundation model for com- putational pathology.Nature Medicine, 2024
Richard J Chen, Tong Ding, Ming Y Lu, Drew FK Williamson, Guillaume Jaume, Bowen Chen, Andrew Zhang, Daniel Shao, Andrew H Song, Muhammad Shaban, et al. Towards a general-purpose foundation model for com- putational pathology.Nature Medicine, 2024. 1, 3, 18
2024
-
[13]
Ying Chen, Guoan Wang, Yuanfeng Ji, Yanjun Li, Jin Ye, Tianbin Li, Ming Hu, Rongshan Yu, Yu Qiao, and Junjun He. Slidechat: A large vision-language assistant for whole- slide pathology image understanding.Proceedings of the Computer Vision and Pattern Recognition Conference, pages 5134–5143, 2025. 1
2025
-
[14]
Mapping the landscape of histomorphological cancer pheno- types using self-supervised learning on unannotated pathol- ogy slides.Nature Communications, 15(1):4596, 2024
Adalberto Claudio Quiros, Nicolas Coudray, Anna Yeaton, Xinyu Yang, Bojing Liu, Hortense Le, Luis Chiriboga, Afreen Karimkhan, Navneet Narula, David A Moore, et al. Mapping the landscape of histomorphological cancer pheno- types using self-supervised learning on unannotated pathol- ogy slides.Nature Communications, 15(1):4596, 2024. 14
2024
-
[15]
Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, Inderjit Dhillon, Marcel Blis- tein, Ori Ram, Dan Zhang, Evan Rosen, et al. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities.arXiv preprint arXiv:2507.06261, 2025. 2, 14
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[16]
de Jong, Eric Marcus, and Jonas Teuwen
Edwin D. de Jong, Eric Marcus, and Jonas Teuwen. Current pathology foundation models are unrobust to medical center differences.arXiv preprint arXiv:2501.18055, 2025. 1
-
[17]
Taher Dehkharghanian, Azam Asilian Bidgoli, Abtin Riasa- tian, Pooria Mazaheri, Clinton J. V . Campbell, Liron Pan- tanowitz, H. R. Tizhoosh, and Shahryar Rahnamayan. Bi- ased data, biased AI: Deep networks predict the acquisition site of TCGA images.Diagnostic Pathology, 18(1):67, 2023. 1
2023
-
[18]
A fusocelular skin dataset with whole slide images for deep learning mod- els.Scientific Data, 12:788, 2025
Roc ´ıo del Amor, Miguel L´opez-P´erez, Pablo Meseguer, San- dra Morales, Liria Terradez, Jose Aneiros-Fernandez, Javier Mateos, Rafael Molina, and Valery Naranjo. A fusocelular skin dataset with whole slide images for deep learning mod- els.Scientific Data, 12:788, 2025. 3
2025
-
[19]
Tong Ding, Sophia J Wagner, Andrew H Song, Richard J Chen, Ming Y Lu, Andrew Zhang, Anurag J Vaidya, Guil- laume Jaume, Muhammad Shaban, Ahrong Kim, et al. Mul- timodal whole slide foundation model for pathology.arXiv preprint arXiv:2411.19666, 2024. 14
-
[20]
Wagner, Andrew H
Tong Ding, Sophia J. Wagner, Andrew H. Song, Richard J. Chen, Ming Y . Lu, Andrew Zhang, Anurag J. Vaidya, Guil- laume Jaume, Muhammad Shaban, Ahrong Kim, Drew F. K. Williamson, Harry Robertson, Bowen Chen, Cristina Almagro-P´erez, Paul Doucet, Sharifa Sahai, Chengkuan Chen, Christina S. Chen, Daisuke Komura, Akihiro Kawabe, Mieko Ochi, Shinya Sato, Tomoy...
-
[21]
Rudolfv: A foundation model by pathologists for patholo- gists.arXiv preprint arXiv:2401.04079, 2024
Jonas Dippel, Barbara Feulner, Tobias Winterhoff, Timo Milbich, Stephan Tietz, Simon Schallenberg, Gabriel Dern- bach, Andreas Kunft, Simon Heinke, Marie-Lisa Eich, Ju- lika Ribbat-Idel, Rosemarie Krupar, Philipp Anders, Niklas Prenißl, Philipp Jurmeister, David Horst, Lukas Ruff, Klaus- Robert M¨uller, Frederick Klauschen, and Maximilian Alber. Rudolfv: ...
-
[22]
Wiest, Marta Ligero, Srividhya Sainath, Narmin Ghaffari Laleh, Omar S
Dyke Ferber, Georg W ¨olflein, Isabella C. Wiest, Marta Ligero, Srividhya Sainath, Narmin Ghaffari Laleh, Omar S. M. El Nahhas, Gustav M¨uller-Franzes, Dirk J¨ager, Daniel Truhn, and Jakob Nikolas Kather. In-context learning en- ables multimodal large language models to classify cancer pathology images.Nature Communications, 15(1):10104,
-
[23]
Vaesim: A probabilistic ap- proach for self-supervised prototype discovery.Image and Vision Computing, 137:104746, 2023
Matteo Ferrante, Tommaso Boccato, Simeon Spasov, Andrea Duggento, and Nicola Toschi. Vaesim: A probabilistic ap- proach for self-supervised prototype discovery.Image and Vision Computing, 137:104746, 2023. 14
2023
-
[24]
Alexandre Filiot, Paul Jacob, Alice Mac Kain, and Char- lie Saillard. Phikon-v2, a large and public feature extractor for biomarker prediction.arXiv preprint arXiv:2409.09173,
-
[25]
Domain-adversarial train- ing of neural networks.Journal of Machine Learning Re- search, 17(59):1–35, 2016
Yaroslav Ganin, Evgeniya Ustinova, Hana Ajakan, Pas- cal Germain, Hugo Larochelle, Franc ¸ois Laviolette, Mario Marchand, and Victor Lempitsky. Domain-adversarial train- ing of neural networks.Journal of Machine Learning Re- search, 17(59):1–35, 2016. 2, 4
2016
-
[26]
Deep learning-enabled integra- tion of histology and transcriptomics for tissue spatial profile analysis.Research, 8:0568, 2025
Yongxin Ge, Jiake Leng, Ziyang Tang, Kanran Wang, Kaicheng U, Sophia Meixuan Zhang, Sen Han, Yiyan Zhang, Jinxi Xiang, Sen Yang, et al. Deep learning-enabled integra- tion of histology and transcriptomics for tissue spatial profile analysis.Research, 8:0568, 2025. 14
2025
-
[27]
Aaron Grattonfiori, Abhimanyu Dubey, Abhinav Jauhri, , et al. The llama 3 herd of models.arXiv preprint arXiv:2407.21783, 2024. 3, 18
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[28]
Domain-specific language model pre- training for biomedical natural language processing.ACM Transactions on Computing for Healthcare (HEALTH), 3(1): 1–23, 2021
Yu Gu, Robert Tinn, Hao Cheng, Michael Lucas, Naoto Usuyama, Xiaodong Liu, Tristan Naumann, Jianfeng Gao, and Hoifung Poon. Domain-specific language model pre- training for biomedical natural language processing.ACM Transactions on Computing for Healthcare (HEALTH), 3(1): 1–23, 2021. 29
2021
-
[29]
Deep residual learning for image recognition.Proceedings of the IEEE conference on computer vision and pattern recog- nition, pages 770–778, 2016
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition.Proceedings of the IEEE conference on computer vision and pattern recog- nition, pages 770–778, 2016. 3, 18
2016
-
[30]
On the foundations of shortcut learning
Katherine L Hermann, Hossein Mobahi, Thomas Fel, and Michael C Mozer. On the foundations of shortcut learning. arXiv preprint arXiv:2310.16228, 2023. 4
-
[31]
Ziaul Hoque, Anja Keskinarkaus, Pia Nyberg, and Tapio Sepp¨anen
Md. Ziaul Hoque, Anja Keskinarkaus, Pia Nyberg, and Tapio Sepp¨anen. Stain normalization methods for histopathology image analysis: A comprehensive review and experimental comparison.Information Fusion, 102:101997, 2024. 1
2024
-
[32]
Howard, James Dolezal, Sara Kochanny, Je- free Schulte, Heather Chen, Lara Heij, Dezheng Huo, Rita Nanda, Olufunmilayo I
Frederick M. Howard, James Dolezal, Sara Kochanny, Je- free Schulte, Heather Chen, Lara Heij, Dezheng Huo, Rita Nanda, Olufunmilayo I. Olopade, Jakob N. Kather, Nicole Cipriani, Robert L. Grossman, and Alexander T. Pearson. The impact of site-specific digital histology signatures on deep learning model accuracy and bias.Nature Communi- cations, 12(1):4423...
2021
-
[33]
Pathoduet: Foundation models for pathological slide analysis of h&e and ihc stains.Medical Image Analysis, 97: 103289, 2024
Shengyi Hua, Fang Yan, Tianle Shen, Lei Ma, and Xiaofan Zhang. Pathoduet: Foundation models for pathological slide analysis of h&e and ihc stains.Medical Image Analysis, 97: 103289, 2024. 1, 3
2024
-
[34]
Tinglin Huang, Tianyu Liu, Mehrtash Babadi, Wengong Jin, and Rex Ying. Scalable generation of spatial transcriptomics from histology images via whole-slide flow matching.arXiv preprint arXiv:2506.05361, 2025. 2
-
[35]
Montine, and James Zou
Zhi Huang, Federico Bianchi, Mert Yuksekgonul, Thomas J. Montine, and James Zou. A visual–language foundation model for pathology image analysis using medical twitter. Nature Medicine, 29:2307–2316, 2023. 2
2023
-
[36]
Quilt-1m: One million image-text pairs for histopathology.arXiv preprint arXiv:2306.11207, 2023
Wisdom Oluchi Ikezogwo, Mehmet Saygin Seyfioglu, Fate- meh Ghezloo, Dylan Stefan Chan Geva, Fatwir Sheikh Mohammed, Pavan Kumar Anand, Ranjay Krishna, and Linda Shapiro. Quilt-1m: One million image-text pairs for histopathology.arXiv preprint arXiv:2306.11207, 2023. 2
-
[37]
Gottscho, Florian Wagner, Stephen R
Amanda Janesick, Robert Shelansky, Andrew D. Gottscho, Florian Wagner, Stephen R. Williams, Morgane Rouault, Ghezal Beliakoff, Carolyn A. Morrison, Michelli F. Oliveira, Jordan T. Sicherman, Andrew Kohlway, Jawad Abousoud, Tingsheng Yu Drennon, Seayar H. Mohabbat, 10x Develop- ment Teams, and Sarah E. B. Taylor. High resolution map- ping of the tumor micr...
2023
-
[38]
Siddharth Jha, Lutfi Eren Erdogan, Sehoon Kim, Kurt Keutzer, and Amir Gholami. Characterizing prompt com- pression methods for long context inference.arXiv preprint arXiv:2407.08892, 2024. 14
-
[39]
Piotr Keller, Muhammad Dawood, and Fayyaz ul Amir Min- has. Do tissue source sites leave identifiable signatures in whole slide images beyond staining? InTrustworthy Ma- chine Learning for Healthcare: First International Work- shop, TML4H 2023, Virtual Event, May 4, 2023, Proceed- ings, page 1–10, 2023. 2
2023
-
[40]
Jonah K ¨omen, Hannah Marienwald, Jonas Dippel, and Julius Hense. Do histopathological foundation models elimi- nate batch effects? a comparative study.arXiv preprint arXiv:2411.05489, 2024. 1, 2, 4, 5, 6, 7, 15, 28
-
[41]
de Jong, Julius Hense, Hannah Marienwald, Jonas Dippel, Philip Naumann, Eric Marcus, Lukas Ruff, Maximilian Alber, Jonas Teuwen, Frederick Klauschen, and Klaus-Robert M¨uller
Jonah K ¨omen, Edwin D. de Jong, Julius Hense, Hannah Marienwald, Jonas Dippel, Philip Naumann, Eric Marcus, Lukas Ruff, Maximilian Alber, Jonas Teuwen, Frederick Klauschen, and Klaus-Robert M¨uller. Towards Robust Foun- dation Models for Digital Pathology, 2025. 1, 2, 6, 15, 25
2025
-
[42]
Learning domain-invariant representations of histological images.Frontiers in Medicine, 6:162, 2019
Maxime W Lafarge, Josien PW Pluim, Koen AJ Eppenhof, and Mitko Veta. Learning domain-invariant representations of histological images.Frontiers in Medicine, 6:162, 2019. 2
2019
-
[43]
Gemini Embedding: Generalizable Embeddings from Gemini
Jinhyuk Lee, Feiyang Chen, Sahil Dua, Daniel Cer, Madhuri Shanbhogue, Iftekhar Naim, Gustavo Hern ´andez ´Abrego, Zhe Li, Kaifeng Chen, Henrique Schechter Vera, . . . , Min Choi, et al. Gemini embedding: Generalizable embeddings from gemini.arXiv preprint arXiv:2503.07891, 2025. 3, 14
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[44]
Impact of stain variation and color normalization for prognostic predictions in pathology.Scientific reports, 15(1):2369, 2025
Siyu Lin, Haowen Zhou, Mark Watson, Ramaswamy Govin- dan, Richard J Cote, and Changhuei Yang. Impact of stain variation and color normalization for prognostic predictions in pathology.Scientific reports, 15(1):2369, 2025. 1, 5
2025
-
[45]
Lost in the Middle: How Language Models Use Long Contexts
Nelson F Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang. Lost in the middle: How language models use long contexts.arXiv preprint arXiv:2307.03172, 2023. 14
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[46]
Manual tumor annotations in tcga, 2021
Chiara Loeffler and Jakob Nikolas Kather. Manual tumor annotations in tcga, 2021. 3
2021
-
[47]
Lu, Bowen Chen, Drew FK Williamson, Richard J
Ming Y . Lu, Bowen Chen, Drew FK Williamson, Richard J. Chen, Ivy Liang, Tong Ding, Guillaume Jaume, Igor Odintsov, Long Phi Le, Georg Gerber, Anil V . Parwani, An- drew Zhang, and Faisal Mahmood. A visual-language foun- dation model for computational pathology.Nature Medicine, 30(3):863–874, 2024. 1, 2, 3, 18
2024
-
[48]
A generalizable pathology founda- tion model using a unified knowledge distillation pretrain- ing framework.Nature Biomedical Engineering, pages 1–20,
Jiabo Ma, Zhengrui Guo, Fengtao Zhou, Yihui Wang, Yingxue Xu, Jinbang Li, Fang Yan, Yu Cai, Zhengjie Zhu, Cheng Jin, Yi Lin, Xinrui Jiang, Chenglong Zhao, Danyi Li, Anjia Han, Zhenhui Li, Ronald Cheong Kin Chan, Jiguang Wang, Peng Fei, Kwang-Ting Cheng, Shaoting Zhang, Li Liang, and Hao Chen. A generalizable pathology founda- tion model using a unified kn...
-
[49]
Visualizing data using t-sne.Journal of machine learning research, 9 (Nov):2579–2605, 2008
Laurens van der Maaten and Geoffrey Hinton. Visualizing data using t-sne.Journal of machine learning research, 9 (Nov):2579–2605, 2008. 4
2008
-
[50]
Marc Macenko, Marc Niethammer, J. S. Marron, David Bor- land, John T. Woosley, Xiaojun Guan, Charles Schmitt, and Nancy E. Thomas. A method for normalizing histology slides for quantitative analysis. In2009 IEEE International Symposium on Biomedical Imaging: From Nano to Macro, pages 1107–1110, 2009. 2, 4, 5
2009
-
[51]
Data-driven color augmentation for h&e stained images in computational pathology.Journal of Pathology Informat- ics, 14:100183, 2023
Niccol `o Marini, Sebastian Ot ´alora, Marek Wodzinski, Se- lene Tomassini, Aldo Franco Dragoni, Stephane Marchand- Maillet, Juan Pedro Dominguez Morales, Lourdes Duran- Lopez, Simona Vatrano, Henning M¨uller, and Manfredo At- zori. Data-driven color augmentation for h&e stained images in computational pathology.Journal of Pathology Informat- ics, 14:1001...
2023
-
[52]
Dmitry Nechaev, Alexey Pchelnikov, and Ekaterina Ivanova. Hibou: A family of foundational vision transformers for pathology.arXiv preprint arXiv:2406.05074, 2024. 1, 3, 18
-
[53]
Comprehen- sive genomic characterization of squamous cell lung cancers
The Cancer Genome Atlas Research Network. Comprehen- sive genomic characterization of squamous cell lung cancers. Nature, 489:519–525, 2012. 3
2012
-
[54]
On spectral clustering: Analysis and an algorithm.Advances in neural information processing systems, 14, 2001
Andrew Ng, Michael Jordan, and Yair Weiss. On spectral clustering: Analysis and an algorithm.Advances in neural information processing systems, 14, 2001. 29
2001
-
[55]
fmmap: A framework reducing site-bias batch effect from foundation models in pathology
Hai Cao Truong Nguyen and David Joon Ho. fmmap: A framework reducing site-bias batch effect from foundation models in pathology. InMICCAI Workshop on Computa- tional Pathology with Multimodal Data (COMPAYL), 2025. 5
2025
-
[56]
Learning relative gene expres- sion trends from pathology images in spatial transcriptomics
Kazuya Nishimura, Haruka Hirose, Ryoma Bise, Kaito Shiku, and Yasuhiro Kojima. Learning relative gene expres- sion trends from pathology images in spatial transcriptomics. arXiv preprint arXiv:2512.06612, 2025. 2
-
[57]
GPT-4V(ision) System Card, 2023
OpenAI. GPT-4V(ision) System Card, 2023. 2
2023
-
[58]
DINOv2: Learning Robust Visual Features without Supervision
Maxime Oquab, Timoth ´ee Darcet, Th ´eo Moutakanni, Huy V o, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, Mah- moud Assran, Nicolas Ballas, Wojciech Galuba, Russell Howes, Po-Yao Huang, Shang-Wen Li, Ishan Misra, Michael Rabbat, Vasu Sharma, Gabriel Synnaeve, Hu Xu, Herv ´e Je- gou, Julien Mairal, ...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[59]
Staining invariant fea- tures for improving generalization of deep convolutional neural networks in computational pathology.Frontiers in Bioengineering and Biotechnology, 7, 2019
Sebastian Ot ´alora, Manfredo Atzori, Vincent Andrearczyk, Amjad Khan, and Henning M ¨uller. Staining invariant fea- tures for improving generalization of deep convolutional neural networks in computational pathology.Frontiers in Bioengineering and Biotechnology, 7, 2019. 2
2019
-
[60]
Color transfer between images.IEEE Computer Graphics and Applications, 21(5):34–41, 2001
Erik Reinhard, Michael Adhikhmin, Bruce Gooch, and Peter Shirley. Color transfer between images.IEEE Computer Graphics and Applications, 21(5):34–41, 2001. 2, 5, 25
2001
-
[61]
Lucas Sanc ´er´e, Carina Lorenz, Doris Helbig, Oana-Diana Persa, Sonja Dengler, Alexander Kreuter, Martim Laimer, Anne Fr ¨ohlich, Jennifer Landsberg, Johannes Br ¨agelmann, and Katarzyna Bozek. Histo-miner: Deep learning based tissue features extraction pipeline from h&e whole slide im- ages of cutaneous squamous cell carcinoma.arXiv preprint arXiv:2505....
-
[62]
Rapid artefact removal and h&e-stained tissue segmentation.Scientific Re- ports, 14(1):309, 2024
BA Schreiber, J Denholm, F Jaeckle, Mark J Arends, KM Branson, C-B Sch ¨onlieb, and EJ Soilleux. Rapid artefact removal and h&e-stained tissue segmentation.Scientific Re- ports, 14(1):309, 2024. 14
2024
-
[63]
Web-scale k-means clustering
David Sculley. Web-scale k-means clustering. InProceed- ings of the 19th international conference on World wide web, pages 1177–1178, 2010. 29
2010
-
[64]
A foundation model for spatial proteomics,
Muhammad Shaban, Yuzhou Chang, Huaying Qiu, Yao Yu Yeo, Andrew H Song, Guillaume Jaume, Yuchen Wang, Luca L Weishaupt, Tong Ding, Anurag Vaidya, et al. A foundation model for spatial proteomics.arXiv preprint arXiv:2506.03373, 2025. 14
-
[65]
Tarek Shaban, Christoph Baur, Nassir Navab, and Shadi Albarqouni
M. Tarek Shaban, Christoph Baur, Nassir Navab, and Shadi Albarqouni. Staingan: Stain style transfer for digital histo- logical images. In2019 IEEE 16th International Symposium on Biomedical Imaging (ISBI 2019), pages 953–956, 2019. 2
2019
-
[66]
George Shaikovski, Eugene V orontsov, Adam Casson, Julian Viret, Eric Zimmermann, Neil Tenenholtz, Yi Kan Wang, Jan H. Bernhard, Ran A. Godrich, Juan A. Retamero, Razik Yousfi, Nicol`o Fusi, Thomas J. Fuchs, Kristen Severson, and Siqi Liu. Prism2: Unlocking multi-modal general pathology ai with clinical dialogue.arXiv preprint arXiv:2506.13063,
-
[67]
Randstainna: Learning stain-agnostic features from histol- ogy slides by bridging stain augmentation and normalization
Yiqing Shen, Yulin Luo, Dinggang Shen, and Jing Ke. Randstainna: Learning stain-agnostic features from histol- ogy slides by bridging stain augmentation and normalization. InMedical Image Computing and Computer Assisted Inter- vention – MICCAI 2022, pages 212–221, 2022. 2
2022
-
[68]
CPath-Omni: A Unified Multimodal Foundation Model for Patch and Whole Slide Image Analysis in Com- putational Pathology, 2024
Yuxuan Sun, Yixuan Si, Chenglu Zhu, Xuan Gong, Kai Zhang, Pingyi Chen, Ye Zhang, Zhongyi Shui, Tao Lin, and Lin Yang. CPath-Omni: A Unified Multimodal Foundation Model for Patch and Whole Slide Image Analysis in Com- putational Pathology, 2024. 2
2024
-
[69]
Qwen3 technical report, 2025
Qwen Team. Qwen3 technical report, 2025. 2
2025
-
[70]
Glm-4.5v and glm-4.1v-thinking: Towards versatile multi- modal reasoning with scalable reinforcement learning, 2025
V Team, Wenyi Hong, Wenmeng Yu, Xiaotao Gu, Guo Wang, Guobing Gan, Haomiao Tang, Jiale Cheng, Ji Qi, Junhui Ji, Lihang Pan, Shuaiqi Duan, Weihan Wang, Yan Wang, Yean Cheng, Zehai He, Zhe Su, Zhen Yang, Ziyang Pan, Aohan Zeng, Baoxu Wang, Bin Chen, Boyan Shi, Changyu Pang, Chenhui Zhang, Da Yin, Fan Yang, Guoqing Chen, Jiazheng Xu, Jiale Zhu, Jiali Chen, J...
2025
-
[71]
Structure-preserving color normalization and sparse stain separation for histological images.IEEE Transactions on Medical Imaging, 35(8):1962–1971, 2016
Abhishek Vahadane, Tingying Peng, Amit Sethi, Shadi Al- barqouni, Lichao Wang, Maximilian Baust, Katja Steiger, Anna Melissa Schlitter, Irene Esposito, and Nassir Navab. Structure-preserving color normalization and sparse stain separation for histological images.IEEE Transactions on Medical Imaging, 35(8):1962–1971, 2016. 2
1962
-
[72]
arXiv preprint arXiv:2501.16652 (2025)
Anurag Vaidya, Andrew Zhang, Guillaume Jaume, An- drew H. Song, Tong Ding, Sophia J. Wagner, Ming Y . Lu, Paul Doucet, Harry Robertson, Cristina Almagro-Perez, Richard J. Chen, Dina ElHarouni, Georges Ayoub, Con- nor Bossi, Keith L. Ligon, Georg Gerber, Long Phi Le, and Faisal Mahmood. Molecular-driven foundation model for oncologic pathology.arXiv prepri...
-
[73]
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution
Peng Wang, Shuai Bai, Sinan Tan, Shijie Wang, Zhihao Fan, Jinze Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Yang Fan, Kai Dang, Mengfei Du, Xuancheng Ren, Rui Men, Dayiheng Liu, Chang Zhou, Jingren Zhou, and Jun- yang Lin. Qwen2-vl: Enhancing vision-language model’s perception of the world at any resolution.arXiv preprint arXiv:2409.12191, 2024. 3, 18
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[74]
Retccl: Clustering-guided contrastive learning for whole-slide image retrieval.Medical image analysis, 83: 102645, 2023
Xiyue Wang, Yuexi Du, Sen Yang, Jun Zhang, Minghui Wang, Jing Zhang, Wei Yang, Junzhou Huang, and Xiao Han. Retccl: Clustering-guided contrastive learning for whole-slide image retrieval.Medical image analysis, 83: 102645, 2023. 14
2023
-
[75]
Jackson, Jun Zhang, Deborah Dil- lon, Nancy U
Xiyue Wang, Junhan Zhao, Eliana Marostica, Wei Yuan, Ji- etian Jin, Jiayu Zhang, Ruijiang Li, Hongping Tang, Kanran Wang, Yu Li, Fang Wang, Yulong Peng, Junyou Zhu, Jing Zhang, Christopher R. Jackson, Jun Zhang, Deborah Dil- lon, Nancy U. Lin, Lynette Sholl, Thomas Denize, David Meredith, Keith L. Ligon, Sabina Signoretti, Shuji Ogino, Jeffrey A. Golden, ...
2024
-
[76]
Nirschl, Joel Neal, Maximilian Diehn, Sen Yang, and Ruijiang Li
Jinxi Xiang, Xiyue Wang, Xiaoming Zhang, Yinghua Xi, Feyisope Eweje, Yijiang Chen, Yuchen Li, Colin Bergstrom, Matthew Gopaulchan, Ted Kim, Kun-Hsing Yu, Sierra Wil- lens, Francesca Maria Olguin, Jeffrey J. Nirschl, Joel Neal, Maximilian Diehn, Sen Yang, and Ruijiang Li. A vision– language foundation model for precision oncology.Nature, 638(8051):769–778, 2025. 1
2025
-
[77]
Wright, Ari Robicsek, Brian Piening, Carlo Bifulco, Sheng Wang, and Hoifung Poon
Hanwen Xu, Naoto Usuyama, Jaspreet Bagga, Sheng Zhang, Rajesh Rao, Tristan Naumann, Cliff Wong, Zelalem Gero, Javier Gonz´alez, Yu Gu, Yanbo Xu, Mu Wei, Wenhui Wang, Shuming Ma, Furu Wei, Jianwei Yang, Chunyuan Li, Jian- feng Gao, Jaylen Rosemon, Tucker Bower, Soohee Lee, Roshanthi Weerasinghe, Bill J. Wright, Ari Robicsek, Brian Piening, Carlo Bifulco, S...
2024
-
[78]
Wright, Ari Robicsek, Brian Piening, Carlo Bifulco, Sheng Wang, and Hoifung Poon
Hanwen Xu, Naoto Usuyama, Jaspreet Bagga, Sheng Zhang, Rajesh Rao, Tristan Naumann, Cliff Wong, Zelalem Gero, Javier Gonz´alez, Yu Gu, Yanbo Xu, Mu Wei, Wenhui Wang, Shuming Ma, Furu Wei, Jianwei Yang, Chunyuan Li, Jian- feng Gao, Jaylen Rosemon, Tucker Bower, Soohee Lee, Roshanthi Weerasinghe, Bill J. Wright, Ari Robicsek, Brian Piening, Carlo Bifulco, S...
2024
-
[79]
Yingxue Xu, Yihui Wang, Fengtao Zhou, Jiabo Ma, Cheng Jin, Shu Yang, Jinbang Li, Zhengyu Zhang, Chenglong Zhao, Huajun Zhou, Zhenhui Li, Huangjing Lin, Xin Wang, Jiguang Wang, Anjia Han, Ronald Cheong Kin Chan, Li Liang, Xiuming Zhang, and Hao Chen. A multi- modal knowledge-enhanced whole-slide pathology founda- tion model.arXiv preprint arXiv:2407.15362, 2024. 1
-
[80]
A Versa- tile Pathology Co-pilot via Reasoning Enhanced Multimodal Large Language Model, 2025
Zhe Xu, Ziyi Liu, Junlin Hou, Jiabo Ma, Cheng Jin, Yi- hui Wang, Zhixuan Chen, Zhengyu Zhang, Fuxiang Huang, Zhengrui Guo, Fengtao Zhou, Yingxue Xu, Xi Wang, Ronald Cheong Kin Chan, Li Liang, and Hao Chen. A Versa- tile Pathology Co-pilot via Reasoning Enhanced Multimodal Large Language Model, 2025. 2
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.