ViPSim: Collaborating Visual and Parameter Spaces for Consistent Long-Horizon Embodied World Models
Pith reviewed 2026-06-30 09:28 UTC · model grok-4.3
The pith
Unifying visual priors with action parameters removes trajectory drift in long-horizon robot simulations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
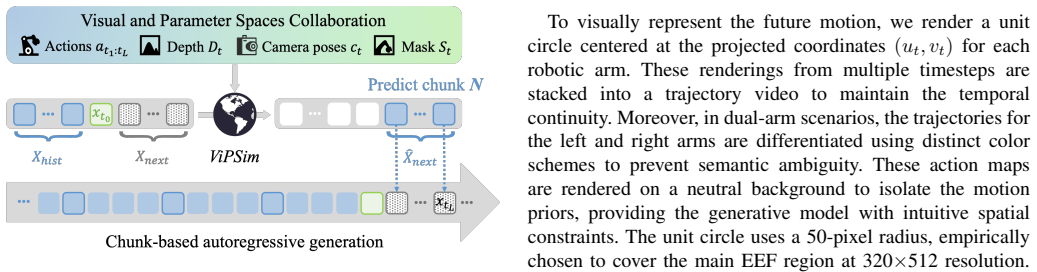
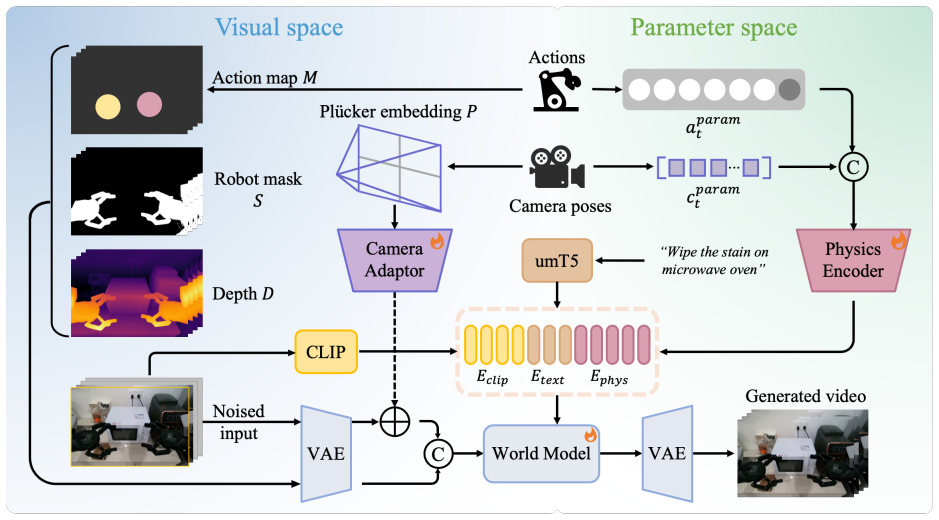
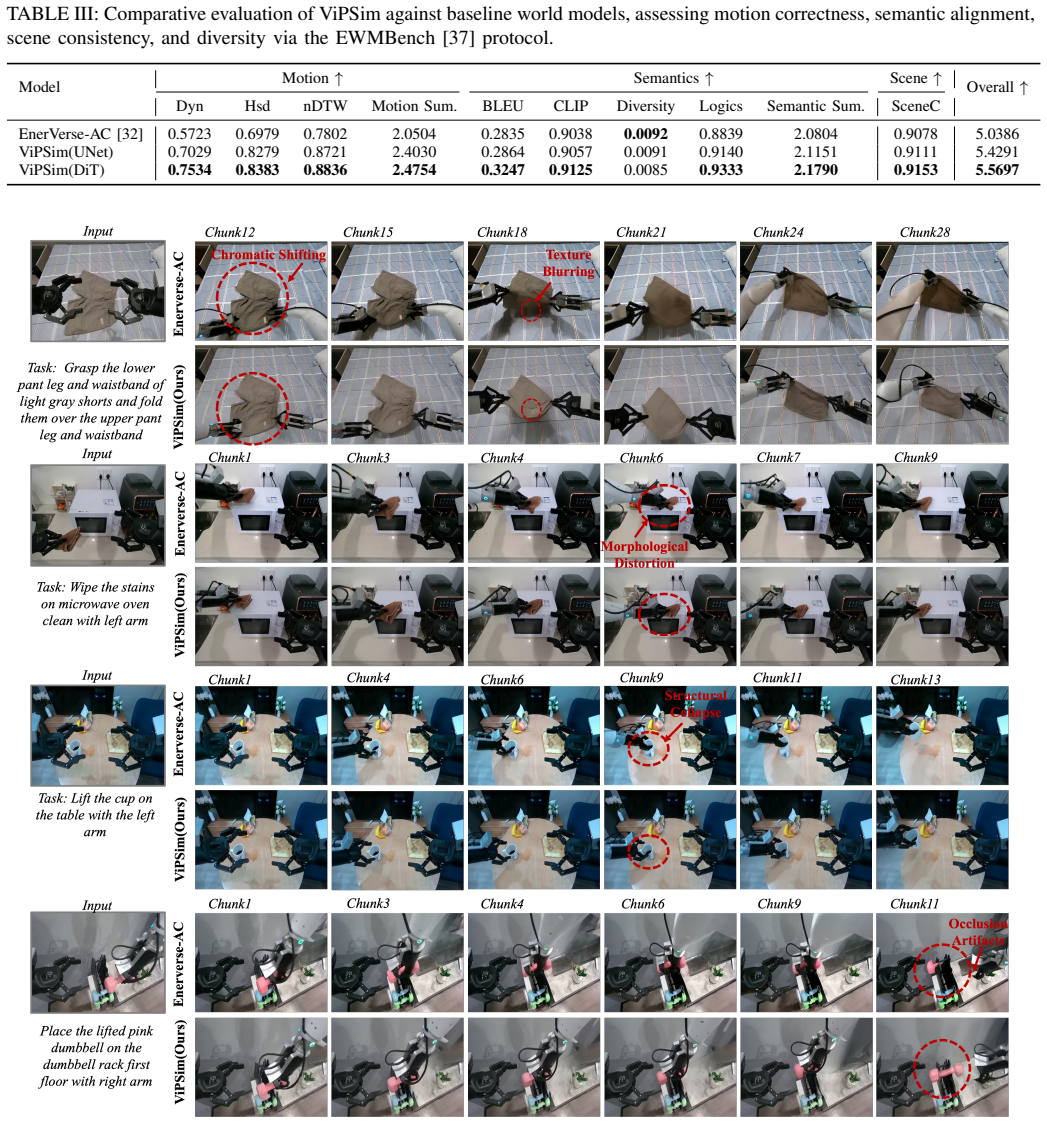
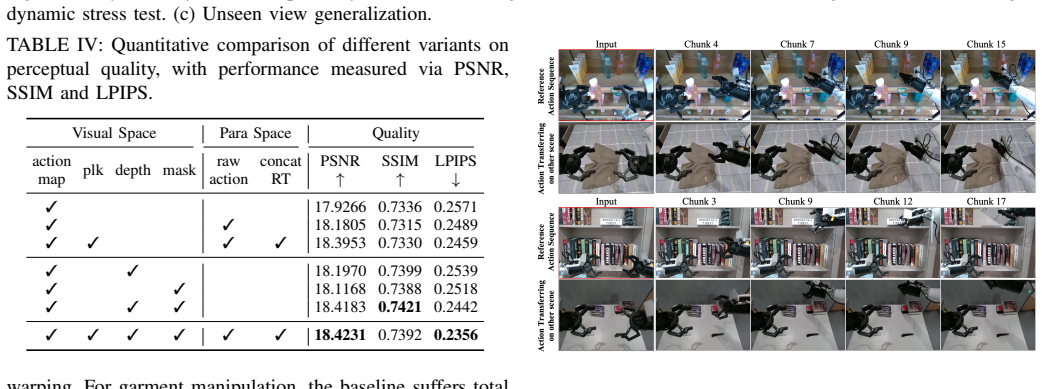
ViPSim achieves consistent long-horizon generation through the synergistic collaboration of Visual and Parameter Spaces. The Visual Space supplies dense structural grounding via pixel-aligned projections of end-effector pose, camera perspectives, depth-informed scene geometry, and robotic morphological masks. The Parameter Space supplies precise motion guidance via raw action sequences and camera matrices. By unifying the two, generated states remain simultaneously anchored by geometric boundaries and steered by numerical commands.
What carries the argument
Unification of Visual Space (explicit spatial priors) and Parameter Space (numerical drivers) so states are anchored by geometry and steered by actions.
If this is right
- Trajectory consistency improves markedly across long-horizon rollouts.
- Complex deformable interactions such as cloth folding emerge without explicit supervision.
- Performance holds in out-of-distribution and cross-embodiment settings.
- The framework remains agnostic to the choice of video-generation backbone.
- The resulting models supply a high-fidelity base for automated evaluation and predictive control of embodied agents.
Where Pith is reading between the lines
- Better simulators could reduce the number of real-world trials needed to validate vision-language-action policies.
- The same dual-space structure might extend to other embodied tasks that require both visual fidelity and precise control signals.
- If the geometric correspondence holds, downstream tasks such as sim-to-real transfer for deformable manipulation become more tractable.
Load-bearing premise
Integrating pixel projections of poses, depths, masks, and camera views with raw action sequences and matrices supplies enough geometric correspondence to stop accumulated drift and inconsistent interactions.
What would settle it
A controlled long-horizon rollout experiment in which ViPSim still produces measurable trajectory drift or visibly inconsistent robot-object contacts despite the visual-parameter unification.
Figures



read the original abstract
Embodied World Models (EWMs) have emerged as a scalable and risk-free paradigm for advancing embodied intelligence, enabling the safety-critical evaluation of Vision-Language-Action systems. However, their reliability as evaluation benchmarks and foundational simulators is often hindered by the representation gap between low-dimensional actions and high-dimensional video synthesis. This gap results in a lack of geometric correspondence, manifesting as accumulated trajectory drift and inconsistent robot-object interactions during long-horizon rollouts. To bridge this gap, we propose ViPSim, a framework that achieves consistent long-horizon generation through the synergistic collaboration of Visual and Parameter Spaces. We define the Visual Space as a domain of explicit spatial priors, integrating pixel-aligned projections of end-effector pose, camera perspectives, depth-informed scene geometry, and robotic morphological masks to provide dense structural grounding. Concurrently, the Parameter Space serves as a domain of numerical drivers, injecting raw action sequences and camera matrices to provide precise motion guidance. By unifying these two spaces, ViPSim ensures that the generated states are simultaneously anchored by geometric boundaries and steered by numerical commands. Extensive experiments demonstrate that ViPSim is backbone-agnostic and significantly enhances trajectory consistency. Notably, our approach exhibits emergent capabilities in generating complex interactions with deformable objects (e.g., cloth folding) and maintains robust performance in out-of-distribution and cross-embodiment scenarios, providing a high-fidelity foundation for the automated evaluation and predictive control of embodied agents.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes ViPSim, a framework for embodied world models that unifies a Visual Space (defined via pixel-aligned projections of end-effector pose, camera perspectives, depth-informed scene geometry, and robotic morphological masks) with a Parameter Space (raw action sequences and camera matrices) to enforce geometric correspondence. This is claimed to eliminate accumulated trajectory drift and inconsistent robot-object interactions in long-horizon rollouts, with the method being backbone-agnostic, yielding significant consistency gains, emergent capabilities (e.g., deformable object interactions like cloth folding), and robust out-of-distribution/cross-embodiment performance.
Significance. If the experimental results hold, the work addresses a practical bottleneck in embodied simulators for Vision-Language-Action evaluation by supplying explicit spatial priors alongside numerical drivers. The backbone-agnostic design and reported OOD robustness would be useful strengths for downstream predictive control and automated benchmarking.
major comments (2)
- [Abstract] Abstract: the central claim that unifying the two spaces 'ensures' elimination of trajectory drift rests on the sufficiency of the listed visual priors plus parameter inputs; no derivation or explicit integration mechanism (e.g., how masks and depth are fused with action sequences inside the generative model) is supplied in the abstract, which is load-bearing for the geometric-correspondence argument.
- [Abstract] The manuscript asserts 'extensive experiments' with 'significant enhancement' and 'robust' OOD performance, yet the abstract supplies neither quantitative metrics, baselines, error bars, nor ablation controls; without these, the strength of the consistency and emergent-capability claims cannot be assessed.
minor comments (2)
- [Abstract] The terms 'Visual Space' and 'Parameter Space' are introduced as novel domains but lack a concise formal definition or notation that would allow readers to distinguish them from standard conditioning inputs in video-generation models.
- [Abstract] The phrase 'backbone-agnostic' is used without specifying which backbones were tested or what invariance property is being claimed.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and the recommendation for minor revision. We address the comments on the abstract below and will incorporate targeted revisions to improve clarity and precision.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that unifying the two spaces 'ensures' elimination of trajectory drift rests on the sufficiency of the listed visual priors plus parameter inputs; no derivation or explicit integration mechanism (e.g., how masks and depth are fused with action sequences inside the generative model) is supplied in the abstract, which is load-bearing for the geometric-correspondence argument.
Authors: The abstract is a high-level summary; the explicit fusion mechanism (pixel-aligned visual priors combined with parameter inputs via the backbone-agnostic architecture) and geometric correspondence details are provided in Section 3, including the model diagram and equations for space unification. We agree the wording 'ensures' can be strengthened for precision in the abstract and will revise it to 'achieves through synergistic collaboration' while adding a brief clause on the integration of visual and parameter spaces. revision: yes
-
Referee: [Abstract] The manuscript asserts 'extensive experiments' with 'significant enhancement' and 'robust' OOD performance, yet the abstract supplies neither quantitative metrics, baselines, error bars, nor ablation controls; without these, the strength of the consistency and emergent-capability claims cannot be assessed.
Authors: We note that abstracts in this domain typically emphasize conceptual contributions over specific numbers due to space constraints, with all quantitative results (metrics, baselines, error bars, ablations) reported in Sections 4–5. However, to address the concern, we will revise the abstract to include representative quantitative highlights (e.g., consistency gains and OOD robustness figures) if length permits. revision: yes
Circularity Check
No significant circularity
full rationale
The manuscript presents ViPSim as an architectural framework proposal that unifies two defined spaces (Visual Space via explicit spatial priors and Parameter Space via numerical drivers) to address trajectory drift. No equations, derivations, fitted parameters, or first-principles predictions appear in the provided text; claims of consistency and emergent capabilities are asserted via experiments rather than reducing to self-definition or self-citation chains. The derivation chain is therefore self-contained as a descriptive hypothesis without internal reduction to inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption A representation gap exists between low-dimensional actions and high-dimensional video synthesis that causes accumulated trajectory drift and inconsistent interactions.
invented entities (2)
-
Visual Space
no independent evidence
-
Parameter Space
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Physical Intelligence, Kevin Black, Noah Brown, James Darpinian, Karan Dhabalia, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fusai, et al.π 0.5: a vision-language-action model with open-world generalization, 2025
2025
-
[2]
Depthvla: Enhancing vision-language-action models with depth-aware spatial reasoning, 2025
Tianyuan Yuan, Yicheng Liu, Chenhao Lu, Zhuoguang Chen, Tao Jiang, and Hang Zhao. Depthvla: Enhancing vision-language-action models with depth-aware spatial reasoning, 2025
2025
-
[3]
Evo-0: Vision-language-action model with implicit spatial understanding, 2025
Tao Lin, Gen Li, Yilei Zhong, Yanwen Zou, Yuxin Du, Jiting Liu, Encheng Gu, and Bo Zhao. Evo-0: Vision-language-action model with implicit spatial understanding, 2025
2025
-
[4]
Gemini Robotics: Bringing AI into the Physical World
Gemini Robotics Team, S Abeyruwan, J Ainslie, JB Alayrac, MG Are- nas, T Armstrong, A Balakrishna, R Baruch, M Bauza, M Blokzijl, et al. Gemini robotics: Bringing ai into the physical world, 2025.URL https://arxiv. org/abs/2503.20020, 1:6, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
Univla: Learning to act anywhere with task-centric latent actions, 2025
Qingwen Bu, Yanting Yang, Jisong Cai, Shenyuan Gao, Guanghui Ren, Maoqing Yao, Ping Luo, and Hongyang Li. Univla: Learning to act anywhere with task-centric latent actions, 2025
2025
-
[6]
GigaBrain Team, Angen Ye, Boyuan Wang, Chaojun Ni, Guan Huang, Guosheng Zhao, Haoyun Li, Jie Li, Jiagang Zhu, Lv Feng, et al. Gigabrain-0: A world model-powered vision-language-action model. arXiv preprint arXiv:2510.19430, 2025
-
[7]
Vid2world: Crafting video diffusion models to interactive world models, 2025
Siqiao Huang, Jialong Wu, Qixing Zhou, Shangchen Miao, and Ming- sheng Long. Vid2world: Crafting video diffusion models to interactive world models, 2025
2025
-
[8]
Worldgym: World model as an environ- ment for policy evaluation, 2025
Julian Quevedo, Ansh Kumar Sharma, Yixiang Sun, Varad Suryavanshi, Percy Liang, and Sherry Yang. Worldgym: World model as an environ- ment for policy evaluation, 2025
2025
-
[9]
Worldeval: World model as real-world robot policies evaluator, 2025
Yaxuan Li, Yichen Zhu, Junjie Wen, Chaomin Shen, and Yi Xu. Worldeval: World model as real-world robot policies evaluator, 2025
2025
-
[10]
Towards high-consistency embodied world model with multi- view trajectory videos, 2025
Taiyi Su, Jian Zhu, Yaxuan Li, Chong Ma, Zitai Huang, Hanli Wang, and Yi Xu. Towards high-consistency embodied world model with multi- view trajectory videos, 2025
2025
-
[11]
Enact: Evaluating embodied cognition with world modeling of egocentric interaction, 2025
Qineng Wang, Wenlong Huang, Yu Zhou, Hang Yin, Tianwei Bao, Jianwen Lyu, Weiyu Liu, Ruohan Zhang, Jiajun Wu, Li Fei-Fei, and Manling Li. Enact: Evaluating embodied cognition with world modeling of egocentric interaction, 2025
2025
-
[12]
Gen2act: Human video generation in novel scenarios enables generalizable robot manipulation, 2024
Homanga Bharadhwaj, Debidatta Dwibedi, Abhinav Gupta, Shubham Tulsiani, Carl Doersch, Ted Xiao, Dhruv Shah, Fei Xia, Dorsa Sadigh, and Sean Kirmani. Gen2act: Human video generation in novel scenarios enables generalizable robot manipulation, 2024
2024
-
[13]
Enerverse: Envisioning embodied future space for robotics manipulation, 2025
Siyuan Huang, Liliang Chen, Pengfei Zhou, Shengcong Chen, Zhengkai Jiang, Yue Hu, Yue Liao, Peng Gao, Hongsheng Li, Maoqing Yao, and Guanghui Ren. Enerverse: Envisioning embodied future space for robotics manipulation, 2025
2025
-
[14]
Genie envi- sioner: A unified world foundation platform for robotic manipulation, 2025
Yue Liao, Pengfei Zhou, Siyuan Huang, Donglin Yang, Shengcong Chen, Yuxin Jiang, Yue Hu, Jingbin Cai, Si Liu, Jianlan Luo, Liliang Chen, Shuicheng Yan, Maoqing Yao, and Guanghui Ren. Genie envi- sioner: A unified world foundation platform for robotic manipulation, 2025
2025
-
[15]
Cosmos World Foundation Model Platform for Physical AI
Niket Agarwal, Arslan Ali, Maciej Bala, Yogesh Balaji, Erik Barker, Tiffany Cai, Prithvijit Chattopadhyay, Yongxin Chen, Yin Cui, Yifan Ding, et al. Cosmos world foundation model platform for physical ai. arXiv preprint arXiv:2501.03575, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[16]
Ctrl- world: A controllable generative world model for robot manipulation, 2025
Yanjiang Guo, Lucy Xiaoyang Shi, Jianyu Chen, and Chelsea Finn. Ctrl- world: A controllable generative world model for robot manipulation, 2025
2025
-
[17]
Learning real- world action-video dynamics with heterogeneous masked autoregression, 2025
Lirui Wang, Kevin Zhao, Chaoqi Liu, and Xinlei Chen. Learning real- world action-video dynamics with heterogeneous masked autoregression, 2025
2025
-
[18]
Unified world models: Coupling video and action diffusion for pretraining on large robotic datasets, 2025
Chuning Zhu, Raymond Yu, Siyuan Feng, Benjamin Burchfiel, Paarth Shah, and Abhishek Gupta. Unified world models: Coupling video and action diffusion for pretraining on large robotic datasets, 2025
2025
-
[19]
Unifolm-wma-0: A world-model-action (wma) framework under unifolm family, 2025
Unitree. Unifolm-wma-0: A world-model-action (wma) framework under unifolm family, 2025
2025
-
[20]
Wristworld: Generating wrist-views via 4d world models for robotic manipulation, 2025
Zezhong Qian, Xiaowei Chi, Yuming Li, Shizun Wang, Zhiyuan Qin, Xiaozhu Ju, Sirui Han, and Shanghang Zhang. Wristworld: Generating wrist-views via 4d world models for robotic manipulation, 2025
2025
-
[21]
Magicworld: Interactive geometry- driven video world exploration, 2025
Guangyuan Li, Siming Zheng, Shuolin Xu, Jinwei Chen, Bo Li, Xiaobin Hu, Lei Zhao, and Peng-Tao Jiang. Magicworld: Interactive geometry- driven video world exploration, 2025
2025
-
[22]
Roboscape: Physics-informed embodied world model, 2025
Yu Shang, Xin Zhang, Yinzhou Tang, Lei Jin, Chen Gao, Wei Wu, and Yong Li. Roboscape: Physics-informed embodied world model, 2025
2025
-
[23]
Learning primitive embodied world models: Towards scalable robotic learning, 2025
Qiao Sun, Liujia Yang, Wei Tang, Wei Huang, Kaixin Xu, Yongchao Chen, Mingyu Liu, Jiange Yang, Haoyi Zhu, Yating Wang, Tong He, Yilun Chen, Xili Dai, Nanyang Ye, and Qinying Gu. Learning primitive embodied world models: Towards scalable robotic learning, 2025
2025
-
[24]
Tesseract: Learning 4d embodied world models, 2025
Haoyu Zhen, Qiao Sun, Hongxin Zhang, Junyan Li, Siyuan Zhou, Yilun Du, and Chuang Gan. Tesseract: Learning 4d embodied world models, 2025
2025
-
[25]
Orv: 4d occupancy-centric robot video generation, 2025
Xiuyu Yang, Bohan Li, Shaocong Xu, Nan Wang, Chongjie Ye, Zhaoxi Chen, Minghan Qin, Yikang Ding, Zheng Zhu, Xin Jin, Hang Zhao, and Hao Zhao. Orv: 4d occupancy-centric robot video generation, 2025
2025
-
[26]
Tracegen: World modeling in 3d trace space enables learning from cross-embodiment videos, 2025
Seungjae Lee, Yoonkyo Jung, Inkook Chun, Yao-Chih Lee, Zikui Cai, Hongjia Huang, Aayush Talreja, Tan Dat Dao, Yongyuan Liang, Jia-Bin Huang, and Furong Huang. Tracegen: World modeling in 3d trace space enables learning from cross-embodiment videos, 2025
2025
-
[27]
Dynam- icrafter: Animating open-domain images with video diffusion priors, 2023
Jinbo Xing, Menghan Xia, Yong Zhang, Haoxin Chen, Wangbo Yu, Hanyuan Liu, Xintao Wang, Tien-Tsin Wong, and Ying Shan. Dynam- icrafter: Animating open-domain images with video diffusion priors, 2023
2023
-
[28]
Wan: Open and Advanced Large-Scale Video Generative Models
Team Wan, Ang Wang, Baole Ai, Bin Wen, Chaojie Mao, Chen-Wei Xie, Di Chen, Feiwu Yu, Haiming Zhao, Jianxiao Yang, et al. Wan: Open and advanced large-scale video generative models.arXiv preprint arXiv:2503.20314, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[29]
Genie: Generative interactive environments, 2024
Jake Bruce, Michael Dennis, Ashley Edwards, Jack Parker-Holder, Yuge Shi, Edward Hughes, Matthew Lai, Aditi Mavalankar, Richie Steigerwald, Chris Apps, Yusuf Aytar, Sarah Bechtle, Feryal Behbahani, Stephanie Chan, Nicolas Heess, Lucy Gonzalez, Simon Osindero, Sherjil Ozair, Scott Reed, Jingwei Zhang, Konrad Zolna, Jeff Clune, Nando de Freitas, Satinder Si...
2024
-
[30]
ivideogpt: Interactive videogpts are scalable world models, 2024
Jialong Wu, Shaofeng Yin, Ningya Feng, Xu He, Dong Li, Jianye Hao, and Mingsheng Long. ivideogpt: Interactive videogpts are scalable world models, 2024
2024
-
[31]
Irasim: A fine-grained world model for robot manipulation, 2025
Fangqi Zhu, Hongtao Wu, Song Guo, Yuxiao Liu, Chilam Cheang, and Tao Kong. Irasim: A fine-grained world model for robot manipulation, 2025
2025
-
[32]
Enerverse-ac: Envisioning embodied environ- ments with action condition, 2025
Yuxin Jiang, Shengcong Chen, Siyuan Huang, Liliang Chen, Pengfei Zhou, Yue Liao, Xindong He, Chiming Liu, Hongsheng Li, Maoqing Yao, and Guanghui Ren. Enerverse-ac: Envisioning embodied environ- ments with action condition, 2025
2025
-
[33]
Video depth anything: Consistent depth estimation for super-long videos, 2025
Sili Chen, Hengkai Guo, Shengnan Zhu, Feihu Zhang, Zilong Huang, Jiashi Feng, and Bingyi Kang. Video depth anything: Consistent depth estimation for super-long videos, 2025
2025
-
[34]
Sam 2: Segment anything in images and videos, 2024
Nikhila Ravi, Valentin Gabeur, Yuan-Ting Hu, Ronghang Hu, Chaitanya Ryali, Tengyu Ma, Haitham Khedr, Roman R¨adle, Chloe Rolland, Laura Gustafson, Eric Mintun, Junting Pan, Kalyan Vasudev Alwala, Nicolas Carion, Chao-Yuan Wu, Ross Girshick, Piotr Doll ´ar, and Christoph Feichtenhofer. Sam 2: Segment anything in images and videos, 2024
2024
-
[35]
Motionctrl: A unified and flexible motion controller for video generation, 2024
Zhouxia Wang, Ziyang Yuan, Xintao Wang, Tianshui Chen, Menghan Xia, Ping Luo, and Ying Shan. Motionctrl: A unified and flexible motion controller for video generation, 2024
2024
-
[36]
Qingwen Bu, Jisong Cai, Li Chen, Xiuqi Cui, Yan Ding, Siyuan Feng, Shenyuan Gao, Xindong He, Xuan Hu, Xu Huang, et al. Agibot world colosseo: A large-scale manipulation platform for scalable and intelligent embodied systems.arXiv preprint arXiv:2503.06669, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[37]
Ewmbench: Evaluating scene, motion, and semantic quality in embodied world models, 2025
Hu Yue, Siyuan Huang, Yue Liao, Shengcong Chen, Pengfei Zhou, Liliang Chen, Maoqing Yao, and Guanghui Ren. Ewmbench: Evaluating scene, motion, and semantic quality in embodied world models, 2025
2025
-
[38]
Yolo-world: Real-time open-vocabulary object detection, 2024
Tianheng Cheng, Lin Song, Yixiao Ge, Wenyu Liu, Xinggang Wang, and Ying Shan. Yolo-world: Real-time open-vocabulary object detection, 2024
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.