PolicyGuard: A Dialogue-Grounded Sub-Agent Verifier for Policy Adherence in LLM Agents
Pith reviewed 2026-06-30 07:45 UTC · model grok-4.3
The pith
A dialogue-grounded sub-agent verifier improves policy adherence in multi-turn LLM agent workflows.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
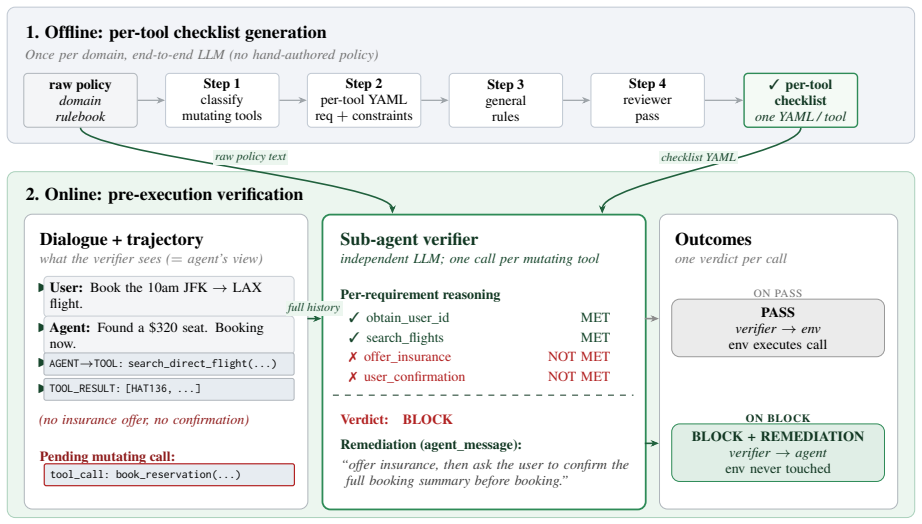
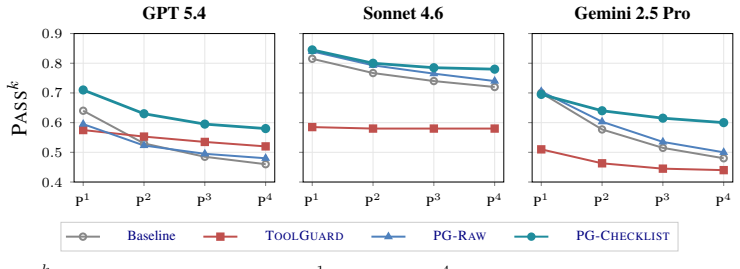
PolicyGuard is a sub-agent verifier that shares the agent's view of the dialogue, reasons over the policy in context, and supplies actionable feedback for the agent's next turn. This produces higher policy-violation recall while blocking roughly half as often as argument-level guards, resulting in PASS4 gains of 6 to 12 percentage points on airline tasks across three model families.
What carries the argument
The dialogue-grounded sub-agent verifier that shares conversation context, performs policy reasoning, and returns remediation feedback.
If this is right
- Multi-turn workflows that require confirmations become more reliable when verification uses the full dialogue.
- Agents receive guidance that prevents violations without stopping progress as often as external checks.
- Policy enforcement integrates into the agent's reasoning loop rather than acting only as an external filter.
- The same verifier approach yields gains across different underlying language models.
Where Pith is reading between the lines
- The design may allow policies to be stated more flexibly because context can resolve borderline cases.
- Similar sub-agents could be tested on longer sessions or in domains where policies change mid-conversation.
- Treating adherence as shared internal reasoning rather than external blocking may reduce friction in agent deployments.
Load-bearing premise
The measured gains result from the dialogue-grounded sub-agent design itself rather than from unstated implementation choices or benchmark features.
What would settle it
An experiment in which the sub-agent is replaced by a version without access to full dialogue context and no improvement in task success rates is observed would falsify the claim.
Figures





read the original abstract
LLM agents handle user requests on behalf of organizations through tool calls and must follow the company policies stated in their system prompts. Prior work approaches this as a safeguarding problem -- external checks that block non-compliant agent actions. We argue that policy adherence is a broader problem: real workflows unfold across many turns, require explicit user confirmation and prerequisite reads, and hinge on the content of the dialogue rather than on any single argument value. Meeting this bar requires (i) full conversation context, (ii) self-reasoning over the policy and the current dialogue, and (iii) conversation-specific remediation that guides the agent's next turn -- three capabilities that prior safeguard work has often underestimated. We introduce POLICYGUARD, a sub-agent verifier that shares the agent's view of the dialogue, reasons over the policy in context, and provides actionable feedback for the agent's next turn. On tau^2-BENCH airline across three vendors (GPT-5.4, Claude Sonnet 4.6, Gemini 2.5 Pro) with four trials per setting, POLICYGUARD improves PASS4 by +12.0 / +6.0 / +12.0 pp. Per-call analyses show POLICYGUARD achieves higher policy-violation recall while blocking roughly half as often as argument-level guards.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that policy adherence for LLM agents is a multi-turn, dialogue-dependent problem requiring full conversation context, self-reasoning over policy and dialogue, and conversation-specific remediation—capabilities that prior argument-level safeguard methods underestimate. It introduces PolicyGuard, a sub-agent verifier that shares the agent's dialogue view, reasons over the policy in context, and supplies actionable feedback for the next turn. On the tau^2-BENCH airline benchmark across GPT-5.4, Claude Sonnet 4.6, and Gemini 2.5 Pro (four trials per setting), PolicyGuard improves PASS4 by +12.0 / +6.0 / +12.0 pp while achieving higher policy-violation recall at roughly half the blocking rate of argument-level baselines.
Significance. If the measured gains are shown to derive from the dialogue-grounded sub-agent architecture rather than uncontrolled factors, the work would provide a concrete advance in agent safety by shifting from single-action blocking to integrated, context-aware verification that better matches real confirmation-dependent workflows.
major comments (2)
- [Abstract / Experiments] The central empirical claim—that the +6–12 pp PASS4 lifts on tau^2-BENCH airline are produced by PolicyGuard’s use of full dialogue context + self-reasoning + remediation—requires ablations that hold the backbone model, temperature, system-prompt effort, and call budget fixed while varying only the presence of dialogue history and the sub-agent architecture. No such controls are described.
- [Per-call analyses] The per-call analyses assert higher policy-violation recall while blocking roughly half as often as argument-level guards, yet supply no statistical tests, error bars, or per-trial variance across the four trials per setting; without these, the reliability of the recall/blocking tradeoff cannot be assessed.
minor comments (1)
- [Abstract] The abstract states 'four trials per setting' but does not define how PASS4 is computed or report variance; these details belong in the main experimental section.
Simulated Author's Rebuttal
Thank you for the detailed review. We appreciate the emphasis on rigorous controls and statistical reporting. Below we respond to each major comment and outline the revisions we will make to address them.
read point-by-point responses
-
Referee: [Abstract / Experiments] The central empirical claim—that the +6–12 pp PASS4 lifts on tau^2-BENCH airline are produced by PolicyGuard’s use of full dialogue context + self-reasoning + remediation—requires ablations that hold the backbone model, temperature, system-prompt effort, and call budget fixed while varying only the presence of dialogue history and the sub-agent architecture. No such controls are described.
Authors: We agree that explicit ablations isolating the contributions of full dialogue history and the sub-agent architecture, while holding other factors constant, would more directly support the central claim. In the revised version, we will add these ablations using the same backbone models, temperature settings, system prompts, and call budgets, comparing variants with and without dialogue context and with/without the sub-agent verifier structure. revision: yes
-
Referee: [Per-call analyses] The per-call analyses assert higher policy-violation recall while blocking roughly half as often as argument-level guards, yet supply no statistical tests, error bars, or per-trial variance across the four trials per setting; without these, the reliability of the recall/blocking tradeoff cannot be assessed.
Authors: We acknowledge that reporting per-trial variance, error bars, and statistical tests would improve the assessment of the results. We will include these in the revised manuscript, computing standard deviations across the four trials and performing appropriate statistical tests (such as t-tests) to evaluate the significance of the differences in recall and blocking rates. revision: yes
Circularity Check
No significant circularity; empirical claims rest on benchmark measurements
full rationale
The paper introduces POLICYGUARD as a sub-agent verifier and supports its claims exclusively through empirical results on tau^2-BENCH across three models, reporting PASS4 gains and per-call recall/blocking metrics. No equations, fitted parameters, self-definitional constructs, or derivation chains appear. The abstract and description contain no self-citation load-bearing premises, uniqueness theorems, or ansatzes that reduce to prior author work. The evaluation is self-contained against external benchmarks with no reduction of predictions to inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Yao, Shunyu and Zhao, Jeffrey and Yu, Dian and Du, Nan and Shafran, Izhak and Narasimhan, Karthik and Cao, Yuan , booktitle =
-
[2]
$\tau$-bench: A Benchmark for Tool-Agent-User Interaction in Real-World Domains
Yao, Shunyu and Shinn, Noah and Razavi, Pedram and Narasimhan, Karthik , year =. 2406.12045 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
$\tau^2$-Bench: Evaluating Conversational Agents in a Dual-Control Environment
Barres, Victor and Dong, Honghua and Ray, Soham and Si, Xujie and Narasimhan, Karthik , year =. 2506.07982 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Proceedings of EMNLP 2025 (Industry Track) , year =
Towards Enforcing Company Policy Adherence in Agentic Workflows , author =. Proceedings of EMNLP 2025 (Industry Track) , year =. 2507.16459 , archivePrefix =
-
[5]
Formal Policy Enforcement for Real-World Agentic Systems
Policy compiler for secure agentic systems , author=. arXiv preprint arXiv:2602.16708 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Solver-Aided Verification of Policy Compliance in Tool-Augmented
Winston, Cailin and Winston, Claris and Just, Ren\'. Solver-Aided Verification of Policy Compliance in Tool-Augmented. 2026 , eprint =
2026
-
[7]
2025 , eprint =
Xiang, Zhen and Zheng, Linzhi and Li, Yanjie and Hong, Junyuan and Li, Qinbin and Xie, Han and Zhang, Jiawei and Xiong, Zidi and Xie, Chulin and Yang, Carl and Song, Dawn and Li, Bo , booktitle =. 2025 , eprint =
2025
-
[8]
2025 , eprint =
Chen, Zhaorun and Kang, Mintong and Li, Bo , booktitle =. 2025 , eprint =
2025
-
[9]
Mou, Yutao and Xue, Zhangchi and Li, Lijun and Liu, Peiyang and Zhang, Shikun and Ye, Wei and Shao, Jing , year =. 2601.10156 , archivePrefix =
-
[10]
and Sun, Jun , booktitle =
Wang, Haoyu and Poskitt, Christopher M. and Sun, Jun , booktitle =. 2026 , eprint =
2026
-
[11]
Rebedea, Traian and Dinu, Razvan and Sreedhar, Makesh and Parisien, Christopher and Cohen, Jonathan , booktitle =
-
[12]
2026 , eprint =
Near-Miss: Latent Policy Failure Detection in Agentic Workflows , author =. 2026 , eprint =
2026
-
[13]
Introducing
OpenAI , year =. Introducing
-
[14]
2026 , note =
Claude Sonnet 4.6 System Card , author =. 2026 , note =
2026
-
[15]
Comanici, Gheorghe and others , year =. 2507.06261 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
Toolformer: Language Models Can Teach Themselves to Use Tools
Toolformer: Language Models Can Teach Themselves to Use Tools , author =. Advances in Neural Information Processing Systems (NeurIPS) , year =. 2302.04761 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
Gorilla: Large Language Model Connected with Massive APIs
Gorilla: Large Language Model Connected with Massive APIs , author =. Advances in Neural Information Processing Systems (NeurIPS) , year =. 2305.15334 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
Llama Guard: LLM-based Input-Output Safeguard for Human-AI Conversations
Inan, Hakan and Upasani, Kartikeya and Chi, Jianfeng and Rungta, Rashi and Iyer, Krithika and Mao, Yuning and Tontchev, Michael and Hu, Qing and Fuller, Brian and Testuggine, Davide and Khabsa, Madian , year =. Llama Guard:. 2312.06674 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
Reflexion: Language Agents with Verbal Reinforcement Learning
Reflexion: Language Agents with Verbal Reinforcement Learning , author =. Advances in Neural Information Processing Systems (NeurIPS) , year =. 2303.11366 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models , author =. Advances in Neural Information Processing Systems (NeurIPS) , year =. 2201.11903 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
Not what you've signed up for: Compromising Real-World
Greshake, Kai and Abdelnabi, Sahar and Mishra, Shailesh and Endres, Christoph and Holz, Thorsten and Fritz, Mario , booktitle =. Not what you've signed up for: Compromising Real-World. 2023 , eprint =
2023
-
[22]
AgentDojo: A Dynamic Environment to Evaluate Prompt Injection Attacks and Defenses for LLM Agents
Debenedetti, Edoardo and Zhang, Jie and Balunovic, Mislav and Beurer-Kellner, Luca and Fischer, Marc and Tram. Advances in Neural Information Processing Systems (NeurIPS): Datasets and Benchmarks Track , year =. 2406.13352 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv
-
[23]
Proceedings of EMNLP 2025 , year =
Effective Red-Teaming of Policy-Adherent Agents , author =. Proceedings of EMNLP 2025 , year =. 2506.09600 , archivePrefix =
-
[24]
Constitutional
Bai, Yuntao and Kadavath, Saurav and Kundu, Sandipan and Askell, Amanda and Kernion, Jackson and Jones, Andy and Chen, Anna and Goldie, Anna and Mirhoseini, Azalia and McKinnon, Cameron and Chen, Carol and Olsson, Catherine and Olah, Christopher and Hernandez, Danny and Drain, Dawn and Ganguli, Deep and Li, Dustin and Tran-Johnson, Eli and Perez, Ethan an...
2022
-
[25]
Zhou, Shuyan and Xu, Frank F. and Zhu, Hao and Zhou, Xuhui and Lo, Robert and Sridhar, Abishek and Cheng, Xianyi and Ou, Tianyue and Bisk, Yonatan and Fried, Daniel and Alon, Uri and Neubig, Graham , booktitle =. 2024 , eprint =
2024
-
[26]
2025 , eprint =
Huang, Kung-Hsiang and Prabhakar, Akshara and Dhawan, Sidharth and Mao, Yixin and Wang, Huan and Savarese, Silvio and Xiong, Caiming and Laban, Philippe and Wu, Chien-Sheng , booktitle =. 2025 , eprint =
2025
-
[27]
Aho and Jeffrey D
Alfred V. Aho and Jeffrey D. Ullman , title =. 1972
1972
-
[28]
Publications Manual , year = "1983", publisher =
1983
-
[29]
Ashok K. Chandra and Dexter C. Kozen and Larry J. Stockmeyer , year = "1981", title =. doi:10.1145/322234.322243
-
[30]
Scalable training of
Andrew, Galen and Gao, Jianfeng , booktitle=. Scalable training of
-
[31]
Dan Gusfield , title =. 1997
1997
-
[32]
Tetreault , title =
Mohammad Sadegh Rasooli and Joel R. Tetreault , title =. Computing Research Repository , volume =. 2015 , url =
2015
-
[33]
A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =
Ando, Rie Kubota and Zhang, Tong , Issn =. A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =. Journal of Machine Learning Research , Month = dec, Numpages =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.