Parametric Skills
Pith reviewed 2026-06-30 06:18 UTC · model grok-4.3
The pith
A hypernetwork converts textual skills into LoRA adapters at test time, enabling context-free exploitation that outperforms in-context learning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
ParametricSkills trains a hypernetwork on synthesized trajectories so that any free-form textual skill can be turned into a LoRA adapter; once inserted, the adapter lets the model exploit the skill without the original text in context, producing stronger results than in-context learning on complex software-engineering subtasks while also supporting additive skill accumulation over time.
What carries the argument
The hypernetwork that maps a textual skill description to a set of LoRA adapter weights for insertion into the base model.
If this is right
- Skills become usable without occupying context length or requiring precise instruction following.
- Average performance on the six SWE subtasks rises 6.44 points relative to in-context learning.
- BERT Score and F1 both increase, indicating both semantic and surface-level improvements.
- Skills can be added incrementally at test time without retraining the base model.
Where Pith is reading between the lines
- Because the adapters are additive, the same hypernetwork could support skill libraries that grow across sessions or users without interference.
- The separation of skill content from the base model weights may allow the same learned adapters to be reused or composed on different base models.
- If the hypernetwork generalizes, new skills could be created from a few demonstrations and immediately turned into adapters without manual rewriting.
Load-bearing premise
The single-turn and multi-turn trajectories synthesized with OpenCode around the collected skills are representative of the exploitation patterns that will appear at test time.
What would settle it
A clear drop in the reported gains when the same hypernetwork is tested on software-engineering problems whose structure or distribution differs markedly from the OpenCode-synthesized training set.
Figures






read the original abstract
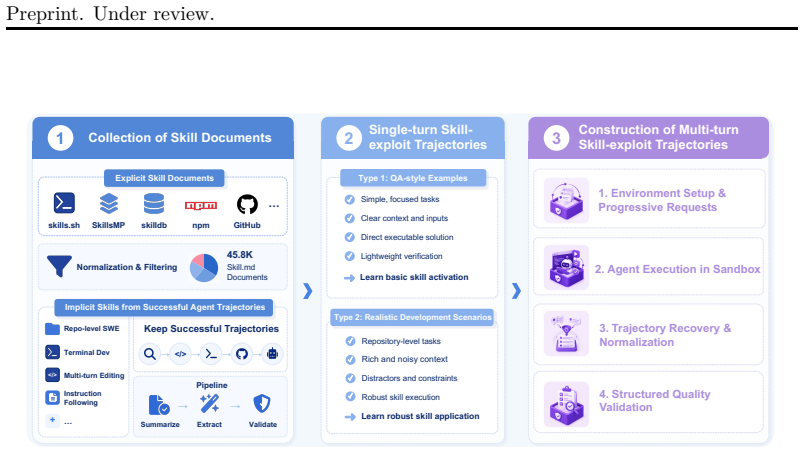
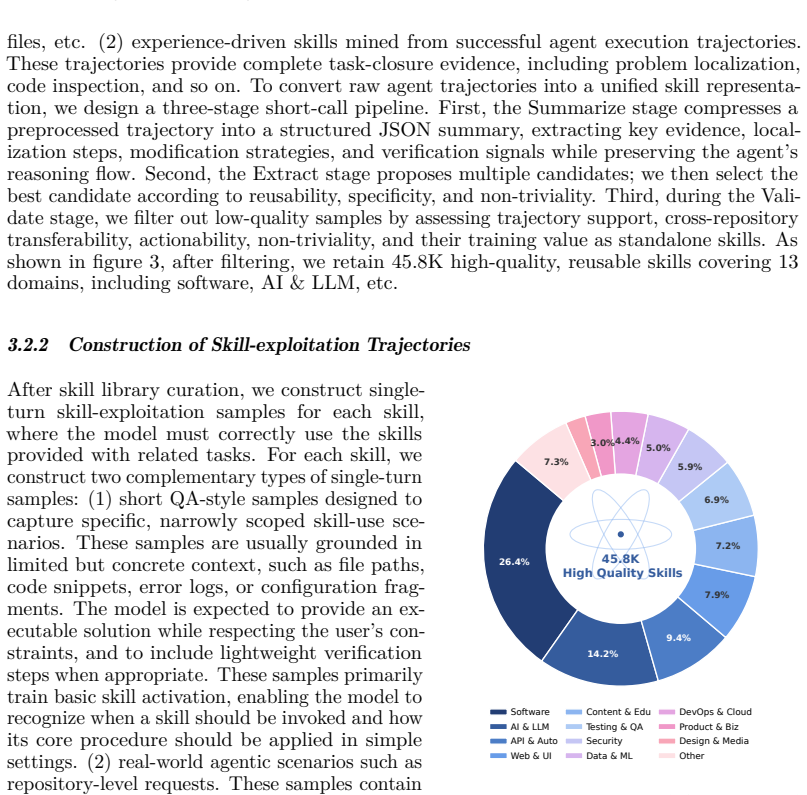
Since intelligence fundamentally relies on efficient skill acquisition (Chollet, 2019), the ability to leverage skills is critical. For LLMs, skills, manually authored or extracted from task trajectories, are textual recipes encoding mature problem-solving experience and are critical to agentic capabilities. Despite widespread deployment, their utility is limited by the model's ability to comprehend and follow skill instructions, especially under complex and long-context scenarios, where key instructions are difficult to locate and adhere to. To address this limitation, we propose ParametricSkills, a framework that can convert free-form textual skills into parameters at test time, enabling context-free skill exploitation. Specifically, we first construct a large-scale, high-quality skill library, and synthesize single-turn and multi-turn skill exploitation trajectories built around these skills with OpenCode. Using these data, we then train a hypernetwork that parameterizes both the skill content and the test-time exploitation methodology by receiving textual skills and converting them into LoRA adapters. Experimental results on six complex software engineering (SWE) subtasks demonstrate that, the proposed ParametricSkills averagely outperforms in-context learning by 6.44 points as judged by DeepSeek-V4-Flash, while also achieving significantly higher BERT Score and F1 score, confirming its effectiveness. Beyond performance, we further find that parametric skills, being inherently accumulative, offer a preliminary yet promising avenue toward test-time continual learning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes ParametricSkills, a framework that trains a hypernetwork to convert free-form textual skills into LoRA adapters at test time. Skills are drawn from a constructed library; single- and multi-turn exploitation trajectories are synthesized with OpenCode; the hypernetwork is trained on these trajectories so that skill content and exploitation methodology are both parameterized. On six software-engineering subtasks the method is reported to outperform in-context learning by an average of 6.44 points according to DeepSeek-V4-Flash judgments, while also showing higher BERT Score and F1; the authors further note that the parametric representation is inherently accumulative and therefore offers a route to test-time continual learning.
Significance. If the performance advantage can be shown to reflect genuine task improvement rather than evaluator artifact, the work would supply a concrete mechanism for making skills context-free and accumulative, addressing a recognized bottleneck in long-context agentic behavior. The hypernetwork approach to skill parameterization is technically distinct from standard in-context or retrieval-based methods and, if reproducible, would constitute a measurable advance in the direction of continual, parameter-level skill acquisition.
major comments (2)
- [Abstract] Abstract: the headline claim of a 6.44-point average improvement rests exclusively on judgments produced by DeepSeek-V4-Flash. No calibration against human labels, inter-annotator agreement, or correlation with execution-based correctness is reported. Because the judge is the sole source of the numeric superiority, any systematic preference for the LoRA-injected output style or for the syntactic patterns of OpenCode-synthesized trajectories would render the central performance claim uninterpretable.
- [Abstract] Abstract and experimental description: the training trajectories are synthesized separately via OpenCode, yet no analysis is provided of how well these trajectories cover the distribution of real test-time exploitation scenarios. The weakest assumption—that the synthetic single- and multi-turn data suffice for generalization—is therefore load-bearing for the reported gains, but remains untested.
minor comments (2)
- [Abstract] The abstract states that ParametricSkills also achieves “significantly higher BERT Score and F1 score,” but does not indicate whether these metrics correlate with the LLM-judge scores or with any execution-based ground truth.
- [Abstract] No information is given on the number of runs, variance, or statistical tests supporting the 6.44-point figure.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below and indicate where revisions will be made to the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the headline claim of a 6.44-point average improvement rests exclusively on judgments produced by DeepSeek-V4-Flash. No calibration against human labels, inter-annotator agreement, or correlation with execution-based correctness is reported. Because the judge is the sole source of the numeric superiority, any systematic preference for the LoRA-injected output style or for the syntactic patterns of OpenCode-synthesized trajectories would render the central performance claim uninterpretable.
Authors: We agree that the 6.44-point figure depends on the LLM judge and that explicit calibration to human labels or execution-based metrics is not reported. At the same time, the manuscript already presents significantly higher BERT Score and F1 as orthogonal, automatic metrics that do not rely on the judge. These results indicate improved semantic similarity and precision independent of any stylistic bias. We will revise the abstract and results section to foreground the automatic metrics, add a limitations paragraph discussing possible judge biases, and qualify the headline claim accordingly. revision: partial
-
Referee: [Abstract] Abstract and experimental description: the training trajectories are synthesized separately via OpenCode, yet no analysis is provided of how well these trajectories cover the distribution of real test-time exploitation scenarios. The weakest assumption—that the synthetic single- and multi-turn data suffice for generalization—is therefore load-bearing for the reported gains, but remains untested.
Authors: The single- and multi-turn trajectories were generated with OpenCode specifically to produce exploitation sequences grounded in the skill library for software-engineering contexts. While we did not conduct an explicit distributional overlap analysis between the synthetic data and real test-time scenarios, the consistent gains across six diverse subtasks provide indirect support for generalization. We will expand the experimental section with additional detail on the synthesis procedure and add a limitations discussion that explicitly notes the untested coverage assumption. revision: partial
Circularity Check
No circularity; empirical gains rest on held-out evaluation after separate synthesis
full rationale
The paper describes constructing a skill library, synthesizing trajectories via OpenCode, training a hypernetwork to produce LoRA adapters from textual skills, and then reporting average gains of 6.44 points (plus BERT/F1) versus in-context learning on six SWE subtasks. No equations, fitted-parameter renamings, or self-citation chains appear that would make the reported performance reduce to the training inputs by construction. The evaluation is on held-out tasks with metrics external to the hypernetwork training loop, rendering the central claim self-contained rather than tautological.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
EvoSkill: Automated Skill Discovery for Multi-Agent Systems
Salaheddin Alzubi, Noah Provenzano, Jaydon Bingham, Weiyuan Chen, and Tu Vu. Evoskill: Automated skill discovery for multi-agent systems.arXiv preprint arXiv:2603.02766,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Proceedings of the 42nd International Conference on Machine Learning (ICML) , year =
Accessed: 2026-06-26. Rujikorn Charakorn, Edoardo Cetin, Yujin Tang, and Robert Tjarko Lange. Text-to-lora: Instant transformer adaption.arXiv preprint arXiv:2506.06105,
-
[3]
arXiv preprint arXiv:2602.15902 , year =
Rujikorn Charakorn, Edoardo Cetin, Shinnosuke Uesaka, and Robert Tjarko Lange. Doc- to-lora: Learning to instantly internalize contexts.arXiv preprint arXiv:2602.15902,
-
[4]
On the Measure of Intelligence
François Chollet. On the measure of intelligence.arXiv preprint arXiv:1911.01547,
work page internal anchor Pith review Pith/arXiv arXiv 1911
-
[5]
Accessed: 2026-06-23
URL https://github.com/sst/opencode. Accessed: 2026-06-23. DeepSeek-AI. Deepseek-v4: Towards highly efficient million-token context intelligence,
2026
-
[6]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, et al. The llama 3 herd of models.arXiv preprint arXiv:2407.21783,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
David Ha, Andrew Dai, and Quoc V Le. Hypernetworks.arXiv preprint arXiv:1609.09106,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Yichen Huang and Lin F Yang. Winning gold at imo 2025 with a model-agnostic verification- and-refinement pipeline.arXiv preprint arXiv:2507.15855,
-
[9]
Search-R1: Training LLMs to Reason and Leverage Search Engines with Reinforcement Learning
Bowen Jin, Hansi Zeng, Zhenrui Yue, Jinsung Yoon, Sercan Arik, Dong Wang, Hamed Zamani, and Jiawei Han. Search-r1: Training llms to reason and leverage search engines with reinforcement learning.arXiv preprint arXiv:2503.09516,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Achieving Gold-Medal-Level Olympiad Reasoning via Simple and Unified Scaling
Yafu Li, Runzhe Zhan, Haoran Zhang, Shunkai Zhang, Yizhuo Li, Zhilin Wang, Jiacheng Chen, Futing Wang, Xuyang Hu, Yuchen Fan, et al. Achieving gold-medal-level olympiad reasoning via simple and unified scaling.arXiv preprint arXiv:2605.13301,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Jiaye Lin, Yifu Guo, Yuzhen Han, Sen Hu, Ziyi Ni, Licheng Wang, Mingguang Chen, Hongzhang Liu, Ronghao Chen, Yangfan He, et al. Se-agent: Self-evolution trajectory op- timization in multi-step reasoning with llm-based agents.arXiv preprint arXiv:2508.02085,
-
[12]
A comprehensive survey on long context language modeling.arXiv preprint arXiv:2503.17407,
Jiaheng Liu, Dawei Zhu, Zhiqi Bai, Yancheng He, Huanxuan Liao, Haoran Que, Zekun Wang, Chenchen Zhang, Ge Zhang, Jiebin Zhang, et al. A comprehensive survey on long context language modeling.arXiv preprint arXiv:2503.17407,
-
[13]
SHINE: A Scalable In-Context Hypernetwork for Mapping Context to LoRA in a Single Pass
9 Preprint. Under review. Yewei Liu, Xiyuan Wang, Yansheng Mao, Yoav Gelbery, Haggai Maron, and Muhan Zhang. Shine: A scalable in-context hypernetwork for mapping context to lora in a single pass. arXiv preprint arXiv:2602.06358,
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
RoBERTa: A Robustly Optimized BERT Pretraining Approach
Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, and Veselin Stoyanov. Roberta: A robustly optimized bert pretraining approach.arXiv preprint arXiv:1907.11692,
work page internal anchor Pith review Pith/arXiv arXiv 1907
-
[15]
Decoupled Weight Decay Regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization.arXiv preprint arXiv:1711.05101,
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
SKILL0: In-Context Agentic Reinforcement Learning for Skill Internalization
Zhengxi Lu, Zhiyuan Yao, Jinyang Wu, Chengcheng Han, Qi Gu, Xunliang Cai, Weiming Lu, Jun Xiao, Yueting Zhuang, and Yongliang Shen. Skill0: In-context agentic reinforcement learning for skill internalization.arXiv preprint arXiv:2604.02268,
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
Long Phan, Alice Gatti, Ziwen Han, Nathaniel Li, Josephina Hu, Hugh Zhang, Chen Bo Calvin Zhang, Mohamed Shaaban, John Ling, Sean Shi, et al. Humanity’s last exam. arXiv preprint arXiv:2501.14249,
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
Skill1: Unified Evolution of Skill-Augmented Agents via Reinforcement Learning
Yaorui Shi, Yuxin Chen, Zhengxi Lu, Yuchun Miao, Shugui Liu, Qi Gu, Xunliang Cai, Xiang Wang, and An Zhang. Skill1: Unified evolution of skill-augmented agents via reinforcement learning.arXiv preprint arXiv:2605.06130,
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
ALFWorld: Aligning Text and Embodied Environments for Interactive Learning
Mohit Shridhar, Xingdi Yuan, Marc-Alexandre Côté, Yonatan Bisk, Adam Trischler, and Matthew Hausknecht. Alfworld: Aligning text and embodied environments for interactive learning.arXiv preprint arXiv:2010.03768,
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[20]
Skill-SD: Skill-Conditioned Self-Distillation for Multi-turn LLM Agents
Hao Wang, Guozhi Wang, Han Xiao, Yufeng Zhou, Yue Pan, Jichao Wang, Ke Xu, Yafei Wen, Xiaohu Ruan, Xiaoxin Chen, et al. Skill-sd: Skill-conditioned self-distillation for multi-turn llm agents.arXiv preprint arXiv:2604.10674, 2026a. Miles Wang, Robi Lin, Kat Hu, Joy Jiao, Neil Chowdhury, Ethan Chang, and Tejal Pat- wardhan. Frontierscience: Evaluating ai’s...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[21]
SkillRL: Evolving Agents via Recursive Skill-Augmented Reinforcement Learning
Peng Xia, Jianwen Chen, Hanyang Wang, Jiaqi Liu, Kaide Zeng, Yu Wang, Siwei Han, Yiyang Zhou, Xujiang Zhao, Haifeng Chen, et al. Skillrl: Evolving agents via recursive skill-augmented reinforcement learning.arXiv preprint arXiv:2602.08234,
work page internal anchor Pith review Pith/arXiv arXiv
-
[22]
Yicheng Xiao, Lin Song, Rui Yang, Cheng Cheng, Yixiao Ge, Xiu Li, and Ying Shan. Lora-gen: Specializing large language model via online lora generation.arXiv preprint arXiv:2506.11638,
-
[23]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388,
work page internal anchor Pith review Pith/arXiv arXiv
-
[24]
ARIS: Autonomous Research via Adversarial Multi-Agent Collaboration
Ruofeng Yang, Yongcan Li, and Shuai Li. Aris: Autonomous research via adversarial multi-agent collaboration.arXiv preprint arXiv:2605.03042, 2026a. 10 Preprint. Under review. Yifan Yang, Ziyang Gong, Weiquan Huang, Qihao Yang, Ziwei Zhou, Zisu Huang, Yan Li, Xuemei Gao, Qi Dai, Bei Liu, et al. Skillopt: Executive strategy for self-evolving agent skills.ar...
work page internal anchor Pith review Pith/arXiv arXiv
-
[25]
Fangchen Yu, Haiyuan Wan, Qianjia Cheng, Yuchen Zhang, Jiacheng Chen, Fujun Han, Yulun Wu, Junchi Yao, Ruilizhen Hu, Ning Ding, et al. Hipho: How far are (m) llms from humans in the latest high school physics olympiad benchmark?arXiv preprint arXiv:2509.07894,
-
[26]
GLM-5: from Vibe Coding to Agentic Engineering
Aohan Zeng, Xin Lv, Zhenyu Hou, Zhengxiao Du, Qinkai Zheng, Bin Chen, Da Yin, Chendi Ge, Chenghua Huang, Chengxing Xie, et al. Glm-5: from vibe coding to agentic engineering. arXiv preprint arXiv:2602.15763,
work page internal anchor Pith review Pith/arXiv arXiv
-
[27]
CoEvoSkills: Self-Evolving Agent Skills via Co-Evolutionary Verification
Hanrong Zhang, Shicheng Fan, Henry Peng Zou, Yankai Chen, Zhenting Wang, Jiayu Zhou, Chengze Li, Wei-Chieh Huang, Yifei Yao, Kening Zheng, et al. Coevoskills: Self-evolving agent skills via co-evolutionary verification.arXiv preprint arXiv:2604.01687,
work page internal anchor Pith review Pith/arXiv arXiv
-
[28]
A Comprehensive Survey on Agent Skills: Taxonomy, Techniques, and Applications
Yingli Zhou, Wang Shu, Yaodong Su, Wenchuan Du, Yixiang Fang, and Xuemin Lin. A comprehensive survey on agent skills: Taxonomy, techniques, and applications.arXiv preprint arXiv:2605.07358,
work page internal anchor Pith review Pith/arXiv arXiv
-
[29]
POST" and id=None. cls.create(attach_host_name=False, method=
and the search- augmented question-answering benchmark Search-QA (Jin et al., 2025).ParametricSkills shares the skill-to-LoRA backbone but differs in three aspects: (i) we target real-world agentic tasks such as production-level software engineering rather than a simple demonstration on ALFWorld and Search-QA, (ii) we construct a comprehensive skills libr...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.