Recognition: 2 theorem links
· Lean TheoremARIS: Autonomous Research via Adversarial Multi-Agent Collaboration
Pith reviewed 2026-05-08 17:53 UTC · model grok-4.3
The pith
ARIS coordinates autonomous machine learning research by pairing an executor model with a reviewer from a different model family to catch plausible but unsupported claims.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
ARIS establishes that machine-learning research workflows can be coordinated through cross-model adversarial collaboration as a default configuration, where an executor model drives forward progress and a reviewer from a different model family critiques intermediate artifacts and requests revisions to ensure evidential support.
What carries the argument
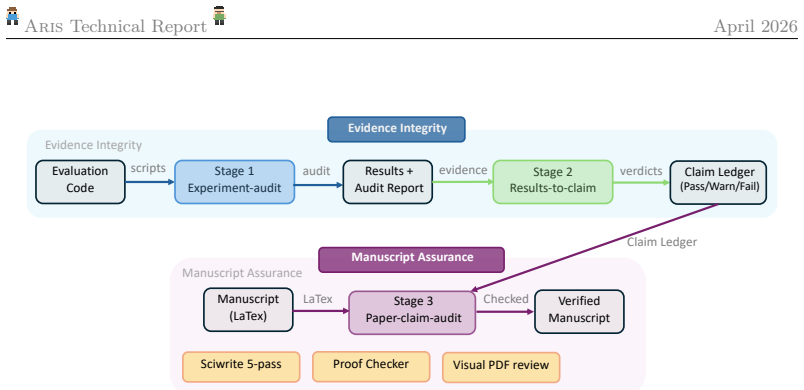
The assurance layer, which performs a three-stage process of integrity verification, result-to-claim mapping, and claim auditing that cross-checks manuscript statements against the claim ledger and raw evidence.
If this is right
- Workflows maintain evidence through iterative revisions requested by the reviewer.
- The persistent wiki enables reuse of prior findings under review.
- Experimental claims undergo scientific-editing and proof checks before final output.
- A self-improvement loop records traces and adopts harness changes only after reviewer approval.
Where Pith is reading between the lines
- This method could extend to non-ML research domains if similar model families are available for review.
- Reducing human intervention in research might accelerate discovery cycles but requires validation of the reviewer's reliability.
- Integration with more models could strengthen the adversarial aspect over time.
Load-bearing premise
A reviewer model from a different family will reliably detect and force correction of plausible but unsupported claims produced by the executor in long-horizon workflows.
What would settle it
An experiment in which the executor model inserts a fabricated or unsupported claim into the workflow and the reviewer model fails to identify or request revision of the unsupported element.
Figures









read the original abstract
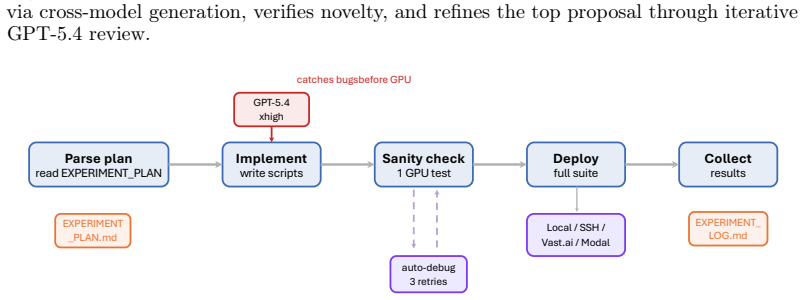
This report describes ARIS (Auto-Research-in-sleep), an open-source research harness for autonomous research, including its architecture, assurance mechanisms, and early deployment experience. The performance of agent systems built on LLMs depends on both the model weights and the harness around them, which governs what information to store, retrieve, and present to the model. For long-horizon research workflows, the central failure mode is not a visible breakdown but a plausible unsupported success: a long-running agent can produce claims whose evidential support is incomplete, misreported, or silently inherited from the executor's framing. Therefore, we present ARIS as a research harness that coordinates machine-learning research workflows through cross-model adversarial collaboration as a default configuration: an executor model drives forward progress while a reviewer from a different model family is recommended to critique intermediate artifacts and request revisions. ARIS has three architectural layers. The execution layer provides more than 65 reusable Markdown-defined skills, model integrations via MCP, a persistent research wiki for iterative reuse of prior findings, and deterministic figure generation. The orchestration layer coordinates five end-to-end workflows with adjustable effort settings and configurable routing to reviewer models. The assurance layer includes a three-stage process for checking whether experimental claims are supported by evidence: integrity verification, result-to-claim mapping, and claim auditing that cross-checks manuscript statements against the claim ledger and raw evidence, as well as a five-pass scientific-editing pipeline, mathematical-proof checks, and visual inspection of the rendered PDF. A prototype self-improvement loop records research traces and proposes harness improvements that are adopted only after reviewer approval.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents ARIS (Auto-Research-in-sleep), an open-source harness for autonomous machine-learning research. It coordinates workflows via a default cross-model adversarial setup in which an executor model advances research while a reviewer from a different model family critiques artifacts and requests revisions. The architecture comprises an execution layer (65+ Markdown skills, MCP integrations, persistent wiki, deterministic figures), an orchestration layer (five workflows with adjustable effort and routing), and an assurance layer (three-stage claim auditing for integrity, result-to-claim mapping, and cross-checks against a claim ledger, plus a five-pass editing pipeline, proof checks, and PDF inspection). A prototype self-improvement loop records traces and adopts harness changes only after reviewer approval.
Significance. If the assurance mechanisms were shown to reliably detect and correct evidential gaps, ARIS would offer a concrete, reusable framework for mitigating a recognized failure mode in long-horizon LLM agents. The open-source release, extensive reusable skill library, and deterministic components constitute practical contributions that could be adopted by other agent systems. At present, however, the work remains a detailed design proposal whose central assurance claim rests on architectural description rather than demonstrated performance.
major comments (2)
- [Abstract / Assurance layer] Abstract and assurance-layer description: the central claim that the default cross-model (different-family) reviewer configuration prevents plausible but unsupported success is presented as the key mitigation, yet the manuscript reports no quantitative results from the claimed early deployment experience—no detection rates for unsupported claims, no counts of revisions forced by reviewers, no same-family vs. cross-family comparison on injected errors, and no measurement of whether reviewer requests actually close evidential gaps.
- [Assurance layer] Orchestration and assurance layers: the three-stage claim auditing process (integrity verification, result-to-claim mapping, claim auditing against ledger and raw evidence) and five-pass editing pipeline are described in detail, but no concrete examples or metrics are supplied showing that these stages actually surface and correct the specific failure mode of silently inherited or misreported claims in multi-step workflows.
minor comments (2)
- [Abstract] The abstract refers to 'early deployment experience' without specifying the number of research tasks, models used, or duration; adding a short table or paragraph with these basic deployment statistics would improve reproducibility.
- [Throughout] The manuscript introduces several new terms (claim ledger, MCP, ARIS research harness) without an explicit glossary or first-use definitions; a short nomenclature table would aid readers.
Simulated Author's Rebuttal
We thank the referee for the careful review and for recognizing the practical value of the open-source release, skill library, and deterministic components. We agree that stronger empirical illustration of the assurance mechanisms would improve the manuscript and address this below. We respond point-by-point to the major comments.
read point-by-point responses
-
Referee: [Abstract / Assurance layer] Abstract and assurance-layer description: the central claim that the default cross-model (different-family) reviewer configuration prevents plausible but unsupported success is presented as the key mitigation, yet the manuscript reports no quantitative results from the claimed early deployment experience—no detection rates for unsupported claims, no counts of revisions forced by reviewers, no same-family vs. cross-family comparison on injected errors, and no measurement of whether reviewer requests actually close evidential gaps.
Authors: We acknowledge the absence of quantitative metrics such as detection rates or controlled comparisons. The manuscript presents ARIS primarily as a system architecture with qualitative early-deployment observations rather than a full empirical evaluation. In revision we will add concrete counts of reviewer-requested revisions and adopted changes drawn from our prototype traces, plus one or two worked examples showing how cross-model review closed specific evidential gaps. We do not possess data from same-family versus cross-family experiments on injected errors; such a study would require a separate experimental design outside the scope of the current design-focused report. The open-source release is intended to enable exactly these follow-on measurements by the community. revision: partial
-
Referee: [Assurance layer] Orchestration and assurance layers: the three-stage claim auditing process (integrity verification, result-to-claim mapping, claim auditing against ledger and raw evidence) and five-pass editing pipeline are described in detail, but no concrete examples or metrics are supplied showing that these stages actually surface and correct the specific failure mode of silently inherited or misreported claims in multi-step workflows.
Authors: We agree that explicit examples would make the mechanisms more convincing. The revised manuscript will include a detailed trace of at least one multi-step workflow in which the claim-auditing stage identified a silently inherited or misreported claim (e.g., a result incorrectly attributed to an earlier step) and how the five-pass editing pipeline corrected the manuscript. Where deployment logs permit, we will also report the number of claims processed and the fraction that required revision at each stage. revision: yes
- Large-scale quantitative benchmarks (detection rates, precision/recall of the assurance layer, or controlled same-family vs. cross-family ablation studies) are not available from the early-deployment data and cannot be generated without new, dedicated experiments.
Circularity Check
No circularity: system description with no derivations or self-referential reductions
full rationale
The manuscript is a descriptive system paper outlining ARIS architecture (execution, orchestration, and assurance layers), workflows, and design choices for cross-model review. No equations, fitted parameters, predictions, or self-citations appear as load-bearing elements. The central claim that cross-model reviewers mitigate plausible unsupported claims is presented as an architectural recommendation rather than a derived result that reduces to its own inputs by construction. Absence of quantitative validation data is a separate empirical gap, not circularity.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption LLM agents can execute research tasks when supplied with reusable skills, persistent memory, and orchestration workflows
- domain assumption A reviewer model from a different family can detect incomplete or misreported evidence in executor outputs
invented entities (1)
-
ARIS research harness
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Constitutional AI: Harmlessness from AI Feedback
Yuntao Bai, Saurav Kadavath, Sandipan Kundu, Amanda Askell, Jackson Kernion, Andy Jones, Anna Chen, Anna Goldie, Azalia Mirhoseini, Cameron McKinnon, et al. Constitu- tional ai: Harmlessness from ai feedback, 2022.URL https://arxiv. org/abs/2212.08073, 2212,
work page internal anchor Pith review arXiv 2022
-
[2]
Juraj Gottweis, Wei-Hung Weng, Alexander Daryin, Tao Tu, Anil Palepu, Petar Sirkovic, Artiom Myaskovsky, Felix Weissenberger, Keran Rong, Ryutaro Tanno, et al. Towards an ai co-scientist.arXiv preprint arXiv:2502.18864,
work page internal anchor Pith review arXiv
-
[3]
rlhf: Scaling reinforcement learning from human feedback with ai feedback , author=
URL https://gist.github.com/ karpathy/442a6bf555914893e9891c11519de94f. Accessed: 2026-05-03. Harrison Lee, Samrat Phatale, Hassan Mansoor, Thomas Mesnard, Johan Ferret, Kellie Lu, Colton Bishop, Ethan Hall, Victor Carbune, Abhinav Rastogi, et al. Rlaif vs. rlhf: Scaling reinforcement learning from human feedback with ai feedback.arXiv preprint arXiv:2309.00267,
-
[4]
Meta-Harness: End-to-End Optimization of Model Harnesses
Yoonho Lee, Roshen Nair, Qizheng Zhang, Kangwook Lee, Omar Khattab, and Chelsea Finn. Meta-harness: End-to-end optimization of model harnesses.arXiv preprint arXiv:2603.28052,
work page internal anchor Pith review arXiv
-
[5]
AutoSOTA: An End-to-End Automated Research System for State-of-the-Art AI Model Discovery
Yu Li, Chenyang Shao, Xinyang Liu, Ruotong Zhao, Peijie Liu, Hongyuan Su, Zhibin Chen, Qinglong Yang, Anjie Xu, Yi Fang, et al. Autosota: An end-to-end automated research system for state-of-the-art ai model discovery.arXiv preprint arXiv:2604.05550,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Encouraging divergent thinking in large language models through multi-agent debate
16 ArisTechnical Report April 2026 Tian Liang, Zhiwei He, Wenxiang Jiao, Xing Wang, Yan Wang, Rui Wang, Yujiu Yang, Shuming Shi, and Zhaopeng Tu. Encouraging divergent thinking in large language models through multi-agent debate. InProceedings of the 2024 conference on empirical methods in natural language processing, pp. 17889–17904, 2024a. Weixin Liang,...
2026
-
[7]
https://arxiv.org/abs/2306.00622
URLhttps://github.com/aiming-lab/AutoResearchClaw. Ryan Liu and Nihar B Shah. Reviewergpt? an exploratory study on using large language models for paper reviewing.arXiv preprint arXiv:2306.00622,
-
[8]
The AI Scientist: Towards Fully Automated Open-Ended Scientific Discovery
Chris Lu, Cong Lu, Robert Tjarko Lange, Jakob Foerster, Jeff Clune, and David Ha. The ai scientist: Towards fully automated open-ended scientific discovery.arXiv preprint arXiv:2408.06292,
work page internal anchor Pith review arXiv
-
[9]
Ziming Luo, Atoosa Kasirzadeh, and Nihar B Shah. The more you automate, the less you see: Hidden pitfalls of ai scientist systems.arXiv preprint arXiv:2509.08713,
-
[10]
arXiv preprint arXiv:2603.08127 (2026)
Yougang Lyu, Xi Zhang, Xinhao Yi, Yuyue Zhao, Shuyu Guo, Wenxiang Hu, Jan Piotrowski, Jakub Kaliski, Jacopo Urbani, Zaiqiao Meng, Lun Zhou, and Xiaohui Yan. Evoscientist: Towards multi-agent evolving ai scientists for end-to-end scientific discovery.arXiv preprint arXiv:2603.08127,
-
[11]
Self-Refine: Iterative Refinement with Self-Feedback
Aman Madaan, Niket Tandon, Prakhar Gupta, Skyler Hallinan, Luyu Gao, Sarah Wiegreffe, Uri Alon, Nouha Dziri, Shrimai Prabhumoye, Yiming Yang, et al. Self-refine: Iterative refinement with self-feedback, 2023.URL https://arxiv. org/abs/2303.17651, 2303,
work page internal anchor Pith review arXiv 2023
-
[12]
dev/overview/skills
URL https://docs.openhands. dev/overview/skills. Accessed: 2026-05-03. Chen Qian, Wei Liu, Hongzhang Liu, Nuo Chen, Yufan Dang, Jiahao Li, Cheng Yang, Weize Chen, Yusheng Su, Xin Cong, et al. Chatdev: Communicative agents for software development. InProceedings of the 62nd annual meeting of the association for computational linguistics (volume 1: Long pap...
2026
-
[13]
Coursera, Stanford University
URLhttps: //www.coursera.org/learn/sciwrite. Coursera, Stanford University. Samuel Schmidgall, Yusheng Su, Ze Wang, Ximeng Sun, Jialian Wu, Xiaodong Yu, Jiang Liu, Michael Moor, Zicheng Liu, and Emad Barsoum. Agent laboratory: Using llm agents as research assistants.Findings of the Association for Computational Linguistics: EMNLP 2025, pp. 5977–6043,
2025
-
[14]
Reflexion: Language Agents with Verbal Reinforcement Learning
URL https://arxiv. org/abs/2303.11366, 8,
work page internal anchor Pith review arXiv
-
[15]
Ai can learn scientific taste.arXiv preprint arXiv:2603.14473, 2026
Jingqi Tong, Mingzhe Li, Hangcheng Li, Yongzhuo Yang, Yurong Mou, Weijie Ma, Zhiheng Xi, Hongji Chen, Xiaoran Liu, Qinyuan Cheng, et al. Ai can learn scientific taste.arXiv preprint arXiv:2603.14473,
-
[16]
Claw Code: Public rust implementation of the claw cli agent harness
17 ArisTechnical Report April 2026 UltraWorkers. Claw Code: Public rust implementation of the claw cli agent harness. GitHub repository,
2026
-
[17]
Accessed: 2026- 05-03
URLhttps://github.com/ultraworkers/claw-code. Accessed: 2026- 05-03. Xingyao Wang, Boxuan Li, Yufan Song, Frank F. Xu, Xiangru Tang, Mingchen Zhuge, Jiayi Pan, Yueqi Song, Bowen Li, Jaskirat Singh, Hoang H. Tran, Fuqiang Li, Ren Ma, Mingzhang Zheng, Bill Qian, Yanjun Shao, Niklas Muennighoff, Yizhe Zhang, Binyuan Hui, Junyang Lin, Robert Brennan, Hao Peng...
2026
-
[18]
AutoGen: Enabling Next-Gen LLM Applications via Multi-Agent Conversation
URLhttps://arxiv.org/abs/2308.08155. Yutaro Yamada, Robert Tjarko Lange, Cong Lu, Shengran Hu, Chris Lu, Jakob Foerster, Jeff Clune, and David Ha. The ai scientist-v2: Workshop-level automated scientific discovery via agentic tree search.arXiv preprint arXiv:2504.08066,
work page internal anchor Pith review arXiv
-
[19]
Self-Rewarding Language Models
Weizhe Yuan, Richard Yuanzhe Pang, Kyunghyun Cho, Xian Li, Sainbayar Sukhbaatar, Jing Xu, and Jason Weston. Self-rewarding language models.arXiv preprint arXiv:2401.10020,
work page internal anchor Pith review arXiv
-
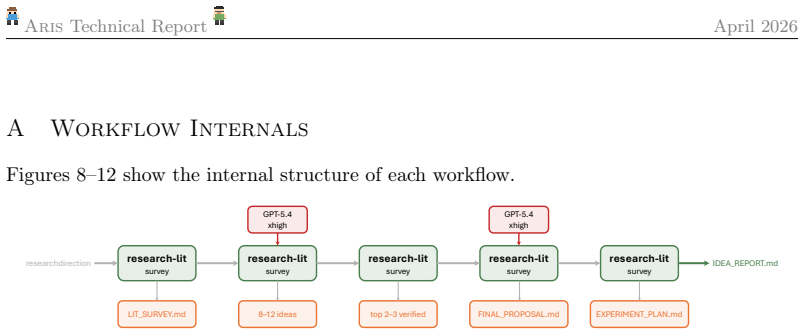
[20]
18 ArisTechnical Report April 2026 A Workflow Internals Figures 8–12 show the internal structure of each workflow. research-litsurveyresearch-litsurveyresearch-litsurveyresearch-litsurveyresearch-litsurvey GPT-5.4xhigh GPT-5.4xhigh LIT_SURVEY .md8–12 ideastop 2–3 verifiedFINAL_PROPOSAL.mdEXPERIMENT_PLAN.md researchdirection IDEA_REPORT.md Figure 8: Workfl...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.